目录
数组
数组分为静态数组和动态数组两种,之前我们学习的数组就属于静态数组。
-
静态数组:数组创建完成后大小固定,不能改变数组长度,无法动态增加或减少元素数量。
-
动态数组:动态数组是一种可以自动扩展大小的数组,它可以在运行时动态地增加或减少元素的数量
我们之前说过,数组在内存中是一片连续空间。而且由于元素类型一致,所以数组中每个元素大小是一样的。这样就可以根据数组起始地址、元素大小、元素索引计算出任意元素的内存地址,实现快速随机访问(跳着访问)。
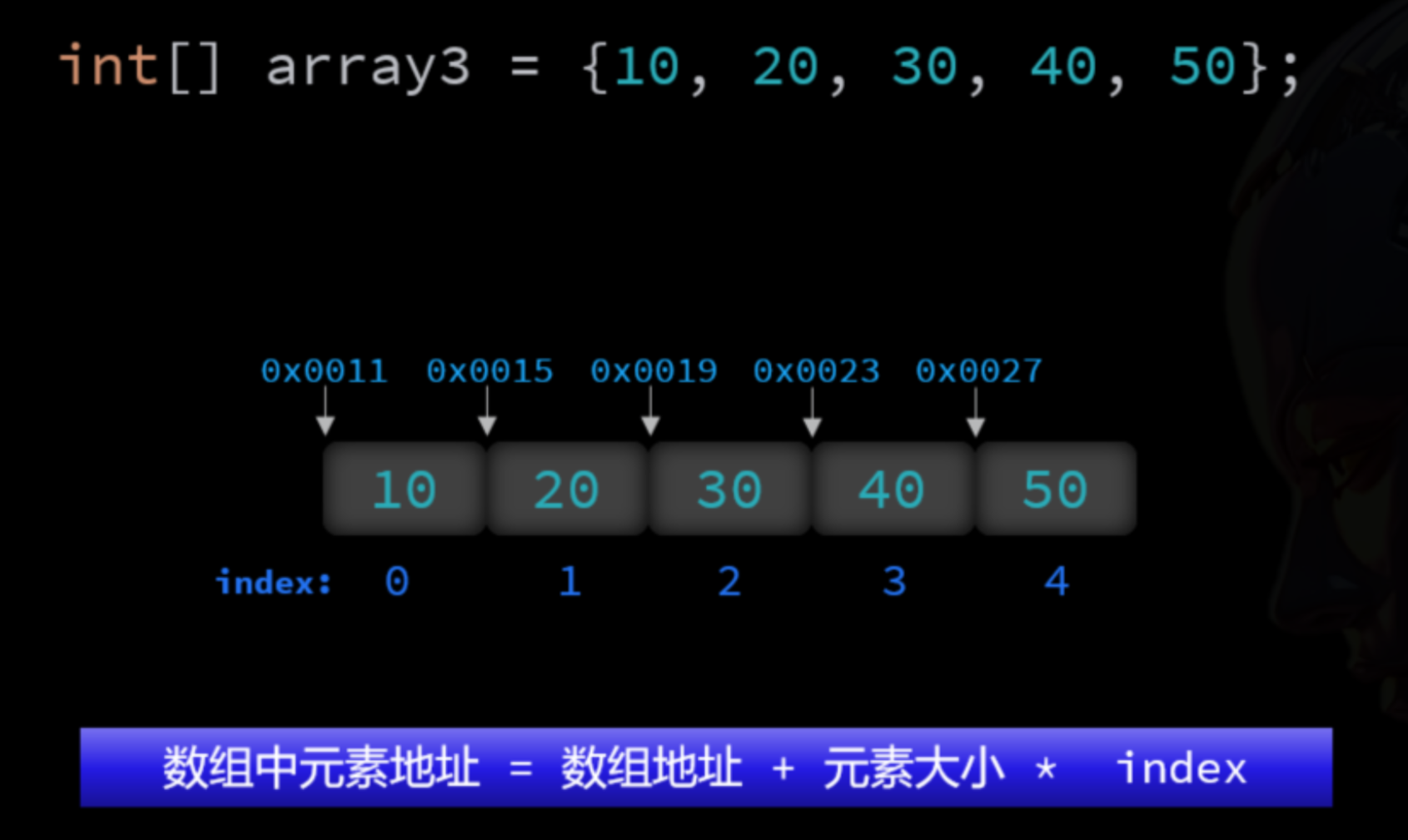
ArrayList
在集合体系中,ArrayList底层就是数组,而且是动态数组。
-
ArrayList默认的容量为10,也就是初始数组大小
-
当元素存不下时触发扩容,默认扩大为原来1.5倍
构造方法:
| 构造方法 | 描述 |
|---|---|
| ArrayList() | 构造一个初始容量为 10 的空列表。 |
| ArrayList(int initialCapacity) | 构造一个具有指定初始容量的空列表。 |
| ArrayList(Collection<? extends E> c) | 构造一个包含指定集合元素的列表,按照集合迭代器返回元素的顺序。 |
在我们创建ArrayList时,如果知道需要的大小最好写上这样不浪费空间。
java
public static void main(String[] args) {
// 创建一个ArrayList对象,初始化容量为3
List<String> list = new ArrayList<>(3);
list.add("hello");
list.add("world");
list.add("java");
System.out.println(list.size());
// 也可以使用List.of创建只读集合
List<String> list2 = List.of("hello", "world", "java");
