核心技术篇③ | 虚拟人的声音情感:从语音合成到声音克隆
导语
虚拟人的拟人化体验,除了逼真的视觉形象,自然且富有情感的声音表达是核心关键。机械、无感情的合成语音会让虚拟人失去灵魂,而兼具音色辨识度、语气情感、说话节奏的声音,能让虚拟人的交互体验大幅提升。从基础的文本转语音(TTS),到能复刻真人声线的声音克隆,再到工业级的情感化声音定制,技术的迭代让虚拟人的"声音表达"越来越贴近真人。本文将从技术原理、主流工具、实战操作到工业级落地方案,全面拆解虚拟人声音技术的全链路内容。
通用发声
专属声线
文本输入
声音技术选择
语音合成 TTS
声音克隆 Voice Clone
情感/语气控制
虚拟人口型驱动
音频/视频输出
1. 虚拟人声音技术核心分类与主流工具
虚拟人的声音技术主要分为两大核心方向,二者相辅相成,共同实现虚拟人从"发声"到"个性化发声"的升级,同时衍生出语音合成+声音克隆的一站式工具,满足不同场景的需求。
1.1 核心技术分类
- 语音合成(TTS,Text-to-Speech) :核心是将文本内容转换为自然的语音音频,是虚拟人"开口说话"的基础,核心要求是发音标准、语气自然、支持情感与节奏控制;
- 声音克隆(Voice Clone) :基于少量真人音频样本(几秒到几十秒),复刻真人的音色、语气、说话习惯,让虚拟人拥有专属声线,是克隆式虚拟人的核心声音技术,核心要求是复刻精度高、音色还原度强、泛化性好。
1.2 全品类主流工具盘点
目前行业内的开源/商用工具按能力可分为三类,覆盖从基础合成到高端克隆的全场景,工具的核心特点与适配性如下表所示:
虚拟人声音技术工具分类
场景
场景
场景
纯语音合成
Fish Speech SOTA
ChatTTS 推荐
NaturalReaders
ElevenLabs
语音合成+声音克隆
MetaVoice
CozyVoice 2
XTTS v2
纯声音克隆
OpenVoice 推荐
通用虚拟人发声
直播讲解
AI客服
中小团队虚拟人定制
快速个性化发声
克隆式虚拟人
真人IP数字分身
| 能力分类 | 主流工具 | 核心特点 | 适配场景 |
|---|---|---|---|
| 纯语音合成 | Fish Speech(SOTA)、ChatTTS、NaturalReaders、ElevenLabs | 专注文本转语音,语气/情感控制能力强,合成效果自然,部分支持流式输出 | 通用虚拟人发声、直播讲解、AI客服 |
| 语音合成+声音克隆 | MetaVoice、CozyVoice 2、XTTS v2 | 兼顾高质量TTS与零样本声音克隆,一站式完成声音制作,无需单独工具配合 | 中小团队虚拟人定制、快速实现个性化发声 |
| 纯声音克隆 | OpenVoice | 专注音色迁移,零样本克隆效果好,开源生态完善,上手门槛低,支持多语言 | 克隆式虚拟人、真人IP数字分身的声线复刻 |
核心推荐 :国内开源场景下,ChatTTS 是语音合成的首选(对话场景优化、语气控制精细),OpenVoice 是声音克隆的主流工具(零样本、易操作),二者结合可满足90%以上的虚拟人声音制作需求。
2. 语音合成:让虚拟人说出自然有情感的话
语音合成是虚拟人声音技术的基础,而当下的TTS技术已从"能说话"升级为"会说话",支持精细化的语气控制、流式实时输出,完美适配虚拟人直播、实时交互等场景。其中,ChatTTS作为国内开源社区的标杆,是虚拟人场景的最优选择,以下将以ChatTTS为核心,拆解语音合成的核心技术与实战操作。
2.1 ChatTTS:专为对话场景优化的开源TTS
ChatTTS是面向自然对话场景设计的开源语音合成模型,相比传统TTS,其核心优势是拟人化对话感强、支持精细化的语气/停顿/情感控制、轻量级易部署,能完美模拟真人的说话节奏,适配虚拟人直播、答疑、互动等所有对话场景。
ChatTTS核心优势
对话场景优化
拟人化对话感强
模拟真人说话节奏
全局+局部语气控制
全局: Refine阶段统一定义风格
局部: 文本内嵌标签精准调整
流式输出
边推理边输出
延迟低至几百毫秒
轻量级部署
模型体积小
本地/云端均可部署
2.2 ChatTTS的精细化语气控制
ChatTTS的语气控制分为全局语气控制 和局部细粒度控制两个维度,可实现从整段语音的风格定义到词/句级的细节调整,让虚拟人的声音拥有丰富的情感表达。
2.2.1 全局语气控制:Refine阶段统一定义
在文本预处理的Refine阶段,通过设置prompt参数,可统一控制整段语音的口语化程度、笑意、停顿节奏,核心代码如下:
python
params_refine_text = chat.RefineTextParams(prompt='[oral_2][laugh_0][break_4]')参数中的标签为全局控制指令,可自由组合,实现整段语音的风格统一。
2.2.2 局部细粒度控制:文本内嵌标签精准调整
在需要合成的文本中,直接内嵌控制标签,可实现词级别、句子级别的停顿、笑声、断句调整,模拟真人说话时的换气、停顿与情感表达,示例如下:
python
TEXT = "大家好,[uv_break] 我是虚拟主播小A。[laugh] 今天给大家带来最新的产品讲解。[break_2]"ChatTTS控制标签体系
全局控制
Refine阶段
oral_2
laugh_0
break_4
局部控制
文本内嵌
uv_break
lbreak
laugh
break_2
口语化程度
0-9, 推荐2-5
笑意控制
0=轻笑, 1=普通笑, 2=大笑
段落停顿
0-7, 推荐2-4
词级停顿
模拟真人换气
换行断句
长文本分段
插入笑声
情感表达
句子停顿
控制节奏
| 标签类型 | 语法格式 | 含义/控制作用 | 取值/使用说明 |
|---|---|---|---|
| 口语化控制 | oral_\<0-9\> | 控制语音的口语化程度,数值越高越贴近真人对话 | 0-9,推荐2-5(虚拟人对话场景) |
| 笑意控制 | laugh_\<0-2\> | 插入笑声/表示笑意,还原真人的情感表达 | 0=轻笑,1=普通笑,2=大笑 |
| 段落停顿 | break_\<0-7\> | 控制句子/段落之间的停顿长度,值越大停顿越明显 | 0-7,推荐2-4(常规对话) |
| 词级停顿 | uv_break | 在词级别插入细粒度暂停,模拟真人换气 | 无取值,直接嵌入文本即可 |
| 换行断句 | lbreak | 词级暂停与换行断句控制,适配长文本分段 | 无取值,直接嵌入文本即可 |
2.3 流式TTS:解决虚拟人实时交互的延迟问题
普通TTS需要将整段文字生成完成后再输出音频,延迟极高,无法适配虚拟人直播、实时答疑等交互场景。流式TTS 则实现了"边推理、边输出",模型一边处理文本,一边分块输出语音音频,前端可即时播放,大幅降低交互延迟。
2.3.1 流式TTS的核心价值
- 普通TTS:整段生成,延迟与文本长度正相关,适合静态口播;
- 流式TTS:逐块生成,延迟低至几百毫秒,适合虚拟人实时对话、直播弹幕答疑等动态场景。
2.3.2 ChatTTS流式播放的整体架构
