【4.1】★★☆☆☆
考点:在串联的自然连接(NATURAL JOIN)中,在"字段被'用掉'一次后,就无法再用于后续连接"的风险。

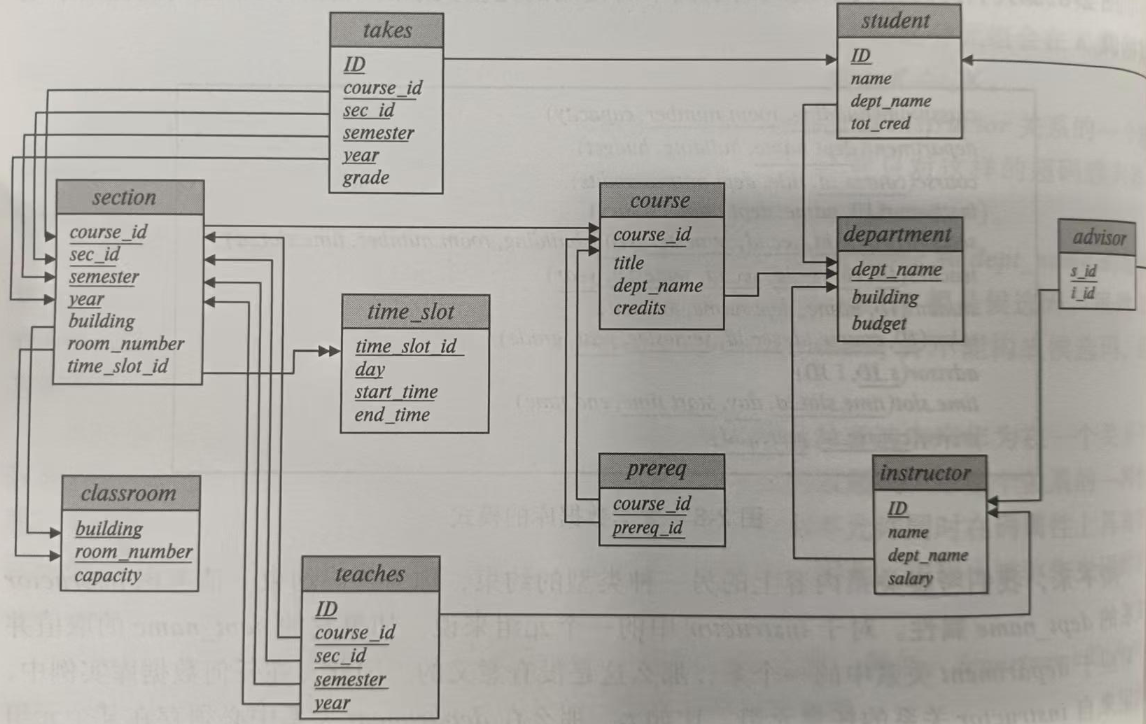
NATURAL JOIN 无法区分"用于连接本表的字段"和"用于连接下一张表的字段"。当 section 表被加入时,它的 course_id 已经被用来和 teaches 表的 course_id 对齐了。当你试图用这个结果再去 NATURAL JOIN course 时,数据库会尝试匹配所有同名字段。
section 表和 course 表同名的字段只有 course_id。
teaches 表和 course 表同名的字段也只有 course_id。
此时生成的中间结果集 里,虽然保留了 course_id,但这个 course_id 已经不再是"属于 section 表的原始字段"了,它是一个合并后的字段。
【4.2】

【a题】★☆☆☆☆
考点:COALESCE(a.name, b.name)的使用
涉及表格:instructor teaches
提示:
COALESCE(T.sect_id, 0) 是一个SQL函数,
使用 COALESCE(a.name, b.name) AS name 的意思是:
"请优先看
a.name,如果它不是 NULL ,就用它;如果它是NULL,那就退而求其次用b.name。"
具体含义是:检查 T.sect_id 这个字段的值。
- 如果
T.sect_id不是NULL,就返回T.sect_id本身的值。 - 如果
T.sect_id是NULL,就返回0。
最终,这个表达式的结果会被命名为 SectionID。
这个函数常用于为可能为空的字段提供一个"兜底"的默认值,确保查询结果中不会出现 NULL,从而使数据更清晰,或避免在后续计算中出现问题。
显示所有教师,因此instructor英国作为主表,左联,从表选用teaches,然后用coalesce teaches的sect_id字段,并设置替换值为0
【正解】
select instructor.ID coalesce(teaches.ID, 0) AS SECTION_ID
from instructor left outer join teaches on instructor.ID=teaches.ID
【b题】☆☆☆☆☆
标量子查询本质上就是一个只返回单个值(一行一列)的子查询。你可以把它想象成一个"临时变量"或者一个"动态计算出的数值",因为它返回的结果是单一的
【正解】
select instructor.ID coalesce(teaches.ID, 0) AS SECTION_ID from instructor, teaches where instructor.ID=teaches.ID
【c题】★★★☆☆
考点:join的顺序
涉及表:teaches instructor
思路:明确指出要写出有多少位老师就有多少记录,因此instructor作为主表,section作为从表
select section.sec_id, instructor.ID, coalesce(teaches.ID, "-") AS instructor_name
from instructor left outer join teaches on instructor.ID=teaches.ID left outer join section on section.course_id=teaches.course_id
where teaches.year=2018 and teaches.semester="Spring"
先写 Instructor I 会导致结果不符合题目 c 的要求 ,主要有两个核心问题:会漏掉没老师的课程 ,并且结果集的主体变成了"老师"而不是"课程段"。
题目 c 的核心要求是:"显示 2018 年春季开设的所有课程段的列表"。
- 你的写法 :以
