
有些性能提升,一眼就能看出来。比如平均延迟更低了,吞吐更高了,首 token 更快了。这样的数字很适合放在 benchmark 表格里,也很适合拿出来做对比。但还有一种性能提升,不是第一眼最炸裂,却更接近真实体验。它不是让系统"最快的时候再快一点",而是让系统在持续使用、多会话切换、长上下文推进的时候,不那么容易突然卡一下。
如果你经常和 AI 系统连续对话,你一定知道这种差别有多明显。有时候系统不是普遍慢,它只是偶尔慢。 平时都很顺,但某一轮突然停住三秒、五秒,用户的感觉就会瞬间从"真流畅"变成"怎么又卡了"。
这类问题,在单轮问答里不一定明显,在实验室里也未必突出,但一旦进入真实多 session 的使用场景,就会变成最影响体感的一部分。
最近,我们把 Mooncake 正式引入 OpenClaw 的推理链路里,专门围绕这件事做了一轮验证。结果很直接:Mooncake 带来的最大变化,不是把已经很快的请求再压快一点,而是把那些最影响体验的长尾延迟,明显拉回来了。换句话说:OpenClaw 不只是更快了,更重要的是更稳了。
Mooncake 作为业界主流的分布式 KVCache 存储引擎,通过专用缓存集群为 SGLang 等推理框架提供高吞吐、低延迟的服务。龙蜥社区不仅是 Mooncake 的重要支持者,而且核心代码的主要贡献者来自阿里云、浪潮信息、摩尔线程等龙蜥社区智算联盟成员单位。目前,龙蜥社区已在官方组织(openanolis)下正式 Fork 该项目,并推动其原生集成至 Anolis OS 与 ANCK 内核体系。未来,龙蜥社区智算联盟将持续深化贡献,致力将 Mooncake 打造为面向大模型场景的标准化存储底座,加速其从开源项目向生产级智算基础设施的转化落地。
为什么想认真讲这次升级
过去大家聊模型性能,经常会自然地盯着两个方向看:平均值和极限值。前者决定"整体快不快",后者决定"跑分好不好看"。但对于真正拿来用的系统来说,还有一个指标往往更关键,那就是长尾。因为用户不会用统计学和你对话。用户只会记得两件事:
- 这套系统大多数时候是不是很跟手。
- 它会不会在关键时刻突然掉链子。
如果一个系统平时都很快,但偶尔突然卡到几秒钟,它在用户心里的评价通常不会是"平均性能不错",而是"有点不稳"。
这就是为什么我们一直觉得,OpenClaw 这种面向真实持续交互的系统,不能只看快路径。
快路径当然重要,但慢路径的上限,很多时候更决定体验。
这次 Mooncake 接入 OpenClaw,我们最关心的也正是这一点:
在多会话、长上下文、连续轮转的真实使用模式下,它能不能把那些偶发的慢请求压下去?
我们拿到的答案是:能。
而且不是"略有帮助",而是那种一看曲线就能明白的改善。
先说结论:这次最大的收益,是稳定性升级
如果只用一句话概括这轮结果,我们会这样说:
Mooncake 改变的不是最快请求有多快,而是最慢请求还能有多慢。
这句话不是修辞,基本就是我们这轮测试最核心的观察。
在 baseline,也就是 OpenClaw + SGLang 的配置下,系统的中位数其实已经不差。 真正的问题,不在那些顺利跑完的请求上,而在少数会突然拉得很长的请求上。
而接入 Mooncake 之后,这部分最影响体验的尖峰明显被削平了。
