摘要:
3D 医学图像分割依赖大有效感受野 (ERF)建模长程空间依赖,Transformer 存在计算复杂度高、细粒度分割精度差的缺陷,传统 CNN 直接扩大卷积核会引发优化不稳定、性能饱和、参数爆炸问题。该文从理论上证明了结构重参数化块会导致空间上不同的学习速率,由此提出Rep3d,使用轻量级调制网络来生成基于接收域的缩放掩码,在普通编码器体系结构中自适应地重新加权内核更新。
介绍:
论文的出发点还是为卷积核赋予近似Transformer的长距离建模能力,一个方式就是使用更大的卷积核。但是,简单的增加卷积核大小并不能提高性能,标准卷积依赖于静态的、权重共享的核,并且缺乏跨空间位置调节重要性的能力;结构重参数化之前学习过,就是训练时网络中使用不同大小卷积核的并行路径,在推理时,将不同大小的卷积核融合得到唯一路径(CLSA)。该文章想在大核卷积中引入空间先验,还想在训练过程中就实现重参数化。
为了达成这个目的,作者首先对CSLA进行了理论分析,发现每个分支相当于在不同的学习率下进行更新,导致收敛速度的元素差异,这与人类视觉相似,于是提出了一种新的接受性偏差再参数化策略,该策略将距离核中心的空间距离编码为学习前的空间偏差。
Rep3d:
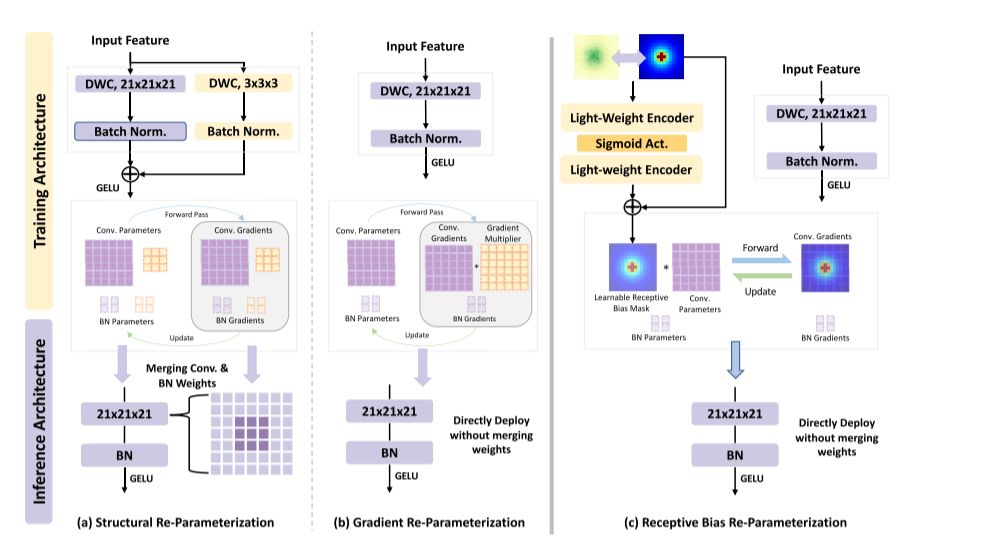
可以先从下图了解Rep3d的过程,第一个就是CLSA,第二个是为大核赋予一个静态掩码控制学习率,第三个就是本文提出的方法。
首先对CLSA进行理论分析,训练过程如下第一个公式,推理是融合就是第二三个公式:
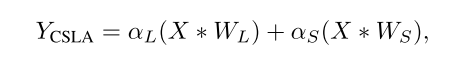
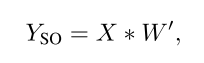
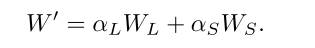
