从0开始搭建一主两节点k8s集群对接Ceph集群
一、K8s 与 Ceph 对接的核心作用
Kubernetes(K8s)是容器编排平台,核心解决容器的调度、部署和生命周期管理,但自身不提供持久化存储能力(容器默认存储为临时存储,容器销毁数据丢失);
Ceph 是开源的分布式存储系统,支持块存储(RBD)、文件存储(CephFS)、对象存储(RGW)三种存储形态,具备高可用、可扩展、分布式特性。
两者对接的核心价值是:为 K8s 集群提供企业级的持久化存储能力,让容器化应用的数据能够持久化保存,同时满足不同类型应用的存储需求,具体体现在:
-
数据持久化:容器重启 / 重建 / 迁移后,数据不丢失(如数据库、中间件、日志服务等核心应用的持久化需求);
-
存储弹性扩展:Ceph 支持 PB 级存储扩容,可随 K8s 集群业务增长无缝扩展存储资源;
-
多存储形态适配
:
- RBD(块存储):适配数据库(MySQL/PostgreSQL/Redis)、分布式存储等需要裸块设备的场景;
- CephFS(文件存储):适配日志共享、大数据分析、多 Pod 共享文件的场景(支持 RWX 多节点读写);
- RGW(对象存储):适配静态资源(图片 / 视频)、备份归档等场景;
-
高可用保障:Ceph 的多副本、故障自动恢复特性,为 K8s 应用提供 99.99% 级别的数据可靠性;
-
存储生命周期管理:通过 K8s 的 PVC/PV/StorageClass 机制,实现存储的动态申请、扩容、释放,适配 DevOps 自动化流程。
二、典型应用场景
| 场景类型 | 存储类型 | 对接价值 |
|---|---|---|
| 数据库集群(MySQL/PG) | RBD | 块存储低延迟特性适配数据库 IO 需求,多副本保障数据不丢失,支持 Volume 扩容 |
| 微服务日志共享 | CephFS | 多 Pod(多节点)可同时读写日志文件,满足 ELK/EFK 日志收集的共享存储需求 |
| 大数据处理(Spark/Flink) | CephFS | 任务节点共享数据集,支持大规模文件并行读写 |
| 静态资源服务(Nginx) | RGW/CephFS | 海量图片 / 视频存储,支持 K8s Pod 直接挂载或通过 API 访问 |
| 有状态应用(ETCD/Zookeeper) | RBD | 为有状态应用提供专属持久化存储,保障集群元数据安全 |
三、对接优势对比传统存储
| 特性 | 传统存储(SAN/NAS) | K8s+Ceph 对接方案 |
|---|---|---|
| 扩展性 | 扩容复杂(需停机 / 手动配置) | 在线无缝扩容,支持横向扩展节点 |
| 适配容器化 | 需手动映射存储卷 | 动态 PV/PVC,自动化生命周期管理 |
| 成本 | 硬件 /license 成本高 | 开源免费,可基于 x86 服务器部署 |
| 多存储形态 | 单一形态(SAN = 块 / NAS = 文件) | 块 / 文件 / 对象三合一,适配全场景 |
| 高可用 | 依赖硬件冗余 | 软件定义多副本,故障自动恢复 |
四、RBD和CephFS对比
1. RBD(块存储)
RBD 是 Ceph 提供的块设备存储服务,将 Ceph 集群的分布式对象存储(RADOS)抽象为标准的块设备(类似磁盘),可以被挂载到物理机 / 虚拟机 / K8s Pod 中,支持快照、克隆、精简配置、条带化等特性,本质是 "分布式的虚拟磁盘"。
2. CephFS(文件存储)
CephFS 是 Ceph 提供的POSIX 兼容的分布式文件系统,支持多客户端并发读写,通过元数据服务器(MDS)管理文件元数据(目录、权限、索引等),数据存储在 RADOS 中,本质是 "分布式的网络文件系统(类似 NFS/GlusterFS)"。
1. RBD 核心特性
表格
| 特性 | 说明 |
|---|---|
| 块设备抽象 | 暴露为块设备(/dev/rbdX),可格式化(ext4/xfs)后挂载,与物理磁盘无感知 |
| 单镜像单挂载(默认) | 普通 RBD 镜像默认仅支持ReadWriteOnce(RWO),多节点同时挂载会损坏文件系统 |
| 多挂载支持 | 需开启exclusive-lock特性,或使用 Raw Block 模式(无文件系统,业务自行控并发) |
| 快照 / 克隆 | 支持增量快照、跨镜像克隆,适合虚拟机磁盘、数据库冷备 |
| 精简配置 | 按需分配存储空间(声明 100G,实际只用 10G 则仅占用 10G) |
| 无元数据服务器 | 无需额外组件,直接与 MON/OSD 交互,架构简单 |
2. CephFS 核心特性
| 特性 | 说明 |
|---|---|
| POSIX 兼容 | 支持标准文件操作(ls/cp/rm 等),兼容 Linux/Unix 文件系统语义 |
| 多客户端并发读写 | 支持ReadWriteMany(RWX),多节点 / Pod 可同时挂载读写 |
| 元数据服务器(MDS) | 必须部署 MDS 集群管理元数据(目录结构、文件索引),MDS 可多实例高可用 |
| 数据池 + 元数据池 | 需单独创建 "数据池"(存文件数据)和 "元数据池"(存元数据),分离存储提升性能 |
| 子卷组(Subvolume Group) | K8s 对接时需创建子卷组,不能直接挂载根目录,需挂载子卷 |
| 权限控制 | 支持 POSIX 权限、ACL,可按用户 / 目录粒度授权 |
五、选型建议
选 RBD:
- 业务需要块设备(如数据库、虚拟机);
- 对 IOPS / 延迟要求高;
- 需快照 / 克隆特性;
- 单节点使用,或能自行控制多节点并发(如数据库集群)。
选 CephFS:
- 业务需要多节点共享存储(RWX);
- 依赖 POSIX 文件系统语义(如传统应用、日志共享);
- 无需极致 IOPS,更看重共享性和易用性。
用kubeadm方式搭建k8s集群
0. 时间同步
集群所有主机
bash
dnf install chrony -y
sed -i '/^pool/ c server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl enable --now chronyd
systemctl restart chronyd
chronyc sources -v1.主机规划
| 主机名 | IP 地址 | 配置最低要求 | 角色 | 安装组件 |
|---|---|---|---|---|
| k8s-M | 172.25.254.81 | CPU>=4, MEM>=4GB, DISK=100G | Master | apiserver, controller-manager, scheduler, etcd, kube-proxy, docker, calico |
| k8s-S1 | 172.25.254.82 | CPU>=2, MEM>=2GB, DISK=100G | Worker | kubelet, kube-proxy, docker, coredns |
| k8s-S2 | 172.25.254.83 | CPU>=2, MEM>=2GB, DISK=100G | Worker | kubelet, kube-proxy, docker, coredns |
2.关闭swap分区以及防火墙和selinux
2.1关闭swap分区
2.2关闭火墙
2.3关闭selinux
setenforce 0 #临时关闭
getenforce #验证
#永久关闭
vim /etc/selinux/config
将这行
SELINUX=enforcing
改为
SELINUX=disabled
然后
reboot
或者直接用这条
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
reboot验证
3.安装基本软件
更换镜像源
sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirror.nju.edu.cn/rocky|g' \
-i.bak \
/etc/yum.repos.d/rocky*.repo
dnf makecache
dnf install net-tools nfs-utils vim wget curl bash-completion device-mapper-persistent-data psmisc tree -y
dnf install ipvsadm -y4.修改linux最大连接数
bash
vim /etc/security/limits.conf
#在文件末尾添加以下内容:
* soft nofile 655350
* hard nofile 655350
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited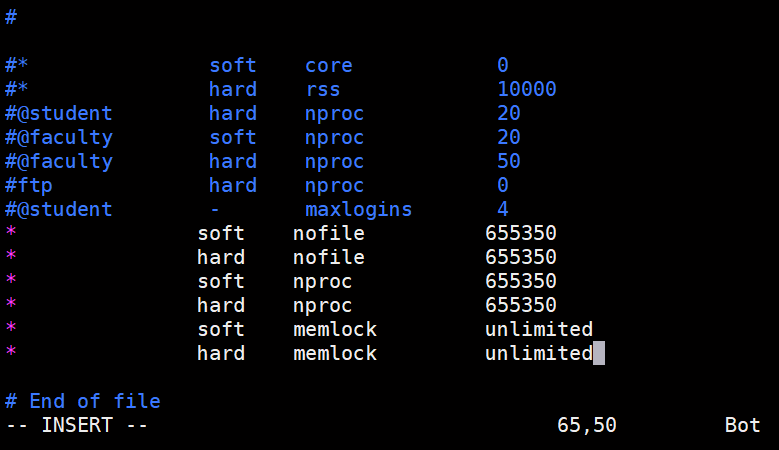
5.开启路由转发
[root@k8s-M yum.repos.d]# echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf
[root@k8s-M yum.repos.d]# sysctl -p
net.ipv4.ip_forward = 1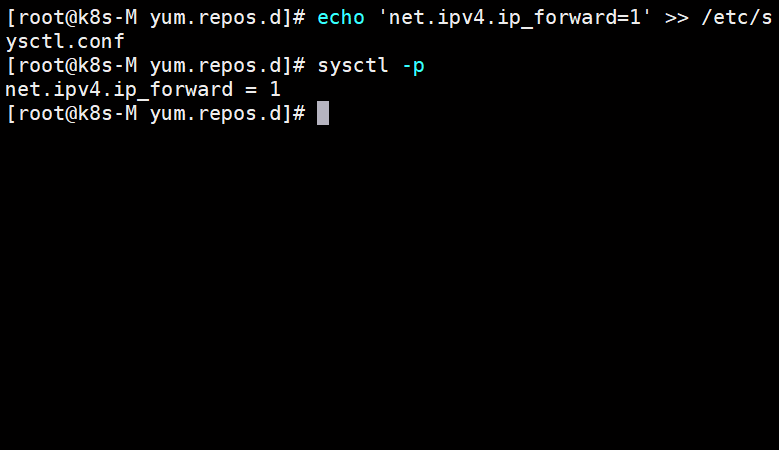
做完这一切设置之后我们可以关机拍个快照!
