递归、搜索与回溯知识点整理
一、递归(Recursion)
- 什么是递归?
递归的核心定义:函数自己调用自己的过程,是C语言与数据结构中的核心思想,典型应用场景包括:
二叉树的遍历(前/中/后序),快速排序,归并排序
- 为什么会用到递归?
递归的本质是问题的自相似性:
主问题可以被拆解为多个和原问题结构完全相同的子问题
子问题又可以继续拆解为更小规模的、结构相同的子问题
最终拆解到"足够简单、可直接解决"的边界情况(递归出口)
例如:
二叉树遍历:每个节点的遍历逻辑,与它的左、右子树的遍历逻辑完全相同
快排/归并排序:每个子数组的排序逻辑,与原数组的排序逻辑完全相同
- 如何理解递归?(三层递进理解法)
1) 误区:过度纠结递归展开的每一层调用栈细节,容易陷入混乱。
2) 进阶:把递归函数当成一个"黑盒",只关注它的输入和输出,不用关心内部执行细节。
3) 终极心法:不要在意递归的细节展开图,把递归函数当成一个能完成特定任务的黑盒,相信这个黑盒一定能完成任务(基于数学归纳法的正确性)
示例:二叉树前序遍历
cpp
void dfs(TreeNode* root) {
// 递归出口:空树直接返回
if(root == NULL) return;
printf(root->val); // 处理当前节点
dfs(root->left); // 相信dfs能遍历左子树
dfs(root->right); // 相信dfs能遍历右子树
}示例:归并排序
cpp
void merge(int* nums, int left, int right) {
// 递归出口:区间内只有一个元素,无需排序
if(left >= right) return;
int mid = (left + right) / 2;
merge(nums, left, mid); // 相信merge能排好左半部分
merge(nums, mid + 1, right); // 相信merge能排好右半部分
mergeTwoSortedArrays(nums, left, mid, right); // 合并有序数组
}- 如何写好一个递归?(三步走)
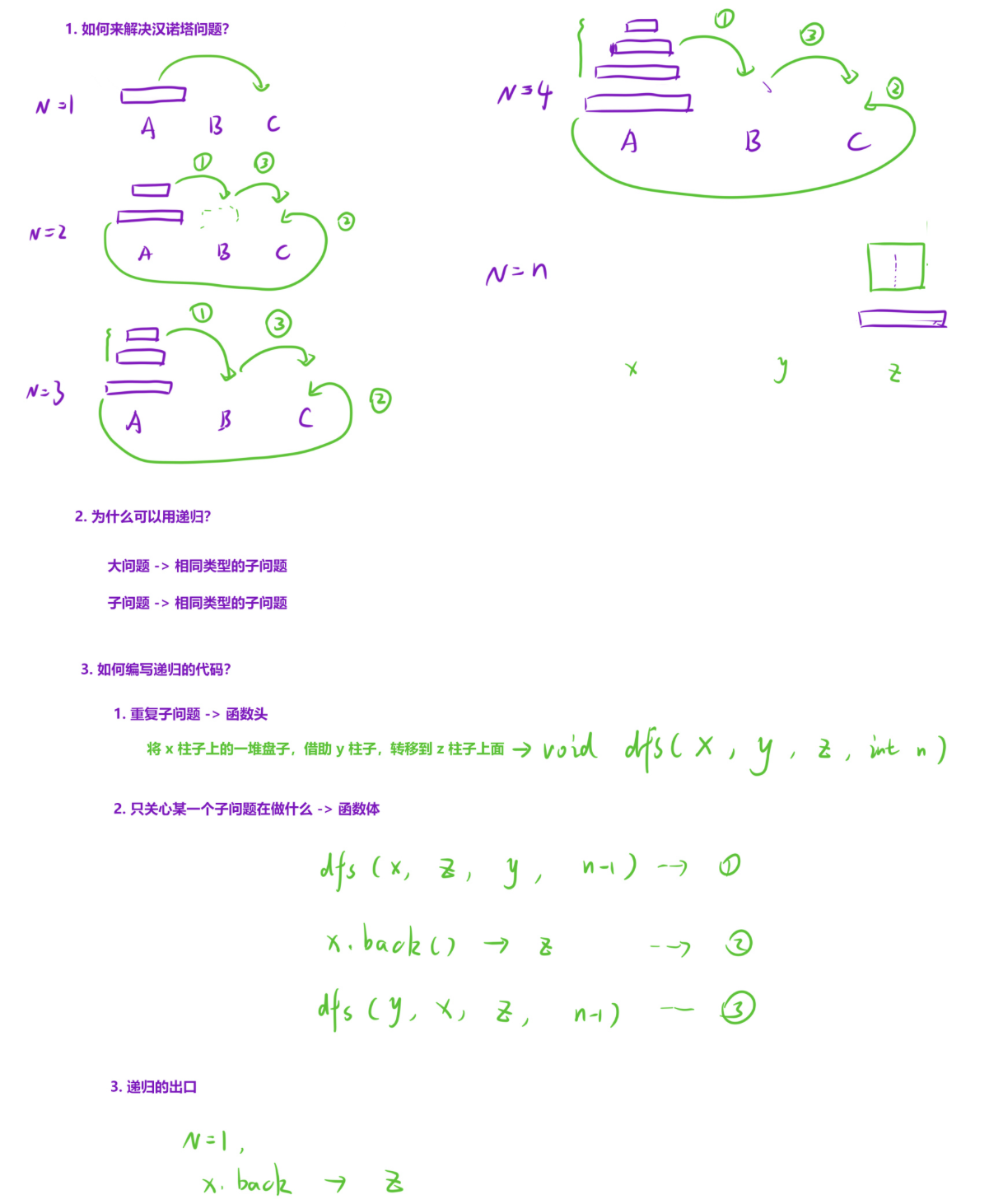
1) 设计函数头:先找到相同的子问题,明确函数的输入参数和功能(例如汉诺塔问题中,函数功能是"将x柱上的n个盘子,借助y柱,移到z柱")。
