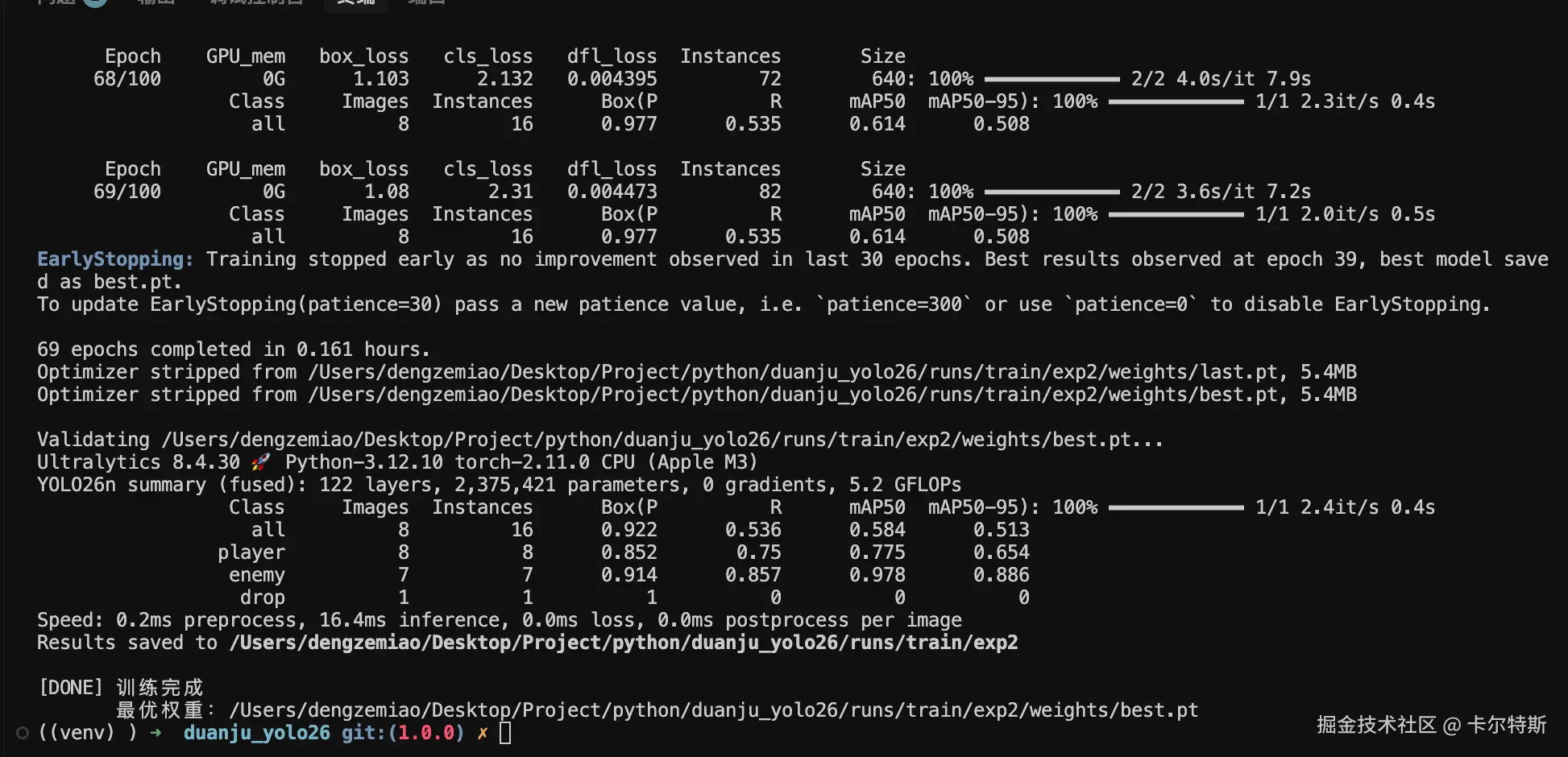
一、素材组装脚本
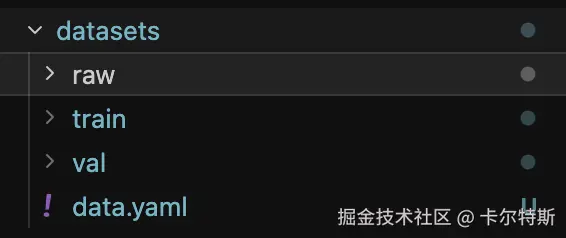
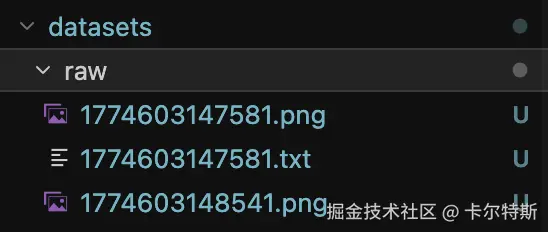
初始图片跟标注文件都在 datasets/raw 文件夹中,需要将这些标注按照官方格式区分出来,只需要使用下面脚本修改其中的 源文件夹 SOURCE_DIR 路径即可,会自动将图片与 .txt 标注文件自行按比例分割到对应文件夹。
python
"""
数据集分流脚本 - 将已标注的图片和 .txt 按比例分流到 train/val 目录。
运行方式(项目根目录):
python scripts/split_dataset.py
说明:
- 只处理同时存在图片和对应 .txt 标注文件的配对
- 未标注的图片(无 .txt)原地不动,不参与分流
- 分流结果输出到 OUTPUT_DIR 下的标准 YOLO 目录结构:
train/images/ train/labels/
val/images/ val/labels/
输出结构示例:
datasets/
raw/ 原始文件,分流后保持不变
train/
images/
labels/
val/
images/
labels/
"""
import random
import shutil
import sys
from pathlib import Path
# ── 配置 ──────────────────────────────────────────────────────────────────────
SOURCE_DIR = Path(__file__).parent.parent / "datasets" / "raw" # 源文件夹
OUTPUT_DIR = Path(__file__).parent.parent / "datasets" # 输出根目录
TRAIN_RATIO = 0.8 # 训练集比例,剩余归验证集(默认 8:2)
RANDOM_SEED = 42 # 随机种子,固定后每次分流结果一致
IMG_EXTS = {".jpg", ".jpeg", ".png", ".bmp", ".webp"} # 支持的图片格式
# ──────────────────────────────────────────────────────────────────────────────
def collect_annotated_pairs(source: Path) -> list[tuple[Path, Path]]:
"""扫描 source 目录,返回所有 (image, label) 配对(只含已标注的)。"""
pairs = []
for img_path in sorted(source.iterdir()):
if img_path.suffix.lower() not in IMG_EXTS:
continue
txt_path = img_path.with_suffix(".txt")
if txt_path.exists():
pairs.append((img_path, txt_path))
return pairs
def split(pairs: list, ratio: float, seed: int) -> tuple[list, list]:
"""随机打乱后按 ratio 切分为 train/val。"""
data = pairs[:]
random.seed(seed)
random.shuffle(data)
cut = max(1, int(len(data) * ratio))
return data[:cut], data[cut:]
def copy_pairs(pairs: list, images_dir: Path, labels_dir: Path) -> tuple[int, int]:
"""复制文件,跳过已存在的(去重),返回 (复制数, 跳过数)。"""