Instructor(老师)为主表。这意味着 SQL 会先找所有老师,然后看他们教了什么课。 - 后果 :如果某门课(Section)还没有安排任何老师 ,那么
Instructor表里就没有对应的人,这门课就不会出现在结果的第一行。这直接违反了题目"没老师的课程也要显示"的要求。
【正解】
select section.sec_id, instructor.ID, coalesce(teaches.ID, "-") AS instructor_name
from section left outer join teaches on ( section.course_id=teaches.course_id and section.sec_id=teaches.sec_id ) left outer join instructor on instructor.ID=teaches.ID
where teaches.year=2018 and teaches.semester="Spring"
在你提供的 SQL 语句中,"有多少位老师就有多少记录"这一逻辑的实现,核心在于 表之间的连接方式 以及 主表的选择。我们来逐步分析它是如何运作的:
1. 主表是 Section(课程段)
1FROM Section S这是整个查询的"地基"。这意味着最终的结果集首先会包含所有满足 WHERE 条件的课程段。即使某个课程段暂时没有老师,它也会先被选出来。
2. 第一次连接:LEFT OUTER JOIN Teaches
1LEFT OUTER JOIN Teaches T ON (S.CourseID = T.CourseID AND S.SecID = T.SecID)- 作用 :将课程段(
Section)与排课记录(Teaches)关联起来。 - 关键点 :
Teaches表通常是一对多的关系。一门课(Section)可以对应Teaches表中的多条记录,每条记录代表一位老师。 - 效果 :如果课程段 A 有 3 位老师,那么在
Teaches表里就会有 3 条关于课程段 A 的记录(CourseID和SecID相同,但ID不同)。当Section与Teaches连接时,这 3 条记录会被"展开",导致课程段 A 在结果中出现 3 次。
3. 第二次连接:LEFT OUTER JOIN Instructor
1LEFT OUTER JOIN Instructor I ON T.ID = I.ID- 作用 :根据
Teaches表里的老师 ID,去查找老师的具体信息(如姓名)。 - 效果:由于上一步已经把"一个课程段对应多位老师"的情况展开成了多行,这一步只是给每一行配上具体的老师名字。
总结
这个查询之所以能实现"有多少位老师就有多少记录",是因为它利用了 Teaches 表作为中间桥梁。
【d题】
涉及表:instructor department
将instructor按dept_namegroupby,然后select的时候count一下id。这里要保证没有教师的系也要显示,因此外左联系,系做主表,教师做从表
【正解】
select D.name count(I.ID) AS faculty
from department D left outer join instructor I on D.dept_name=I.dept_name
group by D.dept_name
【4.7】☆☆☆☆☆

主键,主键非空,外域键约束
CREATE TABLE employee(
ID varchar2(5) PRIMARY KEY not null,
person_name varchar2(5) not null,
street varchar2(10),
city varchar2(10)
)
CREATE TABLE company(
company_name varchar2(5) PRIMARY KEY not null,
city varchar2(10),
)
CREATE TABlE manages(
ID varchar2(5) PRIMARY KEY not null,
manager_id varchar2(10)
FOREIGN KEY(ID) references employee(ID)
FOREIGN KEY(manager_id) references employee(ID)
)
CREATE TABLE works(
ID varchar(5) PRIMARY KEY not null,
company_name varchar2(5),
salary numeric(10,2),
FOREIGN KEY(company_name) references company(company_name)
FOREIGN KEY(ID) references employee(ID)
)
【4.10】★★☆☆☆
考点:COALESCE(a.name, b.name) 带ON的全外联与自然全外联的区别 合并拷贝表

使用 COALESCE(a.name, b.name) AS name 的意思是:
"请优先看
a.name,如果它不是 NULL ,就用它;如果它是NULL,那就退而求其次用b.name。"
| 语法 | 连接类型 | 连接条件指定方式 | 适用场景 |
|---|---|---|---|
| Natural Join | 内连接(默认)或外连接 | 自动匹配所有同名列 | 两表有完全同名的列,且需自动连接时 |
| ON | 所有连接类型(内、外、交叉) | 显式指定任意条件(不限于同名列) | 需灵活控制连接条件(如非同名列、复杂逻辑) |
| USING | 所有连接类型(内、外、交叉) | 显式指定同名列 | 两表有完全同名的列,需显式声明连接条件时 |
要理解自然全外连接(NATURAL FULL OUTER JOIN) 与带 ON 条件的全外连接(FULL OUTER JOIN ... ON) 的区别,需从连接条件的指定方式 、结果列的处理 、适用场景 等维度分析。结合你给出的关系 a(name, address, title) 和 b(name, address, salary),我们通过定义、语法、结果列、连接条件四个角度对比:
定义与连接条件
-
自然全外连接 :自动以两表所有同名属性 作为连接条件,匹配这些属性值相等的元组,同时保留两表中未匹配的元组。
对于
a和b,同名属性是name和address,因此连接条件是a.name = b.name AND a.address = b.address。语法:
a NATURAL FULL OUTER JOIN b(无需显式写条件,自动识别同名属性)。 -
带
ON的全外连接 :需显式指定连接条件 (可以是任意条件,不限于同名属性),匹配条件成立的元组,同时保留未匹配的元组。语法:
a FULL OUTER JOIN b ON (a.name = b.name AND a.address = b.address)(需手动写条件)。
结果列的处理
-
自然全外连接 :结果中同名属性只保留一份 (自动合并),无重复列。
例如:
a和b都有name和address,结果中只显示name、address各一列,再合并a.title和b.salary,最终列:name, address, title, salary。 -
带
ON的全外连接 :结果中同名属性会保留两份 (来自a和b各一列),需通过COALESCE等函数合并(否则会有a.name、b.name等重复列)。
空值处理与合并
-
自然全外连接 :自动处理同名属性的空值,合并后同名属性只有一列(本质是隐式合并)。
例如:若
a中某元组name为空,b中某元组name为空,自然连接会将这两个空值视为"匹配"(空值与空值相等?不,SQL 中NULL = NULL为UNKNOWN,但自然连接的实现通常会将空值视为可匹配,或通过数据库实现逻辑处理)。 -
带
