文章目录
-
- 一、理论原理(简明直觉)
-
- [1. 神经网络本质是复合函数](#1. 神经网络本质是复合函数)
- [2. 为什么要"反向传播"](#2. 为什么要“反向传播”)
- [3. 为什么 sigmoid + 交叉熵会特别简洁](#3. 为什么 sigmoid + 交叉熵会特别简洁)
- 二、网络结构与前向传播(把题目抄清楚)
-
- [1. 隐藏层加权和](#1. 隐藏层加权和)
- [2. 隐藏层激活(sigmoid)](#2. 隐藏层激活(sigmoid))
- [3. 输出层加权和](#3. 输出层加权和)
- [4. 输出层激活(sigmoid)](#4. 输出层激活(sigmoid))
- [5. 单样本二元交叉熵损失](#5. 单样本二元交叉熵损失)
- 三、反向传播:从输出端开始按链式法则往回推
- 四、逐项推导各个偏导数(从右到左)
-
- [1. 损失对输出 y y y 的梯度](#1. 损失对输出 y y y 的梯度)
- [2. 损失对输出层加权和 b b b 的梯度(输出误差项)](#2. 损失对输出层加权和 b b b 的梯度(输出误差项))
- [3. 损失对输出层权重 β j \beta_j βj 的梯度](#3. 损失对输出层权重 β j \beta_j βj 的梯度)
- [4. 损失对隐藏层输出 z j z_j zj 的梯度](#4. 损失对隐藏层输出 z j z_j zj 的梯度)
- [5. 损失对隐藏层加权和 a j a_j aj 的梯度(隐藏层误差项)](#5. 损失对隐藏层加权和 a j a_j aj 的梯度(隐藏层误差项))
- [6. 损失对输入到隐藏层权重 α j i \alpha_{ji} αji 的梯度](#6. 损失对输入到隐藏层权重 α j i \alpha_{ji} αji 的梯度)
- [7.(可选)损失对输入 x i x_i xi 的梯度](#7.(可选)损失对输入 x i x_i xi 的梯度)
- 五、把前向与反向"串成一套可实现的算法"
-
- [1. 前向(必须保存)](#1. 前向(必须保存))
- [2. 反向(先误差项,再权重梯度)](#2. 反向(先误差项,再权重梯度))
- 六、用"路径乘积"再看一遍:反向传播到底省了什么
-
- [示例: D = 3 D=3 D=3、 M = 2 M=2 M=2 时"公共后缀梯度"如何复用](#示例: D = 3 D=3 D=3、 M = 2 M=2 M=2 时“公共后缀梯度”如何复用)
- 七、最终可直接记住的"实现级公式"清单
本文用一个最典型的「一层隐藏层 + 输出层」前馈神经网络(全 sigmoid),把网络与符号抄清楚,再从前向传播开始,按链式法则逐项推导出所有关键偏导数,最后整理成一套可直接实现的反向传播流程。
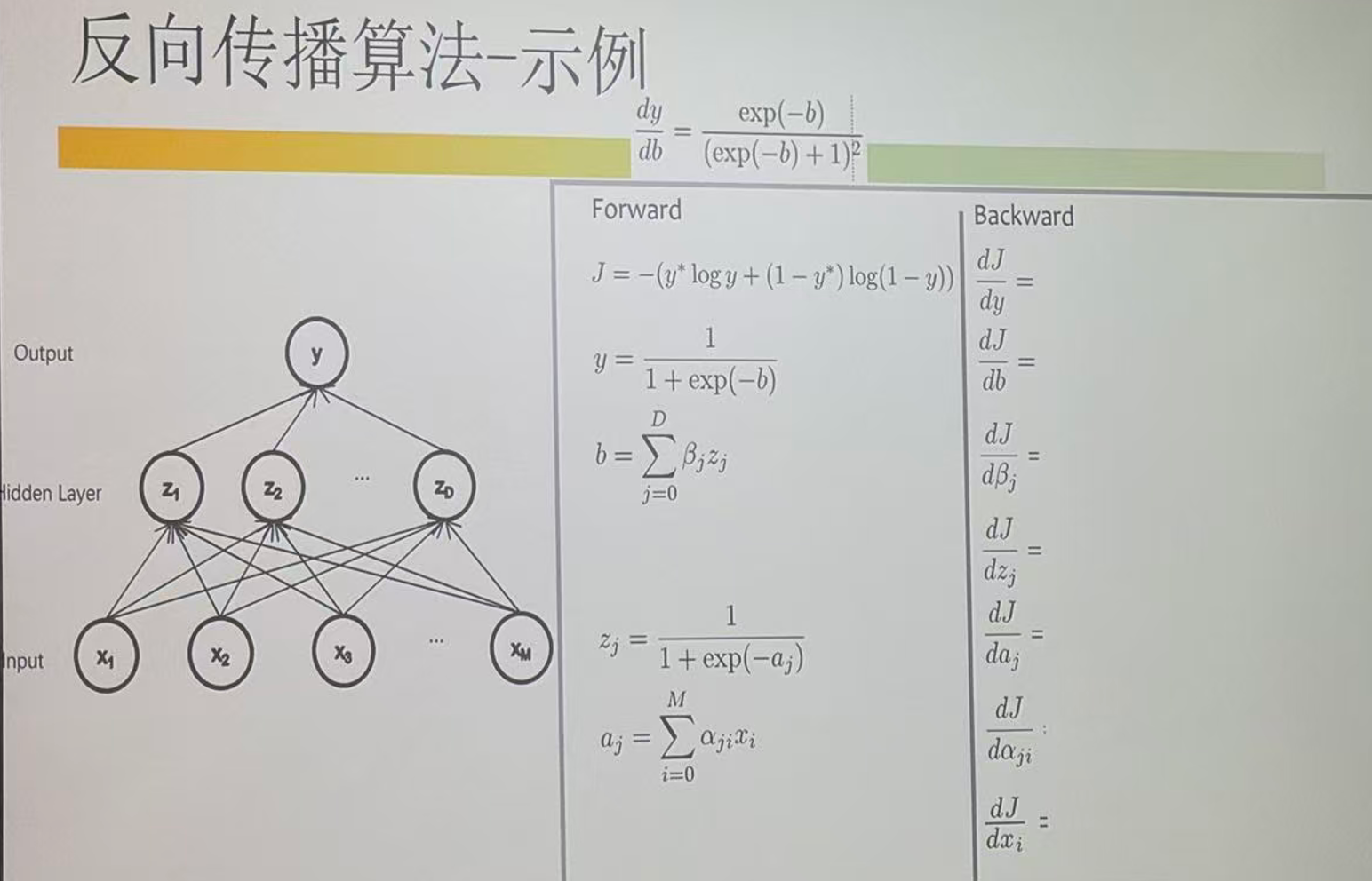
全程围绕同一条计算图:
x → a → z → b → y → J x \;\rightarrow\; a \;\rightarrow\; z \;\rightarrow\; b \;\rightarrow\; y \;\rightarrow\; J x→a→z→b→y→J
一、理论原理(简明直觉)
1. 神经网络本质是复合函数
两层网络可以视为一串函数复合:
x → α a → σ z → β b → σ y → loss J x \xrightarrow{\;\alpha\;} a \xrightarrow{\;\sigma\;} z \xrightarrow{\;\beta\;} b \xrightarrow{\;\sigma\;} y \xrightarrow{\;\text{loss}\;} J xα aσ zβ bσ yloss J
因此损失就是复合函数:
J = J ( y ( b ( z ( a ( x ) ) ) ) ) J = J\big(y(b(z(a(x))))\big) J=J(y(b(z(a(x)))))
复合函数求导的唯一规则就是链式法则。
