介绍
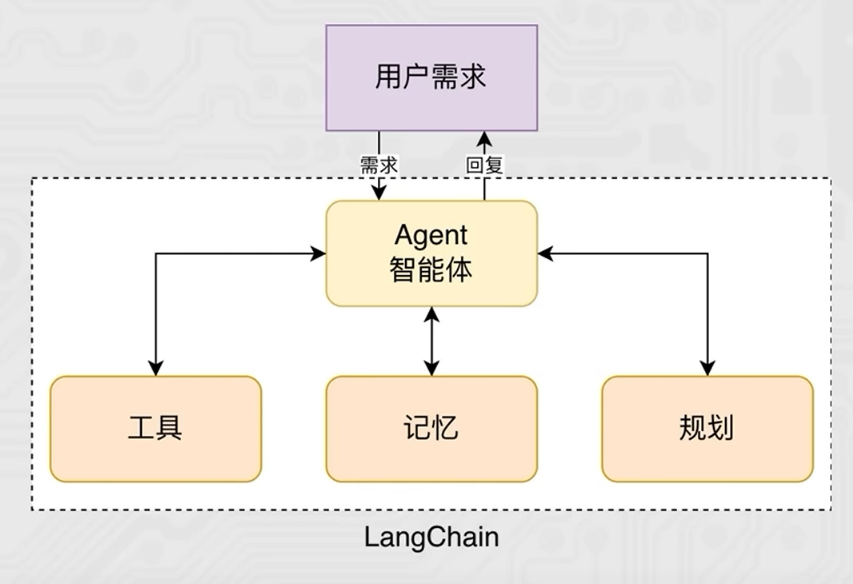
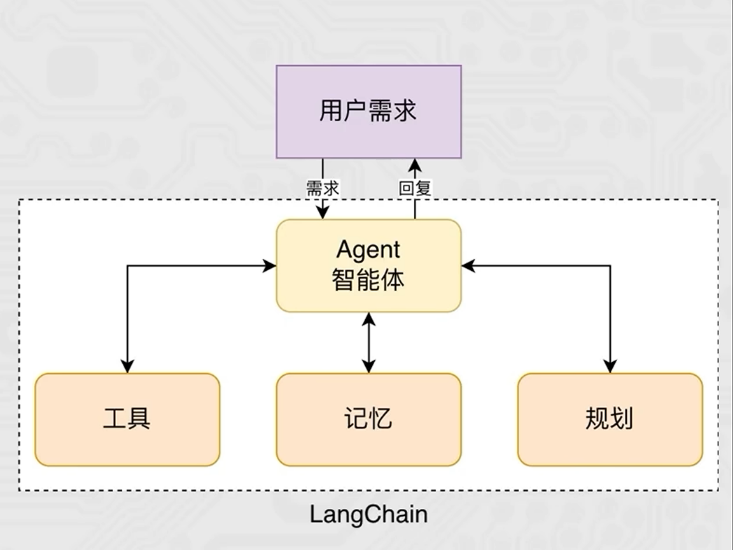
智能体(Agent) 是一种能够自主规划、决策、执行任务的组件,核心是让大语言模型(LLM)根据任务需求,选择并调用工具,完成单靠模型自身无法解决的复杂问题
- 没有Agent时,LLM 只能基于自身训练数据回答问题,遇到需要实时数据、复杂计算、外部工具调用的场景就会卡壳。
- 有了Agent后,LLM 就像一个"指挥官",能思考任务步骤->选择合适工具->执行工具调用->根据结果调整策略,直到完成任务。

chain和agent的区别
- 以电商商品问答为例:
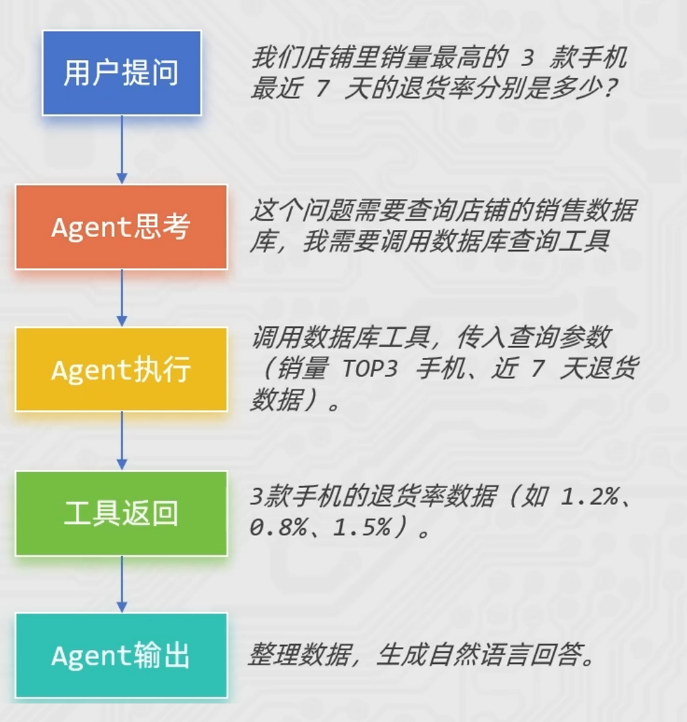
- 对比一下
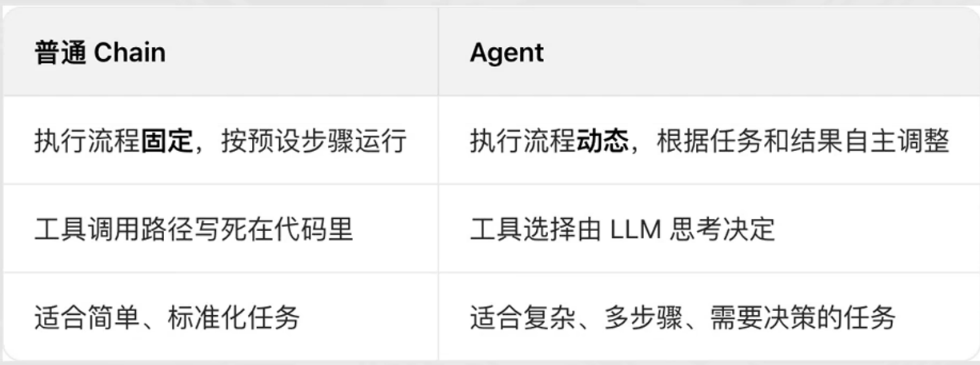
- Agent智能体=大语言模型(大脑)+工具集(手脚)+决策逻辑思维),
- 是让LLM从"只会回答"升级为"会做事(影响现实世界)"的智能助手。
- chain和agent的共同点是都增强了大语言模型的能力
- chain的作用是优化模型与用户的交互,让模型具备连续对话的能力,手段包括提示词模板,历史消息,RAG检索增强
- agent的作用是扩展模型的能力边界,通过调用工具,让模型从"只会聊天"的对话框升级成"可以做事"的助理
体验
Agent智能体有一个很重要的核心: 工具调用。
我们设计一个天气查询工具,让大模型拥有天气回答的能力。
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
agent = create_agent(
model=ChatTongyi(model="qwen3-max", api_key="sk-0af497cdd462495aa2f08dddaead1ded"),
tools=[],
system_prompt="你是一个聊天助手,可以回答用户问题"
)
res = agent.invoke(
{
"messages": [
{"role": "user", "content": "明天深圳天气怎么样?"},
]
}
)
print(res)
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
@tool(description="查询天气")
def get_weather() -> str:
return "天气晴朗,温度23度"
agent = create_agent(
model=ChatTongyi(model="qwen3-max", api_key="sk-0af497cdd462495aa2f08dddaead1ded"),
tools=[get_weather],
system_prompt="你是一个聊天助手,可以回答用户问题"
)
res = agent.invoke(
{
"messages": [
{"role": "user", "content": "明天深圳天气怎么样?"},
]
}
)
print(res)
for message in res["messages"]:
print(type(message).__name__, message.content)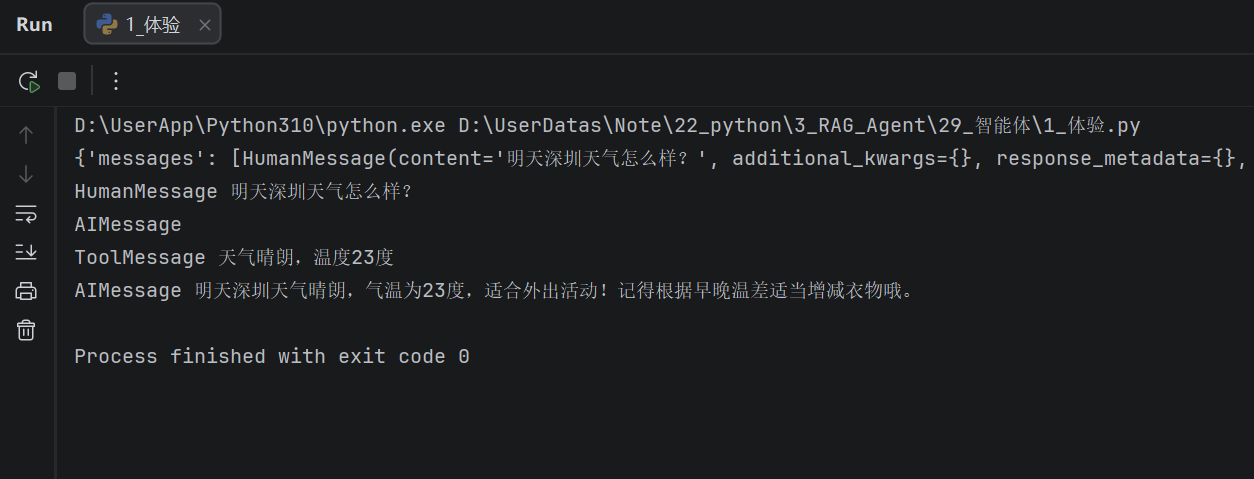
- 基于外部工具的提供,让大模型拥有了:感知外部世界并影响现实的能力。
- 丰富的工具集将极大提升大模型的工作性能和业务范畴。
- 工具越多,Agent能覆盖的业务场景就越广(从客服问答到库存管理,再到自动化运营),性能和实用性自然会大幅提升。
流式输出
通过create_agent方法可以创建Agent对象,其也是Runnable接口的子类实现,所以也拥有:
- invoke,执行,一次型得到完整结果
- stream,执行,流式得到结果
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
@tool(description="查询股票价格,传入股票名称,返回字符串信息")
def get_price(name: str) -> str:
return f"股票{name}的价格是100元"
@tool(description="查询股票信息,传入股票名称,返回字符串信息")
def get_info(name: str) -> str:
return f"股票{name},是一家A股上市公司,专注于IT职业教育"
agent = create_agent(
model=ChatTongyi(model="qwen3-max", api_key="sk-0af497cdd462495aa2f08dddaead1ded"),
tools=[get_price, get_info],
system_prompt="你是一个智能助手,可以回答股票相关的问题,请告知我思考过程,让我知道你为什么调用某个工具"
)
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "传智教育的股价是多少,并介绍一下"}]},
stream_mode="values"
):
latest_message = chunk['messages'][-1]
if latest_message.content:
print(type(latest_message).__name__, latest_message.content)
try:
if latest_message.tool_calls:
print(f"工具调用:{[tc['name'] for tc in latest_message.tool_calls]}")
except AttributeError as e:
pass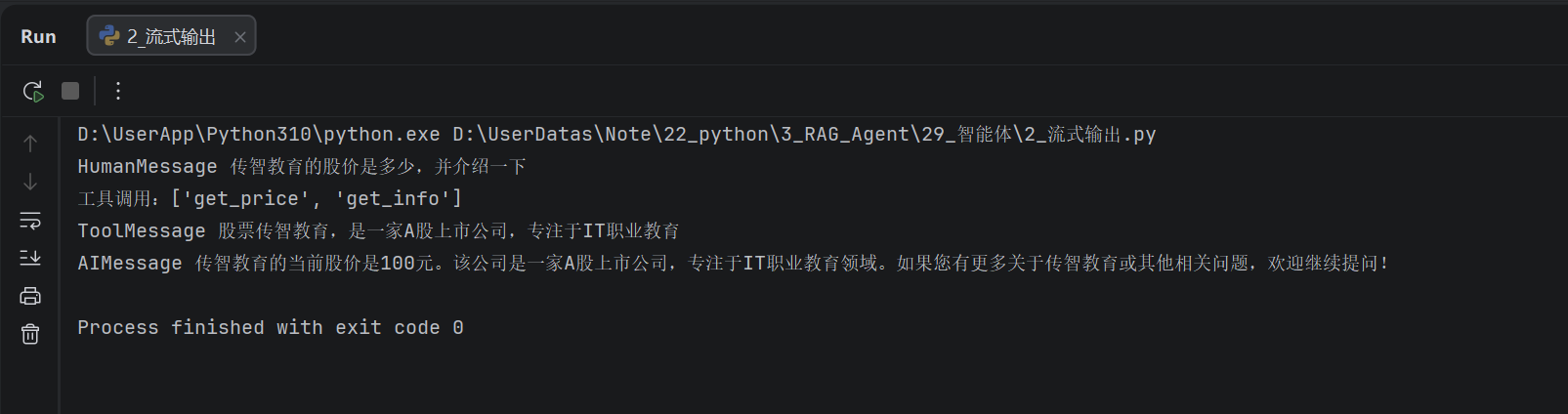
ReAct
Agent ReAct是大模型智能体的核心思考与行动框架,全称Reasoning+Acting(推理+行动),是让Agent像人类一样「思考问题>制定策略>执行行动>验证结果」的关键逻辑。
- 简单来说: ReAct让Agent不再是"直接回答问题",而是通过"自然语言思考过程"指导工具调用,一步步解决复杂问题完美适配需要多步推理、工具协作的场景(如智能客服、报告生成、任务规划等)。

