
文章目录
- [一、为什么 SAM 会出现?](#一、为什么 SAM 会出现?)
-
- [1.1 NLP 的"前辈们"已经探好了路](#1.1 NLP 的"前辈们"已经探好了路)
- [1.2 分割任务本身需要一个新范式](#1.2 分割任务本身需要一个新范式)
- [1.3 数据才是真正的护城河](#1.3 数据才是真正的护城河)
- [二、Segment Anything Model 的 Pipeline 是什么](#二、Segment Anything Model 的 Pipeline 是什么)
-
- [2.1 SAM v1 整体 Pipeline](#2.1 SAM v1 整体 Pipeline)
- [2.2 SAM v1 三大核心模块](#2.2 SAM v1 三大核心模块)
-
- [2.2.1 Image Encoder(图像编码器)](#2.2.1 Image Encoder(图像编码器))
- [2.2.2 Prompt Encoder(提示编码器)](#2.2.2 Prompt Encoder(提示编码器))
- [2.2.3 Mask Decoder(掩码解码器)](#2.2.3 Mask Decoder(掩码解码器))
- [三、SAM 的 Interactive Pipeline(最核心)](#三、SAM 的 Interactive Pipeline(最核心))
- [四、SAM 支持哪些交互功能](#四、SAM 支持哪些交互功能)
-
- [4.1 Click Segmentation](#4.1 Click Segmentation)
- [4.2 Multi-click Refinement](#4.2 Multi-click Refinement)
- [4.3 Box-guided Segmentation](#4.3 Box-guided Segmentation)
- [4.4 Everything Mode(分割一切)](#4.4 Everything Mode(分割一切))
- [4.5 Automatic Mask Generation](#4.5 Automatic Mask Generation)
- [4.6 Interactive Annotation](#4.6 Interactive Annotation)
- [五、SAM Pipeline 为什么快](#五、SAM Pipeline 为什么快)
-
- [5.1 重计算在 Encoder](#5.1 重计算在 Encoder)
- [5.2 Decoder 很轻](#5.2 Decoder 很轻)
- [六、Promptable Segmentation:到底"promptable"在什么?](#六、Promptable Segmentation:到底"promptable"在什么?)
-
- [6.1 一句话理解](#6.1 一句话理解)
- [6.2 zero-shot 的哲学](#6.2 zero-shot 的哲学)
- [6.3 歧义感知:为什么一次返回 3 个 mask?](#6.3 歧义感知:为什么一次返回 3 个 mask?)
- 七、三大模块拆解:不是论文翻译,是"它为什么这样设计"
-
- [7.1 Image Encoder:为什么一定要 ViT?](#7.1 Image Encoder:为什么一定要 ViT?)
- [7.2 Prompt Encoder:把"人类意图"翻译成"机器语言"](#7.2 Prompt Encoder:把"人类意图"翻译成"机器语言")
- [7.3 Mask Decoder:SAM 最精妙的部分](#7.3 Mask Decoder:SAM 最精妙的部分)
- [八、为什么 Foundation Model 思路能迁移到 Segmentation?](#八、为什么 Foundation Model 思路能迁移到 Segmentation?)
-
- [8.1 什么是"分割的基础模型"?](#8.1 什么是"分割的基础模型"?)
- [8.2 三个必要条件,SAM 都满足了](#8.2 三个必要条件,SAM 都满足了)
- [8.3 SAM 学到的到底是什么?](#8.3 SAM 学到的到底是什么?)
- 九、工程视角:从论文到生产线
-
- [9.1 推理速度全景图](#9.1 推理速度全景图)
- [9.2 Embedding Cache 的生产级设计](#9.2 Embedding Cache 的生产级设计)
- [9.3 显存问题:模型很大,但可以分而治之](#9.3 显存问题:模型很大,但可以分而治之)
- [9.4 移动端部署:这条路走得通吗?](#9.4 移动端部署:这条路走得通吗?)
- [9.5 TensorRT / ONNX 部署实战](#9.5 TensorRT / ONNX 部署实战)
- [十、SAM 的缺点:6 个真实场景下的翻车记录](#十、SAM 的缺点:6 个真实场景下的翻车记录)
-
- [10.1 密集细长结构 ------ "纹理混乱"](#10.1 密集细长结构 —— "纹理混乱")
- [10.2 低对比度目标 ------ "看不见就是看不见"](#10.2 低对比度目标 —— "看不见就是看不见")
- [10.3 上下文依赖概念 ------ "它真的不懂语境"](#10.3 上下文依赖概念 —— "它真的不懂语境")
- [10.4 对扰动的脆弱性](#10.4 对扰动的脆弱性)
- [10.5 零样本不是万能 ------ 新域失败率高达 72.6%](#10.5 零样本不是万能 —— 新域失败率高达 72.6%)
- [10.6 微调中的灾难性遗忘](#10.6 微调中的灾难性遗忘)
- [10.7 补充](#10.7 补充)
- [十一、SAM vs MobileSAM vs FastSAM:选型指南](#十一、SAM vs MobileSAM vs FastSAM:选型指南)
-
- [11.1 架构差异一览](#11.1 架构差异一览)
- [11.2 MobileSAM:比你想象的精巧](#11.2 MobileSAM:比你想象的精巧)
- [11.3 FastSAM:完全不同的哲学](#11.3 FastSAM:完全不同的哲学)
- [11.4 选型决策框架](#11.4 选型决策框架)
- [十二、SAM v1 Python Demo:从入门到魔改](#十二、SAM v1 Python Demo:从入门到魔改)
-
- [12.1 环境配置](#12.1 环境配置)
- [12.2 最简 Demo:点一下,出 mask](#12.2 最简 Demo:点一下,出 mask)
- [12.3 场景 1:交互式抠图(多点修正)](#12.3 场景 1:交互式抠图(多点修正))
- [12.4 场景 2:全图自动分割 → 生成 instance masks](#12.4 场景 2:全图自动分割 → 生成 instance masks)
- [12.5 场景 3:框选分割 ------ Bounding Box Prompt](#12.5 场景 3:框选分割 —— Bounding Box Prompt)
- [12.6 场景 4:批量处理 ------ Embedding Cache 实战](#12.6 场景 4:批量处理 —— Embedding Cache 实战)
- 十三、总结金句

为什么一个 632M 参数的模型能在 23 个没见过的数据集上零样本超越有监督方法?为什么 Meta 要花重金标 11 亿个掩码?这篇文章试图用工程师的语言回答这些问题。
一、为什么 SAM 会出现?
