文章目录
- 前言
- 链路层和局域网
-
- 链路虚拟化:网络作为链路层
- 数据中心网络(简略介绍)
- [回顾: Web 页面请求的历程](#回顾: Web 页面请求的历程)
-
- [准备: DHCP、 UDP、 IP 和以太网](#准备: DHCP、 UDP、 IP 和以太网)
- [仍在准备: DNS 和 ARP](#仍在准备: DNS 和 ARP)
- [仍在准备:域内路由选择到 DNS 服务器](#仍在准备:域内路由选择到 DNS 服务器)
- [Web 客户-服务器交互: TCP 和 HTTP](#Web 客户-服务器交互: TCP 和 HTTP)
- 参考目录
前言
阅读本文前请注意最后编辑时间,文章内容可能与目前最新的技术发展情况相去甚远。欢迎各位评论与私信,指出错误或是进行交流等。
本文是关于《计算机网络:自顶向下方法(第七版)》的学习分享,内容书写顺序也是按照书中的顺序。本文并不会提及书中的所有内容,主要写重点的知识,以及自己感兴趣的内容。会对原文中的内容进行一定的精简,或者加上个人的理解。
链路层和局域网
链路虚拟化:网络作为链路层
在本章开始时,我们将链路视为连接两台通信主机的物理线路。在学习多路访问协议时,我们看到了多台主机能够通过一条共享的线路连接起来,并且连接主机的这种"线路"能够是无线电频谱或其他媒体。 这使我们将该链路更多地抽象为一条信道,而不是作为一条线路。 在我们学习以太局域网时 , 我们看到互联媒体实际上能够是一种相当复杂的交换基础设施。 然而,经过这种演化,主机本身维持着这样的视图,即互联媒体只是连接两台或多台主机的链路层信道。 我们看到,例如一台以太网主机不知道它是通过单一局域网网段还是通过地理上分布的交换局域网或通过 VLAN 与其他局域网主机进行连接。
在两台主机之间由拨号调制解调器连接的场合,连接这两台主机的链路实际上是电话网,这是一个逻辑上分离的、 全球性的电信网络,它有自己的用于数据传输的交换机、 链路和协议栈。 然而,从因特网链路层的观点看,通过电话网的拨号连接被看作一根简单的"线路"。 在这个意义上,因特网虚拟化了电话网,将电话网看成为两台因特网主机之间提供链路层连接的链路层技术。 类似地, 一个覆盖网络将因特网视为为覆盖节点之间提供连接性的一种手段。
在本节中,我们将考虑多协议标签交换 (MPLS) 网络。 与电路交换的电话网不同、MPLS 客观上讲是一种分组交换的虚电路网络。 它们有自己的分组格式和转发行为。从因特网的观点看,我们能够认为 MPLS像电话网和交换以太网一样,作为 为 IP 设备提供互联服务的链路层技术。 因此,我们将在链路层讨论中考虑MPLS。
多协议标签交换 (Multiprotocol Label Switching, MPLS) 自 20 世纪 90 年代中后期在一些产业界的努力下进行演化,以改善IP路由器的转发速度。 它采用来自虚电路网络领域的一个关键概念: 固定长度标签。 其目标是: 对于基于固定长度标签和虚电路的技术,在不放弃基于目的地IP数据报转发的基础设施的前提下, 当可能时 通过选择性地标识数据报并允许路由器基于固定长度的标签(而不是目的地IP地址)转发数据报来增强其功能。重要的是,这些技术与IP协同工作,使用 IP寻址和路由选择。
首先考虑由 MPLS路由器处理的链路层帧格式,以此开始学习 MPLS。下图显示了在MPLS使能的路由器之间传输的一个链路层帧,该帧具有一个小的 MPLS 首部,该首部增加到第二层(如以太网)首部和第三层(即 IP) 首部之间。RFC 3032定义了用于这种链路的MPLS首部的格式。 包括在MPLS首部中的字段是: 标签; 预留的3 比特实验字段; 1 比特S字段, 用于指示一系列"成栈"的MPLS首部的结束 (我们这里不讨论这个高级主题);寿命字段。