2. 为什么要"反向传播"
如果对每个权重都从头展开一次链式法则,会反复计算相同的后缀(比如 b → y → J b\to y\to J b→y→J),非常低效。反向传播做的是:
- 从输出端先算一次"公共后缀"的梯度(例如 ∂ J ∂ b \frac{\partial J}{\partial b} ∂b∂J)
- 再把它逐层往前传,得到各层"误差项"(例如 ∂ J ∂ a j \frac{\partial J}{\partial a_j} ∂aj∂J)
- 最后用"误差项 × 输入激活"一次性得到该层所有权重梯度
这相当于把链式法则做成了可复用的"动态规划"。
3. 为什么 sigmoid + 交叉熵会特别简洁
在本题组合下(输出层 sigmoid + 二元交叉熵),会得到非常经典的化简:
∂ J ∂ b = y − y ∗ \frac{\partial J}{\partial b}=y-y^* ∂b∂J=y−y∗
这使得输出层误差项既简洁又易于实现,后续梯度表达式也会自然呈现"误差 × 输入"的统一结构。
二、网络结构与前向传播(把题目抄清楚)
这是一个「一层隐藏层 + 输出层」的前馈网络,所有激活函数都是 sigmoid。
- 输入层: x 1 , ... , x M x_1,\dots,x_M x1,...,xM,并引入偏置输入 x 0 = 1 x_0=1 x0=1
- 隐藏层: z 1 , ... , z D z_1,\dots,z_D z1,...,zD,并引入偏置单元 z 0 = 1 z_0=1 z0=1
- 输出层:标量 y y y
- 输入 → \to →隐藏权重: α j i \alpha_{ji} αji(从 x i x_i xi 到 z j z_j zj)
- 隐藏 → \to →输出权重: β j \beta_j βj(从 z j z_j zj 到输出)
1. 隐藏层加权和
对每个 j = 1 , ... , D j=1,\dots,D j=1,...,D:
a j = ∑ i = 0 M α j i x i ( x 0 = 1 ) a_j=\sum_{i=0}^{M}\alpha_{ji}x_i \qquad (x_0=1) aj=i=0∑Mαjixi(x0=1)
2. 隐藏层激活(sigmoid)
z j = σ ( a j ) = 1 1 + exp ( − a j ) z_j=\sigma(a_j)=\frac{1}{1+\exp(-a_j)} zj=σ(aj)=1+exp(−aj)1
并约定偏置单元:
z 0 = 1 z_0=1 z0=1
3. 输出层加权和
b = ∑ j = 0 D β j z j ( z 0 = 1 ) b=\sum_{j=0}^{D}\beta_j z_j \qquad (z_0=1) b=j=0∑Dβjzj(z0=1)
4. 输出层激活(sigmoid)
y = σ ( b ) = 1 1 + exp ( − b ) y=\sigma(b)=\frac{1}{1+\exp(-b)} y=σ(b)=1+exp(−b)1
5. 单样本二元交叉熵损失
真实标签 y ∗ ∈ { 0 , 1 } y^*\in\{0,1\} y∗∈{0,1}:
J = − ( y ∗ log y + ( 1 − y ∗ ) log ( 1 − y ) ) J=-\Big(y^*\log y+(1-y^*)\log(1-y)\Big) J=−(y∗logy+(1−y∗)log(1−y))
到这里为止,前向传播完成:从 x → a → z → b → y → J x\rightarrow a\rightarrow z\rightarrow b\rightarrow y\rightarrow J x→a→z→b→y→J。
三、反向传播:从输出端开始按链式法则往回推
先记住 sigmoid 的导数(对任意 t t t):
d σ ( t ) d t = σ ( t ) ( 1 − σ ( t ) ) \frac{d\,\sigma(t)}{dt}=\sigma(t)\big(1-\sigma(t)\big) dtdσ(t)=σ(t)(1−σ(t))
