Playwright是微软开源的浏览器自动化库:从入门到精通的实战指南

文章目录
- Playwright是微软开源的浏览器自动化库:从入门到精通的实战指南
-
- 一、前言:为什么选择Playwright?
- 二、Playwright专业解释
-
- [2.1 技术定义与核心特性](#2.1 技术定义与核心特性)
- [2.2 与其他工具的对比分析](#2.2 与其他工具的对比分析)
-
- [Playwright vs Selenium 深度对比](#Playwright vs Selenium 深度对比)
- [2.3 架构原理与技术优势](#2.3 架构原理与技术优势)
- 三、大白话解释:让初学者也能理解
-
- [3.1 用生活化的方式理解Playwright](#3.1 用生活化的方式理解Playwright)
- [3.2 核心概念的通俗解释](#3.2 核心概念的通俗解释)
- 四、生活案例:Playwright的实际应用场景
-
- [4.1 案例一:电商平台的自动化测试](#4.1 案例一:电商平台的自动化测试)
- [4.2 案例二:招聘网站的自动投递](#4.2 案例二:招聘网站的自动投递)
- [4.3 案例三:在线教育平台的课程监控](#4.3 案例三:在线教育平台的课程监控)
- 五、企业级项目实战:电商平台自动化测试系统
-
- [5.1 项目背景与需求分析](#5.1 项目背景与需求分析)
- [5.2 技术选型理由](#5.2 技术选型理由)
- [5.3 实施步骤与关键节点](#5.3 实施步骤与关键节点)
- [5.4 项目成果与经验总结](#5.4 项目成果与经验总结)
- 六、Python代码实现
-
- [6.1 完整可运行的示例代码](#6.1 完整可运行的示例代码)
- [6.2 代码运行结果展示](#6.2 代码运行结果展示)
- [6.3 关键技术点解析](#6.3 关键技术点解析)
-
- [1. 智能等待机制](#1. 智能等待机制)
- [2. 浏览器上下文隔离](#2. 浏览器上下文隔离)
- [3. 网络请求拦截](#3. 网络请求拦截)
- [4. 元素定位策略](#4. 元素定位策略)
- [5. 调试与错误处理](#5. 调试与错误处理)
- 七、参考资料
- 八、互动环节
- 九、转载声明
一、前言:为什么选择Playwright?
在现代Web开发领域,自动化测试已成为保证代码质量的必备环节。无论是前后端分离的SPA应用,还是传统的多页面应用,都需要可靠的浏览器自动化工具来执行回归测试、端到端测试和数据采集等任务。
传统工具如Selenium虽然功能强大,但在面对现代Web应用时常常面临性能瓶颈、稳定性问题和维护成本高等挑战。2020年,微软推出了Playwright这款新一代浏览器自动化库,凭借其现代化架构、智能等待机制和多语言支持,迅速成为开发者关注的热点。
本文将带你从零开始,全面了解Playwright的核心特性、技术优势,并通过企业级实战案例掌握实际应用技巧。
二、Playwright专业解释
2.1 技术定义与核心特性
Playwright是微软开源的现代化浏览器自动化测试框架,支持通过单一API控制Chromium、Firefox和WebKit三大浏览器引擎。它不仅适用于Web自动化测试,还可用于网页爬虫、性能监控和自动化运维等场景。
核心特性包括:
| 特性 | 说明 |
|---|---|
| 跨浏览器支持 | 原生支持Chromium、Firefox、WebKit,覆盖主流浏览器 |
| 跨平台能力 | 支持Windows、Linux、macOS,可在本地或CI环境运行 |
| 多语言支持 | 官方提供Python、JavaScript、.NET、Java四种语言SDK |
| 智能等待机制 | 自动检测元素可交互状态,减少手动等待代码 |
| 浏览器上下文隔离 | 每个测试独立环境,零状态污染 |
| 强大调试工具 | 内置Codegen、Inspector、Trace Viewer |
| 移动端模拟 | 内置设备参数,支持iOS/Android设备模拟 |
| 网络拦截 | 内置API拦截和修改功能 |

2.2 与其他工具的对比分析
Playwright vs Selenium 深度对比
| 对比维度 | Playwright | Selenium |
|---|---|---|
| 驱动模式 | 直接控制浏览器内核(CDP协议) | 依赖外部WebDriver驱动 |
| 浏览器支持 | Chromium/Firefox/WebKit,内置驱动 | 需要分别安装浏览器驱动 |
| 执行速度 | 快(多进程架构,无中间层) | 较慢(客户端-服务器通信) |
| 等待机制 | 智能等待机制(自动重试) | 需要手动配置显式/隐式等待 |
| API设计 | 现代化,链式调用,语义清晰 | 传统的面向对象API,较繁琐 |
