目标
我想尝试让AI帮我整理游戏开发资料,这样未来我有什么需求时可以让他快速获取本地的资料帮助我分析并给出结论(比如搜索某一技术相关的所有文档并总结)。当前最大的游戏开发资料的来源肯定是GDC了(网址:https://gdcvault.com/browse/)所以我想让它先帮我抓取上面的资料,并生成一个页面我可以本地访问浏览。
经历
不过尝试后发现,这件事并不如我想象中那样容易。
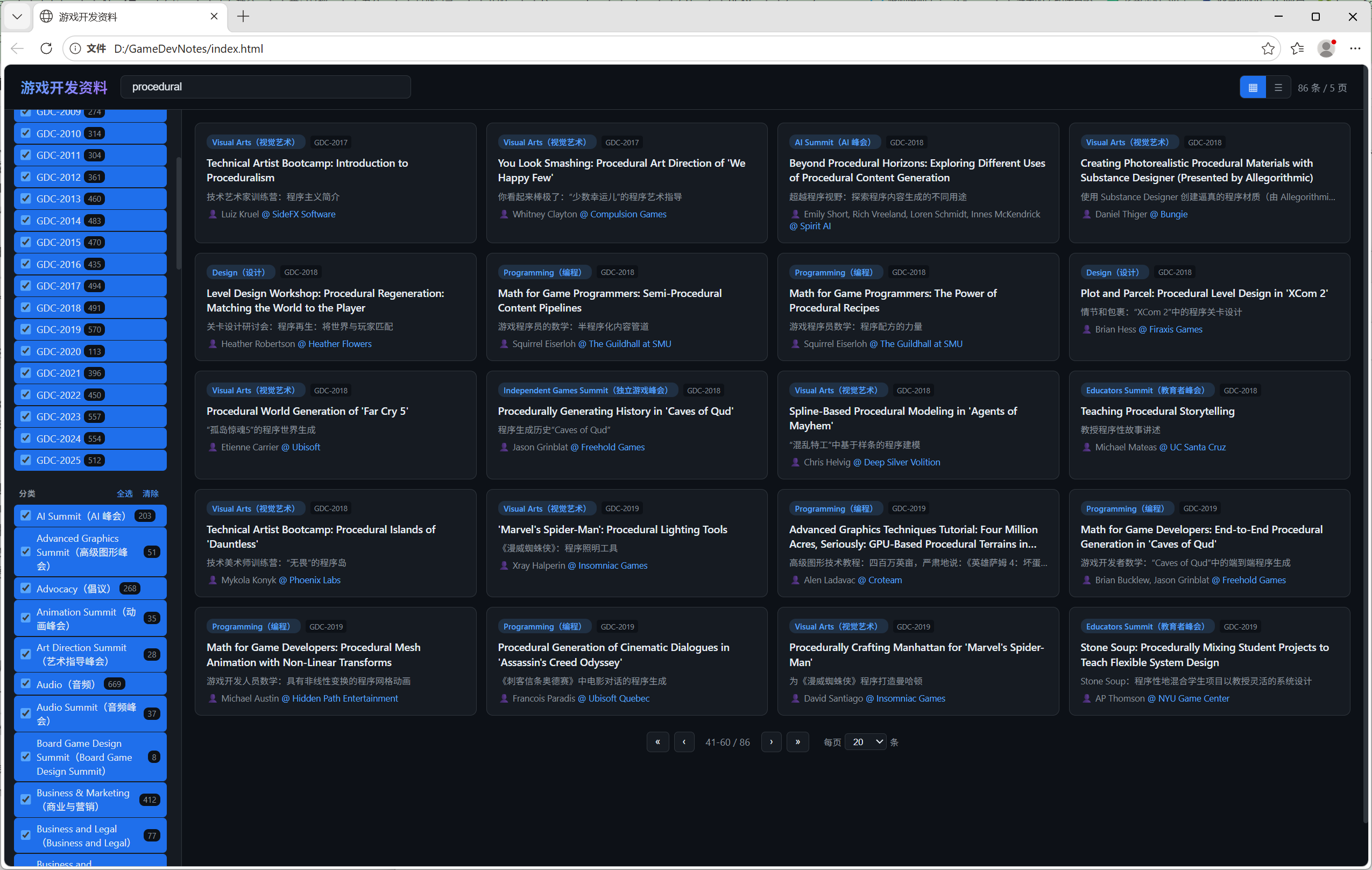
第一次我尝试时,我直接给了AI资料地址,告诉它抓取上面所有分享的标题下来,生成一个页面。结果,虽然它生成了看似不错的界面:
但我检查后发现,分享的数目少了非常多!