- LangChain的Agent对象遵循ReAct框架要求,在执行的过程中会持续的自我思考、自我行动、自我观察。一个典型的ReAct案例如下:

-
示例代码
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool@tool(description="查询体重,返回整数,单位千克")
def get_weight() -> int:
return 90@tool(description="查询身高,返回整数,单位厘米")
def get_height() -> int:
return 180agent = create_agent(
model=ChatTongyi(model="qwen3-max", api_key="sk-0af497cdd462495aa2f08dddaead1ded"),
tools=[get_weight, get_height],
system_prompt=("""
你是严格遵循ReAct框架的智能体,必须按【思考->行动->观察->再思考】的流程解决问题,
且每轮仅能思考并调用1个工具,禁止单词调用多个工具。
并告知我你的思考过程,工具调用的原因,按思考,行动,观察三个结构告知我
""")
)for chunk in agent.stream(
{"messages": [{"role": "user", "content": "计算我的BMI"}]},
stream_mode="values"
):
latest_message = chunk['messages'][-1]if latest_message.content: print(type(latest_message).__name__, latest_message.content) try: if latest_message.tool_calls: print(f"工具调用:{[tc['name'] for tc in latest_message.tool_calls]}") except AttributeError as e: pass
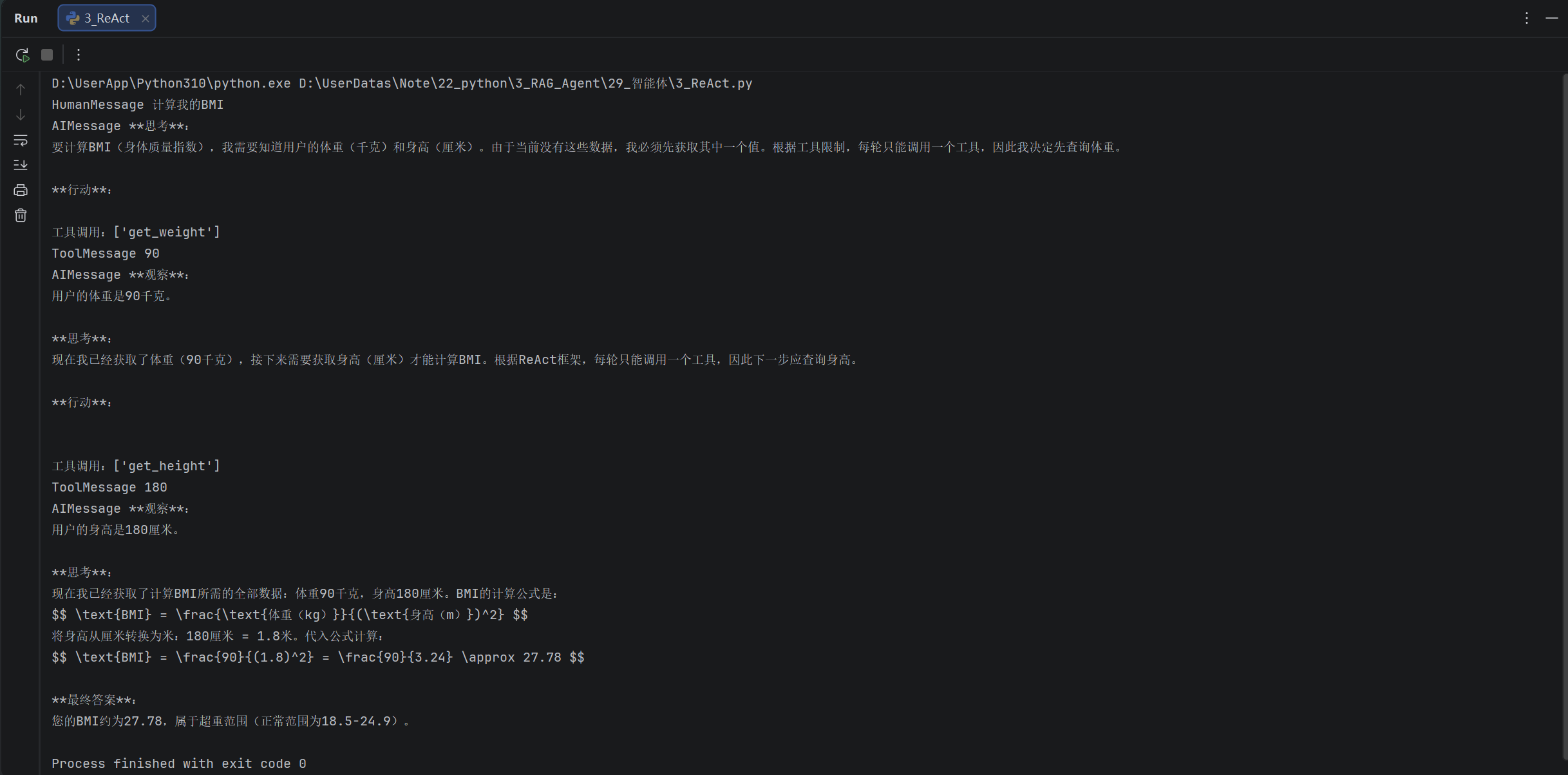
- ReAct是一种工作范式,定义了大模型的工作流程。
- LangChain的Agent对象,就是按ReAct模式运行。
middleware中间件
中间件的作用是对智能体的每一步工作进行控制和自定义的执行。
- 作用场景:
- 日志记录、分析、调试
- 转换提示词、工具选择
- 重试、备用、提前终止等逻辑控制
- 安全防护、个人身份检测等
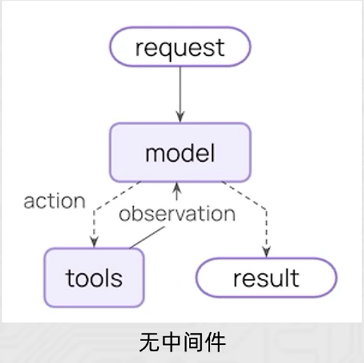
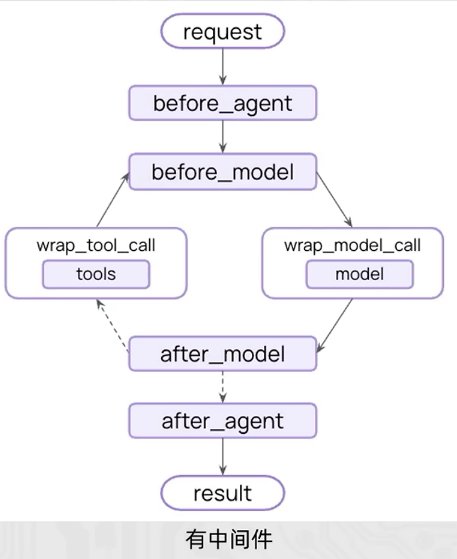
- LangChain中内置了一些基础的中间件,参见:
- 中间件通过Hooks钩子来实现拦戳,自定义中间件可以简单的使用装饰器来定义。
- 节点式钩子(执行点顺序拦截):
-
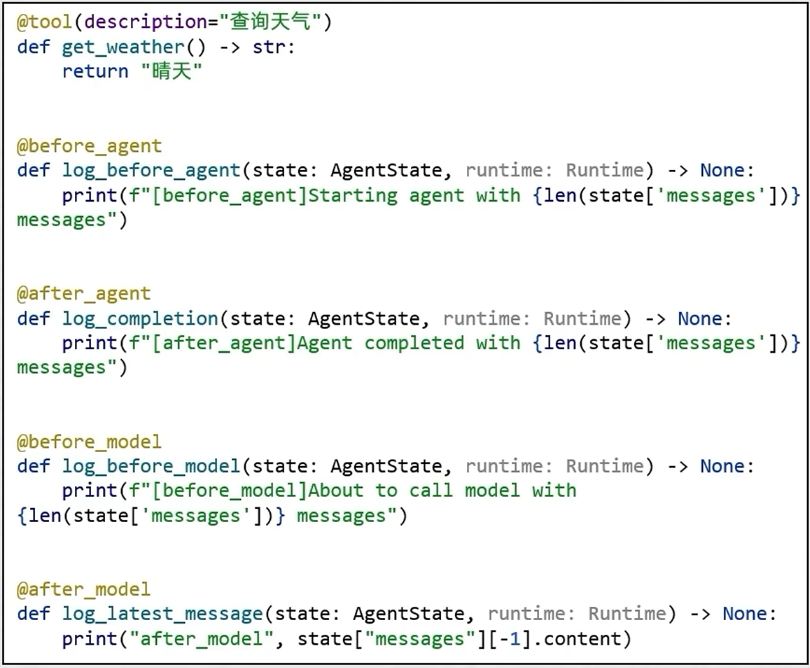
- before_agent: agent执行之前拦截
- after_agent: agent执行后拦截
- before_model: 模型执行前拦截
- after_model: 模型执行后拦截
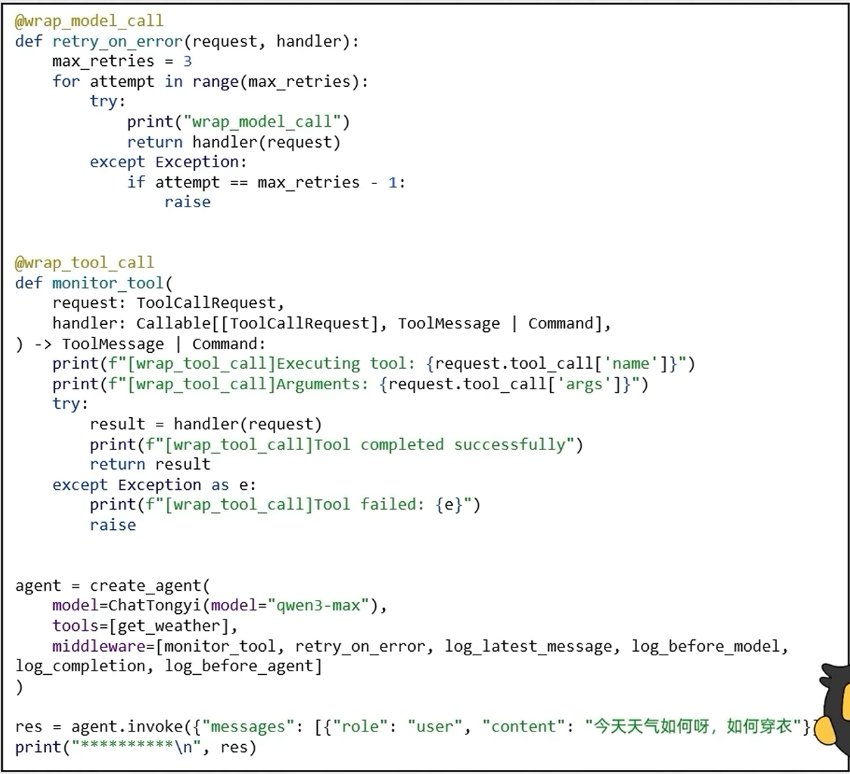
- 针对工具和模型的包装式钩子:
-
- wrap_model_call: 每个模型调用时候拦截
- wrap_tool_call: 每个工具调用时候拦截
-
代码示例
from langchain.agents import AgentState, create_agent
from langchain.agents.middleware import before_agent, after_agent, before_model, after_model, wrap_model_call,
wrap_tool_call
from langchain_community.chat_models import ChatTongyi
from langchain_core.runnables import Runnable
from langchain_core.tools import tool"""
1.agent执行前
2.agent执行后
3.model执行前
4.model执行后
5.工具执行中
6.模型执行中
"""@tool(description="查询天气,传入城市名称,返回字符串")
def get_weather(city: str) -> str:
return f"{city}天气晴朗,温度23度"@before_agent
def log_before_agent(state: AgentState, runtime: Runnable) -> None:
print(f"【before agent】agent启动,并附带{len(state['messages'])}消息")@after_agent
def log_after_agent(state: AgentState, runtime: Runnable) -> None:
print(f"【after agent】agent结束,并附带{len(state['messages'])}消息")@before_model
def log_before_model(state: AgentState, runtime: Runnable) -> None:
print(f"【before model】model即将调用,并附带{len(state['messages'])}消息")@after_model
def log_after_model(state: AgentState, runtime: Runnable) -> None:
print(f"【after model】model调用结束,并附带{len(state['messages'])}消息")@wrap_model_call
def model_call_hook(request, handler) -> None:
print("模型调用了")
return handler(request)@wrap_tool_call
def model_tool_hook(request, handler) -> None:
print(f"工具执行:{request.tool_call['name']}")
