一. 为什么需要智能指针
在 C++ 开发中,内存管理始终是一把双刃剑。与具备垃圾回收机制的语言(如 Java 或 Python)相比,C++ 让开发者能够直接掌控内存分配,这种特性既带来了无与伦比的性能优势,也潜藏着诸多隐患
传统指针的局限
在传统的 C++ 编程中,我们习惯于使用 new 在堆上分配内存,并用 delete 进行释放。然而,这种人工管理内存的方式在复杂逻辑场景中存在明显缺陷,主要表现在三个方面:
-
内存泄漏: 最常见的情况。开发者在申请内存后,因为逻辑分支过多(如 if-else 提前返回)或者逻辑过于复杂,导致 delete 语句被执行。随着程序运行时间的增长,内存被逐渐耗尽
-
野指针与重复释放: 当一个指针被 delete 后,如果没有及时置为 nullptr,它就变成了野指针。如果再次尝试访问或第二次执行 delete,程序会立即崩溃
-
**异常安全:**这是最隐蔽的风险。即便你在函数末尾写了 delete,但如果函数中间的代码抛出了异常,执行流会直接跳过释放逻辑,导致内存泄漏
我们可以把内存管理想象成在一个房间里工作:new 是开灯,delete 是关灯 。 在小程序里,谁开灯谁关灯很简单;但在大型项目中,对象往往在多个模块间传递,"所有权" 变得极其模糊
是由创建对象的函数负责销毁?还是由接收对象的容器负责销毁?
如果规则不明确,就会出现没人关灯或者多个人抢着关灯的情况

为了解决这些痛点,C++ 引入了智能指针(Smart Pointers) 。它的核心逻辑非常朴素:利用对象的生命周期来管理资源
通过将原始指针封装在一个对象中,当这个对象的生命周期结束(例如离开局部作用域)时,由它的析构函数自动调用 delete。这种资源的自动化管理机制有效解除了开发者手动管理内存的负担
二. RAII 思想与智能指针
提到智能指针,就绕不开一个核心概念:RAII(Resource Acquisition Is Initialization,资源获取即初始化)
这个名字听起来有些绕口,但它的核心逻辑非常直接:将资源的生命周期与对象的生命周期绑定
1. 核心本质
RAII 的本质是利用 C++ 的局部对象自动销毁机制。 在 C++ 中,当一个局部对象离开作用域时,它的析构函数(Destructor)会被强制调用。RAII 正是抓住了这一点:
-
获取资源: 在构造函数中申请资源(如内存、文件句柄、锁等)
-
管理资源: 在对象的整个生命周期内持有资源
-
释放资源: 在析构函数中自动释放资源
为什么 RAII 是安全的
我们可以通过一个简单的对比来看出 RAII 的威力:
-
**传统方式:**需要手动调用 close() 或 delete。如果中间代码抛出异常,释放语句会被跳过,导致资源泄漏
-
RAII 方式: 无论函数是因为执行完毕返回,还是因为抛出异常而提前退出,系统都会进行栈解退,自动调用局部对象的析构函数
对象销毁时必然释放资源,这种确定性机制构成了 C++ 异常安全的核心保障
2. 代码实现
智能指针其实就是 RAII 思想在内存管理上的具体实现
为了让一个管理资源的类用起来像一个指针,它必须在满足 RAII 的基础上,实现以下特质:
-
内部持有一个 T* ptr
-
为了便于像迭代器或原生指针那样访问元素,智能指针类通常会重载 (*) (->) 和 \[\]等运算符
cpp
template<class T>
class SmartPtr
{
public:
SmartPtr(T* ptr) : _ptr(ptr) {} // 获取资源
~SmartPtr() { delete _ptr; } // 释放资源
// 重载运算符使其具备指针的能力
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
T& operator[](size_t i) { return _ptr[i]; }
private:
T* _ptr;
};通过这种设计,我们既享受了原生指针的便利,又获得了自动管理内存的安全性
3. 标准库智能指针概览
在现代 C++ 中,所有的智能指针都定义在 <memory> 头文件中。虽然它们都遵循 RAII 思想,但它们在拷贝语义和所有权管理上有着本质的区别
我们可以将标准库中的四种主要智能指针简单归纳如下:
| 智能指针 | 诞生标准 | 核心特性 | 现状建议 |
|---|---|---|---|
| auto_ptr | C++98 | 拷贝即转移所有权 | 弃用 / 禁止使用 |
| unique_ptr | C++11 | 独占所有权,不可拷贝 | 首选(最轻量) |
| shared_ptr | C++11 | 共享所有权,引用计数 | 共享场景使用 |
| weak_ptr | C++11 | 观察者,不增加引用计数 | 配合 shared_ptr |
核心特性与设计细节
除了基本的功能外,现代 C++ 智能指针在设计上考虑了极高的安全性和灵活性:
1. 防御性设计:explicit
