国产开源大模型发布时间线
本文档按发布时间倒序梳理三大主流国产开源大模型(MiniMax、DeepSeek、Qwen)系列的关键版本,便于横向对比各阵营的技术演进脉络。
数据截至 2026 年 3 月 29 日 · 涵盖 MiniMax、DeepSeek、Qwen 三大开源模型系列
一、MiniMax 模型时间线
魔塔社区:MiniMax @ ModelScope
2026 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2026-03-18 | MiniMax M2.7 | 文本 / Agent | 新一代 Agent 旗舰,首次实现"模型自我进化",可深度参与自身训练与优化,研发场景中可承担 30%--50% 工作量 |
| 2026-02-12 | MiniMax M2.5 | 文本 | 原生 Agent 生产级模型,编程能力显著提升,支持工具调用与搜索,成本优势突出(1 万美元可支持 4 个 Agent 连续工作一年) |
| 2026-01-16 | MiniMax Music-2.5 | 音乐 | 音乐生成模型升级版,支持纯音乐创作,突破风格边界 |
2025 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2025-12-22 | MiniMax M2.1 | 文本 | 多语言编程专家,专注复杂编程体验与精准代码重构 |
| 2025-10-30 | MiniMax Music-2.0 | 音乐 | 百变唱将,人声灵动,精准乐器控制,支持 5 分钟音乐创作 |
| 2025-10-29 | MiniMax Speech-2.6 | 语音 | 新一代语音模型,极致音质与韵律表现,首包响应时间压缩至 250 ms |
| 2025-10-28 | MiniMax Hailuo-2.3 | 视频 | 肢体动作、物理表现与指令遵循能力全面升级,支持 Fast 版本 |
| 2025-10-27 | MiniMax M2 | 文本 | 10B 激活参数(总参 230B),专为编码与 Agent 工作流优化,开源后登顶开源模型榜首 |
| 2025-09-11 | MiniMax Music-1.5 | 音乐 | 支持 4 分钟音乐时长,回归"好听"本质 |
| 2025-08-06 | MiniMax Speech-2.5 | 语音 | 支持更多语种,极高相似度声音克隆表现 |
| 2025-06-18 | MiniMax Hailuo-02 | 视频 | 支持 1080P 分辨率及 10 秒视频生成 |
| 2025-06-16 | MiniMax M1 | 文本 / 推理 | 推理模型,80K 思维链 × 1M 上下文输入,效果比肩海外顶尖模型,全球首个开源大规模混合架构推理模型 |
| 2025-04-02 | Speech-02 系列 | 语音 | 超真实人声表现,卓越韵律与稳定性 |
| 2025-02-15 | Image-01 | 图像 | 支持文本描述生成多种尺寸图片 |
| 2025-02-11 | T2V-01-Director / I2V-01-Director | 视频 | 导演级运镜控制,电影级镜头叙事语言 |
| 2025-01-15 | Text-01 / VL-01 | 文本 / 视觉 | 全新一代文本模型与视觉理解模型 |
2024 年及更早
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2024-08-31 | Video Generation API | 视频 | 视频生成接口首次开放 |
| 2024-06-27 | Music Generation API | 音乐 | 音乐生成接口首次开放 |
| 2024-05 | abab 6.5s / 6.5 / 5.5 | 文本 | abab 系列主力版本 |
| 2024-01 | abab 5.5s | 文本 | abab 系列早期优化版 |
MiniMax 模型分类汇总
| 类别 | 代表模型 |
|---|---|