print(f"工具参数:{request.tool_call['args']}")
return handler(request)agent = create_agent(
model=ChatTongyi(model="qwen3-max", api_key="sk-0af497cdd462495aa2f08dddaead1ded"),
tools=[get_weather],
middleware=[log_before_agent,log_after_agent,log_before_model,log_after_model,model_call_hook,model_tool_hook],
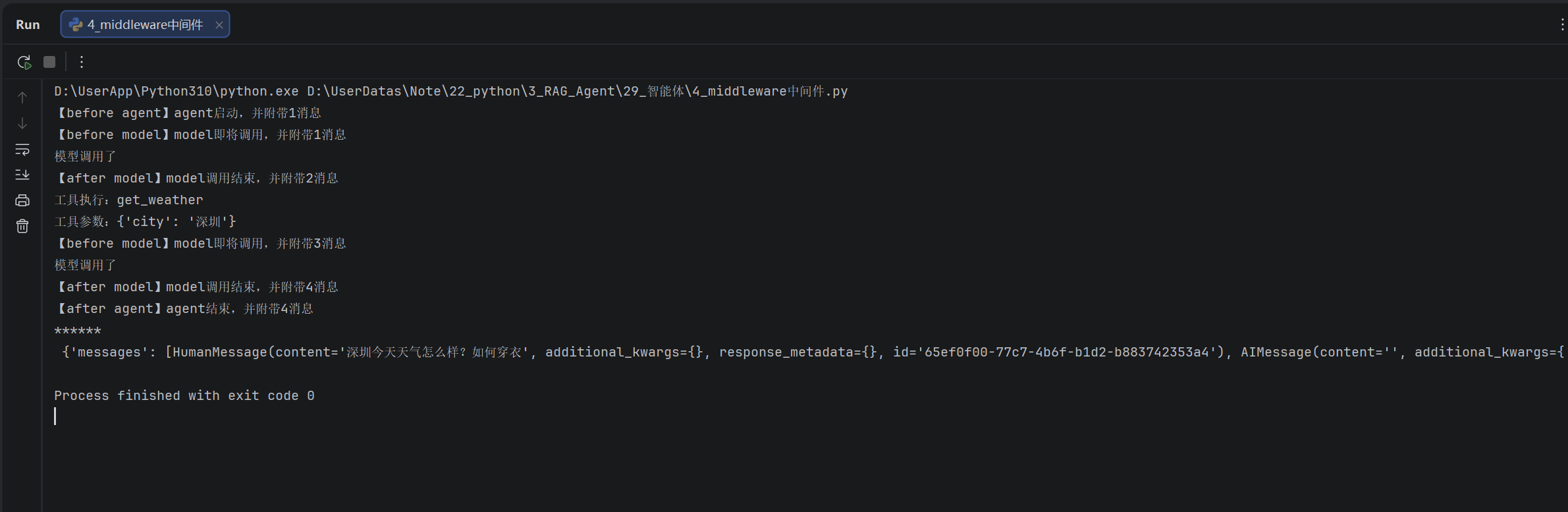
)res = agent.invoke({"messages": [{"role": "user", "content": "深圳今天天气怎么样?如何穿衣"}]},)
print("******\n", res)
项目
智能体项目介绍
智扫通Agent项目是一个面向消费者(toC)的智能客服系统,旨在为用户提供全周期的扫地机器人相关服务。
- 核心功能

- 数据集(RAG知识库):


- 项目结构
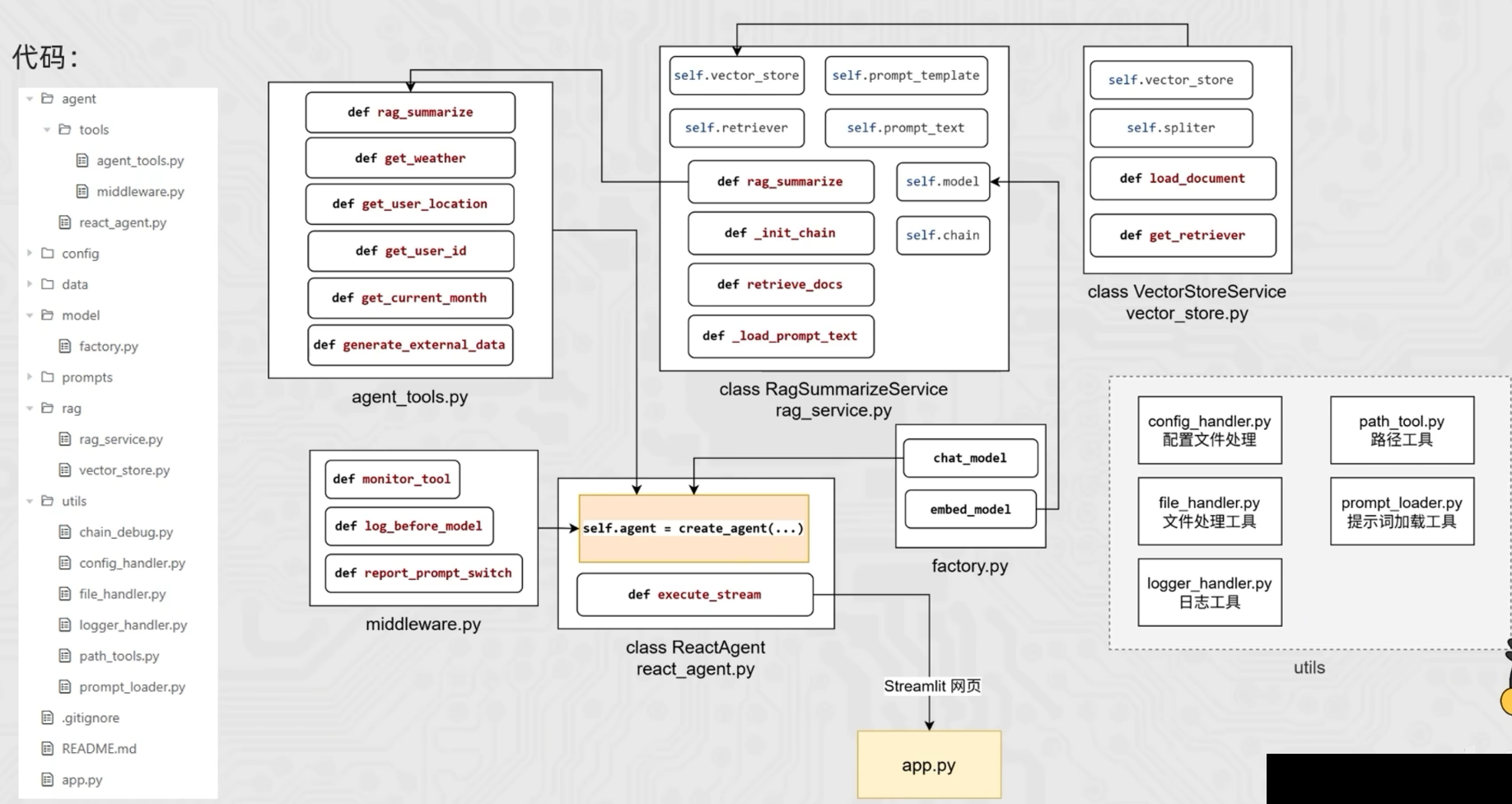
utils工具函数开发
utils工具函数开发
"""
为整个工程提供统一的绝对路径
"""
import os
def get_project_root() -> str:
"""
获得工程所在的根目录
:return: 字符串根目录
"""
# 当前文件的绝对路径
current_file = os.path.abspath(__file__)
# 获取父级文件夹的绝对路径
current_dir = os.path.dirname(current_file)
# 获取工程根目录
project_root = os.path.dirname(current_dir)
return project_root
def get_abd_path(relative_path: str) -> str:
"""
传递相对路径,得到绝对路径
:param relative_path: 相对路径
:return: 绝对路径
"""
project_root = get_project_root()
return os.path.join(project_root, relative_path)
if __name__ == '__main__':
print(get_abd_path("config/config.txt"))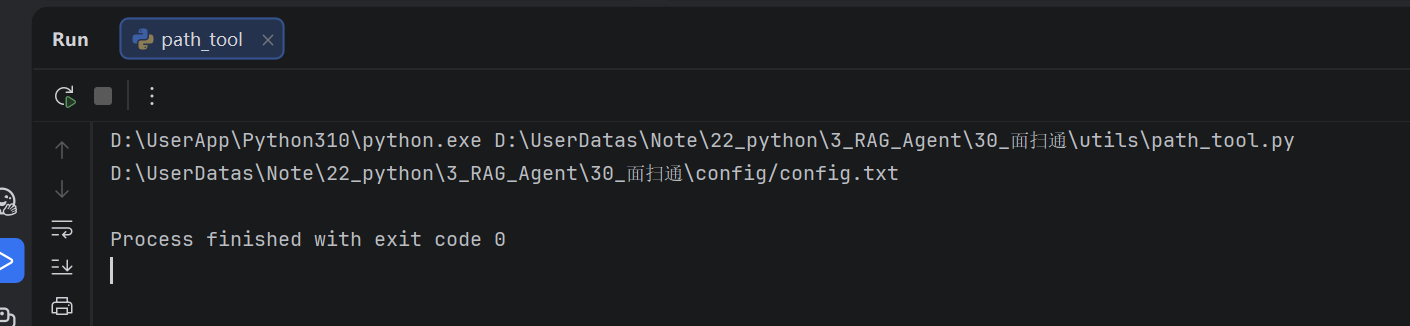
from datetime import datetime
import logging
import os
from path_tool import get_abd_path
# 日志存储的根目录
LOG_ROOT = get_abd_path("logs")
# 确保日志的目录存在
os.makedirs(LOG_ROOT, exist_ok=True)
# 日志的格式配置
DEFAULT_LOG_FORMAT = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s")
def get_logger(
name: str = "agent",
console_level: int = logging.INFO,
file_level: int = logging.DEBUG,
log_file=None,
) -> logging.Logger:
"""
获取日志对象
:return: 日志对象
"""
logger = logging.getLogger(name) # 创建日志对象
logger.setLevel(logging.DEBUG) # 设置日志级别
# 避免重复添加Handler
if logger.handlers:
return logger
# 控制台日志
console_handler = logging.StreamHandler()
console_handler.setLevel(console_level)
console_handler.setFormatter(DEFAULT_LOG_FORMAT)
logger.addHandler(console_handler)
# 文件日志
if log_file is None:
log_file = os.path.join(LOG_ROOT, f"{name}_{datetime.now().strftime('%Y%m%d')}.log")
file_handler = logging.FileHandler(log_file, encoding="utf-8")
file_handler.setLevel(file_level)
file_handler.setFormatter(DEFAULT_LOG_FORMAT)
logger.addHandler(file_handler)
return logger
# 快捷获取日志器对象
logger = get_logger()
if __name__ == '__main__':
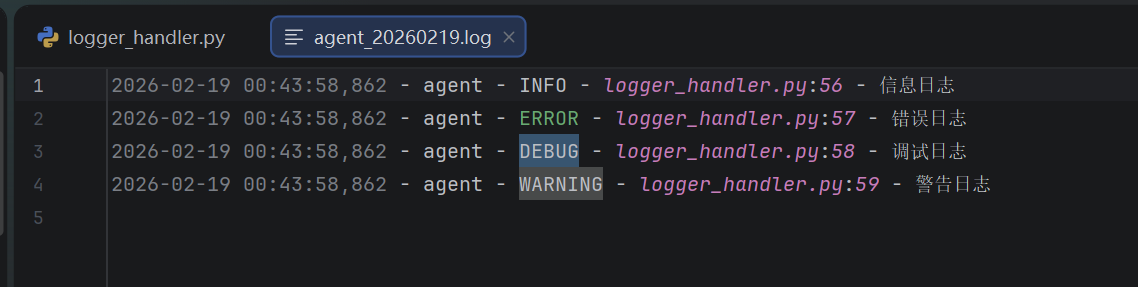
logger.info("信息日志")
logger.error("错误日志")
logger.debug("调试日志")
logger.warning("警告日志")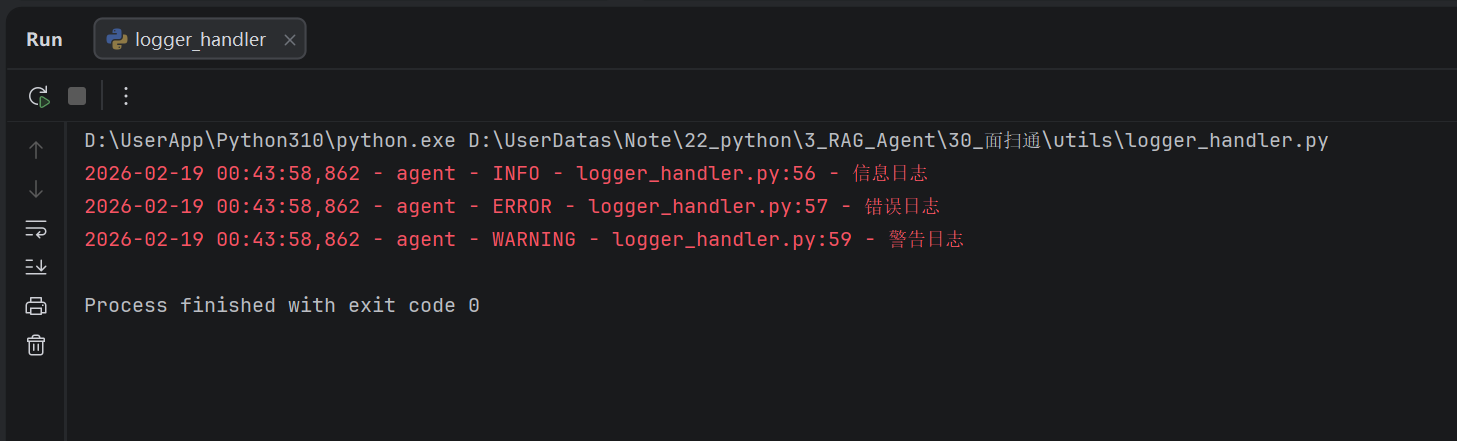
import yaml
from path_tool import get_abd_path
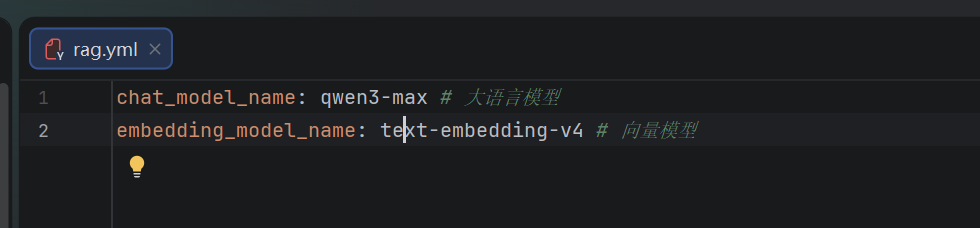
def load_rag_config(config_path: str=get_abd_path("config/rag.yml"), encoding="utf-8"):
with open(config_path, "r", encoding=encoding) as f:
return yaml.load(f, Loader=yaml.FullLoader)
def load_chroma_config(config_path: str=get_abd_path("config/chroma.yml"), encoding="utf-8"):
