运行大语言模型不仅昂贵,而且浪费。
每次你发送一个长提示词时,模型都会在所谓的 KV 缓存中存储大量中间数据。 这个缓存随着每个 token 不断增长,快速消耗 GPU 内存、拖慢响应速度并增加成本。
大多数解决方案试图压缩这些内存,但总会有一个权衡。你要么节省内存,要么损失精度。
Google 的 TurboQuant 打破了这个权衡。
它可以将 KV 缓存压缩高达 6 倍,在某些情况下,其性能与全精度模型完全相同。
这是一个不同寻常的结果。本文将用通俗易懂的语言解释其原因。
1、什么是 KV 缓存?

首先,你需要理解 KV 缓存到底是什么。它是 TurboQuant 要压缩的对象。
当语言模型处理文本时,它将输入分解为 token(大约每个词一个 token)。对于每个 token,模型计算两组数字:
一个 Key 和一个 Value。这些数字共同让模型在生成下一个词时决定应该对每个之前的 token 给予多少关注。
可以这样理解: Key 是一个标签,Value 是实际内容。当模型想要回忆某些内容时,它会查看所有 Key 来找到相关的那些,然后读取对应的 Value。KV 缓存为整个对话存储所有这些 Key-Value 对,这样模型就不会在每个新 token 上重新计算它们。
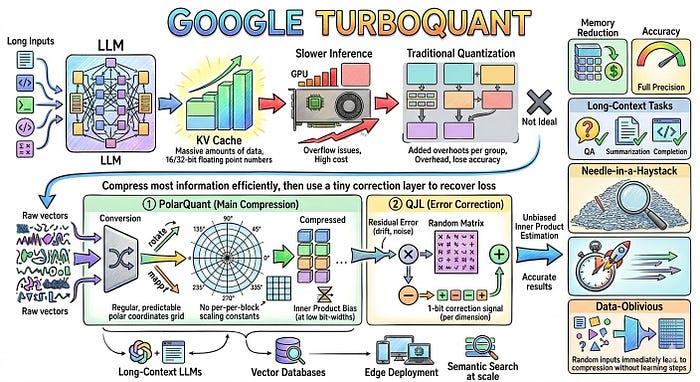
问题在于: 这些对以 16 位或 32 位浮点数存储。一个大模型的单层可能有数千万个这样的数字。有了数百层和数千个 token,KV 缓存可能消耗数 GB 的 GPU 内存。
量化的作用: 不再将每个数字存储为 16 位精度,而是将其存储为 3 或 4 位。文件变小了。查找更快了。但你在舍入中会损失一些精度。核心挑战是最小化这种精度损失。
2、向量到底是什么(以及为什么这很重要)
TurboQuant 是一个向量量化算法。 如果你没有在 AI 中使用过向量,以下是你需要了解的最基本知识。
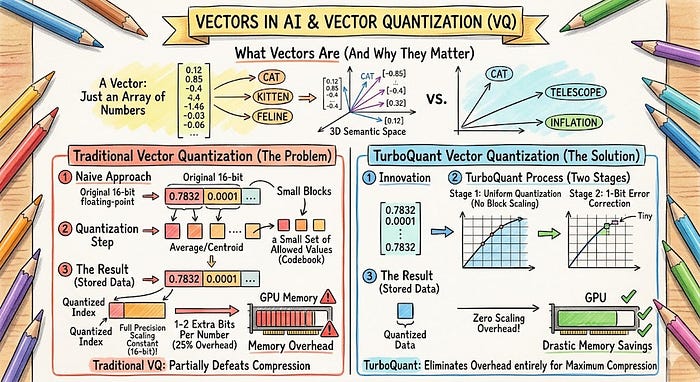
向量只是一组数字。
在 AI 中,向量是模型编码含义的方式。单词 "cat" 可能被表示为 1,536 个数字的列表。相似的词(cat、kitten、feline)有相似的向量。距离较远的概念(cat、telescope、inflation)有非常不同的向量。
向量量化意味着通过用从一小组允许值中提取的近似值替换精确值(如 0.7832194...)来压缩这些数字列表。压缩是有损的。问题在于你会损失多少信息。
朴素的方法将向量分成小块,计算每个块的平均值或质心,并存储每个数字属于哪个块的索引。
问题在于: 每个块都需要以全精度存储自己的缩放常数。这些常数为每个数字增加 1 到 2 个额外位,部分抵消了压缩效果。
TurboQuant 完全消除了这种开销。这就是核心创新。