发现这个情况后,我尝试让AI去修复这个问题,但总是解决不了,因为我对它生成的产物完全不了解,也不能帮他去找问题。
想了想,我还是放弃了这个工程。新开了个工程,从零开始一步一步地监督它做事。我也将工程上传了GIT:https://gitcode.com/u013412391/GameDevNotes
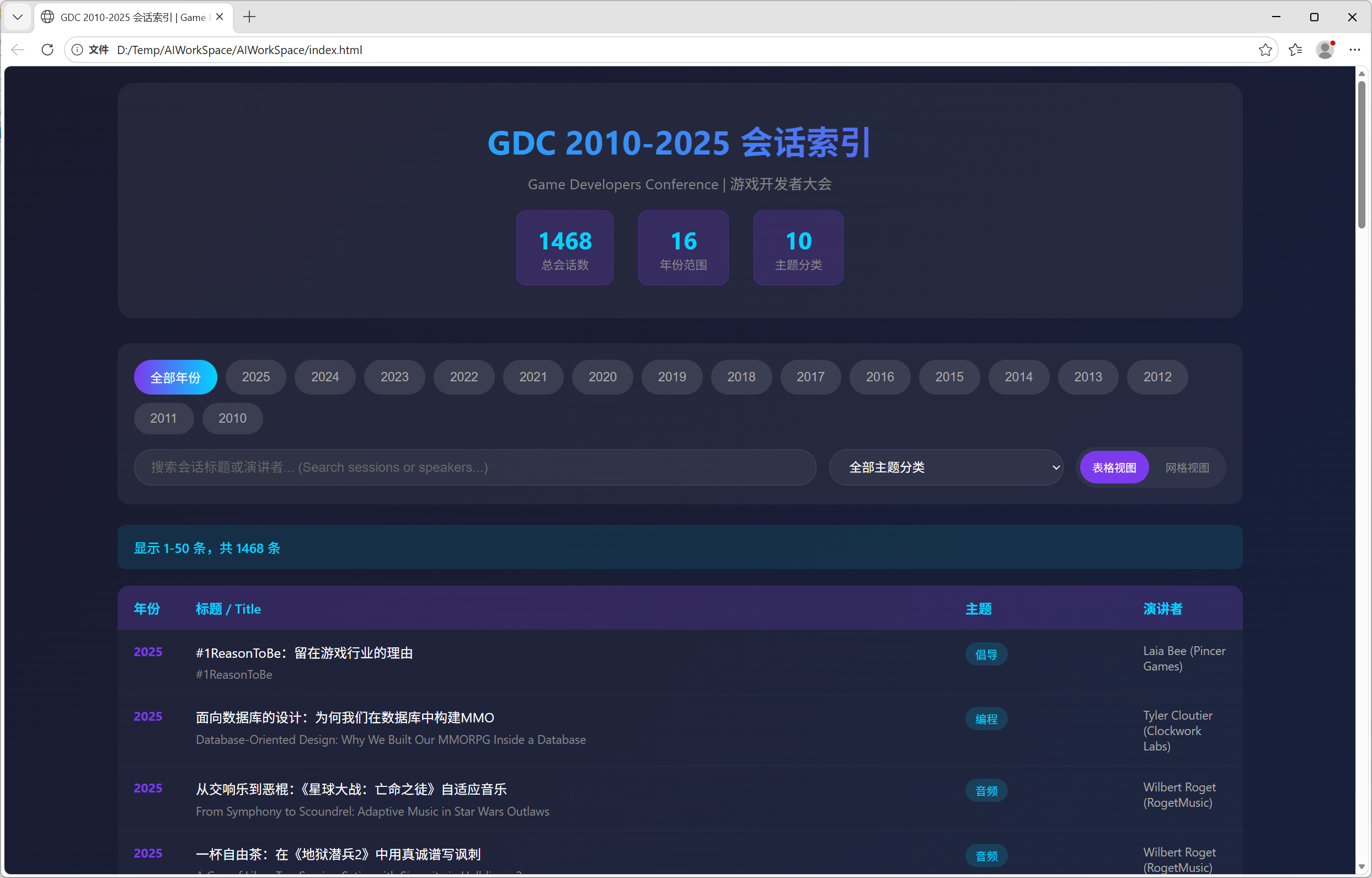
最后成功达到预期。右上角页面可以看到现在是8605条,相对于之前的一版1468已经完整很多(实际发现有些极个别的情况没拿到,但是那些分享也点不开,这种情况应该小于1%)
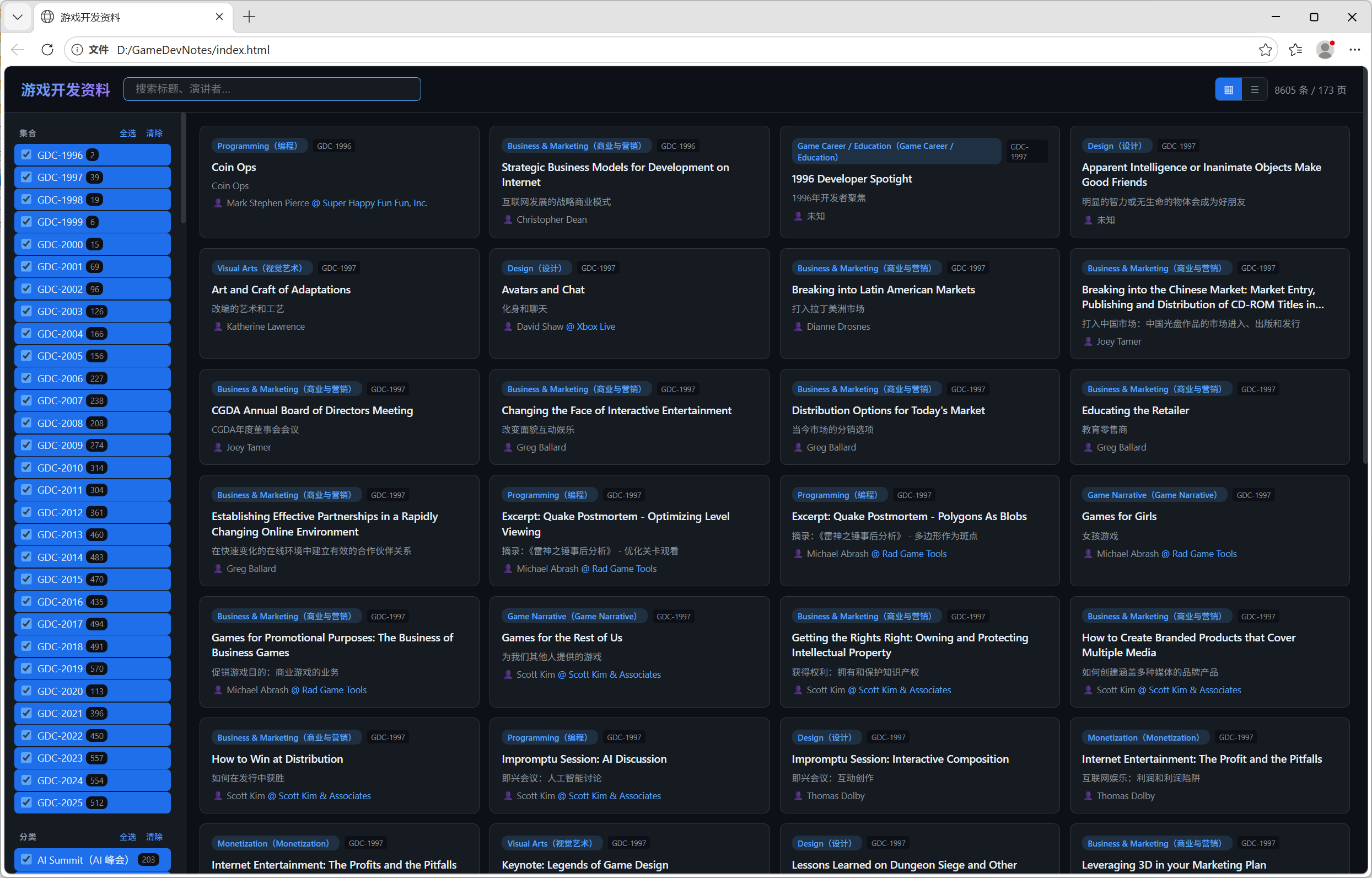
所以我想记录下我从中得到的经验
经验
1) 让AI"给我做个工具处理数据"而不是"给我处理数据"
特别是批处理的时候,最好让AI去实现这个处理数据的逻辑,你来实际触发,而非直接让AI去处理。
我在第一次失败的项目中,就是直接让AI抓取页面上的数据,这样不仅时间很慢,还消耗了很多token,因为他在处理数据的时候也 "看" 了这些数据。虽然这种方式它可以顺便也翻译一下,但是我预期这应该是两步:
- 抓取数据
- 执行翻译
而这两步只要有工具去批量执行就好,并不需要AI去看实际的内容的。
当然,有些情况AI也是会自己写一个工具然后批量执行并且不看内容的,但是视它对你的指示的理解,有可能真的每个内容都会看的。而如果他只是生成一个工具,随后你自己触发,那AI就绝无可能会在这期间看到内容了,这样又快又省token。
而这里,就牵扯到分解
2)分解成可验证的最小步骤
完成目标后,回过头来看,我实际将任务分成了下面几个步骤:
create_gdc_notes.py负责抓取GDC上的分享,每次分享存到一个json文件里。保证数目上一个不漏,但是细节数据允许漏,比如我这里遇到一个严重的问题就是标题会由于太长而被截断。fetch_gdc_note_details负责对一次GDC分享获取细节,即进入这个GDC分享的链接,获取完整标题,以及简介等。batch_fetch_gdc_note_details.py负责批量运行上述脚本translate_notes.py负责对一个GDC的json文件翻译特定的字段,我这里只翻译了标题。batch_translate_notes.py负责批量运行上述脚本generate_note_index.py负责生成最终html页面