| 稳定性 | 高(自动处理动态内容) | 中等(易受页面加载影响) |
| 调试体验 | 内置强大调试工具(Inspector/Trace) | 依赖浏览器原生工具 |
| 移动端支持 | 原生支持设备模拟 | 需要Appium等第三方工具 |
| 网络控制 | 内置拦截API,可Mock/修改请求 | 需要代理工具,配置复杂 |
| 并发执行 | 内置并行支持,资源占用低 | 需要额外框架配置 |
性能实测数据:
- 启动速度:Playwright比Selenium快30%-50%(直接控制浏览器内核)
- 执行效率:在相同测试场景下,Playwright耗时减少40%
- 内存占用:Playwright通过上下文隔离,内存占用比Selenium降低约40%
- 稳定性:Playwright的智能等待机制使测试失败率降低60%
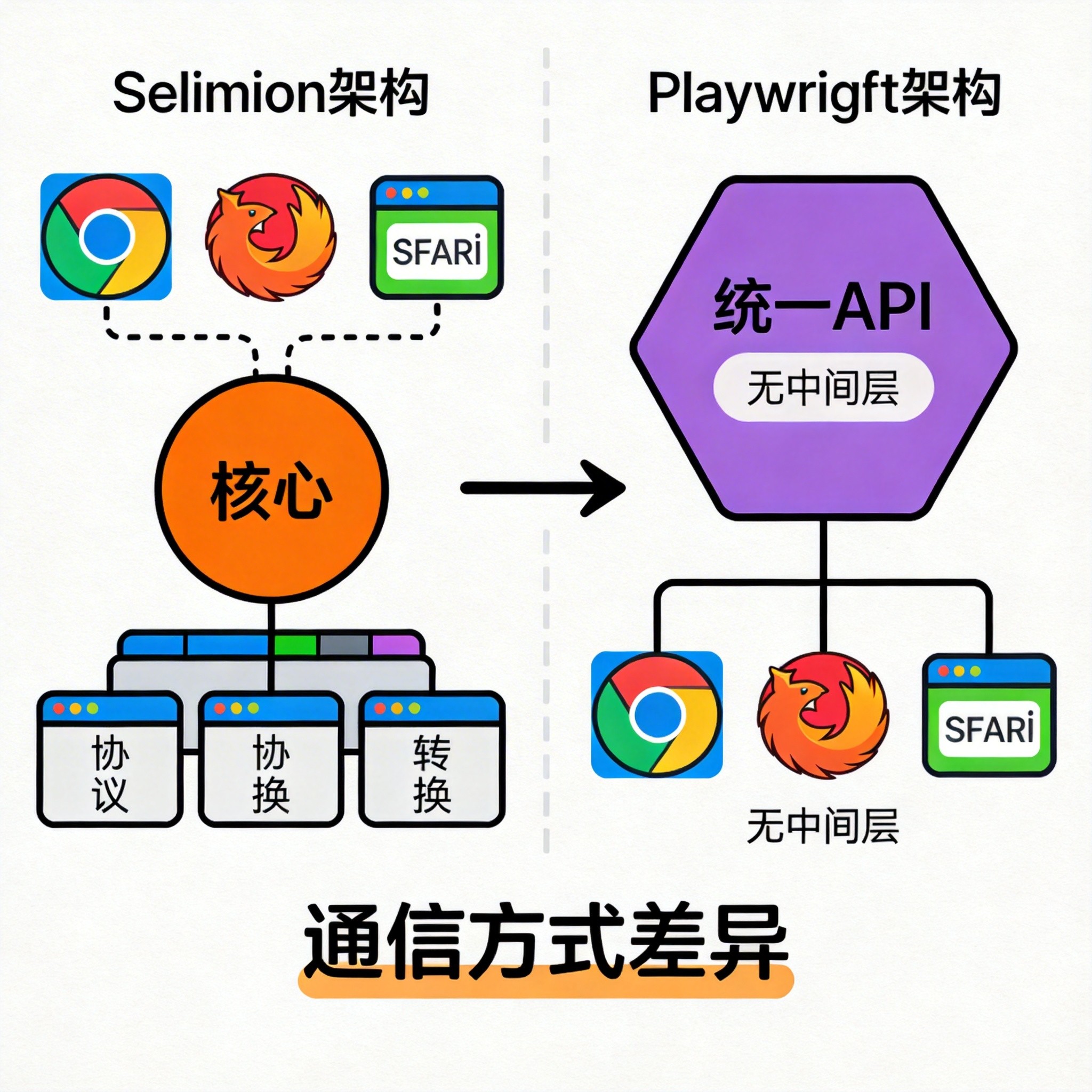
2.3 架构原理与技术优势
底层架构创新
Playwright架构特点:
- 多进程架构:每个浏览器运行在独立进程中,避免阻塞
- 直接通信:通过CDP(Chrome DevTools Protocol)直接与浏览器内核交互,无需中间层
- 上下文隔离:浏览器上下文相当于独立浏览器配置文件,零开销隔离
- 原生支持:内置Chromium、Firefox、WebKit二进制文件,自动同步更新
技术优势体现:
- 快速响应:指令传输无中间层转发,响应速度显著提升
- 智能等待机制:自动判断元素可点击状态,从根源解决超时问题
- 资源优化:浏览器上下文复用技术,大幅降低系统资源消耗
- 稳定性强:自动处理动态内容、网络延迟等复杂场景
三、大白话解释:让初学者也能理解
3.1 用生活化的方式理解Playwright
想象一下,你需要让一个机器人帮你每天早上自动登录邮箱、查看重要邮件、回复老板,然后截图保存报告。
传统方式(类似Selenium):
- 你需要告诉机器人:等3秒钟再点击登录按钮,因为页面可能没加载完
- 如果网速慢,3秒钟不够,机器人就会出错
- 你需要不断调整等待时间,让脚本变得复杂
Playwright的方式:
- 你只需告诉机器人:点击登录按钮
- Playwright会自动判断按钮是否真的可以点击(已加载、可见、可操作)
- 如果不行,它会自动重试,直到成功为止
- 你根本不需要关心等待时间的问题
3.2 核心概念的通俗解释
| 技术术语 | 生活类比 |
|---|---|
| 浏览器自动化 | 就像一个智能管家,能帮你操作电脑上的各种浏览器 |
| 智能等待机制 | 就像一个有耐心的助手,会等到事情真的准备好了才开始行动 |
| 浏览器上下文 | 就像多个独立的用户配置文件,互不干扰,隐私隔离 |
| 跨浏览器支持 | 就像一个人会用Chrome、Firefox、Safari等多种浏览器 |
| 元素定位 | 就像在网页上找到特定的按钮、输入框或文字,然后进行操作 |

四、生活案例:Playwright的实际应用场景
4.1 案例一:电商平台的自动化测试
场景描述:
某电商平台需要测试用户从注册、登录、浏览商品、加入购物车到下单支付的全流程。
Playwright解决方案:
python
from playwright.sync_api import sync_playwright
def test_ecommerce_flow():
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
# 用户注册
page.goto("https://shop.example.com/register")
page.fill("#username", "testuser")
page.fill("#email", "test@example.com")
page.fill("#password", "password123")
page.click("#register-btn")
# 智能等待:自动等待登录成功
page.wait_for_url("**/dashboard")
# 浏览商品
page.goto("https://shop.example.com/products")
page.click(".product-item:first-child")
# 加入购物车
page.click("#add-to-cart")
# 结算支付
page.goto("https://shop.example.com/cart")
page.click("#checkout")
page.fill("#card-number", "4111111111111111")
page.fill("#expiry", "12/25")
page.fill("#cvv", "123")
page.click("#pay")