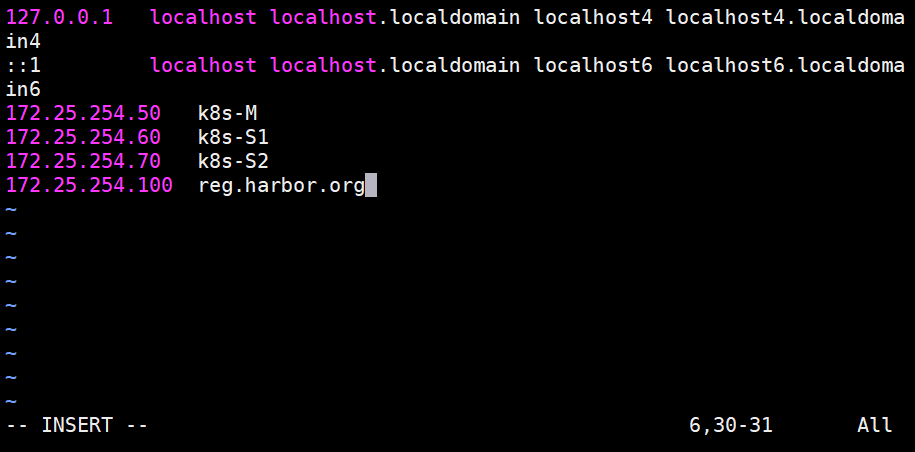
给所有主机设置hosts解析文件
6.配置并安装docker
6.1 添加 Docker 源
dnf install yum-utils -y
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/rhel/docker-ce.repo6.2 安装 Docker
dnf install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y6.3 配置 Docker
cat > /etc/docker/daemon.json <<EOF
{
"default-ipc-mode": "shareable",
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "50"
},
"insecure-registries": ["reg.harbor.org"],
"registry-mirrors": [
"https://docker.1ms.run"
]
}
EOF6.4 启动 Docker
systemctl enable docker --now查看docker版本
docker version
查看docker的详细信息
docker info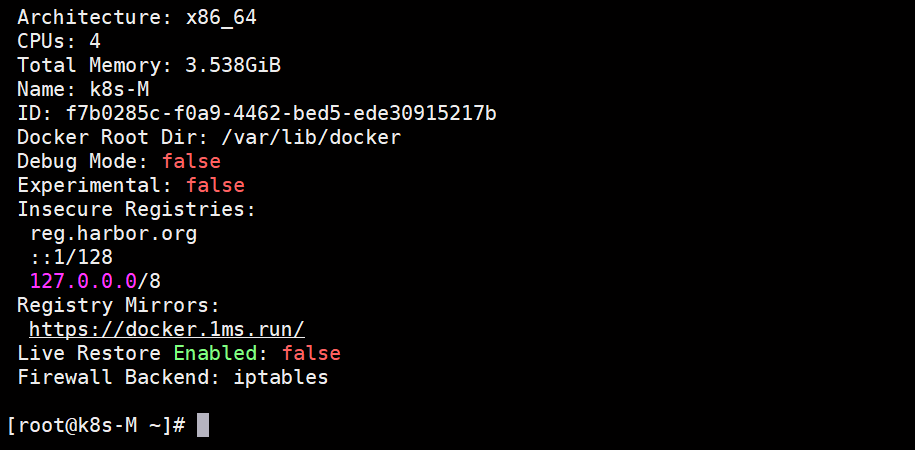
主要检查镜像源的配置是否识别成功,也可以看看自己的harbor仓库地址是否识别到
7.安装CRI
注意:以下操作需要在 k8s-1、k8s-2 和 k8s-3 这三台主机上执行。
CRI 为容器运行时,常见的有 cri-docker 和 containerd,两者任选其一安装即可,不要两者都安装。
7.1 安装 cri-docker(二选一)
1.下载 cri-docker
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.24/cri-dockerd-0.3.24.amd64.tgz2.解压文件
tar -zxf cri-dockerd-0.3.24.amd64.tgz3.将文件复制到 /usr/bin 目录下
cp cri-dockerd/cri-dockerd /usr/bin/4.设置文件可执行权限
chmod +x /usr/bin/cri-dockerd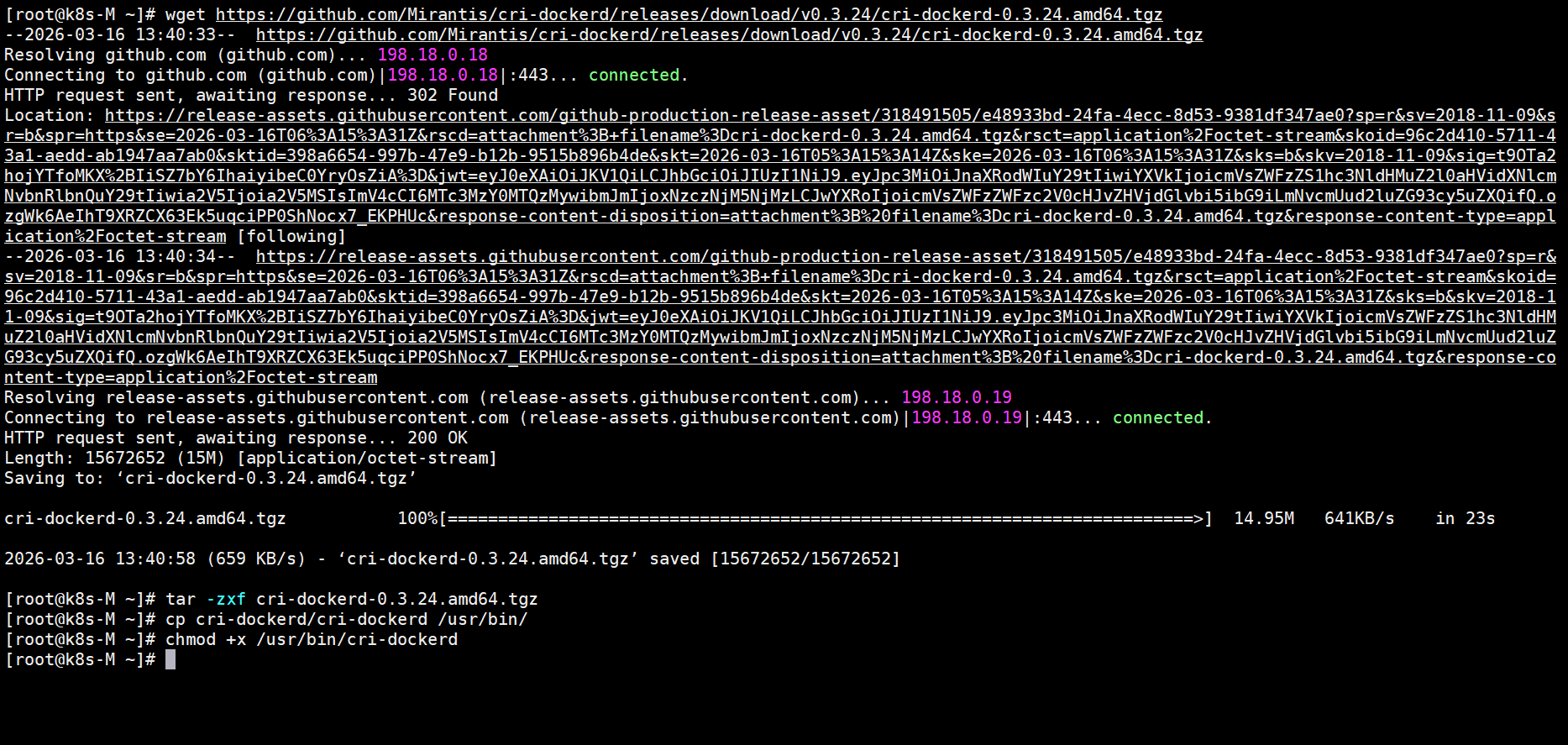
5.配置
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
#ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.k8s.io/pause:3.10.1
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.10.1
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF6.配置cri-docker套接字文件
cat > /usr/lib/systemd/system/cri-docker.socket <<EOF
[Unit]
Description=CRI Docker socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF7.启动 cri-docker 服务
systemctl daemon-reload
systemctl enable --now cri-docker
systemctl is-active cri-docker至此我们的docker环境就已经准备完毕了!