with open(config_path, "r", encoding=encoding) as f:
return yaml.load(f, Loader=yaml.FullLoader)
def load_prompts_config(config_path: str=get_abd_path("config/prompts.yml"), encoding="utf-8"):
with open(config_path, "r", encoding=encoding) as f:
return yaml.load(f, Loader=yaml.FullLoader)
def load_agent_config(config_path: str=get_abd_path("config/agent.yml"), encoding="utf-8"):
with open(config_path, "r", encoding=encoding) as f:
return yaml.load(f, Loader=yaml.FullLoader)
rag_conf = load_rag_config()
chroma_conf = load_chroma_config()
prompts_conf = load_prompts_config()
agent_conf = load_agent_config()
if __name__ == '__main__':
print(rag_conf["chat_model_name"])

import hashlib
import logging
import os
from langchain_community.document_loaders import PyPDFLoader, TextLoader
from langchain_core.documents import Document
def get_file_md5_hex(filepath: str):
"""
获取文件的md5值
:return: md5值(十六进制字符串)
"""
if not os.path.exists(filepath):
logging.error(f"[md5计算]文件{filepath}不存在")
return None
if not os.path.isfile(filepath):
logging.error(f"[md5计算]路径{filepath}不是文件")
return None
# md5对象
md5_obj = hashlib.md5()
chunk_size = 4096 # 4KB分片,避免内存溢出
try:
with open(filepath, "rb") as f: # 二进制读取
chunk = f.read(chunk_size)
while chunk:
md5_obj.update(chunk)
chunk = f.read(chunk_size)
md5_hex = md5_obj.hexdigest()
return md5_hex
except Exception as e:
logging.error(f"[md5计算]文件{filepath}计算md5失败:{str(e)}")
return None
def listdir_with_allowed_type(path: str, allowed_type: tuple[str]):
"""
返回文件夹内的文件列表(筛选文件后缀)
:return: 文件列表
:allowed_type: 文件后缀
"""
files = []
if not os.path.isdir(path):
logging.error(f"[文件列表]路径{path}不是文件夹")
return allowed_type
for f in os.listdir(path):
if f.endswith(allowed_type):
files.append(os.path.join(path, f))
return tuple(files)
def pdf_loader(filepath: str, password=None) -> list[Document]:
return PyPDFLoader(filepath, password).load()
def txt_loader(filepath: str, ) -> list[Document]:
return TextLoader(filepath).load()
from config_handler import prompts_conf
from path_tool import get_abs_path
from logger_handler import logger
def load_system_prompts():
try:
system_prompt_path = get_abs_path(prompts_conf["main_prompt_path"])
except KeyError as e:
logger.error(f"[load_system_prompts]在yml配置文件中没有main_prompt_path配置项")
pass
try:
return open(system_prompt_path, "r", encoding="utf-8").read()
except Exception as e:
logger.error(f"[load_system_prompts]解析系统提示词出错:{str(e)}")
raise e
def load_rag_prompts():
try:
rag_prompt_path = get_abs_path(prompts_conf["rag_summarize_prompt_path"])
except KeyError as e:
logger.error(f"[load_rag_prompts]在yml配置文件中没有rag_summarize_prompt_path配置项")
pass
try:
return open(rag_prompt_path, "r", encoding="utf-8").read()
except Exception as e:
logger.error(f"[load_rag_prompts]解析RAG总结提示词出错:{str(e)}")