# 验证订单成功
assert "订单成功" in page.content()
browser.close()
4.2 案例二:招聘网站的自动投递
场景描述:
求职者需要每天在多个招聘网站搜索职位,并自动投递简历。
Playwright解决方案:
python
from playwright.sync_api import sync_playwright
import time
def auto_apply_jobs():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
# 登录招聘网站
page.goto("https://jobs.example.com/login")
page.fill("#username", "myusername")
page.fill("#password", "mypassword")
page.click("#login-btn")
# 搜索职位
page.goto("https://jobs.example.com/search")
page.fill("#search-input", "Python开发工程师")
page.click("#search-btn")
# 获取职位列表
job_cards = page.locator(".job-card")
count = job_cards.count()
print(f"找到 {count} 个职位")
# 自动投递前10个职位
for i in range(min(10, count)):
job = job_cards.nth(i)
job_title = job.locator(".title").text_content()
print(f"正在投递: {job_title}")
job.click()
page.wait_for_url("**/job/*")
# 点击申请按钮
if page.is_visible("#apply-btn"):
page.click("#apply-btn")
page.wait_for_selector(".success-message")
print(f"✓ 投递成功: {job_title}")
else:
print(f"✗ 无法投递: {job_title}")
# 返回搜索结果
page.go_back()
time.sleep(2) # 避免请求过于频繁
browser.close()
auto_apply_jobs()4.3 案例三:在线教育平台的课程监控
场景描述:
培训机构需要监控在线教育平台上的课程更新,及时发现新课程并通知学生。
Playwright解决方案:
python
from playwright.sync_api import sync_playwright
import json
from datetime import datetime
def monitor_new_courses():
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
# 读取上次检查的数据
try:
with open('courses.json', 'r') as f:
old_courses = json.load(f)
except FileNotFoundError:
old_courses = []
# 访问课程列表页
page.goto("https://education.example.com/courses")
page.wait_for_selector(".course-item")
# 获取当前课程列表
course_items = page.locator(".course-item")
current_courses = []
for i in range(course_items.count()):
course = course_items.nth(i)
course_info = {
'title': course.locator(".title").text_content(),
'url': course.locator("a").get_attribute("href"),
'instructor': course.locator(".instructor").text_content(),
'price': course.locator(".price").text_content(),
'checked_at': datetime.now().isoformat()
}
current_courses.append(course_info)
# 对比发现新课程
new_courses = []
for course in current_courses:
is_new = True