images_dir.mkdir(parents=True, exist_ok=True)
labels_dir.mkdir(parents=True, exist_ok=True)
copied, skipped = 0, 0
for img, lbl in pairs:
img_dst = images_dir / img.name
lbl_dst = labels_dir / lbl.name
if img_dst.exists() and lbl_dst.exists():
skipped += 1
continue
shutil.copy2(img, img_dst)
shutil.copy2(lbl, lbl_dst)
copied += 1
return copied, skipped
def main(
source_dir: Path = SOURCE_DIR,
output_dir: Path = OUTPUT_DIR,
train_ratio: float = TRAIN_RATIO,
seed: int = RANDOM_SEED,
) -> None:
if not source_dir.exists():
print(f"[ERROR] 源目录不存在:{source_dir}")
sys.exit(1)
print(f"[INFO] 源目录:{source_dir}")
print(f"[INFO] 输出目录:{output_dir}")
print(f"[INFO] 分流比例:train {train_ratio:.0%} / val {1 - train_ratio:.0%}")
print("-" * 50)
# 收集已标注配对
pairs = collect_annotated_pairs(source_dir)
total = len(pairs)
if total == 0:
print("[WARN] 未找到任何已标注的图片(图片 + 同名 .txt),请确认路径和标注文件。")
sys.exit(0)
# 统计未标注数量
all_imgs = sum(1 for p in source_dir.iterdir() if p.suffix.lower() in IMG_EXTS)
unannotated = all_imgs - total
print(f"[INFO] 已标注:{total} 张 | 未标注(跳过):{unannotated} 张")
# 分流
train_pairs, val_pairs = split(pairs, train_ratio, seed)
print(f"[INFO] train:{len(train_pairs)} 张 | val:{len(val_pairs)} 张")
print()
# 复制文件
t_copied, t_skipped = copy_pairs(train_pairs, output_dir / "train" / "images", output_dir / "train" / "labels")
v_copied, v_skipped = copy_pairs(val_pairs, output_dir / "val" / "images", output_dir / "val" / "labels")
print(f"[DONE] 分流完成")
print(f" train → 新增 {t_copied} 张,跳过 {t_skipped} 张(已存在)")
print(f" val → 新增 {v_copied} 张,跳过 {v_skipped} 张(已存在)")
print(f" 路径 → {output_dir}")
if __name__ == "__main__":
# 支持命令行传参(可选):
# python scripts/split_dataset.py [源目录] [train比例]
# python scripts/split_dataset.py datasets/raw 0.9
args = sys.argv[1:]