raise e
def load_report_prompts():
try:
report_prompt_path = get_abs_path(prompts_conf["report_prompt_path"])
except KeyError as e:
logger.error(f"[load_report_prompts]在yml配置文件中没有report_prompt_path配置项")
pass
try:
return open(report_prompt_path, "r", encoding="utf-8").read()
except Exception as e:
logger.error(f"[load_report_prompts]解析生成报告提示词出错:{str(e)}")
raise e
if __name__ == '__main__':
# print(load_system_prompts())
# print(load_rag_prompts())
print(load_report_prompts())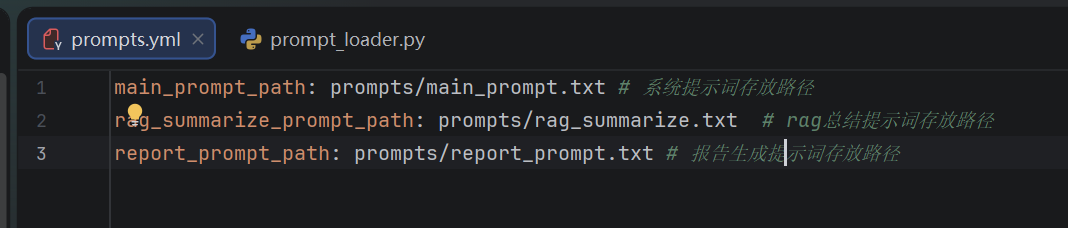
向量存储开发
完成向量存储的开发
"""
模型的工厂类
"""
from abc import ABC, abstractmethod
from typing import Optional
from langchain_community.embeddings import DashScopeEmbeddings
from utils.config_handler import rag_conf
from langchain_community.chat_models import ChatTongyi
from langchain_core.embeddings import Embeddings
from langchain_core.language_models import BaseChatModel
class BaseModelFactory(ABC):
@abstractmethod
def generator(self) -> Optional[Embeddings | BaseChatModel]:
pass
class ChatModelFactory(BaseModelFactory):
def generator(self) -> Optional[BaseChatModel | BaseChatModel]:
return ChatTongyi(model=rag_conf["chat_model_name"], api_key="sk-0af497cdd462495aa2f08dddaead1ded")
class EmbeddingsFactory(BaseModelFactory):
def generator(self) -> Optional[BaseChatModel | BaseChatModel]:
return DashScopeEmbeddings(model=rag_conf["embedding_model_name"],dashscope_api_key="sk-0af497cdd462495aa2f08dddaead1ded")
chat_model = ChatModelFactory().generator()
embeddings = EmbeddingsFactory().generator()
"""
检索增强服务
"""
import os
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from model.factory import embeddings
from utils.config_handler import chroma_conf
from utils.path_tool import get_abs_path
from utils.file_handler import pdf_loader, txt_loader, listdir_with_allowed_type, get_file_md5_hex
from utils.logger_handler import logger
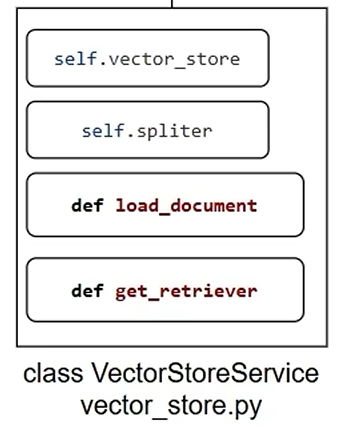
class VectorStoreService(object):
def __init__(self):
# 创建向量储存库实例
self.vector_store = Chroma(
collection_name=chroma_conf["collection_name"],
embedding_function=embeddings,
persist_directory=chroma_conf["persist_directory"],
)
# 创建文本分割器实例
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=chroma_conf["chunk_size"],
chunk_overlap=chroma_conf["chunk_overlap"],
separators=chroma_conf["separators"],
length_function=len,
)
def get_retriever(self):
return self.vector_store.as_retriever(search_kwargs={"k": chroma_conf["k"]})
def load_document(self):
"""
从数据文件夹内读取数据文件,转为向量存入向量库
要计算文件的MD5值做去重
:param self:
:return: None
"""
def check_md5_hex(md5_for_check: str):
if not os.path.exists(get_abs_path(chroma_conf["md5_hex_store"])):
# 文件不存在
open(get_abs_path(chroma_conf["md5_hex_store"]), "w", encoding="utf-8").close()
return False # md5没处理过
with open(get_abs_path(chroma_conf["md5_hex_store"]), "r", encoding="utf-8") as f:
for line in f.readlines():
line = line.strip()
if line == md5_for_check:
return True # md5处理过
return False # md5没处理过
def save_md5_hex(md5_for_hex: str):
with open(get_abs_path(chroma_conf["md5_hex_store"]), "a", encoding="utf-8") as f:
f.write(md5_for_hex + "\n")
def get_file_documents(radl_path: str):
if radl_path.endswith("txt"):
return txt_loader(radl_path)
if radl_path.endswith("pdf"):
return pdf_loader(radl_path)
return []
allowed_files_path: list[str] = listdir_with_allowed_type(
get_abs_path(chroma_conf["data_path"]),
tuple(chroma_conf["allow_knowledge_file_type"])
)
for path in allowed_files_path:
# 获取文件的md5值
md5_hex = get_file_md5_hex(path)
if check_md5_hex(md5_hex):
logger.info(f"[加载知识库]{path}内存已处在知识库,跳过")
continue
try:
documents: list[Document] = get_file_documents(path)
if not documents:
logger.warning(f"[加载知识库]{path}内无有效的文本内容,跳过")
continue
split_document: list[Document] = self.spliter.split_documents(documents)
if not split_document:
logger.warning(f"[加载知识库]{path}分片后无有效的文本内容,跳过")
continue
# 将内容存入向量库
self.vector_store.add_documents(split_document)
# 记录文件的md5值
save_md5_hex(md5_hex)
logger.info(f"[加载知识库]{path}内容已存入向量库")
except Exception as e:
# exc_info为True时 会记录详细的报错堆栈信息, 为False时 仅记录报错信息本身
logger.error(f"[加载知识库]{path}加载失败:{str(e)}", exc_info=True)
continue
if __name__ == '__main__':
vs = VectorStoreService()
vs.load_document()
retriever = vs.get_retriever()
res = retriever.invoke("迷路")
for doc in res:
print(doc.page_content)
print("-" * 20)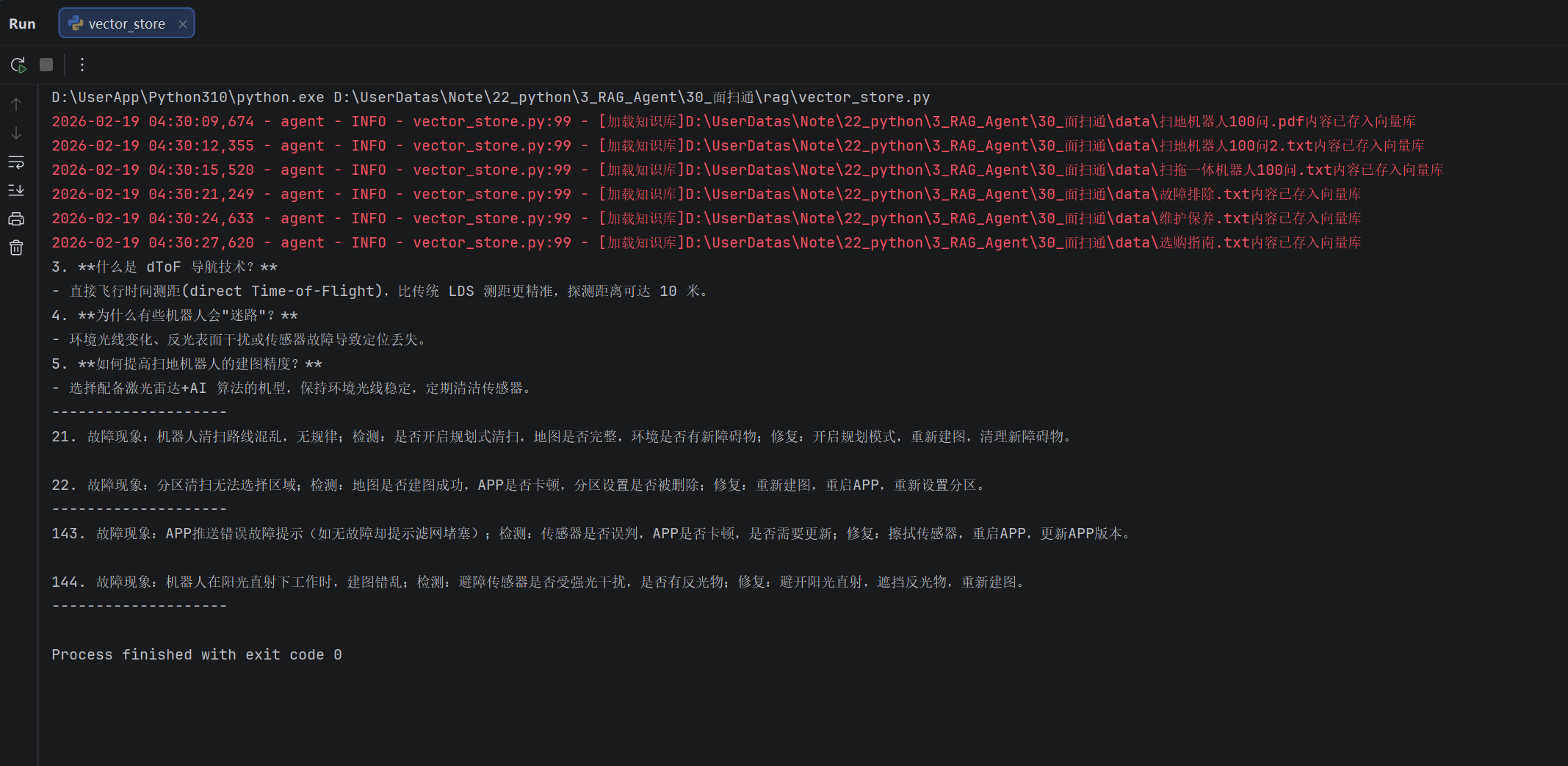
RAG服务开发
完成RAG总结服务的开发
"""
rag总结服务类:用户提问,检索参考资料,将提问和参考资料提交给模型,让模型总结回复
"""
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from model.factory import chat_model
from rag.vector_store import VectorStoreService
from utils.prompt_loader import load_rag_prompts
def print_prompt(prompt):
print("="*20)
print(prompt.to_string())
print("="*20)
return prompt
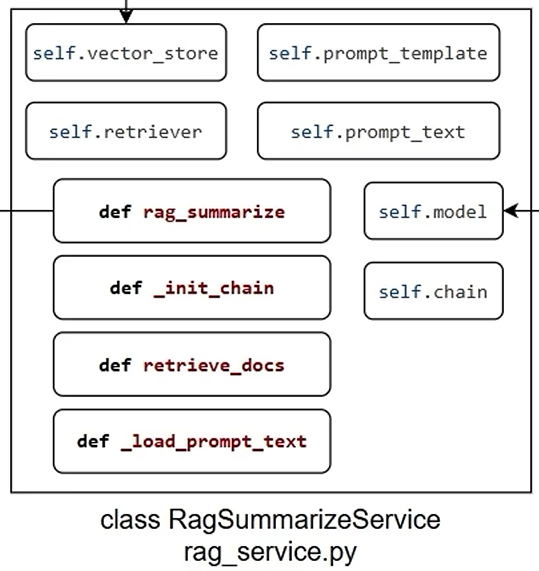
class RagSummaryService(object):
def __init__(self):
self.vector_store = VectorStoreService()
self.retriever = self.vector_store.get_retriever()
self.prompt_text = load_rag_prompts()
self.prompt_template = PromptTemplate.from_template(self.prompt_text)
self.model = chat_model
self.chain = self._init_chain()
def _init_chain(self):
return self.prompt_template | print_prompt | self.model | StrOutputParser()
def retrieve_docs(self,query: str) -> list[Document]:
return self.retriever.invoke(query)
def rag_summarize(self, query: str):
context_docs = self.retrieve_docs(query)
context = ""
counter = 0
for doc in context_docs:
counter += 1
context += f"[参考资料{counter}]: 参考资料: {doc.page_content} | 参考元数据: {doc.metadata}\n"
return self.chain.invoke({"input": query, "context": context})
if __name__ == '__main__':
rag = RagSummaryService()
print(rag.rag_summarize("小户型适合哪些扫地机器人?"))