unique_ptr 和 shared_ptr 的构造函数都使用了 explicit 关键字修饰
防止将一个原始指针隐式转换为智能指针,避免因临时对象的产生而导致意外的资源释放
cpp
shared_ptr<int> p = new int(10); // 编译报错,必须显式构造。2. 类型转换:operator bool
为了像原生指针一样方便,它们都重载了 operator bool。这意味着你可以直接写 if (ptr) 来判断指针是否指向有效资源
3. 数组支持与定制化释放
默认情况下,智能指针在析构时调用 delete。但如果管理的资源是数组(需要 delete\[\])或者非内存资源(如文件 fclose),该怎么办?
-
定制删除器: 你可以在构造时传入一个可调用对象(函数、Lambda 等)作为删除器
-
数组特化: 现代 C++ 提供了 unique_ptr<T\[\]> 和 shared_ptr<T\[\]> 的特化版本,内部会自动处理 delete\[\]
4. 更优雅的构造:make_shared
除了使用原生指针构造,标准库推荐使用 std::make_shared。它能一次性分配控制块和对象本身的内存,效率更高且具备更强的异常安全性
三. auto_ptr 与 unique_ptr
既然已存在 auto_ptr,为何 C++11 还要引入 unique_ptr?关键在于两者底层的拷贝机制存在本质差异
1. auto_ptr
模拟实现
cpp
template<class T>
class my_auto_ptr {
public:
my_auto_ptr(T* ptr) : _ptr(ptr) {}
my_auto_ptr(my_auto_ptr<T>& ap) {
_ptr = ap._ptr;
ap._ptr = nullptr; // 被拷贝者置空
}
my_auto_ptr<T>& operator=(my_auto_ptr<T>& ap) {
if(this != &ap) {
delete _ptr;
_ptr = ap._ptr;
ap._ptr = nullptr;
}
return *this;
}
~my_auto_ptr() { if(_ptr) delete _ptr; }
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
private:
T* _ptr;
};为什么禁止使用 auto_ptr
该设计本意虽好,但在拷贝处理上存在严重缺陷:将 ap1 赋值给 ap2 时,ap1 会被变为空指针。这种极具破坏性的副作用完全违背了开发者对赋值操作的常规认知,若在 STL 容器中使用更是后患无穷
cpp
std::auto_ptr<int> ap1(new int(10));
// 看起来是拷贝,实际上是所有权转移
std::auto_ptr<int> ap2 = ap1;
// 此时 ap1 已经变成了 nullptr
if (ap1.get() == nullptr) {
std::cout << "ap1 变成空指针了" << std::endl;
}
// 如果后面解引用 ap1,程序直接崩溃
// *ap1 = 20; 建议将老代码中的 auto_ptr 重构为 unique_ptr,因为它不仅支持移动语义,还更加安全且语义明确
2. unique_ptr
unique_ptr 的设计理念直截了当:既然拷贝操作可能引发不可预知的后果,那就直接禁止拷贝行为
模拟实现
cpp
template<class T>
class my_unique_ptr {
public:
explicit my_unique_ptr(T* ptr) : _ptr(ptr) {}
~my_unique_ptr() { if(_ptr) delete _ptr; }
// 禁止拷贝构造和赋值
my_unique_ptr(const my_unique_ptr<T>& up) = delete;
my_unique_ptr<T>& operator=(const my_unique_ptr<T>& up) = delete;
// 支持移动语义:明确告诉用户,资源在转移
my_unique_ptr(my_unique_ptr<T>&& up) noexcept : _ptr(up._ptr) {
up._ptr = nullptr;
}
my_unique_ptr<T>& operator=(my_unique_ptr<T>&& up) noexcept {
if (this != &up) {
delete _ptr;
_ptr = up._ptr;
up._ptr = nullptr;
}
return *this;
}
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
private:
T* _ptr;
};为什么它是更好的设计?
