考题分析
大数据是近两年纳入考试大纲,曾经考察过基础知识和案例分析题,针对案例分析,有可能会直接考察书本里的原图,这块目测也会越来越重要
大数据特点
- 大规模(Volume):数据体量超大,TB/PB/EB级爆发增长
- 高速度(Velocity):数据产生、流转、处理速度快,要求实时/准实时计算
- 多样化(Variety):数据类型丰富,结构化+半结构化+非结构化等
- 价值性(Value):海量数据里有效性信息少,需挖掘核心价值
- 真实性(Veracity):数据来源可信、质量准确
大数据系统属性
- 鲁棒性和容错性(Robust and Fault-tolerant):应对人和机器的错误,让系统能够从错误中快读恢复
- 低延迟读取和更新能力(Low Latency Reads and Updates)
- 横向扩展(Scalable):当数据量/负载增大,需要线性扩展,通常采用 scale out(增加机器的个数)而不是scale up(增强机器的性能)
- 通用性(General)
- 延展性(Extensible):新的功能需求出现时,系统需要能够将新功能添加到系统中
- 即席查询能力(Allows Ad Hoc Queries):用户可以按照自己的要求进行即席查询
- 最少维护能力
- 可调试性
Lambda架构
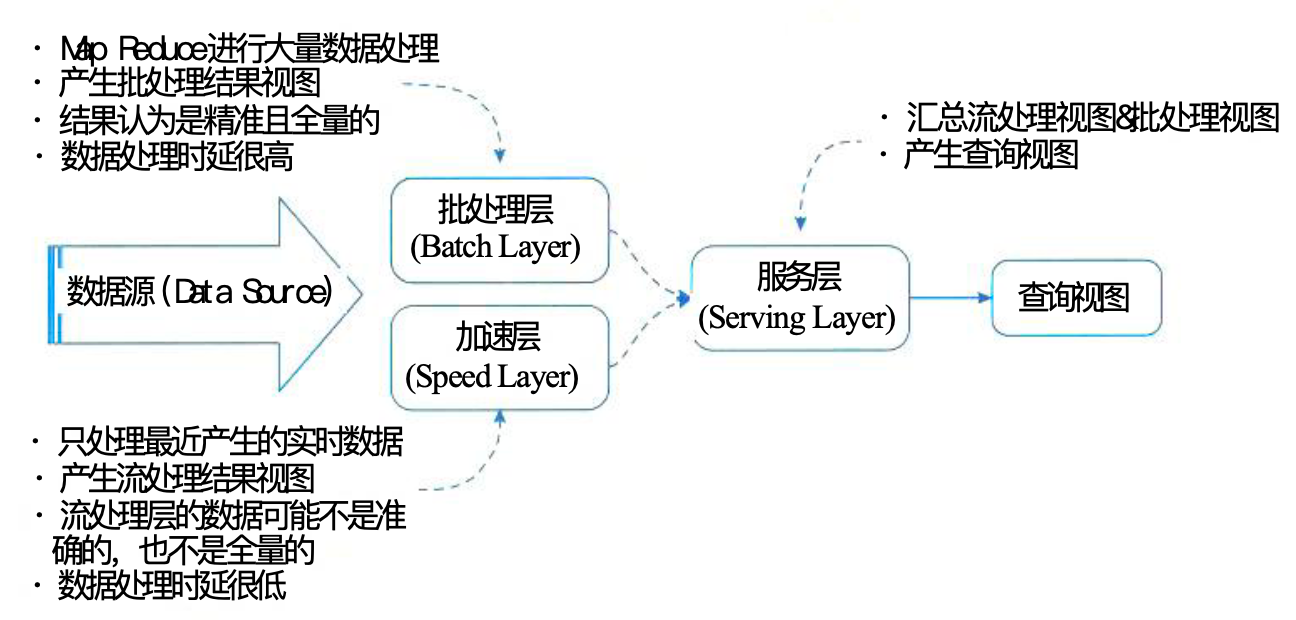
- 批处理层:存储数据集与处理离线数据。其中数据集有三个属性:数据是原始的;数据是不可变的;数据永远是真实的
- 加速层:处理最近的增量数据流
- 服务层:合并批处理产生的Batch View和加速层产生的Real-time View中的结果数据集得到最终数据集
Lambda技术选型
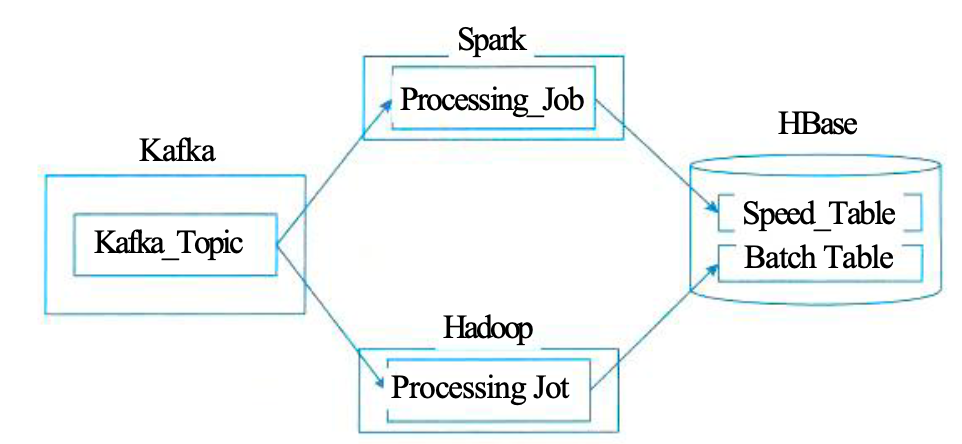
- kafka作为消息队列,用于实时传输和数据处理
- 批处理层:采用Hadoop(HDFS)存储主数据集
- 加速层:采用Spark或Storm
- 服务层:HBase或Cassandra,同时由Hive创建可查询的视图
Lambda架构优缺点