3、老问题:内存开销
传统的向量量化有一个研究人员已经忍受了几十年的结构性缺陷。
当你量化一个数字块时,你需要知道该块的规模才能恢复原始值。
如果数字范围从 0 到 100,这与范围从 0 到 0.001 的块不同。所以你在量化数据旁边存储比例因子。
这些比例因子需要全精度(16 或 32 位),并且必须为每个小块存储。在 4 位量化方案中,为每个数字仅增加一个额外位的开销就是 25% 的存储成本增加。 这部分抵消了压缩的好处。
大多数现有方法,包括 KIVI(一种广泛使用的 KV 缓存量化器),都带有这种开销。它被认为是一种不可避免的成本。
TurboQuant 的两阶段设计通过选择不需要块级缩放常数的量化策略来消除它。
4、那么......这实际上是如何工作的?(简单来说)
在深入数学之前,让我简化一下 TurboQuant 真正在做什么。
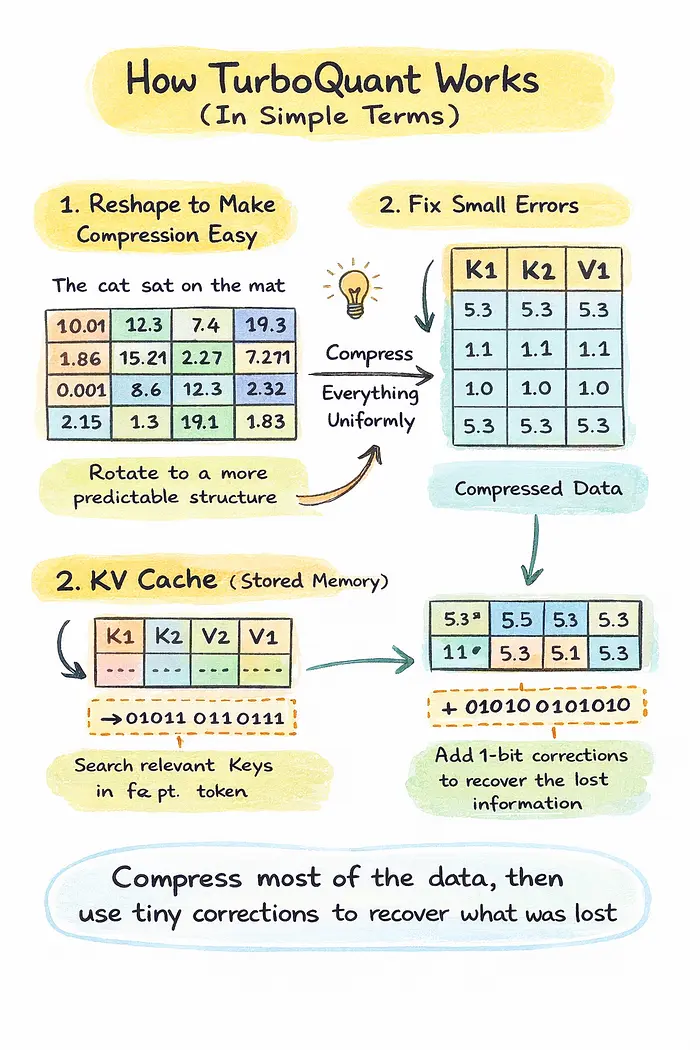
想象你有一个巨大的数字列表,代表模型内部的含义。这些数字是精确的,但完全存储它们是昂贵的。
所以目标很简单: 存储更少的位,但保持含义完整。
TurboQuant 通过两个智能步骤做到这一点:
首先,它将数据重塑成更容易压缩的形式不是处理杂乱、不均匀的值,而是将数据旋转成更可预测的结构。 这使得可以统一压缩所有内容,而无需为每个部分提供额外信息。
然后,它修复压缩过程中引入的小错误压缩总是会引起一些损失。TurboQuant 不是忽略它,而是捕获剩余的错误,并使用每位仅 1 位存储一个微小的校正信号。
简而言之:
它高效地压缩大部分信息,然后使用一个微小的校正层来恢复丢失的内容。
这就是为什么它可以在不影响性能的情况下将内存减少 4 到 6 倍。
5、TurboQuant 如何工作:两个阶段
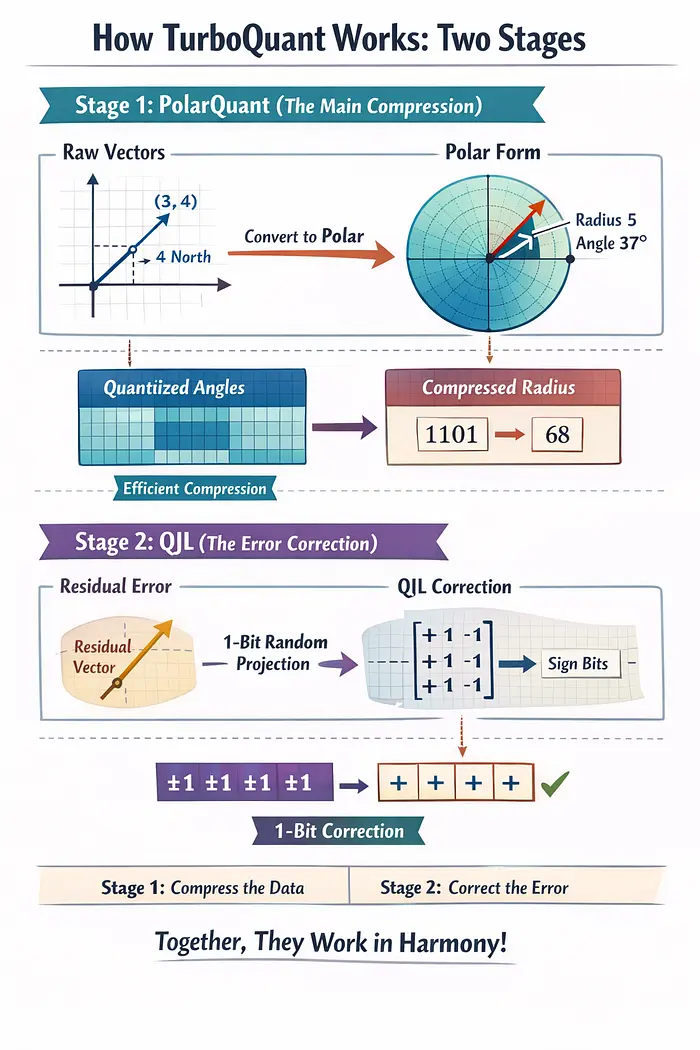
巧妙的部分不仅仅是一个想法。它是两个相互配合的想法。
阶段 1:PolarQuant(主要压缩)
标准量化之所以困难,是因为原始向量中的数字具有不可预测的分布。 一些维度有大值,其他维度有小值。你需要那些缩放常数来处理这种变化。
PolarQuant 通过在量化之前将向量转换为极坐标来解决这个问题。
这里极坐标的含义: 不是将空间中的点描述为"向东 3 个单位,向北 4 个单位"(笛卡尔坐标),极坐标说"总共 5 个单位,37 度角"。到原点的距离是半径 ,方向是角度。
当你将高维向量转换为其极坐标形式时,会发生一些有用的事情。 半径告诉你信号有多强。角度描述方向或含义。而且角度遵循一个可预测、集中的分布,可以整齐地放入固定网格中。
因为网格边界是可预测的,你不需要为每个块单独设置缩放常数。 几何本身处理它。这消除了困扰传统方法的内存开销。
但有一个问题。
PolarQuant(以及一般 MSE 优化的量化器)在内积估计中引入了一个微妙的偏差。
