一、反压介绍
大数据实时计算依托流式处理引擎,对源源不断的流式数据进行低延迟处理,数据链路通常遵循"数据源→采集→实时管道→流式引擎计算→结果输出"的闭环。
反压(BackPressure)是指流式计算链路中,下游处理节点能力不足,导致数据无法及时消费,进而向上游节点传导阻塞信号,迫使上游节点降低数据发送速率,最终形成全链路限流、数据积压的现象,本质是分布式流处理的流量自适应保护机制,但失控的反压会直接引发生产故障。反压可以形象地类比为城市交通系统:当高速公路出口匝道拥堵时,车流会逐渐回堵至主路甚至更上游的入口。在实时计算中,这种"拥堵"会沿着数据流链路逆向传播,最终影响源头数据摄入。
反压问题常见场景如下:
| 场景类型 | 具体表现 |
|---|---|
| 负载高峰 | 短时流量陡增超出处理能力 |
| 资源瓶颈 | CPU/内存/网络资源不足 |
| 数据倾斜 | 个别SubTask处理数据量远超其他 |
| 外部系统阻塞 | 下游Sink写入慢或故障 |
| GC停顿 | JVM垃圾回收导致处理中断 |
轻度反压是引擎的正常自我保护,可避免节点过载崩溃;但重度、持续的反压会引发连锁故障:核心实时业务数据失效、数据积压后恢复耗时极长、作业重启失败、集群资源被占用导致其他任务受影响,直接影响线上业务稳定性,造成业务损失。因此,深入研究反压机制、做好提前防控与调优,是实时作业运维的核心工作。
二、主流大数据实时引擎的反压机制
1.Storm:基于ZooKeeper的全局反压
Storm作为早期主流的流式计算引擎,采用纯实时、逐条处理的架构,拓扑由Spout(数据源)和Bolt(计算算子)组成,上下游通过消息队列传递Tuple数据,其反压机制分为静态配置限流和动态反压两种模式。
Storm 1.0版本之前,无原生动态反压机制,仅支持手动配置静态参数限流,通过设置topology.max.spout.pending参数,限制Spout发送的未确认Tuple数量。当下游Bolt未确认的Tuple数超过阈值,Spout自动停止发送数据,实现被动限流。该方式依赖人工预估阈值,适配性极差,阈值过小导致吞吐不足,阈值过大无法防范反压。
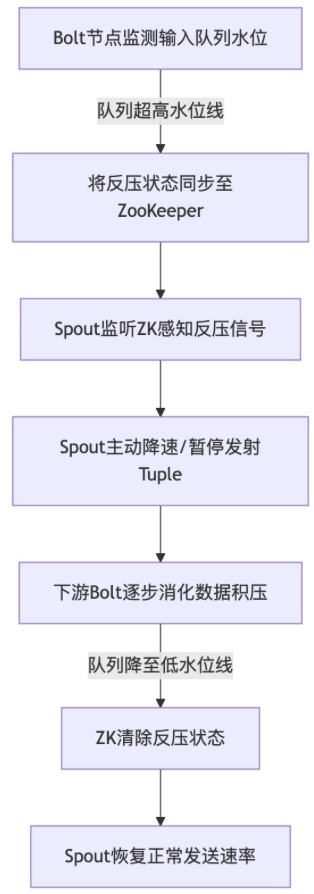
Storm 1.0引入了基于ZooKeeper的自动反压机制。
- 每个Bolt节点内置反压监测线程,实时监控自身输入队列的堆积长度,设定高低水位线阈值;
- 当Bolt输入队列超过高水位线,立即将反压状态写入ZooKeeper集群;