7.2 containerd
...
8.搭建k8s环境
8.1 配置网络软件仓库
cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.34/rpm/
gpgcheck=0
EOF
dnf makecache8.2 安装 Kubernetes
dnf install -y kubelet kubeadm kubectl8.3 启动 kubelet 服务
systemctl enable --now kubelet
kubeadm version
8.4 集群初始化
kubeadm init --apiserver-advertise-address=172.25.254.81 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=1.34.5 \
--service-cidr=10.10.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=all \
--cri-socket unix:///var/run/cri-dockerd.sock
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config8.5 将各个节点加入集群
在各个节点上执行join命令
kubeadm join 172.25.254.50:6443 --token l56qj2.dk8hk3hbp65lh43s \
--discovery-token-ca-cert-hash sha256:29031af881246df3f9987c0b5b083f6071c1e447c02fb8e10b832a68cfc61ff7 \
--cri-socket unix:///var/run/cri-dockerd.sock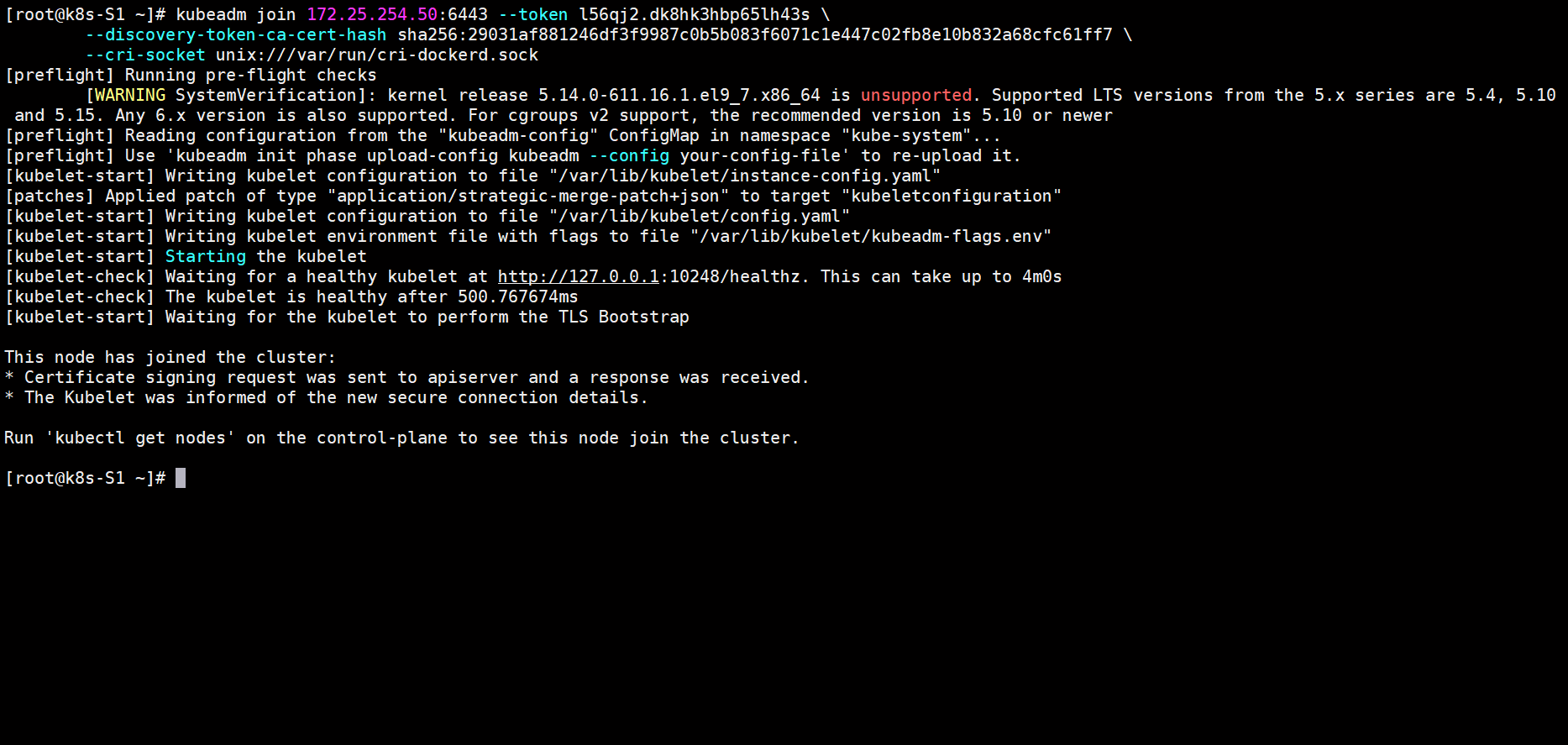
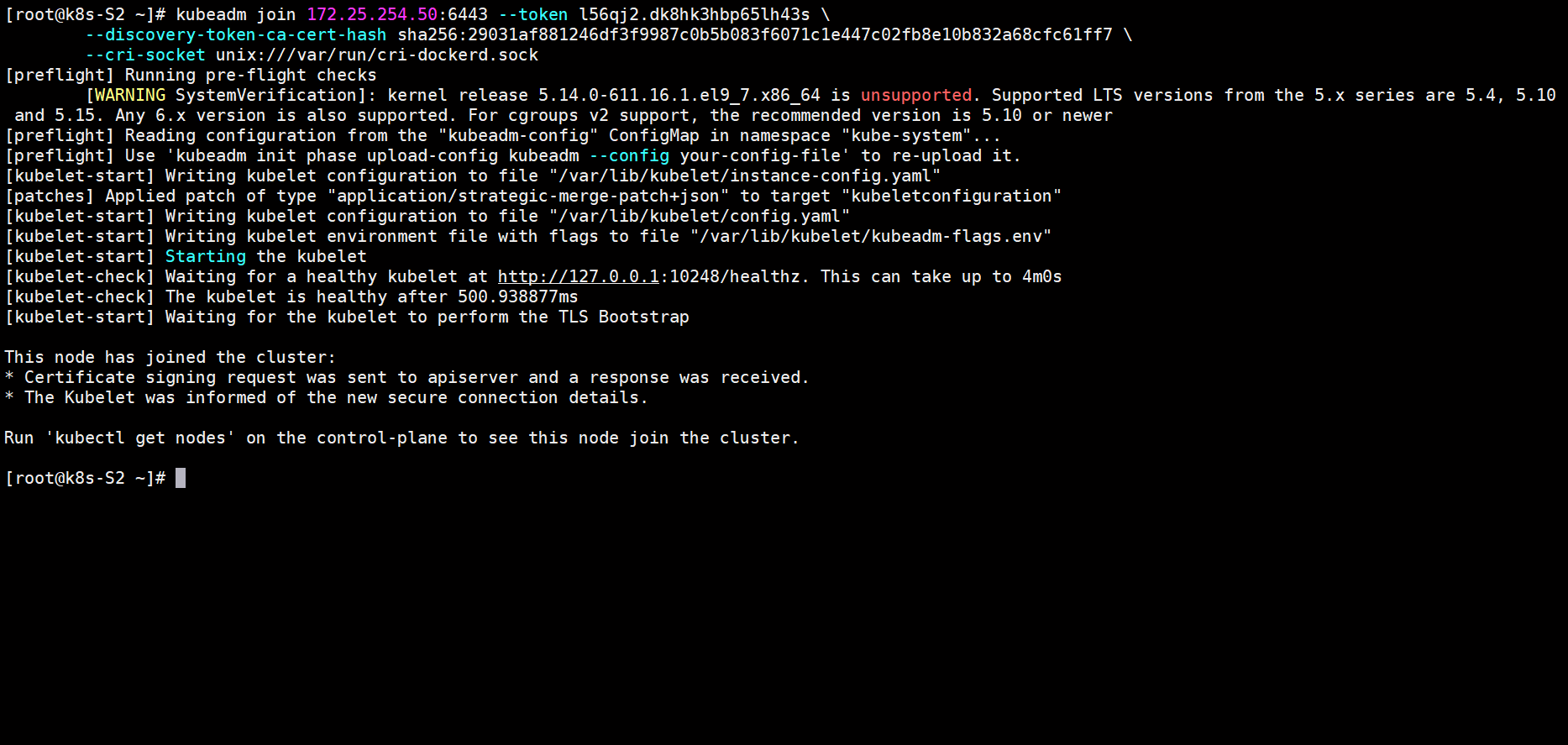
在master节点上查看node节点加入集群没
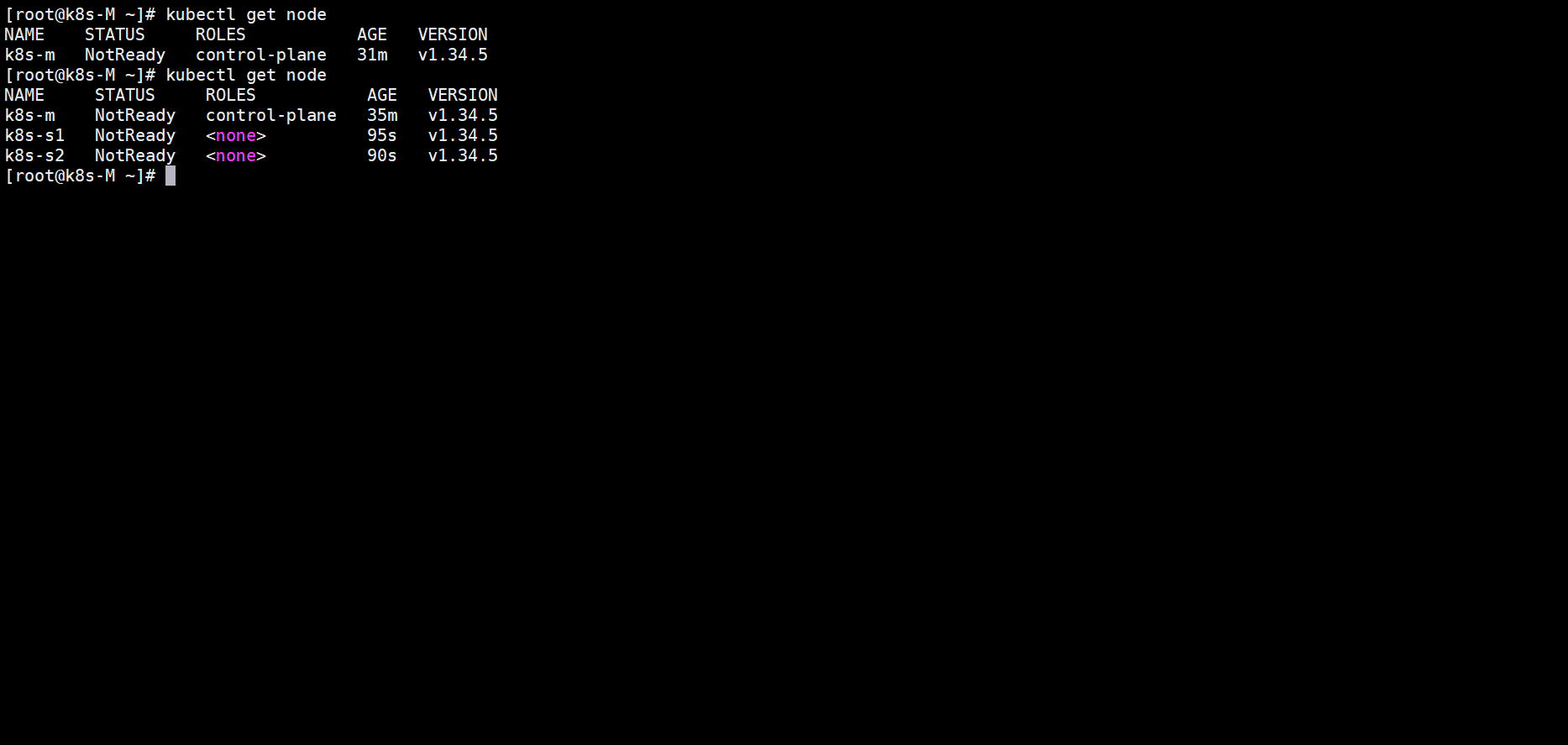
要是token那一块被刷上去了或者找不到了,可以使用下面的这条命令重新生成token
注意:token有两个小时时效性
bash