内积是模型在计算注意力分数时使用的:token 47 应该对 token 12 给予多少关注?有偏差的内积估计意味着这些注意力分数与全精度模型计算的结果略有偏差。
在高比特宽度下,这种偏差很小。在 1 到 2 位时,它变得显著。阶段 2 修复了它。
阶段 2:QJL(错误校正)
在阶段 1 量化了大部分信息后,还剩下一个小残余误差: 量化向量与原始向量之间的差距。
TurboQuant 使用一种称为 量化 Johnson-Lindenstrauss (QJL) 变换的技术对残余应用 1 位校正。
以下是 QJL 的作用:
- 它将残余向量乘以一个随机矩阵
- 它只取每个结果数字的符号(+1 或 -1)
- 每维一位
这听起来很有损。
但在数学上,应用这种特定的随机投影可以在期望中保留内积关系。
QJL 校正是无偏的:平均而言,它准确校正了阶段 1 引入的错误,而不为缩放常数添加任何内存开销。
结果是一个两阶段算法:
- 阶段 1 处理大部分压缩工作并消除内存开销
- 阶段 2 使用 1 位来校正阶段 1 引入的偏差
- 它们共同产生一个按信息论标准接近最优的量化器
论文从数学上证明,TurboQuant 的失真度在约 2.7 的因子范围内接近任何量化算法的理论最小值。这意味着你无法在不违反信息论定律的情况下做得更好。
6、实验与结果
我仔细研究了论文中的结果,这里是事情变得有趣的地方。
TurboQuant 不仅仅是理论上的改进。它实际上在使用更少内存的同时表现出与全精度模型相同的水平。
KV 缓存压缩(LongBench)
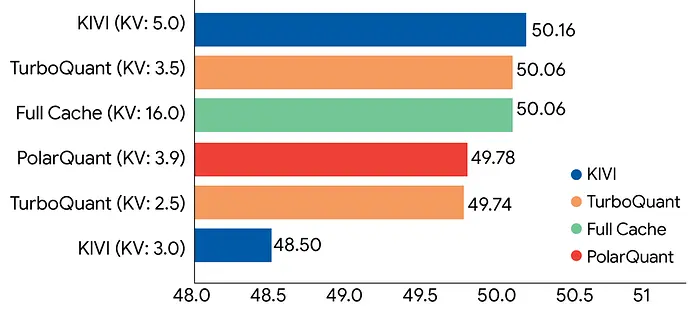
在长上下文任务上,如问答、摘要和代码生成:
-
在 3.5 位时,TurboQuant 完全匹配全精度
-
这已经是 4.5 倍更小的内存使用
-
在 **2.5 位(约 6 倍压缩)**时,性能下降非常小
与其他方法相比:
-
KIVI 在较低位数时开始丢失精度
-
PolarQuant 接近,但仍略落后
**这意味着什么:**你可以在不影响模型质量的情况下将内存减少 4-6 倍。
大海捞针测试(最难的测试)
这个测试检查模型是否能在巨大的文档中找到一小段信息。
-
TurboQuant:0.997(与全精度相同)
-
即使在非常长的上下文中(高达 100K token)也能工作
其他方法: -
SnapKV:0.858
-
PyramidKV:0.895
-
KIVI:0.981
-
PolarQuant:0.995
**这意味着什么:**即使在极端情况下,TurboQuant 也不会丢失精度。
速度:注意力计算
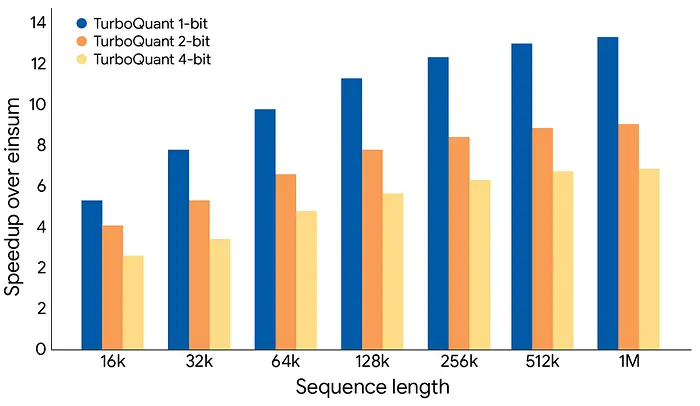
- 在 H100 GPU 上,注意力计算速度比标准 32 位模型快达 8 倍