我觉得分解的标准是 "是否可验证" ,又或者说分解就是为了能阶段性验证 。
这样,一步一步踏踏实实走,出了问题的话也能在一个较小的范围内去调查,否则直到最后才验证的话,那么内部的结构就相当于一个黑盒,只能AI自己去修,你无法发挥自己的智慧去协助解决问题。
3)验证时自己的知识会起到作用
谈到验证,我发现自己的知识在验证时会发挥很大的作用。
当自己对这块功能了解地越多 时,就越能将其分解为更小的可验证步骤,这样开发过程就会更稳。
我这次其实比较惊险的是最后生成html页面的逻辑部分,因为我基本对html的界面开发不了解。所以我给出的指令是直接生成,所幸AI在这方面也比较有经验,直接生成了正确的界面。但后来我发现数据量变大时界面会很卡,所以我想让他加一个分页的功能,结果它开发后界面直接看不到信息了,让他自己去修,自己想了很久也没有修好。最后,我只能让他回退,将大语言模型从 MiniMax 换成了 Claude-Opus-4.6 后重新实现分页逻辑,才成功。这里就纯依赖AI了,否则出了问题我是没有能力去调试出来的。
而对于其他部分,我认为自己的知识有帮助到AI去选择了正确的道路,我让AI总结了细节:
一些实现细节(AI总结)
给AI发消息
目前的开发已经告一段落了,我想总结下开发过程中遇到的一些问题,你来简短的介绍下。我比较印象深刻的是这几个:
- 结合 create_gdc_notes 的实际逻辑,谈谈是怎么获取到所有GDC分享,以及基本信息的,其中有哪些坑。
- 翻译是怎么实现的?有其他哪些方式可选,而当前这种方式最大的优点是什么
- 界面是如何实现的?有其他哪些方式可选,而当前这种方式最大的优点是什么
其他的你觉得可以讲一下的技术点也可以补充下
1. 数据抓取:怎么获取所有 GDC 分享及基本信息
数据源 :GDC Vault 的列表页,URL 格式为 https://gdcvault.com/browse/gdc-{年份后两位},覆盖 1996--2025 共 30 年。
核心流程 (create_gdc_notes.py):
- 请求列表页 HTML,解析所有
li.featured元素 - 从每个