2) 编写函数体:只关心当前子问题的解决逻辑,直接调用递归函数处理更小的子问题。
3) 设置递归出口:当问题规模足够小时,直接解决问题,避免无限递归导致栈溢出。
二、搜索相关概念(DFS vs BFS)
- 核心概念区分
遍历:是一种访问所有节点的形式;搜索:是遍历的目的,用于寻找特定解。
深度优先遍历/深度优先搜索(DFS):沿着一条路径尽可能深地搜索,直到无法前进再回溯,通常用递归或栈实现。
广度优先遍历/广度优先搜索(BFS):按层遍历,先访问当前层所有节点,再访问下一层,通常用队列实现。
- 关系梳理
暴力枚举(穷举所有情况)的实现方式主要有两种:DFS 和 BFS,二者都是"搜索"的具体实现。
例如全排列问题,可以用DFS构建决策树,遍历所有可能的路径得到所有排列结果。
三、回溯与剪枝
- 回溯的本质
回溯算法的本质是深度优先搜索(DFS),是一种暴力搜索的优化形式。
它通过"尝试-失败-回退"的过程,遍历所有可能的解空间,找到满足条件的解。
例如迷宫问题中,遇到死路时回退到上一个节点,尝试其他路径,这就是回溯的过程。
- 剪枝的作用
剪枝是回溯算法的关键优化手段:在搜索过程中,提前判断某些路径不可能得到有效解,直接跳过这些路径,避免无意义的搜索,大幅提高效率。
例如在迷宫中,提前标记已经走过的路径,避免重复访问;或者根据问题规则,直接排除不符合条件的分支。
四、递归的定义与适用条件
在解决一个大规模的问题时,如果满足以下条件,就可以使用递归解决:
-
可拆分性:问题可以被划分为规模更小的子问题,且这些子问题与原问题的解决方法完全相同。
-
递推关系:当知道规模为 n-1 的子问题的解时,可以直接计算出规模为 n 的问题的解。
-
边界条件:存在一个"简单情况",当问题规模足够小时,可以直接求解,无需继续递归。
递归的一般求解过程
-
验证简单情况:先处理递归的终止条件(边界)。
-
假设与递推:假设较小规模的子问题已经解决,基于此解决当前问题。
注:上述过程可以通过数学归纳法来证明其正确性。
题目1:汉诺塔问题(LeetCode 面试题 08.06)
- 题目描述

- 核心递归思路
汉诺塔是递归的经典案例,核心思想是"分治":把大规模问题拆成小规模子问题,递归解决子问题后再处理原问题。
基础情况分析
当 n=1(只有1个盘子):直接把A柱上的盘子移到C柱即可。
当 n=2(2个盘子):需要借助B柱中转,共3步:把A柱上的小盘子(1号)移到B柱;把A柱上的大盘子(2号)移到C柱;把B柱上的小盘子(1号)移到C柱。