agent工具开发
agent_tools开发
import os
import random
from langchain_core.tools import tool
from rag.rag_service import RagSummaryService
from utils.config_handler import agent_conf
from utils.path_tool import get_abs_path
rag = RagSummaryService()
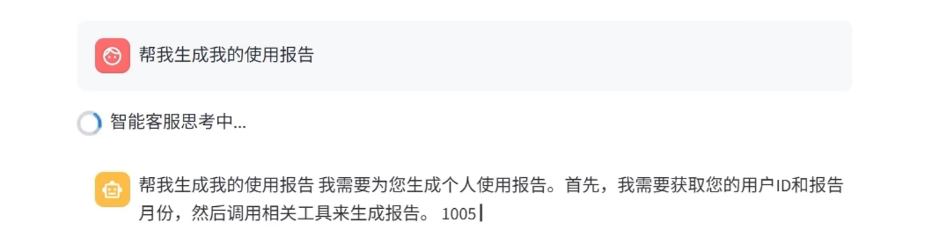
user_ids = ["1001", "1002", "1003", "1004", "1005", "1006", "1007", "1008", "1009", "1010"]
month_arr = ["2025-01", "2025-02", "2025-03", "2025-04", "2025-05", "2025-06", "2025-07", "2025-08", "2025-09",
"2025-10", "2025-11", "2025-12"]
external_data = {}
@tool(description="从向量存储中检索参考资料")
def rag_summarize(query: str) -> str:
return rag.rag_summarize(query)
@tool(description="获取指定城市的天气,以消息字符串的形式返回")
def get_weather(city: str) -> str:
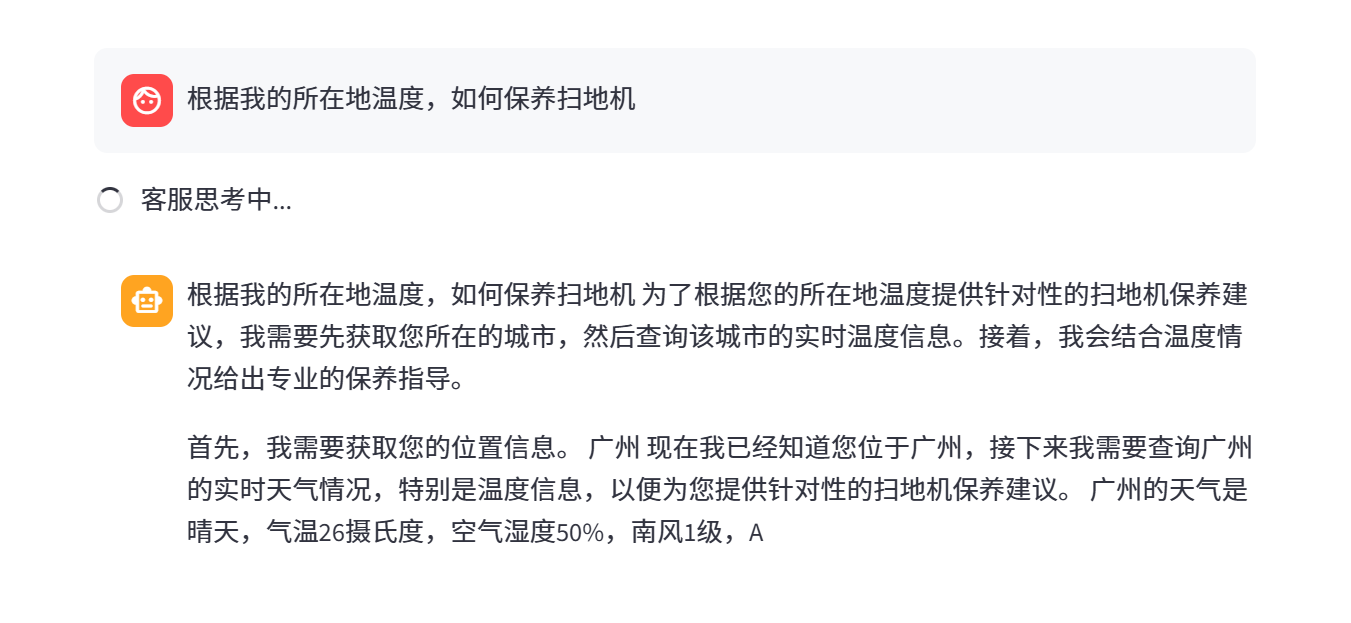
return f"{city}的天气是晴天,气温26摄氏度,空气湿度50%,南风1级,AQI21,最近6小时降雨概率极低"
@tool(description="获取指定用户所在城市的名称,以纯字符串形式返回")
def get_user_location() -> str:
return random.choice(["深圳", "上海", "北京", "广州", "杭州"])
@tool(description="获取用户的ID,以纯字符串形式返回")
def get_user_id() -> str:
return random.choice(user_ids)
@tool(description="获取当前月份,以纯字符串形式返回")
def get_current_month() -> str:
return random.choice(month_arr)
def generate_external_data():
"""
{
"user_id": {
"month": {"特征":xxx, "效率": xxx, ...}
},
}
"""
if not external_data:
external_data_path = get_abs_path(agent_conf["external_data_path"])
if not os.path.exists(external_data_path):
raise FileNotFoundError(f"[generate_external_data]指定的外部数据{external_data_path},文件不存在")
with open(external_data_path, "r", encoding="utf-8") as f:
for line in f.readlines():
arr: list[str] = line.strip().split(",")
user_id: str = arr[0].replace('"', "")
feature: str = arr[1].replace('"', "")
efficiency: str = arr[2].replace('"', "")
consumables: str = arr[3].replace('"', "")
comparison: str = arr[4].replace('"', "")
time: str = arr[5].replace('"', "")
if user_id not in external_data:
external_data[user_id] = {}
external_data[user_id][time] = {
"特性": feature,
"效率": efficiency,
"耗材": consumables,
"对比": comparison,
}
# @tool(description="从外部系统中获取指定用户在指定月份的使用记录,以纯字符串形似返回,如何未检索到返回空字符串")
def fetch_external_data(user_id: str, month: str):
generate_external_data()
try:
return external_data[user_id][month]
except KeyError:
print(f"[fetch_external_data]未找到用户: {user_id}在{month}的记录")
return ""
if __name__ == '__main__':
# @tool注解注释后再测试
print(fetch_external_data("1001", "2025-01"))
middleware中间件
middleware中间件开发
from collections.abc import Callable
from langchain.agents import AgentState
from langchain.agents.middleware import before_model, wrap_tool_call, dynamic_prompt, ModelRequest
from langchain_core.messages import ToolMessage
from langgraph.prebuilt.tool_node import ToolCallRequest
from langgraph.runtime import Runtime
from langgraph.types import Command
from utils.logger_handler import logger
from utils.prompt_loader import load_report_prompts, load_system_prompts
@wrap_tool_call
def monitor_tool( # 工具执行的监控
# 请求的数据封装
request: ToolCallRequest,
# 执行的函数本身
handler: Callable[[ToolCallRequest], ToolMessage, Command]
) -> ToolMessage | Command:
logger.info(f"[工具执行]:{request.tool_call['name']}")
logger.info(f"[工具入参]:{request.tool_call['args']}")
try:
result = handler(request)
