文章目录
- 摘要
- abstract
- 一、LLaVA-NeXT-Interleave:在大型多模态模型中处理多图像、视频和 3D。
-
- 1.1 做了什么:
- 1.2 交错多图像任务和数据
- 1.3指令微调(架构没变:遵循 LLaVA-NeXT 采用最通用的框架,即视觉编码器、中间投影器和强大的 LLM )
- 1.4总结:
- 二、实验
- 总结
摘要
学习LLaVa系列算法中LLaVA-NeXT-Interleave模型,旨在解决现有大型多模态模型(LMMs)主要处理单图像任务、难以泛化到多图像场景的问题。该模型通过将多图像、视频、3D及单图像数据统一转换为交错数据格式,并构建包含117.76万样本的M4-Instruct数据集进行指令微调,实现了跨任务的涌现泛化能力。同时本周工作聚焦于Amazon数据下载与特征提取,算法实验正在进行中。
abstract
Studying the LLaVA series algorithms, specifically the LLaVA-NeXT-Interleave model, aims to address the limitation of existing large multimodal models (LMMs), which primarily handle single-image tasks and struggle to generalize to multi-image scenarios. This model unifies multi-image, video, 3D, and single-image data into an interleaved data format and performs instruction fine-tuning using the M4-Instruct dataset, which contains 1.1776 million samples, achieving emergent generalization capabilities across tasks. Meanwhile, this week's work focuses on Amazon data download and feature extraction, with algorithm experiments currently underway.
一、LLaVA-NeXT-Interleave:在大型多模态模型中处理多图像、视频和 3D。
24年背景:
现有的开放 LMMs 主要专注于单图像任务,它们在多图像场景中的应用仍未得到充分探索。
先前的 LMM 研究分别处理不同场景,无法跨场景泛化新的涌现能力/泛化。
引入 LLaVA-NeXT-Interleave,同时在 LMMs 中处理多图像、多帧(视频)、多视图(3D)和多补丁(单图像)场景。
怎么做:将交错数据格式视为通用模板,训练模型。
思想还是指令跟随数据训练模型,只是数据变成交错数据(多图像、多帧(视频)、多视图(3D)和多补丁(单图像))。
1.1 做了什么:
交错数据格式统一不同任务:将多图像、视频、3D 和单图像数据都转换为交错训练格式,在单个 LMM 中统一不同任务。
新数据集和基准测试:编译了一个高质量训练数据集 M4-Instruct,包含 117.76 万样本,赋予 LMMs M4 能力,跨越 4 个主要领域(多图像、视频、3D 和单图像),包含 14 个任务和 41 个数据集。
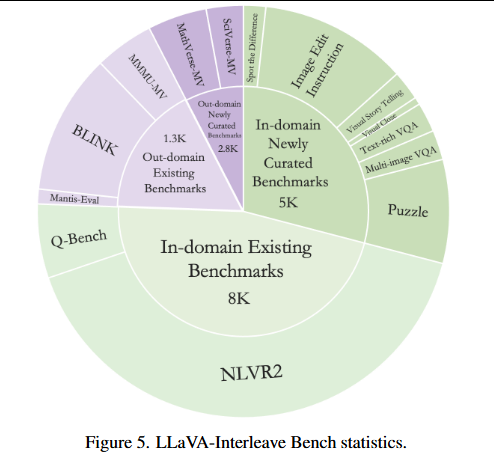
策划了 LLaVA-Interleave Bench (之前是LLaVA Bench )来全面评估 LMMs 的多图像性能。
跨任务转移的涌现能力:通过在多样化任务集上联合训练,展示了跨不同设置和模态转移任务的涌现能力,例如从图像之间的差异检测到视频。
1.2 交错多图像任务和数据
采用交错多图像格式来统一以下四个任务的数据输入:
1.多图像场景包括结合交错视觉 - 语言输入与多个图像的视觉指令。涵盖了我们训练数据中包含的 12 个具有挑战性的现实世界任务,例如找差异、视觉故事讲述、图像编辑指令生成、交错多图像对话、多图像谜题、低级多图像评估等。
