目录
[三、代 价 函 数(cost function)](#三、代 价 函 数(cost function))
[一、CNN的三大核心操作:卷积 池化 全连接](#一、CNN的三大核心操作:卷积 池化 全连接)
[三、LSTM 长短时记忆网络 与 GRU门控机制](#三、LSTM 长短时记忆网络 与 GRU门控机制)
[BERT 的核心特点](#BERT 的核心特点)
简答提问(串知识):机器学习是什么?深度学习是什么?两者有什么区别联系?
1、机器学习 是人工智能的子领域,核心是通过算法在数据中发现规律 ,依赖人工提取特征,适合结构化数据。机器学习 有无监督学习 ,监督学习 ,强化学习。
( 其中,无监督学习 是指不给标签,让计算机自己在数据中发现规律,比如聚类K-means,降维PCA主成分分析法、SVD分解;监督学习 是给定标签和数据,预测结果,比如房价预测、判断是否下雨;强化学习是通过智能体与环境交互试错,最大化积累奖励)
2、深度学习 是机器学习的分支,基于多层神经网络自动提取特征 ,适合非结构化的数据,比如图像、语音。和传统机器学习相比,深度学习可以解决更复杂的问题。深度学习有CNN 卷积神经网络、RNN 循环神经网络、Transform
(其中,卷积神经网络特点是卷积、池化、全连接,构建输入层、隐藏层、输出层。卷积是通过卷积核在数据上移动计算特征图,池化是保留关键特征,就像是把高清图片压缩成缩略图,全连接是根据前面的特征组合起来,输出结果。)
(循环神经网络能很好地处理序列数据,序列数据指数据有顺序性,比如可以根据前后语境预测结果,输入"今天是晴天,天气怎么样",RNN会回答天气真好。但是循环神经网络面临着梯度爆炸/消失的问题,由此又产生了LSTM和GRU门控)
机器学习与深度学习没有绝对的优劣,依赖于具体问题具体分析,根据实际应用场景选择
机器学习
一、概念
1、无监督学习(降维、聚类) :
没有标签,让计算机自己寻找数据规律,并分类
- 聚类 (物以类聚,分类)
一句话概括就是把特征相同、类似的分为一类,物以类聚
举例:把客户分成 高消费客户、普通客户、潜在客户
**k---means聚类:**随机选几个点作为质心,把数据点按"距离最近"分成K组,哪个点离中心近,就归为哪一类。例: 把一群人(数据)分成很多组,哪个人离组长(中心)近,则归为这个组(分类)
- 降维 (提取关键信息,降维)
PVA------主成分分析法
找方向:找到数据变化最大的几个方向(主成分)
转坐标:把数据转到这些新方向上。
砍维度:只保留最重要的几个方向,剩下的扔掉。
总结PVA:找数据变化最大的方向建坐标轴,把其他数据转到新方向上,这样实现了降维的效果,压缩数据只保留最关键的东西。缺点:对异常值敏感
SVD------奇异值分解
由3个矩阵组成,左奇异矩阵、奇异值矩阵、右奇异矩阵的转置

2、监督学习(分类、回归) :
输入数据+标签,用模型预测结果。
- 分类 01问题,下雨/不下雨
- 回归 如房价预测
3、强化学习 :
强化学习是一种 让智能体通过与环境不断交互,学习最优决策策略的一种方法
比如说阿尔法狗下围棋,通过试错最大化积累奖励
回答关键词:让智能体与周边环境交互试错,寻找最优策略,最大化积累奖励
马尔可夫决策过程(Markov Decision Process, MDP)
**核心要素:**状态集合、动作集合、转移概率、奖励机制
通过贝尔曼方程找最优策略,获得最大化积累奖励