-
**编译期拦截:**如果你尝试 p2 = p1,编译器会直接报错
-
显式转移: 如果你确实想转移所有权,必须通过调用 std::move(p1) 明确表示转移意图
-
零成本: 它的性能和原始指针几乎完全一致,没有任何多余的内存开销
四. shared_ptr 的设计与实现
shared_ptr 解决了多个对象共同拥有同一个资源的问题。它的核心逻辑是:只要还有一个 shared_ptr 指向该资源,资源就不会被释放
使用 shared_ptr 非常直观。可以通过 use_count() 随时查看当前有多少个观察者在共享这个资源
cpp
void test() {
// 推荐使用 make_shared,更安全且效率更高
shared_ptr<int> sp1 = std::make_shared<int>(100);
{
shared_ptr<int> sp2 = sp1; // 拷贝:引用计数 +1
cout << "Count: " << sp1.use_count() << endl; // 输出 2
} // sp2 离开作用域:引用计数 -1
cout << "Count: " << sp1.use_count() << endl; // 输出 1
} // sp1 离开作用域:引用计数减为 0,释放内存1. 引用计数
在设计智能指针时,我们面临一个核心挑战:如何让指向同一块内存的多个指针对象,共享同一个计数状态
为什么不能使用静态成员?
假设我们给 shared_ptr<T> 定义了一个 static int _count:
-
创建 sp1 指向资源 A 时,_count 变为 1
-
创建 sp2 指向资源 B(另一个完全不同的资源)时,_count 变成了 2
这样就产生了问题:原本应该独立计数的资源 A 和资源 B,现在却被错误地共享了同一个计数器
堆上动态开辟
为了实现一份资源对应一个计数器,我们需要在构造第一个管理某份资源的智能指针时,在堆上 new 出一个计数器
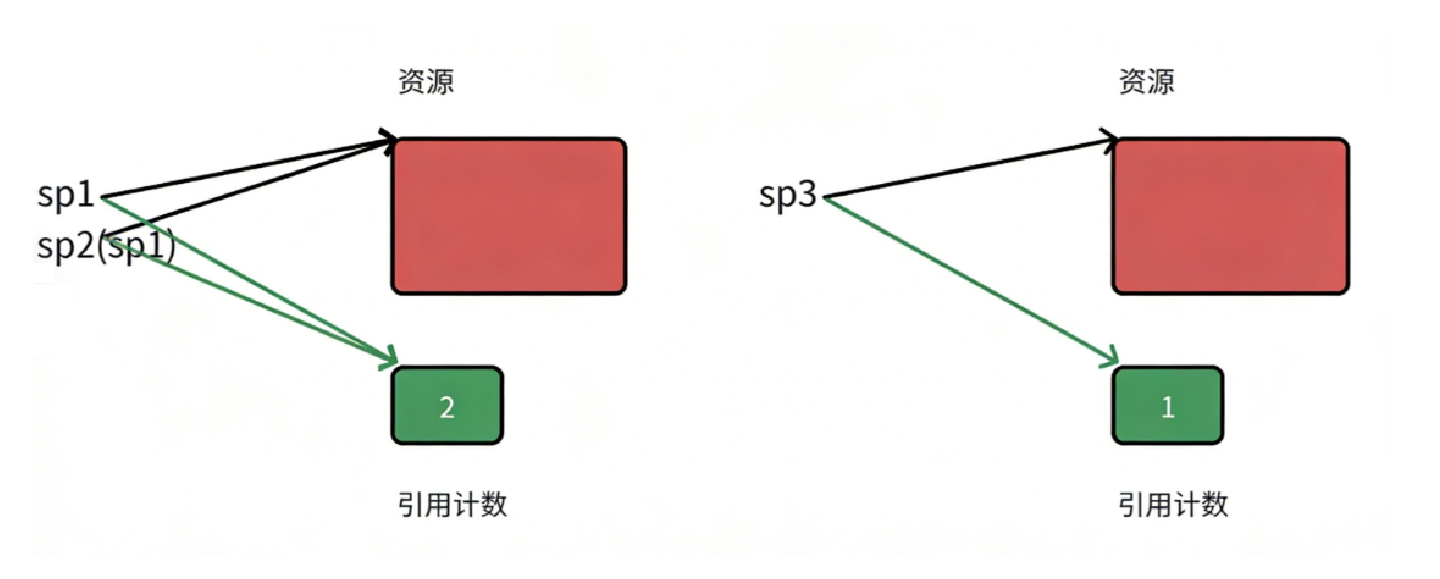
**核心逻辑:**智能指针内部不存储 int,而是存储一个 int* _pCount。 当发生拷贝时,副本指针直接指向同一个堆上的 int* 地址。这样,所有管理同一份资源的指针,看到的都是同一个计数器
2. 模拟实现 shared_ptr
基于堆上开辟计数器的思想,我们的模拟实现需要处理好构造、拷贝、赋值、析构这四个关键环节
cpp
template<class T>
class shared_ptr {
public:
explicit shared_ptr(T* ptr = nullptr)
: _ptr(ptr), _pCount(new int(1)) // 为这块资源开辟计数器
{}
template<class Del>
shared_ptr(T* ptr, Del del)
: _ptr(ptr), _pCount(new int(1)), _del(del)
{}
shared_ptr(const shared_ptr<T>& sp)
: _ptr(sp._ptr), _pCount(sp._pCount), _del(sp._del)
{
++(*_pCount); // 计数器加一
}
shared_ptr<T>& operator=(shared_ptr<T>& sp)
{
if(_ptr != sp._ptr)
{
// 先释放自己的资源
release();
// 再接管新的对象
_ptr = sp._ptr;
_pCount = sp._pCount;
++(*_pCount);
_del = sp._del;
}
return *this;
}
~shared_ptr() { release(); }
int use_count() const { return *_pCount; }
T& operator*() { return *_ptr; }
T* operator->() { return _ptr; }
T* get() const { return _ptr; }
private:
void release()
{
// 如果引用计数减到 0, 说明已经是最后一个管理者
if(--(*_pCount) == 0)
{
_del(_ptr);
delete _pCount;
_ptr = _pCount = nullptr;
}
}
T* _ptr; // 只想资源的指针
int* _pCount; // 指向堆上的引用计数
// 定制删除器
function<void(T*)> _del = [](T* ptr){ delete ptr; };
};实现细节:
-
**独立性:**每一组管理相同资源的 shared_ptr 都有自己独立的堆内存计数器
-
释放: 在 release() 函数中,我们不仅要 delete _ptr(释放资源),还要 delete _pCount。否则计数器本身会造成内存泄漏
-
赋值重载: 必须先调用 release() 尝试释放旧资源,再进行新资源的接管。这是为了保证逻辑的严密性
3. 线程安全问题
关于 shared_ptr 的线程安全,我们要拆开来看:
-
引用计数的安全性: 它是线程安全的。 标准库中的 shared_ptr 引用计数是通过原子操作(Atomic Operations)实现的。即使在多线程环境下同时拷贝或销毁对象,计数器的增减也是准确的,不会导致多次释放
-
资源本身的安全性: 它不是线程安全的。 智能指针管理的是资源的生命周期,但不保证资源内容的操作安全。如果两个线程同时通过 shared_ptr 修改它指向的对象,你依然需要加锁(如 std::mutex)
-
智能指针对象本身的安全性: 如果两个线程同时对同一个智能指针对象进行读写(比如一个线程让它指向 A,另一个线程让它指向 B),这同样是不安全的,需要额外的同步机制
为什么推荐使用 make_shared
在实际开发中,我们有两种方式创建一个 shared_ptr:
直接构造:
cpp
std::shared_ptr<MyClass> sp(new MyClass());工厂函数:
cpp