- 优点:容错性好,出现错误可以修复算法或从头开始重新计算视图;查询灵活度高;易伸缩和易扩展
- 缺点:全场景覆盖带来的编码开销;针对具体场景重新离线训练一遍益处不大;重新部署和迁移成本很高
Kappa架构
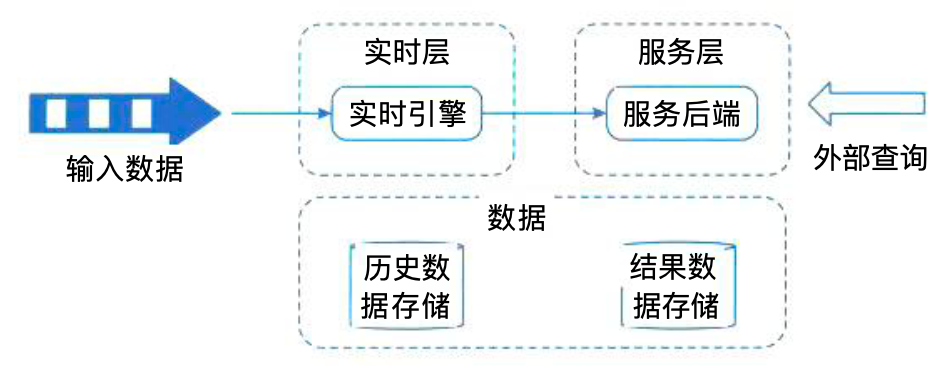
kappa架构删除了批处理层,将所有数据当作实时流来处理
Kappa架构优缺点
- 优点:将实时和离线代码统一,方便维护而且统一了数据口径的问题;避免了Lambda架构中与离线数据合并的问题
- 缺点:消息中间件缓存的数据量和回溯数据有性能瓶颈;实时数据处理时,遇到大量不同实时流进行关联时,依赖实时计算系统的能力,可能因为数据流先后顺序问题导致数据丢失;抛弃了离线数据处理模块的同时也抛弃了离线计算更加稳定可靠的特点
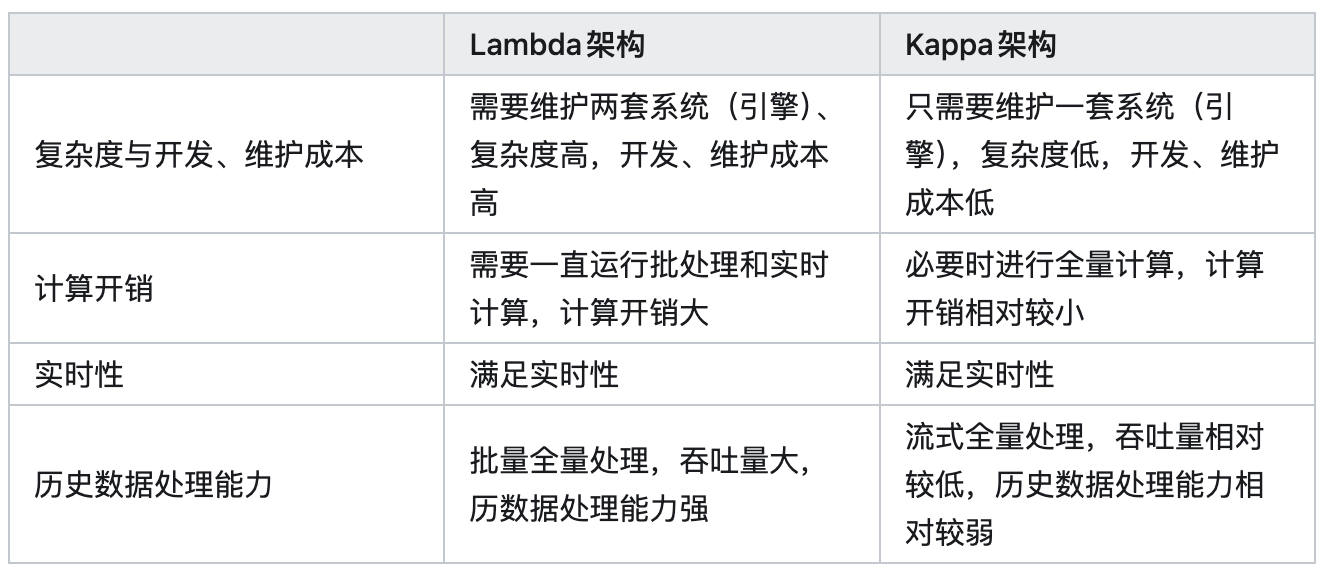
架构对比
选择依据:主要将业务需求、技术要求、系统复杂度、开发维护成本和历史数据处理能力作为考虑因素;计算开销虽然存在一定差别,但是相差不是很大,不作为考虑因素