流式TTS的架构分为三层,核心依赖WebSocket(WSS) 实现双向实时通信,替代传统HTTP的"一次请求一次响应"模式,整体架构如下:
推理层
接口服务层
前端层
WSS双向实时通信
内部调用
Web/App
接收用户输入
实时播放流式音频
FastAPI + Uvicorn
接收文本请求
转发至推理层
逐块返回音频
ChatTTS推理引擎
流式生成语音块
逐块输出音频数据
3. 声音克隆:给虚拟人定制专属辨识度声线
如果说语音合成解决了虚拟人"能说话"的问题,声音克隆则解决了"说专属的话"的问题,让虚拟人拥有独一无二的声线,尤其是克隆式虚拟人,声音克隆是实现"真人1:1复刻"的核心技术。目前开源场景下,OpenVoice 是零样本声音克隆的主流工具,上手门槛低、复刻效果好,以下将拆解其核心原理、实战操作与优化方案。
3.1 OpenVoice核心特点
OpenVoice是一款开源的零样本声音克隆工具,核心优势体现在三个方面:
- 零样本克隆:仅需几秒真人清晰音频,即可实现高精度音色迁移,无需大量训练数据;
- 跨语言支持:支持多语言克隆,复刻的声线可流畅说出不同语言,泛化性强;
- 轻量级易操作:基于命令行即可实现全流程操作,无需复杂的模型训练,新手也能快速上手;
- 音色还原度高:能精准复刻真人的音色、音调,同时支持语气、语速的后续调整。
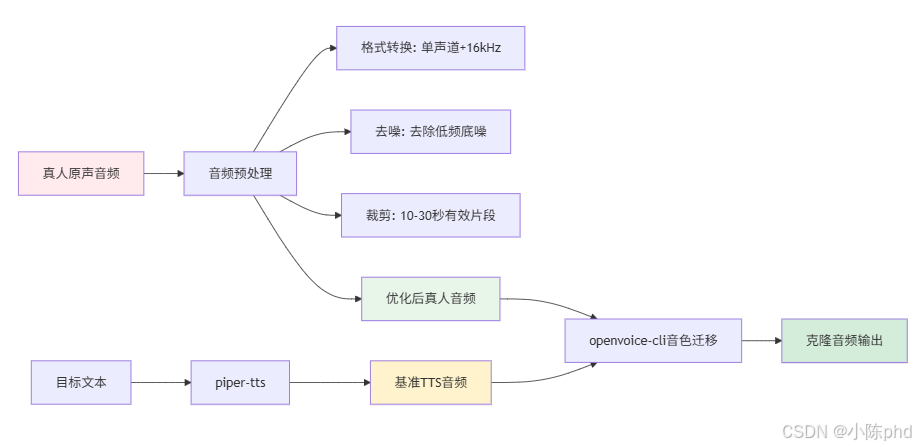
3.2 OpenVoice基础实战:从真人音频到克隆音频
OpenVoice的实战操作分为环境安装、音频预处理、基准TTS生成、声音克隆四个步骤,全程基于命令行,可直接在本地或服务器部署,以下是完整可运行的实战代码。
3.2.1 步骤1:环境安装
安装核心依赖包,包括ffmpeg(音频处理)、piper-tts(基准音频生成)、openvoice-cli(声音克隆核心):
bash
# 安装核心依赖
pip install ffmpeg piper-tts openvoice-cli3.2.2 步骤2:音频预处理(关键步骤)
声音克隆对源音频的格式要求严格,需将真人原声转换为单声道、16kHz采样率的WAV格式,同时可进行裁剪、去噪优化,提升克隆效果,核心命令如下:
bash
# 基础格式转换:m4a → WAV(单声道+16kHz)
ffmpeg -y -i Original_Sound.m4a -ac 1 -ar 16000 Original_Sound.wav
# 进阶优化:裁剪有效片段(10秒开始,时长25秒)+ 去底噪 + 音量标准化
ffmpeg -y -i Original_Sound.m4a -ss 00:00:10 -t 25 -ac 1 -ar 16000 Original_Sound_Crop.wav
ffmpeg -y -i Original_Sound_Crop.wav -af "highpass=f=100, loudnorm=I=-23:TP=-1.5:LRA=11" Original_Sound_Norm.wav优化要点:选择10-30秒的真人清晰无噪音频,去除背景音、静音片段,是提升克隆效果的关键。
3.2.3 步骤3:生成基准TTS音频
通过piper-tts生成一段基准音频,作为声音克隆的"底版",后续将把真人音色迁移至该基准音频:
bash
# 下载中文语音模型(medium版本,平衡效果与速度)
python -m piper.download_voices zh_CN-huayan-medium
