在全局 AI 模型呈现爆发式增长的背景下,高效洞察技术趋势已成为开发者和企业决策的关键。以全球最大的 AI 模型托管平台之一 Hugging Face 为例,其公开模型数量已突破 200 万。面对如此庞大且高频更新的数据,如何快速提取出高价值的模型热度、任务分布及社区关注度变化,对传统的数据开发方案提出了挑战。
本文将以分析 Hugging Face 模型趋势数据集(数万条真实快照数据)为例,展示如何利用 DataWorks Data Agent 实现从原始数据接入、清洗、质量控制、工作流编排到可视化分析的端到端自动化流程。
一、数据准备与接入
从 Kaggle 获取 Hugging Face 模型快照数据集,包含三张原始表:
-
hf_models_snapshot.csv(模型下载快照):记录近 30 天内下载量最高的模型,适合做下载榜单和任务类型分布分析。 -
hf_models_trending.csv(模型趋势快照):记录社区点赞数(Likes)较高的模型,适合分析社区关注度。 -
hf_recent_models.csv(最新模型表):记录最新创建的模型,适合做新模型发现。
⚠️ 注意:下载量和点赞量代表的是热度,并不直接等同于模型能力强弱。
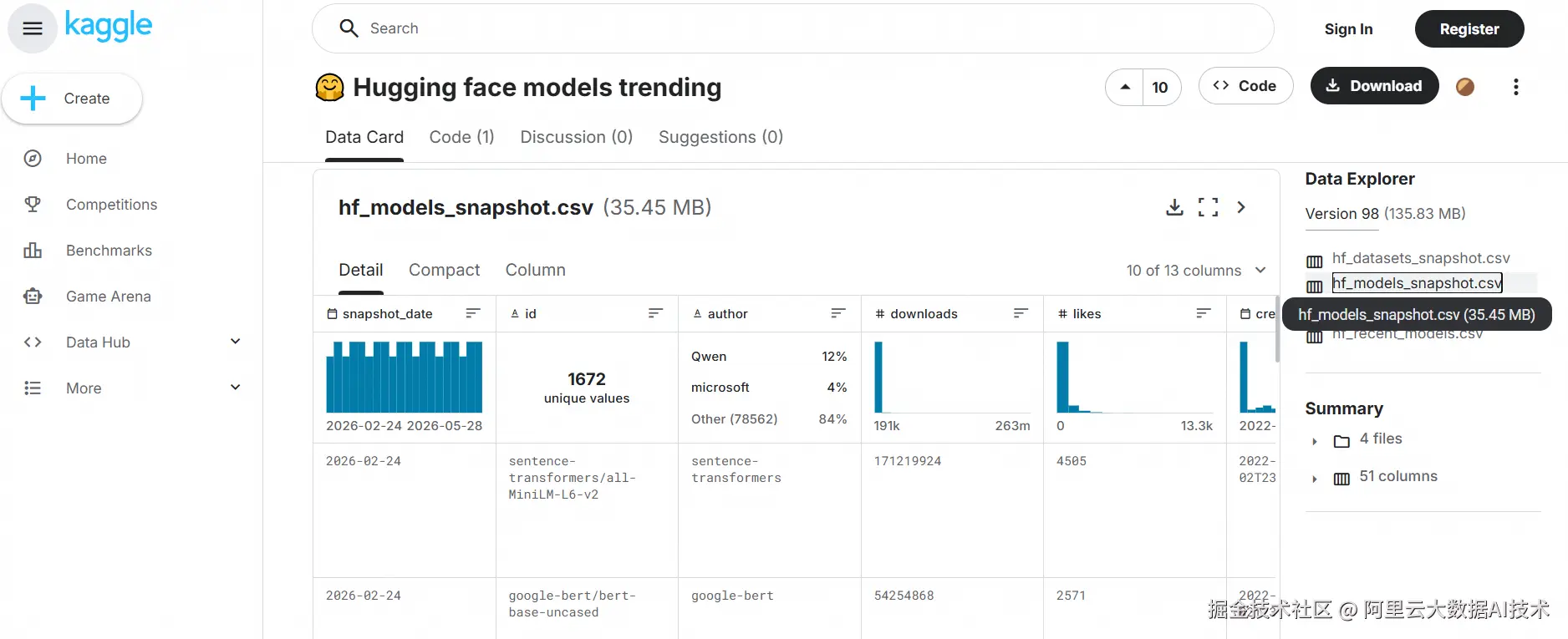
通过DataWorks数据上传功能,将几份CSV文件上传到了MaxCompute,并生成了以下三张原始表:
-
hf_models_snapshot
-
hf_models_trending
-
hf_recent_models
二、DataWorks Data Agent 数据开发
基于 DataWorks Data Agent 进行辅助开发,通过自然语言交互即可生成具体的 SQL 代码,一步步完成数据解析、清洗、检测与工作流的搭建。
2.1 字段探查与语义理解
Data Agent 接入 MaxCompute 原始表后,第一步并非盲目编写代码,而是进行字段探查。它能准确识别模型 ID、作者、下载量、点赞数、任务类型等字段的业务含义,并主动指出潜在风险(例如:下载量与点赞数需从字符串转换为数值,日期需转为标准格式)。 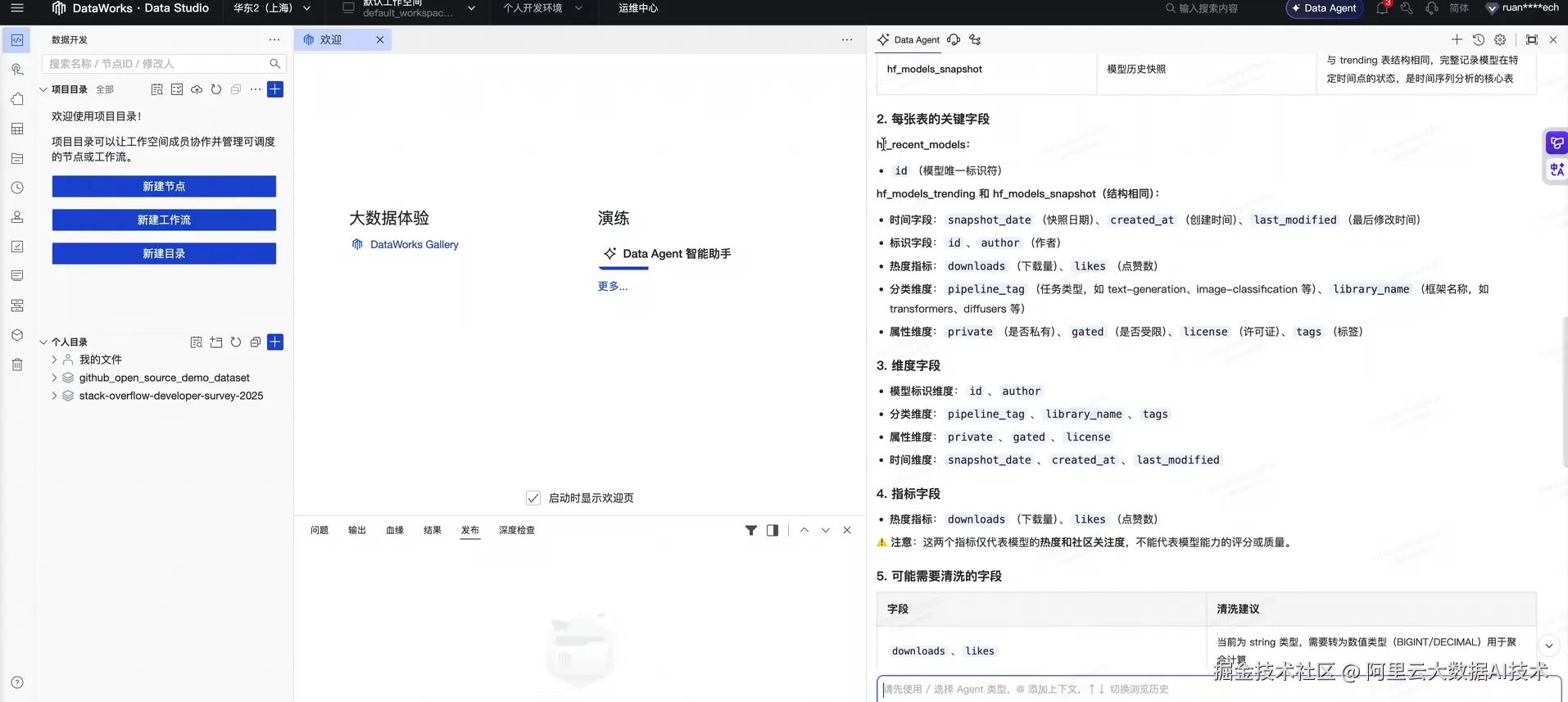
2.2 自动化 ETL 数据清洗
基于探查结果,Data Agent 自动生成高效的 SQL 代码,批量执行清洗操作,( 例如:将 downloads 和 likes 转换为数值型;将缺失的 pipeline_tag 统一标记为 unknown;规范化 gated(访问限制)字段分类;自动去除同一天同一个模型的重复记录等。)
最终,Data Agent 输出三张标准化的清洗表,为后续多维分析奠定基础。
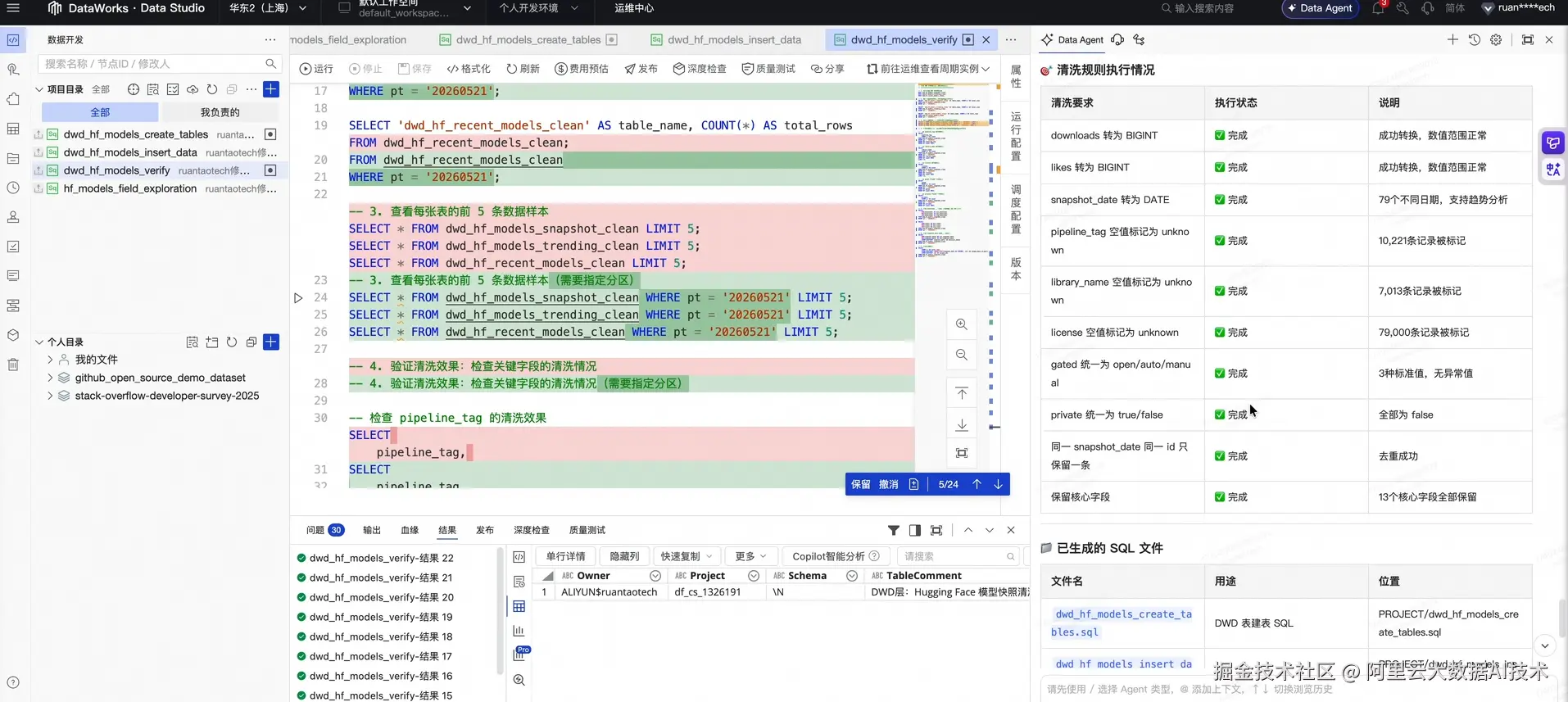
2.3 完成数据质量检查
数据质量是数据资产化前提。Data Agent 基于清洗后的表结构,自主生成一套完整的数据质量监控规则,并执行校验。例如:
-
完整性校验: 模型 ID、下载量、点赞数不允许为空;
-
值域合规性: 指标数值必须大于等于 0;
-
一致性校验: snapshot_date 支持趋势分析,检查是否存在单日重复记录。
在此步骤中,Data Agent 还提供了专业的数据洞察。例如,它在报告中指出 "license 字段存在大比例缺失,不建议将其作为核心维度进行分析"。这种主动发现数据缺陷的能力,能有效规避低质量数据带来的决策偏差。
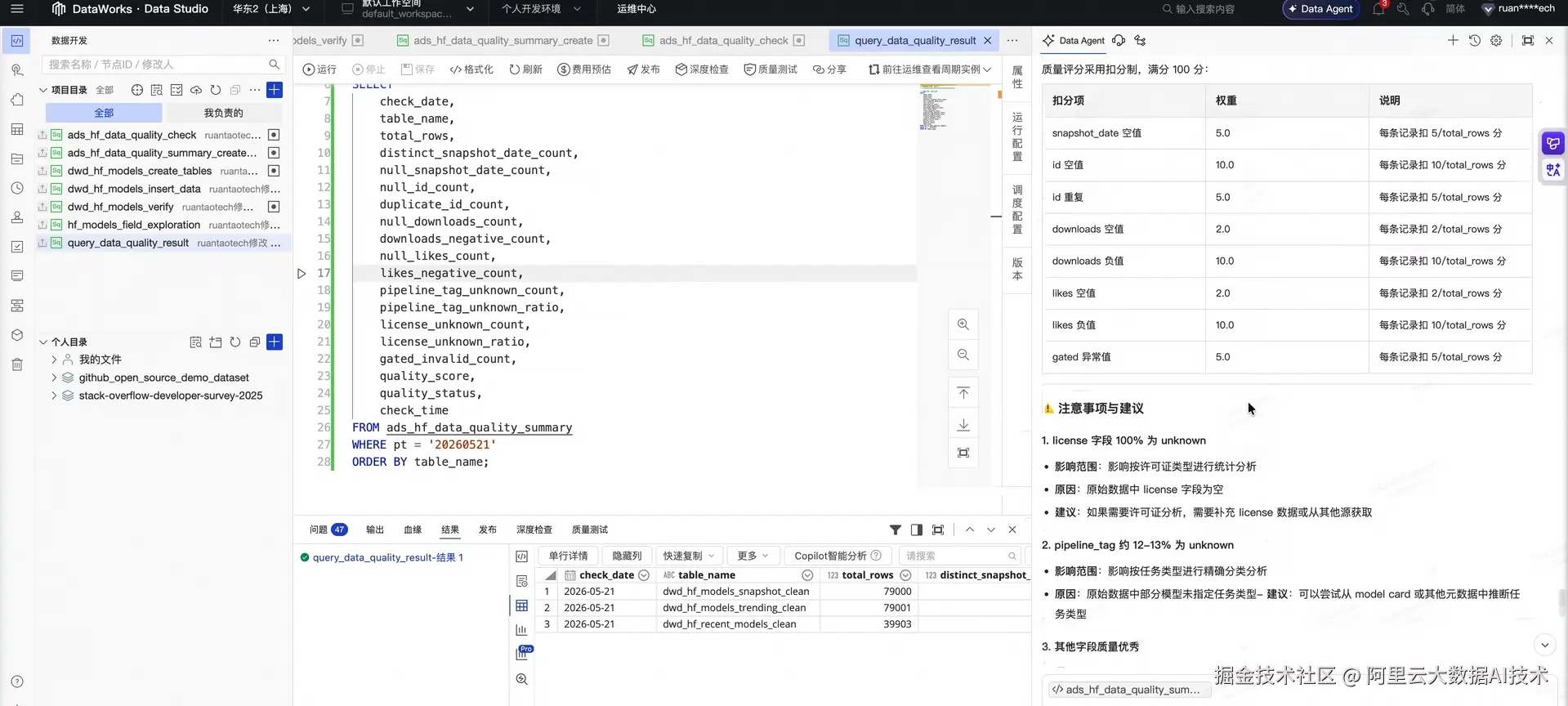
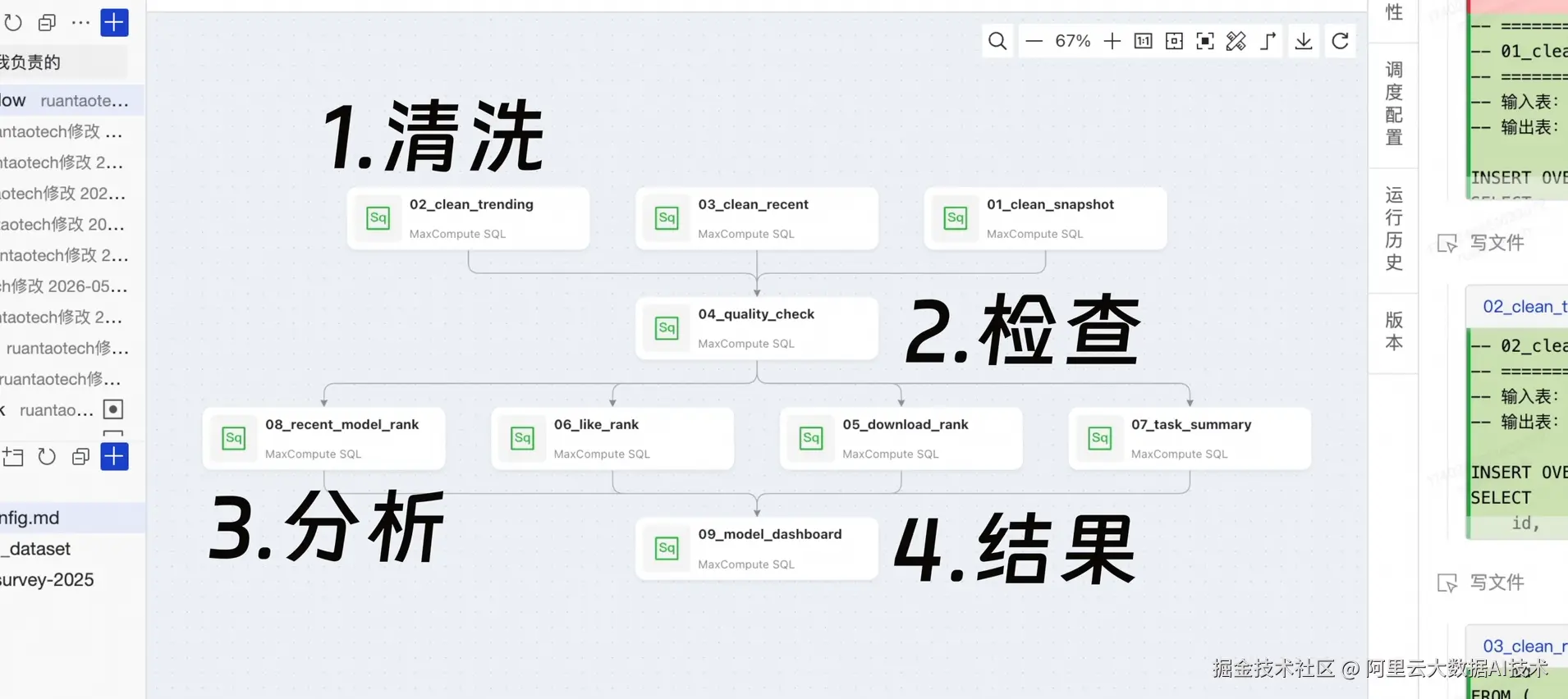
2.4 自动化 DAG 工作流编排
将清洗 → 检查 → 生成排行榜 → 输出结果表的流程固化为可调度任务链,最终输出 ADS 结果表供 ChatBI 使用。
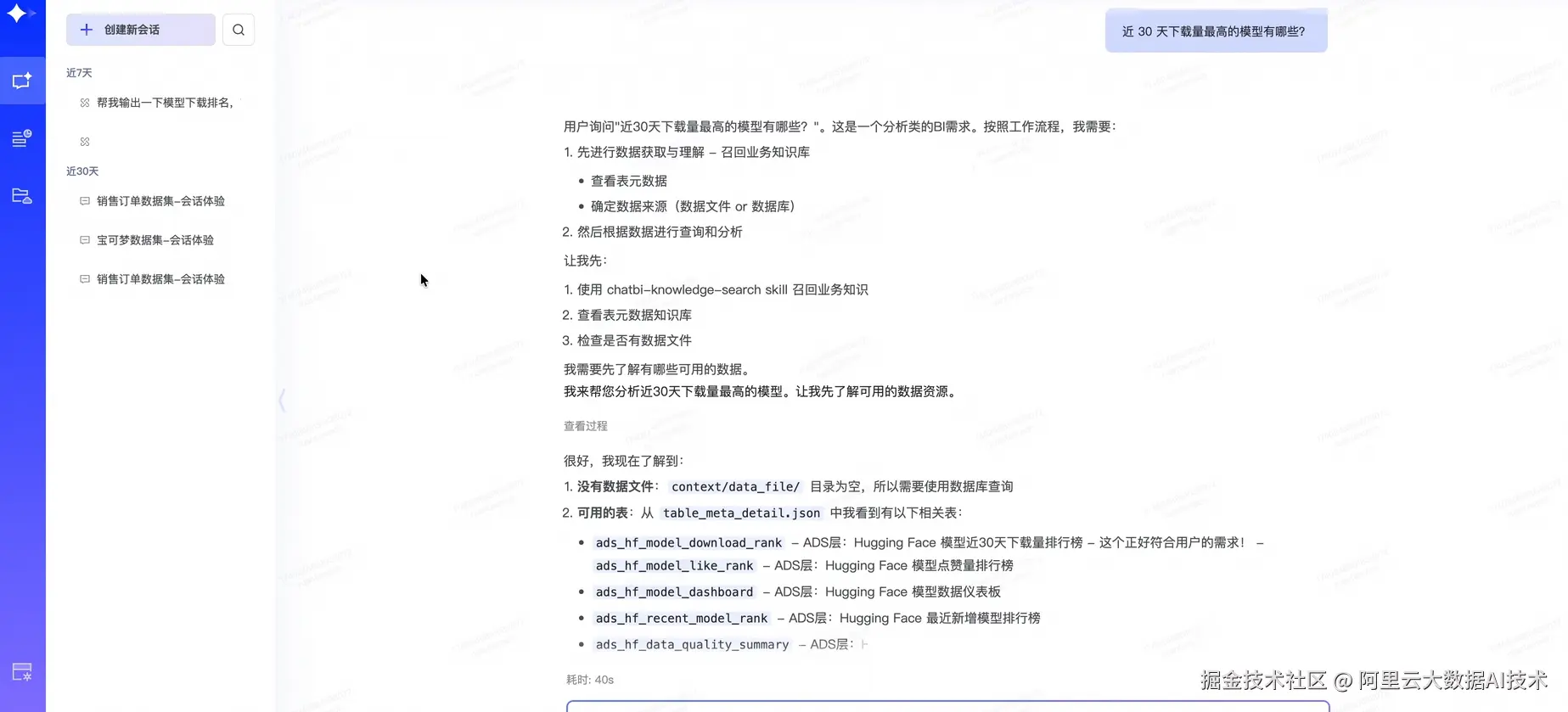
三、DataWorks ChatBI:零代码交互式分析
业务分析人员及管理层无需掌握 SQL,基于自然语言,即可问数据、看图表、生成分析结论。
例如:
问:"近 30 天下载量最高的模型有哪些?"
"不同任务类型的模型下载表现有什么差异?"
DataWorks ChatBI 会在后台自动解析查询意图,自动关联清洗后的结果表,生成包含大盘指标、排行榜单、历史趋势、作者组织分布及任务类型分析的多维可视化报告。甚至还附带了大模型自动生成的行业洞察与行动建议(例如:Qwen 系列模型近期热度极高,建议重点关注;Sentence-Transformers 生态非常活跃等)。
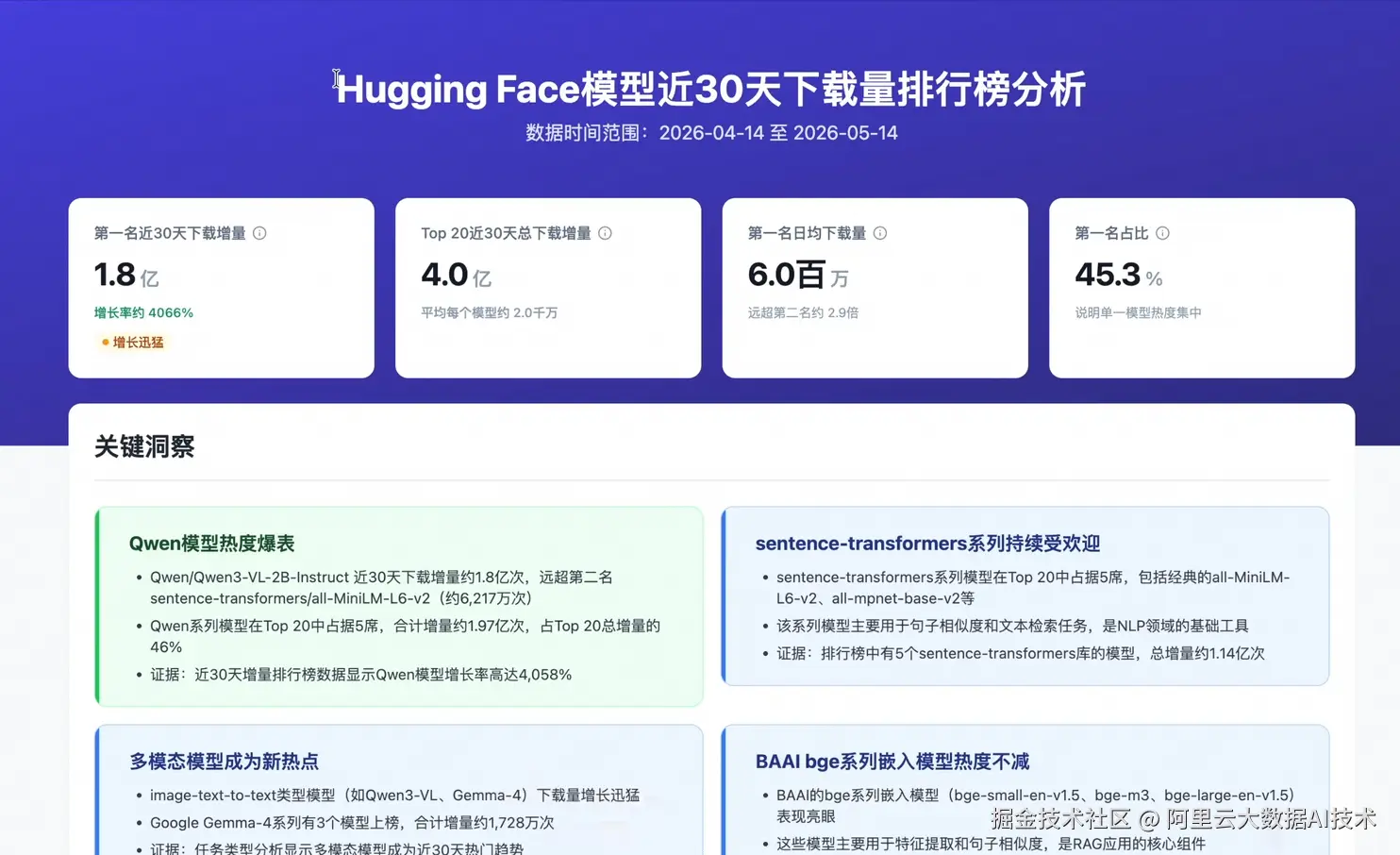
从枯燥的 CSV 文件,到一份"有图、有真相、有深度结论"的分析报告,全程只需几句大白话。这就是DataWorks Data Agent 的数据生产力!