li中提取:标题(<strong>)、分类(span.track_name)、演讲者/公司(<em>by</em>后的文本,用正则分离括号内的公司名)、媒体类型(div.media_type_image的 class)、链接(含会员专属的onclick解析) - 以标题为 key 做去重合并------同一演讲可能有 video 和 slides 两个条目,合并为一条 note 的多个
related_links
遇到的坑:
- 标题截断问题 :列表页的
<strong>显示的标题经常被截断(以...结尾或括号不配对)。解决方案是两遍策略 :第一遍用<strong>文本做 key 保证去重稳定,第二遍从同一li的<a class="session_item">的title属性取完整标题来补全。如果a.title仍然不够完整,则标记is_title_truncated=True,后续通过fetch_gdc_note_details.py访问详情页获取完整标题。 - 会员专属链接提取 :会员内容的
<a href="#">,真正的 URL 藏在onclick的 JS 代码里(如window.location='/play/...'),需要用正则从 onclick 中抠出来。 - 年份编码 :URL 用的是两位年份后缀,1996 年对应
gdc-96而非gdc-1996,2025 对应gdc-25。脚本里通过year - 2000或year - 1900来计算。 - 详情页结构不统一 :不同年份的详情页 HTML 结构差异很大,Overview 可能在
dl.overview-section、div.description、或meta[og:description]里,需要逐层降级查找。
2. 翻译:怎么实现的,有哪些替代方案
当前方案 :调用 Google Translate 的免费 API(translate.googleapis.com/translate_a/single),用 urllib 直接请求,无需 API Key。
关键技巧------编号前缀批量翻译 :把多条文本拼成 [[1]]文本1[[2]]文本2[[3]]文本3 的格式一次性发送,翻译返回后再用 [[N]] 标记拆分回去。这样 50 条标题只需 1 次 HTTP 请求,8605 条标题大约 172 次请求就翻完了。