1.1 NLP 的"前辈们"已经探好了路
2023 年春天,如果你是一个 CV 研究员,你会陷入一种复杂的情绪。
一边是 NLPer 的狂欢 ------ GPT-4 刚发布两个月,few-shot 推理碾压一切榜单,CLIP 已经把视觉和语言打通。另一边是做检测、分割的工程师们,还在为每个新数据集重复写 pipeline:标数据 → 训模型 → 调参 → 上线 → 下一个数据集继续循环。
NLP 的剧本已经写好了:1 个大模型 + prompt,干翻所有下游 fine-tune。那 CV 呢?能不能有一个模型,你给什么它就分割什么?
这不是个技术问题,这是个对世界的表示方式的问题。
1.2 分割任务本身需要一个新范式
回顾 SAM 出现前的分割格局:
| 任务 | 典型方法 | 本质限制 |
|---|---|---|
| 语义分割 | DeepLab / SegFormer | 闭集,只能分固定类别 |
| 实例分割 | Mask R-CNN / YOLACT | 闭集,依赖检测框 |
| 交互式分割 | RITM / f-BRS | 不"理解"图像,只是像素分类 |
每一个任务都是一个孤岛。SAM 的野心是:用 prompt 的抽象,统一所有分割任务。
1.3 数据才是真正的护城河
但如果你 2022 年就在 FAIR 工作,你知道比模型更稀缺的是什么 ------ 数据。互联网上有几十亿张图片,但每张图片上"所有物体"的精确掩码标注几乎不存在。
所以 SAM 的故事里,有两条并行的主线:模型 (SAM)+ 数据引擎(SA-1B)。两者滚动迭代,互相放大。
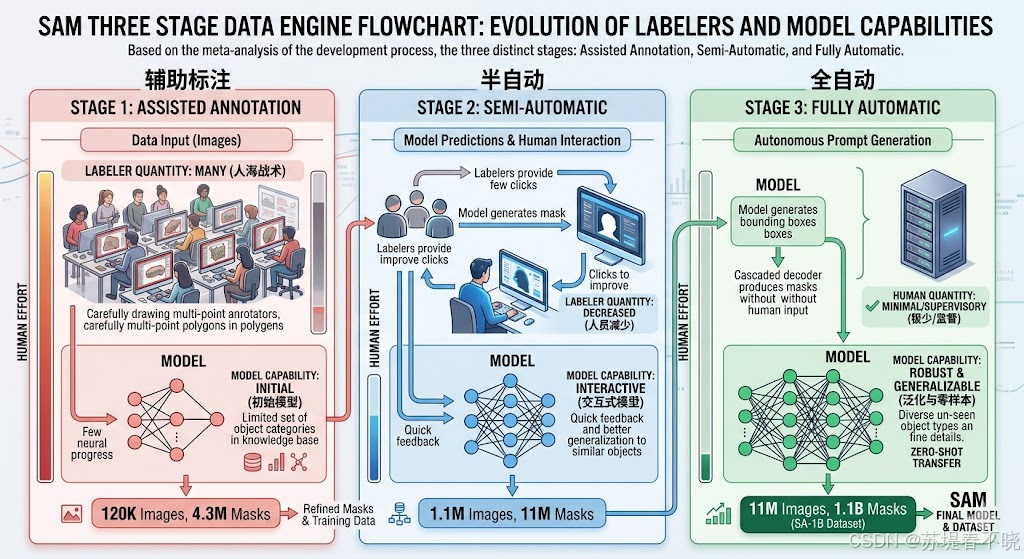
SAM 三大阶段数据引擎流程图------辅助标注→半自动→全自动,每轮参与的标注员数量变化、模型能力变化。
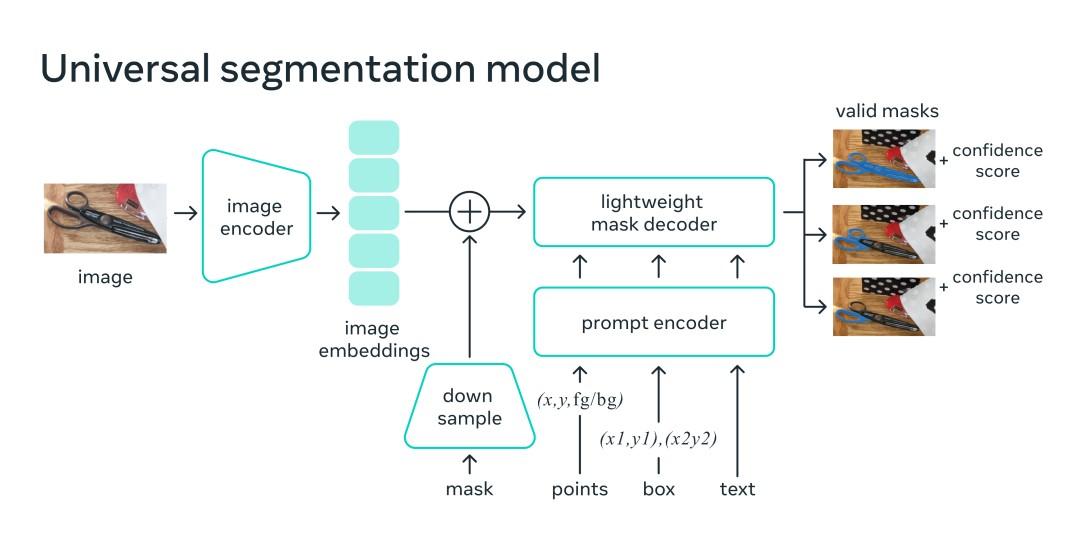
二、Segment Anything Model 的 Pipeline 是什么
SAM v1(Segment Anything Model)本质上是一个:
"可交互(interactive)的 Promptable Segmentation 系统"
它不是传统:
text
输入图像 → 输出固定类别mask而是:
text
输入图像 + 用户提示(prompt)
→ 输出对应目标mask核心思想:
"你告诉我想分割哪里,我负责给你 mask。"
2.1 SAM v1 整体 Pipeline
SAM v1 整体可以理解成:
text
┌────────────────┐
│ Input Image │
└────────┬───────┘
│
▼
┌────────────────────┐
│ Image Encoder │
│ (ViT) │
└────────┬───────────┘
│
Image Embedding
│
┌──────────────┴──────────────┐
│ │
▼ ▼
┌────────────────┐ ┌─────────────────┐
│ Prompt Encoder │ │ Mask Decoder │
│ point/box/mask │ ─────► │ cross-attention │
└────────────────┘ └────────┬────────┘
│
▼
Segmentation Mask可以把 SAM 想成:
text
一个"视觉版 GPT"
Image Encoder:
负责理解世界
Prompt Encoder:
负责理解用户意图
Mask Decoder:
负责把意图映射到像素区域这也是为什么:
SAM 被认为是 segmentation foundation model 的起点。
实际工程经常这样:
text
Image
↓
Image Encoder (offline/cache)
↓
Embedding Cache
↓
User Prompt
↓
Lightweight Decoder
↓
Mask2.2 SAM v1 三大核心模块
2.2.1 Image Encoder(图像编码器)
SAM v1 使用:
- ViT-B
- ViT-L
- ViT-H
本质:
text
Image → Dense Feature Embedding作用:
把整张图编码成"通用视觉特征"。
类似:
text
GPT 把文本编码成 token embedding这里:
text
SAM 把图像编码成 image embedding特点
① 只计算一次
这是 SAM 非常关键的优化。
text
图片不变
→ embedding 不变所以:
- 用户不断点击
- 不需要重新跑 ViT
只需要:重新跑 decoder
这就是:
SAM 交互速度快的核心。
② embedding cache
工程里:
text
先缓存 image embedding之后:
text
point prompt
bbox prompt
mask prompt都复用 embedding。