| 🔤 文本模型 | M2.7、M2.5、M2.1、M2、M1、Text-01、abab 系列 |
| 👁️ 视觉理解 | VL-01 |
| 🎬 视频生成 | Hailuo-2.3、Hailuo-02、T2V / I2V-01-Director |
| 🔊 语音模型 | Speech-2.6、Speech-2.5、Speech-02 系列 |
| 🎵 音乐模型 | Music-2.5、Music-2.0、Music-1.5 |
| 🖼️ 图像模型 | Image-01 |
二、DeepSeek 模型时间线
2026 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2026-02-11 | DeepSeek-V3.2(上下文升级版) | 文本 | 上下文窗口从 128K 扩展至 1M tokens,可一次性处理海量长文本 |
2025 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2025-12-01 | DeepSeek-V3.2 | 文本 | 正式版发布,支持思考 / 非思考双模式切换,定位"话少活好"日常助手,性能比肩 GPT-5 |
| 2025-12-01 | DeepSeek-V3.2-Speciale | 文本 / 推理 | "偏科天才",专攻高难度数学、学术研究逻辑验证与编程竞赛解题 |
| 2025-09-29 | DeepSeek-V3.2-Exp | 文本 | 实验版,引入 DSA 稀疏注意力机制,长文本训练与推理效率大幅提升,API 降价 50% 以上 |
| 2025-09-22 | DeepSeek-V3.1-Terminus | 文本 | V3.1 改进版,优化中英混杂问题,增强 Code Agent 与 Search Agent 能力 |
| 2025-08-21 | DeepSeek-V3.1 | 文本 | 引入混合推理架构(单模型同时支持思考与非思考模式),上下文扩展至 128K,Agent 能力大幅增强 |
| 2025-05-28 | DeepSeek-R1-0528 | 文本 / 推理 | R1 系列旗舰推理模型升级版,让 DeepSeek 声名远播 |
| 2025-03-24 | DeepSeek-V3-0324 | 文本 | V3 小版本升级,提升推理、代码生成与中文写作能力 |
| 2025-01-20 | DeepSeek-R1 | 文本 / 推理 | 强化学习驱动,推理能力比肩 OpenAI o1,以极低成本引爆全球关注 |
2024 年及更早
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2024-12-26 | DeepSeek-V3 | 文本 | 671B 参数 MoE 架构,生成速度较 V2 提升 3 倍,正式开源 |
| 2024-05-06 | DeepSeek-V2 | 多模态 | 新增图像理解与生成模块,支持图文联合推理 |
| 2023-11-08 | DeepSeek-V1 | 文本 | 130 亿参数,初代开源模型,支持中英双语 |
| 更早 | DeepSeek-Coder / DeepSeek-Math | 代码 / 数学 | 代码生成与数学推理领域的专用模型系列 |
DeepSeek 模型分类汇总
| 类别 | 代表模型 |
|---|---|
| 🔤 文本模型 | V3.2、V3.2-Speciale、V3.1、V3.1-Terminus、V3、V2、V1 |
| 🧠 推理模型 | R1、R1-0528 |
| 💻 代码 / 数学 | DeepSeek-Coder、DeepSeek-Math |
三、Qwen(通义千问)模型时间线
魔塔社区:Qwen @ ModelScope
2026 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2026-03-03 | Qwen3.5 小尺寸系列(0.8B / 2B / 4B / 9B) | 文本 / 端侧 | 覆盖超轻量到中等规模端侧部署,支持原生 256K 上下文,可运行于移动设备与边缘场景 |
| 2026-02-27 | Qwen3.5 中等规模系列(Flash / 35B-A3B / 122B-A10B / 27B) | 文本 / 多模态 | 采用 Gated Delta Network + MoE 高效架构,35B-A3B 仅激活 3B 参数即可超越上一代 235B 旗舰,支持 201 种语言 |
| 2026-02-16 | Qwen3.5-Plus(397B-A17B) | 文本 / 多模态 | 全球首个原生多模态 MoE 大模型,总参 3970 亿仅激活 170 亿,性能媲美万亿参数模型,支持视觉 - 语言统一理解 |
| 2026-02-04 | Qwen3-Coder-Next(80B-A3B) | 代码 / Agent | 专为 AI 编程智能体设计,基于 Qwen3-Next 架构,支持 256K 上下文,推理成本显著降低 |
| 2026-01-27 | Qwen3-Max-Thinking(1T+) | 文本 / 推理 | 阿里规模最大旗舰推理模型,预训练数据 36T Tokens,支持自适应工具调用与多轮迭代推理,19 项基准测试领先 |
| 2026-01-12 | qwen-image-plus-2026-01-09 | 图像生成 | 千问图像生成全新快照版,为 qwen-image-max 蒸馏加速版,支持快速生成高质量图像 |
2025 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2025-12 | Wan2.6 系列(t2v / i2v / r2v) | 视频生成 | 通义万相视频生成模型升级,支持文生视频、图生视频、参考生视频等多模态创作 |
| 2025-09 | Qwen3-Omni(30B-A3B) | 全模态 / 端到端 | 原生端到端多语种全模态大模型,流畅处理文本 / 图像 / 音频 / 视频输入,支持实时交互响应 |
| 2025-08 | Qwen-Image / Qwen-Image-Edit | 图像生成 / 编辑 | 通义千问图像基础模型及编辑模型发布,支持高质量文生图与精细化图像编辑 |
| 2025-07 | Qwen3 系列(0.6B--32B Dense + 30B / 235B MoE) | 文本 / 混合推理 | 国内首款融合"快思考"与"慢思考"的混合推理模型,支持 /think 模式切换,119 种语言覆盖,强到弱蒸馏技术使小模型继承旗舰能力 |
| 2025-04 | Qwen3 系列首发 | 文本 / 推理 | 阿里巴巴开源新一代通义千问大语言模型系列,涵盖 6 款密集模型和 2 款混合专家模型 |
| 2025-03 | QwQ-32B | 推理 / 数学 | 开源推理大模型,专注数学推理与逻辑验证,在 AIME、MATH 等基准测试中表现优异 |
| 2025-02 | Qwen2.5-VL 系列(3B / 7B / 32B / 72B) | 视觉语言 | 新一代多模态视觉理解模型,支持文档解析、长视频理解、视觉代理操作,13 项权威评测视觉理解夺冠 |
| 2025-01 | Qwen2.5-Max | 文本 / MoE | 超 20 万亿 token 训练的混合专家架构旗舰模型,通过阿里云 API 提供服务,性能对标世界顶级闭源模型 |
| 2025-01 | Qwen2.5-1M 系列 | 文本 / 长上下文 | 支持 100 万 tokens 超长上下文,采用 YARN 扩展技术,适用于超长文档分析与跨文档推理 |
2024 年
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2024-12 | Qwen2.5-Coder 系列(0.5B--32B) | 代码生成 | 专为编程优化的代码模型系列,支持代码生成、理解、调试与重构,在 HumanEval、MBPP 等评测中领先 |
| 2024-11 | Qwen2.5-Math 系列 | 数学推理 | 专注数学问题求解的专用模型,支持多步推理与公式推导,在 MATH、GSM8K 等基准测试中表现突出 |
| 2024-09 | Qwen2.5 系列(0.5B--72B + MoE) | 文本 / 多领域 | 知识、代码、数学能力全面升级,首次推出领域专用模型(Coder / Math),支持 128K 上下文,29 种语言覆盖 |
| 2024-06 | Qwen2 系列(0.5B--72B + 57B-A14B MoE) | 文本 / 长上下文 | 新一代开源模型,性能全面超越 Qwen1.5 与 Llama3,部分模型支持 128K 上下文,引入细粒度专家与双块注意力机制 |
| 2024-05 | CodeQwen1.5 | 代码生成 | 通义千问代码模型升级,支持多语言代码生成与理解,与 Qwen1.5 架构对齐,生态兼容性提升 |
| 2024-04 | Qwen1.5 系列(0.5B--110B + MoE) | 文本 / 全面开源 | 架构与主流模型对齐,所有模型采用 Apache 2.0 协议取消商业限制,统一支持 32K 上下文,极大推动社区普及 |
| 2024-02 | Qwen1.5 首发 | 文本 / 开源 | 里程碑式升级,通过更开放、易用、强大的重构赢得社区广泛赞誉,形成完整尺寸梯度 |
2023 年及更早
| 发布时间 | 模型名称 | 类别 | 核心特点 |
|---|---|---|---|
| 2023-12 | Qwen-Audio / Qwen-Audio-Chat | 音频理解 | 业界首个开源大规模音频语言模型,支持 30+ 音频任务,理解语音 / 音乐 / 环境音内容 |
| 2023-11 | Qwen-VL / Qwen-VL-Chat | 视觉语言 | 基于 Qwen-7B 扩展的多模态模型,支持 448×448 高分辨率图像、中文 OCR 优化、视觉定位与图文对话 |
| 2023-09 | Qwen-14B / Qwen-72B | 文本 | 推出 140 亿与 720 亿参数模型,性能超越同尺寸开源模型,72B 支持 32K 上下文,逼近 GPT-3.5 水平 |
| 2023-08 | Qwen-7B / Qwen-7B-Chat | 文本 | 通义千问系列首款开源模型,70 亿参数,基于 2.2 万亿 tokens 预训练,支持 8K 上下文,Apache 2.0 协议开源 |
| 2023-04 | 通义千问 1.0 | 文本 | 阿里云峰会正式发布初代通义千问大语言模型,支持中英双语对话与内容创作 |
Qwen 模型分类汇总
| 类别 | 代表模型 |
|---|---|
| 🔤 文本模型 | Qwen3.5 系列、Qwen3 系列、Qwen2.5 系列、Qwen2 系列、Qwen1.5 系列、Qwen-7B / 14B / 72B |
| 🧠 推理模型 | Qwen3-Max-Thinking、QwQ-32B、Qwen3(混合推理模式) |
| 💻 代码模型 | Qwen3-Coder 系列、Qwen2.5-Coder 系列、CodeQwen1.5 |
| 🔢 数学模型 | Qwen2.5-Math 系列 |
| 👁️ 视觉语言 | Qwen2.5-VL 系列、Qwen-VL、Qwen2-VL |
| 🔊 音频模型 | Qwen-Audio、Qwen2-Audio |
| 🌐 全模态 | Qwen3-Omni、Qwen2.5-Omni |
| 🖼️ 图像生成 | Qwen-Image、Qwen-Image-Edit、qwen-image-plus |
| 🎬 视频生成 | Wan2.6 系列(通义万相) |
| 🔍 嵌入 / 重排序 | Qwen3-Embedding 系列、Qwen3-Reranker 系列 |
| 🛡️ 安全模型 | Qwen3Guard 系列 |
四、三大模型最新版本性能对比(2026 年 3 月)
对比对象:MiniMax M2.7 | DeepSeek-V3.2(1M 上下文版) | Qwen3.5 系列
🔹 核心参数与技术架构对比
| 维度 | MiniMax M2.7 | DeepSeek-V3.2(1M 版) | Qwen3.5 系列 |
|---|---|---|---|
| 发布时间 | 2026-03-18 | 2026-02-11 | 2026-02 ~ 03(分批次) |
| 模型类型 | 文本 / Agent 原生 | 文本 / 超长上下文 | 文本 / 多模态 / 端侧 |
| 架构创新 | Agent Harness 自我进化框架 | DSA 稀疏注意力 + 投机采样 | Gated Delta Network + MoE 混合架构 |
| 参数量 | 未公开(高效激活设计) | ~660B(MoE) | 0.8B ~ 397B(多尺寸覆盖) |
| 激活参数 | 高效稀疏激活 | 动态稀疏激活 | 35B 模型仅激活 3B,122B 激活 10B |
| 上下文窗口 | 标准长上下文(官方未强调极限) | 1,000,000 tokens 🔥 | 256K(端侧)/ 1M(Flash 托管版) |
| 支持语言 | 多语言(侧重中英) | 中英为主,多语言支持 | 201 种语言 🌐 |
| 开源协议 | 部分开源 + API 服务 | ✅ MIT License 完全开源 | ✅ Apache 2.0 / 部分模型开源 |
| 部署门槛 | API 为主,企业级部署 | 消费级显卡可运行中等版本 | 0.8B~9B 支持移动端,27B+ 需服务器 |
🔹 基准测试性能对比(公开数据整理)
数据来源:官方技术报告、第三方评测平台(截至 2026 年 3 月)
| 评测基准 | 任务类型 | MiniMax M2.7 | DeepSeek-V3.2 | Qwen3.5-122B |
|---|---|---|---|---|
| SWE-Pro | 软件工程修复 | 🥇 56.22%(追平 Opus) | ~52%(预估) | ~54%(预估) |
| VIBE-Pro | 端到端项目交付 | 🥇 55.6% | --- | --- |
| Terminal Bench 2 | 复杂系统理解 | 🥇 57.0% | --- | --- |
| GDPval-AA(ELO) | 专业办公能力 | 🥇 1495(开源第一) | ~1450(预估) | ~1480(预估) |
| MM-Claw | 复杂 Skills 遵循 | 🥇 62.7%(近 Sonnet 4.6) | --- | --- |
| MathVista | 多模态数学推理 | --- | --- | 🥇 87.4% |
| MMMU | 多学科多模态理解 | --- | --- | 🥇 领先同尺寸模型 |
| HumanEval / MBPP | 代码生成 | 🥈 一线水平 | 🥇 领先开源模型 | 🥈 优秀,小模型继承能力强 |
| MMLU-Pro | 综合知识理解 | 🥈 优秀 | 🥇 接近 GPT-5 水平 | 🥇 旗舰版媲美万亿参数模型 |
| LongBench / Needle | 长上下文检索 | --- | 🥇 1M 上下文精准检索 | 🥈 256K~1M 稳定表现 |
📌 说明:🥇 表示该维度领先或持平国际顶尖闭源模型;--- 表示官方未公开具体数据或该模型非主打方向
🔹 特色能力横向对比
🤖 Agent / 智能体能力
| 能力维度 | MiniMax M2.7 | DeepSeek-V3.2 | Qwen3.5 系列 |
|---|---|---|---|
| 自我进化 | ✅ 首创"模型参与自身训练",可优化强化学习 Harness | ❌ 不支持 | ⚠️ 通过蒸馏实现小模型能力继承 |
| 多智能体协作 | ✅ 原生支持 Agent Teams,角色边界清晰 | ⚠️ 需外部框架支持 | ✅ 支持多工具调用与任务规划 |
| 工具调用遵循率 | ✅ 40+ 复杂 Skills 保持 97% 遵循率 | ✅ 优秀,支持 Search / Code Agent | ✅ 优秀,内置官方工具链(Flash 版) |
| 研发场景替代率 | ✅ 30%~50% 工作流自动化 | ⚠️ 辅助编码为主 | ✅ 支持代码生成 + 调试 + 重构全流程 |
🧠 推理与专业能力
| 能力维度 | MiniMax M2.7 | DeepSeek-V3.2 | Qwen3.5 系列 |
|---|---|---|---|
| 数学 / 逻辑推理 | 🟡 文字强、推理相对弱 | 🟢 接近 GPT-5 水平 | 🟢 Qwen3-Max-Thinking 19 项基准领先 |
| 代码工程能力 | 🟢 生产级排障、日志分析、安全审计 | 🟢 前端生成美观,HumanEval 领先 | 🟢 Qwen3-Coder 专为 Agent 编程优化 |
| 专业领域知识 | 🟢 GDPval-AA 开源第一,金融 / 办公突出 | 🟢 中文写作与搜索优化 | 🟢 201 语言覆盖,全球化部署友好 |
| 多模态理解 | 🟡 侧重文本 + Agent,多模态非核心 | ❌ 纯文本模型 | 🟢 原生多模态,视觉 - 语言统一理解 |
🚀 效率与成本对比
| 维度 | MiniMax M2.7 | DeepSeek-V3.2 | Qwen3.5 系列 |
|---|---|---|---|
| 推理速度 | 高吞吐设计,支持 100+ TPS | DSA 机制 + 投机采样,60 tokens/s | MoE 动态激活,小模型端侧实时响应 |
| 显存占用 | 高效稀疏激活,生产级优化 | 128K 上下文下消费级显卡可运行 | 原生 FP8 训练,显存占用降低约 50% |
| API 成本 | 1 万美元支持 4 个 Agent 年工作 | V3.2 Exp 版 API 降价 50%+ | Flash 版输入 $0.03 / 1M tokens(≤128K) |
| 开源友好度 | 部分模型开源,主打 API 服务 | ✅ 完全开源 + MIT 协议,可商用蒸馏 | ✅ Apache 2.0 为主,社区生态最活跃 |
🔹 适用场景推荐指南
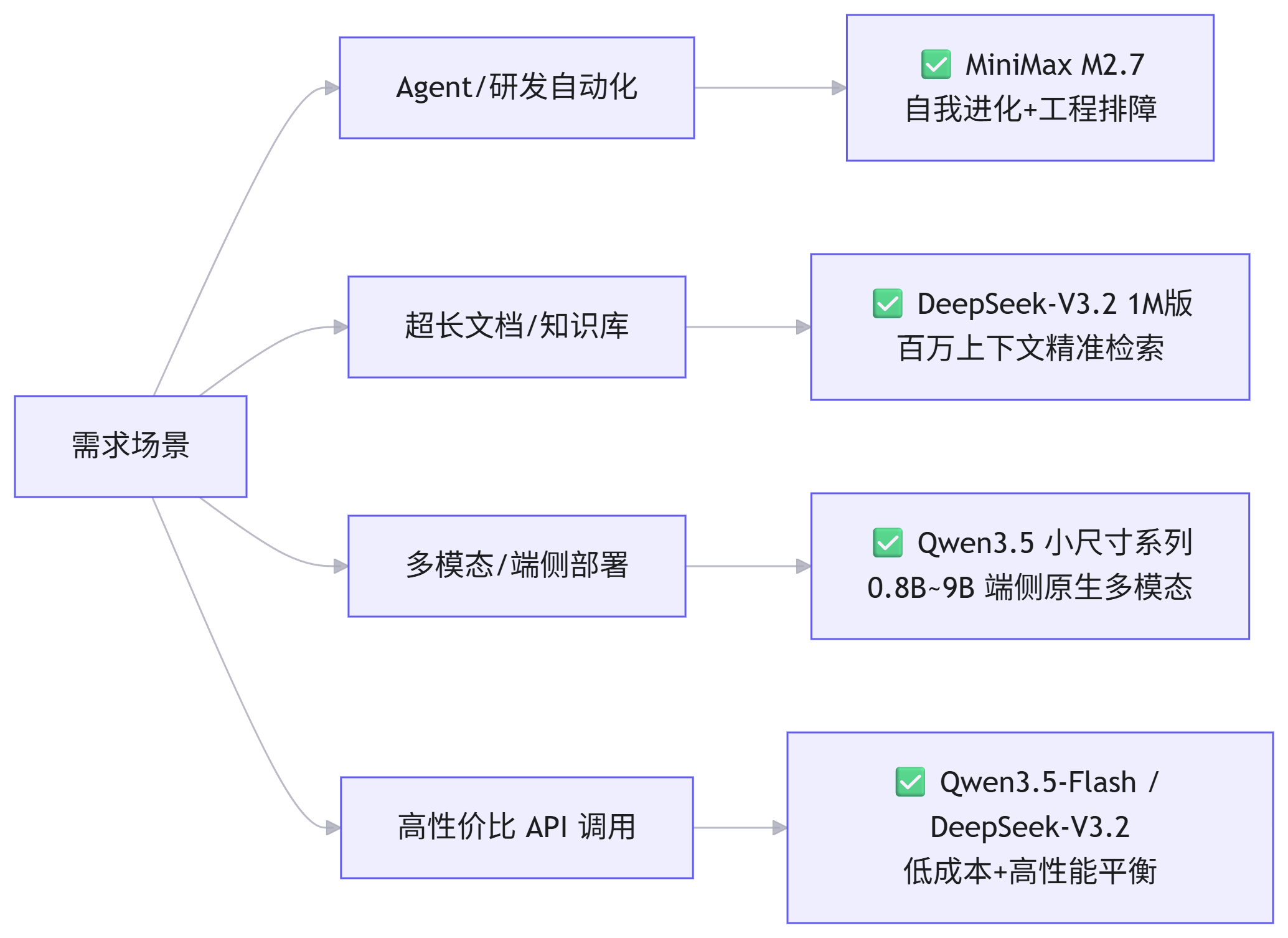 不同模型适用场景
不同模型适用场景
📋 快速选型建议
| 需求 | 首选推荐 | 理由 |
|---|---|---|
| 🔧 自动化研发 / 代码排障 | MiniMax M2.7 | 唯一支持"模型自我进化",生产环境故障恢复 < 3 分钟 |
| 📚 百万字文档 / 跨文档推理 | DeepSeek-V3.2(1M) | 原生 1M 上下文,长文本检索精度行业领先 |
| 📱 移动端 / 边缘设备部署 | Qwen3.5(0.8B~9B) | 小尺寸系列专为端侧优化,支持原生 256K 上下文 |
| 🎨 图文 / 视频多模态创作 | Qwen3.5-Plus / Omni | 全球首个原生多模态 MoE,视觉 - 语言统一理解 |
| 💰 极致性价比 API 调用 | Qwen3.5-Flash | $0.03 / 1M tokens 输入,预装工具链,生产级可用 |
| 🌍 多语言全球化应用 | Qwen3.5 系列 | 201 种语言支持 + 25 万词表,编码效率提升 60% |
| 🔓 完全开源可商用 | DeepSeek-V3.2 | MIT 协议,允许蒸馏训练其他模型,社区支持完善 |
🔹 总结:三大模型核心定位
| 模型 | 核心标签 | 一句话定位 |
|---|---|---|
| MiniMax M2.7 | 🤖 Agent 原生 · 自我进化 | "让模型参与自身迭代,重塑研发工作流" |
| DeepSeek-V3.2 | 📚 超长上下文 · 开源友好 | "百万字一键读懂,开源界的性价比之王" |
| Qwen3.5 系列 | 🌐 全尺寸覆盖 · 原生多模态 | "从手机到云端,一套架构覆盖所有场景" |
💡 选型建议
- 追求极致工程自动化 → 选 MiniMax M2.7
- 需要处理海量文本 / 完全开源 → 选 DeepSeek-V3.2
- 要求多模态 + 多尺寸 + 全球化 → 选 Qwen3.5 系列
- 预算敏感 / 初创团队 → 优先考虑 Qwen3.5-Flash 或 DeepSeek 开源版本
📌 注:以上对比基于官方公开信息及第三方评测整理,实际效果可能因具体任务、提示词工程及部署环境而异。建议结合自身业务场景进行小范围实测后再做最终选型。
结束~