二、数据集分类、特征工程与特征缩放
1、训练集、验证集、测试集:
- 训练集:用来训练模型,训练集的数据用来直接参与模型的学习过程,使模型尽可能贴合数据
- 验证集:用于模型的选择和超参数的调整
- 测试集:评估模型的泛化能力,像"考场",看模型在实际应用中效果怎样
划分这些的目的是防止过拟合 ,提高模型泛化能力 (黑体的这俩词记住了)
(补充参数与超参数:参数是通过训练数据得到的,超参数比如学习率、权重是自己设定的。 超参数的调整方法:网格搜索------把预定的超参数都试一遍,选最优的)
2、特征工程: 通过对数据清洗、变换、构造 ,将原始数据转征,核心目标是提升模 化为更适合机器学习模型的高质量特型泛化能力 (一般目标都是这个,照着答"泛化能力")
3、特征缩放: 统一特征的范围 ,避免量纲差异大,提升模型训练的效率,比如标准化、归一化
(提问,为什么要归一化和标准化,有什么作用?目的是统一特征的范围 ,避免量纲差异大,提升模型训练的效率)
- 标准化 :
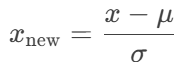
比如基于距离的模型(KNN、SVM、K-Means)
补充KNN与K-Means的区别:
KNN属于监督学习,类别是已知的。具体实现:找距离最近的k个样本点,看这k个点中概率最高的类别作为预测的类别。
K-means属于非监督学习,事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。
- 归一化:
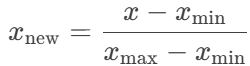
适合固定输出范围的数据。比如树模型(决策树、随机森林、XGBoost)
特征处理:
离散特征处理(标签编码、频数编码、独热编码创建二进制向量........)
连续特征处理(标准化、归一化、取对数.......)
4、其他补充
结构化数据(有固定格式,比如excel)
非结构化数据(图像、音频)
鲁棒性:面对异常值仍能保持稳定性
交叉验证:适合数据量小的情况,合理划分训练集、验证集,比如K折交叉验证,留一交叉验证
标签不平衡问题
标签不平衡主要指的是某个类别的样本相较于其他样本 特别多/特别少,可能会影响预测结果
focal loss (通过调整损失函数让模型更关注难以分类的样本,适合极端不平衡的场景)
过采样(数据量不够,所以需要过采样,需要增加数据量,最简单直接的办法就是复制样本,或者SMOTE方法插值)
欠采样(数据量太多,减少些样本量,随机删除/聚类保留重要信息)
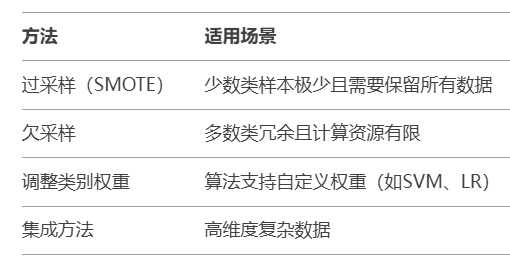
**数据增强操作:**对现有数据样本进行一系列变换来生成新样本,比如针对图像(旋转裁剪压缩),文本(同义词替换)
三、代 价 函 数 (cost function)
衡量模型预测与y实际真实值之间的差异 (整体所有样本误差的平均)
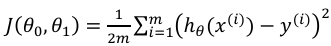 (平方代价函数------输出为连续的场景)
(平方代价函数------输出为连续的场景)
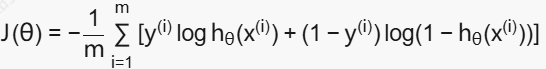 (交叉熵代价函数------分类问题)
(交叉熵代价函数------分类问题)
其中h(x)代表预测值,y代表真实值
要想预测越准确→让误差越小→代价函数越小,因此我们要找代价函数最小值
如何最小化代价函数?