因此:
∂ y ∂ b = y ( 1 − y ) , ∂ z j ∂ a j = z j ( 1 − z j ) \frac{\partial y}{\partial b}=y(1-y),\qquad \frac{\partial z_j}{\partial a_j}=z_j(1-z_j) ∂b∂y=y(1−y),∂aj∂zj=zj(1−zj)
四、逐项推导各个偏导数(从右到左)
1. 损失对输出 y y y 的梯度
把 J J J 看作 J ( y ) J(y) J(y):
∂ J ∂ y = − ( y ∗ y − 1 − y ∗ 1 − y ) \frac{\partial J}{\partial y} = -\left(\frac{y^*}{y}-\frac{1-y^*}{1-y}\right) ∂y∂J=−(yy∗−1−y1−y∗)
2. 损失对输出层加权和 b b b 的梯度(输出误差项)
链式法则:
∂ J ∂ b = ∂ J ∂ y ⋅ ∂ y ∂ b = ∂ J ∂ y ⋅ y ( 1 − y ) \frac{\partial J}{\partial b} =\frac{\partial J}{\partial y}\cdot\frac{\partial y}{\partial b} =\frac{\partial J}{\partial y}\cdot y(1-y) ∂b∂J=∂y∂J⋅∂b∂y=∂y∂J⋅y(1−y)
在"sigmoid + 二元交叉熵"的组合下可化简为:
∂ J ∂ b = y − y ∗ \frac{\partial J}{\partial b}=y-y^* ∂b∂J=y−y∗
定义输出层误差项:
δ ( out ) ≜ ∂ J ∂ b = y − y ∗ \delta^{(\text{out})}\triangleq \frac{\partial J}{\partial b}=y-y^* δ(out)≜∂b∂J=y−y∗
3. 损失对输出层权重 β j \beta_j βj 的梯度
由于:
b = ∑ j = 0 D β j z j ⇒ ∂ b ∂ β j = z j b=\sum_{j=0}^{D}\beta_j z_j \quad\Rightarrow\quad \frac{\partial b}{\partial \beta_j}=z_j b=j=0∑Dβjzj⇒∂βj∂b=zj
所以:
∂ J ∂ β j = ∂ J ∂ b ⋅ ∂ b ∂ β j = ( y − y ∗ ) z j = δ ( out ) z j \frac{\partial J}{\partial \beta_j} =\frac{\partial J}{\partial b}\cdot\frac{\partial b}{\partial \beta_j} =(y-y^*)\,z_j =\delta^{(\text{out})}z_j ∂βj∂J=∂b∂J⋅∂βj∂b=(y−y∗)zj=δ(out)zj
偏置权重对应 z 0 = 1 z_0=1 z0=1:
∂ J ∂ β 0 = y − y ∗ \frac{\partial J}{\partial \beta_0}=y-y^* ∂β0∂J=y−y∗
4. 损失对隐藏层输出 z j z_j zj 的梯度
因为:
∂ b ∂ z j = β j \frac{\partial b}{\partial z_j}=\beta_j ∂zj∂b=βj
所以:
∂ J ∂ z j = ∂ J ∂ b ⋅ ∂ b ∂ z j = ( y − y ∗ ) β j = δ ( out ) β j \frac{\partial J}{\partial z_j} =\frac{\partial J}{\partial b}\cdot\frac{\partial b}{\partial z_j} =(y-y^*)\,\beta_j =\delta^{(\text{out})}\beta_j ∂zj∂J=∂b∂J⋅∂zj∂b=(y−y∗)βj=δ(out)βj