从图中立即能够看出,一个 MPLS加强的帧仅能在两个均为 MPLS使能的路由器之间发送。 (因为一个非MPLS 使能的路由器,当它在期望发现IP首部的地方发现了一个MPLS首部时会相当混淆!)一个 MPLS使能的路由器常被称为标签交换路由器 (labels switched router) , 因为它通过在其转发表中查找 MPLS标签,然后立即将数据报传递给适当的输出接口来转发MPLS帧。 因此, MPLS使能的路由器不需要提取目的 IP地址和在转发表中执行最长前缀匹配的查找。 但是路由器怎样才能知道它的邻居是否的确是MPLS使能的呢? 路由器如何知道哪个标签与给定IP 目的地相联系呢?为了回答这些问题,我们需要看看一组MPLS使能路由器之间的交互过程。
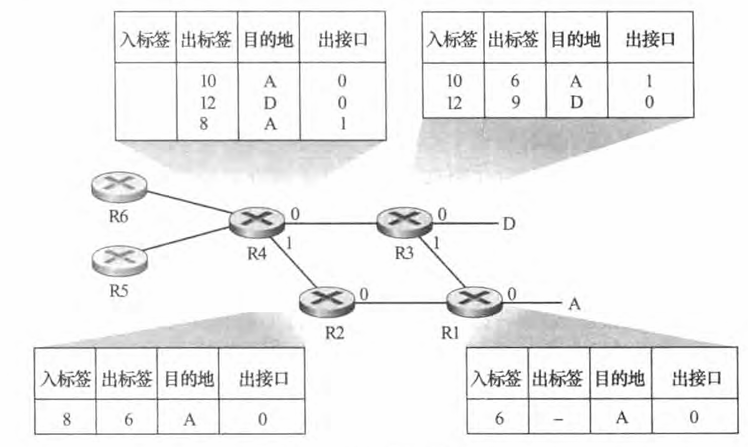
在下图所示的例子中,路由器R1 到 R4 都是MPLS使能的, R5 和 R6 是标准的 IP路由器。 R1 向 R2 和 R3 通告了它 (R1) 能够路由到目的地A, 并且具有 MPLS标签6 的接收帧将要转发到目的地A。 路由器R3 已经向路由器R4通告了它能够路由到目的地A和D 、分别具有 MPLS标签 10 和 12 的入帧将朝着这些目的地交换。 路由器 R2也向路由器R4 通告了它 (R2) 能够到达目的地A, 具有 MPLS标签8 的接收帧将朝着A交换。 注意到路由器R4 现在处于一个到达A且有两个 MPLS路径的令人感兴趣的位置上,经接口 0具有出 MPLS 标签10, 经接口 1 具有出MPLS标签8。 外围部分IP设备 R5、 R6、 A 和 D, 它们经过一个 MPLS 基础设施 (MPLS 使能路由器 R1、 R2、 R3 和R4) 连接在一起,这与一个交换局域网能够将IP设备连接到一起的方式十分相似。 MPLS使能路由器R1 到 R4完成这些工作时从没有接触分组的 IP 首部。
在我们上面的讨论中,我们并没有指定在 MPLS使能路由器之间分布标签的特定协议,因为该协议的细节已经超出了本书的范围。我们也不讨论MPLS实际上是如何计算在 MPLS使能路由器之间分组的路径的,也不讨论它如何收集链路状态信息(例如,未由 MPLS预留的链
路带宽量)以用于这些路径计算中。 现有的链路状态路由选择算法(例如OSPF) 已经扩展为向 MPLS 使能路由器"洪泛"。 令人感兴趣的是,实际路径计算算法没有标准化,它们当前是厂商特定的算法。
至今为止,我们关于MPLS的讨论重点基于这样的事实, MPLS 基于标签执行交换而不必考虑分组的IP地址。 然而, MPLS 的真正优点和当前对MPLS感兴趣的原因并不在于交换速度的潜在增加,而在于MPLS使能的新的流量管理能力。 如前面所述, R4到 A具有两条MPLS路径。 如果转发基于IP地址执行,IP路由选择协议将只指定到A的单一最小费用的路径。 所以, MPLS提供了沿着多条路由转发分组的能力,使用标准IP路由选择协议这些路由将是不可能的。 这是使用MPLS 的一种简单形式的流量工程 (traffic engineering), 其中网络运行者能够超越普通的IP路由选择,迫使某些流量沿着一条路径朝着某给定的目的地引导,并且朝着相同目的地的其他流量沿着另一条路径流动(无论是由于策略、性能或某些其他原因)
将MPLS 用于其他目的也是可能的。 能用于执行 MPLS 转发路径的快速恢复,例如.经过一条预计算的无故障路径重路由流量来对链路故障做出反应 。 最后,我们注意到 MPLS 能够并且已经被用于实现所谓虚拟专用网 (Virtual Private Nehvork, VPN ) 。 在为用户实现一个 VPNR 的过程中, ISP 使川它的 MPLS 使能网络将用户的各种网络连接在一起。 MPLS能被用于将资源和由用户的 VPN 使用的寻址方式相
隔离,其他用户利用该VPN跨越该ISP 网络。
这里有关MPLS 的讨论是简要的,我们鼓励读者查阅文献 我们注意到对MPLS有许多可能的用途, 看起来它将迅速成为因特网流量工程的瑞士军刀!
