原文:A small object detection method based on multidimensional collaborative attention and feature fusion
原文链接:https://doi.org/10.1117/12.3092531
摘要
为了解决像素尺度小和特征信息少而导致小目标检测困难的问题,本文提出了一种基于多维协同注意力和特征融合的小目标检测方法。首先,提出了多尺度特征融合模块,通过融合目标的细节信息与语义信息,为小目标检测提供更精确的特征表示。进而,提出了多维协同注意力模块,通过捕捉通道、高度和宽度之间特征的相互作用,能够更好地引导模型捕捉小目标的细节信息和上下文信息。最后,提出了层级特征融合模块,将骨干网络提取的特征与多维协同注意力特征进行逐层融合,强化了特征图中的目标关键信息,进一步增强模型对小目标的检测能力。在VisDrone-DET2019和HIT-UAV数据集上的实验结果表明,本文方法在mAP50指标上分别达到了54.8%和80.8%,与基线相比,mAP50指标提高了4.5%和5.2%。
本文方法
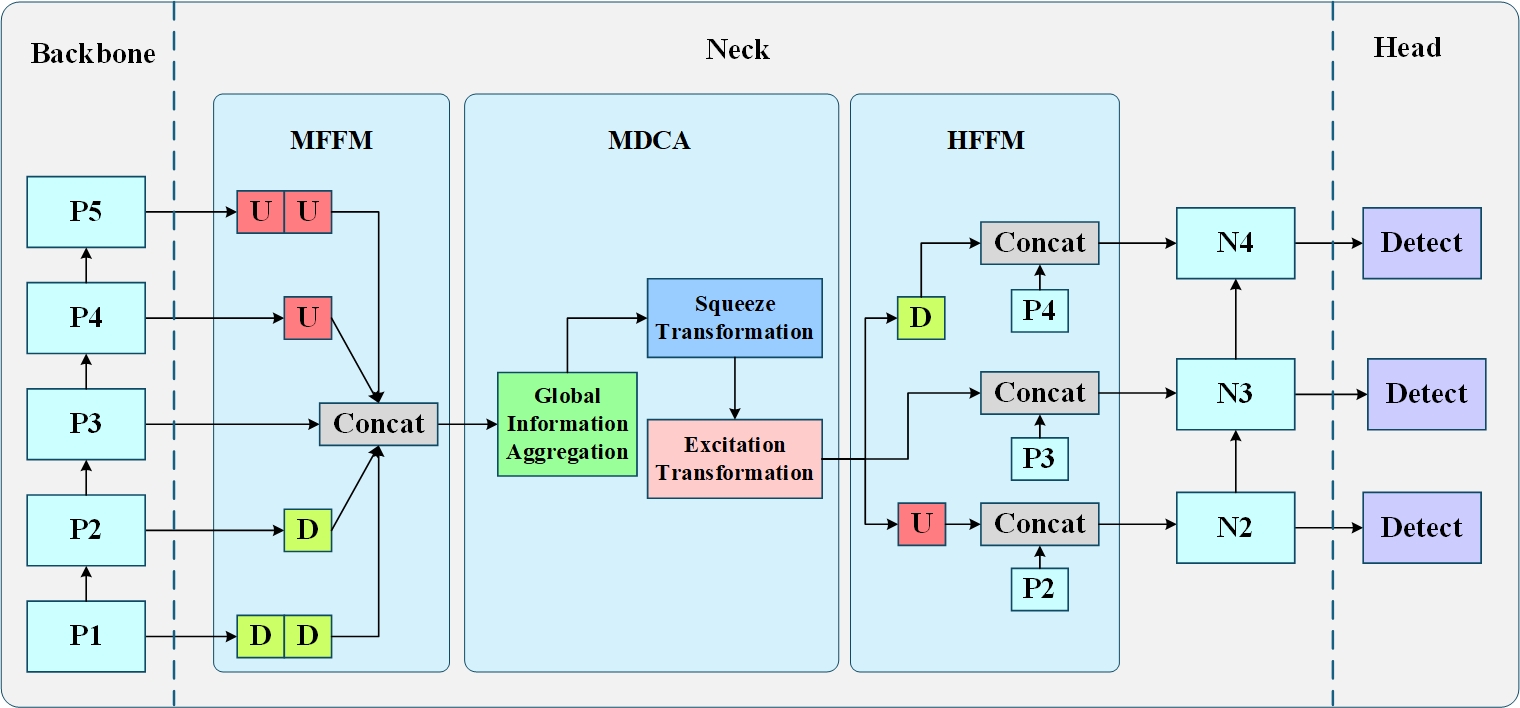
