CLIP(Contrastive Language-Image Pre-training):Learning Transferable Visual Models From Natural Language Supervision
- 摘要
- [1. 介绍](#1. 介绍)
- [2. 方法](#2. 方法)
-
- [2.1 自然语言监督](#2.1 自然语言监督)
- [2.2 创建一个足够大的数据集](#2.2 创建一个足够大的数据集)
- [2.3 选择有效的预训练方法](#2.3 选择有效的预训练方法)
- [2.4 选择和扩展模型](#2.4 选择和扩展模型)
- [2.5 训练](#2.5 训练)
- [3. 实验](#3. 实验)
- 附录
-
- [1. A. 线性探针评估](#1. A. 线性探针评估)
- [1.1 数据集](#1.1 数据集)
- [1.2 模型](#1.2 模型)
- 总结
摘要
- 传统 CV 模型只能识别固定类别
- CLIP 用图文对比学习做零样本视觉理解
- 不用标注就能识别新物体
当前最先进的计算机视觉系统,都被训练去预测一组固定的、预先定义好的物体类别。这种受限的监督方式限制了模型的通用性与实用性 ,因为要指定任何其他视觉概念,都需要额外的标注数据。
直接从与图像对应的原始文本中学习,是一种很有前景的替代方案,因为它能利用范围更广的监督信号。
我们证明:"预测哪段文字描述对应哪张图" 这个简单的预训练任务,是一种高效、可扩展的从零学习 SOTA 图像表征的方法 。我们在从互联网收集的4 亿对(图像,文本)数据上做了训练。
预训练完成后,可以用自然语言来指代学到的视觉概念(或描述新的概念),从而让模型能零样本迁移到下游任务。
我们在30 多个不同的计算机视觉数据集上做了测试,覆盖任务包括:OCR、视频动作识别、地理定位、多种细粒度物体分类等。该模型在大多数任务上都能实现有效迁移,且常常不需要针对数据集做专门训练,就能媲美全监督基线模型。
1. 介绍
在过去几年中,直接从原始文本中学习的预训练方法彻底改变了NLP。
诸如自回归语言建模与掩码语言建模这类与任务无关的训练目标,已在计算量、模型容量和数据规模上实现了多个数量级的扩展,使模型能力持续稳步提升。
"文本到文本(text-to-text)" 作为标准化输入输出接口的提出(McCann 等人,2018;Radford 等人,2019;Raffel 等人,2019),让任务无关的架构能够零样本迁移到下游数据集,不再需要专门的输出层或针对数据集的定制化改造。
以 GPT-3(Brown 等人,2020)为代表的旗舰模型,如今在大量任务上均可与专用模型媲美,且几乎不需要针对特定数据集的训练数据。
这些研究结果表明,在网页规模的文本集合中,现代预训练方法所能获取的整体监督效果,超过了高质量人工标注的自然语言处理数据集。然而在计算机视觉等其他领域,在 ImageNet 等人工标注数据集上对模型进行预训练仍是常规做法(邓等人,2009年)。这
种直接从网页文本中学习的可扩展预训练方法,能否在计算机视觉领域带来类似的突破性进展?此前的相关研究已展现出积极的趋势。
尽管这些方法作为概念验证令人振奋,但利用自然语言监督来学习图像特征的做法仍然很少见 。
这很可能是因为,它们在通用基准测试上的表现远低于其他方法。
例如,Li 等人(2017)在 ImageNet 上的零样本分类准确率只有 11.5%。
这远低于当前最先进模型 88.4% 的准确率(Xie 等人,2020),
甚至低于传统计算机视觉方法约 50% 的准确率(Deng 等人,2012)。
于是,研究者转而使用范围更窄、但目标更明确的弱监督方法 来提升性能。
Mahajan 等人(2018)指出,在 Instagram 图像上预测与 ImageNet 相关的标签(Hashtag)是一种有效的预训练任务。将这些预训练模型在 ImageNet 上微调后,准确率提升了超过 5%,并刷新了当时的最优结果。