数据中心网络(简略介绍)
近年来,因特网公司如谷歌、微软、脸书 (Facebook) 和亚马逊(以及它们在亚洲和欧洲的同行)已经构建了大量的数据中心。每个数据中心都容纳了数万至数十万台主机,并且同时支持着很多不同的云应用(例如搜索、电子邮件、社交网络和电子商务)。 每个数据中心都有自己的数据中心网络 (data center network) , 这些数据中心网络将其内部主机彼此互联并与因特网中的数据中心互联。在本节中,我们简要介绍用于云应用的数据中心网络。
大型数据中心的投资巨大, 一个有100000 台主机的数据中心每个月的费用超过 1200万美元。在该费用中,用于主机自身的开销占45% (每3 ~4 年需要更新一次) ; 变压器、不间断电源系统、长时间断电时使用的发电机以及冷却系统等基础设施的开销占25% ; 用于功耗的电力设施的开销占 15% ; 用于联网的开销占 15% , 这包括了网络设备(交换机、路由器和负载均衡设备)、外部链路以及传输流量的开销、 (在这些比例中,设备费用是分期偿还的,因此费用通常是由一次性购买和持续开销(如能耗)构成的。)尽管联网不是最大的费用,但是网络创新是减少整体成本和性能最大化的关键 。
主机就像是数据中心的工蜂: 它们负责提供内容(例如,网页和视频)、存储邮件和文档,并共同执行大规模分布式计算(例如,为搜索引擎提供分布式索引计算)。数据中心中的主机称为刀片 (blade) , 与比萨饼盒类似, 一般是包括CPU、 内存和磁盘存储的商用主机。 主机被堆叠在机架上,每个机架一般堆放20 ~40 台刀片~ 在每一个机架顶部有一台交换机,这台交换机被形象地称为机架顶部 (Top of Rack, TOR) 交换机,它们与机架上的主机互联,并与数据中心中的其他交换机互联。 具体来说,机架上的每台主机都有一块与TOR 交换机连接的卡,每台TOR交换机有额外的端口能够与其他TOR交换机连接。 目前主机通常用40Gbps 的以太网连接到它们的TOR 交换机。每台主机也会分配一个自己的数据中心内部的IP地址。
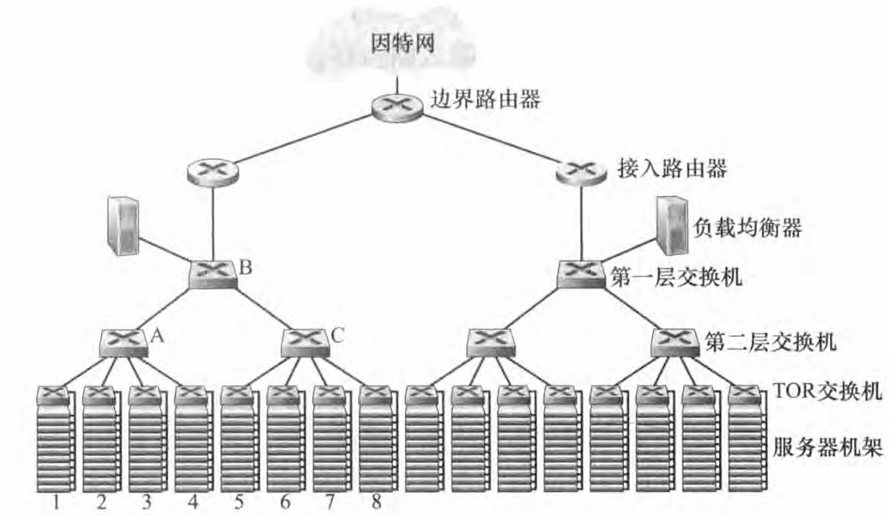
数据中心网络支持两种类型的流量: 在外部客户与内部主机之间流动的流量,以及内部主机之间流动的流量。 为了处理外部客户与内部主机之间流动的流量,数据中心网络包括了一台或者多台边界路由器 (border router) , 它们将数据中心网络与公共因特网相连。数据中心网络因此需要将所有机架彼此互联,并将机架与边界路巾器连接,如图显示了一个数据中心网络的例子。 数据中心网络设计 (data center network design) 是互联网络和协议设计的艺术,该艺术专注于机架彼此连接和与边界路由器相连。
- 负载均衡
一个云数据中心,如一个谷歌或者微软的数据中心,能够同时提供诸如搜索、电子邮件和视频应用等许多应用。 为了支持来自外部客户的请求,每一个应用都与一个公开可见的 IP 地址关联,外部用户向该地址发送其请求并从该地址接收响应。 在数据中心内部,外部请求首先被定向到一个负载均衡器 (load balancer) 。 负载均衡器的任务是向主机分发请求,以主机当前的负载作为函数来在主机之间均衡负载。 一个大型的数据中心通常会有几台负载均衡器,每台服务于一组特定的云应用。 