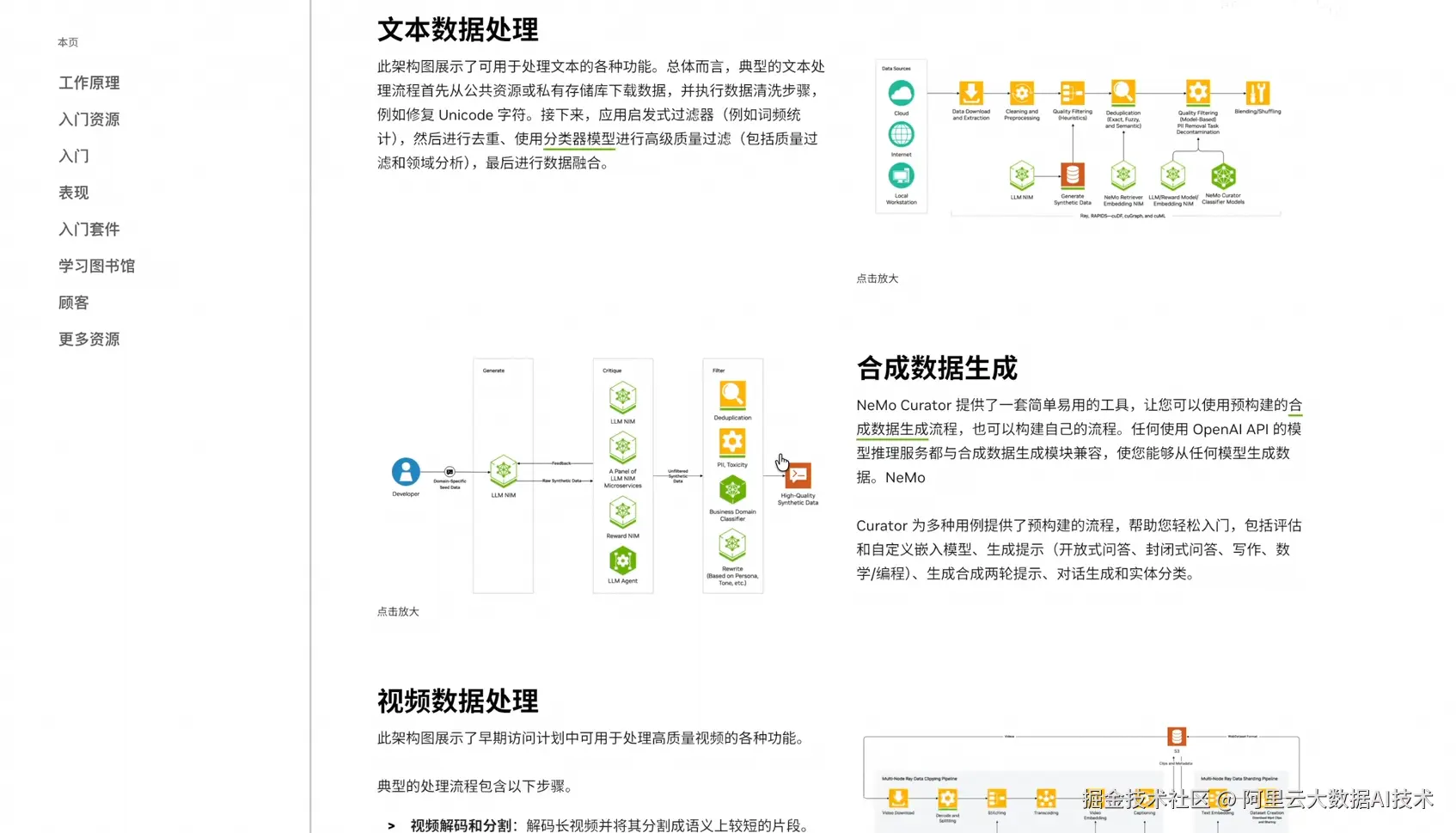
四、NVIDIA NeMo Curator:赋能大规模高质量数据处理
在模型开发全链路中,训练数据质量直接决定模型性能。NVIDIA NeMo Curator 专注于 PB 级大规模数据的预处理,能够针对文本、图像、音视频等多模态数据,提供一整套可扩展的数据处理流水线:
-
更高准确率:用更少的数据和训练算力,实现更高准确率
-
更快处理速度:借助 RAPIDS 实现 GPU 加速
-
可扩展性: 通过跨多个节点扩展,可处理超过 100 PB 的数据
-
分类模型: 采用 SOTA 分类模型,以微服务形式保障安全性、内容合规性和多样性
NVIDIA NeMo Curator 支持训练数据的优化,DataWorks Data Agent 促进数据的理解与高效利用,两者协同互补,相辅相成。
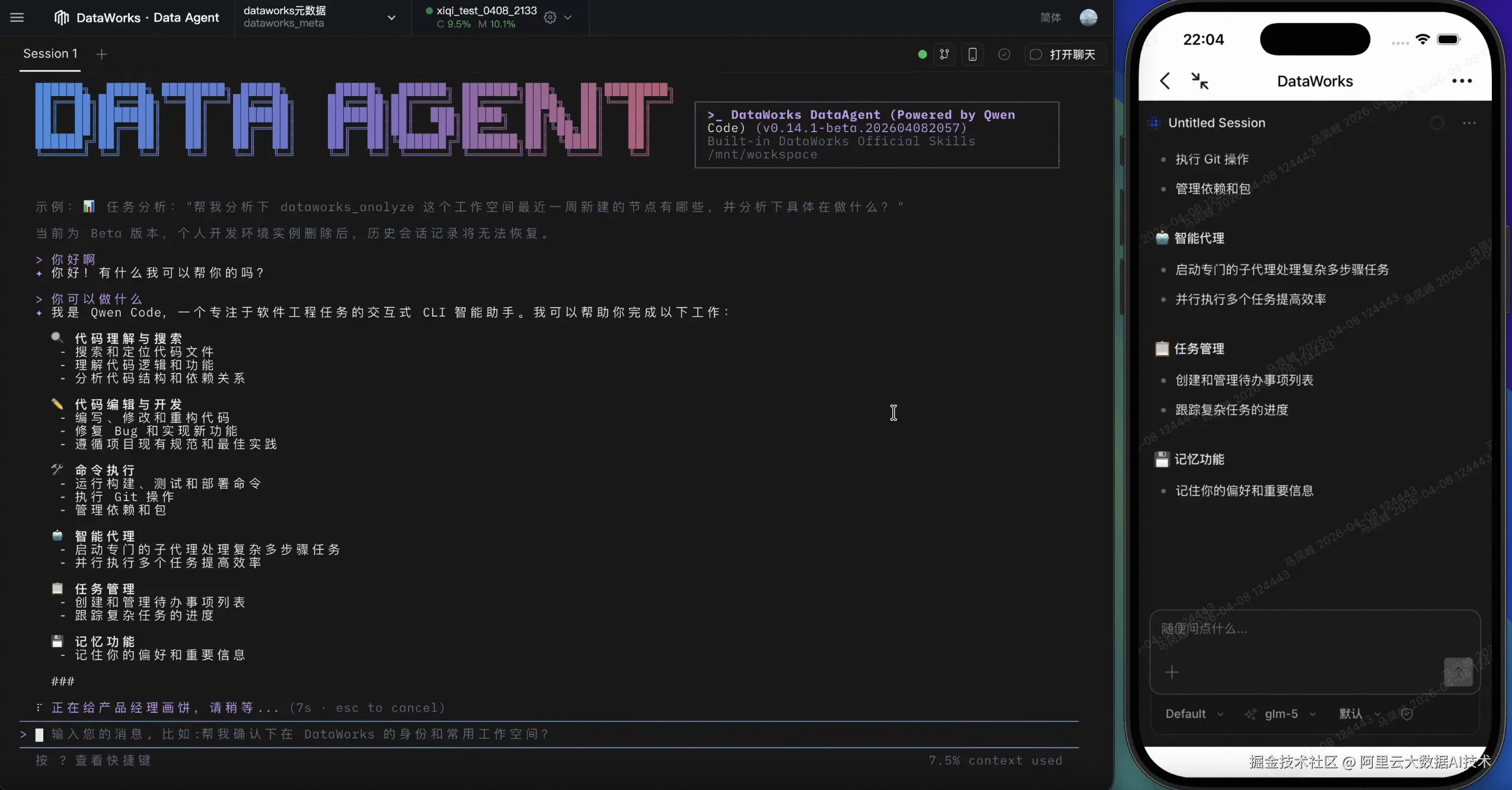
五、DataWorks Data Agent,为开发者而生
Data Agent,是 DataWorks 平台内的一站式 AI 智能体,包含 Agent 智能体、代码编程助手、ChatBI 以及快捷 AI 操作等核心能力。依托强大的 AI 推理与自然语言交互技术,用户仅需通过对话即可自动化完成数据集成、数据开发与运维、质量治理、数据分析等全周期任务。此刻,DataWorks Data Agent 已完成从"功能模块"到"智能工作流中枢"的全面进化。新版本彻底打破了传统菜单式操作的局限,基于开发者与业务人员的真实习惯,重构为四种独立且无缝切换的交互模式:
-
Chat UI 模式:零门槛自然语言对话面板,开箱即用,让业务洞察触手可及;
-
CLI 模式:Web 终端直连,专为极客打造,敲命令、跑任务,效率拉满;
-
远程控制模式:扫码即连,手机端实时同步会话与执行进度,实现类似 Apple Continuity 的无缝接力,随时随地掌控全局;
-
IM Channel 模式:深度打通钉钉、飞书与企业微信,无需切换后台,在熟悉的聊天窗口中即可直接调用 Agent 能力。
立即开通 ,即刻开启你的智能开发分析之旅
DataWorks Data Agent 详细介绍 help.aliyun.com/zh/datawork...
DataWorks Data Agent 体验入口 dataworks.data.aliyun.com/product/age...