Kolesnikov 等人(2019)和 Dosovitskiy 等人(2020)也证明:通过在噪声标注的 JFT-300M 数据集上预训练模型来预测类别,可以在更广泛的迁移学习基准上取得巨大提升。
这条工作路线代表了当前实用主义的中间立场,即从有限数量的监督"黄金标签"和从几乎无限数量的原始文本中学习之间进行学习。然而,这并非没有妥协。两者的作品都经过精心设计,并在工艺限制下,他们的监督班分别为1000班和18291班。自然语言能够通过其通用性来表达并监督更广泛的视觉概念。这两种方法还使用静态softmax分类器来执行预测,并且缺乏动态输出的机制。这严重削弱了它们的灵活性,限制了它们的"零样本"能力。
这一系列研究工作,代表了当前在两种训练思路之间务实的折中路线:一种是依赖有限的高质量 "黄金标注" 进行监督学习,另一种是利用近乎无限的原始文本进行学习。
不足:
- 上述两项工作都在设计时精心限定了监督信号的范围 ------前者将类别限制为 1000 类,后者限制为 18291 类。而自然语言凭借其通用性,能够表达并监督范围宽广得多的视觉概念。
- 同时,这些方法都使用静态的 softmax 分类器进行预测,缺少动态输出的机制。这严重限制了模型的灵活性,也削弱了它们的 "零样本" 能力。
这些弱监督模型与近期直接从自然语言中学习图像表征的研究之间 ,一个关键差异在于规模 。
Mahajan 等人(2018)和 Kolesnikov 等人(2019)使用加速器年级别的算力,在数百万至数十亿张图像上训练模型;
而 VirTex、ICMLM 和 ConVIRT 仅使用加速器天级别的算力,在十几万张图像上训练。
在本工作中,我们填补了这一差距,并研究在大规模数据下使用自然语言监督训练的图像分类器的行为。
得益于互联网上大量公开的此类图文数据,我们构建了一个包含 4 亿对(图像,文本) 的全新数据集,并证明一种简化版的 ConVIRT 从零训练即可高效地从自然语言监督中学习。我们将其命名为 CLIP(对比语言 - 图像预训练) 。
我们通过训练8 个不同规模、算力跨度接近两个数量级的模型来研究 CLIP 的可扩展性,并发现迁移性能随算力增长呈平稳可预测的趋势。
我们发现,CLIP 与 GPT 系列模型类似,在预训练阶段就学会了执行广泛任务 ,包括光学字符识别(OCR)、地理定位、动作识别等。
我们在30 多个现有数据集上评测了 CLIP 的零样本迁移性能,发现它可与以往针对特定任务的全监督模型媲美。
我们还通过线性探针表征学习分析验证了这些结论,表明 CLIP 优于目前公开效果最好的 ImageNet 预训练模型(2021年) ,同时计算效率更高。
此外,我们发现零样本 CLIP 模型比精度相当的监督式 ImageNet 模型鲁棒性更强,这表明对任务无关模型进行零样本评估,更能代表模型的真实能力。
2. 方法
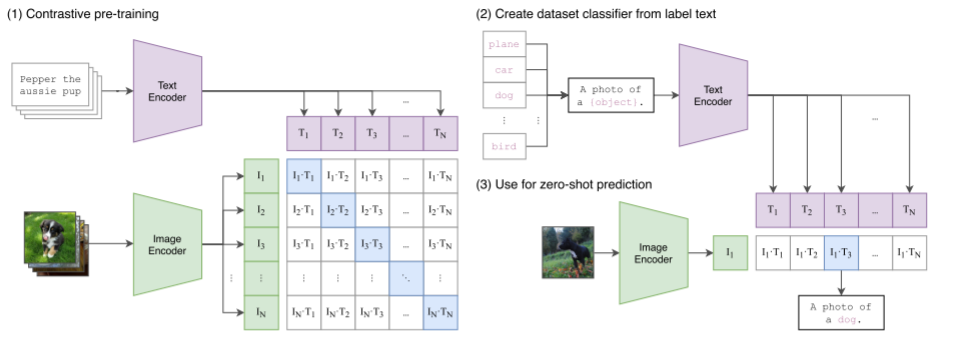
图 1.我们的方法摘要。 标准图像模型联合训练图像特征提取器和线性分类器来预测某些标签,而 CLIP 联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。 在测试时,学习的文本编码器通过嵌入目标数据集类的名称或描述来合成零样本线性分类器。
2.1 自然语言监督
我们方法的核心思想,是从自然语言中包含的监督信号来学习感知能力。
一句话:
用 "人话" 当标签,来教模型看懂图片。
-
传统监督学习(老方法):必须用 "固定标签"
以前教模型认图,必须给固定类别:
0 = 猫
1 = 狗
2 = 汽车
3 = 鸟
模型只能认这固定几类,多一个都不行。
而且必须人工标注,成本高、扩展性差。
-
自然语言监督(新方法):用句子、描述、文字当监督不用固定标签!