kubeadm token create --print-join-commandkubeadm reset --force --cri-socket unix:///var/run/cri-dockerd.sock#强制重置k8s集群
rm -rf \
/etc/kubernetes \
/var/lib/kubelet \
/var/lib/etcd \
/var/lib/cni \
/etc/cni/net.d \
/var/lib/containerd \
/var/lib/docker \
/run/flannel \
/run/calico \
/var/run/calico \
$HOME/.kube8.6 下载并安装calico插件
calico官网
https://docs.tigera.io/calico/3.30/getting-started/kubernetes/self-managed-onprem/onpremises下载calico安装脚本
curl https://raw.githubusercontent.com/projectcalico/calico/v3.30.6/manifests/calico.yaml -O将所有镜像的地址改为国内镜像源

执行安装calico的脚本
在master节点上执行以下命令
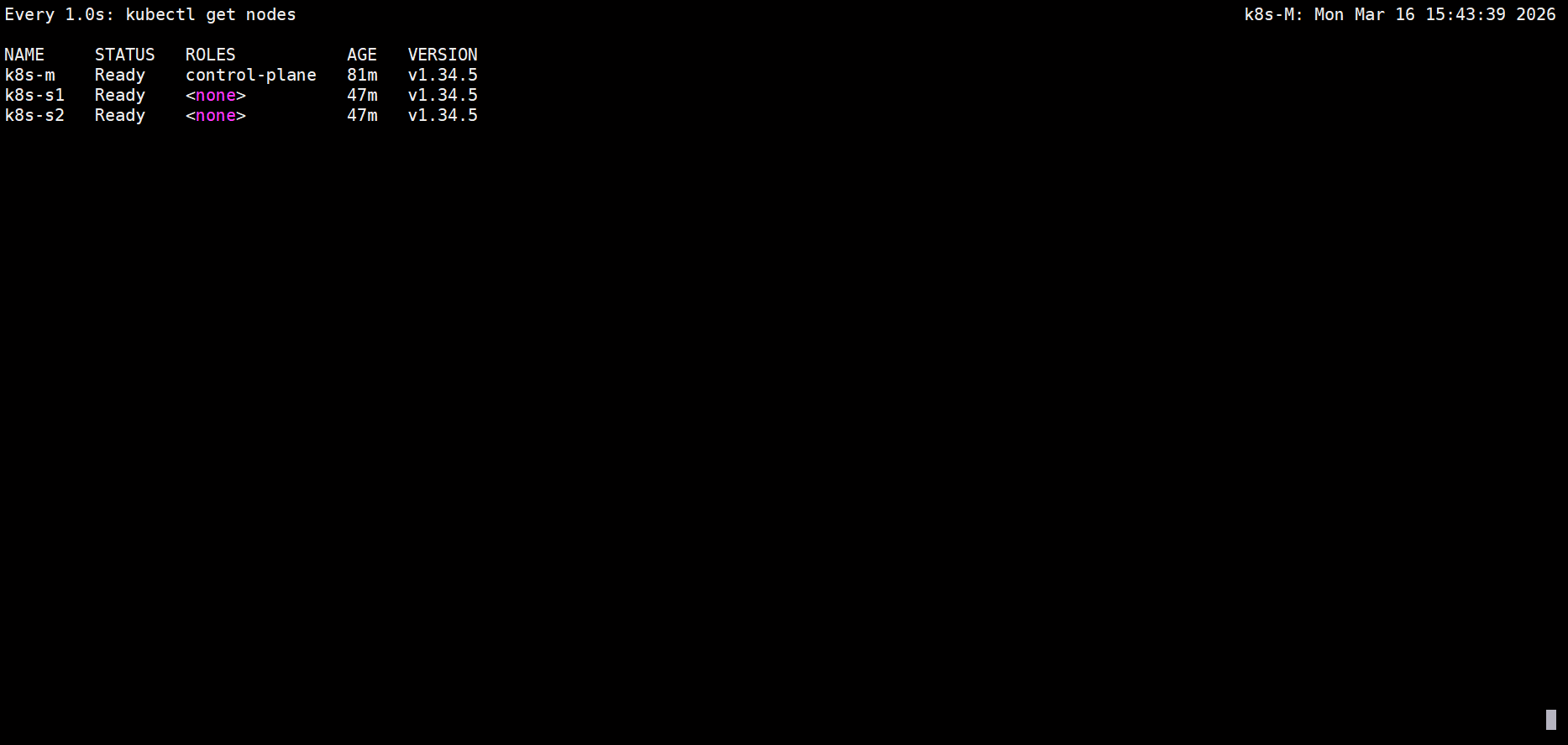
[root@k8s-M ~]# kubectl apply -f calico.yaml然后等待即可
不出意外的话,节点状态会由NotReady转变为Ready
8.7 配置k8s的代码补全(可选)
echo "source <(kubectl completion bash)" >> ~/.bashrc
echo 'source <(kubeadm completion bash)' >> $HOME/.bashrc
source ~/.bashrc用Cephadm方式搭建Ceph集群
0. 关闭火墙并且将selinux设置为disabled
集群所有主机
bash
systemctl status firewalld.service
○ firewalld.service
Loaded: masked (Reason: Unit firewalld.service is masked.)