System.out.println(list2.size());
}总结
-
**随机访问快:**有索引,所以随机访问速度特别快
-
**增删元素慢:**由于增删涉及到扩容、元素拷贝,所以速度慢
-
查找慢:根据元素值查找只能逐一遍历,效率比较低
链表
链表(Linked List) 在内存空间中是不连续的,由分散在内存中的一个个节点组成,元素就存储在节点之中。
根据节点指针域指向不同,链表可以分为三类:
-
单向链表
-
双向链表
-
循环链表
单向链表:节点指针域中记录下一个节点的地址
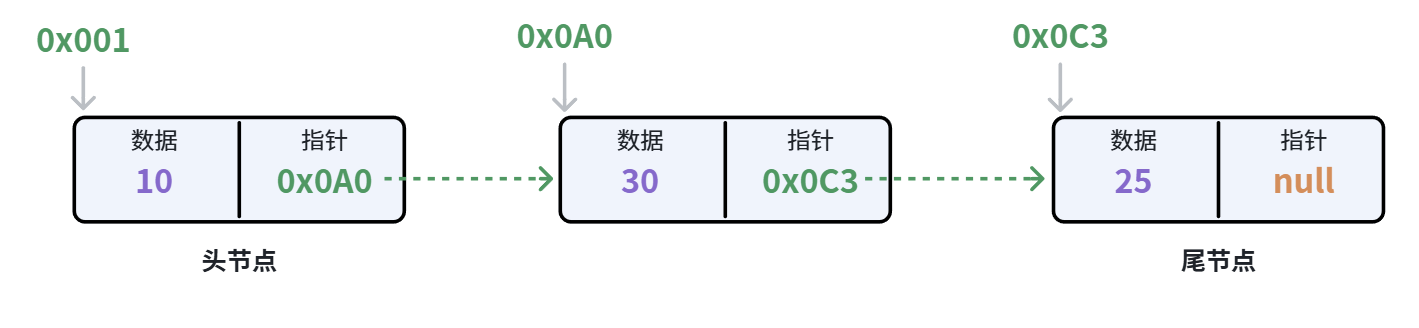
双向链表:节点指针域中记录上一个节点、下一个节点的地址

双向链表既可以从头到尾遍历,也可以从尾到头遍历,更加灵活。缺点是会占用更多内存。
循环链表:尾节点的指针与记录头节点的地址,链表形成环状
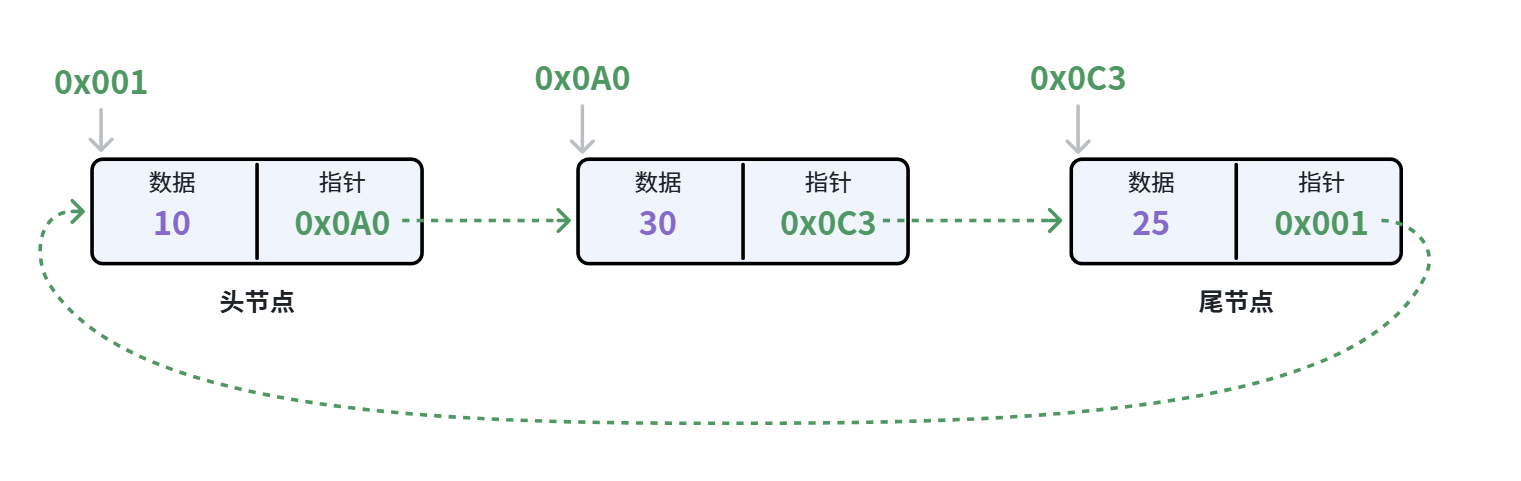
循环链表因为是环形结构,所以可以从任一节点访问整个链表,往往用来处理大型数据集或者解决一些特殊问题。
LinkedList
List集合有一个子类LinkedList,底层采用双向链表结构。提供了很多从链表头、尾操作的方法:
| 返回值 | 方法 | 描述 |
|---|---|---|
| void | addFirst(E e) | 添加元素到当前链表的开头 |
| void | addLast(E e) | 添加元素到当前链表的末尾 |
| E | getFirst() | 返回链表开头的元素 |
| E | getLast() | 返回链表末尾的元素 |
| E | removeFirst() | 移除并返回链表开头的元素 |
| E | removeLast() | 移除并返回链表末尾的元素 |
java
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("world");
System.out.println(list);
list.addFirst("hello");