直接用网上随便的文字描述来教模型。
比如:
"一只黑白相间的猫趴在沙发上"
"夕阳下的海边,有只狗在跑"
"红色跑车停在路边"
模型的任务变成:
学会 "图片 ↔ 文字" 的对应关系。
-
为什么叫 "监督"?
因为:
文字 = 监督信号
文字告诉模型图片里有什么。
你不用人工标 "猫、狗、车",
网上的 caption、描述、标题、alt 文本,全是天然的监督。
-
核心好处
不用人工标注
网上图文配对直接用。
类别无限
不用预先定义 1000 类,语言能说的,模型都能懂。
能零样本识别
没训练过的东西,只要用文字描述,模型就能认。
-
最直观比喻
传统监督:
老师拿着卡片教你:
这是猫 → 卡片写 "猫"
这是狗 → 卡片写 "狗"
只能认卡片上的东西。
自然语言监督:
老师直接给你看一整本图文故事书
你自己学会:
图片 → 文字 的对应关系。
之后任何新东西,用一句话描述,你就能懂。
最终极简总结
自然语言监督 = 用 "人类的文字描述" 当监督信号,让模型看图识字、学会通用视觉,不再局限于固定类别。
2.2 创建一个足够大的数据集
现有研究主要使用三个数据集:MS-COCO(Lin 等,2014)、Visual Genome(Krishna 等,2017)以及 YFCC100M(Thomee 等,2016)。
尽管 MS-COCO 和 Visual Genome 是高质量的众包标注数据集,但以现代标准来看规模偏小,各自仅包含约 10 万张训练图片。相比之下,其他计算机视觉系统的训练数据规模可达 35 亿张 Instagram 图片(Mahajan 等,2018)。
包含 1 亿张图片的 YFCC100M 是一种可行替代方案,但每张图像的元数据过于稀疏且质量参差不齐。许多图像使用类似 20160716 113957.JPG 这样自动生成的文件名作为 "标题",或包含相机曝光参数这类 "描述"。
在经过过滤、仅保留带有英文自然语言标题或描述的图像后,该数据集规模缩减为原来的 1/6,仅剩 1500 万张图片,大小与 ImageNet 大致相当。
自然语言监督的一个主要动机是这种形式的大量数据在互联网上公开可用。由于现有的数据集不能充分反映这种可能性,因此只考虑这些数据集的结果会低估这一研究方向的潜力。
为了解决这个问题,我们构建了一个新的数据集,其中包含4亿对(图像,文本)对 ,这些数据来自互联网上各种公开可用的资源。
为了尝试覆盖尽可能广泛的视觉概念集,我们搜索(图像,文本)对作为构建过程的一部分,其文本包含500,000个查询集中的一个我们通过每个查询包含多达20,000对(图像、文本)来近似地平衡结果。结果数据集的总字数与用于训练GPT-2的WebText数据集相似。我们将此数据集称为WebImageText的WIT。
50万x2万=1000亿,一个词最多对应2万张图,大部分没有,实际才4亿。
2.3 选择有效的预训练方法
当前最先进的计算机视觉系统会消耗极其庞大的计算资源。
Mahajan 等人(2018)训练其 ResNeXt101-32x48d 模型耗费了19 个 GPU 年;Xie 等人(2020)训练 Noisy Student EfficientNet-L2 模型则耗费了33 个 TPUv3 核心年。要知道,这两套系统都只是为了预测ImageNet 的 1000 个固定类别。
相比之下,想要从自然语言中学习开放集合的视觉概念,任务难度显得异常艰巨。
在研究过程中我们发现,训练效率是成功扩展自然语言监督的关键 ,因此我们最终基于效率这一指标选定了预训练方法。
我们**最初的方法与 VirTex 类似,从零开始联合训练图像卷积神经网络(CNN)与文本 Transformer,目标是预测图像的标题。**然而,我们在高效扩展这种方法时遇到了困难。
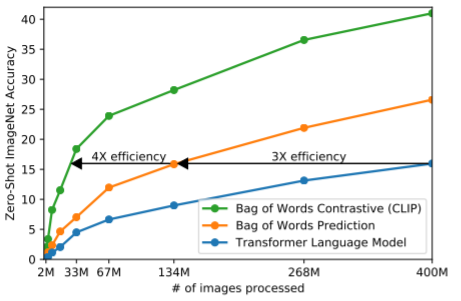
图2。CLIP在零样本转移时比我们的图像标题基线效率高得多。尽管表达能力很强,但我们发现基于转换器的语言模型在零样本ImageNet分类方面相对较弱。在这里,我们看到它的学习速度比预测文本的词袋(BoW)编码的基线慢3倍(Joulin et al., 2016)。将预测目标替换为CLIP的对比目标进一步提高了4倍的效率
