想象一下,你开了一家餐厅。厨师(LLM)负责做菜,但厨房不能只有厨师------你需要采购员买食材、质检员检查卫生、服务员上菜。中间件就是Agent世界的"后厨团队",它们在关键时刻介入,让整个流程更顺畅、更安全。
在LangChain 1.0中,中间件(Middleware)是扩展Agent能力的核心机制。如果说create_agent是Agent的骨架,那中间件就是它的神经系统------感知、调控、保护,让Agent从"能用"变成"好用"。
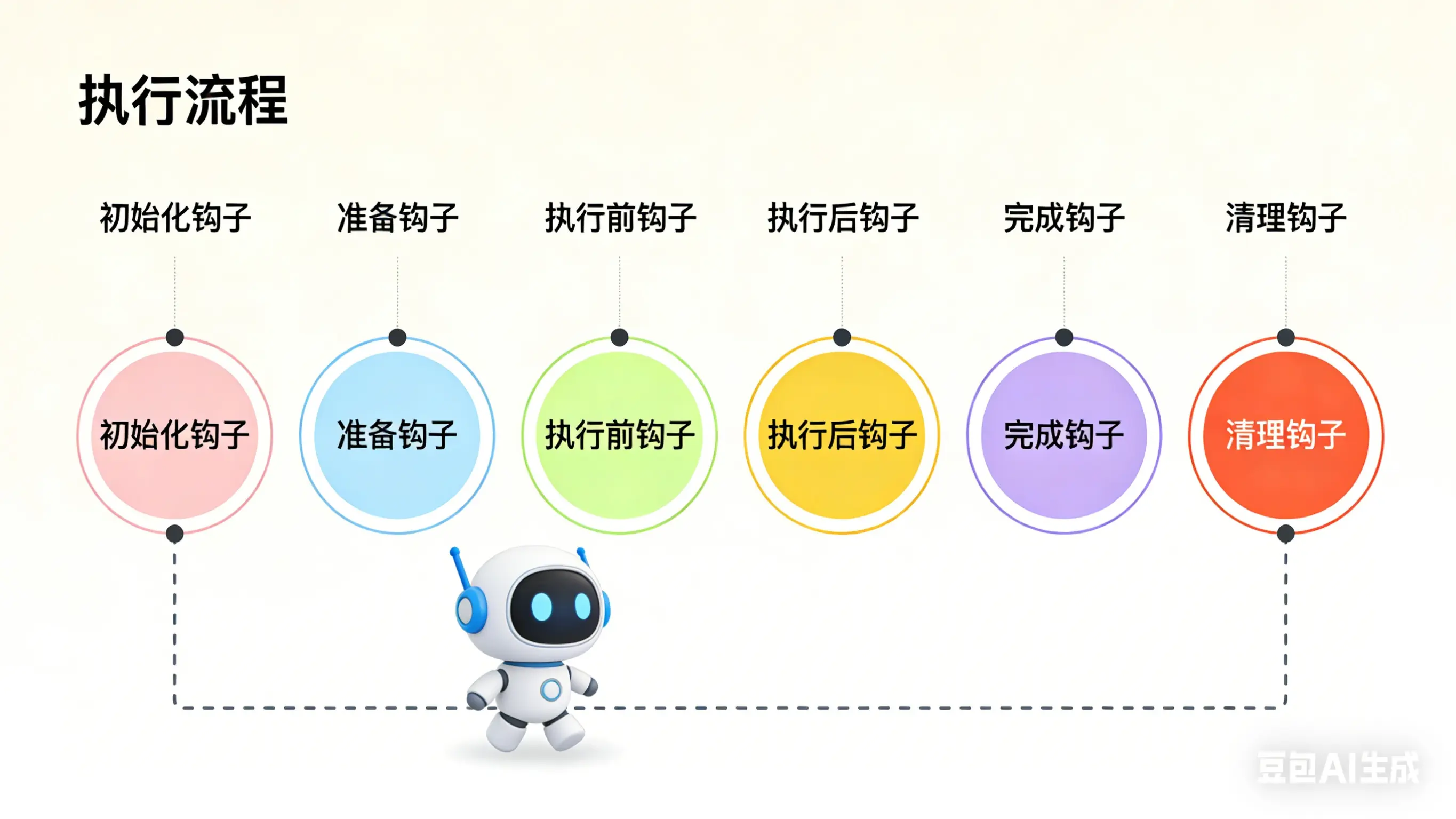
一、Middleware架构:六把"手术刀"精准切入
LangChain 1.0的中间件设计了六个生命周期钩子,覆盖Agent执行的每个关键环节:
| 钩子 | 执行时机 | 典型用途 |
|---|---|---|
before_agent |
Agent启动时(一次) | 加载记忆、验证输入、初始化资源 |
before_model |
每次调用LLM前 | 修剪历史消息、注入上下文、PII脱敏 |
wrap_model_call |
包裹LLM调用全过程 | 缓存、重试、动态切换模型 |
wrap_tool_call |
包裹工具执行全过程 | 工具权限校验、结果拦截、错误处理 |
after_model |
LLM返回后,工具执行前 | 输出校验、人工审批(HITL)、安全护栏 |
after_agent |
Agent结束时(一次) | 保存结果、发送通知、清理资源 |
这种设计的高明之处在于**"洋葱模型"**------每个wrap_*钩子都像一层洋葱皮,请求进去时要剥开层层包装,响应出来时又要再穿回去。这种双向拦截能力,让开发者能完全掌控数据流。
二、两种姿势写中间件:装饰器 vs 类
LangChain提供了两种创建中间件的方式,就像你可以选择"快餐"或"正餐":
2.1 装饰器模式:快速原型首选
适合单一功能的轻量级场景,代码简洁得像一条 tweet:
python
from langchain.agents.middleware import before_model, wrap_model_call
from langchain.agents import create_agent
from typing import Callable
# 像贴便利贴一样添加日志功能
@before_model
def log_before_model(state, runtime):
print(f"🤖 即将调用模型,当前消息数:{len(state['messages'])}")
return None # 返回None表示不修改状态
# 给模型调用加上"防弹衣"(重试机制)
@wrap_model_call
def retry_model(request, handler: Callable):
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"⚠️ 第{attempt + 1}次失败,正在重试:{e}")
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[log_before_model, retry_model] # 像搭积木一样组合
)装饰器的本质 :LangChain会在背后动态创建一个继承自AgentMiddleware的类,把你的函数包装成对应的方法。简单,但功能相对有限。
2.2 类模式:生产环境利器
当你需要多个钩子协同工作 、同步/异步双版本 、或复杂的初始化配置时,类模式是不二之选:
python
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable, Any
class ProductionGradeMiddleware(AgentMiddleware):
"""
生产级中间件示例:日志 + 监控 + 熔断
"""
def __init__(self, sentry_client, max_latency=30):
self.sentry = sentry_client
self.max_latency = max_latency
self.request_count = 0
def before_agent(self, state, runtime) -> dict[str, Any] | None:
"""Agent启动时:初始化追踪"""
self.request_count += 1
print(f"📊 第{self.request_count}次请求开始")
return {"trace_id": f"req_{self.request_count}"}
def before_model(self, state, runtime) -> dict[str, Any] | None:
"""调用前:检查消息长度,防止Token爆炸"""
msg_count = len(state["messages"])
if msg_count > 50:
# 触发消息摘要逻辑(可配合SummarizationMiddleware)
print(f"⚠️ 消息过多({msg_count}),建议清理历史")
return None
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""包裹调用:添加熔断和监控"""
import time
start = time.time()
try:
response = handler(request)
latency = time.time() - start