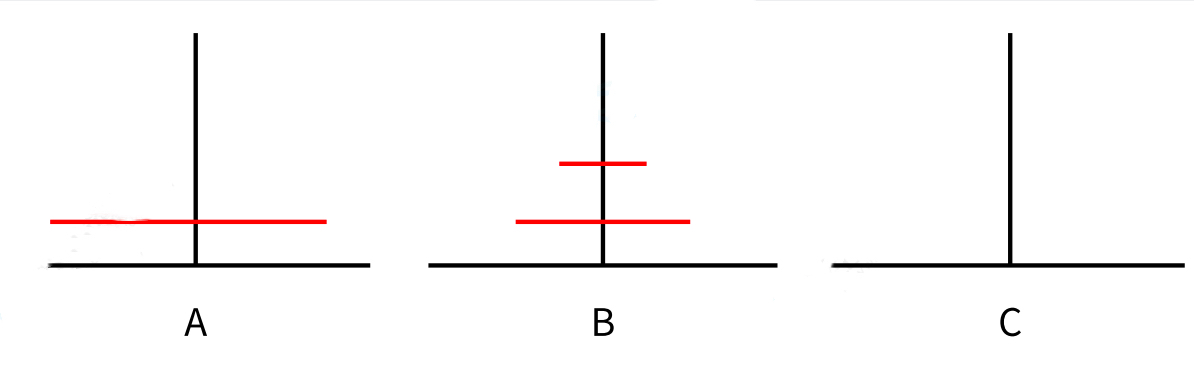
当 n>2(n个盘子):可以复用 n=2 的策略,将问题拆分为3步:把A柱上的n-1个盘子,借助C柱中转,全部移到B柱上;把A柱上剩下的最大的1个盘子,直接移到C柱上;把B柱上的n-1个盘子,借助A柱中转,全部移到C柱上。
关键逻辑:移动过程中,A柱上的最大盘子始终在最底部,不会被其他盘子压住,因此不会违反"大盘不压小盘"的规则。
- 递归函数设计与流程
函数定义 void dfs(vector<int>& a, vector<int>& b, vector<int>& c, int n)
功能:将 a 柱上的 n 个盘子,借助 b 柱中转,移动到 c 柱上。
参数:a(源柱)、b(辅助柱)、c(目标柱)、n(当前需要移动的盘子数量)。
递归流程
- 边界条件(n == 1):直接将 a 柱最顶端的盘子移到 c 柱:
cpp
if (n == 1) {
c.push_back(a.back());
a.pop_back();
return;
}-
第一步:移动n-1个盘子到辅助柱:将 a 柱上的 n-1 个盘子,借助 c 柱中转,移动到 b 柱:
dfs(a, c, b, n - 1); -
第二步:移动最大盘子到目标柱:将 a 柱上剩下的最大盘子直接移到 c 柱:
c.push_back(a.back());
a.pop_back(); -
第三步:移动n-1个盘子到目标柱:将 b 柱上的 n-1 个盘子,借助 a 柱中转,移动到 c 柱:
dfs(b, a, c, n - 1);
cpp
#include <vector>
using namespace std;
class Solution {
public:
void hanota(vector<int>& a, vector<int>& b, vector<int>& c) {
// 调用递归函数,将a柱的所有盘子(a.size()个)借助b柱移到c柱
dfs(a, b, c, a.size());
}
private:
// 递归函数:将a柱的n个盘子,借助b柱,移动到c柱
void dfs(vector<int>& a, vector<int>& b, vector<int>& c, int n) {
// 边界条件:只有1个盘子时,直接移动
if (n == 1) {
c.push_back(a.back());