之所以用 [[N]] 编号前缀而不是换行分隔,是因为 Google Translate 对换行的处理不稳定------有时候会合并或拆分行,导致输入输出的条数对不上,无法一一匹配。编号前缀在翻译后仍然保留,解析非常可靠。
可选替代方案:
- Google Cloud Translation API(付费):有正式的批量翻译接口,质量稳定,但需要付费和配置 API Key
- DeepL API:翻译质量更高,尤其在长文本和技术术语上,但免费额度有限(每月 50 万字符)
- 大语言模型(如 GPT/Claude):翻译质量最好,能理解游戏开发专业术语的上下文,但成本高、速度慢
- 本地模型(如 Argos Translate):离线运行无费用,但质量不如在线服务
当前方案最大的优点 :零成本 + 零配置 + 批量高效 。不需要申请任何 API Key,不需要安装额外依赖(只用标准库 urllib),且通过编号前缀技巧实现了高效批量翻译。对于标题级别的短文本翻译,质量完全够用。
3. 界面:怎么实现的,有哪些替代方案
当前方案 :generate_note_index.py 扫描所有 note_info.json,把 8605 条数据序列化为 JSON 直接嵌入到一个自包含的 index.html 中(HTML_TEMPLATE.replace('__NOTES_DATA__', json.dumps(...)))。页面用纯原生 JS,无任何框架依赖。
功能:暗色主题、网格/列表双视图、左侧栏按集合(年份)和分类筛选、搜索(标题/中文标题/演讲者/公司)、详情侧滑面板、分页(20/50/100/200 条/页)。
可选替代方案:
- 前后端分离(React/Vue + API 服务器):更灵活、支持增量加载,但需要启动服务器,部署复杂
- 静态站点生成器(Hugo/Jekyll/VitePress):有现成主题和搜索插件,但需要学习框架约定,且 8600+ 页面的构建速度可能很慢
- 数据库 + Web 框架(Flask/Django):支持复杂查询和大数据量,但又是一个要维护的服务
- Electron/Tauri 桌面应用:体验好,但打包分发成本高