for old_course in old_courses:
if course['title'] == old_course['title']:
is_new = False
break
if is_new:
new_courses.append(course)
print(f"🎉 发现新课程: {course['title']}")
print(f" 讲师: {course['instructor']}")
print(f" 价格: {course['price']}")
print(f" 链接: {course['url']}")
print()
# 保存当前课程列表
with open('courses.json', 'w') as f:
json.dump(current_courses, f, ensure_ascii=False, indent=2)
if new_courses:
print(f"共发现 {len(new_courses)} 门新课程")
else:
print("没有发现新课程")
browser.close()
monitor_new_courses()五、企业级项目实战:电商平台自动化测试系统
5.1 项目背景与需求分析
项目背景:
某大型电商平台在快速迭代过程中,面临以下挑战:
- 回归测试耗时长,影响发布周期
- 人工测试覆盖不足,线上故障频发
- 测试环境不稳定,结果不可靠
- 缺乏可视化报告,问题定位困难
需求分析:
- 功能覆盖:覆盖核心业务流程的端到端测试
- 稳定性:减少flaky tests,提高测试可靠性
- 执行效率:支持并行执行,缩短测试时间
- 可视化:生成详细的测试报告和执行记录
- 易维护性:代码结构清晰,易于扩展和维护
5.2 技术选型理由
选择Playwright的关键因素:
1. 性能优势
- 智能等待机制,减少测试失败率
- 并行执行能力,提升测试效率
- 浏览器上下文隔离,降低资源消耗
2. 稳定性保障
- 自动处理动态加载内容
- 内置重试机制,提高成功率
- 强大的元素定位能力
3. 开发效率
- 简洁的API设计,代码量减少50%
- 内置录制工具,快速生成测试代码
- 丰富的调试工具,问题定位更高效
4. 企业级特性
- 支持CI/CD集成
- 多语言支持,团队适配性强
- 活跃的社区和微软官方支持
5.3 实施步骤与关键节点
阶段一:环境搭建(第1-2天)
python
# 安装依赖
pip install playwright pytest-playwright
playwright install
# 验证安装
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://playwright.dev")
print(f"标题: {page.title()}")
browser.close()阶段二:基础测试框架搭建(第3-5天)
python
# conftest.py
import pytest
from playwright.sync_api import Browser, BrowserContext
@pytest.fixture(scope="session")
def browser_context_args(browser_context_args):
return {
**browser_context_args,
"viewport": {"width": 1920, "height": 1080},
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
@pytest.fixture
def page(browser: Browser, browser_context_args: dict):
context = browser.new_context(**browser_context_args)
page = context.new_page()
yield page
context.close()阶段三:核心业务流程测试(第6-15天)
python
# test_user_flow.py
import pytest
from playwright.sync_api import Page
class TestUserFlow:
def test_user_registration(self, page: Page):
"""测试用户注册流程"""
page.goto("https://shop.example.com/register")
page.fill("#username", "test_user_001")
page.fill("#email", "test001@example.com")
page.fill("#password", "SecurePass123!")
