目录
[一、正排索引 vs 倒排索引](#一、正排索引 vs 倒排索引)
[3、roaring bitmap](#3、roaring bitmap)
在探讨 Elasticsearch(以下简称 ES)时,我们最常听到的一个词就是"快"。无论是亿级数据的全文检索,还是复杂的聚合分析,ES 都能在毫秒级返回结果。支撑这种高性能的核心基石,正是倒排索引。
本文将从原理层面深入剖析,什么是倒排索引,它与传统数据库的正排索引有何不同,以及 ES 是如何利用它实现极速搜索的。
一、正排索引 vs 倒排索引
要理解倒排索引,首先得看看我们熟悉的传统关系型数据库(如 MySQL)是如何工作的。
1、正排索引
在关系型数据库中,数据是以"行"为单位存储的。当我们查询数据时,通常是基于主键 ID 去查找具体的行记录。这种"文档 ID -> 文档内容"的映射关系,被称为正排索引。
场景模拟:
假设我们要查找内容中包含"Elasticsearch"的所有文章。在正排索引中,数据库不得不进行全表扫描:
- 读取文档 1,检查内容是否包含"Elasticsearch"。
- 读取文档 2,检查...
- 读取文档 N,检查...
这种方式在数据量小的时候尚可接受,但一旦数据量达到千万级,LIKE '%keyword%' 的查询效率将呈指数级下降,甚至导致数据库崩溃。
2、倒排索引
为了解决这个问题,Elasticsearch 采用了倒排索引。它的核心思想是建立"关键词 -> 文档 ID"的映射。
类比理解:
- 正排索引 就像是一本书的内容,你需要一页页翻才能找到你想看的情节。
- 倒排索引 就像是书末尾的索引页,它直接告诉你"Elasticsearch"这个词出现在第 1 页、第 5 页和第 10 页。
二、倒排索引的核心结构
倒排索引主要由两个部分组成:词典 和倒排列表。
1、词典
词典存储了所有文档中出现过的词项,并按照字典顺序排序。它的作用类似于字典的目录,用于快速定位某个词项是否存在。
2、倒排列表
倒排列表记录了包含某个词项的所有文档 ID 以及相关的元数据。一个典型的倒排列表条目包含以下信息:
- 文档 ID:包含该词项的文档唯一标识。
- 词频:该词项在文档中出现的次数。词频越高,通常意味着相关性越强。
- 位置信息:词项在文档中的具体位置。这对于短语查询(如"快速 搜索")至关重要,它确保两个词是相邻的。
- 偏移量:词项在原始文本中的起始和结束位置,用于搜索结果的高亮显示。
三、倒排索引的构建过程
倒排索引的构建是一个复杂但高效的过程,主要包含以下几个步骤:
- 文档收集:收集需要索引的原始文档。
- 分词 :使用分析器将文档内容分解成独立的词项。例如,句子"I love Elasticsearch"会被分解为