System.out.println(list);
list.addLast("java");
list.addLast("java");
System.out.println(list);
list.removeLast();
System.out.println(list);
}
java
[world]
[hello, world]
[hello, world, java, java]
[hello, world, java]总结
-
**随机访问慢:**在内存中是非连续空间,无法根据索引快速计算地址,所以随机访问慢
-
**增删元素块:**只需要改变节点中指针指向就能实现增删、没有元素拷贝,所以速度块
-
查找慢:根据元素值查找只能逐一遍历,效率比较低
栈和队列
队列
**队列(Queue)**是一组线性数据集合,要求从一端添加数据,从另一端移除数据,实现先进先出的效果。
类似于人们排队买票:
买票必须排队,队列有一个入口,一个出口。
-
先来的人在队首,先买票
-
后来的人在队尾,后买票
这叫做先进先出,这也是队列这种数据结构的特点。
这种先进先出的特性非常适合用在任务处理的业务中。比如:电商行业的秒杀业务,秒杀商品有限,肯定是先来先得。这个时候就可以用队列,无数的用户下单抢购,系统就可以把参与秒杀的人放入队列中,按照下单的顺序,先到先得。
队列数据结构总结:
-
结构特征:入口出口不在一起
-
效果:先进先出
-
应用场景:有序任务处理
栈
栈(Stack)同样是一种操作受限的线性数据结构。但与队列恰好相反,栈要求在同一端添加和删除数据。也就是说入口和出口是在一起的。
比如,浏览器有历史记录功能,你浏览过的所有页面都会添加到浏览历史中。如果浏览历史页面放入一个集合,我们肯定希望满足下面的要求:
-
最先浏览的页面在集合的最底部
-
最近浏览的页面在集合的最上面
这样,当我点击后退一步时,就能找到最近一次访问的页面了:
浏览器的历史记录存取页面数据的过程,刚好就是**先进后出,**完全符合栈的特征。
栈数据结构总结:
-
结构:入口和出口在一起
-
特点:先进后出
二叉树
树
前面我们学习的数据结构都是线性数据结构,即所有数据可以排成一条线,不会出现分叉。所以元素之间只会有前后关系,数据遍历也只有正序和倒序两种。
树是一种非线性数据结构,数据之间不一定能排成一条线,而是像大树一样会出现分叉。只不过树这种结构是倒过来的,根在上,叶子在下:
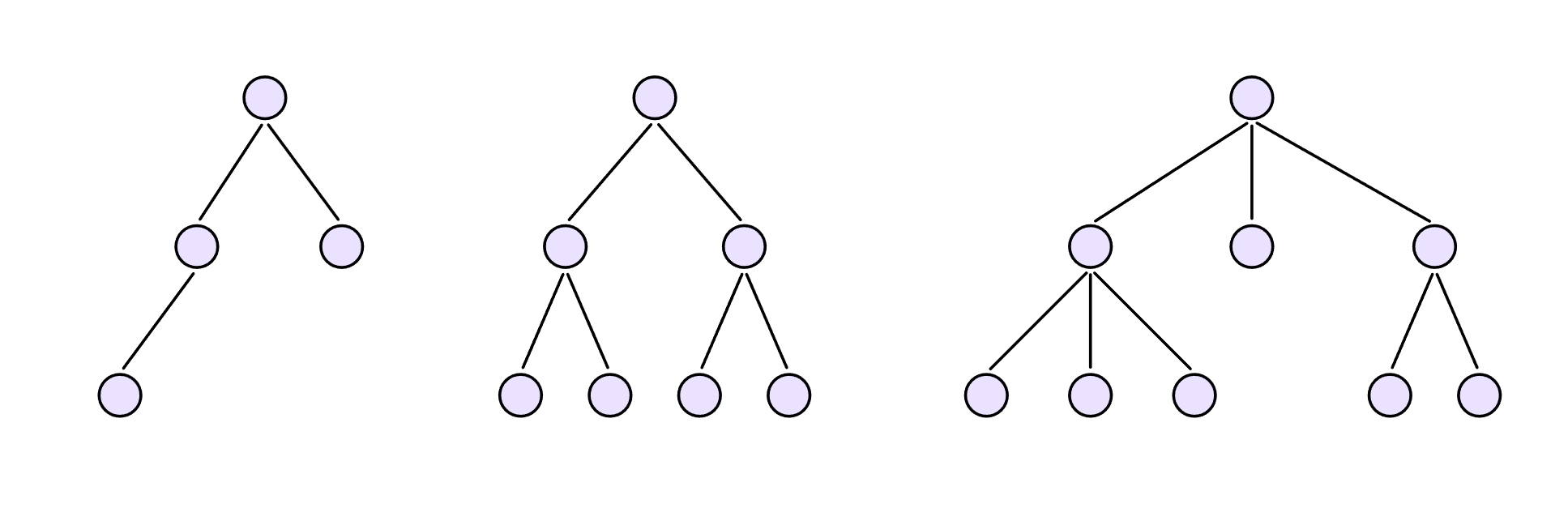
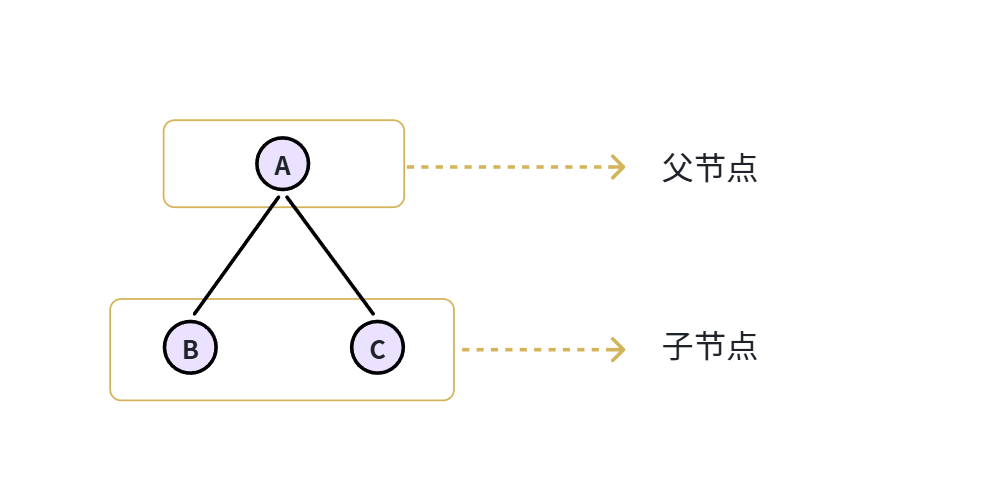
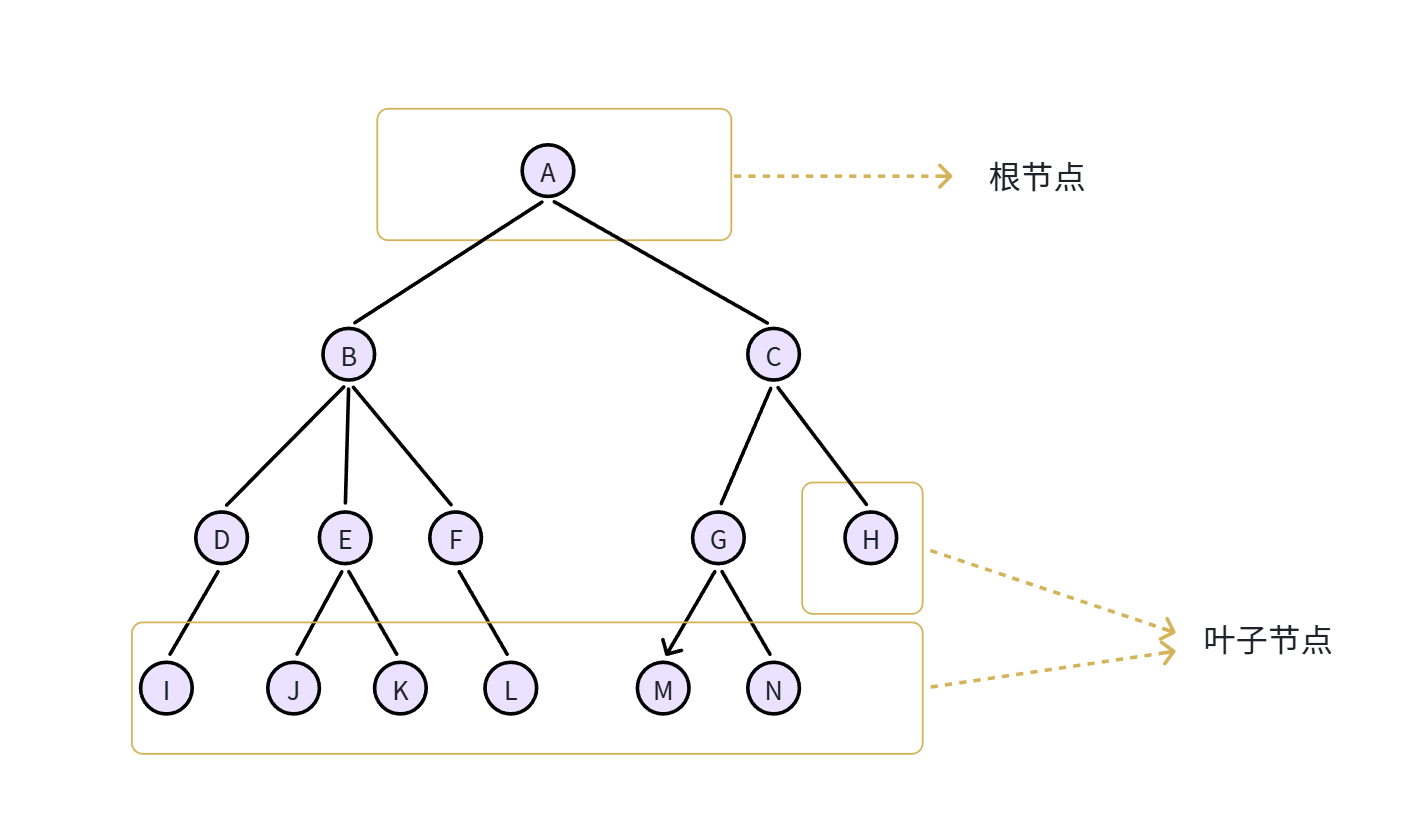
虽然B是A的子节点,但是B也有自己的子节点D、E、F,所以B、D、E、F又形成了一棵树,它们是A的左子树。同理,C、G、H形成了A的右子树。
另外,我们把节点到叶子节点的最长路径(边数)称为节点高度。例如:
-
节点A的高度就是3
-
节点B的高度是2
-
节点D的高度是1
-
节点I是叶子节点,高度为0
二叉树
树的结构由很多种,但最常用的还是二叉树 (Binary Tree)。顾名思义,二叉树的每个节点最多有两个叉,也就是两个子节点,分别是左子节点 和右子节点。
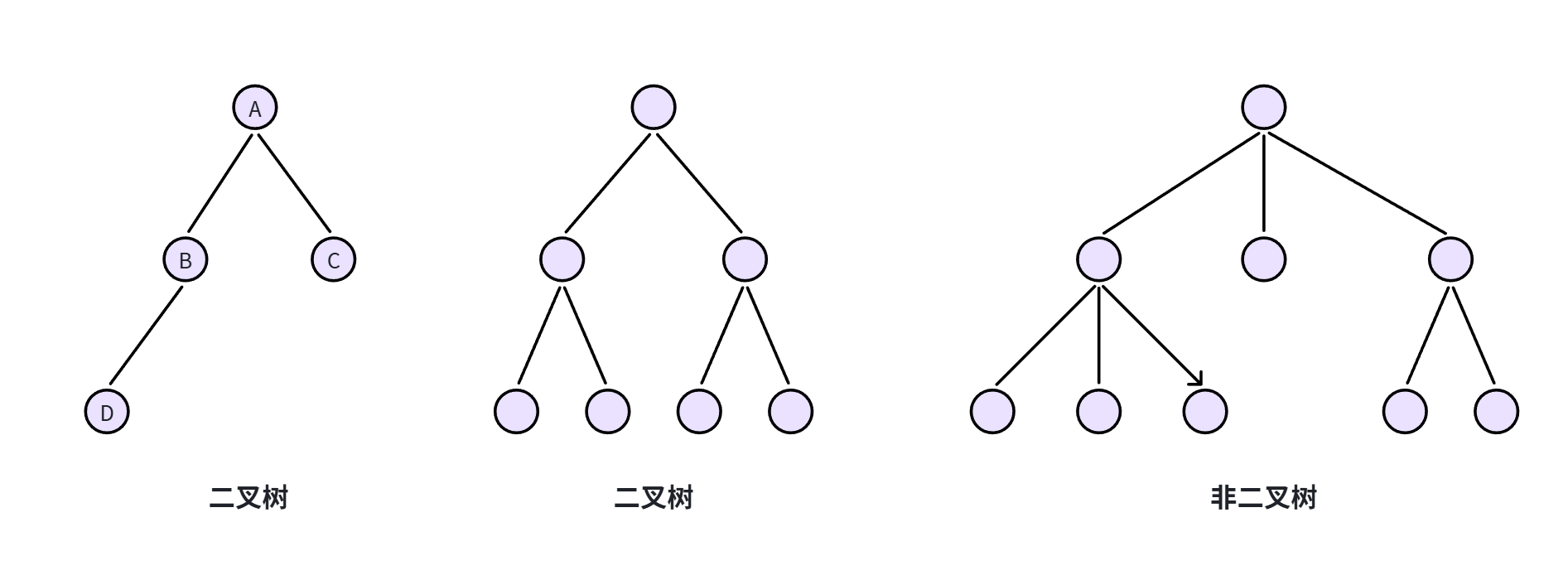
注意,这里是说最多两个子节点,也有可能只有一个子节点。比如上图中的第一棵树的B节点,只有左子节点。
二叉搜索树
二叉搜索树 (Binary Search Tree)是一种特殊的二叉树,顾名思义,二叉搜索树是为了实现快速搜索而生的。
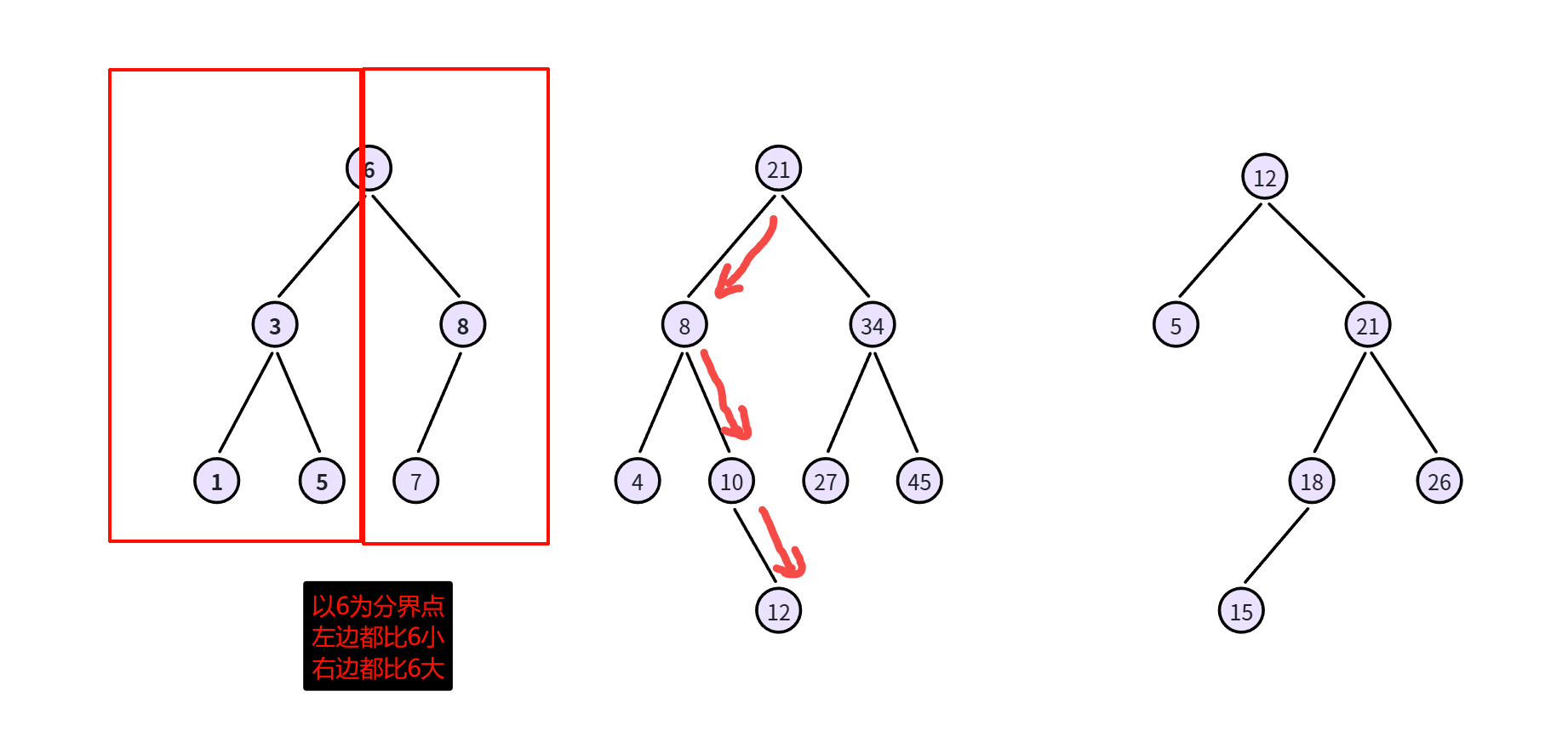
例如,我们要在上图第二棵树中查找是否存在12这个元素,步骤如下:
-
与根节点比较,小于根就去找根的左子树,大于根就去找根的右子树。12小于21,找左子树,找到节点8
-
与子树的父节点比较,小于父节点就去找左子树,大于父节点就去找右子树。12大于8,找右子树,找到节点10
-
与子树的父节点比较,小于父节点就去找左子树,大于父节点就去找右子树。12大于10,找右子树,找到12了
树中有8个数据,但是我们只需要4次比较我们就找到了。如果是一个线性结构,比如链表,最差的情况下,你需要8次才能找到。这就是二叉搜索树的威力。
另外,二叉搜索树的这种特点也保证了树中的元素是经过排序的,使用合适的遍历方式,可以确保元素按照从小到大顺序依次遍历。
平衡二叉搜索树
虽然二叉搜索树在多数情况下效率都很高,但是也有极端情况。比如下图左边的二叉树:
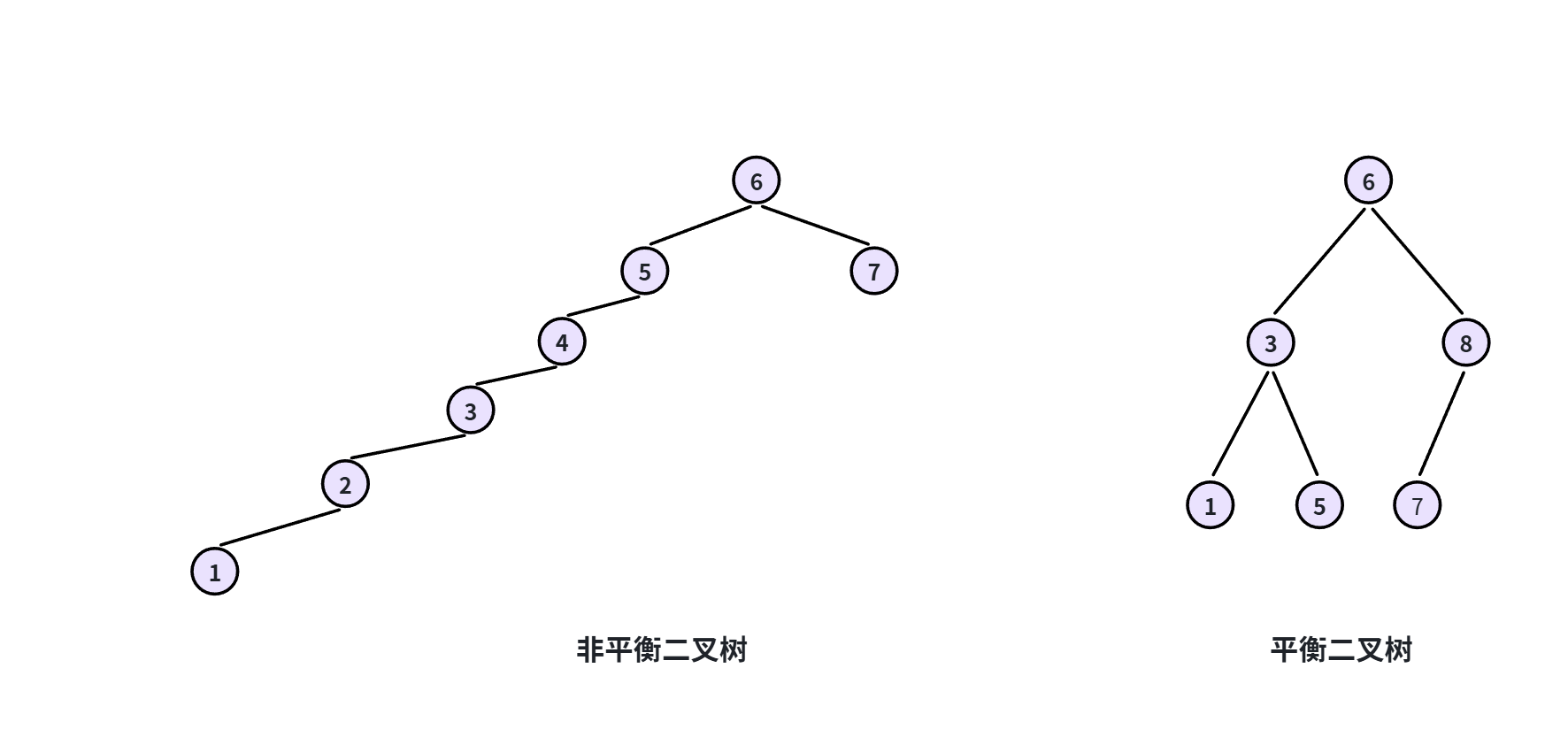
由于数据不均衡,左边的二叉树已经退化成了链表,查找的效率大大下降。
平衡二叉搜索树就是为了解决这一问题。平衡二叉搜索要求:二叉树中任意一个节点的左右子树的高度相差不能大于 1
比如上图中:
-
左边二叉树根节点的左子树高度是4,右子树高度是0,相差太大了。是非平衡二叉树
-
右边二叉树根节点左子树高度为1,右子树高度也是1,左右平衡,是平衡二叉树
平衡二叉树并不是说绝对的平衡,而是尽量让左右子树相差不大,这样才能保证更好的节点增、删、改、查的效率。
平衡二叉搜索树中最知名的就是红黑树了,Java中的Set集合有一个实现类,叫做TreeSet,底层就是采用红黑树。
红黑树会左旋或者右旋来保证二叉树的平衡。
TreeSet
TreeSet首先是Set集合,所以具备Set集合的所有特点:存取无序(存和取的顺序不一致)、不允许重复、无索引。
但同时,TreeSet还具备二叉搜索树的特征,可以将存入的元素按照大小排序。
元素唯一、存取无顺序,元素会排序。
java
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
sortInteger();
sortString();
}
public static void sortInteger(){
TreeSet<Integer> ts = new TreeSet<>();
ts.add(10);
ts.add(5);
ts.add(20);
ts.add(15);
ts.add(30);
// 数字按照大小排序
System.out.println(ts); // [5, 10, 15, 20, 30]