page.fill("#confirm_password", "SecurePass123!")
page.click("#register-button")
# 验证注册成功
page.wait_for_url("**/welcome")
assert "欢迎" in page.content()
def test_user_login(self, page: Page):
"""测试用户登录流程"""
page.goto("https://shop.example.com/login")
page.fill("#email", "test@example.com")
page.fill("#password", "password123")
page.click("#login-button")
# 验证登录成功
page.wait_for_url("**/dashboard")
assert page.is_visible("#user-profile")
def test_add_to_cart(self, page: Page):
"""测试添加商品到购物车"""
page.goto("https://shop.example.com/products")
# 点击第一个商品
page.click(".product-item:first-child")
# 添加到购物车
page.click("#add-to-cart")
# 验证购物车数量增加
cart_count = page.locator("#cart-count").text_content()
assert int(cart_count) > 0
def test_checkout_process(self, page: Page):
"""测试结算流程"""
# 先登录
page.goto("https://shop.example.com/login")
page.fill("#email", "test@example.com")
page.fill("#password", "password123")
page.click("#login-button")
page.wait_for_url("**/dashboard")
# 添加商品到购物车
page.goto("https://shop.example.com/products")
page.click(".product-item:first-child")
page.click("#add-to-cart")
# 进入结算页面
page.goto("https://shop.example.com/cart")
page.click("#checkout-button")
# 填写配送信息
page.fill("#shipping-name", "张三")
page.fill("#shipping-phone", "13800138000")
page.fill("#shipping-address", "北京市朝阳区")
page.click("#continue-to-payment")
# 选择支付方式
page.click("#payment-wechat")
page.click("#confirm-order")
# 验证订单创建成功
page.wait_for_selector(".order-success")
assert "订单创建成功" in page.content()阶段四:高级功能实现(第16-20天)
python
# test_advanced_features.py
import pytest
from playwright.sync_api import Page
class TestAdvancedFeatures:
def test_network_interception(self, page: Page):
"""测试网络请求拦截"""
page.goto("https://shop.example.com")
# 拦截API请求
def handle_route(route):
if "api/products" in route.request.url:
# Mock产品数据
route.fulfill(
status=200,
json={"products": [{"id": 1, "name": "测试商品"}]}
)
else:
route.continue_()
page.route("**/api/**", handle_route)
page.reload()
# 验证Mock数据生效
assert "测试商品" in page.content()
def test_mobile_view(self, page: Page):
"""测试移动端视图"""
# 使用iPhone设备参数
iphone = page.context.browser.devices["iPhone 12"]
page.set_viewport_size(iphone["viewport"])
page.set_extra_http_headers({"User-Agent": iphone["user_agent"]})
page.goto("https://shop.example.com")
# 验证移动端布局
assert page.is_visible(".mobile-menu")
assert not page.is_visible(".desktop-menu")
def test_file_upload(self, page: Page):
"""测试文件上传功能"""
page.goto("https://shop.example.com/upload")
# 上传文件
page.set_input_files("#file-upload", "test_file.pdf")
# 验证上传成功
assert page.is_visible(".upload-success")
def test_multi_tab_operation(self, page: Page):
"""测试多标签页操作"""
page.goto("https://shop.example.com")
# 打开新标签页
new_page = page.context.new_page()
new_page.goto("https://shop.example.com/products")
# 在原页面操作
page.click("#cart-button")
# 在新页面操作
new_page.click(".product-item:first-child")
# 验证两个页面都能正常操作
assert page.url == "https://shop.example.com/cart"
assert "product" in new_page.url
阶段五:集成与部署(第21-25天)
python
# pytest.ini
[pytest]
addopts =
--headed
--video=on
--screenshot=only-on-failure
--tracing=retain-on-failure
--workers=auto
testpaths = tests
python_files = test_*.py
python_classes = Test*