在训练更新计算梯度时
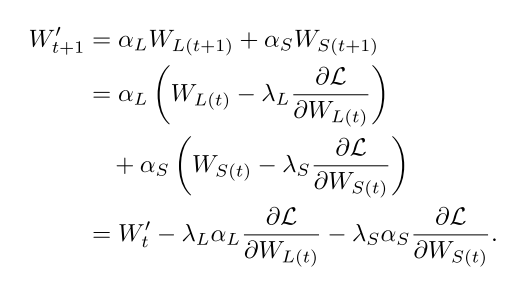
也就是说,当大核和小核的学习率相同或不同时,会出现两种情况:
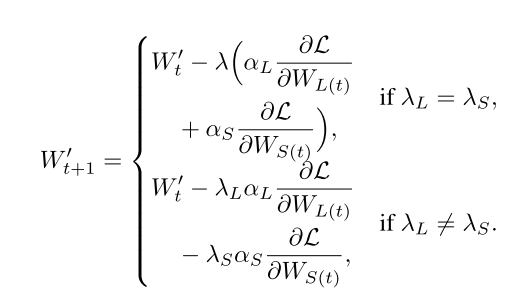
由于WS具有比WL更小的感受野,并且WS主要贡献于等价核W'的中心区域,所以位于W'中心位置值接收到来自WS和WL两个卷积的梯度,导致更快的收敛和更强的局部学习;而W'外围的值只接受到WL的梯度,导致收敛较慢,但保持全局上下文感知。
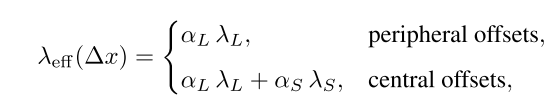
根据上面的分析,就能发现,其实CLSA相当于就是为大卷积核的不同位置赋予了不同的学习率,这样就引出本文的方法。首先,计算卷积核上每个点到中心点的直线距离(f),距离越近,数值越小,之后生成固定分数模板 P。
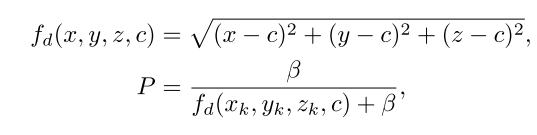
但P是固定的,为了达到自适应的效果,使用了一个超轻量的 2 层小网络(生成器) ,一起训练,让分数表变成可学习、自适应的。
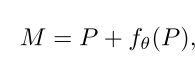
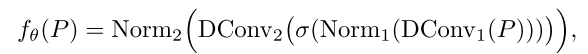
最后,把原始卷积核 W 和智能分数表 M 逐点相乘得到有效权重 W_eff, 分数高的中心:权重被放大→多更新、学得多 ,分数低的边缘:权重被缩小→少更新、学得稳。
实验:
文章将该方法使用在3DUX-Net上:
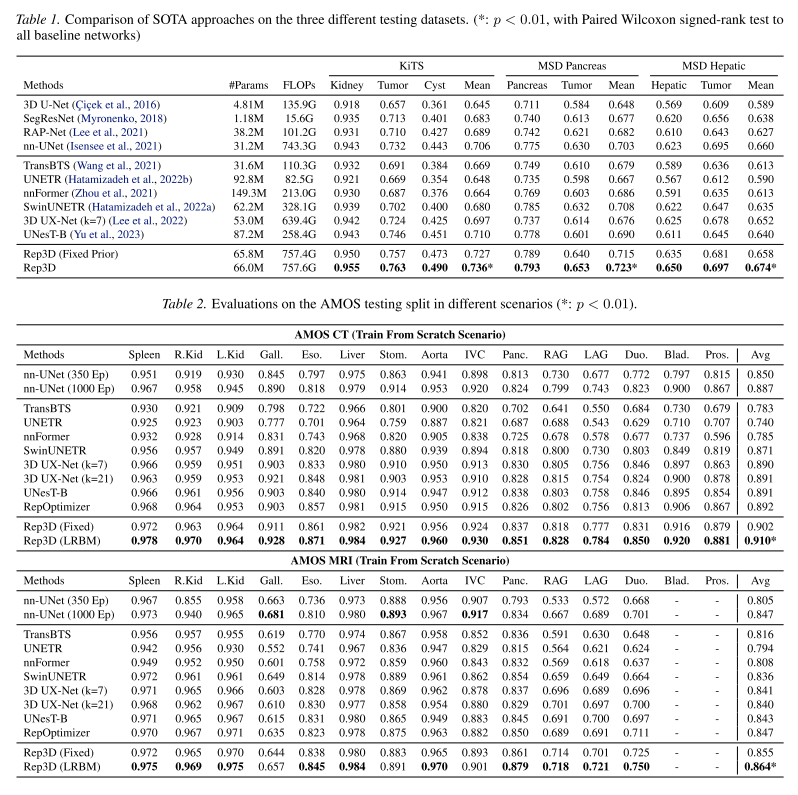
对两层生成器的消融实验:

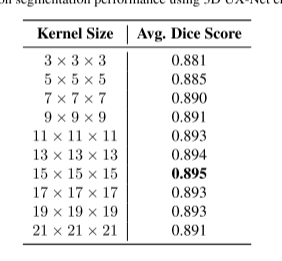
· 核大小的实验: