一、JVM内存区域划分
核心区域:
1.程序计数器:很小的区域,只是用来记录当前指令执行到哪个地址了
2.元数据区: 保存当前类被加载好的数据(放类对象)
元信息:指的是一些属性,比如类名,继承自哪些类,实现了哪些接口,方法名,参数有几个,参数类型和方法的返回值等
3.栈:保存方法的调用关系
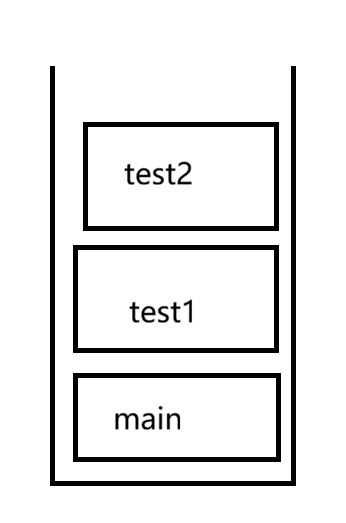
栈的空间不大,一般也就几MB或几十MB这样,所谓的栈溢出就是递归逻辑出现问题,导致栈的空间不够用
4.堆:保存 new 的对象
Test t = new Test();
new Test();这部分是在堆上的
如果t是一个局部变量,t就在栈上;
如果t是一个成员变量,t就在堆上;
如果t是一个静态成员变量,t就在元数据区;
堆是JVM最大的空间区域了,因此当堆上的对象不再使用了,就需要释放它(垃圾回收机制)
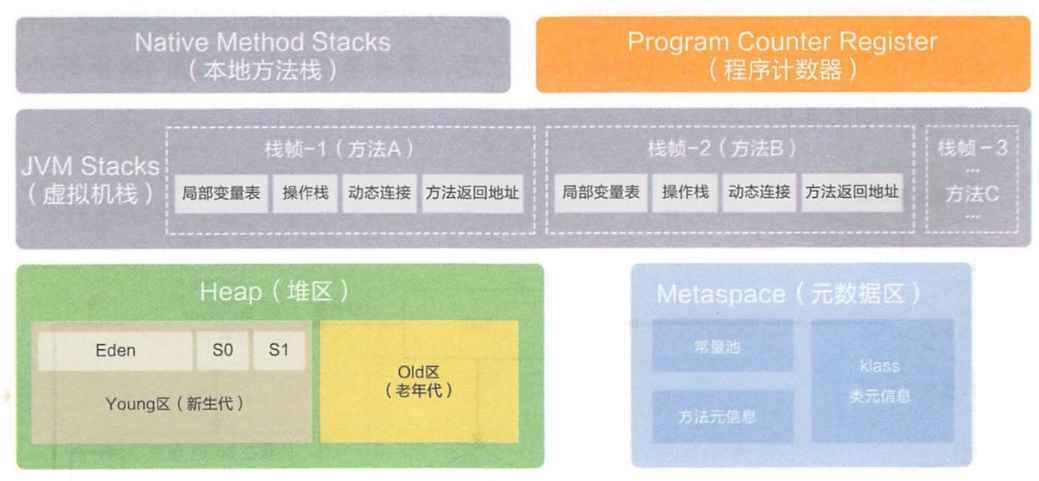
元数据区和堆,整个java进程共用一份
程序计数器和栈可能有多份,因为可能存在多个线程
二、JVM类加载
类加载的步骤
1.加载:找到 .class文件,找到类的全限定名(例如java.long.String),打开文件,读取文件到内存里
2.验证:解析,校验 .class文件读到的内容是否是合法的,并且把这里的内容转成结构化的数据,这里的格式必须符合《Java虚拟机规范》的全部约束要求
3.准备:给类对象申请内存空间,内存空间为0
4.解析:针对字符串常量进行初始化,字符串常量本身包含在 .class文件中,把从该文件中解析出来的字符串常量放到内存空间里(元数据区,常量池中)
5.初始化:对类对象进行初始化,针对类对象的各种属性进行填充,包括类中的静态成员,如果这个类还有父类,且父类未加载,则父类也会执行上述过程
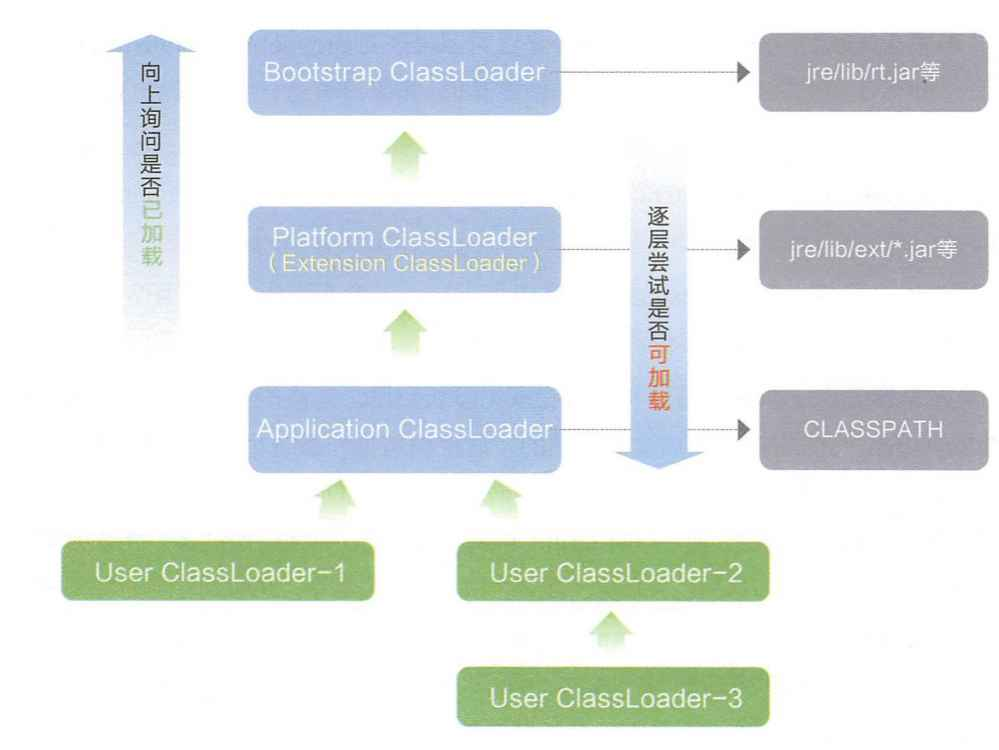
双亲委派模型
首先要理解一些概念:
该模型描述了类加载中,根据全限定类名,找到**.class**文件的过程
类加载器:JVM中有专门的模块,负责类加载