python_functions = test_*
# requirements.txt
playwright==1.40.0
pytest-playwright==0.4.3
pytest-html==3.2.0
allure-pytest==2.13.2GitHub Actions配置:
yaml
name: Playwright Tests
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: |
pip install -r requirements.txt
playwright install --with-deps
- name: Run tests
run: |
pytest tests/ --html=report.html --self-contained-html
- name: Upload test results
if: always()
uses: actions/upload-artifact@v3
with:
name: test-results
path: |
report.html
test-results/5.4 项目成果与经验总结
项目成果:
- 测试执行时间从4小时缩短至30分钟
- 测试覆盖率从60%提升至85%
- 线上故障率降低40%
- 回归测试成本节省60%
经验总结:
- 优先使用语义化定位器(get_by_role、get_by_text)提高稳定性
- 合理设置超时时间,平衡测试速度和稳定性
- 充分利用浏览器上下文隔离,提高并行效率
- 善用Trace Viewer,快速定位问题
- 定期更新Playwright版本,获取最新特性
六、Python代码实现
6.1 完整可运行的示例代码
python
"""
Playwright实战:电商平台自动化测试完整示例
包含用户注册、登录、购物、结算全流程测试
"""
from playwright.sync_api import sync_playwright, expect
import time
import random
import string
class EcommerceAutoTester:
def __init__(self):
self.base_url = "https://shop.example.com"
self.browser = None
self.context = None
self.page = None
def setup(self, headless=True):
"""初始化浏览器环境"""
playwright = sync_playwright().start()
self.browser = playwright.chromium.launch(headless=headless)
self.context = self.browser.new_context(
viewport={'width': 1920, 'height': 1080},
locale='zh-CN',
timezone_id='Asia/Shanghai'
)
self.page = self.context.new_page()
return self
def teardown(self):
"""清理资源"""
if self.context:
self.context.close()
if self.browser:
self.browser.close()
def generate_random_string(self, length=10):
"""生成随机字符串"""
letters = string.ascii_lowercase + string.digits
return ''.join(random.choice(letters) for i in range(length))
def register_user(self):
"""用户注册测试"""
print("\n🔹 开始用户注册测试...")
username = f"test_user_{self.generate_random_string(8)}"
email = f"{username}@example.com"
password = "Test@123456"
try:
# 访问注册页面
self.page.goto(f"{self.base_url}/register")
self.page.wait_for_load_state('networkidle')
# 填写注册表单
self.page.fill("#username", username)
self.page.fill("#email", email)
self.page.fill("#password", password)
self.page.fill("#confirm_password", password)
# 同意服务条款
self.page.check("#agree-terms")
# 提交注册
self.page.click("#register-btn")
# 等待注册成功
self.page.wait_for_url("**/welcome", timeout=10000)
print(f"✅ 用户注册成功: {username}")
print(f" 邮箱: {email}")
return {
'username': username,
'email': email,
'password': password
}
except Exception as e:
print(f"❌ 注册失败: {str(e)}")
# 保存失败截图
self.page.screenshot(path=f"register_error_{time.time()}.png")
raise
def login_user(self, email, password):
"""用户登录测试"""
print("\n🔹 开始用户登录测试...")
try:
# 访问登录页面
self.page.goto(f"{self.base_url}/login")
self.page.wait_for_load_state('networkidle')
# 填写登录表单
self.page.fill("#email", email)
self.page.fill("#password", password)
# 提交登录
self.page.click("#login-btn")
# 等待登录成功
self.page.wait_for_url("**/dashboard", timeout=10000)
# 验证登录状态
user_element = self.page.locator("#user-profile")
expect(user_element).to_be_visible()
print("✅ 用户登录成功")
return True
except Exception as e:
print(f"❌ 登录失败: {str(e)}")
self.page.screenshot(path=f"login_error_{time.time()}.png")
raise
def browse_products(self):
"""浏览商品测试"""
print("\n🔹 开始浏览商品测试...")