由于负载均衡器基于分组的目的端口号(第四层)以及目的IP地址做决策,因此它们常被称为"第四层交换机"。 一旦接收到一个对于特定应用程序的请求,负载均衡器将该请求分发到处理该应用的某一台主机上(该主机可能再调用其他主机的服务来协助处理该请求)。 当主机处理完该请求后,向负载均衡器回送响应,再由负载均衡器将其中继发回给外部客户。 负载均衡器不仅平衡主机间的工作负载,而且还提供类似NAT的功能,将外部IP地址转换为内部适当主机的 IP地址,然后再将流向客户的分组按照相反的转换进行处理。 这防止客户直接接触主机,从而具有隐藏网络内部结构和防止客户直接与主机交互等安全性益处。 - 等级体系结构
对于仅有数千台主机的小型数据中心, 一个简单的网络也许就足够了。 这种简单网络由一台边界路由器、 一台负载均衡器和几十个机架组成,这些机架由单一以太网交换机进行互联。 但是当主机规模扩展到几万至几十万的时候,数据中心通常应用路由器和交换机等级结构 , 上图显示了这样的拓扑。 在该等级结构的顶端,边界路由器与接入路由器相连(在图中仅仅显示了两台,但是能够有更多)。 在每台接入路由器下面,有3 层交换机。 每台接入路由器与一台第一层交换机相连,每台第一层交换机与多台第二层交换机以及一台负载均衡器相连。 每台第二层交换机又通过机架的 TOR 交换机(第三层交换机)与多个机架相连。 所有链路通常使用以太网作为链路层和物理层协议,并混合使用铜缆和光缆。 通过这种等级式设计,可以将数据中心扩展到几十万台主机的规模。 - 数据中心网络的发展趋势
为了降低数据中心的费用,同时提高其在时延和吞吐量上的性能,因特网云服务巨头都在不断地部署新的数据中心网络设计方案。 尽管这些设计方案都是专有的,但是许多重要的趋势是一样的。其中的一个趋势是部署能够克服传统等级设计缺陷的新型互联体系结构和网络协议
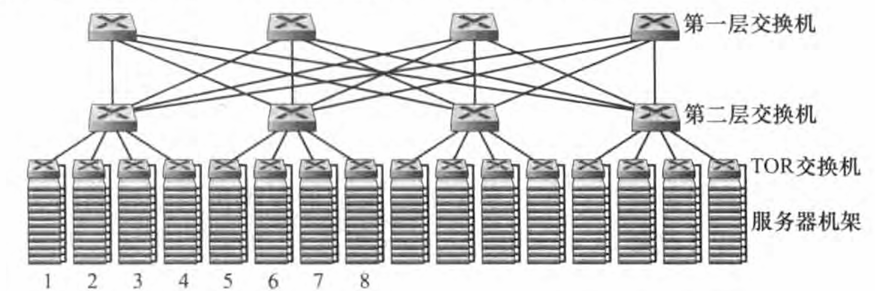
一种方法是采用全连接拓扑 (fully connected topology) 来替代交换机和路由器的等级结构, 下图中显示了这种拓扑。 在这种设计中,每台第一层交换机都与所有第二层交换机相连,因此: 1.主机到主机的流量绝不会超过该交换机层次;2.对于n台第一层交换机,在任意两台二层交换机间有几n条不相交的路径。 这种设计可以显著地改善主机到主机的容量。
另外一个主要的趋势就是采用基于船运集装箱的模块化数据中心 (Modular Data Center, MDC )。 在一个 MDC 中,在一个标准的 12 米船运集装箱内, 工厂构建一个"迷你数据中心"并将该集装箱运送到数据中心的位置。 每一个集装箱都有多达数千台主机,堆放在数十台机架上,并且紧密地排列在一起。 在数据中心位置,多个集装箱彼此互联,同时也和因特网连接。 一旦预制的集装箱部署在数据中心,通常难以检修。 因此,当组件(服务器和交换机)随着时间的推移出现故障时,集装箱继续运行但是性能下降。 当许多组件出现故障并且性能已经下降到低于某个阈值时,整个集装箱将会被移除,并用新的来替换。