ON的全外连接 :需手动合并同名属性 (如用COALESCE(a.name, b.name)),否则结果会有重复列。同时,空值的匹配逻辑由ON条件决定(如a.name = b.name中,NULL = NULL为UNKNOWN,但全外连接会保留未匹配行,因此空值行会被保留)。
【正解】
select coalesce(a.name, b.name) AS name, coalesce(a.address,b,address) AS address, title, salary
from a full outer join b on (a.name=b.name and a.address=b.address)
| 维度 | 自然全外连接 (NATURAL FULL OUTER JOIN) |
带 ON 的全外连接 (FULL OUTER JOIN ... ON) |
|---|---|---|
| 连接条件 | 自动以所有同名属性为条件 | 需显式指定条件(可任意) |
| 结果列 | 同名属性自动合并为1列 | 同名属性保留2列(需手动合并) |
| 空值处理 | 隐式合并,自动处理同名属性空值 | 需手动合并(如 COALESCE),空值匹配由 ON 条件决定 |
| 语法灵活性 | 依赖同名属性,结构变化需修改 | 灵活,可指定任意条件,但需手动处理重复列 |
【4.12】★☆☆☆☆
考点:权限追溯 权限依赖传递 权限归属权职绑定

核心作用是明确权限授予的"责任主体"与"上下文",尤其在涉及角色权限传递、审计追踪、权限隔离等场景中至关重要。是否包含该子句,取决于用户希望如何管理权限的"来源"与"可追溯性"。
在数据库权限体系中,权限可以由用户直接拥有 ,也可以通过角色继承获得。当一个用户(或角色)将权限授予另一个用户时,系统需要记录"是谁(或哪个角色)授出的权限",以便在权限回收、审计、角色失效时能精准追溯和控制。
为什么"应该"包含 GRANTED BY CURRENT ROLE?
当授权行为是通过角色完成时,包含该子句有以下关键价值:
-
权限来源可追溯
数据库系统(如 Oracle、PostgreSQL)会记录权限的"授予者"。若使用角色授权,
GRANTED BY CURRENT ROLE明确指出该权限是由当前激活的角色授出的,而非用户本身。这在审计日志、权限合规检查中至关重要。 -
支持角色权限的"传递性"与"隔离性"
如果一个角色 A 被授予了
SELECT权限,并通过GRANT ... GRANTED BY A授予用户 B,那么当角色 A 被撤销时,系统可以自动识别并处理通过 A 授出的权限(如级联撤销或标记为"孤儿权限"),避免权限"悬空"或滥用。 -
避免权限"污染"与"混淆"
若不指定
GRANTED BY,系统可能默认将权限归因于执行授权的"当前用户",而非其扮演的角色。这会导致权限归属混乱------例如,用户以角色 A 登录并授权,但权限却显示为"用户本人"授出,未来角色 A 被撤销时,该权限可能不会被自动清理,造成安全风险。 -
符合最小权限原则与职责分离
在企业级系统中,权限管理常遵循"角色驱动"模式。通过显式指定
GRANTED BY CURRENT ROLE,可以确保权限的授予行为与角色的职责绑定,避免用户以"个人身份"越权授出本应由角色管理的权限。
【4.13】
考点:权限依赖

【1题】★☆☆☆☆
不一定需要,v依赖于r,相对于视图只能是r的列子集,不需要看到全貌,比如管理系统表r有很多信息包括教师的工资,但教务处是不能看到工资的,这张对教务处的表格v就是引用自全表r的,那么让教务处查看v表,不需要让教务处拥有查看r表的权限。
【2题】★☆☆☆☆
需要,因为v是依赖于r的,修改v必然会引发对r的修改。
【3题】★☆☆☆☆
假设教务处录入新老师,新老师的年龄是33岁,但是视图v的筛选条件有where age<30,那么INSERT INTO v (id, name, age) VALUES (1, 'Wang', 33); 会显示插入成功,但是受限于视图条件,并不会被展示出来。