文章目录
索引
索引是一种有序的存储结构,按照单个或者多个列的值进行排序,用于提升搜索效率
主键索引
sql
PRIMARY KEY(key1,key2)唯一索引
sql
UNIQUE(key1)普通索引
sql
INDEX(key)
--OR--
KEY(key[,...])组合索引
sql
INDEX idx(key1,key2[,..]);
UNIQUE(key1,key2[,..]);
PRIMARY KEY(key1,key2[,..]);全文索引
Elasticsearch的全文索引最常用,搜索引擎的实现,通过关键字反向索引文章。
主键选择
innoDB中表是索引组织表,每张表中有且仅有一个主键
1.显式设置PRIMARY KEY则该设置的key为主键
2.没有设置,只有一个非空唯一索引,该索引为主键;有多个非空唯一索引,选择声明的第一个
3.没有非空唯一索引,自动生成一个6字节的_rowid作为主键
索引的实现
在InnoDB中,索引对应的是B+树。
PRIMARY KEY → #map 在innoDB是B+树。
KEY → #multimap<int,xx>
索引存储
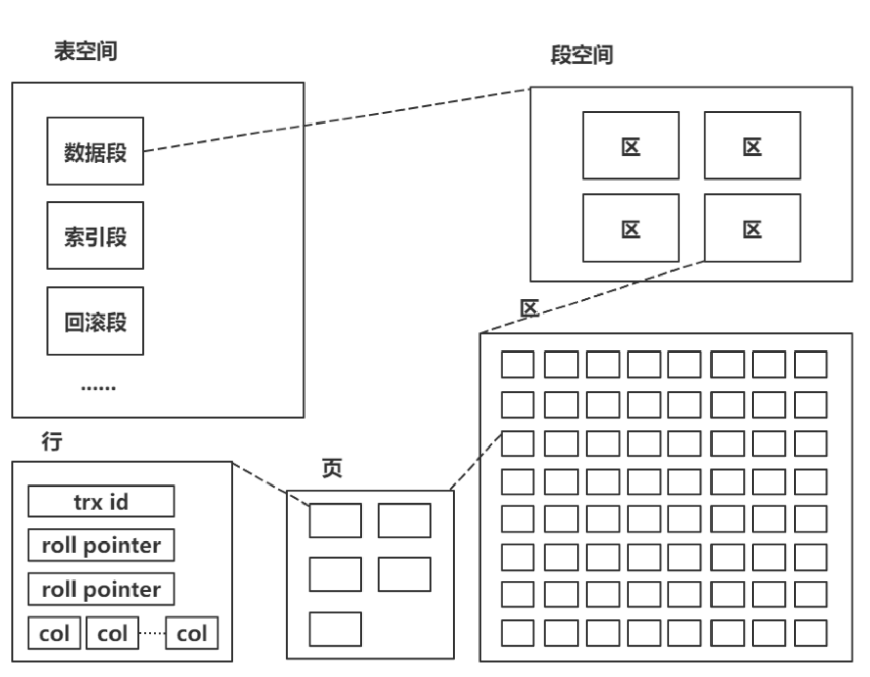
磁盘访问时间:寻道时间 (8-12ms)+旋转时间(7200转/min,即半周4ms)+传输时间(约0.3ms)
访问速度:磁盘随机IO<<磁盘顺序io(省去大部分寻道时间)≈内存随机IO<<内存顺序IO。
约束
为了实现数据的完整性,对于innodb提供了
primary key,unique key,foreign key,default,not null
外键约束
外键用来关联两个表,来保证参照的完整性。
约束和索引的区别
创建主键索引或者唯一索引的时候同时就创建了约束;约束是逻辑上的概念;索引是一个数据结构既包含逻辑概念也包含物理的存储方式
B+树
多路平衡搜索树
其每个节点映射磁盘数据。以页为单位,物理磁盘页一般为4KB,innodb默认页大小为16KB,对页的一次访问就是磁盘IO到内存,大约10ms ,缓存中会缓存经常访问的页。
B+树的特征:
①非叶子节点只存储索引信息
②叶子节点还存储数据信息
③叶子节点之间依次连接
④节点的大小为16KB,映射的是连续的磁盘页。
问题①:为什么采用多路的数据结构而不是红黑树?
相较于平衡二叉搜索树这是一个矮胖的结构,跳转较少的节点就可以找到需要的数据。
问题②:为什么叶子节点只存储索引信息?
在B+树种非叶子节点只有key信息,而叶子节点才有key value信息。非叶子结点的16KB能够容纳更多的索引信息,树的结构更加矮胖,IO次数更少
问题③:为什么叶子节点彼此相连?