另一种重要趋势是,大型云提供商正在其数据中心越来越多地建造或定制几乎所有东西, 包括网络适配器、交换机路由器、 TOR、软件和网络协议。 由亚马逊开创的另一个趋势是,用"可用性区域"来改善可靠性,这种技术在不同的邻近建筑物中基本上复制不同的数据中心。 通过让建筑物邻近(几千米远),互相交互的数据能够跨越位于相同可用性区域的数据中心进行同步,与此同时提供容错性。
回顾: Web 页面请求的历程
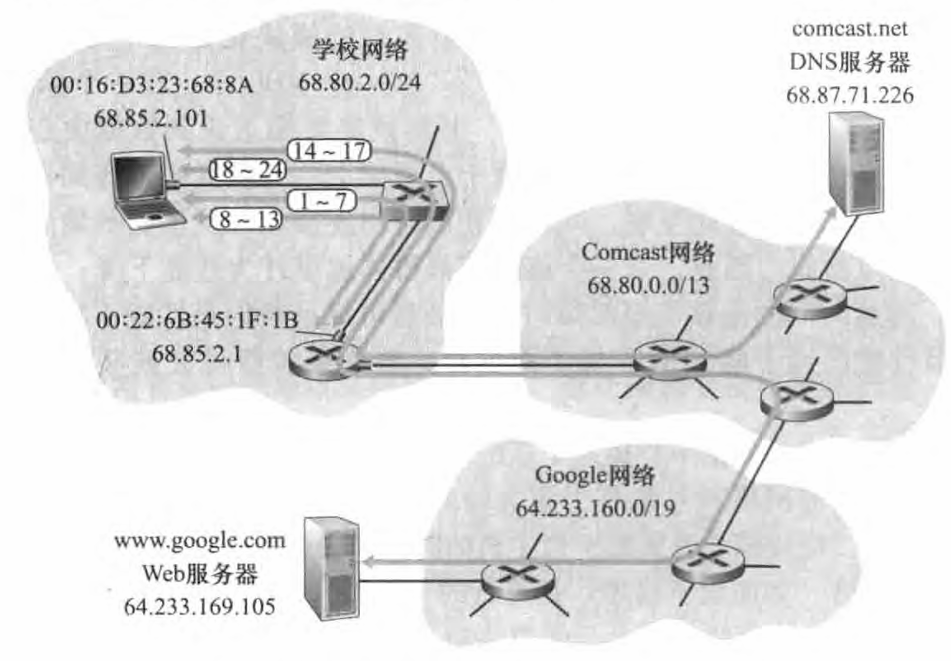
既然我们已经在本章中学过了链路层,并且在前面几章中学过了网络层、运输层和应用层,那么我们沿协议栈向下的旅程就完成了!在本书的一开始 ,我们说过"本书的大部分内容与计算机网络协议有关",在本章中,我们无疑已经看到了情况的确如此!通过对已经学过的协议做一个综合的、全面的展望,我们希望总结一下沿协议栈向下的旅程。 而做这个"全面的"展望的一种方法是识别许多协议,这些协议涉及满足 甚至最简单的请求: 下载一个Web页面。图示了我们的场景: 一名学生 Bob将他的便携机与学校的以太网交换机相连,下载一个Web页面(比如说www.google. com 主页)。 如我们所知,为满足这个看起来简单的请求,背后隐藏了许多细节
准备: DHCP、 UDP、 IP 和以太网
我们假定Bob 启动他的便携机,然后将其用一根以太网电缆连接到学校的以太网交换机, 交换机又与学校的路由器相连,如图所示。 学校的这台路由器与一个ISP连接,本例中 ISP 为 comcast.net。 且comcast.net 为学校提供了 DNS 服务;所以, DNS服务器驻留在Comcast 网络中而不是学校网络中。 我们将假设 DHCP服务器运行在路由器中,就像常见情况那样。当 Bob 首先将其便携机与网络连接时,没有 IP地址他就不能做任何事情(例如下载一个Web 网页)。 所以, Bob 的便携机所采取的一个网络相关的动作是运行 DHCP协议、以从本地DHCP服务器获得一个IP地址以及其他信息。
- Bob 便携机上的操作系统生成一个 DHCP请求报文,并将这个报文放入具有目的端口67 (DHCP服务器)和源端口68 (DHCP客户)的 UDP报文段,该 UDP 报文段则被放置在一个具有广播 lP 目的地址 (255.255. 255. 255) 和源 IP 地址0.0.0.0 的 IP 数据报中,因为 Bob 的便携机还没有一个 IP 地址。
- 包含 DHCP请求报文的 IP 数据报则被链路层协议放置在以太网帧中。 该以太网帧具有目的MAC 地址FF: FF: FF: FF: FF: FF, 使该帧将广播到与交换机连接的所有设备(如果顺利的话也包括 DHCP 服务器);该帧的源 MAC 地址是 Bob 便携机的 MAC 地址00: 16: D3: 23: 68: 8 A。
- 包含 DHCP请求的广播以太网帧是第一个由 Bob便携机发送到以太网交换机的帧。该交换机在所有的出端口广播入帧,包括连接到路由器的端口。
- 路由器在它的具有 MAC地址00:22:6B:45: 1F 的接口接收到该广播以太网帧,该帧中包含 DHCP请求、并且从该以太网帧中抽取出 IP数据报。 该数据报的广播 IP 目的地址指示了这个IP 数据报应当由在该节点的高层协议处理,因此该数据报的载荷(一个UDP 报文段)被分解 向上到达 UDP, DHCP请求报文从此 UDP 报文段中抽取出来。 此时DHCP服务器有了 DHCP请求报文