2.多帧场景指通过将视频采样为多帧来将视频作为输入数据,保留多图像序列中的时间视觉线索。主要关注 2 个任务:视频详细标注和视频 VQA。
3.多视图场景通过来自不同视角的多视图图像描绘 3D 环境,其中视觉对应和差异可以指示 3D 世界中的空间信息。包括 2 个任务:具身 VQA(对话和规划)和 3D 场景 VQA(标注和基础)。
4.多补丁场景表示传统的单图像任务。
M4-Instruct:策划了一个全面的训练数据集,包括 117.76 万实例,称为 M4-Instruct,广泛跨越多图像、多帧和多视图场景,包含 14 个任务和 41 个数据集,以及多补丁数据以保持基本单图像性能。
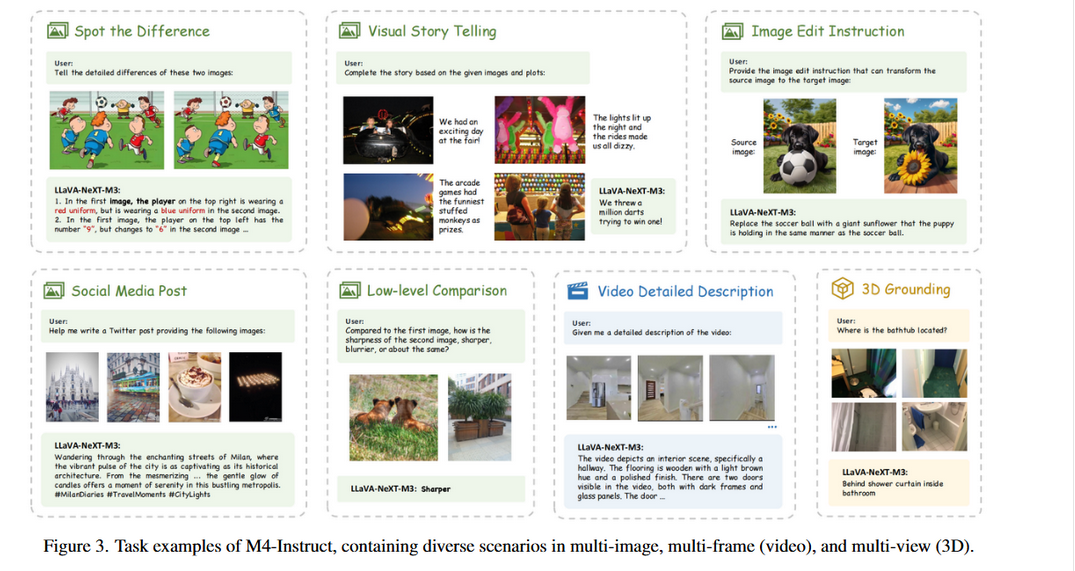
展示了前三个场景的任务示例:多图像,视频,3D视角。
M4-Instruct 的数据概述:
1.多图像数据,大多数数据集是从先前的公共工作中收集的,并严格转换为统一格式。
2.视频数据,我们从 LLaVA-Hound 收集了一个 25.5 万子集,包括 24 万视频 VQA 和 1.5 万视频详细标注。
- 3D 数据,广泛收集了 相关项目的训练集,涵盖室外和室内场景。
4.单图像数据,随机采样了 LLaVA-NeXT 中 40% 的阶段 -2 微调数据,旨在保持单图像能力。
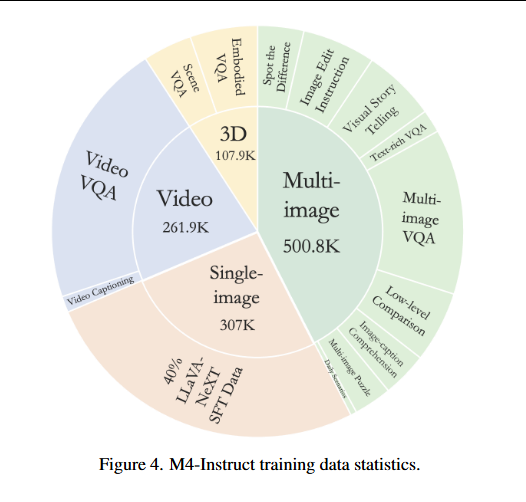
利用 GPT-4V 标注了 3 个新任务以启用更多样化的能力,即现实世界差异、合成差异和 Twitter 帖子。
如图为基准测试的数据概述。
将多图像任务分为两类将多图像任务分为两类:
1.域内评估包括在训练期间已经见过的任务,旨在验证模型在熟悉场景中的性能。
2.域外评估涉及与训练场景不重叠的任务,揭示 LMMs 的泛化能力。
1.3指令微调(架构没变:遵循 LLaVA-NeXT 采用最通用的框架,即视觉编码器、中间投影器和强大的 LLM )
指令微调期间的几个关键技术:
1.从单图像模型继续训练。交错多图像任务可以被视为单图像场景的扩展,格式更灵活,推理更具挑战性。 LLaVA-NeXT-Image 作为基础模型使用 M4-Instruct 数据集执行交错多图像指令微调。
2.训练期间混合交错数据格式。交错多图像训练期间对图像 token 的位置采用两种格式选择:一种是将所有图像 token 放在提示前面,同时在文本中保持占位符,表示为前置格式。第二种保留交错格式将图像 token 放在它们原本的位置,即的位置,表示为交错格式,对于第二种LLaVA-NeXT-Interleave 支持更灵活的推理模式,对不同输入格式表现出鲁棒性。
3.组合不同数据场景提高单个任务性能。现有工作仅使用一种类型的数据源进行监督微调,利用 M4-Instruct 同时使用四个不同任务(多图像/帧/视图/补丁)进行指令微调。
四个现实世界交错场景上评估我们的 LLaVA-NeXT-Interleave 模型:
多图像评估,采用提出的 LLaVA-Interleave Bench,涵盖全面的域内和域外任务。
视频评估,利用现有的 NExT-QA、MVBench 、视频详细描述(VDD)和 ActivityNet-QA(Act)。
3D 评估选择 ScanQA 、3D-LLM 中的两个任务, 3D 辅助对话和任务分解。
单图像:原LLaVA-NeXT 任务。

三种交错场景的性能比较,包括多图像、多帧(视频)和多视图 (3D)。
模型在各种评估基准上均实现了 SoTA 性能。
1.4总结:
因为对视频,3D等论文没有看太多,所以相关的任务性能指标不清楚没有放,只放了sota结果。
可学习的点:就这个指令微调思想+设计数据+结构就能够从单图像模型上,泛化到多图像、3D、视频...上。
二、实验
在本周对amazon数据进行了下载,除了交互外,还下载了元数据(图片,文本,地区...)。
对于数据相关特征做了提取。
正在跑算法。
总结
在上周的设计下,重新下载了数据,对数据进行了相关操作,节奏在一步步往下走。论文的学习按照LLaVa系列论文,学习多模态图像扩展的视频3D等,继续马上到最新LLaVa多模态研究,之后计划深入细节。