Active: inactive (dead)
getenforce
Disabled1. 配置时间同步
集群所有主机
bash
dnf install chrony -y
sed -i '/^pool/ c server ntp.aliyun.com iburst' /etc/chrony.conf
systemctl enable --now chronyd
systemctl restart chronyd
chronyc sources -v2. cephadm工具安装
bash
cat >> /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/x86_64
gpgcheck=0
[ceph-noarch]
name=Ceph noarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/noarch
gpgcheck=0
[ceph-source]
name=Ceph source
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/SRPMS
gpgcheck=0
EOF
dnf install cephadm -y3. 安装docker
集群所有主机
bash
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
dnf install docker-ce -y
systemctl enable --now docker4. cephadm初始化集群
bash
cephadm --docker bootstrap \
--mon-ip 172.25.254.91 \
--initial-dashboard-user admin \
--initial-dashboard-password vb \
--dashboard-password-noupdate \
--allow-fqdn-hostname注意:这里建议开启科学上网再进行初始化集群
或者先拉取ceph的镜像
quay.io/ceph/ceph:v19可以上网找国内镜像源进行下载,然后加载进docker
5. 集群扩容
拷贝ceph配置文件的公钥给要加入的节点
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph3添加节点到集群
cephadm shell ceph orch host add ceph2
cephadm shell ceph orch host add ceph36. 安装ceph-common客户端管理
集群所有主机
bash
yum install -y https://mirrors.aliyun.com/epel/epel-release-latest-9.noarch.rpm
sed -i 's|^#baseurl=https://download.example/pub|baseurl=https://mirrors.aliyun.com|' /etc/yum.repos.d/epel*
sed -i 's|^metalink|#metalink|' /etc/yum.repos.d/epel*
dnf install ceph-common -y7. 给集群添加osd设备
ceph orch apply osd --all-available-devices
8. 添加管理节点
ceph orch host label add ceph1 _admin9. 部署mon,mgr
ceph orch apply mon "ceph1 ceph2 ceph3"
ceph orch apply mgr --placement "ceph1 ceph2 ceph3"10. 检查集群状态
ceph orch ps
ceph -s
ceph -w!CAUTION
以下命令仅在实验环境使用!!!谨慎在生产环境使用
由于我创建mon和mgr时资源不足,导致创建失败,所以才用强制删除再重新建立
如果遇到了某个mon或者mgr出现建立错误
试试强制删掉再重新建立
# 1. 彻底删除坏掉的 mon.ceph1
ceph orch daemon rm mon.ceph1 --force
# 2. 重新在 ceph1 上创建 mon
ceph orch daemon add mon ceph1
# 3. 彻底删除坏掉的 mgr.ceph1
ceph orch daemon rm mgr.ceph1.rkitrb --force
# 4. 重新在 ceph1 上创建 mgr
ceph orch daemon add mgr ceph1对接Ceph
项目网址:https://github.com/ceph/ceph-csi
下载之后解压进入ceph-csi-3.16.2/deploy/rbd/kubernetes
wget https://github.com/ceph/ceph-csi/archive/refs/tags/v3.16.2.tar.gz


https://github.com/ceph/ceph-csi/tree/devel/examples
0. k8s安装ceph客户端
bash
cat >> /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/x86_64
gpgcheck=0
[ceph-noarch]
name=Ceph noarch
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/noarch
gpgcheck=0
[ceph-source]
name=Ceph source
baseurl=https://mirrors.aliyun.com/ceph/rpm-squid/el9/SRPMS
gpgcheck=0
EOF
yum install -y https://mirrors.aliyun.com/epel/epel-release-latest-9.noarch.rpm
sed -i 's|^#baseurl=https://download.example/pub|baseurl=https://mirrors.aliyun.com|' /etc/yum.repos.d/epel*
sed -i 's|^metalink|#metalink|' /etc/yum.repos.d/epel*
dnf install ceph-common -y1. 配置本地解析
集群所有主机都要配置
bash
cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.254.100 k8s-m
172.25.254.10 k8s-n1
172.25.254.20 k8s-n2
172.25.254.91 ceph1
172.25.254.92 ceph2
172.25.254.93 ceph3
EOF2. 获取ceph配置文件
只有获取了ceph配置文件才能通过ceph-common来管理ceph
bash
scp -r /etc/ceph/ root@k8s-m:/etc/
scp -r /etc/ceph/ root@k8s-n1:/etc/
scp -r /etc/ceph/ root@k8s-n2:/etc/3. 创建数据池并初始化
ceph新建pool,user
bash
[root@k8s-m ~]# ceph osd pool create kubernetes
[root@k8s-m ~]# rbd pool init kubernetes
如果创建错误可以删除用过以下命令
#查看存在的池
[root@k8s-m kubernetes]# ceph osd pool ls
#ceph默认是关闭了删除池的功能要开启,确保安全
[root@k8s-m kubernetes]# ceph config set mon mon_allow_pool_delete true
#要输入两次池的名称来确认要要删除
[root@k8s-m kubernetes]# ceph osd pool delete kubernets kubernets --yes-i-really-really-mean-it
#设置回关闭
[root@k8s-m kubernetes]# ceph config set mon mon_allow_pool_delete false4. 去除master的污点
bash
[root@k8s-m kubernetes]# kubectl describe nodes k8s-m | grep -i taint
[root@k8s-m kubernetes]# kubectl taint node k8s-m node-role.kubernetes.io/control-plane:NoSchedule-