5 ) 我们假设运行在路由器中的DHCP服务器能够以CIDR块68.85.2.0/24 分配IP 地址。所以本例中,在学校内使用的所有 IP地址都在Comcast 的地址块中。 我们假设DHCP 服务器分配地址68. 85. 2. 101 给 Bob 的便携机。 DHCP 服务器生成包含这个IP 地址以及 DNS 服务器的 IP 地址 (68.87. 71. 226) 、默认网关路由器的 IP 地址( 68. 85. 2. 1) 和子网块 (68. 85. 2. 0/ 24) (等价为 "网络掩码) 的一个 DHCP ACK 报文。 该 DHCP 报文被放入一个 UDP 报文段中, UDP 报文段被放人一个 IP 数据报中, IP 数据报再被放入一个以太网帧中。 这个以太网帧的源 MAC 地址是路由器连到归属网络时接口的 MAC地址 (00:22: 6B: 45 : 1F: 1B) , 目的 MAC 地址是 Bob 便携机的 MAC 地
址 (00: 16: D3 : 23 : 68 : 8A) - 包含 DHCP ACK 的以太网帧由路由器发送给交换机。 因为交换机是自学习的 、 并且先前从 Bob 便携机收到(包含 DHCP请求的)以太网帧,所以该交换机知道寻址到00: 16: 03: 23: 68: 8A 的帧仅从通向 Bob 便携机的输出端口转发。
- Bob 便携机接收到包含 DHCP ACK 的以太网帧,从该以太网帧中抽取 IP数据报,从IP 数据报中抽取 UDP报文段,从 UDP报文段抽取DHCP ACK报文。 Bob 的 DHCP客户端则记录下它的IP地址和它的 DNS 服务器的 IP地址。 它还在其 IP转发表中安装默认网关的地址。Bob 便携机将向该默认网关发送目的地址为其子网68.85.2.0/24 以外的所有数据报。 此时, Bob便携机已经初始化好它的网络组件,并准备开始处理Web 网页获取。
仍在准备: DNS 和 ARP
当 Bob 将 www. google. com 的 URL 键入其 Web 浏览器时,他开启了一长串事件,这将导致谷歌主页最终显示在其Web浏览器上。 Bob 的 Web浏览器通过生成一个TCP套接字开始了该过程, 套接字用于向www. google. com 发送 HTTP 请求。 为了生成该套接字, Bob便携机将需要知道www. google. com 的 IP 地址。 使用 DNS协议提供这种名字到 IP地址的转换服务。
-
Bob 便携机上的操作系统因此生成一个 DNS 查询报文,将字符串www. google. com 放入 DNS 报文的问题段中。 该 DNS 报文则放置在一个具有53 号 (DNS 服务器)目的端口的UDP报文段中。 该UDP报文段则被放入具有IP 目的地址68.87. 71. 226 (在第5 步中DHCP ACK返回的 DNS服务器地址)和源IP地址68.85.2. 101 的 IP 数据报中。
-
Bob 便携机则将包含 DNS 请求报文的数据报放入一个以太网帧中。该帧将发送(在链路层寻址)到 Bob学校网络中的网关路由器。 然而,即使 Bob便携机经过上述第5步中的DHCP ACK 报文知道了学校网关路由器的 IP 地址 (68.85. 2. 1) , 但仍不知道该网关路由器的MAC 地址。 为了获得该网关路由器的 MAC地址, Bob便携机将需要使用 ARP协议。
-
Bob 便携机生成一个具有目的 lP地址68. 85. 2. 1 (默认网关)的 ARP 查询报文,将该ARP报文放置在一个具有广播目的地址 (FF: FF: FF:FF: FF:FF) 的以太网帧中,并向交换机发送该以太网帧,交换机将该帧交付给所有连接的设备,包括网关路由器。
-
网关路由器在通往学校网络的接口上接收到包含该 ARP查询报文的帧,发现在ARP 报文中目标IP地址68. 85.2. 1 匹配其接口的 IP 地址。 网关路由器因此准备一个ARP回答, 指示它的 MAC地址00:22: 6B: 45 : 1F: 1B 对应 IP 地址 68. 85. 2. 1。 它将 ARP 回答放在一个以太网帧中, 其目的地址为00: 16: D3: 23: 68: 8A (Bob 便携机) , 并向交换机发送该帧,再由交换机将帧交付给Bob便携机。
-
Bob 便携机接收包含 ARP 回答报文的帧,并从 ARP 回答报文中抽取网关路由器的 MAC 地址 (00:22: 6B: 45: 1F: 1B)
13 ) Bob 便携机现在(最终!)能够使包含 DNS查询的以太网帧寻址到网关路由器的MAC 地址。 注意到在该帧中的 IP数据报具有 IP 目的地址68.87. 71. 226 (DNS 服务器) ,而该帧具有目的地址00:22:68:45: 1F: 1B (网关路由器) 。 Bob 便携机向交换机发送该帧,交换机将该帧交付给网关路由器。
仍在准备:域内路由选择到 DNS 服务器
14 ) 网关路由器接收该帧并抽取包含DNS查询的 IP数据报。 路由器查找该数据报的目的地址 (68. 87. 71. 226) , 并根据其转发表决定该数据报应当发送到Comcast网络中最左边的路由器。IP数据报放置在链路层帧中,该链路适合将学校路由器连接到最左边Comcast 路由器,并且该帧经这条链路发送。
15 ) 在 Comcast 网络中最左边的路由器接收到该帧, 抽取IP数据报, 检查该数据报的目的地址 (68. 87. 71. 226) , 并根据其转发表确定出接口,经过该接口朝着 DNS 服务器转发数据报,而转发表己根据Comcast 的域内协议(如 RIP、 OSPF 或IS-IS)以及因特网的域间协议BGP 所填写。
16 ) 最终包含 DNS 查询的lP 数据报到达了 DNS 服务器。 DNS 服务器抽取出 DNS 查询报文,在它的 DNS 数据库中查找名字 www.google. com,找到包含对应www.google. com 的 IP 地址 (64. 233. 169. 105 ) 的 DNS 源记录。(假设它当前缓存在 DNS服务器中。)前面讲过这种缓存数据源于google. com 的权威 DNS 服务器。 该DNS 服务器形成了一个包含这种主机名到IP地址映射的DNS 回答报文,将该DNS 回答报文放入UDP报文段中,该报文段放入寻址到 Bob便携机 (68. 85. 2. 101 ) 的 IP数据报中。该数据报将通过Comcast 网络反向转发到学校的路由器, 并从这里经过以太网交换机到Bob 便携机。