["i", "love", "elasticsearch"]。 - 词汇规范化:对词项进行标准化处理,例如转换为小写、去除停用词(如"the"、"is")、词干提取等。这能确保"Love"和"love"被视为同一个词。
- 构建倒排列表:为每个唯一的词项创建一个倒排列表,记录包含该词项的所有文档 ID、词频、位置等信息。
- 生成索引文件:将词典和倒排列表持久化存储到磁盘上,形成索引段。
四、倒排索引的查询机制
当用户发起一个搜索请求时,Elasticsearch 会执行以下操作:
- 查询解析 :将用户的查询语句(如"quick brown fox")使用与索引时相同的分析器进行处理,分解为词项
["quick", "brown", "fox"]。 - 查找倒排列表:在词典中查找每个词项对应的倒排列表。
- 合并结果 :根据查询逻辑(AND/OR)合并这些倒排列表。
- AND 查询:取所有倒排列表的交集,找出同时包含所有词项的文档。
- OR 查询:取所有倒排列表的并集,找出包含任意一个词项的文档。
- 评分排序:使用 BM25 等算法,根据词频、文档频率等信息计算每个匹配文档的相关性得分,并按得分高低排序返回结果。
五、性能优化技术
为了在海量数据下保持高性能,Lucene(ES 的底层库)对倒排索引进行了深度优化:
1、有限状态转换器
词典使用有限状态转换器这种高效的数据结构进行压缩存储。它不仅能极大地减少磁盘和内存占用,还支持高效的前缀查询。
2、跳跃表
在倒排列表中引入跳跃表,可以在合并大型列表时跳过大量不相关的文档 ID,从而加速查询。
3、roaring bitmap
使用 roaring bitmap 来高效地表示和压缩文档 ID 集合,特别适用于基数较高的场景,能显著降低内存消耗并提升聚合性能。
六、举例
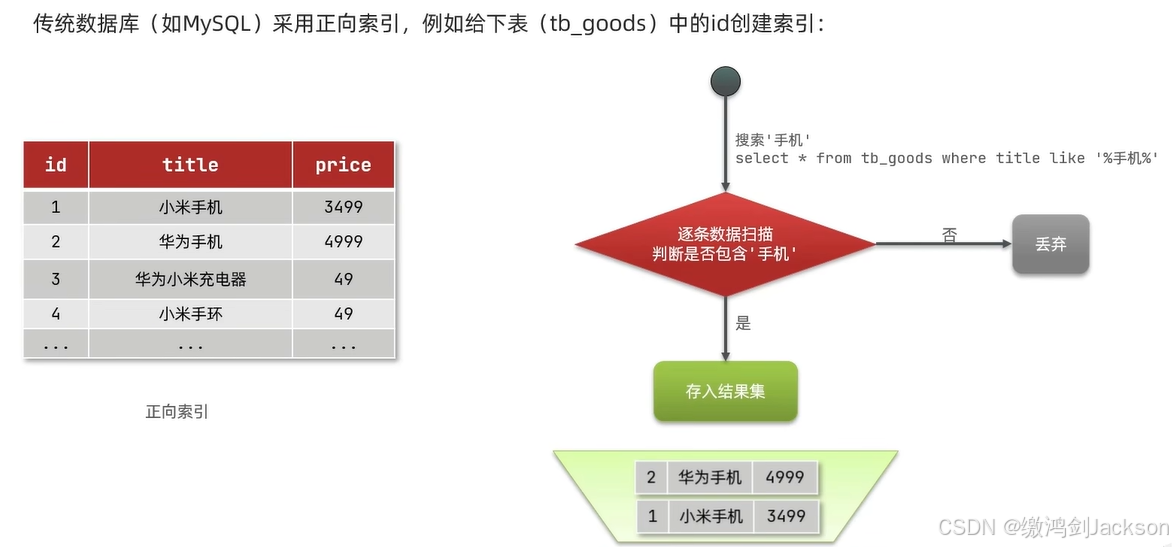
1、传统数据库(如mysql)
一行一行地用like进行匹配,表的行数较多时,效率很低,显然不合适。
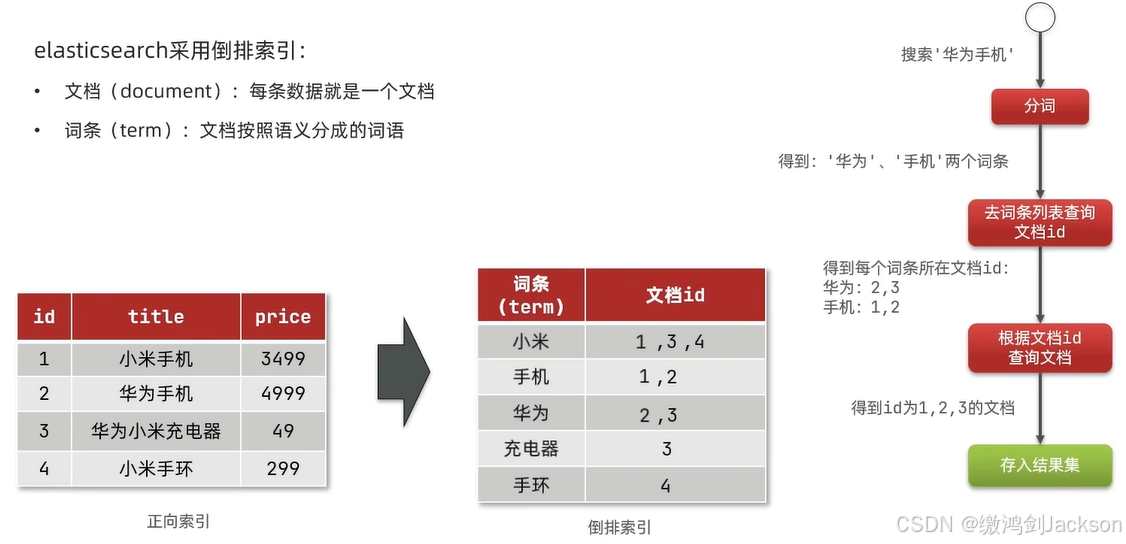
2、ElasticSearch
先根据词条(term)去找相关行(也叫文档)的id,再根据行的id,找那行的数据。
说白了就是,词条--->行id(文档id)--->行数据。
总结
倒排索引是 Elasticsearch 的灵魂。它通过牺牲一定的写入性能和存储空间,换取了无与伦比的读取速度。理解倒排索引的原理,不仅能帮助你更好地使用 ES,还能在遇到慢查询、内存溢出等问题时,为你提供清晰的排查思路。
下次当你在搜索框中输入关键词并瞬间得到结果时,不妨想一想,这背后正是倒排索引在默默地高效运转。