# 文本转语音,生成基准音频(输入文本为Unread.txt,输出为TTS_Sound.wav)
python -m piper --model zh_CN-huayan-medium.onnx --output-file TTS_Sound.wav --input-file Unread.txt3.2.4 步骤4:执行声音克隆
通过openvoice-cli实现音色迁移,将基准音频的音色替换为真人原声的音色,生成最终的克隆音频:
bash
# 单文件声音克隆:-i=基准音频,-r=真人优化后音频,-o=克隆输出音频,-d=推理设备
python -m openvoice_cli single -i TTS_Sound.wav -r Original_Sound_Norm.wav -o Cloned_Sound.wav -d cuda设备参数 :-d cuda(N卡GPU)、-d mps(苹果M系列芯片)、-d cpu(通用CPU),根据自身硬件选择。
3.3 OpenVoice进阶优化:提升克隆效果的核心技巧
基础操作可实现音色复刻,而通过以下进阶优化,能让克隆的声音更自然、更贴近真人:
- 音频质量优化:优先使用真人近距离、无背景音的录音,避免杂音、混响;
- 时长控制:真人音频片段控制在10-30秒,覆盖不同声调、语速,让模型学习更全面;
- 去噪标准化:必须通过ffmpeg去除低频底噪(100Hz以下),并进行音量标准化,避免音量忽高忽低;
- 文本匹配:基准TTS的输入文本,尽量与真人音频的文本风格一致(如口语化/书面化),提升克隆的自然度。
4. 工业级虚拟人声音方案:从技术落地到体验优化
开源工具能满足基础的虚拟人声音制作需求,而工业级的虚拟人产品(如大厂数字人、真人IP数字分身、直播虚拟主播),对声音的复刻精度、情感表达、稳定性、适配性 要求更高,需要一套标准化的落地方案。以下拆解工业界(如豆包、讯飞星火等)的虚拟人声音克隆与合成方案,以及核心的声纹识别模型。
4.1 工业级Voice Clone核心落地方案
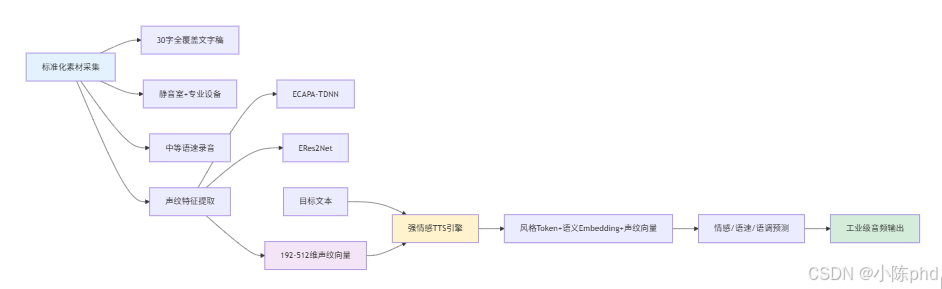
工业级方案摒弃了开源工具的"零样本"随意性,通过标准化素材采集、精准声纹提取、强情感TTS引擎,实现音色、语气、情感、说话习惯的全方位复刻,核心分为三步:
4.1.1 步骤1:标准化真人素材采集
预先设计**"发音全覆盖"的文字稿**(30字左右),包含中文全部声母、韵母、语调、连读、轻读等信息,同时固定录音环境(静音室)、设备(专业麦克风)、语速(中等),确保素材的标准化,让模型能完整学习真人的发音特点。
4.1.2 步骤2:精准声纹特征提取
不再采用零样本迁移,而是通过小型声纹识别模型,从真人音频中提取128维-512维的声纹特征向量,精准刻画说话人的音色、音调、声线特点,为后续的音色迁移提供精准的特征依据。
4.1.3 步骤3:强情感TTS引擎驱动
采用工业级TTS引擎(如Fish Speech,当前SOTA),该引擎内置情感建模、语速/停顿/语调预测、上下文风格建模能力,在输出阶段通过**"风格token+语义embedding+声纹向量"** 三者融合,精准控制虚拟人的说话方式,实现音色、语气、情感、说话节奏的全方位复刻,让虚拟人的声音与真人无异。
4.2 工业级核心:小型声纹识别模型
声纹特征提取是工业级声音克隆的核心,目前主流的小型声纹识别模型有两款,均能从几秒音频中提取高精度的声纹特征,适配虚拟人场景的轻量级部署需求。