17 ) Bob 便携机从 DNS 报文抽取出服务器www. google. com 的 IP 地址。 最终,在大量工作后, Bob便携机此时准备接触www. google. com 服务器!
Web 客户-服务器交互: TCP 和 HTTP
18 ) 既然 Bob 便携机有了 www. google. com 的 IP 地址, 它能够生成 TCP 套接字,该套接字将用于向www.google. com 发送 HTTP GET 报文。 当 Bob 生成TCP 套接字时,在Bob便携机中的TCP必须首先与www.google. com 中的 TCP 执行三次握手 。 Bob 便携机因此首先生成一个具有目的端口 80 (针对 HTTP 的)的TCP SYN 报文段, 将该TCP报文段放置在具有目的IP地址64.233. 169. 105 (www. google. com) 的 IP数据报中, 将该数据报放置在MAC 地址为00:22:68:45: 1F: 1B ( 网关路由器)的帧中,并向交换机发送该帧。
19 ) 在学校网络、 Comcast 网络和谷歌网络中的路由器朝着 www. google. com 转发包含TCP SYN 的数据报,使用每台路由器中的转发表,如前面步骤 14 ~ 16 那样。 前面讲过支配分组经Comcast 和谷歌网络之间域间链路转发的路由器转发表项,是由 BGP 协议决定
的
- 最终,包含TCP SYN 的数据报到达www. googole. com 。 从数据报抽取出 TCP SYN 报文并分解到与端口 80相联系的欢迎套接字。 对于谷歌HTTP服务器和 Bob便携机之间的 TCP 连接生成一个连接套接字。 产生一个TCP SYNACK报文段,将其放入向 Bob 便携机寻址的一个数据报中,最后放入链路层帧中, 该链路适合将www. google. com 连接到其第一跳路由器。
21 ) 包含 TCP SYNACK 报文段的数据报通过谷歌、 Comcast 和学校网络,最终到达Bob 便携机的以太网卡, 数据报在操作系统中分解到步骤 18 生成的 TCP套接字,从而进入连接状态。
22 ) 借助于 Bob 便携机上的套接字,现在(终于!)准备向 www. google. com 发送字节了 , Bob 的浏览器生成包含要获取的URL 的 HTTP GET报文 。 HTTP GET报文则写入套接字,其中GET报文成为一个TCP报文段的载荷。 该TCP报文段放置进一个数据报中, 并交付到www. google. C'om, 如前面步骤 18-20 所述。
-
在 www. google. com 的 HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将请求的Web 页内容放入HTTP响应体中,并将报文发送进TCP套接字中。
-
包含 HTTP 回答报文的数据报通过谷歌、 Comcast 和学校网络转发,到达 Bob便携机。 Bob 的 Web 浏览器程序从套接字读取HTTP响应,从HTTP响应体中抽取Web 网页的 html, 并最终(终于!)显示了 Web 网页。
参考目录
书籍:《计算机网络:自顶向下方法(第七版)》