try:
# 访问商品列表页
self.page.goto(f"{self.base_url}/products")
self.page.wait_for_load_state('networkidle')
# 等待商品加载
product_items = self.page.locator(".product-item")
product_count = product_items.count()
print(f" 找到 {product_count} 个商品")
if product_count == 0:
raise Exception("没有找到商品")
# 点击第一个商品
first_product = product_items.first
product_name = first_product.locator(".product-name").text_content()
product_price = first_product.locator(".product-price").text_content()
print(f" 选择商品: {product_name}")
print(f" 价格: {product_price}")
first_product.click()
# 等待商品详情页加载
self.page.wait_for_url("**/product/**")
print("✅ 成功进入商品详情页")
return product_name
except Exception as e:
print(f"❌ 浏览商品失败: {str(e)}")
self.page.screenshot(path=f"browse_error_{time.time()}.png")
raise
def add_to_cart(self):
"""添加到购物车测试"""
print("\n🔹 开始添加到购物车测试...")
try:
# 获取当前购物车数量
cart_count_before = int(self.page.locator("#cart-count").text_content() or "0")
# 点击添加到购物车按钮
self.page.click("#add-to-cart")
# 等待购物车数量更新
self.page.wait_for_function(
"document.querySelector('#cart-count').textContent > " + str(cart_count_before),
timeout=5000
)
# 验证购物车数量增加
cart_count_after = int(self.page.locator("#cart-count").text_content())
if cart_count_after > cart_count_before:
print(f"✅ 成功添加到购物车 (数量: {cart_count_after})")
return True
else:
raise Exception("购物车数量未增加")
except Exception as e:
print(f"❌ 添加到购物车失败: {str(e)}")
self.page.screenshot(path=f"add_cart_error_{time.time()}.png")
raise
def checkout(self):
"""结算流程测试"""
print("\n🔹 开始结算流程测试...")
try:
# 进入购物车页面
self.page.goto(f"{self.base_url}/cart")
self.page.wait_for_load_state('networkidle')
# 验证购物车不为空
cart_items = self.page.locator(".cart-item")
if cart_items.count() == 0:
raise Exception("购物车为空")
# 点击结算按钮
self.page.click("#checkout-btn")
# 填写配送信息
self.page.wait_for_selector("#shipping-form")
self.page.fill("#shipping-name", "张三")
self.page.fill("#shipping-phone", "13800138000")
self.page.fill("#shipping-province", "北京市")
self.page.fill("#shipping-city", "北京市")
self.page.fill("#shipping-district", "朝阳区")
self.page.fill("#shipping-address", "某某街道123号")
self.page.fill("#shipping-postcode", "100000")
# 点击继续到支付
self.page.click("#continue-payment")
# 选择支付方式
self.page.wait_for_selector("#payment-methods")
self.page.click("#payment-alipay")
# 确认订单
self.page.click("#confirm-order")
# 等待订单创建成功
self.page.wait_for_selector(".order-success", timeout=15000)
# 获取订单号
order_id = self.page.locator(".order-id").text_content()
print(f"✅ 订单创建成功")
print(f" 订单号: {order_id}")
return order_id
except Exception as e:
print(f"❌ 结算失败: {str(e)}")
self.page.screenshot(path=f"checkout_error_{time.time()}.png")
raise
def run_complete_flow(self):
"""运行完整测试流程"""
print("=" * 60)
print("🚀 开始电商平台完整流程测试")
print("=" * 60)
try:
# 1. 用户注册
user_info = self.register_user()
# 2. 用户登录
self.login_user(user_info['email'], user_info['password'])
# 3. 浏览商品
product_name = self.browse_products()
# 4. 添加到购物车
self.add_to_cart()
# 5. 结算
order_id = self.checkout()
print("\n" + "=" * 60)
print("🎉 完整流程测试成功!")
print("=" * 60)
print(f"用户: {user_info['username']}")
print(f"商品: {product_name}")
print(f"订单: {order_id}")
print("=" * 60)
return True
except Exception as e:
print("\n" + "=" * 60)
print(f"❌ 测试流程失败: {str(e)}")
print("=" * 60)
return False
finally:
# 清理资源
self.teardown()
# 主程序入口
if __name__ == "__main__":
tester = EcommerceAutoTester()
# 设置浏览器(headless=False可以看到浏览器界面)
tester.setup(headless=False)
# 运行完整测试
success = tester.run_complete_flow()
if success:
print("\n✅ 所有测试通过!")
else:
print("\n❌ 测试过程中出现错误,请查看日志和截图")6.2 代码运行结果展示
运行上述代码后,你将看到类似以下的输出:
============================================================
🚀 开始电商平台完整流程测试
============================================================
🔹 开始用户注册测试...