在图 2 中可以看到,一个拥有6300 万参数的 Transformer 语言模型(其算力消耗已是 ResNet-50 图像编码器的两倍),学习识别 ImageNet 类别的速度,比一种简单得多的词袋编码预测基线模型慢 3 倍。
这两种方法有一个关键的相似之处:它们都试图精确预测与每张图像对应的文本中的具体单词。
由于与图像一同出现的描述、评论和相关文本种类繁多,这是一项非常困难的任务。
近期在图像对比表征学习领域 的研究发现,对比学习目标能比传统的预测式目标学到更好的表征 (Tian 等人,2019)。
另有研究表明,尽管图像生成模型能够学到高质量的视觉表征,但要达到相同性能,其计算量比对比模型高出一个数量级以上(Chen 等人,2020a)。
基于这些发现,我们转而训练模型去解决一个更简单的替代任务:只判断哪段文本整体上与哪张图像配对,而不去预测文本里的每个具体单词。
从相同的词袋编码基线出发,我们在图 2 中把预测目标替换成了对比学习目标,
结果观察到模型向 ImageNet 零样本迁移的效率进一步提升了 4 倍。

图3。用于CLIP实现核心的类似numpy的伪代码。
给定一批N个(图像、文本)配对,训练CLIP以预测一批中的N×N个可能的(图像、文本)配对中的哪一个实际发生。为此,Clip通过联合训练图像编码器和文本编码器来学习多模式嵌入空间,以最大化批次中N个实数对的图像和文本嵌入的余弦相似性,同时最小化N个−N个错误配对的嵌入的余弦相似性。我们在这些相似性分数上优化了对称的交叉熵损失。在图3中,我们包含了Clip实现的核心的伪代码。据我们所知,这种批量构造技术和目标最早是在深度度量学习领域引入的,当时多类别N对损失Sohn(2016)被Oord等人推广用于对比表征学习。(2018)作为InfoNCE的损失,最近被Zhang等人改编用于医学成像领域的对比(文本、图像)表征学习。(2020)。
- 让 真配对(图 A + 文字 A) 变得很像很像
- 让 假配对(图 A + 文字 B) 变得一点都不像
- CLIP 同时训练两个编码器,让配对的图和文字在向量空间里靠近,不配对的远离,用对称交叉熵损失保证双向对齐
由于我们的预训练数据集规模极大,过拟合并非主要问题,因此与 Zhang 等人(2020)的实现相比,CLIP 的训练细节得到了简化。
我们从零开始训练 CLIP,不使用 ImageNet 预训练权重初始化图像编码器,也不使用预训练权重初始化文本编码器。我们没有在表征与对比嵌入空间之间使用非线性投影------ 这一操作由 Bachman 等人(2019)提出,并由 Chen 等人(2020b)推广。
相反,我们仅使用线性投影,将每个编码器的表征映射到多模态嵌入空间。
我们并未观察到两种版本在训练效率上存在差异,并推测非线性投影可能只与当前仅用于图像的自监督表征学习方法的细节相适配 。我们还去掉了 Zhang 等人(2020)提出的文本变换函数 (t_{u})(该函数会从文本中均匀随机采样一个句子),因为 CLIP 预训练数据集中的许多(图像、文本)对本身就只有一句话。
我们同样简化了图像变换函数 (t_{v})。
训练期间唯一使用的数据增强方式是从缩放后的图像中随机正方形裁剪。最后,控制 softmax 中 logits 范围的温度参数 τ,在训练中被直接优化为对数参数化的乘法标量,从而避免将其作为超参数手动调节。
不管线性还是非线性,作用只有一个:
把图像特征 / 文字特征 → 映射到同一个空间,方便对比相似度。
你可以理解成:
把图和文字翻译成同一种语言,方便比较。
- 线性 = 只做缩放 + 旋转 + 平移
就像一把尺子,把向量拉长、缩短、转个方向。 - 非线性 = 加激活函数 + 多层网络
相当于用一个小神经网络去做映射。
线性投影:简单、快速、够用。
非线性投影:复杂、花哨、没必要。
CLIP 证明:简单的线性就足够强!
2.4 选择和扩展模型
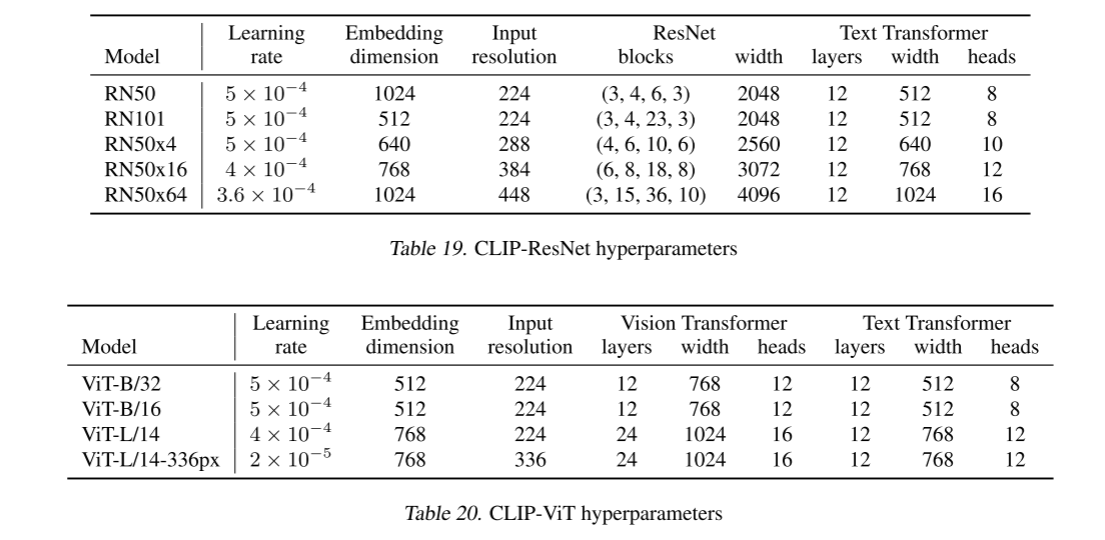
我们考虑两种不同的图像编码器架构。 首先,我们使用 ResNet-50(He et al., 2016a)作为图像编码器的基础架构,因为它的广泛采用和经过验证的性能。 我们使用 He 等人的 ResNetD 改进对原始版本进行了一些修改。 (2019) 和来自Zhang (2019) 的抗锯齿 rect-2 模糊池。 我们还用注意力池机制取代了全局平均池层。 注意力池被实现为单层"变压器式"多头 QKV 注意力,其中查询以图像的全局平均池表示为条件。 对于第二种架构,我们使用最近推出的 Vision Transformer (ViT) 进行实验(Dosovitskiy 等人,2020)。 我们密切关注他们的实现,只进行了微小的修改,即在变压器之前向组合补丁和位置嵌入添加额外的层归一化,并使用略有不同的初始化方案。
文本编码器是一个 Transformer(Vaswani 等人,2017),其架构修改在 Radford 等人中描述。 (2019)。 作为基本尺寸,我们使用 63M 参数、12 层、512 宽的模型,具有 8 个注意力头。 该转换器对具有 49,152 个词汇大小的文本的小写字节对编码 (BPE) 表示进行操作(Sennrich 等人,2015)。 为了计算效率,最大序列长度上限为 76。文本序列用 SOS 和 EOS 标记括起来,变压器最高层在 EOS 标记处的激活被视为文本的特征表示,该特征表示经过层归一化,然后线性投影到多模态嵌入空间中。 文本编码器中使用了屏蔽自注意力,以保留使用预先训练的语言模型进行初始化或添加语言建模作为辅助目标的能力,尽管对此的探索留待未来的工作。
虽然之前的计算机视觉研究通常通过单独增加宽度(Mahajan et al., 2018)或深度(He et al., 2016a)来缩放模型,但对于 ResNet 图像编码器,我们采用 Tan & Le (2019) 的方法,该方法发现在所有宽度、深度和分辨率上分配额外的计算效果优于仅将其分配给模型的一维。 虽然 Tan & Le (2019) 调整了分配给 EfficientNet 架构每个维度的计算比率,但我们使用了一个简单的基线,即平均分配额外计算以增加模型的宽度、深度和分辨率。 **对于文本编码器,我们仅将模型的宽度缩放为与计算出的 ResNet 宽度增加成正比,而根本不缩放深度,**因为我们发现 CLIP 的性能对文本编码器的容量不太敏感。
2.5 训练
我们训练了一系列 5 个 ResNet 和 3 个 Vision Transformer。
对于 ResNet,我们训练一个 ResNet-50、一个 ResNet-101 ,然后再训练 3 个,它们遵循 EfficientNet 风格的模型缩放,并使用 ResNet-50 的大约 4 倍、16 倍和 64 倍的计算量。 它们分别表示为 RN50x4、RN50x16 和 RN50x64。
对于 Vision Transformers,我们训练了 ViT-B/32、ViT-B/16 和 ViT-L/14 。 我们将所有模型训练 32 个 epoch。 我们使用 Adam 优化器(Kingma & Ba,2014),将解耦权重衰减正则化(Loshchilov & Hutter,2017)应用于所有非增益或偏差的权重,并使用余弦时间表衰减学习率(Loshchilov & Hutter,2016)。 当训练 1 个 epoch 时,在基线 ResNet50 模型上结合使用网格搜索、随机搜索和手动调整来设置初始超参数。 