梯度下降算法------看下回分解
四、梯度下降算法
梯度下降:通过最小化代价函数来计算出w和b参数值
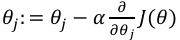 ,其中代价函数为
,其中代价函数为
对代价函数求完偏导并代入到式子中得到:
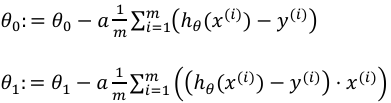
其中: 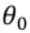 可理解成 wx+b 里面的 b
可理解成 wx+b 里面的 b
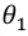 是w,由于w与x相乘,求w的偏导,x视为常数,故上式最后乘了x
是w,由于w与x相乘,求w的偏导,x视为常数,故上式最后乘了x
具体可参考这个文章,关于梯度下降算法写的很细
补充:Adam算法也可求代价函数最小值,区别是Adam自适应自动找学习率,效率更高
学习率的选择
-
学习率过大:在最优解附近震荡、发散,错过最优解
-
学习率过小:收敛慢、效率不高
要么设定学习率,要么使用Adam自适应学习率,优化方向------添加L1/L2正则化防止过拟合
优化器optimizer
通过调整模型参数,找到让损失函数最小化的最优路径,比如Adam
五、过拟合与欠拟合
过拟合:拟合效果过于贴合原始数据,在测试集表现不理想,模型泛化能力不强
欠拟合:拟合效果不好,不能很好适应训练集
高方差过拟合,高偏差欠拟合
过拟合的原因:
模型过于复杂、数据量小、数据噪声大(异常值)
怎么解决过拟合?(正则化、早停法)
1、增加数据量
2、交叉验证 :适合数据量小的情况,合理划分训练集、验证集
3、早停法 :当模型在验证集上的性能开始下降之前停止训练
**4、正则化:**保留所有的特征,但是减少参数λ的大小
第一个式子是线性回归的正则化,第二个是逻辑回归的正则化
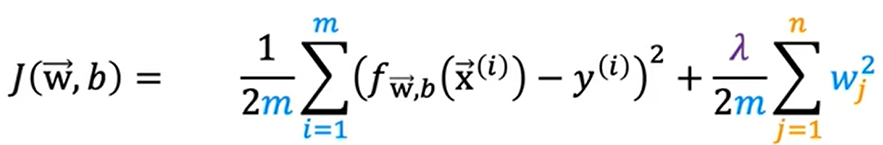
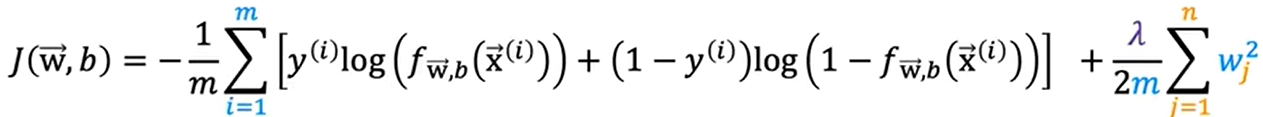
(这里有两种常见正则化,一种是加 | w | , 这叫 L1正则化 。另一种是加w的平方 ,上面式子举例就是加w的平方,叫 L2正则化 )
其中,参数λ(lambda)的作用:
-
λ大:惩罚力度大 → 模型更简单(可能欠拟合)。
-
λ小:惩罚力度小 → 模型更复杂(可能过拟合)。
-
λ=0:关闭正则化 → 变回普通模型。
正则化就像给模型戴个"紧箍咒",让它别学得太复杂,从而更好地适应新数据