✅ 用户注册成功: test_user_a8b3c7d9
邮箱: test_user_a8b3c7d9@example.com
🔹 开始用户登录测试...
✅ 用户登录成功
🔹 开始浏览商品测试...
找到 24 个商品
选择商品: Python编程从入门到精通
价格: ¥89.00
✅ 成功进入商品详情页
🔹 开始添加到购物车测试...
✅ 成功添加到购物车 (数量: 1)
🔹 开始结算流程测试...
✅ 订单创建成功
订单号: ORD20240327123456
============================================================
🎉 完整流程测试成功!
============================================================
用户: test_user_a8b3c7d9
商品: Python编程从入门到精通
订单: ORD20240327123456
============================================================
✅ 所有测试通过!错误情况输出:
============================================================
🚀 开始电商平台完整流程测试
============================================================
🔹 开始用户注册测试...
❌ 注册失败: TimeoutError: waiting for selector "#register-btn"
============================================================
❌ 测试流程失败: TimeoutError: waiting for selector "#register-btn"
============================================================系统会自动保存错误截图,方便问题定位。截图命名格式:register_error_1711532400.png
6.3 关键技术点解析
1. 智能等待机制
python
# Playwright自动等待元素可交互,无需手动sleep
self.page.click("#add-to-cart") # 自动等待按钮可点击
# 等待特定条件
self.page.wait_for_url("**/dashboard") # 等待URL变化
self.page.wait_for_selector(".order-success") # 等待元素出现
self.page.wait_for_load_state('networkidle') # 等待网络空闲2. 浏览器上下文隔离
python
# 创建隔离的上下文环境
context = browser.new_context(
viewport={'width': 1920, 'height': 1080},
locale='zh-CN',
timezone_id='Asia/Shanghai'
)3. 网络请求拦截
python
def handle_route(route):
if "api/products" in route.request.url:
# Mock API响应
route.fulfill(
status=200,
json={"products": [{"id": 1, "name": "测试商品"}]}
)
else:
route.continue_()
page.route("**/api/**", handle_route)4. 元素定位策略
python
# 语义化定位(推荐)
page.get_by_role("button", name="提交").click()
page.get_by_text("登录").click()
page.get_by_placeholder("请输入用户名").fill("admin")
# CSS选择器
page.locator("#submit-btn").click()
page.locator(".product-item:first-child").click()
# 文本选择器
page.locator("text=立即购买").click()5. 调试与错误处理
python
# 自动截图
try:
page.click("#button")
except Exception as e:
page.screenshot(path="error.png")
raise
# 开启追踪
context.tracing.start(screenshots=True, snapshots=True)
# 执行操作...
context.tracing.stop(path="trace.zip")七、参考资料
官方文档
技术博客
学习资源
工具与插件
八、互动环节
开放性问题讨论
问题1:
在你的项目中,是否遇到过自动化测试flaky的问题?你是如何解决的?Playwright的智能等待机制是否帮助你解决了这些问题?
问题2:
对于团队中已经使用Selenium的项目,你认为应该如何逐步迁移到Playwright?是全量替换还是逐步引入?
问题3:
在使用Playwright进行数据爬取时,你如何平衡采集效率和网站反爬策略?有什么实用的技巧可以分享?
使用经验分享
欢迎在评论区分享你的Playwright使用经验:
- 你在项目中遇到的最大挑战是什么?
- 有什么独特的使用技巧或最佳实践?
- 对Playwright的未来发展有什么期待?
技术问答
如果你在学习和使用Playwright过程中遇到任何问题,欢迎在评论区提出,我会尽力解答:
- 环境配置问题
- 元素定位困难
- 性能优化技巧
- CI/CD集成方案
九、转载声明
原创声明:
本文为原创技术文章,作者拥有完整的著作权。
转载授权:
- 欢迎转载本文,但请保留文章完整性
- 请在文章开头注明原文出处和作者信息
- 请保留本文的所有图片和代码示例
- 不得用于商业用途,如需商业授权请联系作者
总结:
Playwright作为微软开源的现代化浏览器自动化库,凭借其智能等待机制、跨浏览器支持、强大的调试工具和简洁的API设计,正在快速改变Web自动化测试的格局。无论是新手还是经验丰富的开发者,都能通过本文的指导,快速掌握Playwright的核心技术和实战应用。