}
public static void sortString(){
TreeSet<String> ts2 = new TreeSet<>();
ts2.add("hello");
ts2.add("world");
ts2.add("java");
// 字符串同样可以排序,但是是按照字典顺序排序
System.out.println(ts2); // [hello, java, world]
}
}Java中的TreeSet就是使用红黑树(自平衡二叉搜索树)结构实现的。因此可以对存入的元素排序,增删改查的效率都非常高。
TreeSet对元素排序是依据自然顺序排序,既:元素必须实现Comparable接口。
Comparable
Comparable,翻译过来就是可比较的,表示当前类型能够比较大小。
java
public interface Comparable<T> {
/**
* 将this与指定的对象o进行比较以进行排序,返回值有三种情况:
* - 大于0,表示 this > o
* - 等于0,表示 this = o
* - 小于0,表示 this < o
*/
public int compareTo(T o);
}compareTo方法就是用来比较大小的方法,将调用compareTo的当前对象(this)与参数中传入的对象(o)做比较,根据比较结果返回三种情况:
-
大于0:说明this大于o
-
等于0:说明this等于o
-
小于0:说明this小于o
凡是实现Comarable接口 的类都需要实现compareTo方法,自定义比较逻辑。这就表示这个类有了比较的规则了,这个类就是可比较的。
哈希表
哈希表的英文是Hash Table,也叫散列表。
所谓的散列就是利用数组可以根据索引随机访问数据的特性,实现高效数据查询。因此散列表,或者哈希表底层就是基于数组来实现的。
哈希表 根据键计算哈希值,决定了数据再数组中存储的位置索引。这样查询时也能根据键计算哈希值,得出数据的索引,快速查找出数据。这就将键(key)与值(value)之间形成了映射关系,具备了根据键高效查询值的能力。