auto sp = std::make_shared<MyClass>();虽然结果看起来一样,但在底层内存的视角下两者有着巨大的差异
1. 内存分配次数
这是最直观的性能差异。
-
直接构造: 需要进行两次独立的堆内存分配。
-
第一次:new MyClass() 在堆上分配对象的内存
-
第二次:shared_ptr 的构造函数会在堆上分配引用计数的内存
-
-
使用 make_shared: 只需进行一次堆内存分配
- 标准库会申请一块足够大的内存,同时存放 MyClass 对象和引用计数
堆分配是昂贵的系统调用。减少一次分配意味着减少了与操作系统的交互,在高频创建对象的场景下,性能提升非常明显
2. 内存局部性
由于 make_shared 将对象和控制块分配在连续的内存空间 中,这带来了更好的缓存命中率
当 CPU 访问对象时,由于引用计数就在它旁边,这部分数据很可能已经被一起加载到了 L1 / L2 缓存中。而 new 出来的版本,对象和控制块可能散落在堆内存的不同角落,增加了 CPU 缓存失效(Cache Miss)的概率
3. 异常安全性
这是一个非常隐蔽的逻辑陷阱。考虑下面这段代码
cpp
// 假设函数原型为:void process(std::shared_ptr<T> p, int priority);
process(std::shared_ptr<MyClass>(new MyClass()), get_priority());在 C++17 之前,编译器对参数的求值顺序有很大的自由度。可能会出现这种顺序:
-
执行 new MyClass()
-
调用 get_priority()
-
构造 shared_ptr
如果第 2 步 get_priority() 抛出了异常,此时 MyClass 已经分配了内存,但 shared_ptr 还没来得及接管它。结果就是:这块内存永远无法被释放,造成内存泄漏
而 std::make_shared 是一个原子化的操作,它要么成功返回智能指针,要么抛出异常且不分配任何内存,天然地规避了这个问题
五. weak_ptr 与 循环引用问题
shared_ptr 通常是管理资源的最佳方案,它完美结合了 RAII 机制和拷贝语义。然而在涉及双向引用的特殊场景中,这种智能指针会陷入循环引用的困境,导致资源无法被正确释放
1. 什么是循环引用
想象一个双向链表的节点结构:
cpp
struct ListNode {
int _data;
std::shared_ptr<ListNode> _prev;
std::shared_ptr<ListNode> _next;
~ListNode() { std::cout << "~ListNode()" << std::endl; }
};
void test() {
std::shared_ptr<ListNode> n1(new ListNode);
std::shared_ptr<ListNode> n2(new ListNode);
// 形成循环引用
n1->_next = n2;
n2->_prev = n1;
// 函数结束前,n1 和 n2 的引用计数均为 2