然后,由于计算限制,超参数被启发式地调整为更大的模型。 可学习的温度参数 τ 被初始化为相当于 0.07(Wu 等人,2018),并进行剪裁以防止 logits 缩放超过 100,我们发现这对于防止训练不稳定是必要的。 我们使用非常大的小批量大小 32,768。 混合精度(Micikevicius et al., 2017)用于加速训练并节省内存。 为了节省额外的内存,使用了梯度检查点(Griewank & Walther,2000;Chen 等人,2016)、半精度 Adam 统计(Dhariwal 等人,2020)和半精度随机舍入文本编码器权重。 嵌入相似度的计算也被分片为单独的 GPU,仅计算其本地批量嵌入所需的成对相似度的子集。 最大的 ResNet 模型 RN50x64 在 592 个 V100 GPU 上训练需要 18 天,而最大的 Vision Transformer 在 256 个 V100 GPU 上训练需要 12 天。 对于 ViT-L/14,我们还以更高的 336 像素分辨率预训练一个额外的 epoch,以提高类似于 FixRes 的性能(Touvron 等人,2019)。 我们将此模型表示为 ViT-L/14@336px。 除非另有说明,本文中报告为"CLIP"的所有结果都使用我们发现性能最佳的模型。
3. 实验
实验部分内容过多,我简要总结下。
我们首先通过各自的编码器计算图像的特征嵌入和可能文本集的特征嵌入。 然后计算这些嵌入的余弦相似度,通过温度参数 τ 进行缩放,并通过 softmax 归一化为概率分布。 请注意,该预测层是一个多项式逻辑回归分类器,具有 L2 归一化输入、L2 归一化权重、无偏差和温度缩放。 当以这种方式解释时,图像编码器是计算机视觉主干,它计算图像的特征表示,文本编码器是超网络(Ha et al., 2016),它根据指定类表示的视觉概念的文本生成线性分类器的权重。
我们发现零样本 CLIP 在一些专门的、复杂的或抽象的任务上相当薄弱,例如卫星图像分类(EuroSAT 和 RESISC45)、淋巴结肿瘤检测(PatchCamelyon)、计算合成场景中的对象(CLEVRCounts)、自动驾驶相关任务,例如德国交通标志识别(GTSRB)、识别到最近汽车的距离(KITTI 距离)。 这些结果凸显了零样本 CLIP 在更复杂的任务上的较差能力。
附录
1. A. 线性探针评估
我们提供了本文中提出的线性探针实验的更多详细信息,包括用于评估的数据集和模型的列表。
1.1 数据集
我们使用 (Kornblith et al., 2019) 引入的经过充分研究的评估套件中的 12 个数据集,并添加 15 个附加数据集,以评估模型在更广泛的分布和任务上的性能。 这些数据集包括 MNIST、面部表情识别 2013 数据集(Goodfellow 等人,2015)、STL-10(Coates 等人,2011)、EuroSAT(Helber 等人,2019)、NWPURESISC45 数据集(Cheng 等人,2017)、德国交通标志识别基准(GTSRB)数据集 (Stallkamp 等人,2011)、KITTI 数据集(Geiger 等人,2012)、PatchCamelyon(Veeling 等人,2018)、UCF101 动作识别数据集(Soomro 等人,2012)、Kinetics 700(Carreira 等人,2019)、CLEVR 数据集的 2,500 个随机样本 (Johnson 等人,2017)、Hateful Memes 数据集(Kiela 等人,2020)和 ImageNet-1k 数据集(Deng 等人,2012)。 对于两个视频数据集(UCF101 和 Kinetics700),我们使用每个视频剪辑的中间帧作为输入图像。 STL-10 和 UCF101 有多个预定义的训练/验证/测试分割,分别为 10 和 3,我们报告所有分割的平均值。 表 9 提供了每个数据集的详细信息和相应的评估指标。