岭回归 是 L2 正则化的一个实例,专门用于线性回归模型,通过引入 L2 惩罚项优化参数。
六、SVM支持向量机
SVM(Support Vector Machine, SVM) 是支持向量机,一种监督学习模型
缺点:适合小批量样本数据,数据量大的场景下不适用
**核心目标:**找最大间隔分界面,尽可能把两类数据分开

支持向量的位置直接决定了超平面的位置,支持向量是边界上的样本点
**SVM的应用场景 :**文本分类、图像识别、预测房价、股票趋势。
七、决策树与随机森林
决策树是像树一样的监督模型,可以用来回归或分类
决策树:选择特征------>递归生成子树------>剪枝优化
决策树选择特征:
-
信息增益:选择使信息不确定性减少最多的特征。
-
基尼系数:选择使数据纯度提升最大的特征。
剪枝优化(防止过拟合):
- 预剪枝:提前终止分裂
- 后剪枝:在生成树之后再处理
随机森林 由多个决策树组成,**每棵树用随机数据和随机特征训练(**怎么避免过拟合?特征随机性),最后投票决定结果。随机森林通过集体智慧提高稳定性
随机森林提供综合多个树的结果,减小了预测的不稳定性
集成学习
通过结合多个模型结果,减少单个模型的偏差
- Bagging:并行训练多个模型,对结果取平均或投票(比如随机森林)
- Boosting:顺序训练多个模型,每个模型尝试修正前一个模型的错误
- Stacking:通过训练元模型Meta-Model来组合多个基模型
八、性能指标
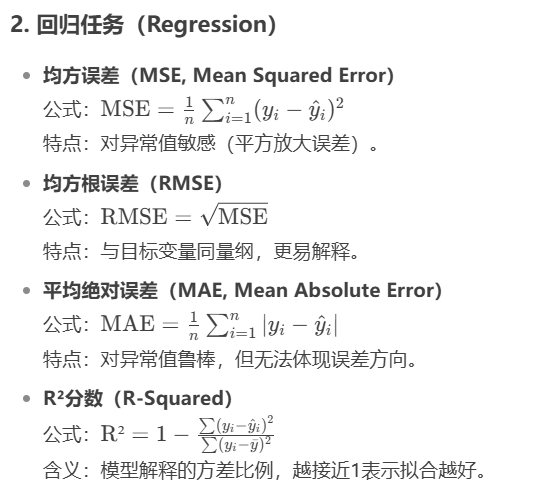
1、分类任务
-
准确率(Accuracy)
公式:Accuracy = 正确预测数 / 总样本数
特点:适用于类别均衡的场景,对类别不平衡数据不敏感(如99%负样本时,全预测负类准确率99%,但无意义)。
-
精确率(Precision)
含义:预测为正类的样本中,实际为正类的比例。
适用场景:关注减少误报(如垃圾邮件检测,避免将正常邮件误判为垃圾)。
-
召回率(Recall,灵敏度 Sensitivity)
含义:实际为正类的样本中,被正确预测的比例。
适用场景:关注减少漏报(如癌症筛查,避免漏诊)。
-
F1分数(F1-Score)
特点:精确率和召回率的调和平均,平衡两者,适用于类别不平衡数据。
恭喜你完成机器学习入门!现在开始深度学习吧!
深度学习(神经网络)
神经网络如何"学习"?
-
试错:输入一张猫图 → 网络预测"是狗" → 比对真实标签"猫" → 发现错了。
-
调整参数 :通过反向传播算法,从后往前逐层调整权重 w 和偏置 b。
-