这也是移动端部署重点。
2.2.2 Prompt Encoder(提示编码器)
这是 SAM 最革命的地方。
SAM 不再:
text
固定类别而是:
text
Prompt-guided segmentationSAM 支持哪些 Prompt
① Point Prompt(点击)
用户:
text
点一下目标例如:
- 点猫
- 点人
- 点桌子
SAM:
text
输出对应mask② Positive / Negative Point
SAM 支持:
| 类型 | 含义 |
|---|---|
| Positive Point | "这是目标" |
| Negative Point | "这不是目标" |
例如:
text
点人(正样本)
点背景(负样本)mask 会不断修正。
这就是:
交互式分割。
③ Box Prompt(框提示)
输入:
text
bboxSAM:
text
在框里做精细分割非常像:
- 检测 + 分割
工程里极其常见。
④ Mask Prompt
输入:
text
已有maskSAM:
text
继续 refinement用于:
- 多轮编辑
- 视频时序
- 交互修正
2.2.3 Mask Decoder(掩码解码器)
核心:
text
Image Embedding
+
Prompt Embedding
→ Mask这里用了:
- Transformer Decoder
- Cross Attention
本质:
"根据 prompt,从 image embedding 中找到对应区域。"
类似:
text
文本 prompt
→ LLM 找相关 tokenSAM:
text
point prompt
→ decoder 找对应像素区域三、SAM 的 Interactive Pipeline(最核心)
SAM 真正厉害的是:
Human-in-the-loop
也就是:
text
人不断点击
→ 模型实时修正mask流程:
text
用户点击
↓
Prompt Encoder
↓
Mask Decoder
↓
生成mask
↓
用户不满意继续点击
↓
再次更新mask四、SAM 支持哪些交互功能
4.1 Click Segmentation
最经典。
text
点哪里
分哪里4.2 Multi-click Refinement
连续点击修正。
text
正点
负点逐步逼近真实边界。
4.3 Box-guided Segmentation
检测框引导分割。
常见于:
- 自动标注
- instance segmentation
4.4 Everything Mode(分割一切)
这是 SAM demo 最震撼的功能。
SAM 会:
text
自动生成大量mask proposal输出:
text
整张图所有可分割区域类似:
text
class-agnostic segmentation4.5 Automatic Mask Generation
自动扫描:
text
grid points然后:
text
生成所有mask工程里常用于:
- 自动标注
- 数据集生成
4.6 Interactive Annotation
这是工业界最重要应用。
人工:
text
点一下SAM:
text
自动出mask标注效率暴涨。
五、SAM Pipeline 为什么快
关键:
5.1 重计算在 Encoder
ViT 最重。
但:
text
只算一次5.2 Decoder 很轻
交互时:
text
只更新 decoder因此:
- 可以实时点击
- 可以连续交互
六、Promptable Segmentation:到底"promptable"在什么?
6.1 一句话理解
Promptable segmentation = 把分割变成一个"填空"任务,而不是一个"归类"任务。
传统语义分割的流程是:输入图像 → 模型 → 80 个类别的 mask 概率图。你只能得到模型见过的类别。
SAM 的流程是:输入图像 + "我想要这块" → 模型 → mask。
6.2 zero-shot 的哲学
这里有一个思维实验:
你给一个从未见过斑马的人看一张斑马照片,说"把左边这只指出来"。他能做到 ------ 哪怕他没见过斑马。为什么?因为 分割的本质是分组(grouping),不是分类(classification)。
SAM 抓住了这个本质:把分割从"这个东西是什么"解耦为"这个东西在哪"。
6.3 歧义感知:为什么一次返回 3 个 mask?
这是 SAM 最精巧的设计之一。考虑一个场景:你在一张人像上点了一下他的衣服。
- mask 1:衣服(最细粒度)
- mask 2:上衣(整体)
- mask 3:整个人(最大粒度)
三个答案都对,只是歧义的层级不同。SAM 输出 3 个 mask 并按 IoU 排序,把"选择权"交还给用户。

三格图------同一个点击分别在衣服/上衣/整个人三个粒度上的 mask 输出,标注不同的 IoU 分数。
七、三大模块拆解:不是论文翻译,是"它为什么这样设计"
7.1 Image Encoder:为什么一定要 ViT?
核心作用 :将整张图像映射为一个稠密的特征图(256 × 64 × 64),每张图像只跑一次。
设计上遵循两个关键原则:
原则 1:图像的表示应该是"一次性"的。
传统交互式分割(如 RITM)每次用户点击都要重新跑特征提取。SAM 的思路是:先一次性编码整张图的"语义字典",后续 prompt 只需在字典里查表,不需要重算。
类比一下就是:你有一本字典(image embedding),然后每次输入 prompt 就是在字典里翻到对应页,而不是每次重新编一本字典。
原则 2:用 ViT 而不是 CNN。
原因很直白 ------ ViT 的全局自注意力机制天然适合"理解整张图"。CNN 的卷积核感受野有限,即使深了也很难建立远距离关联。而 SAM 要做的是 对任何物体的泛化分割,这里面可能有头发丝那么细的物体,也可能有天空那么大的背景。
一个技术细节:SAM 用的是 MAE 预训练的 ViT-H(Masked Autoencoder)。MAE 预训练让 ViT 学会"从局部推断整体"的能力,这种能力天然适合分割 ------ 分割就是看局部像素推断整体 mask。
三个变体的工程权衡:
| 模型 | 参数 | Encoder 特征维 | 单张图编码时间 | 适用场景 |
|---|---|---|---|---|
| ViT-B | 86M | 768 → 256 | ~0.15s (A100) | 需要速度优先 |
| ViT-L | 307M | 1024 → 256 | ~0.38s (A100) | 精度和速度平衡 |
| ViT-H | 632M | 1280 → 256 | ~0.73s (A100) | 追求极致精度 |
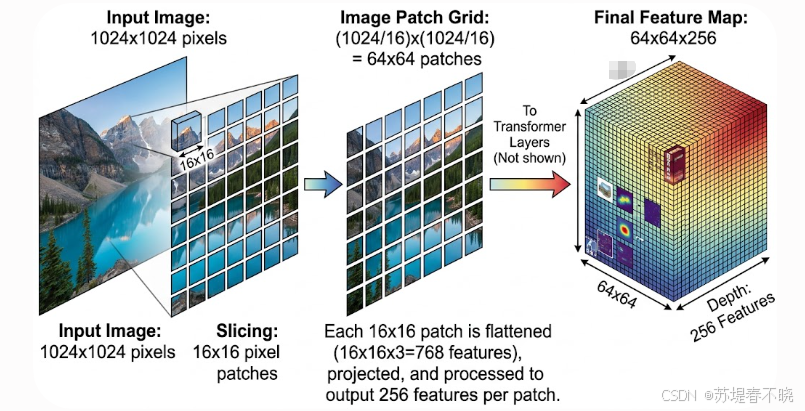
ViT 把图像切成 16×16 patch 的示意图,最终输出 64×64×256 的 feature map。
7.2 Prompt Encoder:把"人类意图"翻译成"机器语言"
Prompt Encoder 是 SAM 的"翻译官"。它把各种形式的 prompt 统一编码为固定维度的向量,喂给 Mask Decoder。
稀疏 prompt(稀疏 = 少数几个位置信息):
- 点 :
(x, y)坐标 + 前景/背景标记 → 位置编码 → 256 维向量。每个点就是一个 256 维向量,N 个点就是 N × 256。 - 框:左上角 + 右下角 → 两个点的位置编码 → 2 × 256。
- 文本:用 CLIP text encoder 编码。但原版 SAM 实际没有发布文本功能,训练时也没有暴露给文本 encoder。
稠密 prompt:
- mask :输入一个粗 mask → 卷积下采样 4 倍 → 与 image embedding 逐元素相加。
为什么是"相加"而不是"拼接"?因为 mask 本质上是在修正 image embedding ------ 告诉它"注意这里、忽略那里",而不是提供全新信息。
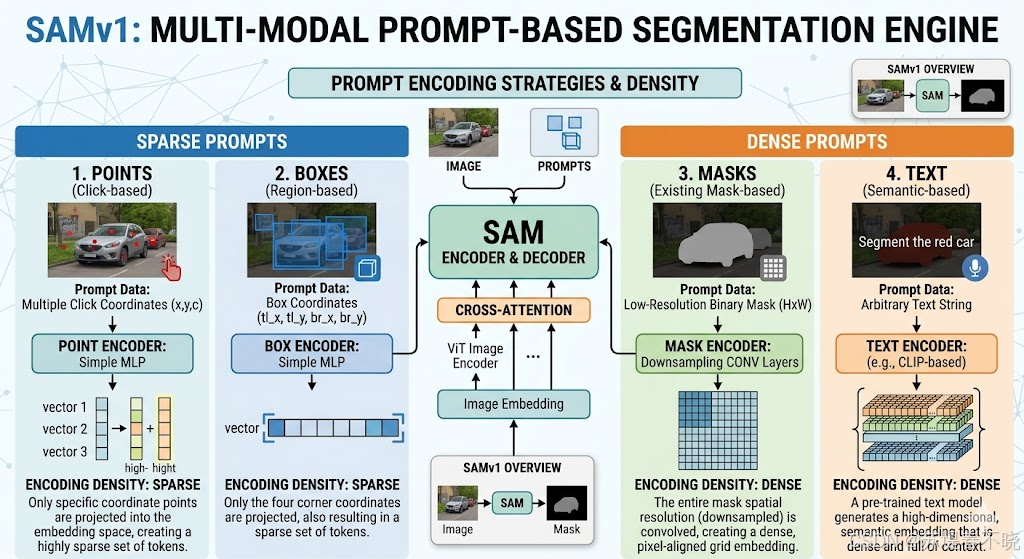
四种 prompt 类型(点/框/mask/文本)的编码示意图,突出每种编码方式是"稀疏"还是"稠密"。
7.3 Mask Decoder:SAM 最精妙的部分
如果 Image Encoder 是"眼睛",Prompt Encoder 是"耳朵",那 Mask Decoder 就是"大脑"。
它的任务:把 image embedding(全局特征)和 prompt embeddings(局部意图)融合,输出精确的 mask。
为什么只要 2 层 Transformer?
这是反直觉的设计 ------ SAM 的 encoder 用了 32 层 ViT,decoder 却只有 2 层。
原因在于:decoder 不需要重新理解图像,它只是在查表。Image Encoder 已经把图像压缩成 64×64 的"语义码本",decoder 只需快速扫描 + 匹配。这也是为什么 decoder 可以在 CPU 上 ~50ms 就跑完。
双层交叉注意力的真正含义:
Layer × 2:
1. Self-Attention (token 之间) → 理解多个 prompt 之间的关系
2. Cross-Attn: Token → Image → "prompt 去图像里找对应特征"
3. MLP + 残差 → 非线性变换
4. Cross-Attn: Image → Token → "图像特征被 prompt 信息增强"第 2 步和第 4 步是双向的 :不仅让 prompt 看到图像(先),还让图像"吸收"prompt 的信息(后)。这个双向设计是关键 ------ 它不是单向查询,而是对话。
输出头的妙用:
- 4 个可学习的 output tokens:3 个 mask token + 1 个 IoU token
- 3 个 mask token 分别生成了 3 个不同粒度的 mask(歧义感知的核心机制)
- IoU token 预测每个 mask 的质量分数
解码后,mask token 与 image embedding 做点积得到最终 mask。这意味着 mask 的本质是"token 与每个像素的相似度"。
八、为什么 Foundation Model 思路能迁移到 Segmentation?