}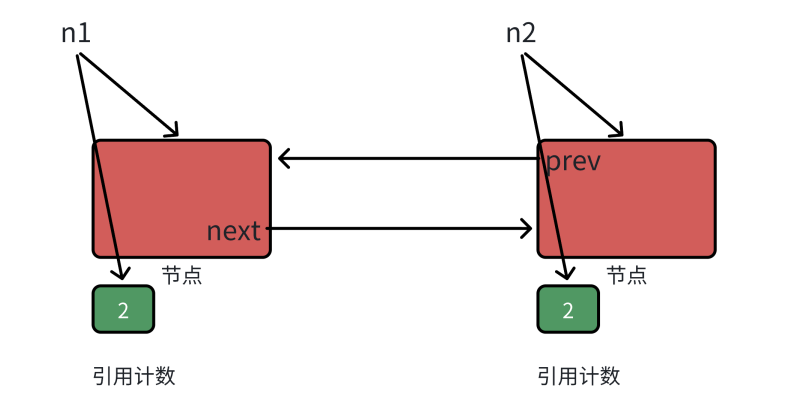
当函数结束,局部变量 n1 和 n2 析构后,堆上的两个节点的引用计数减到了 1。此时,资源的释放逻辑陷入了一个回旋镖式的循环:
-
右边节点(n2)何时释放? 它由左边节点中的成员 _next 管着,只有当 _next 析构时,右边节点才会释放
-
**_next 何时析构?**它是左边节点的成员,只有当左边节点释放时,它的成员 _next 才会析构
-
左边节点(n1)何时释放? 它由右边节点中的成员 _prev 管着,只有当 _prev 析构时,左边节点才会释放
-
**_prev 何时析构?**它是右边节点的成员,只有当右边节点释放时,它的成员 _prev 才会析构
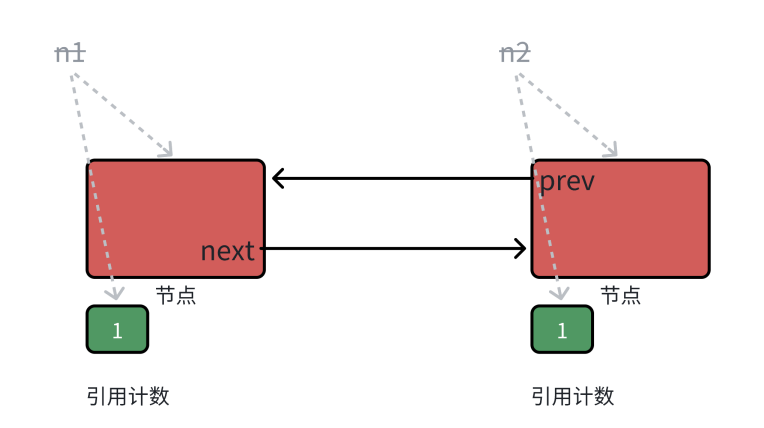
结论: 左等右释放,右等左释放。最终谁都不会释放,逻辑上形成了一个死闭环,导致内存泄漏
2. weak_ptr 的设计
为了修复这个逻辑漏洞,C++11 引入了 weak_ptr。它的定位非常特殊:它不具备 RAII 属性,不参与资源的管理,仅仅是一个旁观者
核心思想:
-
引用计数: 将 weak_ptr 绑定到 shared_ptr 时,它不会增加资源的 use_count
-
**无法直接访问:**它没有重载 * 和 ->。因为它不保证资源一定存在,直接访问极其危险
-
安全提升: 如果想使用资源,必须通过 lock() 方法申请。如果资源还在,它会返回一个临时的 shared_ptr;如果已过期,则返回空
模拟实现
cpp
template<class T>
class weak_ptr
{
public:
weak_ptr()
{}
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get())
{}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
// 这里的 lock 等功能在模拟实现中很难做到
// 想要实现就要把 shared_ptr 和 weak_ptr 一起改
// 把引用计数拿出来放到一个单独类型
// shared_ptr 和 weak_ptr 都要存储指向这个类的对象才能实现
private:
T * _ptr = nullptr;
};现在,我们只需将 ListNode 中的成员改为 weak_ptr 即可解决问题:
cpp
struct ListNode {
std::weak_ptr<ListNode> _prev; // 弱引用,不增加计数
std::weak_ptr<ListNode> _next; // 弱引用,不增加计数
};当 test 函数结束时,局部变量 n1 析构,其计数从 1 直接降为 0(因为 n2->_prev 是弱引用,不计入),资源顺利释放。随后 n2 也会因为失去引用而正常销毁。回旋镖被折断了
弱引用的使用
很多读者会问,既然 weak_ptr 解决了循环引用,那它连 -> 运算符都没有,我该怎么操作链表呢?
关键在于 weak_ptr 提供的 lock() 接口。当你需要访问资源时,通过 lock() 申请一个临时的 shared_ptr。如果资源还没被销毁,这个临时的强引用就能保证你在操作期间资源是绝对安全的
在实际工程(比如实现一个真正的双向链表)中,我们通常不会把 _next 和 _prev 全部设为弱引用。因为如果全部是 weak_ptr,一旦你丢失了指向头节点的那个 shared_ptr,整个链表的所有节点都会因为没有强引用而瞬间被销毁
通用做法是:
-
_next 使用 shared_ptr: 保持从前往后的强力拥有关系,确保链表不会断
-
_prev 使用 weak_ptr: 仅仅作为回看的观察者,打破循环引用
这样做的好处:
-
遍历依然顺滑,往后找节点(cur->_next)依然是直接访问,不需要 lock()
-
打破循环: 因为 _prev 是弱引用,它不会增加前一个节点的计数,循环引用从逻辑上就不存在了
-
**符合直觉:**通常我们认为父节点拥有子节点,在链表中就是前驱拥有后继
六. C++11 与 Boost 智能指针
如果你观察 C++ 的演进史,会发现标准库(STL)的许多新特性并不是凭空产生的,而是经过了长期的实践经验和社区验证。智能指针就是最典型的例子
Boost 库:标准库的实验室
Boost 库被誉为 C++ 准标准库。它的初衷就是为 C++ 标准化提供高质量的可参考实现
Boost 的发起人 Beman Dawes 本身就是 C++ 标准委员会的成员。许多我们现在习以为常的 C++11 / 14 / 17 特性(如智能指针、Lambda、正则表达式),最早都是在 Boost 中成熟并被广泛使用的
智能指针的演进路线图
智能指针的发展并不是一蹴而就的,它经历了一个从"难用"到"好用",再到"标准"的过程:
-
**C++98:**首个智能指针auto_ptr应运而生。尽管它开创了RAII的先河,却因拷贝时所有权转移的缺陷被禁止使用
-
**Boost 时代:**Boost 社区推出了更实用的系列:scoped_ptr、shared_ptr、weak_ptr 以及针对数组的 scoped_array 和 shared_array。这些设计真正解决了工程中的痛点
-
**C++ TR1:**TR1(Technical Report 1)引入了 shared_ptr。需要注意,TR1 并非正式标准,它是标准委员会在正式推出 C++11 前的一份技术草案
-
**C++11:**标准库汲取了 Boost 的优秀设计,引入了 unique_ptr、shared_ptr 和 weak_ptr 等智能指针。其中,unique_ptr 正是对 Boost 中 scoped_ptr 的改良与升级
现代 C++ 智能指针的底层实现逻辑、引用计数机制,几乎完全参考了 Boost 的设计
七. 内存泄露
内存泄漏 并非指内存在物理意义上的消失,而是指程序在申请内存后,因为疏忽或错误,失去了对该段内存的控制,导致这块内存无法被重新利用,从而造成浪费
-
通常是由于忘记调用 delete/free,或者是程序运行逻辑中出现了异常,导致原本该执行的释放代码被跳过
-
相当于程序向系统借了内存,却丢失了指向这些内存的指针,导致系统永远无法收回这些资源
对于操作系统、后台服务(Server)、长时间运行的客户端来说,内存泄漏是毁灭性的。随着可用内存不断减少,系统会频繁进行页面交换,导致功能响应越来越慢,最终因内存溢出而卡死或崩溃
如何检测内存泄漏?
在复杂的工程项目中,肉眼排查泄漏几乎是不可能的。我们需要借助专业的工具进行检测
-
Linux 环境:
-
Valgrind: 业界标杆,功能强大,能准确定位到哪一行代码发生了泄漏
-
LSan: 集成在编译器中,运行速度比 Valgrind 快很多
-
-
Windows 环境:
-
VLD : 一款针对 Visual Studio 的开源工具,使用方便,能直接在输出窗口打印泄漏报告
-
CRT 库内置: 通过 _CrtDumpMemoryLeaks() 等接口进行基础检测
-
内存泄漏的治理应该遵循预防为主,查错为辅的原则
1. 事前预防
-
养成良好的编码规范,申请和释放必须成对出现。但这仅仅是理想状态,在面对 try-catch 异常跳转时,肉眼往往难以保证万无一失
-
尽量使用 std::unique_ptr 或 std::shared_ptr 管理资源。这是目前 C++ 社区公认的最可靠手段。如果场景特殊,也应按照 RAII 思想自己封装管理类
2. 事后查错
-
定期体检: 在项目快上线前,或者在自动化测试流程中,集成内存检测工具
-
日志监控: 监控长期运行服务的内存占用曲线,一旦发现异常增长,立即回溯代码