node/k8s-m untainted[root@k8s-m ~]# kubectl describe nodes k8s-m | grep -i taint
Taints: <none>5. 部署csi控制器与插件的认证用户与授权
bash
#部署用户认证与授权
[root@k8s-m kubernetes]# kubectl apply -f csi-provisioner-rbac.yaml
[root@k8s-m kubernetes]# kubectl apply -f csi-nodeplugin-rbac.yaml6. 部署csi的驱动
[root@k8s-m kubernetes]# cat csidriver.yaml
#
# /!\ DO NOT MODIFY THIS FILE
#
# This file has been automatically generated by Ceph-CSI yamlgen.
# The source for the contents can be found in the api/deploy directory, make
# your modifications there.
#
---
apiVersion: storage.k8s.io/v1
kind: CSIDriver
metadata:
name: "rbd.csi.ceph.com"
spec:
attachRequired: true
podInfoOnMount: false
seLinuxMount: true
fsGroupPolicy: File
#创建部署csi驱动,允许csi能创建和挂载存储卷7. 部署csi控制器与插件
#此处如果没有访问外网能力需要更改镜像地址为国内
[root@k8s-m kubernetes]# sed -i 's#registry.k8s.io/sig-storage#registry.cn-hangzhou.aliyuncs.com/google-containers#' csi-nodeplugin-rbac.yaml
[root@k8s-m kubernetes]# sed -i 's#registry.k8s.io/sig-storage#registry.cn-hangzhou.aliyuncs.com/google-containers#' csi-nodeplugin-rbac.yaml
#部署csi控制器与csi节点插件
[root@k8s-m kubernetes]# kubectl apply -f csi-rbdplugin-provisioner.yaml
[root@k8s-m kubernetes]# kubectl apply -f csi-rbdplugin.yaml8. 创建配置文件configmap cm
[root@k8s-m kubernetes]# ceph mon dump
epoch 5
fsid efbdfc34-28e2-11f1-8442-000c29aef4c3 #id需保存,后面配置文件会用到
last_changed 2026-03-28T05:49:06.271917+0000
created 2026-03-26T07:11:21.671650+0000
min_mon_release 19 (squid)
election_strategy: 1
0: [v2:172.25.254.93:3300/0,v1:172.25.254.93:6789/0] mon.ceph3
1: [v2:172.25.254.92:3300/0,v1:172.25.254.92:6789/0] mon.ceph2
2: [v2:172.25.254.91:3300/0,v1:172.25.254.91:6789/0] mon.ceph1
dumped monmap epoch 5
[root@k8s-m kubernetes]# vim csi-config-map.yaml
#
# /!\ DO NOT MODIFY THIS FILE
#
# This file has been automatically generated by Ceph-CSI yamlgen.
# The source for the contents can be found in the api/deploy directory, make
# your modifications there.
#
---
apiVersion: v1
kind: ConfigMap
metadata:
name: "ceph-csi-config"
data:
config.json: |-
[
{
"clusterID":"297a3e0c-22ca-11f1-aee2-000c29785bd5",
"monitors":[
"172.25.254.91:6789",
"172.25.254.92:6789",
"172.25.254.93:6789"
]
}
]
[root@k8s-m kubernetes]# kubectl apply -f csi-config-map.yaml
configmap/ceph-csi-config configured
[root@k8s-m kubernetes]# cat ceph-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
data:
ceph.conf: |
[global]
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
keyring: |
metadata:
name: ceph-config
[root@k8s-m kubernetes]# kubectl apply -f ceph-config-map.yaml
[root@k8s-m kubernetes]# cat csi-kms-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
{}
metadata:
name: ceph-csi-encryption-kms-config
[root@k8s-m kubernetes]# kubectl apply -f csi-kms-config-map.yaml9. 创建认证文件secret
#为kubernets与ceph-csi创建用户
[root@k8s-m ~]# ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes'
[client.kubernetes]
key = AQBui7tpyXcLNxAAfRIyG39SG4ogbTpUx5Knvw==
#查看用户
[root@k8s-m kubernetes]# ceph auth ls | grep -A 4 client.kubernetes
client.kubernetes
key: AQC5e8dp2TzYGhAAZJcVDS+22V+ySLiNsG4v/Q==
caps: [mgr] profile rbd pool=kubernetes
caps: [mon] profile rbd
caps: [osd] profile rbd pool=kubernetes
[root@k8s-m kubernetes]# cat csi-rbd-secret.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: csi-rbd-secret
stringData:
userID: kubernetes
userKey: AQC5e8dp2TzYGhAAZJcVDS+22V+ySLiNsG4v/Q==
[root@k8s-m kubernetes]# kubectl apply -f csi-rbd-secret.yaml
secret/csi-rbd-secret configured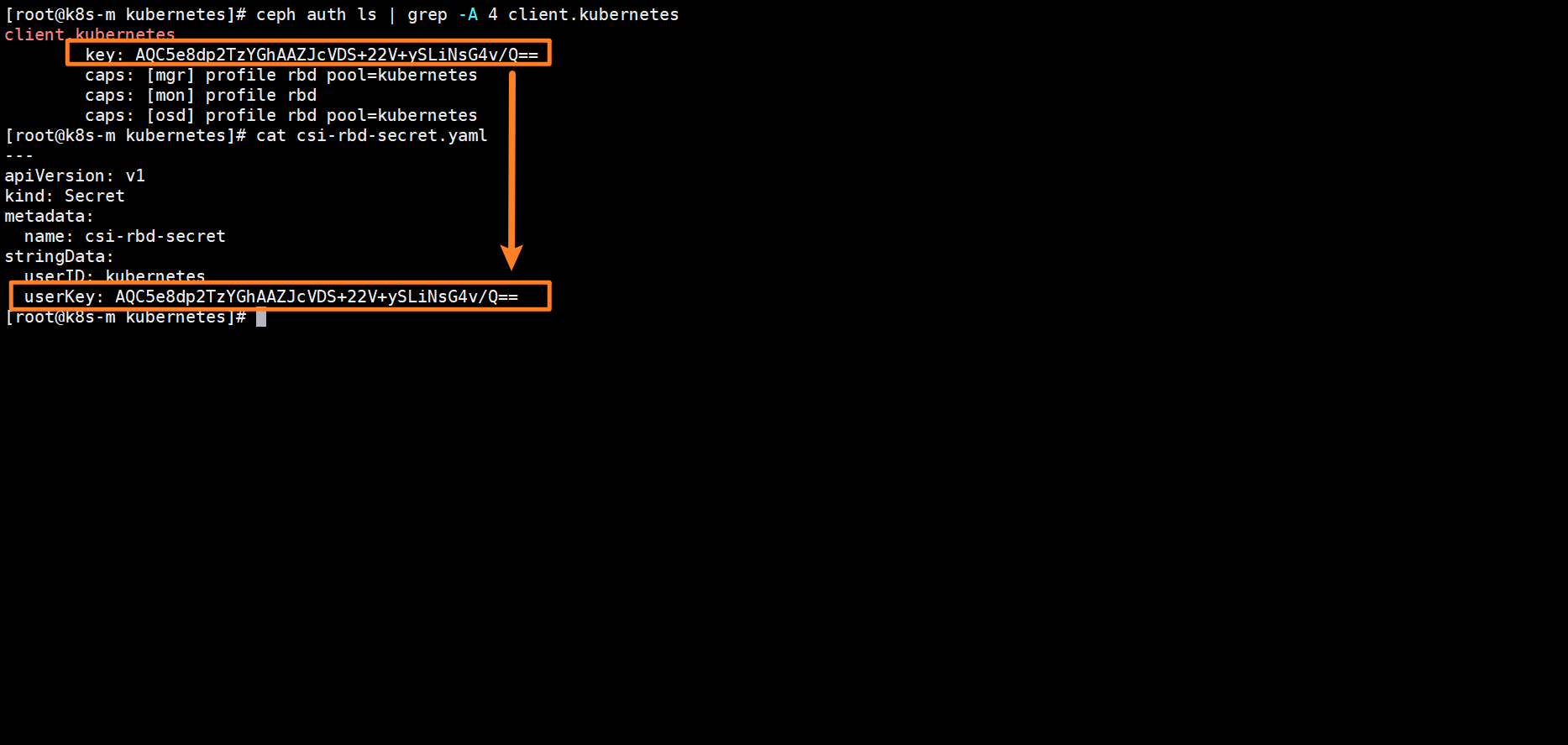

10. 创建存储类
cat <<EOF > csi-rbd-sc.yaml
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-rbd-sc
provisioner: rbd.csi.ceph.com
parameters:
clusterID: b9127830-b0cc-4e34-aa47-9d1a2e9949a8
pool: kubernetes
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret
csi.storage.k8s.io/provisioner-secret-namespace: default
csi.storage.k8s.io/controller-expand-secret-name: csi-rbd-secret
csi.storage.k8s.io/controller-expand-secret-namespace: default
csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret
csi.storage.k8s.io/node-stage-secret-namespace: default
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
- discard
EOF
kubectl apply -f csi-rbd-sc.yaml11. 创建PVC测试
-
由于filesystem禁止多节点挂载即使设置RWX也会被自动降级为RWO,多节点同时挂载会导致文件系统元数据(inode、目录项)损坏,数据丢失且无法恢复。
-
block允许多节点挂载,适用于数据库集群等自带并发控制的场景
cat <
raw-block-pvc.yaml apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: raw-block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 1Gi
storageClassName: csi-rbd-sc
EOFkubectl apply -f raw-block-pvc.yaml
#创建两个pod来测试
cat <raw-block-pod.yaml apiVersion: v1
kind: Pod
metadata:
name: pod-with-raw-block-volume-1
spec:
nodeName:k8s-node1 #调度到node1
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: ["tail -f /dev/null"]
volumeDevices: #使用此参数来调用pvc
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: raw-block-pvcapiVersion: v1
kind: Pod
metadata:
name: pod-with-raw-block-volume-2
spec:
nodeName:k8s-node2 #调度到node2
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: ["tail -f /dev/null"]
volumeDevices: #使用此参数来调用pvc
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: raw-block-pvc
EOF
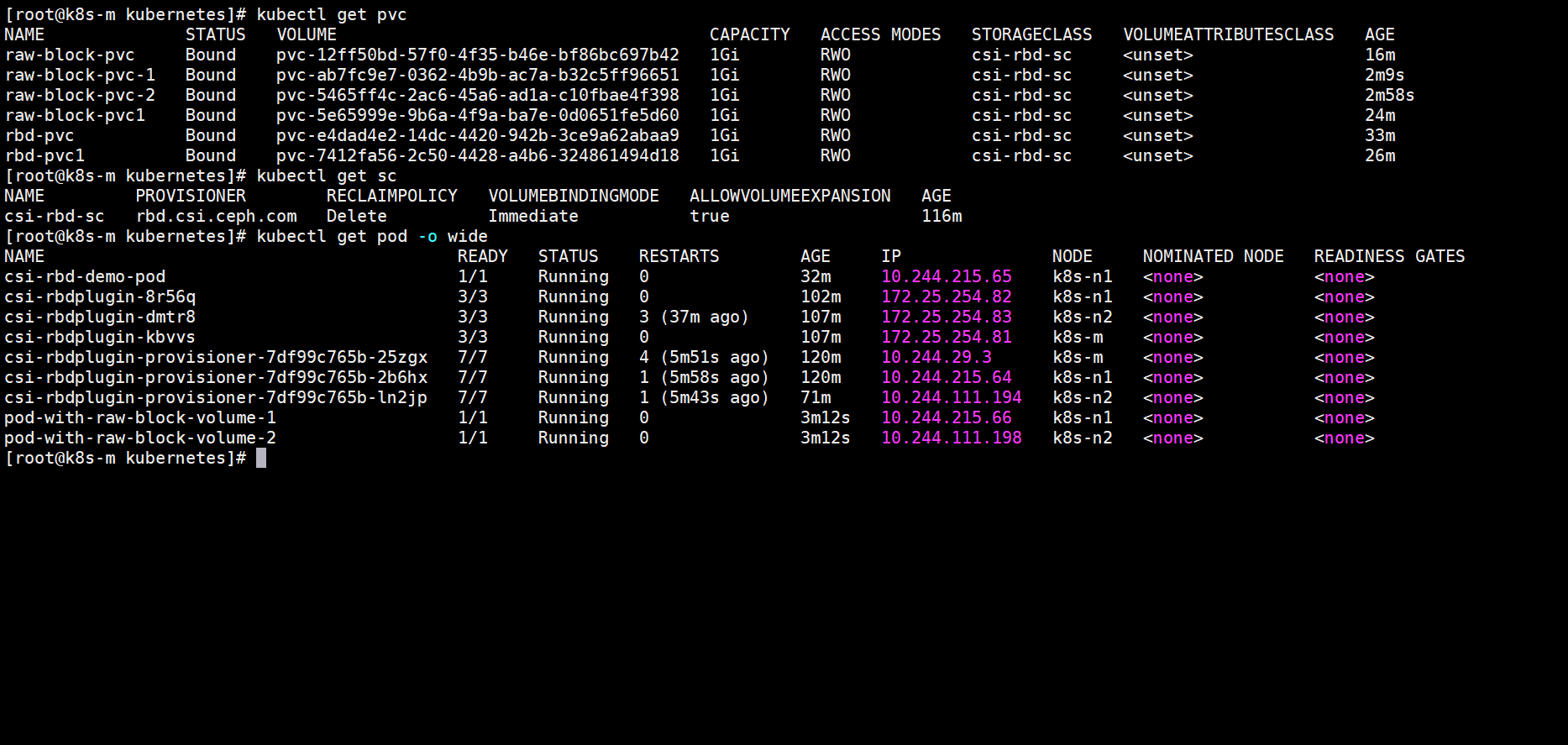
kubectl apply -f raw-block-pod.yaml1. 检查两个 Pod 均运行成功
kubectl get pods -o wide
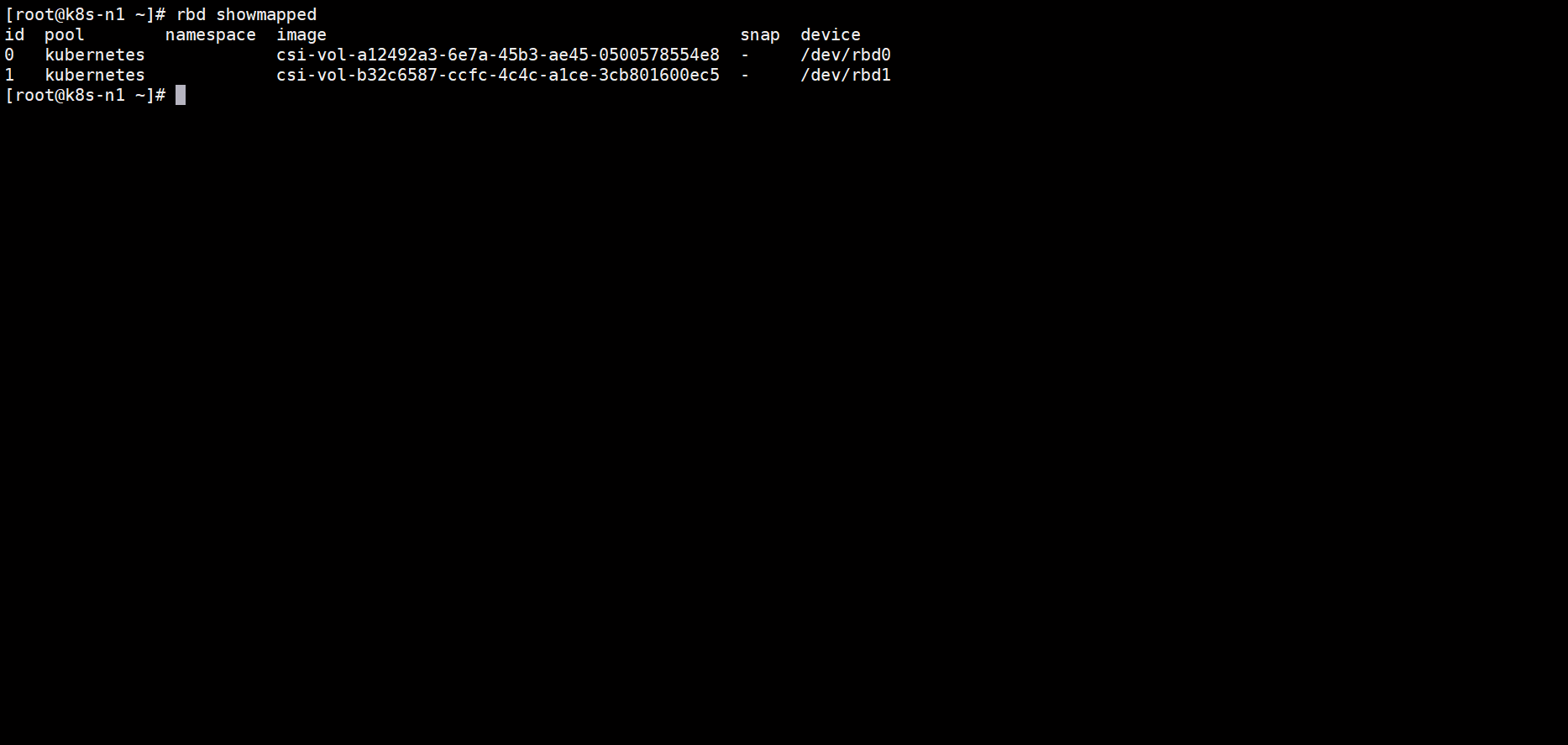
2. 在 Ceph 集群验证多节点映射
ceph osd pool ls # 确认 rbd 池存在
rbd showmapped # 能看到同一个 RBD 镜像被 node-1 和 node-2 同时映射
k8s对接cephfs
准备工作
以下操作与对接ceph rbd一致
- k8s安装ceph客户端
- 配置本地解析
- 获取ceph配置文件
创建数据池与元数据池,fs
bash
cephfs要创建元数据池
#创建数据池与元数据池
ceph osd pool create k8s_cephfs_data 64
ceph osd pool create k8s_cephfs_metadata 64
#根据数据池与元数据池创建fs
ceph fs new <名称> <元数据池> <数据池>
ceph fs new k8s_cephfs k8s_cephfs_metadata k8s_cephfs_data
#查看命令
ceph osd pool ls #查看pool的个数
ceph fs ls #查看文件系统的个数部署MDS
MDS是ceph作为cephfs时必须要的组件用于处理文件系统的元数据
bash
#创建mds(处理元数据组件) --placemenet 3 ceph1 ceph2 ceph3指定部署在节点
ceph orch apply mds k8s_cephfs --placement="3 ceph1 ceph2 ceph3"创建子卷
bash
#在cephfs文件系统中创建一个子卷,不创建的话pvc显示pending,因为volume不能挂载到cephfs文件系统的根目录(k8s_cephfs_data)只能挂载到子目录上
[root@k8s-master kubernetes]# ceph fs subvolumegroup create k8s_cephfs csi
[root@k8s-master kubernetes]# ceph fs subvolumegroup ls k8s_cephfs
[
{
"name": "csi" #查看创建的子卷
}
]创建用户(可选)
bash
这个用户是csi管理ceph集群的用户,可以设定对应用户权限
#创建ceph用户,使用用户进行挂载(可选)
[root@k8s-master kubernetes]# ceph fs authorize fs client.user01 / rwps -o /etc/ceph/ceph.client.user01.keyring client:/etc/ceph/
[root@k8s-master kubernetes]# ceph fs authorize fs client.user02 / r -o /etc/ceph/ceph.client.user02.keyring
ceph权限包括:
r:仅读,如果未指定其他限制,则会向其子目录授予r权限
w:写入,如果未指定其他限制,则会向其子目录授予w权限
p:使用配额权限
s:创建快照权限
#复制用户文件到客户端
scp /etc/ceph/ceph.client.user01.keyring client1:/etc/ceph/
scp /etc/ceph/ceph.client.user02.keyring client2:/etc/ceph/创建控制csi控制器的认证与授权
bash
#创建认证用户与授权
[root@k8s-master kubernetes]# kubectl apply -f csi-nodeplugin-rbac.yaml -f csi-provisioner-rbac.yaml部署csi驱动
bash
[root@k8s-master kubernetes]# cat csidriver.yaml
---
apiVersion: storage.k8s.io/v1
kind: CSIDriver
metadata:
name: "cephfs.csi.ceph.com"
spec:
attachRequired: true
podInfoOnMount: false
fsGroupPolicy: File
seLinuxMount: true
#创建部署csi驱动,允许csi能创建和挂载存储卷
[root@k8s-master kubernetes]# kubectl apply -f csidriver.yaml去除master的污点
bash
[root@k8s-master kubernetes]# kubectl describe nodes k8s-master | grep -i taint
[root@k8s-master kubernetes]# kubectl taint node k8s-master node-role.kubernetes.io/control-plane:NoSchedule-
node/k8s-master untainted部署csi控制器与插件
bash
#此处如果没有访问外网能力需要更改镜像地址为国内
[root@k8s-master kubernetes]# sed -i 's#registry.k8s.io/sig-storage#registry.cn-hangzhou.aliyuncs.com/google-containers#' csi-nodeplugin-rbac.yaml
[root@k8s-master kubernetes]# sed -i 's#registry.k8s.io/sig-storage#registry.cn-hangzhou.aliyuncs.com/google-containers#' csi-nodeplugin-rbac.yaml
部署csi驱动与csi节点插件
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfsplugin-provisioner.yaml -f csi-cephfsplugin.yaml创建配置文件cm
bash
[root@k8s-master kubernetes]# vim csi-cephfs-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: "ceph-csi-config"