便于范围查询,避免中序遍历回溯
总之,索引信息和数据信息分层管理,便于高效地组织磁盘数据,快速实现单点和范围查询。
PRIMARY KEY 和KEY对应两种B+ 树
聚集索引B+树和辅助索引B+树
按照主键构造的B+树;
sql
# table id name id为primary key
select * from user where id >= 18 and id < 40;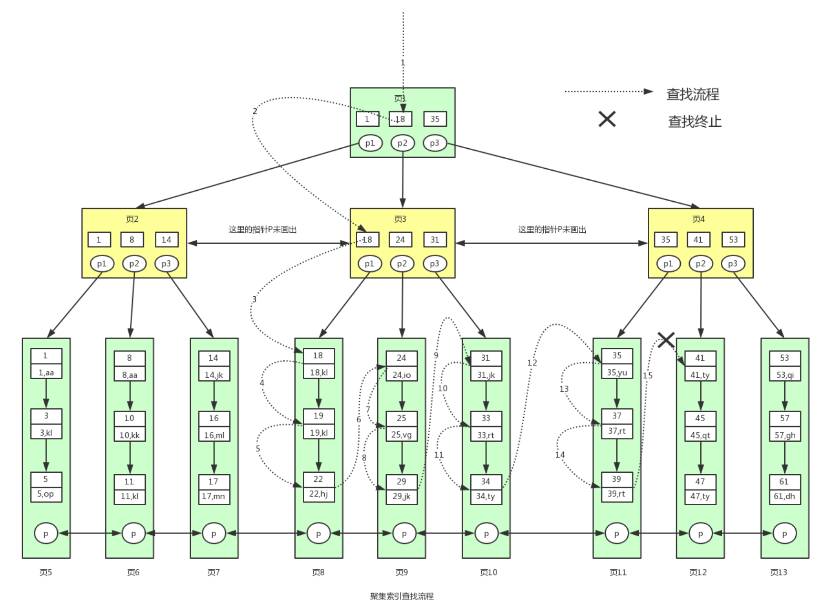
除了主键索引之外的索引就是辅助索引。
辅助索引的叶子节点不包含除了主键信息的所有的行信息,只包含索引的信息
使用辅助索引查到主键值,然后走聚集索引,查到所有行。
sql
--某个表 包含id name lockyNum ; id是主键索引,lockyNum是辅助索引
--KEY()
select * from user where lockNum = 33;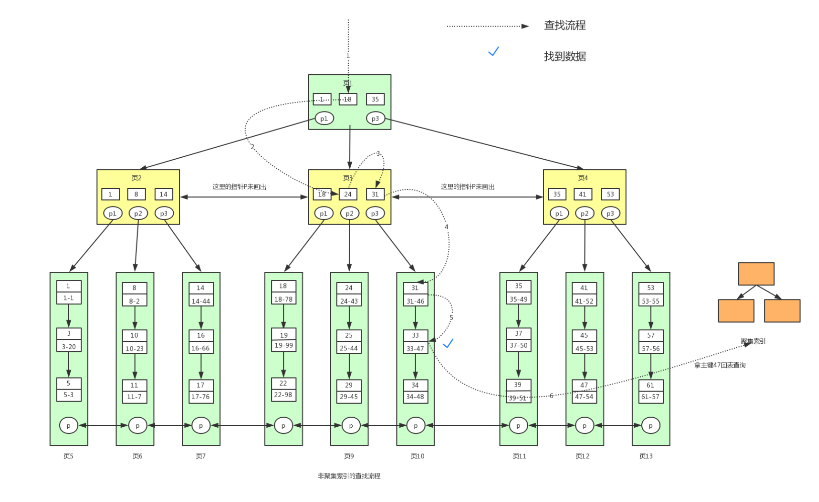
但是实际操作是很快的,好像并没有经过那么多次磁盘io
bufferpool
所有数据库基本上都自定制了缓存策略 ,不走page cache直接direct io刷到file中。
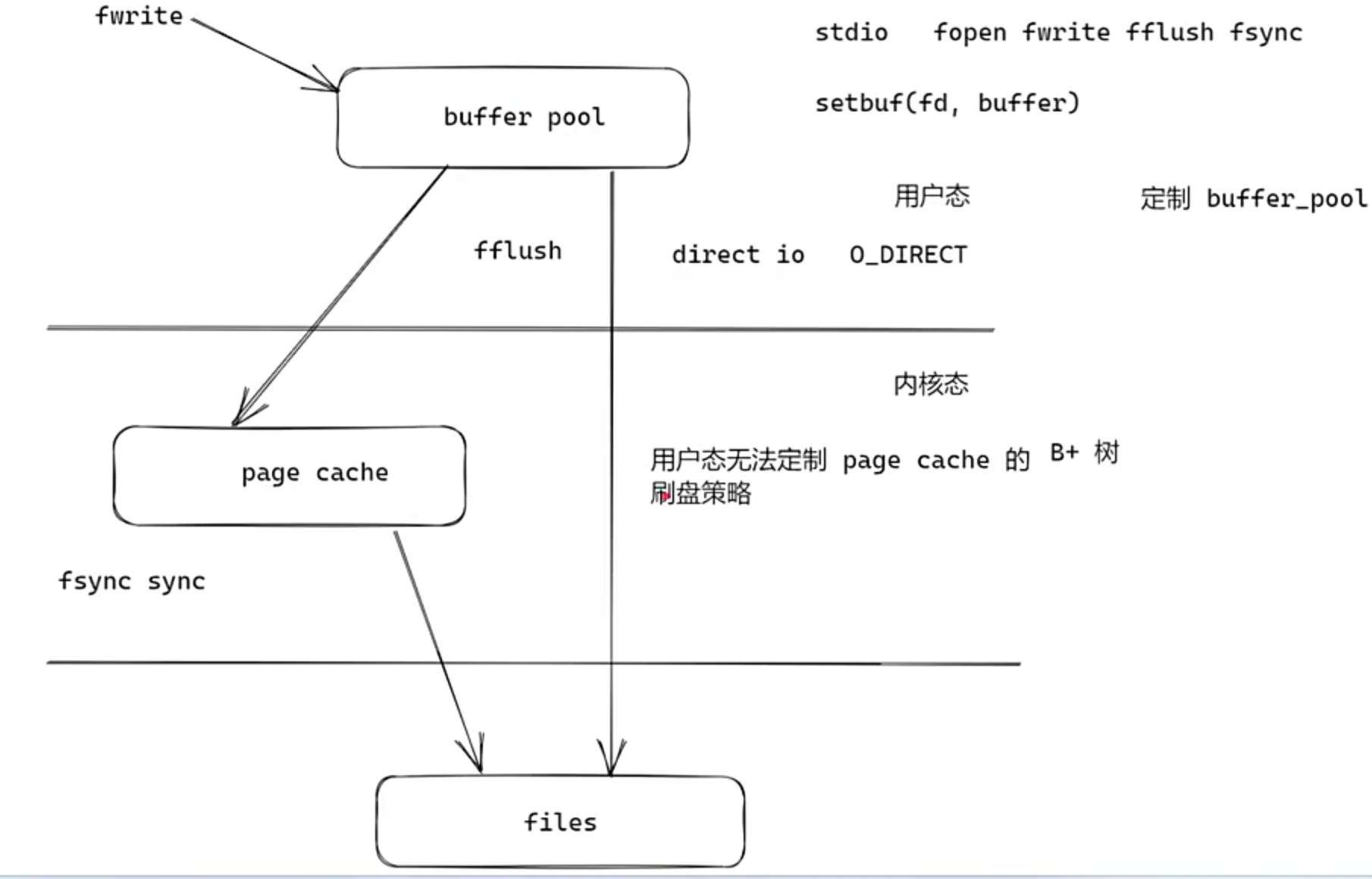
innodb的体系结构
经常访问的磁盘数据会缓存在bufferpool中,采用LRU算法。
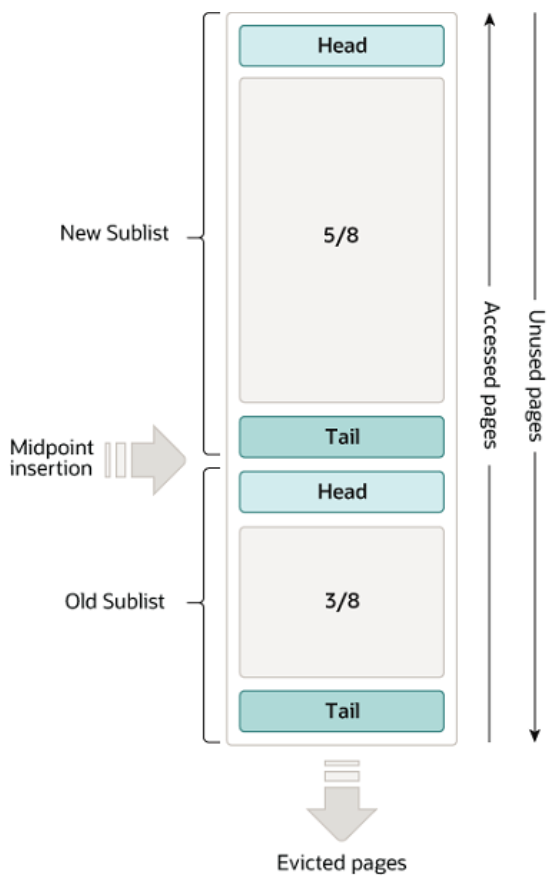
changebuffer用于缓存辅助索引的数据变更,会将其中的数据异步merge到buffer pool当中
redolog确保了缓存中的数据安全,相当于redis的aof。
redolog undolog会用到page cache,B+树中的数据用buffer pool。
最左匹配原则