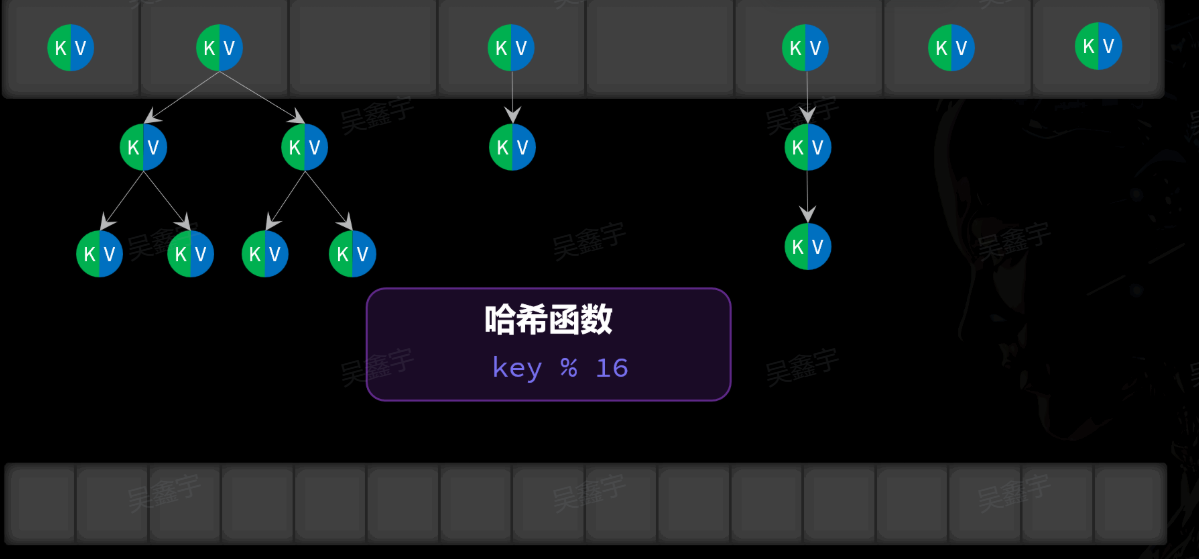
将学号通过哈希运算得到数组的索引,再根据索引对应的位置进行存储。但是存在一种情况,通过学号进行哈希运算得到的结果是一样的。这也就是哈希冲突。
当元素数量超过数组大小时,不管如何优化算法,总会出现两个不同的key计算出了相同hash值 的情况,这样两个数据就需要存储到数组的同一个索引位置。这也就是哈希冲突。
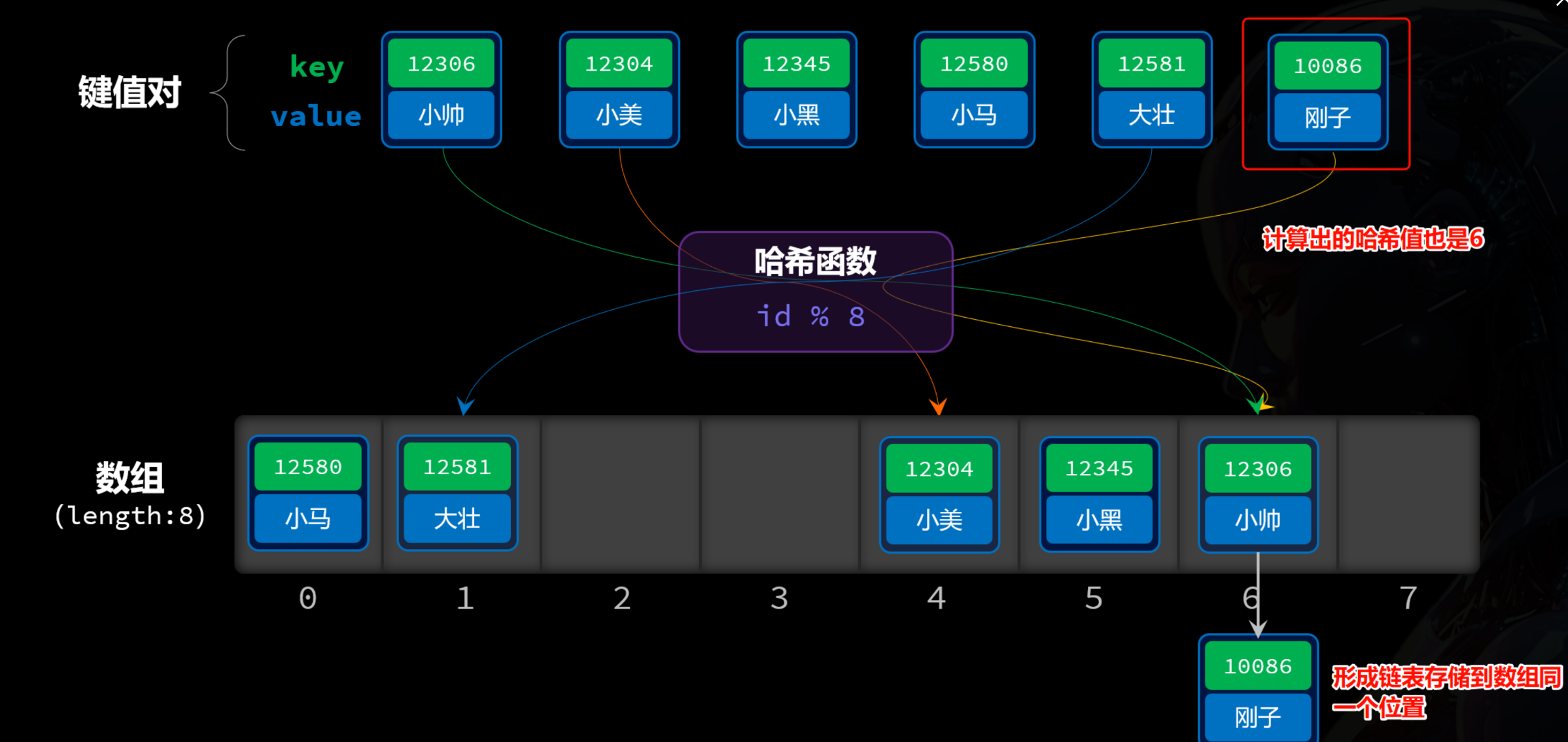
一个好的哈希函数要尽可能做到两点:
-
如果key1 = key2,那么两者的哈希值要尽量一样
-
如果key1 ≠ key2,那么两者的哈希值要尽量不同
这样才能确保不同的数据计算出的数组索引不一样。
哈希冲突不能解决只能尽量避免。例如扩大数组。挂链表、红黑树。
解决哈希冲突的手段主要是两点:
链表法
-
当发生哈希冲突时,先检查两个key是否相同(利用equals方法比较key)
-
如果key相同:说明是key有了新的值,覆盖旧值即可
-
如果key不同:说明是冲突,把两个值形成链表,存入数组中同一个位置
-
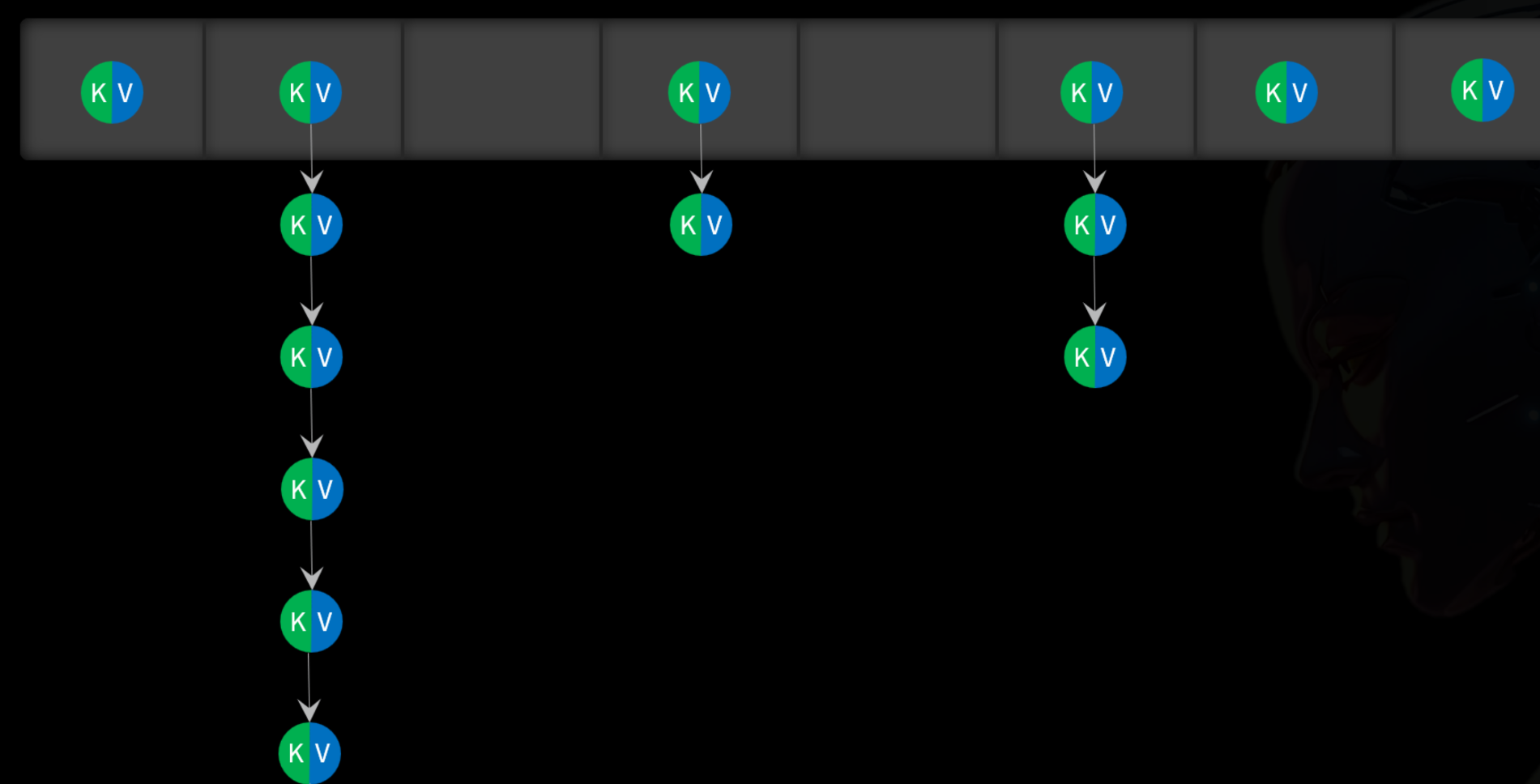
在JDK8之后,当哈希表中某个链表长度超过阈值(8)时,会将链表转为红黑树以提高查询性能:
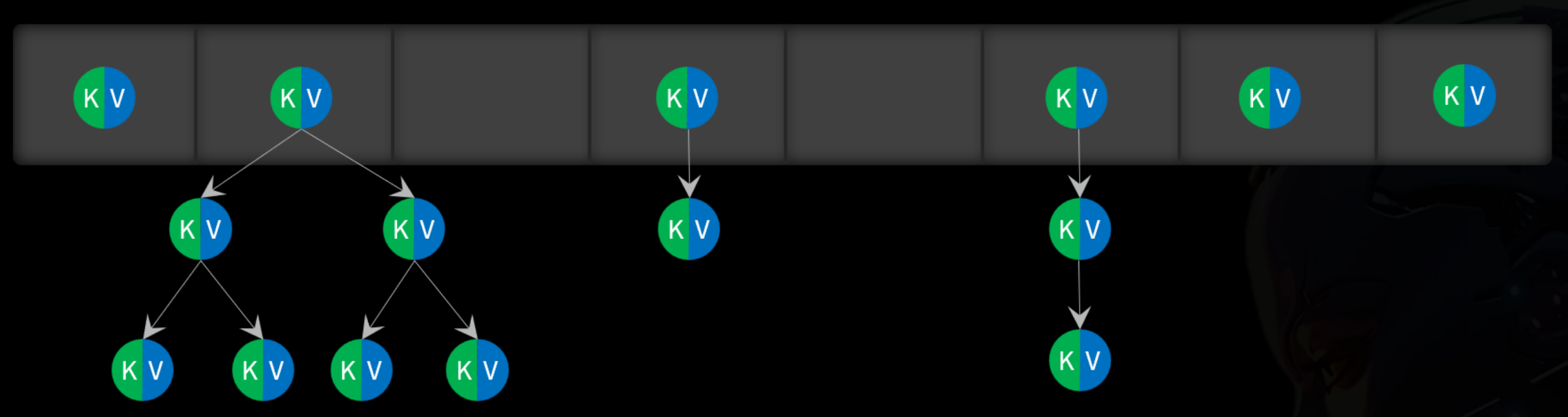
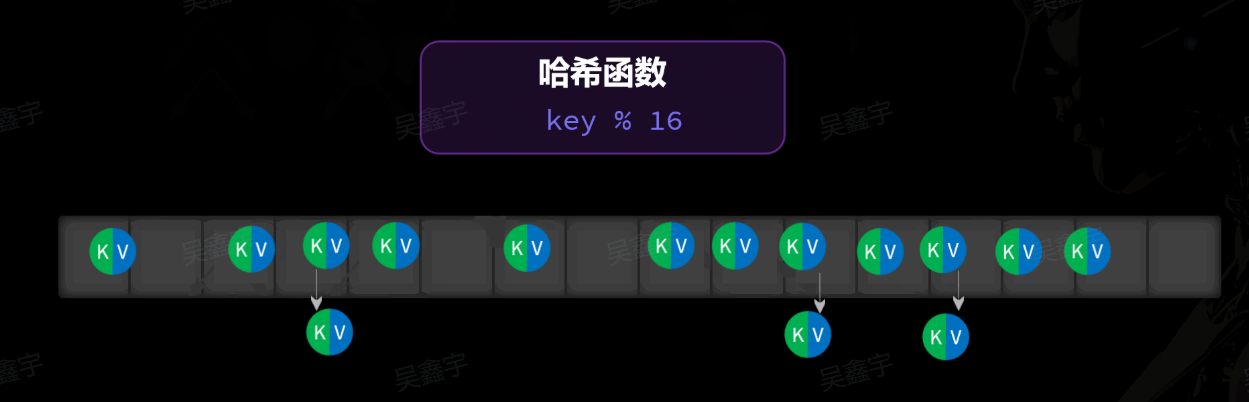
当哈希表的装载因子 超过阈值(0.75)时,就会触发动态扩容,哈希表的数组长度会扩大为原来2倍,然后将所有数据重新计算hash值,写入新的数组,以减少哈希冲突:
动态扩容:
-
我们把元素个数与数组长度的比值称为装载因子(load factor)
-
理论上装载因子越小,出现哈希冲突的概率就越低,我们要保证哈希表的装载因子不超过某个阈值
-
所以,当装载因子超过阈值时(Java中是0.75),就触发扩容,增大数组容量