a.pop_back();
return;
}
// 1. 把a柱上的n-1个盘子,借助c柱,移到b柱
dfs(a, c, b, n - 1);
// 2. 把a柱剩下的最大盘子,直接移到c柱
c.push_back(a.back());
a.pop_back();
// 3. 把b柱上的n-1个盘子,借助a柱,移到c柱
dfs(b, a, c, n - 1);
}
};- 关键知识点总结
1) 递归的核心思想:把复杂的大问题,拆成和原问题解法相同、规模更小的子问题,通过"递推"+"回归"解决。
2) 汉诺塔的递推公式:移动n个盘子需要的步数为 2ⁿ - 1(例如n=3时需要7步,n=14时需要16383步)。
3) 栈的特性:用 vector 模拟栈,back() 取栈顶元素,pop_back() 弹出栈顶元素,push_back() 压入栈顶元素,完全符合题目中"顶端移动"的规则。
4) 参数的传递逻辑:递归调用时,辅助柱和目标柱会动态切换,以实现"中转"的效果,这是汉诺塔递归实现的关键。
题目2:合并两个有序链表(LeetCode 21)
- 题目描述
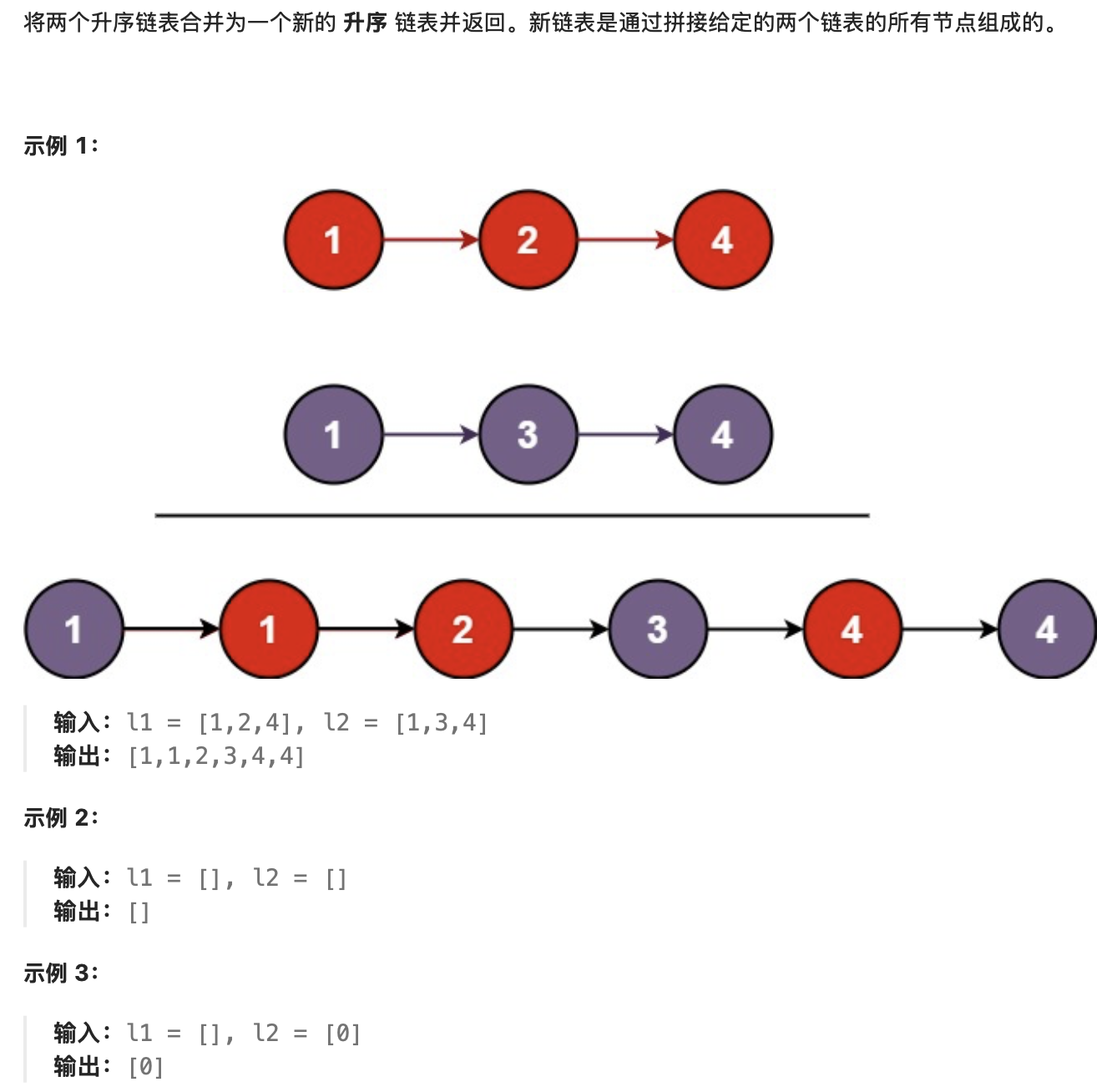
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
- 递归解法核心知识点
1) 递归函数的含义
递归函数的定义是:传入两个链表的头结点,返回合并后链表的头结点。
它的作用是:帮你把两个有序链表合并成一个有序链表,并返回合并后的头。
2) 算法核心思路
递归的核心是分而治之,每次解决"当前一步"的问题,剩下的交给递归处理:
-
选头结点:比较两个链表的头结点值,选择值较小的节点,作为合并后链表的当前头结点。
-
递归处理剩余部分:将"值较小节点的下一个节点"和"另一个链表的头结点"作为新的参数,继续递归合并。
-
拼接结果:将步骤2中递归返回的结果,接到步骤1中选出的头结点后面。
-
返回头结点:将当前选出的头结点作为结果返回,供上一层调用。
3) 递归出口(终止条件)
当某一个链表为空(nullptr)时,直接返回另一个链表。
若 l1 == nullptr,说明 l1 已经遍历完,直接返回 l2 剩余部分即可。
若 l2 == nullptr,同理,直接返回 l1 剩余部分。
4) 关键注意事项
链表题必须画图理解指针操作,明确:谁是当前节点?谁是下一个节点?递归返回的结果要接在谁的后面?
