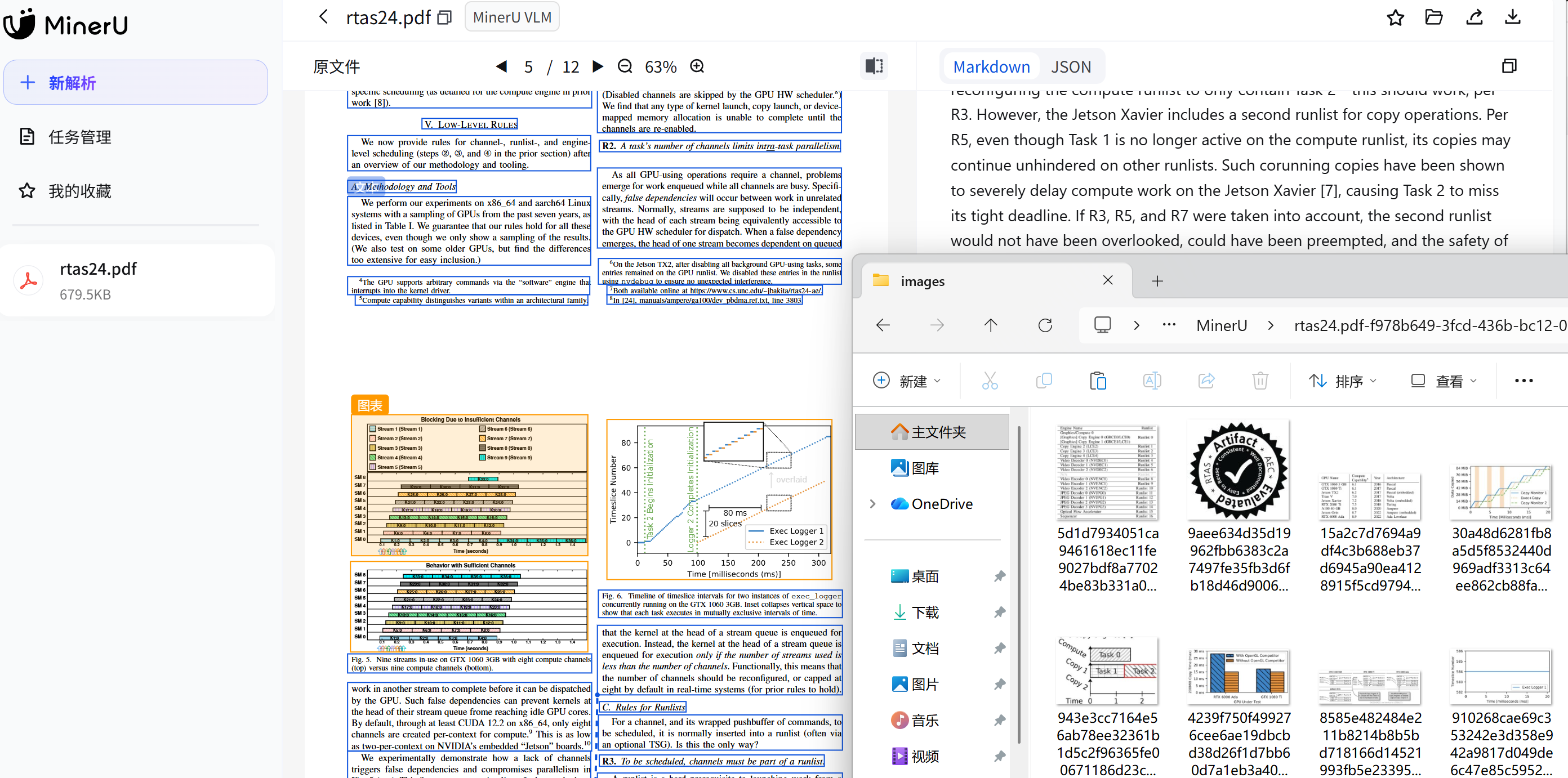
mineru本地版,它不需要配置大模型,它是直接用cpu跑vlm模型的,vlm模型已经内置到mineru软件里了,所以不需要额外配置大模型,转文档给ai用很好,可以用来同时识别图片和文本。(转出来有图片,图片和文档的正文都存在了本地,图片在一个单独的images文件夹下,被转好后的正文引用本地图片路径;然后加一个agent,打开转好文档的目录,里面有转好后的正文文本,和images子文件夹,我这里用zed里面自己的zed agent,加支持图片的模型,我这里用Gemma4 26b a4b,就可以同时识别图片和文字了)