data:
config.json: |-
[
{
"clusterID":"297a3e0c-22ca-11f1-aee2-000c29785bd5",
"monitors":[
"172.25.254.91:6789",
"172.25.254.92:6789",
"172.25.254.93:6789"
],
"cephFS": {
"subvolumeGroup": "csi"
}
}
]
[root@k8s-master kubernetes]# kubectl apply -f csi-config-map.yaml创建secret认证文件
bash
#csi直接使用管理员用户来管理ceph集群
[root@k8s-master kubernetes]# ceph auth get client.admin
[client.admin]
key = AQB5obppMzDDNRAAd5QM5eCYI3syzYr1tIdfYQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[root@k8s-master kubernetes]# vim csi-cephfs-secret
---
apiVersion: v1
kind: Secret
metadata:
name: csi-cephfs-secret
stringData:
userID: admin
userKey: AQB5obppMzDDNRAAd5QM5eCYI3syzYr1tIdfYQ==
adminID: admin
adminKey: AQB5obppMzDDNRAAd5QM5eCYI3syzYr1tIdfYQ==
encryptionPassphrase: test_passphrase
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfs-secret创建存储类
bash
#创建存储类
[root@k8s-master kubernetes]# vim csi-cephfs-sc.yaml
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-cephfs-sc
provisioner: cephfs.csi.ceph.com
parameters:
clusterID: 297a3e0c-22ca-11f1-aee2-000c29785bd5
fsName: k8s_cephfs
pool: k8s_cephfs_data
csi.storage.k8s.io/provisioner-secret-name: csi-cephfs-secret
csi.storage.k8s.io/provisioner-secret-namespace: default
csi.storage.k8s.io/controller-expand-secret-name: csi-cephfs-secret
csi.storage.k8s.io/controller-expand-secret-namespace: default
csi.storage.k8s.io/controller-publish-secret-name: csi-cephfs-secret
csi.storage.k8s.io/controller-publish-secret-namespace: default
csi.storage.k8s.io/node-stage-secret-name: csi-cephfs-secret
csi.storage.k8s.io/node-stage-secret-namespace: default
mounter: kernel
reclaimPolicy: Delete
allowVolumeExpansion: true
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfs-sc.yaml创建PVC
bash
[root@k8s-master kubernetes]# vim csi-cephfs-pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: csi-cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: csi-cephfs-sc
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfs-pvc.yaml
#验证是否bound,bound则对接成功
[root@k8s-master kubernetes]# kubectl get pvc
测试
bash
#创建pod测试是否能挂载使用
[root@k8s-master kubernetes]# vim csi-cephfs-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: csi-cephfs-demo-pod
spec:
containers:
- name: web-server
image: docker.io/library/nginx:latest
volumeMounts:
- name: mypvc
mountPath: /usr/share/nginx/html/ #将默认发布目录挂载上去
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: csi-cephfs-pvc
readOnly: false
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfs-pod.yaml
由于ceph作为cephfs文件系统可以给多pod以及不同节点挂载使用,所以再创一个pod挂载验证
[root@k8s-master kubernetes]# cp csi-cephfs-pod.yaml csi-cephfs-pod2.yaml
[root@k8s-master kubernetes]# cat csi-cephfs-pod2.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: csi-cephfs-demo-pod2
spec:
containers:
- name: web-server
image: docker.io/library/nginx:latest
volumeMounts:
- name: mypvc
mountPath: /usr/share/nginx/html/ #同理
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: csi-cephfs-pvc
readOnly: false
[root@k8s-master kubernetes]# kubectl apply -f csi-cephfs-pod2.yaml
kubectl exec -it csi-cephfs-demo-pod -- /bin/sh -c "echo 'hello test page' > /usr/share/nginx/html/index.html由于默认发布目录被作为挂载路径,目录的文件都被清空覆盖,在集群访问pod的IP会显示403资源不存在

bash
[root@k8s-node1 ~]# curl 10.244.169.154
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.29.6</center>
</body>
</html>
[root@k8s-node1 ~]# curl 10.244.169.155
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.29.6</center>
</body>
</html>
#添加默认发布文件
[root@k8s-master kubernetes]# kubectl exec -it csi-cephfs-demo-pod -- /bin/sh -c "echo 'hello test page' > /usr/share/nginx/html/index.html"
#再次访问
[root@k8s-master kubernetes]# curl 10.244.169.154
hello test page
[root@k8s-master kubernetes]# curl 10.244.169.155
hello test page
#由于访问的内容是一致可以证明cephfs可以被多个节点同时挂载总结
K8s 与 Ceph 的对接是容器化架构中 "计算" 与 "存储" 解耦的核心方案,既利用 K8s 的编排能力实现应用的弹性部署,又通过 Ceph 的分布式存储特性保障数据的高可用和扩展性。实际生产中,可根据应用类型选择 RBD(块存储)或 CephFS(文件存储),并结合 Ceph 的副本策略、扩容能力,构建端到端的容器化存储解决方案。