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2)
{
// 递归出口:某一个链表为空,直接返回另一个
if(l1 == nullptr) return l2;
if(l2 == nullptr) return l1;
// 选值较小的节点作为当前头结点
if(l1->val <= l2->val)
{
// 递归合并 l1->next 和 l2,结果接在 l1 后面
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
else
{
// 递归合并 l1 和 l2->next,结果接在 l2 后面
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
}
};- 知识点拓展
1) 时间复杂度
递归的次数等于两个链表的总节点数,每次递归只做一次比较和一次指针赋值,因此时间复杂度为:O(n + m),其中 n、m 分别为两个链表的长度。
2) 空间复杂度
递归调用栈的深度等于两个链表的总节点数,因此空间复杂度为:O(n + m)(递归栈开销)。
3) 易错点总结
空指针判断:必须先判断链表是否为空,否则访问 l1->val 会导致程序崩溃。
指针赋值方向:l1->next = mergeTwoLists(...) 是关键,不要搞反两个链表的参数顺序。
非递减顺序:题目中是"非递减",因此判断条件用 <= 即可,无需严格 <。
题目3:反转链表(LeetCode 206)
- 题目描述
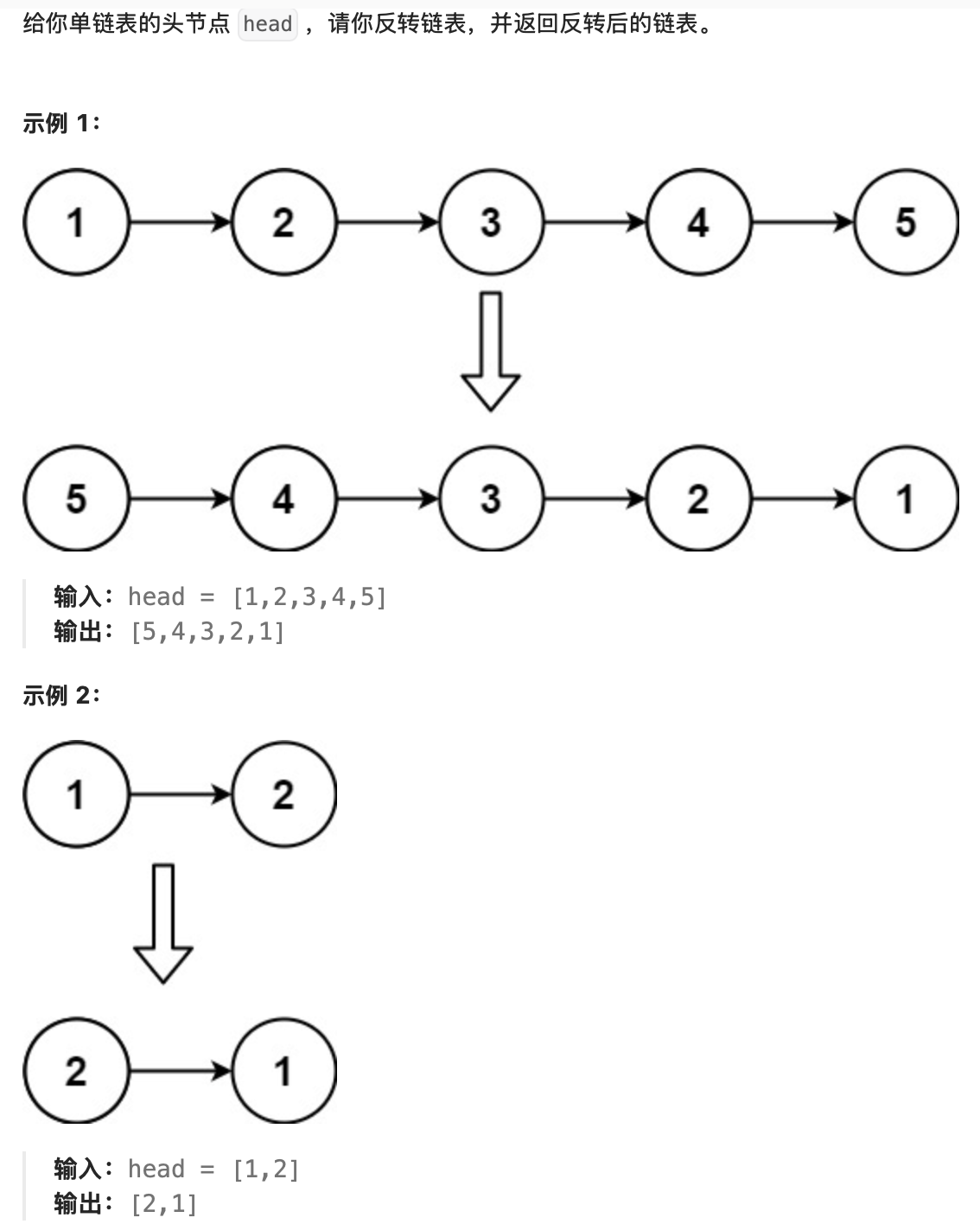
示例 3:
输入:head = []
输出:[]提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
- 递归解法核心知识点
1) 递归函数的含义
递归函数的作用:传入一个链表的头指针,返回反转后链表的头结点。
2) 算法核心思路
递归的本质是"分而治之",核心步骤分为三步:
-
递归处理后半段:先把当前结点之后的链表反转,得到反转后链表的头结点 newHead。
-
调整指针指向:将当前结点的下一个结点的 next 指向当前结点(实现反转)。
-
处理尾结点:将当前结点的 next 置为 nullptr,避免链表出现环。
-
返回结果:返回反转后链表的头结点 newHead。
3) 递归出口(终止条件)
当链表为空 head == nullptr,或链表只有一个结点 head->next == nullptr 时,无需反转,直接返回 head 即可。
4) 关键注意事项
链表题必须画图理解指针操作,明确每个结点的 next 指向变化。
必须将原链表的头结点(反转后的尾结点)的 next 置为 nullptr,否则会形成环形链表。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* reverseList(ListNode* head)
{
// 递归出口:链表为空或只有一个结点,直接返回
if (head == nullptr || head->next == nullptr)
return head;
// 1. 递归处理 head->next 之后的链表,得到反转后的头结点
ListNode* newHead = reverseList(head->next);
// 2. 调整指针:让 head->next 的 next 指向 head
head->next->next = head;
// 3. 处理尾结点:将当前 head 的 next 置为 nullptr,避免成环
head->next = nullptr;
// 4. 返回反转后链表的头结点
return newHead;
}
};- 知识点拓展
1) 复杂度分析
时间复杂度:O(n),每个结点仅被访问一次,其中 n 为链表长度。
空间复杂度:O(n),递归调用栈的深度等于链表长度,最坏情况下(链表长度为 n)需要 n 层栈空间。
2) 易错点总结
-
指针指向错误:忘记设置 head->next = nullptr,会导致反转后的链表形成环,程序运行时死循环。
-
递归出口缺失:没有处理链表为空的情况,会导致空指针访问异常。
-
返回值错误:误将 head 作为返回值,而不是递归返回的 newHead,导致反转后的链表头结点丢失。
-
迭代解法补充(对比学习)
如果需要空间复杂度为 O(1) 的解法,可以使用迭代法:
cpp
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr; // 前一个结点
ListNode* curr = head; // 当前结点
while (curr != nullptr) {
ListNode* nextTemp = curr->next; // 保存下一个结点
curr->next = prev; // 反转指针
prev = curr; // prev 后移
curr = nextTemp; // curr 后移
}
return prev;
}
};时间复杂度:O(n); 空间复杂度:O(1),仅使用常数额外空间。
题目4:两两交换链表中的节点(LeetCode 24)
- 题目描述
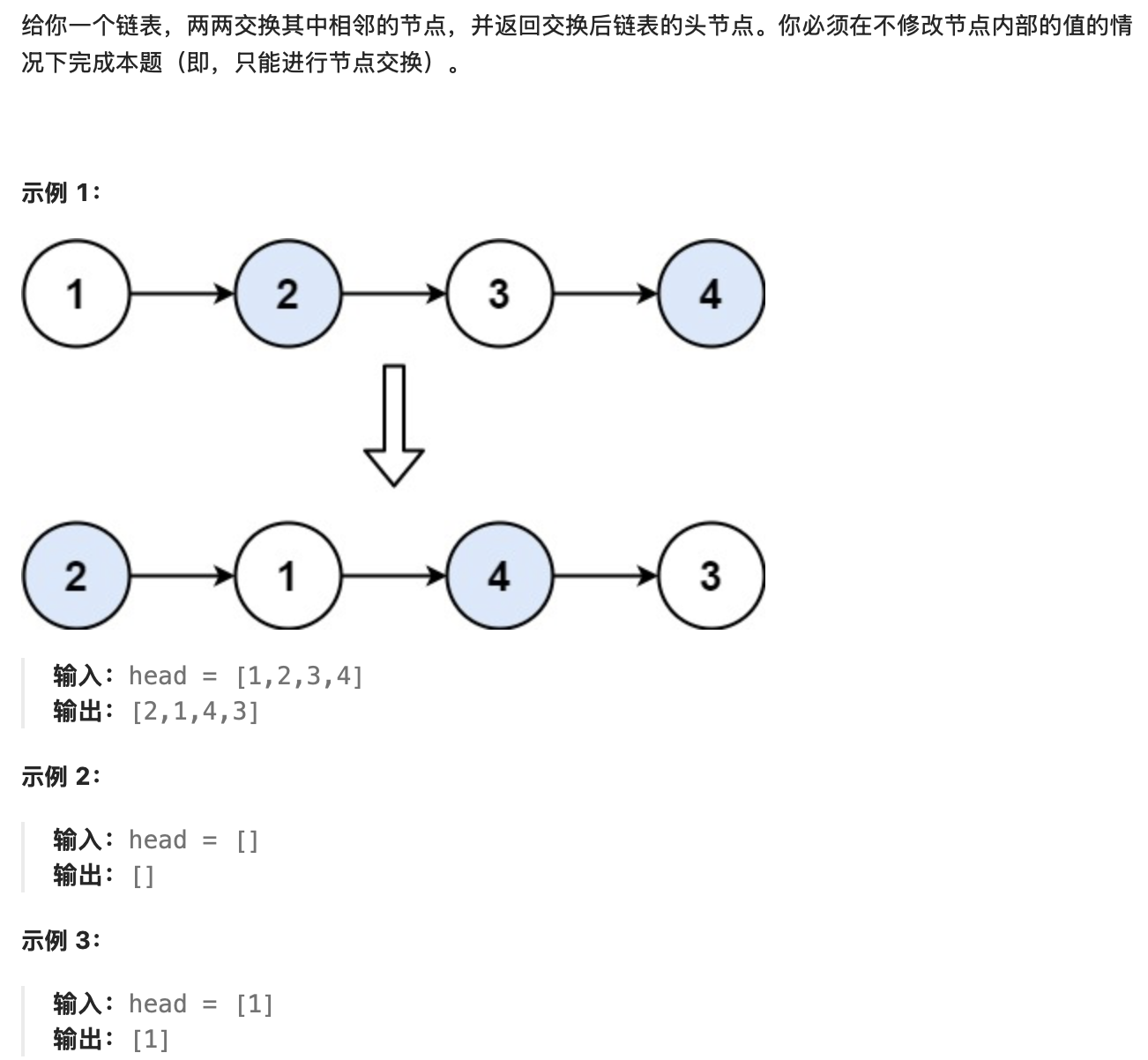
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
- 递归解法核心解析
1) 递归函数的含义
递归函数的作用:传入一个链表的头指针,返回两两交换完成后的链表头结点。
2) 算法核心思路
递归的本质是分而治之,核心步骤分为三步:
-