# 上报指标
if latency > self.max_latency:
print(f"🐌 慢查询警告:{latency:.2f}s")
return response
except Exception as e:
self.sentry.capture_exception(e) # 上报错误
raise # 继续抛出,让上层处理
def after_model(self, state, runtime) -> dict[str, Any] | None:
"""调用后:内容安全审查"""
last_message = state["messages"][-1]
content = last_message.content if hasattr(last_message, 'content') else str(last_message)
# 简单的敏感词检查(实际可用更复杂的策略)
sensitive_words = ["密码", "密钥", "secret_key"]
for word in sensitive_words:
if word in content.lower():
print(f"🚨 检测到敏感信息:{word}")
# 可以在这里触发人工审核或拦截
return None
def after_agent(self, state, runtime) -> dict[str, Any] | None:
"""结束时:保存会话摘要"""
print(f"✅ 请求完成,共{len(state['messages'])}轮对话")
return None
三、状态预处理与响应后处理实战
中间件的精髓在于**"偷梁换柱"**------在数据流动的关键节点,神不知鬼不觉地修改请求或响应。
3.1 动态模型路由:给不同用户不同"大脑"
想象一下,你的SaaS产品同时服务免费用户和VIP用户。免费用户用轻量级模型,VIP用GPT-5------这完全可以在中间件里动态决定:
python
from dataclasses import dataclass
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
@dataclass
class UserContext:
tier: str = "free" # free | pro | enterprise
class SmartRouterMiddleware(AgentMiddleware):
"""
智能路由中间件:根据用户等级分配模型
"""
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
user_tier = request.runtime.context.tier
# 根据用户等级选择模型和工具
if user_tier == "enterprise":
model = ChatOpenAI(model="gpt-5", temperature=0.3)
tools = [advanced_analytics, sql_database, code_interpreter]
print("🏆 Enterprise用户:启用GPT-5 + 全套工具")
elif user_tier == "pro":
model = ChatOpenAI(model="gpt-4.1", temperature=0.5)
tools = [web_search, file_reader]
print("💎 Pro用户:启用GPT-4.1")
else: # free
model = ChatOpenAI(model="gpt-4.1-nano", temperature=0.7)
tools = [basic_search] # 限制工具数量
print("🆓 免费用户:基础版")
# 关键:用request.override()创建新请求,原请求不变
new_request = request.override(model=model, tools=tools)
return handler(new_request)
# 使用
agent = create_agent(
model="gpt-4.1", # 默认模型,会被中间件覆盖
tools=[advanced_analytics, sql_database, web_search, basic_search, code_interpreter, file_reader],
middleware=[SmartRouterMiddleware()],
context_schema=UserContext
)
# VIP用户使用
result = agent.invoke(
{"messages": [{"role": "user", "content": "分析Q3销售数据"}]},
config={"configurable": {"context": UserContext(tier="enterprise")}}
)关键点 :request.override()会创建一个新的请求对象,不会污染原始数据。这种不可变设计让多个中间件组合时更安全。
3.2 动态工具选择:别让模型"选择困难症"
当工具超过20个时,模型容易"看花眼"。我们可以在wrap_model_call中根据用户意图动态筛选工具:
python
from langchain.agents.middleware import wrap_model_call
@wrap_model_call
def intent_based_tool_selector(request, handler):
"""
根据对话意图,只暴露相关工具
"""
user_message = request.state["messages"][-1].content.lower()
# 意图映射表
tool_categories = {
"coding": [code_executor, git_tool, linter],
"analysis": [data_analyzer, chart_generator, sql_query],
"search": [web_search, arxiv_search, wiki_lookup],
"writing": [grammar_checker, style_enhancer, translator]
}
# 简单关键词匹配(实际可用Embedding或分类模型)
selected_tools = []
for intent, tools in tool_categories.items():
if intent in user_message:
selected_tools.extend(tools)
# 保底:至少保留通用工具
if not selected_tools:
selected_tools = [web_search, calculator]
print(f"🔧 根据意图激活{len(selected_tools)}个工具")
return handler(request.override(tools=selected_tools))
四、生产级集成:日志、监控、安全护栏
真正的生产环境,中间件是你的"安全网"和"望远镜"。
4.1 全链路日志中间件
python
import json
import time
from typing import Any
from langchain.agents.middleware import AgentMiddleware
class ObservabilityMiddleware(AgentMiddleware):
"""
可观测性中间件:结构化日志 + 性能追踪
"""
def __init__(self, logger):
self.logger = logger
self.start_times = {}
def _log(self, event: str, data: dict):
self.logger.info(json.dumps({
"event": event,
"timestamp": time.time(),
**data
}))
def before_agent(self, state, runtime) -> None:
self.start_times["agent"] = time.time()
self._log("agent_started", {
"thread_id": runtime.config.get("thread_id"),
"message_count": len(state["messages"])
})
def wrap_model_call(self, request, handler):
call_start = time.time()
model_name = request.model.model_name if hasattr(request.model, 'model_name') else 'unknown'
self._log("model_call_started", {
"model": model_name,
"tool_count": len(request.tools)
})
try:
response = handler(request)
latency = time.time() - call_start
# 估算Token(实际应从response.usage获取)
self._log("model_call_completed", {
"model": model_name,
"latency_ms": round(latency * 1000, 2),
"status": "success"
})
return response
except Exception as e:
self._log("model_call_failed", {
"model": model_name,
"error": str(e),
"error_type": type(e).__name__
})
raise
def after_agent(self, state, runtime) -> None:
total_time = time.time() - self.start_times["agent"]
self._log("agent_completed", {
"total_duration_ms": round(total_time * 1000, 2),
"final_message_count": len(state["messages"])
})4.2 PII(敏感信息)脱敏中间件
如果你处理的是医疗、金融数据,PII脱敏是刚需:
python
import re
from langchain.agents.middleware import AgentMiddleware
class PIIMaskingMiddleware(AgentMiddleware):
"""
PII脱敏中间件:保护用户隐私
"""
PII_PATTERNS = {
"email": r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
"phone": r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b',
"ssn": r'\b\d{3}-\d{2}-\d{4}\b',
"credit_card": r'\b\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4}\b'
}
def __init__(self):
self.mask_map = {} # 占位符 -> 原始值
self.counter = 0
def _mask(self, text: str) -> str:
"""脱敏并记录映射关系"""
for pii_type, pattern in self.PII_PATTERNS.items():
matches = re.finditer(pattern, text)
for match in matches:
original = match.group()
placeholder = f"<{pii_type.upper()}_{self.counter}>"
self.counter += 1
self.mask_map[placeholder] = original
text = text.replace(original, placeholder)
return text
def _unmask(self, text: str) -> str:
"""还原敏感信息"""
for placeholder, original in self.mask_map.items():
text = text.replace(placeholder, original)
return text
def before_model(self, state, runtime):
"""请求前:脱敏"""
messages = state["messages"]
for msg in messages:
if hasattr(msg, 'content') and isinstance(msg.content, str):
msg.content = self._mask(msg.content)
return {"messages": messages}
def after_model(self, state, runtime):
"""响应后:还原(如果需要)"""
# 注意:通常LLM响应不需要包含PII,但以防万一
last_msg = state["messages"][-1]
if hasattr(last_msg, 'content') and isinstance(last_msg.content, str):
last_msg.content = self._unmask(last_msg.content)
return None4.3 安全护栏(Guardrails)中间件
防止Agent"胡说八道"或执行危险操作:
python
from langchain.agents.middleware import AgentMiddleware
from langgraph.types import Command
class SafetyGuardrailMiddleware(AgentMiddleware):
"""
安全护栏:内容审核 + 危险操作拦截
"""
FORBIDDEN_TOOLS = ["execute_shell", "delete_database", "send_email"]
DANGEROUS_KEYWORDS = ["rm -rf", "DROP TABLE", "DELETE FROM"]
def wrap_tool_call(self, request, handler):
tool_name = request.tool_call.get("name", "")
# 危险工具拦截
if tool_name in self.FORBIDDEN_TOOLS:
print(f"🚫 拦截危险工具调用:{tool_name}")
return {
"error": f"Tool '{tool_name}' is blocked by security policy",
"status": "blocked"
}
# 参数检查
arguments = request.tool_call.get("arguments", {})
arg_str = json.dumps(arguments)
for keyword in self.DANGEROUS_KEYWORDS:
if keyword in arg_str:
print(f"🚫 检测到危险参数:{keyword}")
return {
"error": "Dangerous parameters detected",
"status": "blocked"
}
return handler(request)
def after_model(self, state, runtime):
"""输出审查"""
last_message = state["messages"][-1]
# 检查模型是否试图执行未授权操作
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
for call in last_message.tool_calls:
if call.get("name") in self.FORBIDDEN_TOOLS:
# 可以在这里触发人工审核
return Command(update={
"messages": [{
"role": "assistant",
"content": "我检测到您请求的操作涉及敏感功能,需要人工确认。请稍等..."
}]
})
return None
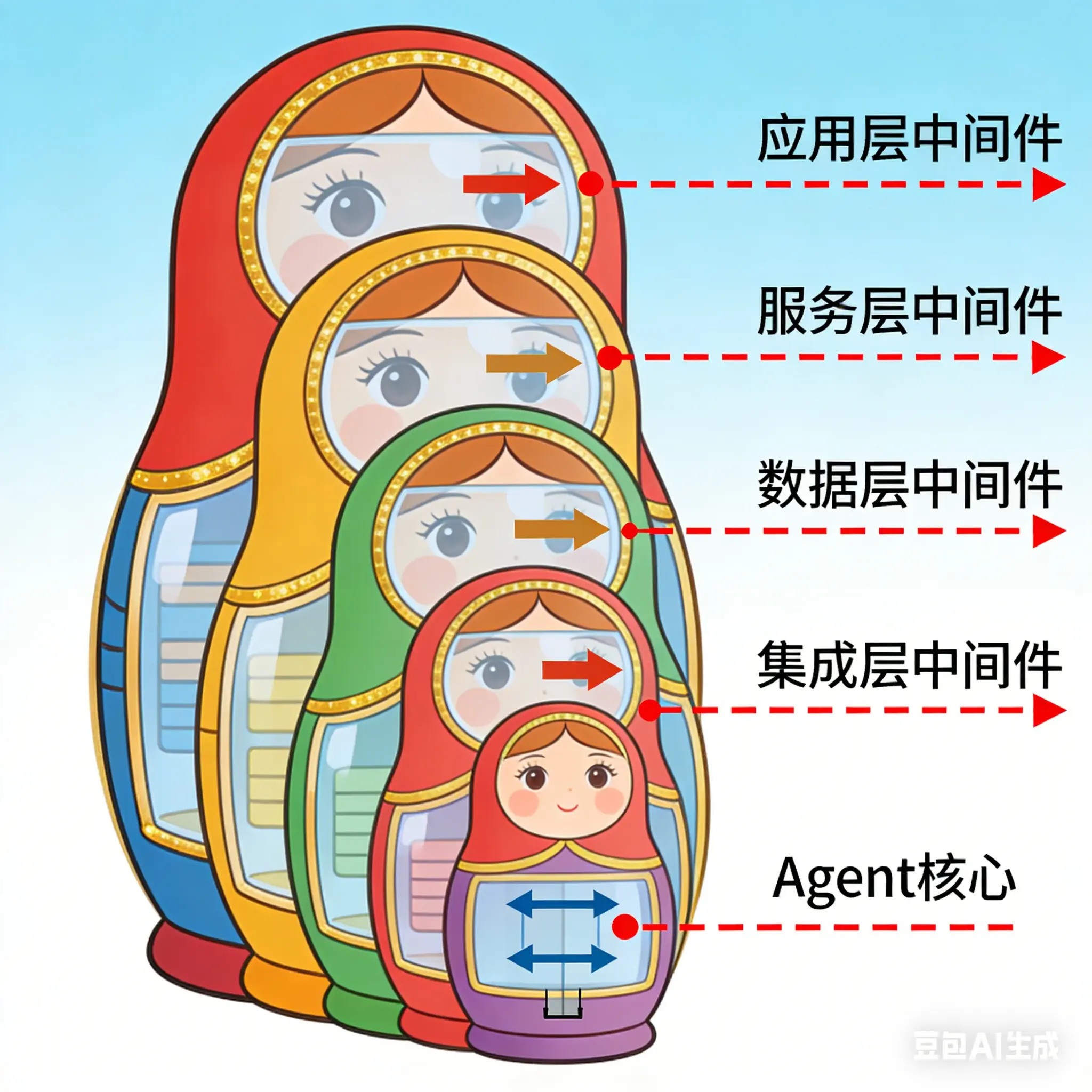
五、中间件组合:1+1>2的艺术
中间件的真正威力在于组合 。LangChain按照数组顺序从外到内包裹中间件------想象成俄罗斯套娃:
python
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[
ObservabilityMiddleware(logger), # 最外层:监控一切
SafetyGuardrailMiddleware(), # 第二层:安全检查
PIIMaskingMiddleware(), # 第三层:隐私保护
SmartRouterMiddleware(), # 第四层:智能路由
# 核心Agent逻辑在最内层
]
)执行顺序:
- 请求进入:Observability → Safety → PII → Router → Agent
- 响应返回:Agent → Router → PII → Safety → Observability
六、总结:中间件设计哲学
LangChain 1.0的中间件系统体现了几个精妙的设计原则:
- 单一职责:每个中间件只做一件事,通过组合实现复杂功能
- 开闭原则:对扩展开放(随时添加新中间件),对修改封闭(不改动Agent核心)
- 洋葱架构:Wrap钩子形成双向拦截,让预处理和后处理天然配对
- 类型安全 :
ModelRequest和ModelResponse提供清晰的接口契约
如果你也曾被旧版LangChain的"回调地狱"劝退,新版的中间件机制绝对能让你眼前一亮。它不再是"在代码里打补丁",而是真正的AOP(面向切面编程)------横切关注点(日志、安全、监控)与业务逻辑彻底解耦。
下一篇预告: 《Context与Runtime:运行时数据注入》------我们将学习如何在工具调用时安全地传递用户信息、权限和上下文,让Agent真正成为"有身份"的智能助手!
关注公众号【dev派】,发送 "agent" 获取全部源码和模板