为了提高小物体检测的性能,本文提出了一种基于多维协作注意力和特征融合的小物体检测方法,如下图所示。首先,主干网络是在YOLOv12主干的基础上构建的,它被分为五个阶段,从中提取的特征图表示为集合{P1, P2, P3, P4, P5}。其次,在颈部结构中,利用多尺度特征融合模块对特征进行上采样(U)或下采样(D)操作,同时使特征匹配P3的维度。然后,通过拼接将这些特征融合。随后,多维协作注意力充分提取通道、高度和宽度三个维度之间的相关特征。通过对多维协作注意力的输出特征进行上采样或下采样,生成三尺度特征,并在层级特征融合中将每个尺度的特征与集合{P2, P3, P4}中的特定特征拼接,以生成语义特征{N2, N3, N4},分别对应小尺度、中尺度和大尺度的检测。最后,采用YOLOv12的检测头对图像中的小物体进行检测。
多维协同注意力机制
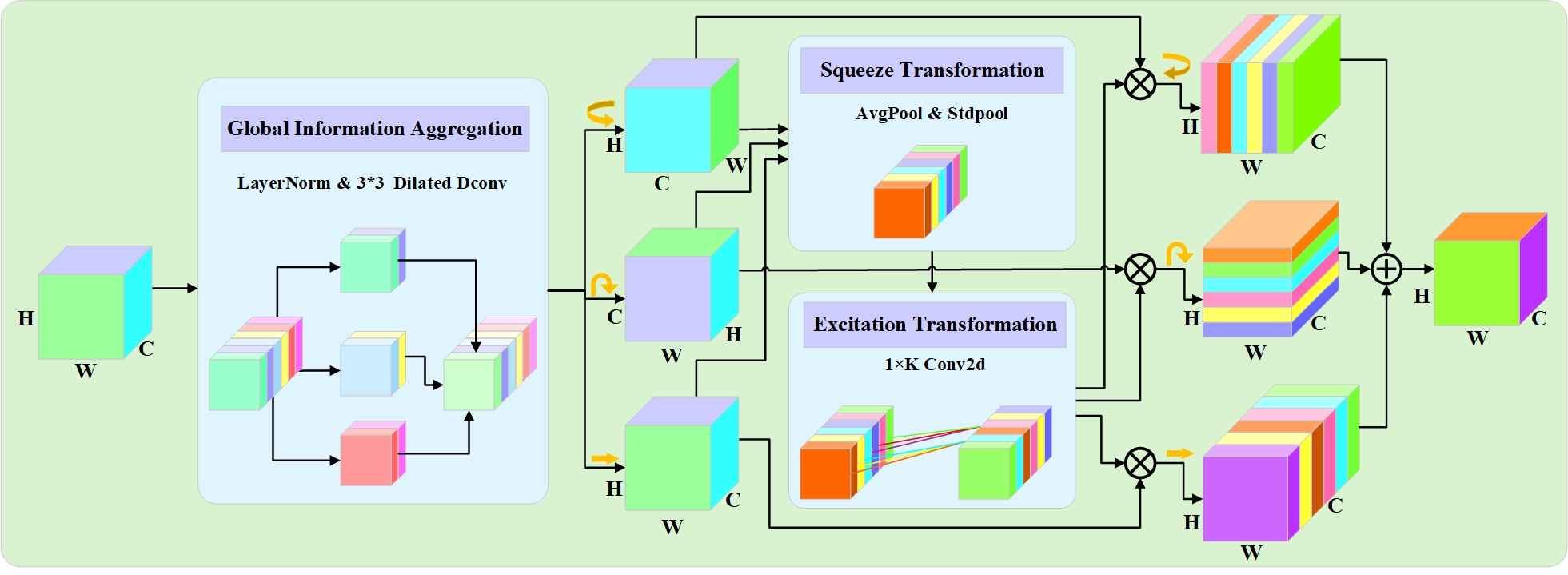
多维协同注意力采用三分支架构,使模型能够以低计算量学习三个维度(通道、高度和宽度)的注意力权重,如下图所示。首先,全局信息聚合将深度特征X分解为多个通道组,并为每个组分别计算通道注意力。随后,全局信息聚合模块生成的特征被转换以形成三个并行分支。前两个分支用于捕捉沿空间维度W和H的特征相互依赖关系,而最后一个分支主要用于捕捉通道C之间的交互。最后,对每个分支分别应用挤压与激励变换,并将这些分支的特征融合在一起。
实验
将本文方法与YOLOv5、YOLOv8和YOLOv10相比,本文方法在检测小目标时表现更为出色,成功检测出了更多的小目标,有效地改善了小目标漏检的情况。
