1. loss
两种方式:
1. 按batch等权平均:
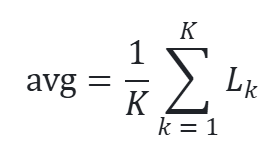
python
for batch_idx, (inputs, target_masks) in enumerate(progress_bar):
outputs = lora_model(**inputs)
loss, loss_focal, loss_dice = process_outputs(outputs, target_masks) # 此时得到的loss是一个batch内的平均loss
...
epoch_loss += loss.item()
avg_train_loss = epoch_loss / len(train_dataloader)特点 :每个batch权重相同。 ----> 1. 如果data_loader的最后一个batch不满,那么这个batch对loss做出的贡献和其他满batch对loss做出的贡献是相同的。 2. 某些batch里有效像素/正样本特别少(比如很多 GT=0),但它仍占同等权重。
对第一个问题举个例子:
假设 batch_size=4,但最后一个 batch 只有 1 张:
- Batch1(4张图)loss=0.10
- Batch2(1张图)loss=1.00
loss=(0.10+1.00)/2=0.55
让只有1张图的 batch占了50%的权重。第二个问题同理。
2. 按样本数加权:
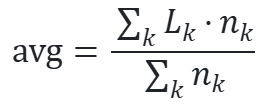
python
sum_loss = 0.0
sum_n = 0
for ...:
n = target_masks.size(0) # batch size
sum_loss += loss.item() * n
sum_n += n
avg = sum_loss / sum_n特点:每张图权重相同(样本级平均)。
按照上面的例子,计算出来的loss如下:
(0.10⋅4+1.00⋅1)/(4+1)=(0.4+1)/5=0.28
什么情况下二者可以认为近似相同:
没有单独更小的batch: drop_last=True 或者 数据量刚好能整除 batch_size。
补充:在第一点提到"某些batch里有效像素/正样本特别少"的问题,要解决这个问题,loss计算需要考虑按有效像素数或正样本数加权(取决于loss归一化的方式),但这属于更高级的对齐问题,如果各个batch内的GT分布不是很极端,可以不考虑这种情况。
2. Dice 和 MIou
1. 关于Miou的说明
- Iou_fg: 只算前景
- mean over classes: 平均iou_fg和iou_bg
- mean over images: 对每张图的iou的平均
2. 两种方法
A 使用混淆矩阵
- Dice = (2TP/(2TP+FP+FN))
- IoU = (TP/(TP+FP+FN))
python
def _confusion_from_binary(pred01: np.ndarray, gt01: np.ndarray):
"""
pred01, gt01: ndarray, values in {0,1}
"""
pred = (pred01 > 0).astype(np.bool_)
gt = (gt01 > 0).astype(np.bool_)
tp = np.logical_and(pred, gt).sum(dtype=np.int64)
fp = np.logical_and(pred, np.logical_not(gt)).sum(dtype=np.int64)
fn = np.logical_and(np.logical_not(pred), gt).sum(dtype=np.int64)
tn = np.logical_and(np.logical_not(pred), np.logical_not(gt)).sum(dtype=np.int64)
return tp, fp, fn, tn
def dice_iou(pred: np.ndarray, gt: np.ndarray, eps: float = 1e-7):
"""
pred, gt: ndarray shape (P, X, Y, Z), values {0,1}
"""
pred=pred[0]
gt=gt[0]
tp, fp, fn, tn = _confusion_from_binary(pred, gt)
dice = (2 * tp + eps) / (2 * tp + fp + fn + eps)
iou = (tp + eps) / (tp + fp + fn + eps)
return float(dice), float(iou)B 用intersection/union推
- intersection = sum(pred * gt)
- union_dice = sum(pred) + sum(gt)
- union_iou = sum(pred) + sum(gt) − intersection
python
def compute_metrics(pred, target, smooth=1e-6):
"""
pred: [B,H,W] logits (NOT sigmoid)
target: [B,H,W] 0/1
empty_policy:(GT empty & Pred empty) => score=1, (GT empty & Pred non-empty) => score=0
"""
prob = torch.sigmoid(pred).detach()
pred_bin = (prob > 0.5).float()
target = target.float()
# flatten per image
pred_f = pred_bin.flatten(1)
tgt_f = target.flatten(1)
inter = (pred_f * tgt_f).sum(1) # [B]
pred_sum = pred_f.sum(1) # [B]
tgt_sum = tgt_f.sum(1) # [B]
union_iou = pred_sum + tgt_sum - inter
union_dice = pred_sum + tgt_sum
iou = (inter + smooth) / (union_iou + smooth)
dice = (2 * inter + smooth) / (union_dice + smooth)
gt_empty = (tgt_sum == 0)
pred_empty = (pred_sum == 0)
# set empty-gt images score based on whether prediction is also empty
iou = torch.where(gt_empty, pred_empty.float(), iou)
dice = torch.where(gt_empty, pred_empty.float(), dice)
return iou.mean().item(), dice.mean().item()这两种在二值预测且同一阈值下是等价的。
3. 对谁求和
A micro
先把所有像素 (跨多张图/多batch)汇总TP/FP/FN,再算 Dice/IoU。适用于更关心整体像素表现(比如器官分割、前景占比相对稳定)的情况。
特点:
- 大目标/大图权重大,小目标权重小
- 数值通常更"乐观",波动更小
- Dice 和 IoU 的对应关系在同一汇总口径下是稳定的
对GT=0多的影响:空图如果预测也空,会贡献大量TN,但TN不进 Dice/IoU;空图对micro的影响相对间接。如果空图预测出 FP,会显著拉低。
B macro over images
每张图 先算一个 Dice/IoU,然后对图做平均。适用于更希望每个病例同等重要的情况。
特点:
- 每张图权重相同,小目标图不再被"淹没"
- 对"哪些图失败了"更敏感
- 通常比 micro 更低、更接近"最差情况"
对GT=0多的影响:如果要把空GT图也纳入平均,必须定义空图得分。
C macro over classes
定义 :分别算背景 IoU、前景 IoU,然后对类别平均。二分类时就是 (IoU_bg + IoU_fg)/2。适用于多分类语义分割,要求类别公平。
特点:
- 强制同时关注背景和前景
- 但对分割来说很多时候"背景 IoU"意义不大
对GT=0多的影响:若某类在某张图里不存在,"是否计入该类 IoU"的策略会影响巨大(同样会出现空集问题)
4. GT=0如何处理
A perfect-empty
空图预测空给满分,空图有FP给0。目标是希望模型"遇到没有目标的图就不要分出东西"。但如果空图占比非常高,指标可能看起来很好。
B ignore-empty
空 GT 的图不计入前景IoU/Dice平均,适用于只想评估"有前景时分割得如何"。并且空图数量很多,担心指标被空图主导
C eps-approx
例如 (tp+eps)/(tp+fp+fn+eps)。当 tp=fp=fn=0 时会得到1,但当GT空且pred有少量FP时,会得到接近0。