8.1 什么是"分割的基础模型"?
NLP 的 GPT 之所以是 foundation model,因为它学到了一个通用的能力:给定前缀,预测下一个词。这个能力足够原子化,又足够通用,任何 NLP 任务都能被转化为这个形式。
SAM 的对应是:给定一张图 + 一个提示,预测对应的 mask。
8.2 三个必要条件,SAM 都满足了
| 条件 | NLP (GPT) | Vision (SAM) |
|---|---|---|
| 统一的接口 | prompt → text | prompt → mask |
| 海量数据 | WebText / CommonCrawl | SA-1B (11 亿 mask) |
| 足够大的模型容量 | 175B params | 632M params |
SA-1B 是第一个"分割版本的 CommonCrawl"------11M 张图片、1.1B 个 mask,是之前任何分割数据集的 400 倍。
8.3 SAM 学到的到底是什么?
这是一个哲学问题。SAM 学到的不是"猫的 mask 长什么样",而是一种通用的分组感知能力:
- 颜色一致性 → 这个区域应该连在一起
- 纹理连续性 → 边缘在哪
- 深度/遮挡 → 这里物体重叠了
- 语义理解 → 这块是一个独立实体
这种"分组感知"就像婴儿学会的"物体恒存"概念 ------ 不需要知道物体名字,就知道它在哪、多大。
九、工程视角:从论文到生产线
9.1 推理速度全景图
SAM 的推理分为两个阶段,差异巨大:
| 阶段 | 耗时 (A100, bs=1) | 耗时 (CPU) | 是否可复用 |
|---|---|---|---|
| Image Encoder (ViT-H) | ~730ms | ~10-20s | ✅ 每图一次 |
| Prompt Encoder + Mask Decoder | ~5ms | ~50ms | ❌ 每次 prompt |
这意味着:如果你要对同一张图做多次分割,只需编码一次。
一个实际的交互式标注工作流:
- 加载图片 → 编码(730ms)← 一次性开销
- 用户点第一下 → 解码(5ms)
- 用户点第二下 → 解码(5ms)
- ......
9.2 Embedding Cache 的生产级设计
这是 SAM 应用中最重要也最容易被忽略的工程优化。
核心思想 :Image Encoder 的输出(256 × 64 × 64)只依赖图片不依赖 prompt,所以可以提前算好存起来。
一个参考的设计模式:
python
# 伪代码:embedding cache 模式
class SAMInferenceService:
def __init__(self):
self.image_encoder = load_sam_encoder("sam_vit_h.pth") # GPU
self.mask_decoder = load_sam_decoder("sam_vit_h.pth") # CPU/GPU
self.embedding_cache = LRUCache(max_size=100) # 缓存最近100张图
def segment(self, image_id: str, image: Image, prompt: Prompt) -> List[Mask]:
# Step 1: 查缓存
if image_id in self.embedding_cache:
image_embedding = self.embedding_cache[image_id]
else:
# Step 2: 缓存未命中,编码
image_embedding = self.image_encoder(image) # GPU
self.embedding_cache[image_id] = image_embedding
# Step 3: 轻量解码(可以移到 CPU 甚至浏览器)
masks, scores = self.mask_decoder(image_embedding, prompt)
return masks典型场景的收益:
| 场景 | 无缓存延迟 | 有缓存延迟 | 加速比 |
|---|---|---|---|
| 网页图片标注(100 次 prompt/图) | 100 × 735ms ≈ 73s | 730ms + 100 × 5ms ≈ 1.2s | 60× |
| 视频秒级分割(30fps × 1s) | 30 × 735ms ≈ 22s | 735ms + 30 × 5ms ≈ 0.9s | 24× |
存储成本:单张图的 embedding 大小 = 256 × 64 × 64 × 4 字节(float32)≈ 4MB。1000 张图缓存仅需 ~4GB。
9.3 显存问题:模型很大,但可以分而治之
| 组件 | 参数量 | FP32 显存 | FP16 显存 |
|---|---|---|---|
| ViT-H Encoder | 632M | ~2.5 GB | ~1.3 GB |
| Mask Decoder | 4M | ~16 MB | ~8 MB |
| 总计 | 636M | ~2.5 GB | ~1.3 GB |
但关键在于:encoder 和 decoder 可以异构部署。
- Encoder 放在 GPU(只跑一次)
- Decoder 放在 CPU(每次 prompt)
如果整条 pipeline 都在 CPU 上跑(纯 CPU 推理),单次分割耗时 ~10-20s ------ 对交互式应用来说太慢,但批量离线处理图片是完全可行的。
9.4 移动端部署:这条路走得通吗?
原版 SAM 无法直接部署到移动端。ViT-H 的 632M 参数对手机来说完全不可行。
但这催生了一系列轻量级工作:
| 模型 | 参数 | 速度 | 部署方式 |
|---|---|---|---|
| SAM (ViT-H) | 636M | 730ms (A100) | 服务器 GPU |
| SAM (ViT-B) | 90M | 150ms (A100) | 服务器 GPU |
| MobileSAM | ~10M | ~10ms (GPU) | ✅ 移动端 |
| FastSAM | 68M | 40ms (GPU) | ✅ 移动端 |
| SAM-Lightening | ~6M | 7ms (A100) | ✅ 边缘设备 |
9.5 TensorRT / ONNX 部署实战
ONNX 导出的可行性:
- Image Encoder 和 Mask Decoder 需要分开导出,因为它们是独立运行的
- ViT encoder 可以导出为静态 shape ONNX(1024×1024),推理时 resize
- Decoder 的 prompt tokens 数量是动态的,需要处理 dynamic axis
TensorRT 优化效果(参考 SAM 家族模型的经验):
| 优化手段 | 加速比 | 显存节省 |
|---|---|---|
| ONNX 导出 | 1.1× | ~10% |
| TensorRT FP16 | 2.5× | ~65% |
| TensorRT INT8 | 3.0× | ~75% |
一个参考的部署链路:
- PyTorch → ONNX(torch.onnx.export)
- ONNX → TensorRT Engine(trtexec 或 Python API)
- 服务端:Triton Inference Server 加载 TensorRT engine
- 前端:发送图片 → 服务端编码 → 返回 embedding → 浏览器端解码
注意 :ViT 的注意力层在 TensorRT 中可能遇到算子不支持问题。常见做法是使用 torch2trt 或手写 plugin。
十、SAM 的缺点:6 个真实场景下的翻车记录
10.1 密集细长结构 ------ "纹理混乱"
树木枝干、血管、裂缝、头发丝 ------ SAM 在此类任务上表现糟糕。2024 年 WACV 一篇论文将其命名为 "纹理混淆(textural confusion)" :SAM 把局部分叉模式误解为全局纹理。更关键的是,针对性微调也无法解决,说明这是架构层面的根本局限。
10.2 低对比度目标 ------ "看不见就是看不见"
在医学影像(CT、MRI)、红外监控等场景,SAM 对低对比度边界的判断能力大幅下降。一个 X 光片里的塑料瓶,对人眼来说很明显,对 SAM 来说几乎透明。
教训:SAM 学的是自然图像中的分组模式,跨域到医学/工业场景时,这种 pattern 不存在。
10.3 上下文依赖概念 ------ "它真的不懂语境"
2024 年一项全面评测发现,SAM 对以下概念几乎无能为力:
- 伪装物体(需要理解"这里应该藏了东西")
- 产品缺陷(正常和异常只有细微差别)
- 视觉显著性(人一眼看到的地方,SAM 不一定觉得重要)
这些都是需要判别能力的任务 ,而 SAM 本质上是个生成式分组模型,它不擅长"判断是不是"。
10.4 对扰动的脆弱性
噪声、模糊、JPEG 压缩 ------ 真实世界的图片不如实验室干净。2024 年 Pattern Recognition 期刊的研究显示 SAM 对常见图像降质敏感度差异很大,某些扰动下 mIoU 下降超过 20%。
10.5 零样本不是万能 ------ 新域失败率高达 72.6%
在全新领域(如特定工业场景),SAM 的 FR₃₀@90(达到 90% IoU 的失败率)高达 72.6%。这提醒我们:SAM 的"分割一切"是建立在自然图像分布上的"一切",不是真正的宇宙万物。
10.6 微调中的灾难性遗忘
NeurIPS 2024 的一篇论文发现:对 SAM 做轻量微调后,模型在目标任务上变好了,但在其他任务上显著退化。这个现象在 NLP 领域早被讨论,但在 SAM 上表现得特别明显 ------ 因为它破坏了模型的"通用分组"能力。
10.7 补充
(1)Encoder 太大
ViT-H:
- 非常吃显存
- 移动端困难
(2)实时视频弱
因为:
text
没有时序建模所以:
- 视频会闪烁
- mask 不稳定
这也是后面 SAM 2 的方向。
十一、SAM vs MobileSAM vs FastSAM:选型指南
11.1 架构差异一览
| 维度 | SAM | MobileSAM | FastSAM |
|---|---|---|---|
| 作者 | Meta FAIR | 韩国KAIST | 中科院自动化所 |
| 发布时间 | 2023.04 | 2023.06 | 2023.06 |
| 视觉编码器 | ViT-H (Transformer) | 蒸馏版 ViT-Tiny | CNN (YOLOv8) |
| 参数总量 | 636M | ~10M | 68M |
| Encoder 速度 | 730ms (A100) | ~8ms (A100) | ~38ms (A100) |
| Mask Decoder | 2层 Transformer | 2层 Transformer(同SAM) | 无(两阶段) |
| 速度 | ~50ms/prompt | ~5ms/prompt | 恒定~40ms(不含prompt阶段) |
| 训练策略 | 从头训 + MAE | 知识蒸馏 | YOLOv8 + 2% SA-1B |
11.2 MobileSAM:比你想象的精巧
MobileSAM 的核心方法是解耦蒸馏(decoupled distillation):
- 先单独蒸馏 Image Encoder(ViT-Tiny ← ViT-H),使用特征层面的 MSE loss
- 然后直接复用 SAM 原版的 Mask Decoder(注意:decoder 是完全一样的)
这意味着:MobileSAM 不是"重新训练一个轻量 SAM",而是"只蒸馏 encoder + 复用 decoder"。decoder 只有 4M 参数,对整体精度影响极小,却保留了 SAM 完整的交互式分割能力。
为什么 decoder 不用蒸馏? 因为 decoder 只有 2 层 Transformer 加几个 MLP,总共 4M 参数,推理只要 5ms。不值得花时间优化。
11.3 FastSAM:完全不同的哲学
FastSAM 不是一个 "SAM 的加速版",它是一个完全不同的架构。它的设计思路是:
用 YOLOv8 做类别无关的实例分割 → 用后处理匹配 prompt
FastSAM 的关键洞察:
- 先分割图中所有"东西"(类别无关的实例 mask)
- 然后根据 prompt 筛选出想要的 mask
这是两阶段方法的复兴:先提出候选 → 再匹配。
优势:
- 速度不随点数量增加(因为"所有实例分割"是一次性完成的)
- 完全 CNN 架构,成熟度极高,部署简单
- 可以同时做目标检测(底层就是 YOLOv8)
劣势:
- 本质上没有"promptable"的灵活性 ------ 只能从"已有的实例"里选,不能精确到任意形状
- 小物体边界容易出现伪影
- 在复杂场景下,实例分割可能漏掉某些物体
11.4 选型决策框架
你的场景是什么?
├── 追求极致精度,不计成本
│ └── SAM (ViT-H) + Embedding Cache
│
├── 交互式应用(用户频繁点),需要快速响应
│ └── SAM (ViT-H) + Cache(编码一次,解码快速)
│
├── 移动端 / 边缘设备
│ ├── 需要 SAM 风格的灵活交互 → MobileSAM
│ └── 只需要"选出所有物体" → FastSAM
│
├── 视频实时处理
│ └── FastSAM(CNN 架构更适合流式)
│
└── 批量离线处理(标注平台)
├── GPU 服务器 → SAM (ViT-H) + 多卡并行编码
└── CPU 集群 → SAM (ViT-B) + ONNX Runtime十二、SAM v1 Python Demo:从入门到魔改
12.1 环境配置
bash
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv-python pycocotools matplotlib onnx onnxruntime下载模型权重:
bash
# ViT-H(最大最准)
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
# ViT-B(轻量快速)
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
# ViT-L(均衡选择)
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_l_0b3195.pth12.2 最简 Demo:点一下,出 mask
python
import cv2
import numpy as np
import matplotlib
matplotlib.use('Agg') # 无 GUI 后端,仅用于保存图片
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
# 1. 加载模型
sam = sam_model_registry["vit_h"](checkpoint="./sam_vit_h_4b8939.pth")
sam.to("cuda")
predictor = SamPredictor(sam)
# 2. 加载并编码图像
image = cv2.imread("./demo.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image) # ← Image Encoder 只在这里跑一次
# 3. 点一下 ------ 传入 image embedding + prompt
input_point = np.array([[280, 350]]) # (x, y) 坐标
input_label = np.array([1]) # 1=前景, 0=背景
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True, # 返回 3 个候选 mask
)
# 4. 可视化 ------ 取最高分的 mask
best_idx = np.argmax(scores)
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.imshow(masks[best_idx], alpha=0.5, cmap='jet')
plt.scatter(input_point[:, 0], input_point[:, 1], c='red', s=100)
plt.title(f"Mask Score: {scores[best_idx]:.3f}")
plt.axis('off')
plt.savefig("./demo_result.png", dpi=150, bbox_inches='tight')
# plt.show()
print("Result saved to ./demo_result.png")原图

demo1

分割个包包

12.3 场景 1:交互式抠图(多点修正)
python
import cv2
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
# 1. 加载模型
sam = sam_model_registry["vit_h"](checkpoint="./sam_vit_h_4b8939.pth")
sam.to("cuda")
predictor = SamPredictor(sam)
def interactive_matting(image_path, output_path):
"""多点交互式抠图:前景点 + 背景点精修"""
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
# 初始点击:目标物体的中心
masks, scores, logits = predictor.predict(
point_coords=np.array([[280, 350]]),
point_labels=np.array([1]), # 前景
multimask_output=True,
)
best_mask = masks[np.argmax(scores)]
# 不满意?加一个背景点修正
masks, scores, _ = predictor.predict(
point_coords=np.array([[280, 350], [460, 165]]), # 两个点
point_labels=np.array([1, 0]), # 前景 + 背景
mask_input=logits[np.argmax(scores):np.argmax(scores) + 1, :, :],
multimask_output=False,
)
best_mask = masks[0]
# 抠图:原图 × mask
result = image.copy()
result[~best_mask] = 0 # 背景变黑
cv2.imwrite(output_path, cv2.cvtColor(result, cv2.COLOR_RGB2BGR))
# 点的坐标和标签
points = np.array([[280, 350], [460, 165]])
labels = np.array([1, 0]) # 1=前景, 0=背景
fg_points = points[labels == 1]
bg_points = points[labels == 0]
# 可视化并保存
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
axes[0].imshow(image)
if len(fg_points) > 0:
axes[0].scatter(fg_points[:, 0], fg_points[:, 1], c='lime', s=80, edgecolors='k', label='Foreground')
if len(bg_points) > 0:
axes[0].scatter(bg_points[:, 0], bg_points[:, 1], c='red', s=80, edgecolors='k', label='Background')
axes[0].set_title("Original")
axes[0].axis('off')
axes[0].legend()
axes[1].imshow(best_mask, cmap='gray')
axes[1].set_title("Mask")
axes[1].axis('off')
axes[2].imshow(result)
if len(fg_points) > 0:
axes[2].scatter(fg_points[:, 0], fg_points[:, 1], c='lime', s=80, edgecolors='k', label='Foreground')
if len(bg_points) > 0:
axes[2].scatter(bg_points[:, 0], bg_points[:, 1], c='red', s=80, edgecolors='k', label='Background')
axes[2].set_title("Result (Background Removed)")
axes[2].axis('off')
axes[2].legend()
viz_path = output_path.rsplit('.', 1)[0] + '_viz.png'
plt.savefig(viz_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"Mask result saved to {output_path}")
print(f"Visualization saved to {viz_path}")
return result
# 2. 执行抠图
interactive_matting("./demo.png", "./demo_matting_result.png")
12.4 场景 2:全图自动分割 → 生成 instance masks
python
import cv2
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
# 1. 加载模型
sam = sam_model_registry["vit_h"](checkpoint="./sam_vit_h_4b8939.pth")
sam.to("cuda")
def auto_segment_all(image_path, output_path="./demo_auto_result.png"):
"""无 prompt 全自动分割 ------ 生成图中所有可能的 mask"""
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask_generator = SamAutomaticMaskGenerator(
model=sam,
points_per_side=32, # 在 32×32 网格上采样点
pred_iou_thresh=0.88, # 过滤低质量 mask
stability_score_thresh=0.95, # 稳定性阈值
min_mask_region_area=100, # 最小 mask 面积
)
masks = mask_generator.generate(image)
print(f"Found {len(masks)} regions")
# 可视化:随机颜色覆盖所有 mask
fig, axes = plt.subplots(1, 2, figsize=(20, 10))
axes[0].imshow(image)
axes[0].set_title("Original")
axes[0].axis('off')
axes[1].imshow(image)
sorted_masks = sorted(masks, key=lambda x: x['area'], reverse=True)
canvas = np.zeros((*image.shape[:2], 4))
for mask_data in sorted_masks:
color = np.random.random(3)
canvas[mask_data['segmentation']] = np.append(color, 0.4)
axes[1].imshow(canvas)
axes[1].set_title(f"Auto Segmentation ({len(masks)} regions)")
axes[1].axis('off')
plt.savefig(output_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"Result saved to {output_path}")
return masks
# 2. 执行全自动分割
auto_segment_all("./demo.png", "./demo_auto_result.png")
12.5 场景 3:框选分割 ------ Bounding Box Prompt
python
import cv2
import numpy as np
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
# 1. 加载模型
sam = sam_model_registry["vit_h"](checkpoint="./sam_vit_h_4b8939.pth")
sam.to("cuda")
predictor = SamPredictor(sam)
def segment_by_box(image_path, box_xyxy, output_path="./demo_box_result.png"):
"""用框来分割 ------ 自动找到框内最显著的目标"""
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor.set_image(image)
# box_xyxy: [x1, y1, x2, y2]
input_box = np.array(box_xyxy) # e.g. [100, 200, 500, 600]
masks, scores, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
# 可视化
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.imshow(masks[0], alpha=0.5, cmap='jet')
rect = plt.Rectangle(
(box_xyxy[0], box_xyxy[1]),
box_xyxy[2] - box_xyxy[0],
box_xyxy[3] - box_xyxy[1],
fill=False, edgecolor='red', linewidth=2
)
plt.gca().add_patch(rect)
plt.title(f"Box Prompt | Score: {scores[0]:.3f}")
plt.axis('off')
plt.savefig(output_path, dpi=150, bbox_inches='tight')
plt.close()
print(f"Result saved to {output_path}")
return masks[0]
# 2. 执行框分割
segment_by_box("./demo.png", [190, 210, 375, 415], "./demo_box_result.png")
12.6 场景 4:批量处理 ------ Embedding Cache 实战
python
import time
import cv2
import numpy as np
import hashlib
import pickle
from pathlib import Path
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
class CachedSamPredictor:
"""带 embedding 缓存的 SAM predictor"""
def __init__(self, sam_model, cache_dir="./sam_cache"):
self.predictor = SamPredictor(sam_model)
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
def _image_hash(self, image: np.ndarray) -> str:
"""用图像哈希作为缓存 key"""
return hashlib.md5(image.tobytes()).hexdigest()
def _cache_path(self, image_hash: str) -> Path:
return self.cache_dir / f"{image_hash}.pkl"
def set_image(self, image: np.ndarray):
img_hash = self._image_hash(image)
cache_path = self._cache_path(img_hash)
if cache_path.exists():
t0 = time.perf_counter()
with open(cache_path, 'rb') as f:
cached = pickle.load(f)
self.predictor.features = cached['features']
self.predictor.original_size = cached['original_size']
self.predictor.input_size = cached['input_size']
self.predictor.is_image_set = True
elapsed = (time.perf_counter() - t0) * 1000
file_size = cache_path.stat().st_size / 1024 / 1024
print(f"[Cache HIT] hash={img_hash[:12]}... load={elapsed:.1f}ms file={file_size:.1f}MB ✓")
return
print(f"[Cache MISS] hash={img_hash[:12]}... encoding...")