5. 损失对隐藏层加权和 a j a_j aj 的梯度(隐藏层误差项)
因为 z j = σ ( a j ) z_j=\sigma(a_j) zj=σ(aj):
∂ J ∂ a j = ∂ J ∂ z j ⋅ ∂ z j ∂ a j = ( ( y − y ∗ ) β j ) ⋅ z j ( 1 − z j ) \frac{\partial J}{\partial a_j} =\frac{\partial J}{\partial z_j}\cdot\frac{\partial z_j}{\partial a_j} =\big((y-y^*)\beta_j\big)\cdot z_j(1-z_j) ∂aj∂J=∂zj∂J⋅∂aj∂zj=((y−y∗)βj)⋅zj(1−zj)
定义隐藏层误差项:
δ j ( hid ) ≜ ∂ J ∂ a j = ( y − y ∗ ) β j z j ( 1 − z j ) = δ ( out ) β j z j ( 1 − z j ) \delta_j^{(\text{hid})}\triangleq \frac{\partial J}{\partial a_j} =(y-y^*)\,\beta_j\,z_j(1-z_j) =\delta^{(\text{out})}\beta_j z_j(1-z_j) δj(hid)≜∂aj∂J=(y−y∗)βjzj(1−zj)=δ(out)βjzj(1−zj)
6. 损失对输入到隐藏层权重 α j i \alpha_{ji} αji 的梯度
由:
a j = ∑ i = 0 M α j i x i ⇒ ∂ a j ∂ α j i = x i a_j=\sum_{i=0}^{M}\alpha_{ji}x_i \quad\Rightarrow\quad \frac{\partial a_j}{\partial \alpha_{ji}}=x_i aj=i=0∑Mαjixi⇒∂αji∂aj=xi
所以:
∂ J ∂ α j i = ∂ J ∂ a j ⋅ ∂ a j ∂ α j i = δ j ( hid ) x i \frac{\partial J}{\partial \alpha_{ji}} =\frac{\partial J}{\partial a_j}\cdot\frac{\partial a_j}{\partial \alpha_{ji}} =\delta_j^{(\text{hid})}\,x_i ∂αji∂J=∂aj∂J⋅∂αji∂aj=δj(hid)xi
展开即:
∂ J ∂ α j i = ( y − y ∗ ) β j z j ( 1 − z j ) x i \frac{\partial J}{\partial \alpha_{ji}} =(y-y^*)\,\beta_j\,z_j(1-z_j)\,x_i ∂αji∂J=(y−y∗)βjzj(1−zj)xi
偏置权重对应 x 0 = 1 x_0=1 x0=1:
∂ J ∂ α j 0 = δ j ( hid ) \frac{\partial J}{\partial \alpha_{j0}}=\delta_j^{(\text{hid})} ∂αj0∂J=δj(hid)
7.(可选)损失对输入 x i x_i xi 的梯度
如果还要继续往更前面的模块反传,注意 x i x_i xi 影响所有隐藏单元,需要求和:
∂ J ∂ x i = ∑ j = 1 D ∂ J ∂ a j ⋅ ∂ a j ∂ x i \frac{\partial J}{\partial x_i} =\sum_{j=1}^{D}\frac{\partial J}{\partial a_j}\cdot\frac{\partial a_j}{\partial x_i} ∂xi∂J=j=1∑D∂aj∂J⋅∂xi∂aj
且:
∂ a j ∂ x i = α j i \frac{\partial a_j}{\partial x_i}=\alpha_{ji} ∂xi∂aj=αji
因此:
∂ J ∂ x i = ∑ j = 1 D δ j ( hid ) α j i = ∑ j = 1 D ( y − y ∗ ) β j z j ( 1 − z j ) α j i \frac{\partial J}{\partial x_i} =\sum_{j=1}^{D}\delta_j^{(\text{hid})}\alpha_{ji} =\sum_{j=1}^{D}(y-y^*)\,\beta_j\,z_j(1-z_j)\,\alpha_{ji} ∂xi∂J=j=1∑Dδj(hid)αji=j=1∑D(y−y∗)βjzj(1−zj)αji
五、把前向与反向"串成一套可实现的算法"
写成实现层面的顺序,就是"先前向存变量,再反向算误差,最后出梯度"。
1. 前向(必须保存)
- 计算 a j a_j aj、 z j z_j zj
- 计算 b b b、 y y y
- 需要监控时再计算 J J J
2. 反向(先误差项,再权重梯度)
输出误差项:
δ ( out ) = y − y ∗ \delta^{(\text{out})}=y-y^* δ(out)=y−y∗
输出层权重梯度(含偏置 j = 0 j=0 j=0):
∂ J ∂ β j = δ ( out ) z j \frac{\partial J}{\partial \beta_j}=\delta^{(\text{out})}z_j ∂βj∂J=δ(out)zj
隐藏层误差项( j = 1 , ... , D j=1,\dots,D j=1,...,D):
δ j ( hid ) = δ ( out ) β j z j ( 1 − z j ) \delta_j^{(\text{hid})}=\delta^{(\text{out})}\beta_j z_j(1-z_j) δj(hid)=δ(out)βjzj(1−zj)
输入到隐藏层权重梯度(含偏置 i = 0 i=0 i=0):
∂ J ∂ α j i = δ j ( hid ) x i \frac{\partial J}{\partial \alpha_{ji}}=\delta_j^{(\text{hid})}x_i ∂αji∂J=δj(hid)xi
这套流程对应的统一模式是:
某层权重梯度 = ( 该层误差项 ) × ( 该权重输入激活 ) \text{某层权重梯度} = (\text{该层误差项}) \times (\text{该权重输入激活}) 某层权重梯度=(该层误差项)×(该权重输入激活)
六、用"路径乘积"再看一遍:反向传播到底省了什么
以 α j i \alpha_{ji} αji 为例,它到 J J J 的路径是:
α j i → a j → z j → b → y → J \alpha_{ji}\rightarrow a_j\rightarrow z_j\rightarrow b\rightarrow y\rightarrow J αji→aj→zj→b→y→J
直接写链式法则:
∂ J ∂ α j i = ∂ J ∂ y ⋅ ∂ y ∂ b ⋅ ∂ b ∂ z j ⋅ ∂ z j ∂ a j ⋅ ∂ a j ∂ α j i \frac{\partial J}{\partial \alpha_{ji}} =\frac{\partial J}{\partial y} \cdot\frac{\partial y}{\partial b} \cdot\frac{\partial b}{\partial z_j} \cdot\frac{\partial z_j}{\partial a_j} \cdot\frac{\partial a_j}{\partial \alpha_{ji}} ∂αji∂J=∂y∂J⋅∂b∂y⋅∂zj∂b⋅∂aj∂zj⋅∂αji∂aj
局部导数分别是:
∂ y ∂ b = y ( 1 − y ) , ∂ b ∂ z j = β j , ∂ z j ∂ a j = z j ( 1 − z j ) , ∂ a j ∂ α j i = x i \frac{\partial y}{\partial b}=y(1-y),\quad \frac{\partial b}{\partial z_j}=\beta_j,\quad \frac{\partial z_j}{\partial a_j}=z_j(1-z_j),\quad \frac{\partial a_j}{\partial \alpha_{ji}}=x_i ∂b∂y=y(1−y),∂zj∂b=βj,∂aj∂zj=zj(1−zj),∂αji∂aj=xi
反向传播的高效点在于:像 ∂ J ∂ b \frac{\partial J}{\partial b} ∂b∂J、 ∂ J ∂ a j \frac{\partial J}{\partial a_j} ∂aj∂J 这种"公共后缀梯度"只算一次,然后被大量权重共享复用,避免重复展开整条链。
示例: D = 3 D=3 D=3、 M = 2 M=2 M=2 时"公共后缀梯度"如何复用
假设隐藏层有 z 1 , z 2 , z 3 z_1,z_2,z_3 z1,z2,z3(并含偏置 z 0 = 1 z_0=1 z0=1),输入有 x 1 , x 2 x_1,x_2 x1,x2(并含偏置 x 0 = 1 x_0=1 x0=1)。输出层加权和为:
b = β 0 + β 1 z 1 + β 2 z 2 + β 3 z 3 , y = σ ( b ) b=\beta_0+\beta_1 z_1+\beta_2 z_2+\beta_3 z_3,\qquad y=\sigma(b) b=β0+β1z1+β2z2+β3z3,y=σ(b)
在"sigmoid + 二元交叉熵"的组合下,我们先得到一次输出层公共后缀梯度:
δ ( out ) ≜ ∂ J ∂ b = y − y ∗ \delta^{(\text{out})}\triangleq \frac{\partial J}{\partial b}=y-y^* δ(out)≜∂b∂J=y−y∗
接下来输出层每一条权重的梯度都共享这同一个 δ ( out ) \delta^{(\text{out})} δ(out):
∂ J ∂ β 1 = δ ( out ) z 1 , ∂ J ∂ β 2 = δ ( out ) z 2 , ∂ J ∂ β 3 = δ ( out ) z 3 \frac{\partial J}{\partial \beta_1}=\delta^{(\text{out})}z_1,\qquad \frac{\partial J}{\partial \beta_2}=\delta^{(\text{out})}z_2,\qquad \frac{\partial J}{\partial \beta_3}=\delta^{(\text{out})}z_3 ∂β1∂J=δ(out)z1,∂β2∂J=δ(out)z2,∂β3∂J=δ(out)z3
如果不做复用,而是对每个 β j \beta_j βj 都从头展开链式法则,会重复计算同一段后缀:
∂ J ∂ β j = ∂ J ∂ y ⋅ ∂ y ∂ b ⋅ ∂ b ∂ β j = ( ∂ J ∂ y ⋅ y ( 1 − y ) ) ⋅ z j \frac{\partial J}{\partial \beta_j} =\frac{\partial J}{\partial y}\cdot\frac{\partial y}{\partial b}\cdot\frac{\partial b}{\partial \beta_j} =\left(\frac{\partial J}{\partial y}\cdot y(1-y)\right)\cdot z_j ∂βj∂J=∂y∂J⋅∂b∂y⋅∂βj∂b=(∂y∂J⋅y(1−y))⋅zj
这里括号里的 ( ∂ J ∂ y ⋅ y ( 1 − y ) ) \left(\frac{\partial J}{\partial y}\cdot y(1-y)\right) (∂y∂J⋅y(1−y)) 对所有 j j j 都相同,相当于会被重复算 3 3 3 次;而反向传播把它一次性"压缩"为 δ ( out ) \delta^{(\text{out})} δ(out),后续只做乘法即可得到全部 β \beta β 的梯度。