架构案例
考虑到案例分析考察时,有的时候会直接考察书籍里的原图,因此建议架构图需要仔细了解下
Lambda案例
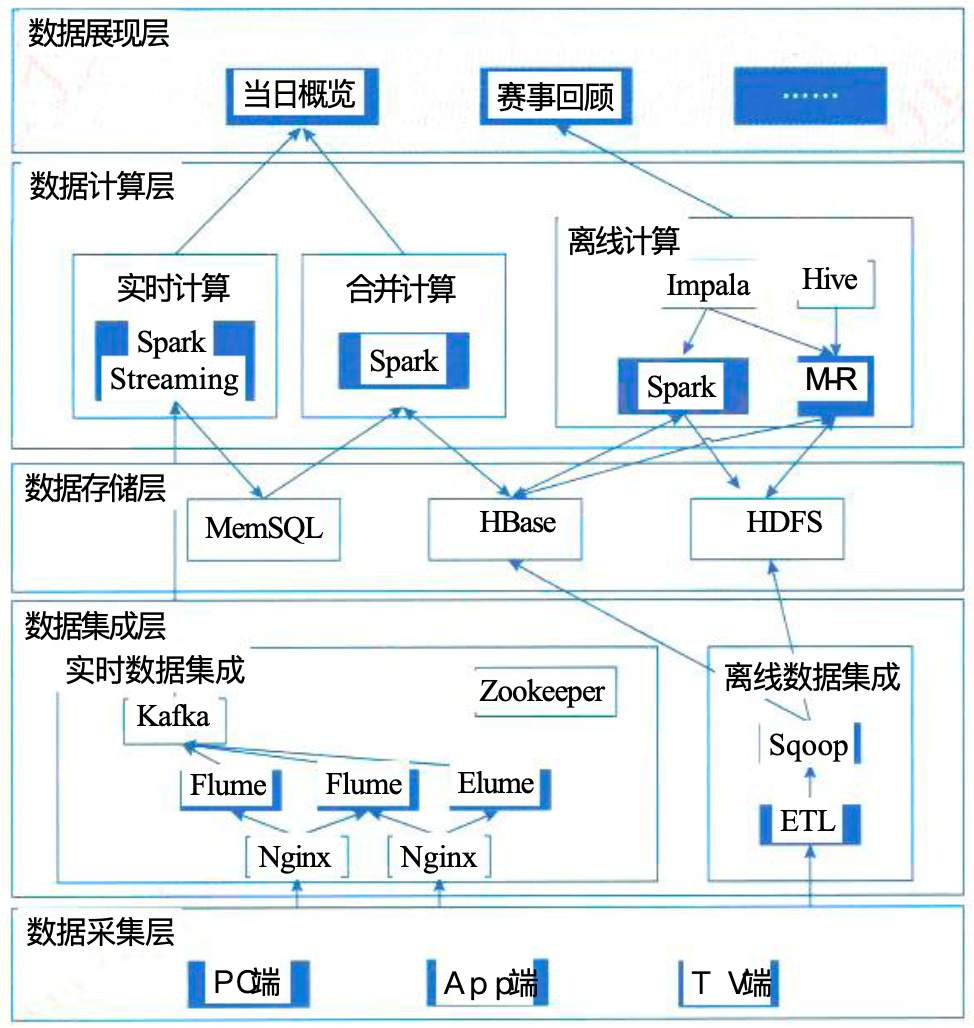
数据计算层
- Impala 是一个交互式SQL查询引擎,可以直接查询存储在HDFS或HBase中的数据
数据存储层
- MemSQL是一个关系型数据库
数据集成层
- flume:分布式数据收集工具,主要用于收集、聚合和传输日志数据
- Sqoop:用于关系型数据库和Hadoop系统之间传输数据的工具
Kappa案例
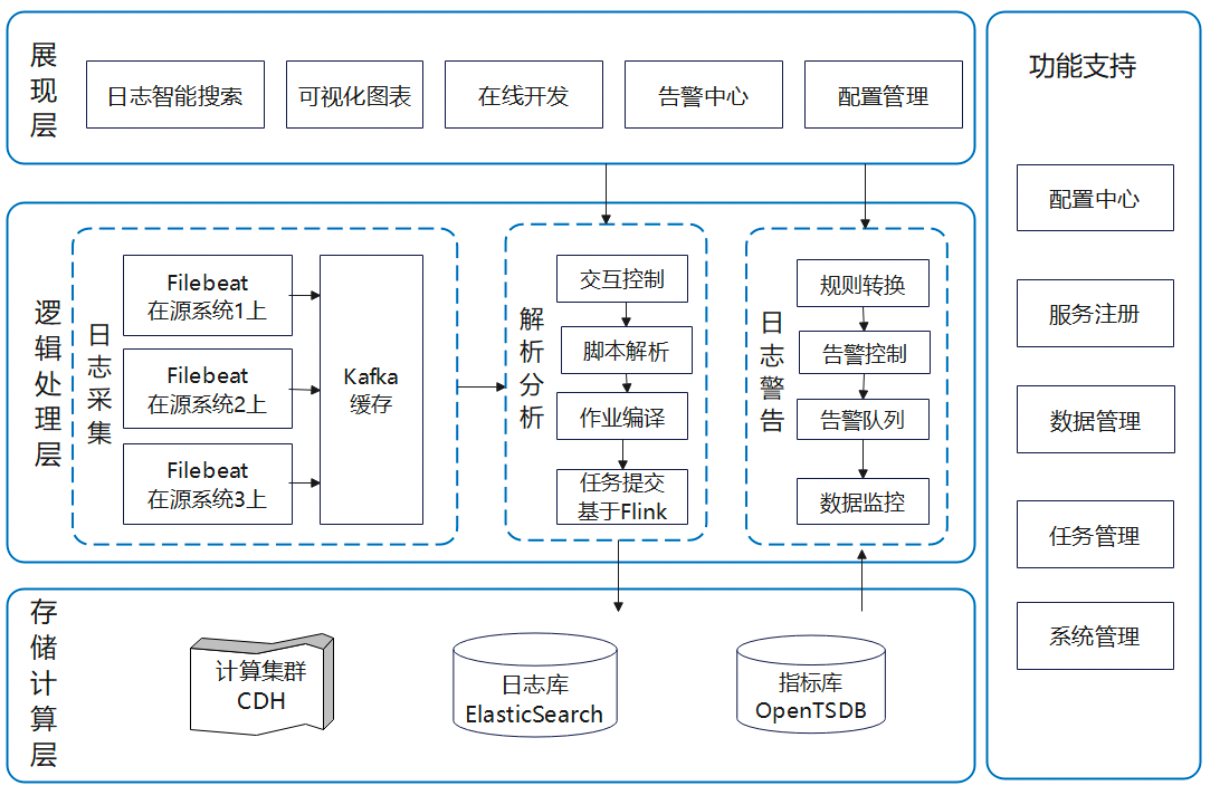
逻辑处理层
- Filebeat与Flume类似,主要用于收集、聚合和传输日志数据
- Flink 流式实时计算框架
存储计算层
- 计算集群CDH是企业级大数据平台,是国内最主流的 Hadoop 发行版,提供一站式存储、计算、管理与安全能力
- OpenTSDB基于HBase的时序数据库,适合存储和查询时间序列数据