t0 = time.perf_counter()
self.predictor.set_image(image)
elapsed = (time.perf_counter() - t0) * 1000
with open(cache_path, 'wb') as f:
pickle.dump({
'features': self.predictor.features,
'original_size': self.predictor.original_size,
'input_size': self.predictor.input_size,
}, f)
file_size = cache_path.stat().st_size / 1024 / 1024
print(f"[Cache MISS] hash={img_hash[:12]}... encode done in {elapsed:.0f}ms saved={file_size:.1f}MB → cache ready")
def predict(self, **kwargs):
return self.predictor.predict(**kwargs)
# 1. 加载模型
sam = sam_model_registry["vit_h"](checkpoint="./sam_vit_h_4b8939.pth")
sam.to("cuda")
# 2. 加载图像
image = cv2.imread("./demo.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 3. 使用缓存 predictor
print("=" * 60)
print("SAM Embedding Cache Benchmark")
print("=" * 60)
cached_predictor = CachedSamPredictor(sam)
# 第一次:缓存 MISS,需要编码
t0 = time.perf_counter()
cached_predictor.set_image(image)
t_miss = time.perf_counter() - t0
masks, scores, _ = cached_predictor.predict(
point_coords=np.array([[280, 350]]),
point_labels=np.array([1]),
multimask_output=True,
)
# 第二次:缓存 HIT,秒加载
t0 = time.perf_counter()
cached_predictor.set_image(image)
t_hit = time.perf_counter() - t0
# 汇总
speedup = t_miss / t_hit if t_hit > 0 else float('inf')
print("=" * 60)
print(f" Cache MISS : {t_miss * 1000:.0f} ms")
print(f" Cache HIT : {t_hit * 1000:.1f} ms")
print(f" Speedup : {speedup:.0f}x faster with cache")
print("=" * 60)
# 4. 可视化并保存
best_idx = np.argmax(scores)
plt.figure(figsize=(12, 8))
plt.imshow(image)
plt.imshow(masks[best_idx], alpha=0.5, cmap='jet')
plt.scatter(280, 350, c='red', s=100)
plt.title(f"Mask Score: {scores[best_idx]:.3f} | Cache: {speedup:.0f}x faster")
plt.axis('off')
plt.savefig("./demo_cache_result.png", dpi=150, bbox_inches='tight')
plt.close()
print("Result saved to ./demo_cache_result.png")
output
py
============================================================
SAM Embedding Cache Benchmark
============================================================
[Cache MISS] hash=f540a683c951... encoding...
[Cache MISS] hash=f540a683c951... encode done in 736ms saved=4.0MB → cache ready
[Cache HIT] hash=f540a683c951... load=6.3ms file=4.0MB ✓
============================================================
Cache MISS : 748 ms
Cache HIT : 9.2 ms
Speedup : 81x faster with cache
============================================================
十三、总结金句
-
SAM 的本质:把分割从"这个东西叫什么"解耦为"这个东西在哪",用 prompt 统一了所有分割任务的接口。
-
Image Encoder 是整个系统的"字典",只编一次,反复查;这个设计让交互式分割从"不可能"变成"丝滑"。
-
Mask Decoder 的 2 层设计告诉我们:好的编码器做完了所有难的工作,解码器只需"查表"------这是经典的"重编码、轻解码"哲学。
-
SA-1B 不是 SAM 附属品,是另一个更重的贡献------11 亿个 mask 才是让 foundation model 思路在 CV 落地的真正燃料。
-
MobileSAM 证明了:不是所有层都需要压缩。只蒸馏 encoder、复用 decoder,四两拨千斤。
-
FastSAM 的教训:YOLO + 后处理虽然快,但丢掉了 SAM 最核心的"promptable"灵活性------这是方案取舍的经典案例。
-
Embedding Cache 是 SAM 落地的第一优化项,它把每次推理从"编码 + 解码"变成了"解码而已",在小批量交互场景下收益高达 60 倍。
-
SAM 不是无敌的------低对比度、细长结构、跨域数据,它还有很多不会做的事情。但它的出现,让分割从"手工匠时代"进入了"工业时代"。
最后一句 :SAM 最重要的遗产不是那三个 mask,而是它证明了一件事 ------ 视觉也可以有 foundation model,关键在于把任务抽象成"填空"而不是"归类"。
作者注:本文基于 Meta 官方论文《Segment Anything》(arXiv:2304.02643)、SA-1B 数据集、MobileSAM、FastSAM 原始论文,以及 2024-2025 年间社区在部署、优化、评测方面的最新进展撰写。