此外,我们创建了两个数据集,分别称为 Country211 和 Rendered SST2。 Country211 数据集旨在评估视觉表示的地理定位能力。 我们过滤了 YFCC100m 数据集(Thomee 等人,2016),找到至少有 300 张带有 GPS 坐标的照片的 211 个国家(定义为具有 ISO-3166 国家/地区代码),并通过对每个国家采样 200 张照片进行训练和 100 张照片进行测试,构建了一个包含 211 个类别的平衡数据集。
渲染的 SST2 数据集旨在测量视觉表示的光学字符识别能力。 为此,我们使用了斯坦福情绪树库数据集(Socher et al., 2013)中的句子,并将它们渲染成图像,白底黑字,分辨率为 448×448。 图 19 显示了该数据集中的两个示例图像。
1.2 模型
结合上面列出的数据集,我们使用线性探针评估以下一系列模型。
-
LM RN50
这是一个多模态模型,它使用自回归损失而不是对比损失,同时使用 ResNet-50 架构作为最小对比模型。 为此,CNN 的输出被投影为四个标记,然后将其作为前缀提供给自回归预测文本标记的语言模型。 除了训练目标之外,该模型还与其他 CLIP 模型在相同的数据集上进行了相同数量的训练。
-
CLIP-RN
包括五个基于 ResNet 的对比 CLIP 模型。 正如论文中所讨论的,前两个模型遵循 ResNet-50 和 ResNet-101,我们对接下来的三个模型使用 EfficientNetstyle (Tan & Le, 2019) 缩放,同时缩放模型宽度、层数和输入分辨率,以获得具有大约 4 倍、16 倍和 64 倍计算量的模型
-
CLIP-ViT
我们包括四个使用 Vision Transformer(Dosovitskiy 等人,2020)架构作为图像编码器的 CLIP 模型。 我们包括在 224×224 像素图像上训练的三个模型:ViT-B/32、ViT-B/16、ViT-L/14 和在 336×336 像素输入图像上微调的 ViT-L/14 模型。
-
EfficietNet
我们使用原始 EfficientNet 论文(Tan & Le,2019)中的九个模型(B0-B8),以及噪声学生变体(B0-B7、L2-475 和 L2-800)(Tan & Le,2019)。 最大的模型(L2-475 和 L2-800)分别采用 475x475 和 800x800 像素的输入分辨率。
-
Instagram
预训练的 ResNeXt 我们使用 (Mahajan et al., 2018) 发布的四个模型 (32x8d、32x16d、32x32d、32x48d),以及使用更高输入分辨率的两个 FixRes 变体 (Touvron et al., 2019)。
-
Big Transfer (BiT)
我们使用 BiT-S 和 BiT-M 模型(Kolesnikov 等人,2019),在 ImageNet-1k 和 ImageNet-21k 数据集上进行训练。 BiT-L 的模型权重未公开。
-