- Spout持续监听ZooKeeper中的反压状态,感知到阻塞信号后,主动降低发送速率甚至暂停发射Tuple;
- 当Bolt队列降至低水位线,反压状态解除,Spout恢复正常发送速率。
Storm2.0在1.0动态反压基础上,引入了WaitStrategyProgressive(渐进等待策略),实现一种动态、自适应的退避,旨在使反压发生时的数据流速调节更加平滑和自适应,以减轻系统震荡。
2.SparkStreaming:基于PID的动态速率调节
Spark Streaming采用微批处理架构,将流式数据切分为定时批次处理,其反压机制在Spark 1.5版本正式引入,基于PID控制器动态调整数据摄入速率,属于批次级限流反压。
在早期的1.5版本以前,仅支持手动配置静态限流参数,Receiver模式下通过spark.streaming.receiver.maxRate限制单接收器每秒摄入数据量,Direct模式下通过spark.streaming.kafka.maxRatePerPartition限制单分区消费速率,无法自适应流量波动,应对峰值流量极易触发反压。
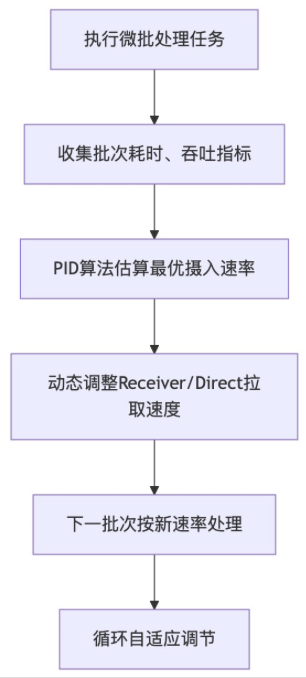
1.5版本引入的动态反压机制核心依托RateController速率控制器和PIDRateEstimator算法实现动态自适应反压:
- 开启参数spark.streaming.backpressure.enabled=true启用动态反压;
- 每个批次任务执行完成后,收集批次处理耗时、调度延迟、数据处理量、处理成功率等指标;
- PID控制器基于历史批次指标,估算下一批次最优的数据摄入速率;
- 将估算速率下发至数据源接收器,动态调整数据拉取速度,匹配集群处理能力;
- 批次处理能力恢复后,自动提升摄入速率,保障吞吐最大化。
3.Flink:基于Credit的动态流控
Flink采用流式持续处理架构,是当前实时计算的主流引擎,其反压机制历经两次迭代,1.5版本之前基于TCP流控+有界缓冲区实现,1.5版本之后引入基于Credit(信用值)的精细化反压机制,彻底解决了传统TCP流控的传导迟钝问题。
Flink1.5版本以前依托TCP协议滑动窗口和引擎内部有界缓冲区实现,下游算子缓冲区占满后,通过TCP滑动窗口阻塞上游网络传输,迫使上游停止发送数据。该机制依赖网络层流控,反压信号传导滞后,且无法精准定位阻塞算子,易出现全链路无差别阻塞的问题。
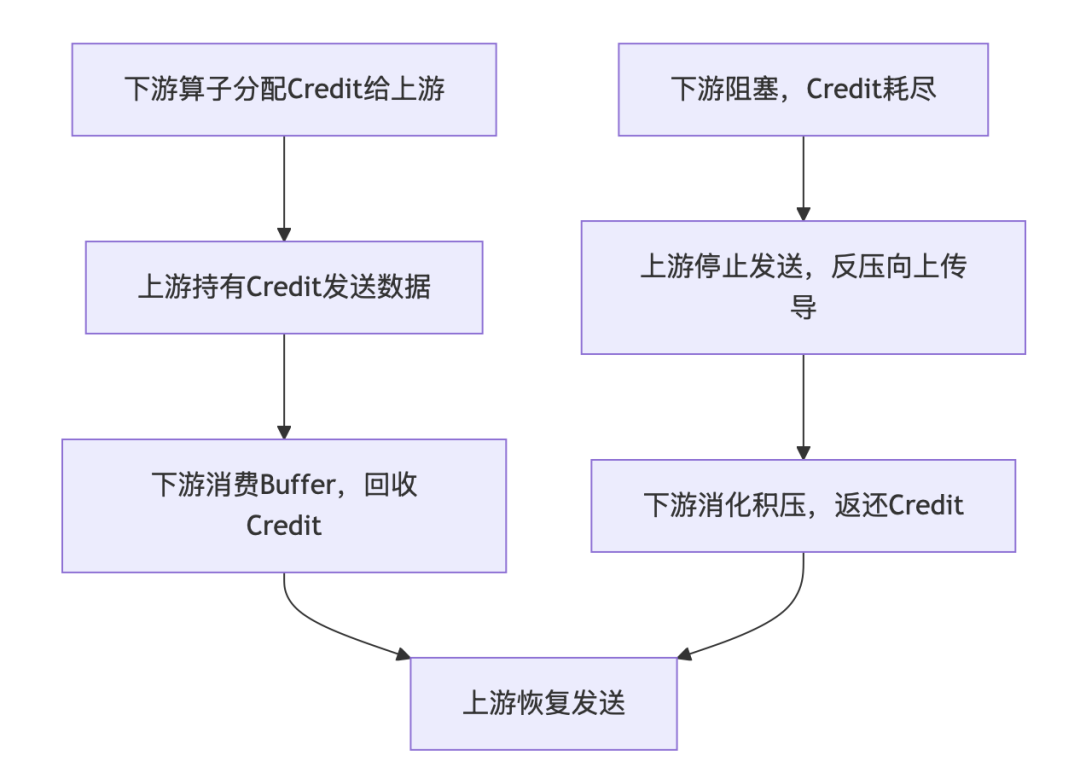