索引个数最好不超过6个,因为修改一个字段就要维护多个B+树。所以需要组合索引
对于组合索引,从左到右依次匹配,遇到< > between like 就停止匹配。
sql
KEY 'name_and_cid' ('name','cid');
EXPLAN select * from 'user' where 'name' = 'flame'
#看这条语句有没有踩到索引 type : ref 踩到索引了 all全表扫秒
possible_keys : name_and_cid 索引名
sql
KEY 'name_and_cid' ('name','cid');
EXPLAN select * from 'user' where 'cid' = 1;
#看这条语句有没有踩到索引 这条sql语句不会踩索引,where后条件没有匹配到 name ... 但是:
sql
where 'cid' = 1 and 'name' = 'flame'是可以踩到的,优化器会自动调整以上语序。
但是用了不等号<>
sql
where 'cid' = 1 and 'name' <> 'flame'的type不是ref,而是range,稍慢于ref,但是也踩索引(mysql 后续的优化)
遇到<> between like就停止匹配
<>可以改为< 0 or > 0
覆盖索引
要查的数据就是辅助索引的信息,走辅助索引时就不需要回表,type返回值是 use index。
所以说不要动不动select *
索引下推
针对普通索引和联合索引场景。
5.6版本后推出,减少回表次数,减少server层和存储引擎层的交互次数,提升查询效率。
没有索引下推机制前:
server层向存储引擎层请求数据,在server层根据索引条件进行数据过滤
有索引下推机制后,将部分索引条件判断推到存储引擎进行过滤,由存储引擎汇总返回给server
索引失效