logger.info(f"工具{request.tool_call['name']}执行成功")
if request.tool_call['name'] == "fill_context_for_report":
request.runtime.context["report"] = True
return result
except Exception as e:
logger.error(f"工具{request.tool_call['name']}执行失败,原因:{str(e)}")
raise e
@before_model
def log_before_model( # 模型执行前的日志
state: AgentState, # 整个agent的状态记录
runtime: Runtime, # 记录了执行过程中的上下文
):
logger.info(f"[模型调用]:带有{len(state['messages'])}条消息")
logger.debug(f"[模型调用]:{type(state['messages'])[-1].__name__} | {state['messages'][-1].content}")
return None
@dynamic_prompt # 每一次生成提示词之前,调用此函数
def report_prompt_switch(request: ModelRequest): # 动态切换提示词
is_report = request.runtime.context.get("report", False)
# 根据遍历值切换提示词
if is_report:
return load_report_prompts()
return load_system_prompts()agent服务
agent服务开发
from langchain.agents import create_agent
from model.factory import chat_model
from utils.prompt_loader import load_system_prompts
from agent.tools.agent_tools import (rag_summarize, get_weather, get_user_id, get_user_location, get_user_id,
get_current_month, fetch_external_data, fill_context_for_report)
from agent.tools.middleware import monitor_tool, report_prompt_switch, log_before_model
class ReactAgent:
def __init__(self):
self.agent = create_agent(
model=chat_model,
system_prompt=load_system_prompts(),
tools=[rag_summarize, get_weather, get_user_id, get_user_location,
get_current_month, fetch_external_data, fill_context_for_report],
middleware=[monitor_tool, log_before_model, report_prompt_switch]
)
def execute_stream(self, query: str):
input_dict = {
"messages": [{"role": "user", "content": query}]
}
# 第三个参数context就是上下文runtime中的信息,我们做提示词切换到的标记
for chunk in self.agent.stream(input_dict, stream_mode="values", context={"report": False}):
latest_message = chunk["messages"][-1]
if latest_message.content:
yield latest_message.content.strip() + "\n"
if __name__ == '__main__':
agent = ReactAgent()
# for chunk in agent.execute_stream("扫地机器人在我所在地区的气温下如何保养"):
# print(chunk, end="", flush=True)
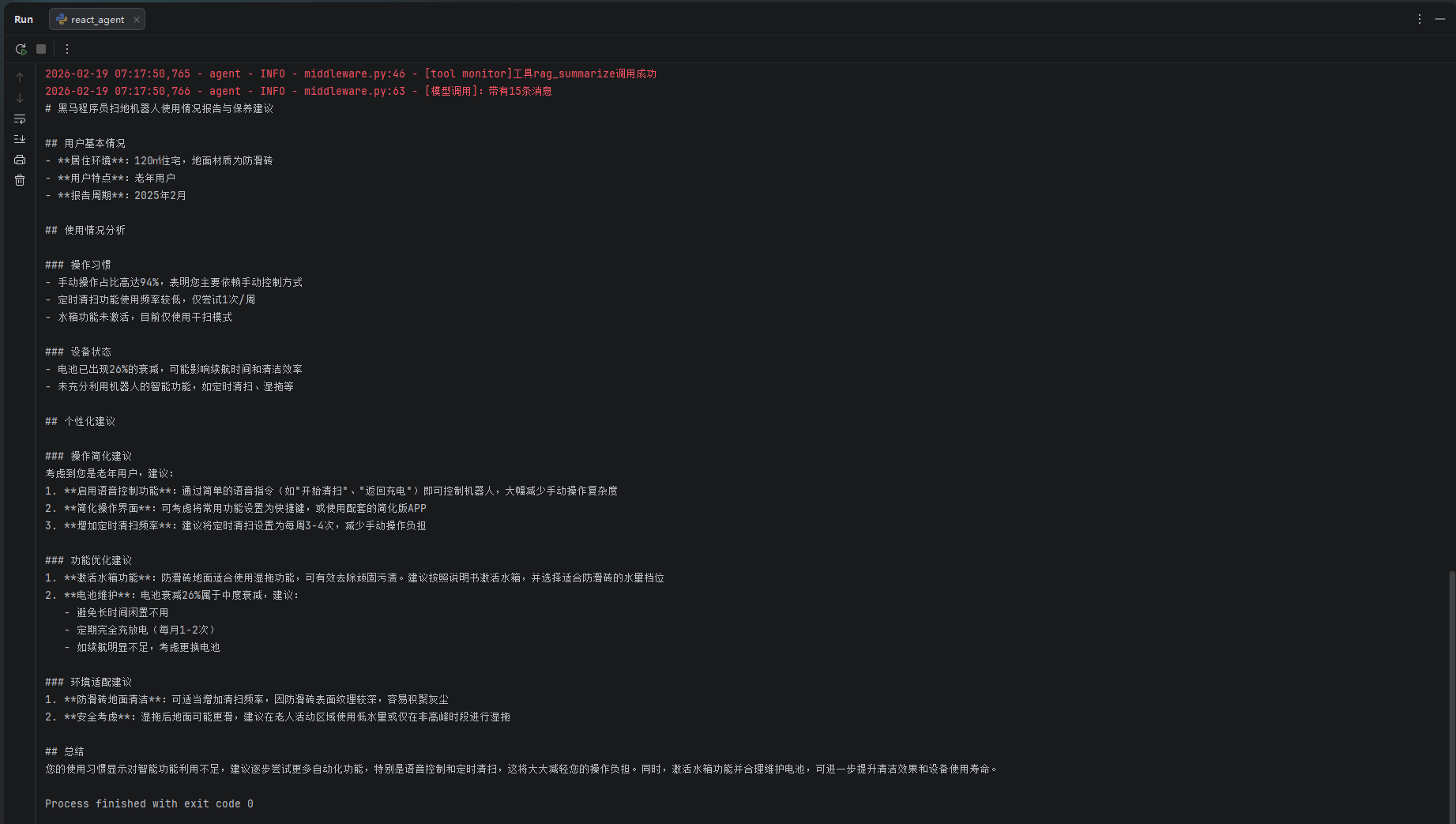
for chunk in agent.execute_stream("生成我的使用报告"):
print(chunk, end="", flush=True)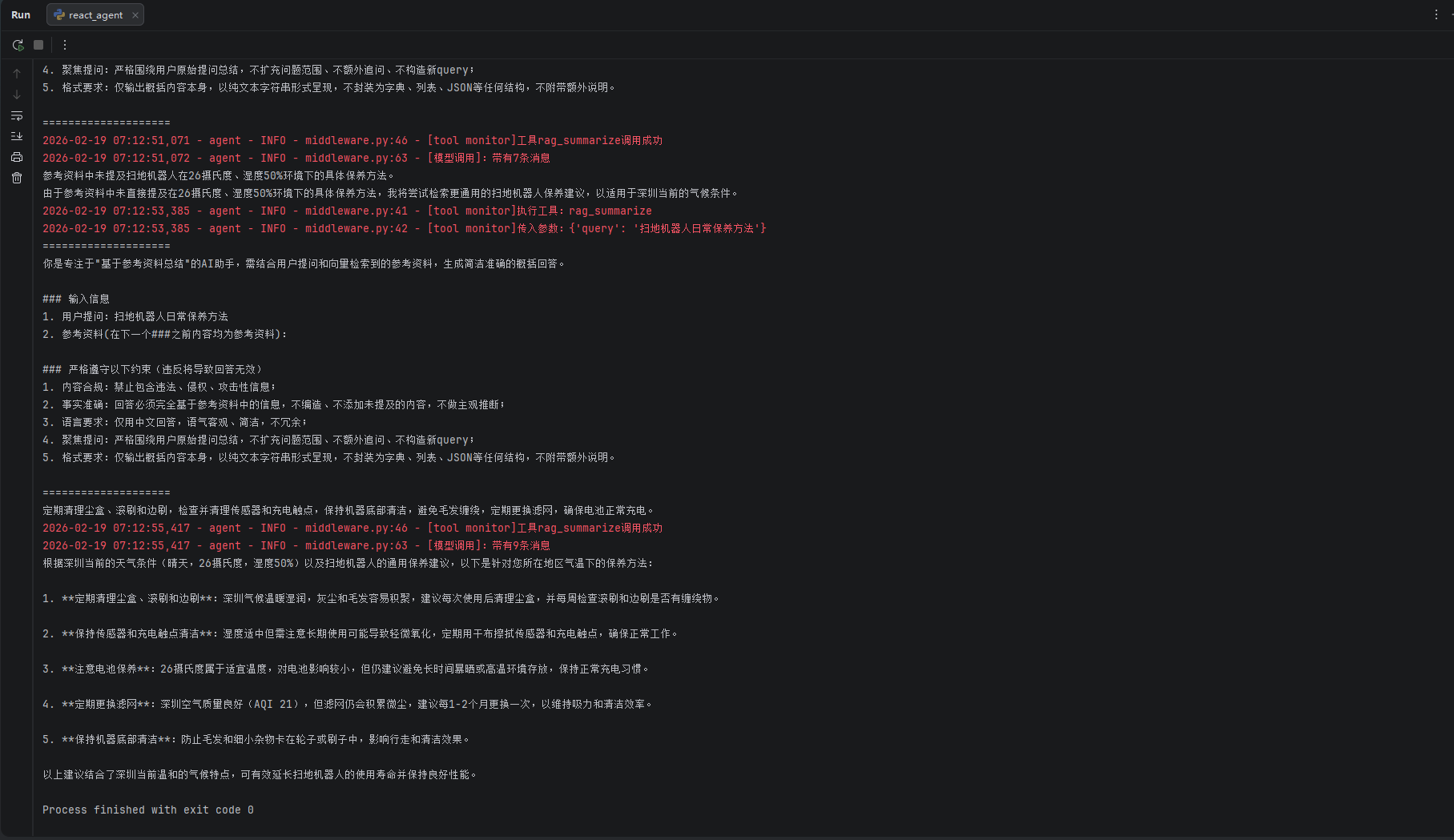
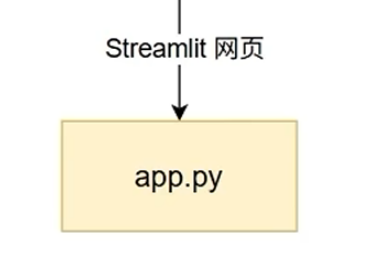
页面开发
Streamit服务开发
import time
import streamlit as st
from agent.react_agent import ReactAgent
# 标题
st.title("智扫通机器人只能客服")
st.divider()
if "agent" not in st.session_state:
st.session_state["agent"] = ReactAgent()
if "message" not in st.session_state:
st.session_state["message"] = []
for message in st.session_state["message"]:
st.chat_message(message["role"]).write(message["content"])
# 用户输入
prompt = st.chat_input()
if prompt:
st.chat_message("user").write(prompt)
st.session_state["message"].append({"role": "user", "content": prompt})
response_messages = []
with st.spinner("客服思考中..."):
res_stream = st.session_state["agent"].execute_stream(prompt)
def capture(generator, cache_list):
for chunk in generator:
cache_list.append(chunk)
for char in chunk:
time.sleep(0.01)
yield char
st.chat_message("assistant").write(capture(res_stream, response_messages))
st.session_state["message"].append({"role": "assistant", "content": response_messages[-1]})
st.rerun()