使用Stable-Diffusion实现文本生成图像
🐬 目录:
一、任务描述

基于 Stable Diffusion 1.5 架构,设计并训练了一个专注于 19 世纪末至 20 世纪初复古印刷艺术风格的专用模型。解决通用模型在生成特定历史艺术风格时一致性差、提示词复杂的问题。
主要工作:
🌐数据工程 : 构建并清洗了包含复古艺术图像及对应文本描述的专业数据集(Old Art Style Images with Caption Dataset)。
🎾模型微调 : 对 SD1.5 进行全参数/部分参数微调,成功将蚀刻线条、低饱和度色彩及纸张纹理等特征"烘焙"进模型权重。
💴效果优化: 实现了无需特定风格提示词即可生成故事书插图、藏书票及早期石版画风格图像的能力
二、模型介绍
Stable Diffusion 1.5 是由 Stability AI 于 2022 年 10 月发布的开源文本生成图像(Text-to-Image)模型。它是基于 Latent Diffusion Model (LDM) 架构的改进版本,是目前 AI 绘画社区中生态最丰富、兼容性最强、使用最广泛的基座模型之一。
🔖核心规格与架构
SD1.5 主要由三个核心组件构成:
👻文本编码器 (Text Encoder) :基于 CLIP ViT-L/14 模型,将用户输入的提示词(Prompt)转换为计算机可理解的向量嵌入(Embeddings)。
👻去噪网络(U-Net) :模型的核心部分,在潜在空间(Latent Space)中逐步去除噪声,根据文本引导生成图像特征。SD1.5 拥有约 8.9 亿 参数。
👻变分编码器(VAE):包含 Encoder 和 Decoder,将像素图像压缩到潜在空间(训练/生成时),并将潜在空间数据解码回像素图像(输出时)。
三、代码实现
1️⃣ 下载Stable-Diffusion-V1.5
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from huggingface_hub import snapshot_download
model_path = snapshot_download(
repo_id="runwayml/stable-diffusion-v1-5",
local_dir=".models/stable-diffusion-v1-5",
local_dir_use_symlinks=False,
resume_download=True
)
print(f"模型已下载到: {model_path}")2️⃣使用文本生成图像
"Desk with a laptop and a cup of coffee"
import matplotlib.pyplot as plt
from diffusers import StableDiffusionPipeline
import torch
import os
model_id = ".models/stable-diffusion-v1-5"
device = "cuda" if torch.cuda.is_available else "cpu"
pipe = StableDiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16
)
pipe.vae.requires_grad_(False)
pipe.text_encoder.requires_grad_(False)
unet = pipe.unet
vae = pipe.vae.to(device)
tokenizer = pipe.tokenizer
text_encoder = pipe.text_encoder.to(device)
noise_scheduler = pipe.scheduler
pipe = pipe.to(device)
pipe.safety_checker = None #关闭安全检查器
pipe.requires_safety_checker = False
def imagegenrator(text):
image = pipe(
text,
num_inference_steps=30,
guidance_scale=7.5
).images[0]
plt.imshow(image)
plt.axis("off")
plt.show()
imagegenrator("Desk with a laptop and a cup of coffee")生成结果如下图所示:

2️⃣微调Stable-Diffusion-V1.5模型
🕜 Old Art Style Images with Caption Dataset数据处理
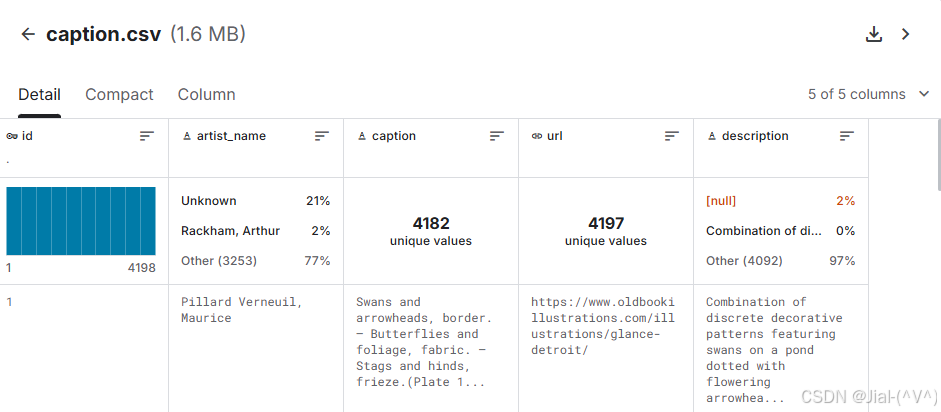
Old Art Style Images with Caption Dataset包含image与caption.csv两部分内容。其中每张图像对应的caption.csv记录包含4个字段:**'id', 'artist_name', 'caption' , 'url', 'description' **,首先将数据进行筛选,得到包含图像与描述对的形式。
import pandas as pd
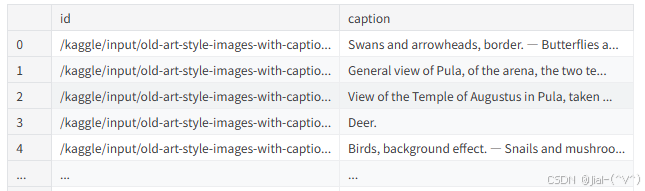
df = pd.read_csv("./datasets/caption.csv")
df = df[["id","caption"]]
df["id"] = df["id"].apply(lambda x: f"./datasets/images/{x}.jpg")
df["caption"] = df["caption"].str.replace(
r"\s*\([^)]*\)", "", regex=True
).str.strip()代码运行结果为:
随后将处理后的数据统一为数据集形式:
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image, UnidentifiedImageError
class DataProcesser(Dataset):
def __init__(self, df, tokenizer):
self.tokenizer = tokenizer
self.df = df
self.transform = transforms.Compose([
transforms.Resize(512),
transforms.CenterCrop(512),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
try:
image = Image.open(row["id"]).convert("RGB")
except (UnidentifiedImageError, OSError):
new_idx = random.randint(0, len(self.df) - 1)
return self.__getitem__(new_idx)
image = self.transform(image)
tokens = self.tokenizer(