这类提升,放在图表里是性能;放到产品里,就是流畅度;落到用户感受上,就是一句很简单的话:
"这次怎么顺了这么多。"
这次我们没有绕开 OpenClaw,而是保留了真实链路
很多性能测试一旦想把结论做得更漂亮,第一步往往就是把系统链路尽量简化,最后变成一个"脱离产品环境"的纯模型 benchmark。
我们这次没有这么做,原因也很简单。
如果我们想验证的是 Mooncake 在 OpenClaw 里的真实价值,那就应该尽量保留 OpenClaw 的真实链路,而不是只拿一段最理想的模型调用来说明问题。
所以,这轮测试里我们保留了:
- OpenClaw Gateway 请求入口
- session 路由
- prompt 组装
- provider 调用
- 多 session 轮转
- 长上下文压力
也就是说,用户平时怎么通过 OpenClaw 去访问模型,这轮测试里大体也还是那条路。
整个主链路可以简单画成这样:

这点很重要,因为它意味着这轮结果不是"只在理想环境里有效",而是已经在 OpenClaw 自己的真实链路里,开始体现出明显收益。 我们把噪声拿掉了,只看更接近推理本身的主路径
当然,保留真实链路,不等于什么都往里塞。
我们这次做了一件非常关键的事:把 tool path 相关的噪声先拿掉。
因为如果把工具调用、工具执行、工具结果处理这些路径全部混在一起,最终测到的就是完整产品体验,而不是更接近推理行为本身的结果。那样当然也有价值,但不利于看清 Mooncake 在多会话推理阶段到底起了多大作用。
所以这轮测试里,我们专门做了 pure-text 口径:
-
请求仍然走 OpenClaw Gateway
-
多 session 轮转保留
-
长上下文保留
-
tools 关闭
-
重点观测首个可见 token 的 TTFT
同时,我们还针对 Qwen3 的输出特性做了一个小控制:在 system prompt 里启用 /no_think,确保统计的是用户真正看到回复的时刻,而不是被隐藏推理过程拖慢的可见输出。
所以,换一个更容易理解的说法,这次测试测的是:真实 OpenClaw 路径下,更接近 GPU 推理主链路的表现。
这也是为什么这次结果,比之前那轮"全量端到端测试"更能说明 Mooncake 本身的价值。
测试方式并不花哨,但很像真实场景
参数方面,我们没有故意堆一个特别夸张的压测模型,而是选择了一组更接近真实使用节奏的设置:
-
模型:Qwen3-14B
-
2 个独立 session
-
每个 session 4 轮
-
round-robin 轮转推进
-
第一轮约 24000 字符上下文
-
后续每轮继续注入约 8000 字符上下文
-
每组 1 轮 warmup + 3 轮正式测量
-
重点看首个可见 token 的到达时间
这组参数的意义在于:它既不是单会话的理想实验,也不是一个只追求极端压力的暴力压测,而是一种更接近真实使用的状态。
你有多个会话在同时推进,每个会话都有越来越长的历史,系统要在这些会话之间来回切换。而用户想要的,是一种持续、稳定、不断线的响应感。
这正是 OpenClaw 需要面对的场景。
baseline 给了很典型的答案:不是不快,是不够快
先看 baseline,也就是 OpenClaw + SGLang。我们测到的关键数据是:
- turn1 TTFT p50 = 756ms
- turn1 TTFT p95 = 5295ms
- turn2+ TTFT p50 = 171ms
- turn2+ TTFT p95 = 4909ms
如果只看 turn2+ p50 = 171ms,你甚至会觉得这套系统已经挺快了。
这个判断其实并没有错,它确实不算慢,问题在于,用户不会只遇到 p50,还会遇到 p95。
当请求落在尾部的时候,它不是多等一两百毫秒,而是会直接被拉到 4 秒、5 秒这个量级。对于持续对话来说,这样的停顿非常容易被感知,也非常容易打断使用节奏。
换句话说,baseline 的问题不是"整体都慢",而是:快的时候已经很快,但慢的时候还是会突然很慢。
下图一眼就能看出来:
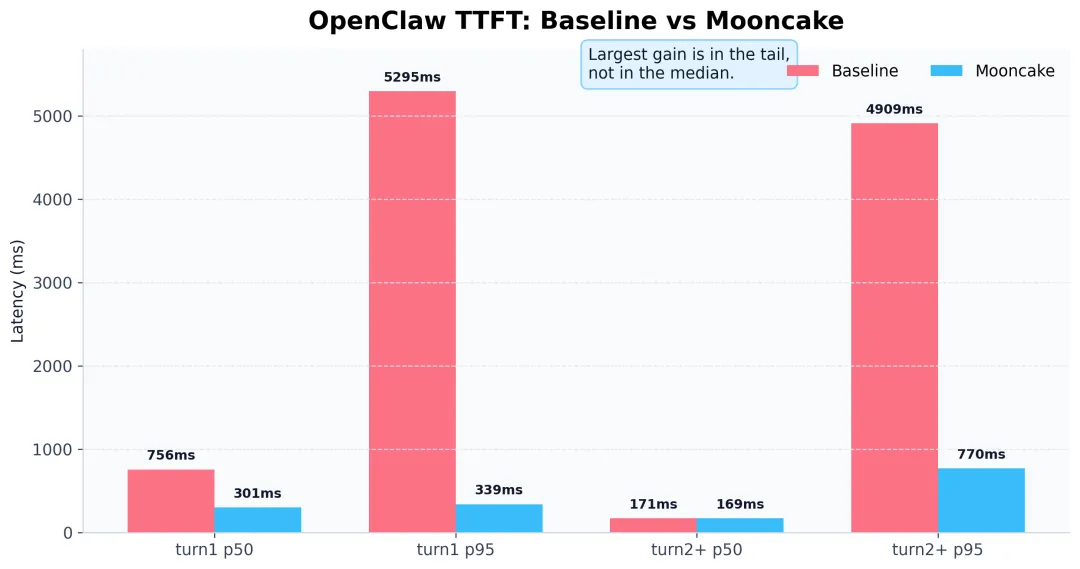
对真实产品来说,这种"中位数不错,但长尾很重"的状态,往往就是最难受的地方。
因为它不会让你觉得系统彻底不可用,但会让你反复在"还不错"和"怎么又卡了"之间来回横跳。
Mooncake 接入后,系统开始呈现出另一种气质
接下来,我们分别测试了三档 Mooncake 配置:4gb、8gb、32gb,结果几乎一样稳定:
Mooncake 4GB
-
turn1 TTFT p50 = 301ms
-
turn1 TTFT p95 = 339ms
-
turn2+ TTFT p50 = 169ms
-
turn2+ TTFT p95 = 770ms
Mooncake 8GB
-
turn1 TTFT p50 = 303ms
-
turn1 TTFT p95 = 339ms
-
turn2+ TTFT p50 = 169ms
-
turn2+ TTFT p95 = 770ms
Mooncake 32GB
-
turn1 TTFT p50 = 306ms
-
turn1 TTFT p95 = 339ms
-
turn2+ TTFT p50 = 169ms
-
turn2+ TTFT p95 = 770ms
把这些数字和 baseline 放在一起看,你会发现 Mooncake 做的并不是"再压 10ms、20ms"的那种局部微调。
它做的是另一件更重要的事:
-
turn1 p95: 5295ms -> 339ms
-
turn2+ p95: 4909ms -> 770ms
而与此同时:
- turn2+ p50: 171ms -> 169ms
这就是这轮结果最值得传播的地方。
Mooncake 不是简单让快路径更快,而是明显让慢路径没有那么慢了。
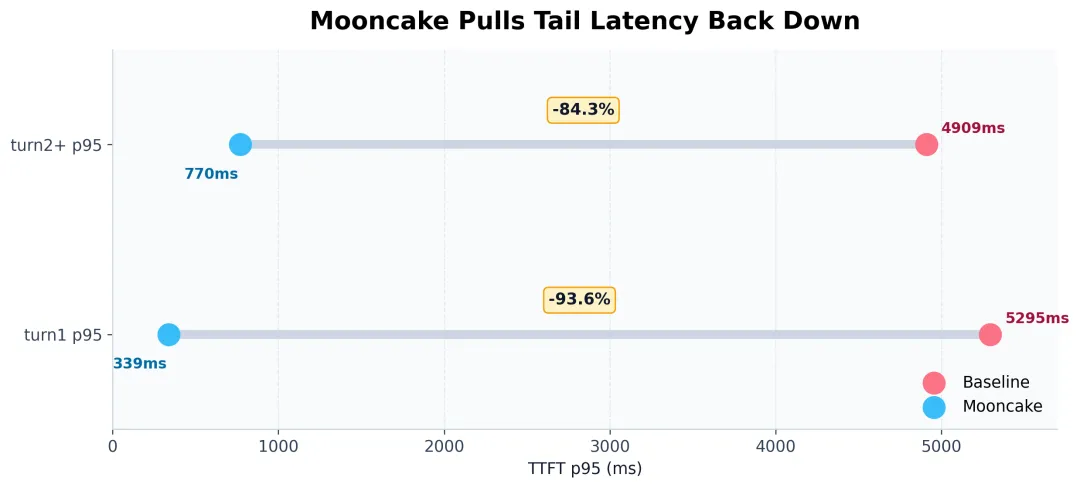
这类优化,放在技术表格里可能没有那种"p50 翻倍"的戏剧感,但放到真实体验里,它的价值非常直接:
-
更少的卡顿
-
更少的等待感
-
更少的掉节奏
-
更连续的交互体验
说到底,用户想要的从来不是"某些请求快得离谱",而是"每次用起来都挺顺"。
Mooncake 正在把 OpenClaw 往这个方向推。
这次真正被改写的,是多轮会话体感
为什么我们反复强调"多 session"?
因为很多系统在单轮、单会话、上下文较短的时候,本来就能跑得很好看。一旦进入多个会话轮流推进、上下文不断叠加的状态,缓存竞争、状态切换、前缀重建等问题才会真正开始暴露。
对于 OpenClaw 这样的系统来说,这不是边角料,而是主战场。因为真实用户不是只问一个问题就走人。他们会连续提问,会切换主题,会在不同会话之间跳转,会把系统真正拖进"持续使用"的状态。
Mooncake 给 OpenClaw 带来的价值,也正是在这里变得很明显:
-
多个 session 来回切换,系统更平滑。
-
长上下文继续向前推进,首 token 更稳定。
-
交互节奏更连贯,体感不容易断。
-
系统给人的感觉,更像"始终在线",而不是"偶尔需要等一等"。
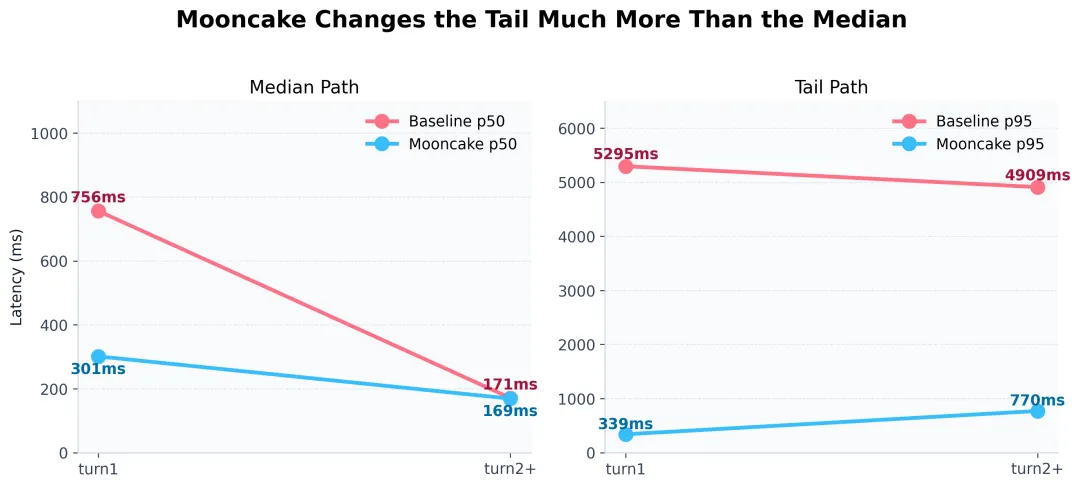
这种变化,很难只用一个"平均值提升"去概括。
它更像是一种从"能跑"到"顺手"的跃迁。
另外一个惊喜点:4GB 就已经够有感觉了
这轮测试里,还有一个结果让我们觉得很有意思。
Mooncake 从 4gb 提升到 8gb,再到 32gb,在当前 workload 下,核心指标几乎没有继续变化。
用图来看非常直观:
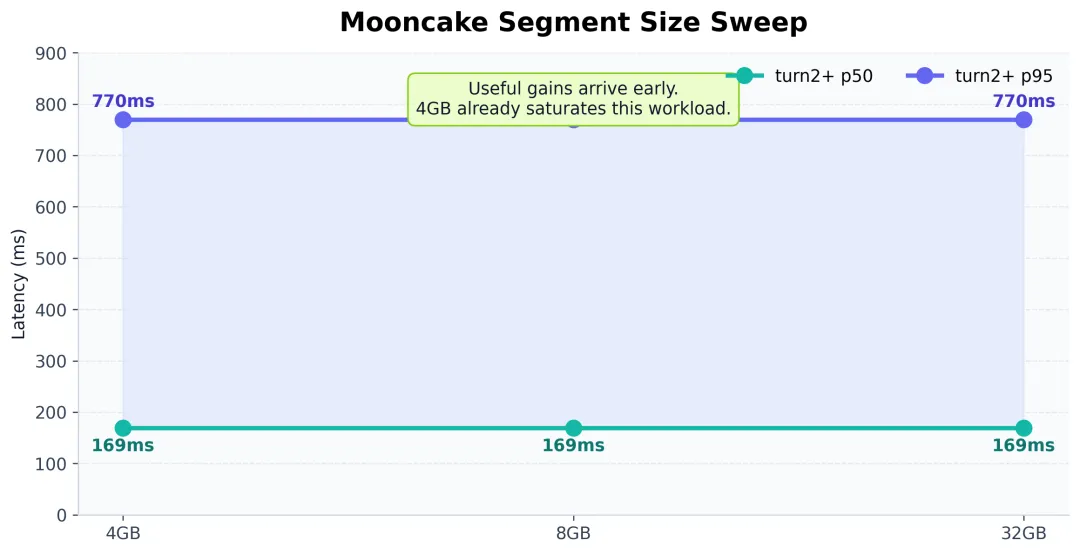
这说明一件很重要的事:Mooncake 的收益出现得很早。也就是说,它并不需要一个特别夸张的配置,才开始显现价值。对工程落地来说,这绝对是个好消息,因为它意味着:
-
方案更容易试
-
配置空间更友好
-
收益和成本的平衡点更靠前
-
真实接入门槛更低
很多技术方案的问题在于,理论上很强,真正落地时却需要很重的条件。 这次 Mooncake 给我们的感受恰恰相反:它的收益不是遥远的,而是很快就能被看到。
从"平时很快,偶然很慢",变成了"整体都更顺"
我们其实可以把这轮结果总结成:Mooncake 让 OpenClaw 从"平时挺快,偶尔很慢",变成了"整体都更顺"。这句话听上去不复杂,但它其实就是用户体验里最有价值的部分。因为绝大多数人不会打开监控面板看 p50、p95。 他们只会凭直觉给出判断:
-
这套系统顺不顺
-
聊起来会不会断
-
会不会突然卡壳
而 Mooncake 这次最实在的贡献,就是让 OpenClaw 在这些维度上的表现更像一个成熟系统。
对 OpenClaw 来说,这不是一次小修补
OpenClaw 一直不是一个只为单轮问答设计的系统。
它天生就要面对更复杂的交互:
-
多 session
-
多轮对话
-
长上下文
-
连续工作流
-
更真实的任务推进节奏
在这样的系统里,稳定性从来都不是一个附加项,而是产品能力本身的一部分。
Mooncake 的引入,让我们第一次非常清楚地看到:当 OpenClaw 真正进入多会话、多轮上下文的真实工作状态之后,系统的响应曲线开始变得更平滑了,交互节奏开始变得更可预测了。
这不只是"性能更好"。
这更像是一次产品层面的体验升级。对用户来说,它意味着更顺。 对开发者来说,它意味着更稳。 对系统来说,它意味着更接近可持续承载真实使用强度的状态。
如果一定要用一句最短的话概括这次升级,我们会选这一句:
接入 Mooncake 之后,OpenClaw 不只是更快了,而是终于把"偶尔很慢"这件事,明显打下去了。
对一个真正要进入日常使用、持续对话、多会话交互场景的 AI 系统来说,这类提升,往往才是最有价值的性能提升。
------ 完 ------