4.2.1 ECAPA-TDNN:行业主流声纹提取模型
ECAPA-TDNN由SpeechBrain出品,是目前工业界的主流声纹识别模型,核心特点:
- 基于传统时间延迟网络(TDNN)优化,加入通道注意力机制(SE-block) 、残差多尺度结构(Res2Block) 和统计池化层(Attentive Statistical Pooling);
- 可在几秒音频中稳定提取192维声纹特征,特征辨识度高、抗干扰能力强;
- 轻量级易部署,适合虚拟人产品的端侧/服务侧集成。
4.2.2 ERes2Net:高精度声纹特征提取模型
ERes2Net由中国科学院研究所+南京理工大学+微软研究所联合出品,是高精度声纹提取的代表,核心特点:
- 在Res2Block基础上,实现全局特征与局部特征的深度融合;
- 全局特征融合:聚合不同层级的声学特征,刻画整体声线特点;
- 局部特征融合:提取单一残差块内的细节特征,还原发音的细微特点;
- 声纹特征的还原精度更高,适合对复刻效果要求极致的克隆式虚拟人。
4.3 工业级虚拟人声音的核心优化方向
工业级虚拟人声音的落地,除了技术实现,更注重用户体验的优化,核心围绕三个方向展开:
- 情感与场景适配:让虚拟人的声音情感与场景匹配(直播带货时热情、答疑时温和、讲解时专业);
- 语速与节奏动态调整:根据虚拟人的口型、动作节奏调整语速,实现"音画同步、声形合一";
- 多模态融合:将声音与虚拟人的面部表情、肢体动作结合,让声音的情感与视觉的情感一致,提升整体拟人化体验。
5. 虚拟人声音技术与口型驱动的联动
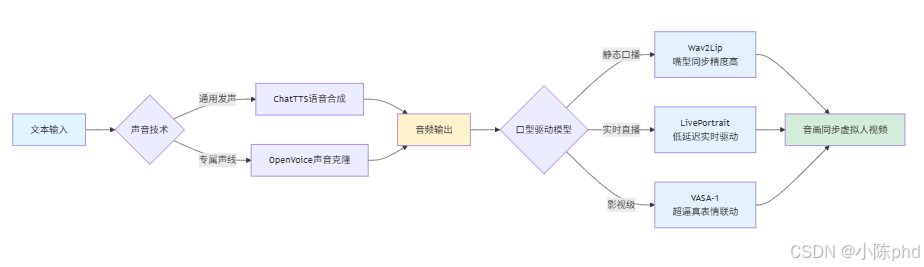
虚拟人的声音表达,最终需要与口型驱动技术联动,实现"音画同步",让声音与嘴型、表情完美匹配,这是虚拟人拟人化体验的最后一公里。目前主流的口型驱动模型(Wav2Lip、LivePortrait、VASA-1)均支持与TTS/声音克隆的音频联动,核心流程为:
文本输入 → ChatTTS/OpenVoice生成音频 → 口型驱动模型(音频+虚拟人形象)→ 音画同步的虚拟人视频核心联动推荐:
- 静态口播场景:ChatTTS+Wav2Lip(嘴型同步精度高);
- 实时直播场景:流式ChatTTS+LivePortrait(低延迟、实时表情/嘴型驱动);
- 影视级场景:工业级TTS+VASA-1(超逼真的声音与微表情/眼神联动)。
核心总结
虚拟人的声音技术,是从"能说话"到"会说话"再到"说专属的话"的迭代过程:
- 语音合成是基础,ChatTTS凭借精细化的语气控制、流式输出,成为国内虚拟人场景的开源首选,让虚拟人能自然、有情感地开口说话;
- 声音克隆是升级,OpenVoice实现了零样本的高精度音色复刻,让虚拟人拥有专属声线,适配克隆式虚拟人、真人IP数字分身等场景;
- 工业级方案是落地,通过标准化素材采集、精准声纹提取、强情感TTS引擎,实现音色、语气、情感的全方位复刻,满足大厂虚拟人产品的高要求;
- 与口型驱动联动是关键,让声音与嘴型、表情完美匹配,实现虚拟人"声形合一"的拟人化体验。
未来,虚拟人的声音技术将朝着多情感融合、跨模态联动、个性化定制的方向发展,结合大语言模型的语义理解,让虚拟人的声音不仅"自然",更能"懂语境、会表达",成为真正有灵魂的数字分身。
拓展指引
下一篇:核心技术篇④ | 让虚拟人"活起来":口型驱动与面部动画全技术拆解,将全面拆解Wav2Lip、LivePortrait、VASA-1三大主流口型驱动模型,从原理到实战,让虚拟人的声音与动作完美匹配。