Vision Transformer (ViT)
我们还包括在 ImageNet-21k 数据集上预训练的四个 ViT (Dosovitskiy et al., 2020) 检查点,即 ViT-B/32、ViT-B/16、ViTL/16 和 ViT-H/14。 我们注意到,他们在 JFT-300M 数据集上训练的性能最佳模型并未公开提供。
-
SimCLRv2 SimCLRv2(Chen 等人,2020c)
项目发布了各种设置下的预训练和微调模型。 我们使用带有选择性内核的七个仅预训练检查点。
-
动量对比 (MoCo)
我们包括 MoCo-v1 (He et al., 2020) 和 MoCo-v2 (Chen et al., 2020d) 检查点。
-
VirTex
我们使用 VirTex 的预训练模型(Desai & Johnson,2020)。 我们注意到 VirTex 具有与 CLIP-AR 类似的模型设计,但在来自 MSCOCO 的小 1000 倍的高质量字幕数据集上进行训练。
-
ResNet
我们添加了(He et al., 2016b)发布的原始 ResNet 检查点,即 ResNet-50、ResNet-101 和 ResNet152。
实验结果就不放了,太多了。
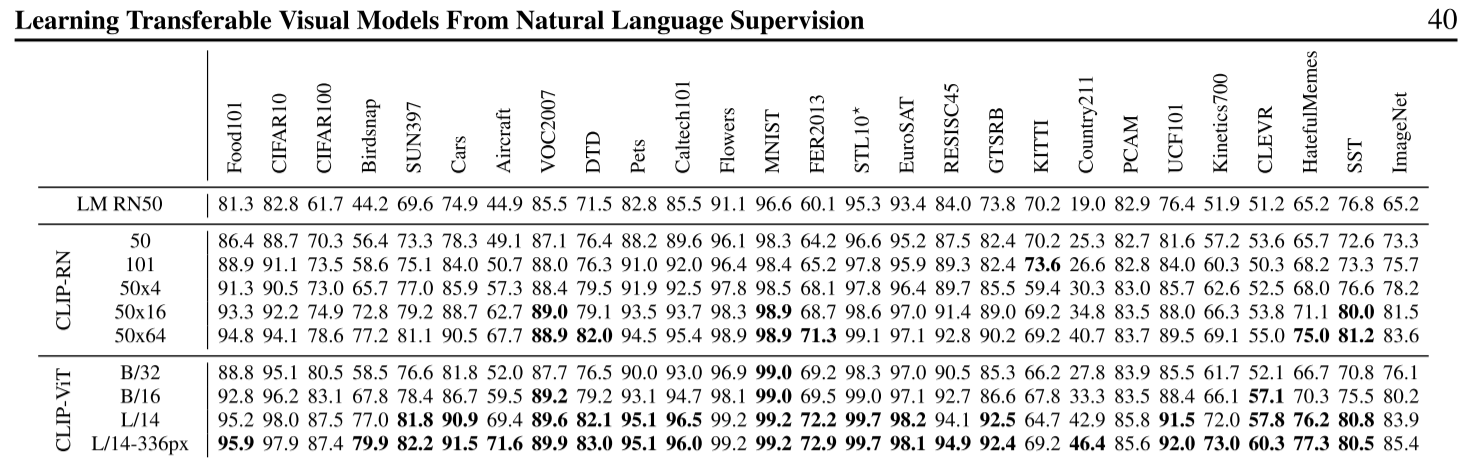
CLIP-VIT实验效果,大多数情况下,性能能达到最优:
总结
一、我们研究了是否有可能将 NLP 中与任务无关的网络规模预训练的成功转移到另一个领域。 我们发现采用这个公式会导致计算机视觉领域出现类似的行为,并讨论了这一研究领域的社会影响。 为了优化其训练目标,CLIP 模型在预训练期间学习执行各种任务。 然后可以通过自然语言提示来利用这种任务学习,以实现向许多现有数据集的零样本迁移。 在足够的规模下,这种方法的性能可以与特定任务的监督模型相媲美,尽管仍有很大的改进空间。
二、CLIP 的真正创新(四点,每点都颠覆)
- 范式革命:用自然语言代替 "离散标签" 做监督
- 传统 CV:
图片 → 人工打标签:0 = 猫、1 = 狗、2 = 车
标签是孤立数字,语义很弱
只能识别训练过的类别 - CLIP:
图片 + 自然语言句子("一只坐在草地上的猫")
监督信号是整句语义,不是数字
直接把 "视觉 ↔ 语言" 对齐
这一步直接把 CV 从 "固定分类" 拉到开放世界、可无限扩展。
- 任务换道:用对比学习代替 "生成 / 分类"
- 前人做图文:
要么 "看图说话"(生成文字)
要么 "关键词分类"
计算重、效果差、零样本很弱(之前只有 10%--20%) - CLIP 用超简单的对比任务:
一个 batch 里 N 张图、N 句话
只学:哪张图配哪句话(N×N 相似度矩阵)
正确对相似度拉高,错误对拉低
简单到离谱,但效率是生成式的 4--10 倍,才能训到 4 亿对。
- 数据规模:4 亿互联网图文对,之前没人敢这么干
- 之前最大的图文数据集:
MS-COCO:10 万
YFCC100M:过滤后十几万 - CLIP 直接上 WIT:4 亿(图,文)对,全是网上爬的、噪声大、但覆盖全世界视觉概念。
没有这个数据规模,零样本能力根本出不来。
- 能力跃迁:零样本分类 ≈ 有监督 SOTA
这是最震撼的:
不微调、不碰 ImageNet 训练数据
直接用 "a photo of a cat" 这种提示
ImageNet 零样本准确率 76.2%,和 ResNet-50 有监督差不多
之前所有模型零样本都很烂,CLIP 直接把零样本从 "玩具" 变成可用工具。