目标:让预测结果越来越接近正确答案(最小化损失函数)。
类比:就像学画画,一开始画猫像狗,老师指出错误后,你逐渐修正线条和颜色,越画越像。
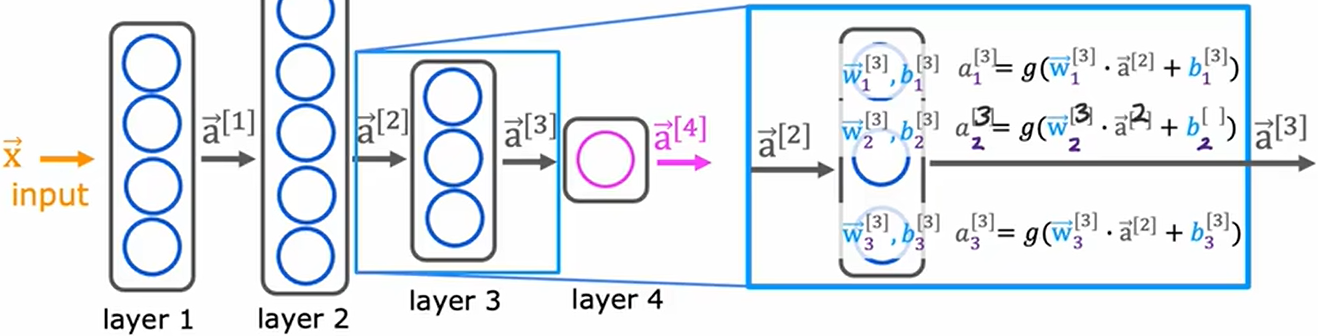
右上角方括号代表第几次,右下角代表该层的第几个神经元对应的参数
神经元、层、激活函数
1. 神经元(Neuron)
-
功能:接收输入信号,决定是否"激活"(传递信号)。
-
数学公式 :
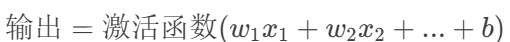
w是权重,b是偏置(类似"门槛",控制激活难易度)
2. 层级结构(Layer)
-
输入层:接收原始数据
-
隐藏层:负责提取特征(低级特征→高级特征)。例如:第一层识别边缘,第二层识别眼睛,第三层识别整个猫脸。
- 输出层:给出最终结果
3. 激活函数(Activation Function)
-
作用 :引入"非线性判断能力"。如果没有激活函数,无论有多少层,神经网络都只能表示线性变换的组合
-
常用函数:
-
Sigmoid :适用于01分类问题,输出概率(0~1),
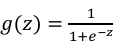 ,通常用于最后的输出层
,通常用于最后的输出层 -
Linear:结果可为正,可为负,g(z) = z
-
ReLU:结果只为正数(负数归零,正数保留),g(z) = max(0 , z)
-
(补充思考:为什么用这些激活函数能引入非线性判断能力?它们表达式明明看起来很简单,尤其是RELU,为什么隐藏层广泛使用relu?
答:虽然relu本身是分段线性函数,但是通过多个隐藏层的组合,可以逼近非线性,试验1000次relu确实可以实现非线性,并且relu可以缓解梯度消失,计算高效,只需比较是否非负,然后输出即可。问就是自己实践过,老师爱动手的孩子)
- 一对多的分类(用softmax)
 比如天气预测:晴天、阴天、雨天
比如天气预测:晴天、阴天、雨天
Softmax回归算法:逻辑回归的推广,可解决多分类问题
左右类比一下,a1代表模型是1 的概率估计,那么右边aj就代表模型结果是j的概率估计
Softmax 函数性质:输出值都在(0,1)区间内,且输出的所有概率值之和为 1,保证了所有类别概率的完整性和归一性

常见的神经网络:
1、全连接神经网络,有三种基本类型的层:输入层、隐藏层和输出层。
2、卷积神经网络CNN,卷积池化全连接
3、循环神经网络 ,LSTM,Transformer,都可以处理序列数据。由于RNN因为梯度消失处理长序列数据不理想,Transformer基于注意力机制而且可以并行处理,能很好地处理长序列数据,注意力机制是模仿人脑思考动态分配权重,选择性关注重要信息
4、GAN对抗神经网络,生成器对抗器不断彼此训练,最终达到生成器数据"以假乱真"的目的
5、GNN图神经网络,处理非欧几里得的图结构数据(无固定维度和空间),比如社交圈、用户喜好推荐
卷积神经网络(CNN)
全称:Convolutional Neural Network (CNN)
核心思想:模仿人类视觉,逐层提取特征(从简单到复杂)
**主要用于:**图像识别、医学影像分析、自动驾驶、人脸识别等
解决传统神经网络参数量大的问题
一、CNN的三大核心操作:卷积 池化 全连接
卷积(抓特征)→ 池化(压缩)→ 全连接(分类)
1. 卷积------提取局部特征
-
工具:卷积核(也叫滤波器,一个小矩阵)。
-
操作 :卷积核在图像上滑动,计算每个位置的加权和,生成特征图。
-
直观比喻:想象你用手电筒(卷积核)扫描一张照片,手电筒照到的每个小区域会被检测是否有某种特征(比如垂直线条)。
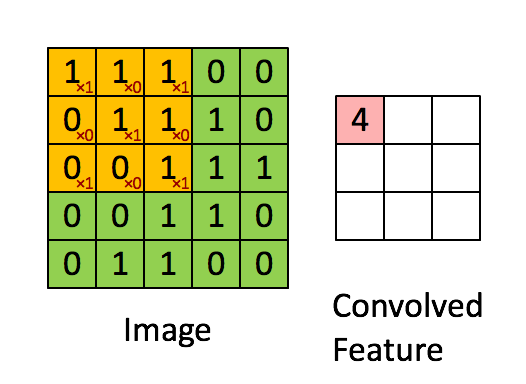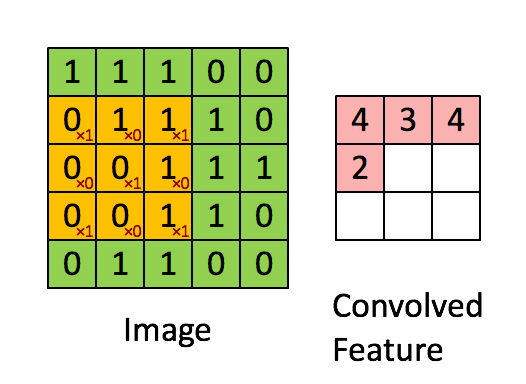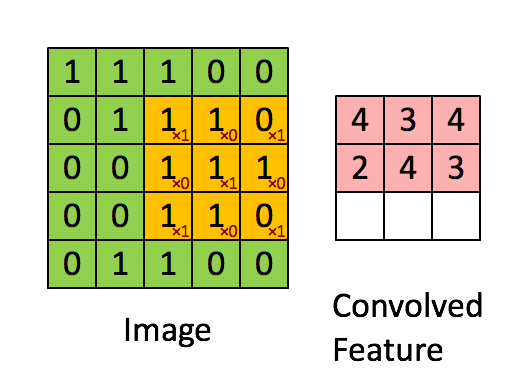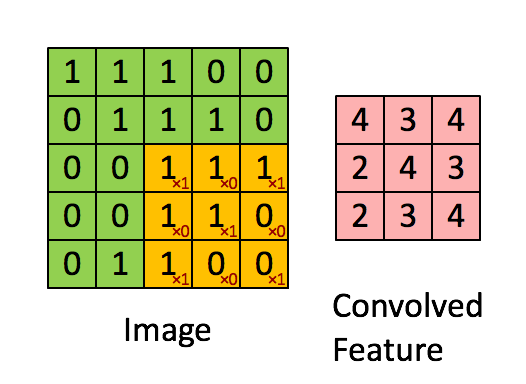
2. 池化------压缩信息,保留关键特征
-
目的:减少数据量,同时保持特征不变。比如把高清图缩小成缩略图,但保留最明显的特征
-
常用方法:最大池化(Max Pooling),取局部区域内的最大值。
3. 全连接层(Fully Connected Layer)------最终分类
-
作用:将前面提取的抽象特征组合起来,输出分类结果(比如"猫"的概率是90%)。
-
类比:就像人类看到"尖耳朵、胡须、圆眼睛"这些特征后,大脑判断这是一只猫。
二、CNN的完整流程(以识别猫为例)
卷积(抓特征)→ 池化(压缩)→ 全连接(分类)又来重复一遍 记住没
多个卷积层和池化层 层层组合
-
输入层:原始图片(比如224×224像素的RGB图像)。
-
卷积层1:用多个卷积核扫描图片,提取低级特征(如边缘、颜色)。
-
池化层1:压缩特征图,减少计算量。
-
卷积层2:组合低级特征,检测更复杂的结构(如猫的耳朵轮廓)。
-
池化层2:进一步压缩。
-
全连接层:将所有特征综合,输出概率("猫:90%","狗:5%"...)。
循环神经网络(RNN)
前言:为什么出现RNN?
---------传统的神经网络处理大量数据时效率低,尤其在处理序列数据方面表现差,没有"记忆功能"。RNN全称 Recurrent Neural Network
一、RNN的定义
RNN 是一种专门处理序列数据 的神经网络模型,其核心思想是通过循环连接,使网络能够记忆历史信息,从而捕捉序列中的时序依赖关系
(补充:什么是序列数据------数据有顺序性,前后关联性强)
关键特点:
-
输入数据具有顺序性(如时间序列、自然语言)。
-
每个时间步的隐藏状态传递历史信息,影响当前输出。
示例:RNN会根据已生成的单词(如"今天天气")预测下一个词(如"晴朗"),保持上下文连贯
二、RNN的局限性
梯度消失 / 爆炸 远 距 离 依 赖 无 法 有 效 学 习
**当序列较长时,早期信息难以传递到后期,**梯度消失/爆炸 远距离依赖无法有效学习。
为什么会有梯度爆炸 / 消失? ------------激活函数选择不对 / 初始权重过大,根源是反向传播的链式法则造成的
改进方案
- LSTM(长短时记忆网络) :
通过"门控机制"(输入门、遗忘门、输出门)选择性地保留或丢弃信息。 - GRU(门控循环单元) :
LSTM的简化版,合并部分门控单元,减少计算量。
三、LSTM 长短时记忆网络 与 GRU门控机制
LSTM------选择性记忆重要东西
通过引入门控机制 和细胞状态 ,增强了对长序列数据的处理能力
**门控机制:**遗忘门、输入门、输出门
GRU 是LSTM的变体,合并 遗忘门 和 输入门 为 更新门,简化运算
隐藏状态直接作为输出,无单独细胞状态
Transformer
Transformer 是一种 基于自注意力机制 的深度学习模型框架,通过 并行计算 和 全局建模,解决了传统RNN梯度消失的问题
自注意力机制是模拟人脑选择性关注重要信息,动态分配权重 (比如"一只猫躺在毯子上,它睡着了"。出现了两个名词"猫"和"毯子",但这里的"它睡着了",我们自然会觉得是猫)
通过自注意力机制来捕捉序列数据中的长距离依赖关系
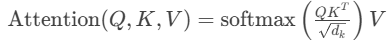 用的softmax函数
用的softmax函数
多头注意力的作用是什么?
答:多个注意力头可以 捕捉不同特征,增强模型表达能力
位置编码的作用?
答:自注意力本身不考虑序列顺序,位置编码通过为每个位置添加唯一向量,让模型感知词序信息。
GAN生成对抗网络
GAN全称生成对抗网络,由生成器和判别器组成。生成器生成假数据,判别器判断真假,两者对抗训练,最终生成器能生成以假乱真的数据,判别器无法区分真假
GAN的优势在于无需显式建模数据分布,但存在模式崩溃、训练稳定性的问题,可以通过改进训练技巧来优化性能
NLP(自然语言处理)
NLP全称 Natural Language Processing,让计算机理解、生成人类语言,比如用于智能客服系统、语言翻译、情感分析等领域
传统方法:比如通过词频统计捕捉语义关系
深度学习方法:
-
词嵌入(Word2Vec、GloVe) → 将词映射为语义向量
-
序列模型(RNN、LSTM) → 处理文本的时序依赖
-
Transformer与预训练模型(BERT、GPT) → 预训练模型指"预训练+微调"。BERT是基于Transformer的预训练语言模型,能够根据上下文语境调整词义解读,提高了自然语言处理的效率
补充bert
BERT是基于Transformer的预训练语言模型。它的核心目标是通过双向语境学习文本的深层语义表示,从而提升各种文本处理任务的效果。
BERT 的核心特点
-
双向 Transformer 架构
传统模型(如 Word2Vec、GPT)仅从单向语境(如从左到右)学习语义,而 BERT 通过双向注意力机制同时捕捉上下文信息(例如 "苹果" 在 "我买了一个苹果" 和 "苹果公司发布了新产品" 中的不同含义)。
-
预训练 + 微调模式:
- 预训练:先在通用大规模数据集上训练基础模型(如 ResNet、BERT)学习通用特征
- 微调 :通过少量标注数据调整模型参数,大幅降低迁移成本。
-
深层语义理解
通过多层 Transformer(如 BERT-base 有 12 层,BERT-large 有 24 层),捕捉词汇、句子、段落的多层次语义关联。
其他补充
deepseek
用到哪些技术?
多头潜在注意力、多Token预测(利用上下文信息提高准确性)、Transformer.......(答前面的深度学习模型,肯定用到了它们,展开说就好)
云计算
按量付费的模式,提供基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)
公有云、私有云、混合云
大数据
大数据特点:数据量大、数据多样性、价值密度低(有价值的信息比例不高)、数据更新快
迁移学习
用已有经验解决新问题,复用已有知识