JVM默认提供了三种类加载器:BootStrapClassLoader、ExtensionClassLoader、ApplicationClassLoader,这三个加载器通过后者可以通过parent引用指向前者,并且这三个加载器负责找的目录的范围是不同的
BootStrapClassLoader在Java的标准库目录找
ExtensionClassLoader在Java的扩展库目录找
ApplicationClassLoader在Java的第三方库,以及当前项目所在目录的类
过程
首先,会把ApplicationClassLoader作为入口,然后把 加载类 的过程委托给它的"父亲"
ExtensionClassLoader 来执行,它也不会立即执行,会把任务委托给BootStrapClassLoader,
BootStrapClassLoader由于没有"父亲",只能自己进行类加载,在标准库范围内找 .class文件,
如果没找到,把任务还给孩子ExtensionClassLoader, 如果它也没找到**,**就把任务还给孩子
ApplicationClassLoader,最后,如果找到就加载,没找到就抛出异常
三、垃圾回收(GC)
Java中释放内存的手段。手动释放内存太麻烦,引入垃圾回收,进行自动释放,JVM会自动识别出某个内存后续是不是不再使用了,然后自动释放
GC回收的是JVM中堆内存区域,本质上是回收"对象"
工作过程
1.找到垃圾(不再使用的对象)
1)引用计数(Python,PHP采用了这个方案)
每个对象在 new 的时候,都搭配一个小的内存空间来记录一个整数
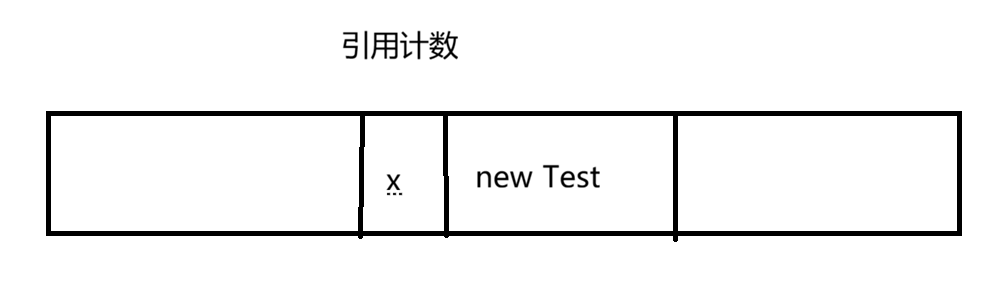
这个整数就表示当前对象有多少个整数指向它,例如:
Test t = new Test();此时x的值为1
Test t2 = new Test(); 此时 x的值为2
Test t3 = t2; 此时 x的值为3
t = null;此时x 的值为2
在Java中,要想使用某个对象,一定是通过某个引用实现的。当 x 为0 时,表示没有引用指向这个对象,那这个对象就是"垃圾"
缺点:
1.内存消耗的更多
2.可能会出现"循环引用"问题
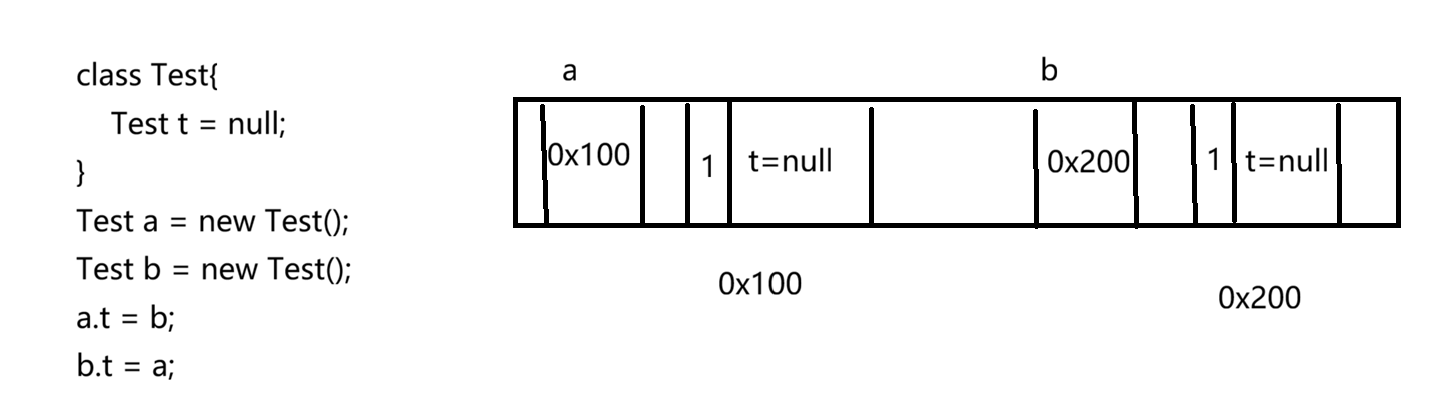
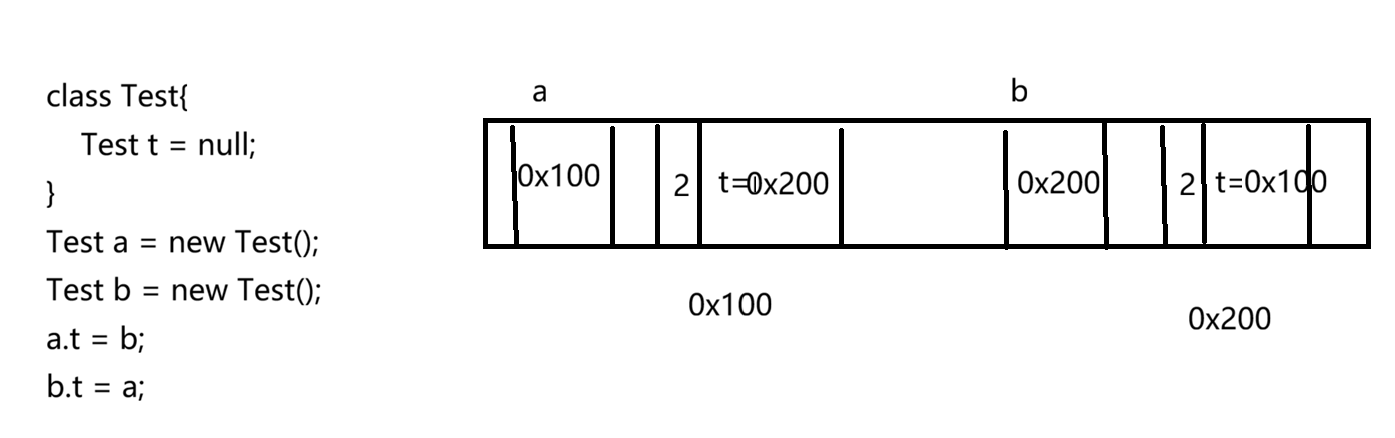
用这个代码简单模拟循环引用,开始执行a.t = b 和b.t = a
此时加入a = null;和 b = null;
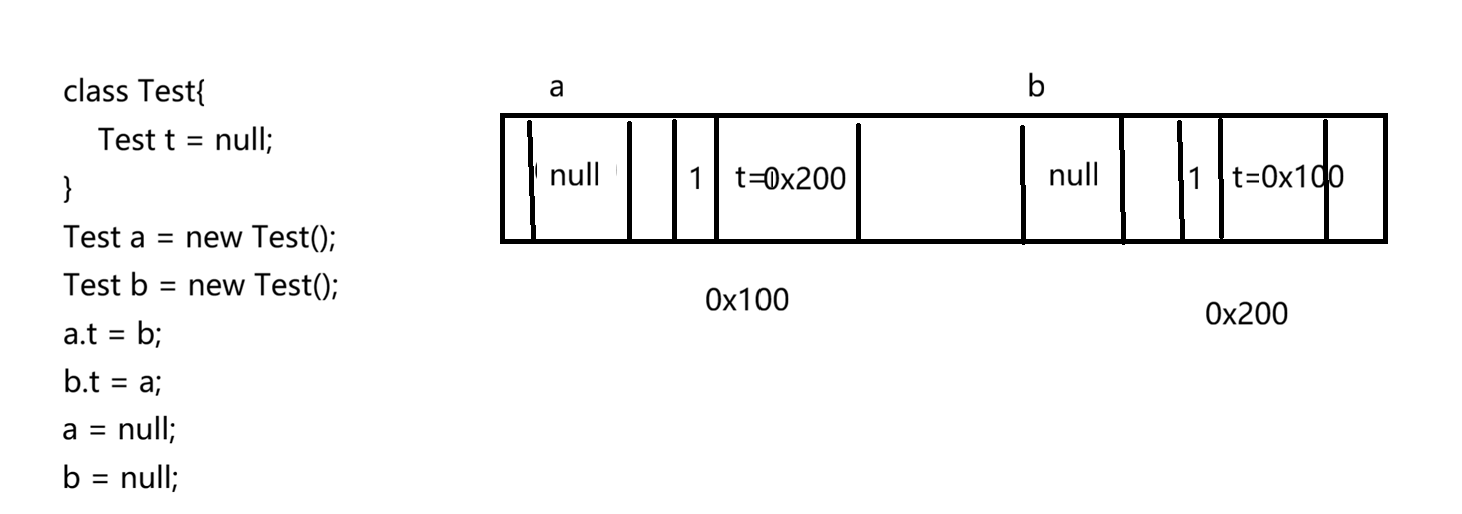
此时,引用计数都不为0,但是两个对象都无法使用,要使用第一个对象就得用第二个对象里的t来访问,要使用第二个对象里的t属性又得用第一个对象里的t属性来访问。因此Java并没有采用这个方案。
2)可达性分析(Java)
1.以代码中的一些特定对象,作为遍历的"起点" (GCRoots)
2.尽可能的进行遍历,判断某个对象是否能访问到
3.每次访问到一个对象,都会把这个对象标记成"可达",当完成所有的对象遍历之后,未被标记成"可达"的对象就会被释放,因为JVM本身是知道有多少个对象的
可达性分析具有周期性,每隔一段时间进行一次这样的遍历,因此当对象特别多的时候就比较消耗时间和内存,因此C++并没有采用这种方案
2.释放垃圾
1.标记清除
把垃圾对象的内存直接释放。但是这样做可能会产生内存碎片问题,举个例子:
假如有8个对象
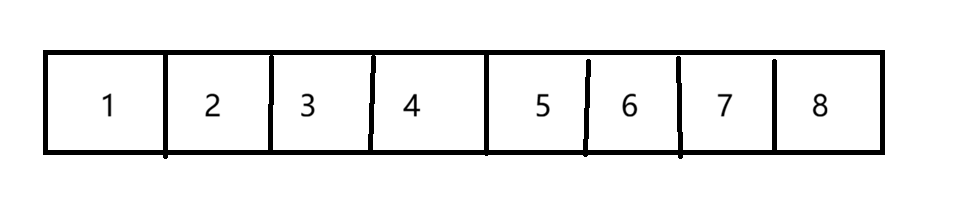
现在要清除2、4、6、8四个对象
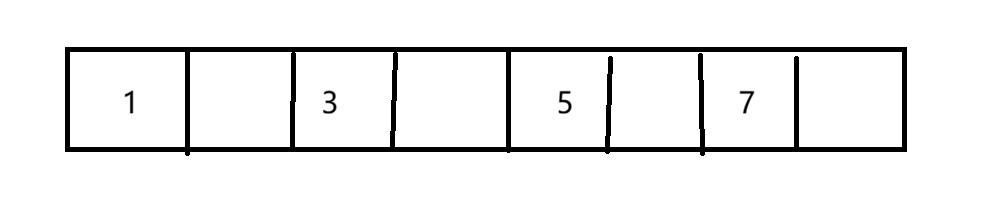
看似多出了四个空间,但这样的空间是不连续的。要知道,申请内存都是申请的连续的内存,所以会造成一种现象,有足够的内存但是申请失败
2.复制算法
一次只使用一半,在清除垃圾前,把不是垃圾的对象拷贝到右边,然后把左边清除
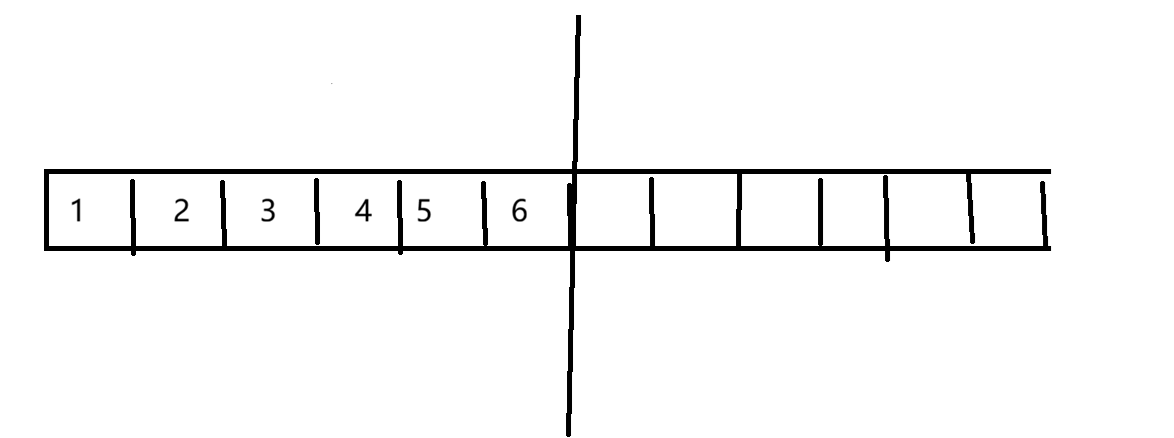
假如删除2、4、6。先把1、3、5拷贝到右边,然后把左边整体清除
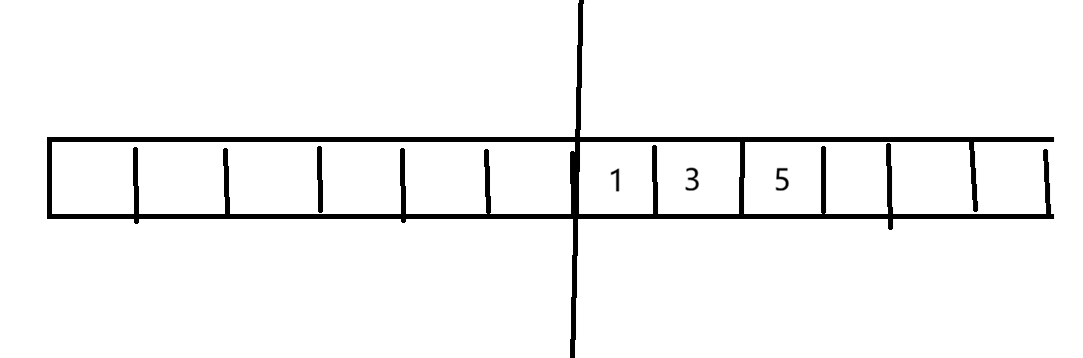
然后申请内存的时候从5后面开始申请即可
缺点:
1.内存利用率很低,
2.当复制对象较多时,成本会很高,尤其是当出现较大对象时
3.标记-整理

假如说删除2、4、6,那么就会把3、5、7迁移
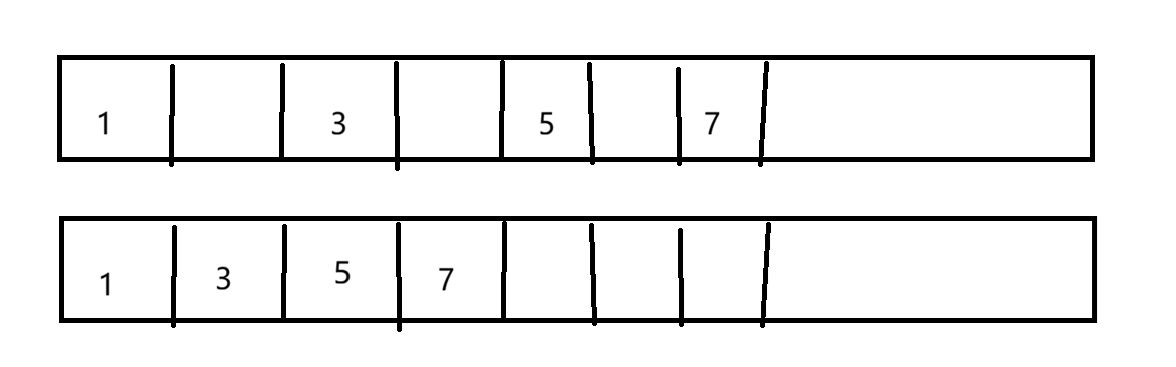
缺点:当复制的对象较多时,成本问题与依旧存在
分代回收
相当于把释放垃圾的三个方法结合起来
这里的代 指的是GC的轮次,即对象每进行一次可达性分析之后,年龄就+1,然后把内存进行划分
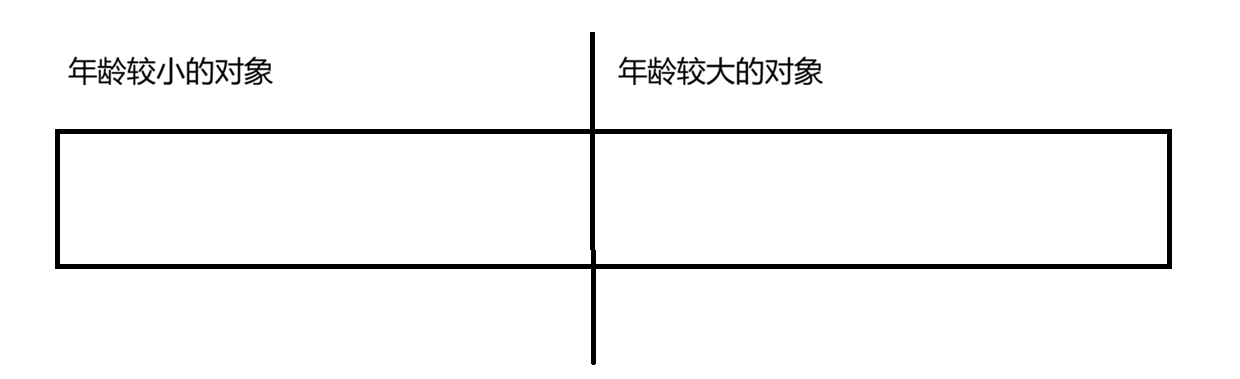
对于年龄较大的对象,GC的频率就可以降低了
对于年龄较小的对象,GC的频率一般较高
然后对年龄较小的对象内存进一步进行划分:分出伊甸区和幸存区
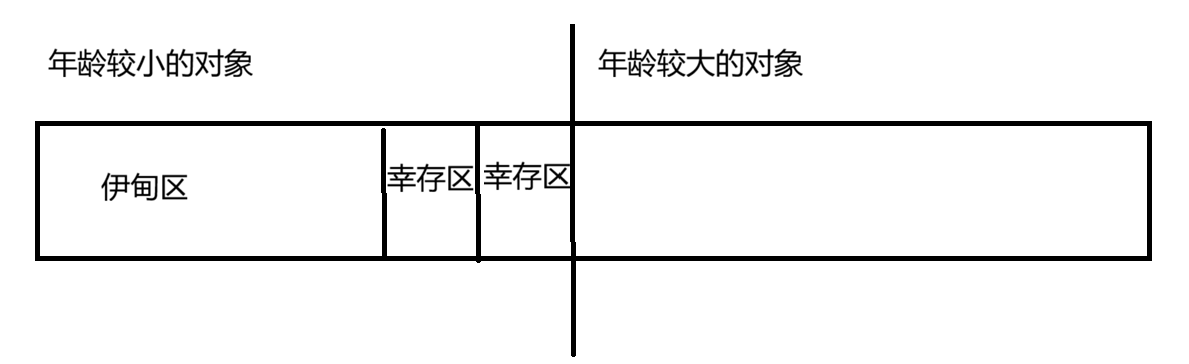
把新创建的对象放在伊甸区,如果新对象经过一轮GC活下来了,就通过复制放到幸存区,然后伊甸区再进行释放,此时复制的对象是比较少的
幸存区的对象也要进行GC,大部分的对象会被消灭,剩下的对象会复制到另一个幸存区
如果幸存区的对象经过多次GC还没有被清除,就会被复制到年龄大的区域
这个方案总体减少了复制的成本
对于年龄较大区域的标准,一般是15(以实际为准),对于比较大的对象,一般直接就进入老年区