递归处理后半段:先处理从第三个节点开始的子链表,返回其交换后的头结点 tmp。
-
交换当前两个节点:
原顺序:head → head->next → 子链表
交换后:head->next → head → tmp
- 返回新头结点:head->next 会成为当前层的新头结点,将其返回给上一层。
3) 递归出口(终止条件)
当链表为空 head == nullptr 时,直接返回 nullptr。
当链表只有一个节点 head->next == nullptr 时,无需交换,直接返回 head。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution
{
public:
ListNode* swapPairs(ListNode* head)
{
// 递归出口:链表为空或只有一个节点,直接返回
if (head == nullptr || head->next == nullptr)
return head;
// 1. 递归处理后续子链表(从第3个节点开始)
auto tmp = swapPairs(head->next->next);
// 2. 保存当前层交换后的新头结点(原第二个节点)
auto ret = head->next;
// 3. 调整指针:将当前节点的next指向tmp,完成交换
head->next->next = head; // 原第二个节点的next指向原第一个节点
head->next = tmp; // 原第一个节点的next指向递归返回的子链表头
// 4. 返回当前层交换后的新头结点
return ret;
}
};- 关键细节与易错点
1) 必须画图理解指针操作:链表题的核心是指针的指向变化,画图能帮你清晰看到每个步骤的节点连接关系,避免逻辑混乱。
2) 交换顺序不能错:必须先处理子链表,再调整当前节点的指针,否则会丢失后续节点的引用。
3) 返回值易错:ret(原第二个节点)才是当前层交换后的新头结点,不能直接返回 head。
4) 边界处理:注意空链表、单节点链表的情况,避免空指针访问异常。
- 复杂度分析
时间复杂度:O(n),每个节点仅被访问一次,其中 n 为链表长度。
空间复杂度:O(n),递归调用栈的深度为链表长度的一半,最坏情况下需要 n/2 层栈空间。
- 拓展:迭代解法(空间复杂度O(1))
如果需要常数级空间复杂度,可以使用迭代法:
cpp
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode dummy(0);
dummy.next = head;
ListNode* prev = &dummy;
while (prev->next != nullptr && prev->next->next != nullptr) {
ListNode* first = prev->next;