Flink1.5版本以后基于信用值做精细化流量管控,实现算子级精准反压,核心流程:
- 上下游算子之间通过InputChannel和ResultPartition传递数据,下游为每个InputChannel分配Credit(信用值),代表可接收的Buffer数量;
- 上游算子只有持有Credit,才能向对应下游发送数据,每发送一个Buffer,Credit减1;
- 下游算子消费完Buffer后,立即回收并向上游返还Credit,恢复上游发送权限;
- 若下游处理缓慢,InputChannel缓冲区占满,无可用Credit,上游算子彻底阻塞,停止发送数据,反压信号逐级向上传导至数据源;
- 下游消费完成后,Credit逐步释放,上游逐级恢复发送,实现平滑自适应。
4.三大引擎反压机制对比
| 维度 | Flink | SparkStreaming | Storm |
|---|---|---|---|
| 反压粒度 | 任务级(SubTask) | 接收器级(Receiver) | 拓扑级(全局) |
| 传播方式 | Credit反馈(直接) | PID速率调整(间接) | ZooKeeper通知 |
| 响应延迟 | 毫秒级 | 批次间隔级(秒级) | 秒级 |
| 资源开销 | 低(控制消息轻量) | 中(PID计算开销) | 高(ZK读写+全局通知) |
| 准确性 | 精确流控 | 基于历史估算 | 阈值触发 |
| 调优复杂度 | 中 | 中(PID参数) | 高(水位线+比例) |
反压机制作为实时流处理系统的核心能力,其演进路径清晰可见:
- 从粗糙到精细:从Storm的全局限流到Flink的任务级Credit流控
- 从被动到主动:从静态参数限流到动态自适应调节
- 从单一到协同:从独立反压到与资源调度、弹性伸缩联动
Flink的Credit-Based机制代表当前业界最高水平,实现了精确、低延迟、任务级隔离的反压处理。
三、总结展望
反压是大数据实时计算场景中不可避免的流量自适应现象,轻度反压可保护集群稳定,重度反压则会引发严重生产故障。三大主流实时引擎中,Storm反压机制简单但响应滞后,Spark Streaming适配准实时场景但调节延迟高,Flink基于Credit的精细化反压机制,凭借灵敏传导、精准限流的优势,成为当前高吞吐低延迟场景的最优解。
当遇到反压问题时,我们要及时识别反压点,分析反压根源,并进行针对性优化。解决反压问题不能只依赖引擎自带的反压机制,更要做好监控预警、提前压测、瓶颈排查、应急处理的全流程管控,从根源上规避重度反压,保障实时作业长效稳定运行。