同样的复用也发生在输入到隐藏层。以隐藏单元 z 2 z_2 z2 为例,它的加权和为:
a 2 = α 20 x 0 + α 21 x 1 + α 22 x 2 , z 2 = σ ( a 2 ) a_2=\alpha_{20}x_0+\alpha_{21}x_1+\alpha_{22}x_2,\qquad z_2=\sigma(a_2) a2=α20x0+α21x1+α22x2,z2=σ(a2)
先计算一次该隐藏单元的公共后缀梯度(隐藏层误差项):
δ 2 ( hid ) ≜ ∂ J ∂ a 2 = δ ( out ) β 2 z 2 ( 1 − z 2 ) \delta^{(\text{hid})}_2\triangleq \frac{\partial J}{\partial a_2} =\delta^{(\text{out})}\beta_2 z_2(1-z_2) δ2(hid)≜∂a2∂J=δ(out)β2z2(1−z2)
那么它连向三个输入的权重梯度只需复用同一个 δ 2 ( hid ) \delta^{(\text{hid})}_2 δ2(hid):
∂ J ∂ α 20 = δ 2 ( hid ) x 0 = δ 2 ( hid ) , ∂ J ∂ α 21 = δ 2 ( hid ) x 1 , ∂ J ∂ α 22 = δ 2 ( hid ) x 2 \frac{\partial J}{\partial \alpha_{20}}=\delta^{(\text{hid})}_2 x_0=\delta^{(\text{hid})}2,\qquad \frac{\partial J}{\partial \alpha{21}}=\delta^{(\text{hid})}2 x_1,\qquad \frac{\partial J}{\partial \alpha{22}}=\delta^{(\text{hid})}_2 x_2 ∂α20∂J=δ2(hid)x0=δ2(hid),∂α21∂J=δ2(hid)x1,∂α22∂J=δ2(hid)x2
也就是说:同一层里,很多条边的梯度只是在"同一个误差项"上乘以不同的输入值,公共后缀梯度天然被共享复用,这正是反向传播能高效计算全网络梯度的核心原因。
七、最终可直接记住的"实现级公式"清单
只记最关键三组就够用:
前向:
a j = ∑ i = 0 M α j i x i , z j = σ ( a j ) , b = ∑ j = 0 D β j z j , y = σ ( b ) a_j=\sum_{i=0}^{M}\alpha_{ji}x_i,\quad z_j=\sigma(a_j),\quad b=\sum_{j=0}^{D}\beta_j z_j,\quad y=\sigma(b) aj=i=0∑Mαjixi,zj=σ(aj),b=j=0∑Dβjzj,y=σ(b)
误差项:
δ ( out ) = y − y ∗ , δ j ( hid ) = δ ( out ) β j z j ( 1 − z j ) \delta^{(\text{out})}=y-y^*,\qquad \delta_j^{(\text{hid})}=\delta^{(\text{out})}\beta_j z_j(1-z_j) δ(out)=y−y∗,δj(hid)=δ(out)βjzj(1−zj)
梯度(误差 × 输入):
∂ J ∂ β j = δ ( out ) z j , ∂ J ∂ α j i = δ j ( hid ) x i \frac{\partial J}{\partial \beta_j}=\delta^{(\text{out})}z_j,\qquad \frac{\partial J}{\partial \alpha_{ji}}=\delta_j^{(\text{hid})}x_i ∂βj∂J=δ(out)zj,∂αji∂J=δj(hid)xi