**这意味着什么:**它不仅更小,而且更快。
向量搜索(这个让我惊讶)
对于最近邻搜索:
- 乘积量化:秒到分钟
- RabitQ:甚至更慢
- TurboQuant:约 0.001 秒
这基本上是即时的。
尽管如此:
- 它仍然实现了比这两种方法更好的召回精度
**这意味着什么:**无需训练,无需索引,无开销。即插即用。
8、"数据无关"意味着什么以及为什么它很重要
大多数量化方法是数据相关的。它们分析你的数据样本,学习分布,并构建针对该分布优化的自定义码本。
乘积量化通过 k-means 聚类做到这一点。更先进的方法(GPTQ、AWQ)使用二阶 Hessian 信息。
这就是为什么它们需要几秒或几分钟来构建索引。这也意味着当数据分布变化时它们会失效。
TurboQuant 是数据无关的。它对任何输入应用相同的随机旋转,然后基于旋转向量的数学属性使用预计算的量化质心。无需学习。无需校准数据。无需数据集特定的调优。
这使得 TurboQuant 适用于:
- KV 缓存量化,token 实时到达,没有机会预先分析数据
- 实时向量搜索系统,新向量持续添加
- 任何数据分布变化的生产系统 ,数据相关量化器会静默退化
如果你的系统实时摄取新数据,数据相关量化会强迫你做出尴尬的选择:定期重新索引(昂贵)或接受质量随数据漂移而退化。TurboQuant 完全避免了这一点。
9、为什么这比看起来更重要
过去几年 AI 的大部分进步都集中在使模型更大上。
但更大的模型有代价:更多内存、更高延迟和更高的基础设施要求。
TurboQuant 表明,我们可能一直在优化错误的东西。
不是无休止地扩展模型,我们可以使现有系统的效率大幅提高。
KV 缓存大小减少 6 倍不仅仅是一个小改进。它直接转化为:
- 在相同硬件上更长的上下文窗口
- 更低的服务成本
- 更快的推理
在许多生产系统中,这比模型精度的小幅提升更重要。
10、这在哪些地方真正有用
这不仅仅是一个学术结果。这些是 TurboQuant 直接适用的具体生产场景。
长上下文 LLM 推理
在长文档(法律合同、研究论文、代码库)上运行 Llama-3.1 或 Gemini 等模型是昂贵的,因为 KV 缓存随上下文长度增长。TurboQuant 在不损失精度的情况下将缓存压缩 4.5 到 6 倍。相同的硬件现在可以以相同的成本处理大约 4 到 6 倍长的上下文。
向量数据库(RAG 系统)
如果你使用 Pinecone、Weaviate、Qdrant 或 pgvector 运行检索增强生成系统,这些数据库存储嵌入向量。使用 TurboQuant 压缩它们意味着:
- 更小的索引存储
- 更快的相似性查找
- 添加新文档时接近零的索引时间
- 数据变化时无需重新训练量化器
边缘和设备上部署