ListNode* second = prev->next->next;
// 交换节点
first->next = second->next;
second->next = first;
prev->next = second;
// 移动指针
prev = first;
}
return dummy.next;
}
};题目5:Pow(x, n)(LeetCode 50)
- 题目描述

- 递归快速幂解法核心解析
1) 核心思想:分治法(二分法)

cpp
class Solution
{
public:
double myPow(double x, int n)
{
// 处理负指数:注意n为-2^31时,直接取反会溢出,需转成long long
return n < 0 ? 1.0 / pow(x, -(long long)n) : pow(x, (long long)n);
}
private:
// 递归快速幂,n为非负整数
double pow(double x, long long n)
{
// 递归出口:n=0时返回1
if (n == 0) return 1.0;
// 分治:先计算x^(n/2)
double tmp = pow(x, n / 2);
// 根据n的奇偶性返回结果
return n % 2 == 0 ? tmp * tmp : tmp * tmp * x;
}
};- 关键细节与易错点
1) 整数溢出问题:int 范围为 -2^{31} ~ 2^{31}-1,当 n = -2^31 时,直接写 -n 会溢出,必须先转成 long long 再取反。
2) 负指数处理:x^{-n} = 1 / x^n,不能直接在递归函数中处理负指数,否则 n/2 向下取整会出错。
3) 浮点数精度:题目允许一定精度误差,使用 double 计算即可满足要求。
4) 递归效率:递归深度为 O(log n),远优于暴力法的 O(n),时间复杂度为 O(log n),空间复杂度为 O(log n)(递归栈开销)。
- 复杂度分析
时间复杂度:O(log n),每次递归/迭代将指数折半,共需 log n 次计算。
空间复杂度:递归法为 O(log n)(递归栈),迭代法为 O(1)。
- 拓展:迭代快速幂(空间复杂度O(1))
如果需要常数级空间复杂度,可以用迭代法实现:
cpp
class Solution {
public:
double myPow(double x, int n) {
long long N = n;
if (N < 0) {
x = 1 / x;
N = -N;
}
double res = 1.0;
while (N > 0) {
if (N % 2 == 1) {
res *= x;
}
x *= x;
N /= 2;
}
return res;
}
};