当前方案最大的优点 :双击即用,零依赖 。生成的 index.html 是一个完全自包含的文件,不需要任何服务器、不需要安装任何东西、不需要网络连接,双击就能在浏览器里打开使用。可以直接扔到 U 盘、发给别人、放在任何地方。这对于一个个人资料收集工具来说,是最理想的分发方式。
4. 其他值得一提的技术点
- 全自动化流水线 :
fetch_all_gdc.bat一键从 2025 倒序到 1996,对每个年份依次执行「抓取列表 → 补全截断标题 → 增量翻译」三步。跑一次就把 30 年的数据全部拉齐。 - 增量设计 :翻译脚本的
--incremental参数只翻译还没有title_cn的条目,避免重复调用 API。详情获取也只处理is_title_truncated=True的条目。 - 标题截断检测 (
utils.py):用两个简单规则判断------末尾是...或左括号比右括号多。看似简单但覆盖了列表页截断的绝大多数情况。 - Python 模板中的引号陷阱 :
generate_note_index.py的 HTML 模板是 Python 的三引号字符串,里面嵌套了 JS 代码,JS 代码中又有 HTML 字符串拼接。三层嵌套的引号冲突是这次开发中反复踩的坑,最终的解决方案是:分页控件的 HTML 用字符串拼接(+连接)而非模板字面量,避免了引号嵌套的问题。
日志已有,不需要再追加了------这次只是口头总结,没有修改任何文件。
总结
总的来说,这次用AI时感受上它就像是你的一个员工,你是它的leader,这个员工不笨,反而懂得很多,但就是懂得太多了使得你的一些描述在缺少上下文上它可能会有很多理解偏差,所以你要一步步地引导它,让他一拍脑袋说 "哦~原来您是这意思啊!我这就去做!",它的优点就是绝对听你的话,就算你是错的方向也会尝试一下,可以说十分 "忠诚"。所以最重要的建议就是 "把任务分解成可验证的最小步骤",这样保证他能时刻走在你预期的道路上。
目前的成果可以看这个GIT:https://gitcode.com/u013412391/GameDevNotes,脚本全部是AI写的
直接点 index.html 就可以打开页面,目前可以直接通过各种条件筛选,或者直接搜索:(当然目前来看和GDC网站上直接搜索差不多,但是速度比他快且是离线的,未来是准备放更多的信息以及除了GDC之外的其他的公开资源的)