较小硬件(手机、笔记本电脑、嵌入式系统)上的较小模型有严格的内存预算。KV 缓存压缩是模型是否能适应设备内存的区别。TurboQuant 为你提供 4 到 6 倍压缩且无精度权衡,这直接扩展了可部署的内容。
大规模语义搜索
Google 的博客文章明确提到这是一个主要用例。构建和查询数十亿嵌入的向量索引需要最小的内存和快速查找。TurboQuant 接近零的索引时间和卓越的召回率使其成为这方面的一个引人注目的选择。
11、TurboQuant 不能做什么
对当前范围的诚实评估,仅基于论文实际声称和测试的内容。
权重量化是不同的。 TurboQuant 专门为激活(KV 缓存值)和向量搜索索引设计,而不是为模型权重。它不是 GPTQ 或 AWQ 等权重量化方法的直接替代品。
在特定模型上测试。 KV 缓存实验使用了 Llama-3.1-8B-Instruct 和 Ministral-7B-Instruct。结果可能在显著不同的架构上有所不同,尽管该算法在理论上是模型无关的。
尚未作为独立的生产库开源。 论文可在 arXiv (arXiv:2504.19874) 上获得,并在 ICLR 2026 上发表。Google Research 有实现,但截至论文发表时,还没有即插即用的 PyPI 包。算法描述得足够好,研究团队从论文实现是可行的。
2.5 位情况权衡精度以换取压缩。 在 2.5 位有效精度(32 个异常通道在 3 位,96 个通道在 2 位)时,LongBench 分数从 50.06 下降到 49.44。这是 1.2% 的下降。这是否可接受取决于你的用例。
12、心智模型
传统量化将数字存储在小块中,需要额外的开销位来记住每个块的规模。这些开销位侵蚀了压缩的好处。
TurboQuant 避免了这个问题,通过将向量旋转到一个规模已经从数据结构中已知的几何中,而不是从每个块的常数中。残余校正的一位处理这引入的偏差。
结果: 具有可证明保证的接近最优压缩,无需训练,预处理时间接近零。
| 功能 | 结果 | |------|------| | KV 缓存压缩 | 4.5 到 6 倍,无精度损失 | | 长上下文大海捞针 | 匹配全精度(0.997)| | LongBench 通用性能 | 在 3.5 位时匹配全精度 | | 注意力计算速度 | 在 H100 上比 32 位快达 8 倍 | | 向量搜索索引时间 | 约 0.001 秒 vs 37 到 600 秒 | | 需要训练或微调 | 无 |
13、最后的思考
很长一段时间以来,大语言模型中的内存一直被视为一种必要的成本。
如果你想要长上下文,你就得为此付出代价。
TurboQuant 挑战了这一假设。
它表明,通过正确的数学方法,你可以在不影响性能的情况下显著减少内存使用。
这种转变很重要。
因为 AI 进步的下一波可能不会来自更大的模型,而是来自使现有系统更快、更便宜、更高效。
如果这是真的,TurboQuant 不仅仅是一个优化。
它是一个方向。