source = Path(args[0]) if len(args) >= 1 else SOURCE_DIR
ratio = float(args[1]) if len(args) >= 2 else TRAIN_RATIO
# 相对路径转为项目根目录的绝对路径
if not source.is_absolute():
source = Path(__file__).parent.parent / source
main(source_dir=source, train_ratio=ratio)二、开始训练脚本
python
"""
YOLO 训练脚本。
运行方式(项目根目录):
python scripts/train.py
训练完成后结果保存在:
runs/train/<实验名>/
weights/best.pt 最优权重(用于推理)
weights/last.pt 最后一轮权重
results.png 训练曲线图
"""
from pathlib import Path
from ultralytics import YOLO
# ── 配置 ──────────────────────────────────────────────────────────────────────
ROOT = Path(__file__).parent.parent
MODEL = ROOT / "yolo26n.pt" # 预训练权重,迁移学习收敛更快
DATA = ROOT / "datasets" / "data.yaml" # 数据集配置文件
EPOCHS = 100 # 训练轮数,数据少可先用 50 试试
IMGSZ = 640 # 输入图片尺寸,与截图分辨率无关(YOLO 内部缩放)
BATCH = 16 # 批次大小,显存不够时调小(8 / 4)
WORKERS = 4 # 数据加载线程数,Mac/CPU 训练建议改为 0
DEVICE = None # None=自动选择(有 GPU 用 GPU,否则 CPU);指定 GPU 填 0
PATIENCE = 30 # 早停轮数,连续 N 轮验证集无提升则停止,防止过拟合(0=关闭早停)
PROJECT = ROOT / "runs" / "train" # 训练结果输出根目录
EXP_NAME = "exp" # 实验名称,重复运行自动加序号 exp2/exp3...
# ──────────────────────────────────────────────────────────────────────────────
def main() -> None:
print(f"[INFO] 模型:{MODEL}")
print(f"[INFO] 数据:{DATA}")
print(f"[INFO] epochs={EPOCHS} imgsz={IMGSZ} batch={BATCH}")
print("-" * 50)
model = YOLO(str(MODEL))
model.train(
data=str(DATA),
epochs=EPOCHS,
imgsz=IMGSZ,
batch=BATCH,
workers=WORKERS,
device=DEVICE,
patience=PATIENCE,
project=str(PROJECT),
name=EXP_NAME,
exist_ok=False, # False=重复运行自动加序号,True=覆盖同名实验
)
# 训练完成后输出最优权重路径
best = PROJECT / EXP_NAME / "weights" / "best.pt"
if not best.exists():
# 自动序号时查找最新的实验目录
candidates = sorted(PROJECT.glob(f"{EXP_NAME}*/weights/best.pt"))
if candidates:
best = candidates[-1]
print("\n[DONE] 训练完成")
print(f" 最优权重:{best}")
if __name__ == "__main__":
main()