①不遵循最左匹配原则;
②索引字段参与运算,作用函数,匹配失效;
③索引字段发生隐式转换(字符串和数字比较,会将字符串转化为数字),索引失效;
④LIKE模糊查询,where name like '%某' 通配符%开头,索引失效
⑤索引字段使用NOT <> !=索引失效,可改为<0 or > 0
索引设置原则
①查询频次高的,且数据量大的列;
②索引字段越短越好
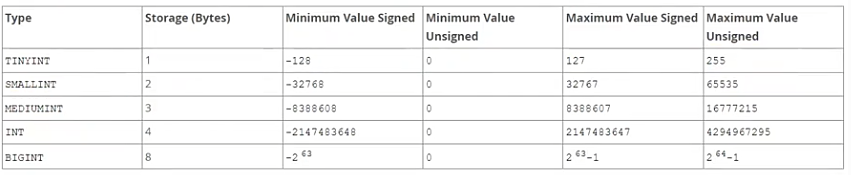
索引字段占用空间越小,节点中容纳的数据就越多,磁盘IO就越少。
③对于很长的动态字符串,考虑使用前缀索引(key(name(4)))
4是怎么呢?算区分度
该列值相同的越少越好
sql
select count(distinct left(name,3))/count(*) as sel3,
count(distinct left(name,4))/count(*) as sel4,
count(distinct left(name,5))/count(*) as sel5,
count(distinct left(name,6))/count(*) as sel6
from user;
alter table user add key(name(4));
-- 注意:前缀索引不能做 order by 和 group by④in 优化为 exist,inner join
⑤尽量扩展索引,使用组合索引;最多6个列参与索引
⑥尽量设置为非空,非空判断会让索引失效
出现了慢sql应该怎么做?
①show processlist
②开启慢查询日志
③分析sql语句,where group by order by是否踩了索引
④分析sql语句,能否把in not in 优化成联合查询
⑤尽量减少联合查询,拆成多个sql语句
⑥不要存储age字段,因为这是会变化的,给数据库带来不必要的开销