总结
1、哈希表底层是一个数组,数组有一个初始容量capicity
2、对key做hash运算,对capacity取余,运算结果作为索引
3、将键值对存入数组中索引位置
4、如果该位置已经存在元素,则比较key是否一样
5、一样,则覆盖旧值;不一样,则形成链表
6、当链表长度超过阈值,转为红黑树,小于阈值,再转为链表
7、哈希表元素达到阈值 ,则对哈希表做扩容,元素做rehash
HashMap初始值是16

有人会问,如果key是字符串怎么办,我们要清楚计算机都是通过数字来进行存储的,在java中我们通过hashcode来进行计算出一个数字来进行接下来的流程。
由于HashMap底层会调用key的hashCode方法计算哈希值,调用key的equals方法比较key是否一致。而Object中hashCode和equals的默认实现与对象的属性值无关,不符合需求。
因此作为key的类型必须重写Object的hashCode和equals方法,基于对象的属性来实现hashCode和equals方法。否则出现哈希冲突时将无法正确比较两个key是否一致。
HashSet底层则是基于HashMap来实现的。不过HashSet是单列集合,没有key/value之分,元素会作为key存储,value都是null。
就以Java中的HashSet为例来总结下哈希表的基本原理(对上述内容更细致的解释):
-
哈希表底层是一个数组,数组有一个初始容量,叫做capacity(默认是16)
-
存储元素时:
-
对key做hash运算(基于key的hashCode方法),再对capacity取余作为在数组中的索引
-
找到数组中索引位置,判断是否有元素
-
没有元素:直接存储
-
有元素:比较key值是否一致(基于key的equals方法)
-
一致:则覆盖旧数据
-
不一致:新加入的元素与之前元素形成链表
-
-
-
当链表长度超过阈值(8),则把链表转为红黑树;红黑树元素小于阈值(6),再转为链表
-
当哈希加载因子达到阈值(0.75),则对哈希表扩容,元素做rehash。
-