row["caption"],
padding="max_length",
truncation=True,
max_length=77,
return_tensors="pt"
)
return {
"image": image,
"input_ids": tokens.input_ids[0]
}🕜 对模型进行lora配置,unet中仅部分结构可以学习
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=8,
lora_alpha=8,
target_modules=["to_q", "to_k", "to_v", "to_out.0"],
lora_dropout=0.05,
bias="none"
)
unet = get_peft_model(unet, lora_config)
unet.to(device)
unet.print_trainable_parameters()🕜配置完成以后,进行监督微调:
from torch.utils.data import DataLoader
from accelerate import Accelerator
from torch.optim import AdamW
from diffusers.optimization import get_cosine_schedule_with_warmup
import timeit
import torch.nn.functional as F
import random
from tqdm import tqdm
dataset = DataProcesser(df, tokenizer)
train_loader = DataLoader(dataset, batch_size=4, shuffle=True)
optimizer = AdamW(unet.parameters(), lr=1e-5)
lr_scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=100,
num_training_steps=len(train_loader)*3
)
accelerator = Accelerator(
gradient_accumulation_steps=1
)
unet, optimizer, train_loader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_loader, lr_scheduler
)
start = timeit.default_timer()
for epoch in tqdm(range(3), position=0, leave=True):
unet.train()
text_encoder.eval()
vae.eval()
train_running_loss = 0
for idx, batch in enumerate(tqdm(train_loader, position=0, leave=True)):
rgb_images = batch["image"].to(device, dtype=torch.float16)
input_ids = batch["input_ids"].to(device)
with torch.no_grad():
latents = vae.encode(rgb_images ).latent_dist.sample() #将像素空间图像RGB压缩到latent空间
latents = latents * 0.18215 # Stable Diffusion V1/V2的标准缩放因子,用于将VAE的输出缩放到U-Net期望的分布范围
text_embeddings = text_encoder(input_ids).last_hidden_state
noise = torch.randn_like(latents) #生成与潜在图像形状相同的高斯噪声
last_batch_size = len(latents)
timesteps = torch.randint(0, 1000, (last_batch_size,), device=device).long() #随机采样时间步(0 到 999)。扩散模型的核心思想是预测图像在任意噪声程度下的噪声。
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps) # 将噪声混合到原始潜在图像中
with accelerator.accumulate(unet): # 用于梯度累积。如果显存不足,可以通过累积多个小 batch 的梯度再更新一次权重来模拟大 batch size 训练。
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states=text_embeddings).sample #输入带噪图像、时间步和文本条件,让 U-Net 预测加入的噪声。
loss = F.mse_loss(noise_pred, noise) #损失函数:计算预测噪声与真实噪声之间的均方误差。目标是让预测噪声尽可能接近真实噪声。
accelerator.backward(loss) #计算梯度(适配混合精度训练和分布式训练)。
optimizer.step() #更新 U-Net 的权重。
lr_scheduler.step() # 更新学习率(通常用于学习率预热或衰减)。
optimizer.zero_grad()
train_running_loss += loss.item()
train_loss = train_running_loss / len(train_loader)
train_learning_rate = lr_scheduler.get_last_lr()[0]
print("-"*30)
print(f"Train Loss EPOCH: {epoch+1}: {train_loss:.4f}")
print(f"Training Time: {stop-start:.2f}s")
unet.save_pretrained("lora_unet") # 保存训练的unet权重3️⃣基于文本生成复古风格的图像(微调后)
from diffusers import StableDiffusionPipeline
from peft import PeftModel
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
pipe.unet = PeftModel.from_pretrained(pipe.unet, "lora_unet")
image = pipe(
"old book illustration style, Desk with a laptop and a cup of coffee",
num_inference_steps=30,
guidance_scale=7.5
).images[0]
plt.imshow(image)
plt.axis("off")
plt.show()生成结果如下图所示:
