使用LangChain进行AI应用构建-RAG及相关核心组件认识
一.文本向量-向量存储部分
这里接着上篇文章介绍剩余两种的向量存储方式。
1.1redis向量存储
我们还可以使用 Redis 来存储向量。大多数开发者都熟悉 Redis,因为它速度快、拥有庞大的客户端库生态系统,并且多年来已被众多大型企业采用。从本质上讲,Redis 是一种键值型的 NoSQL 数据库,除了传统用例之外,Redis 还提供了诸如搜索和查询功能等额外能力,允许用户在 Redis 内创建二级索引结构。这使得 Redis 能够以缓存的速度充当向量数据库。
下面我们简单认识下redissearch是什么,注意只是看看了解就行,目前用的话暂时不需要深究
理解redissearch
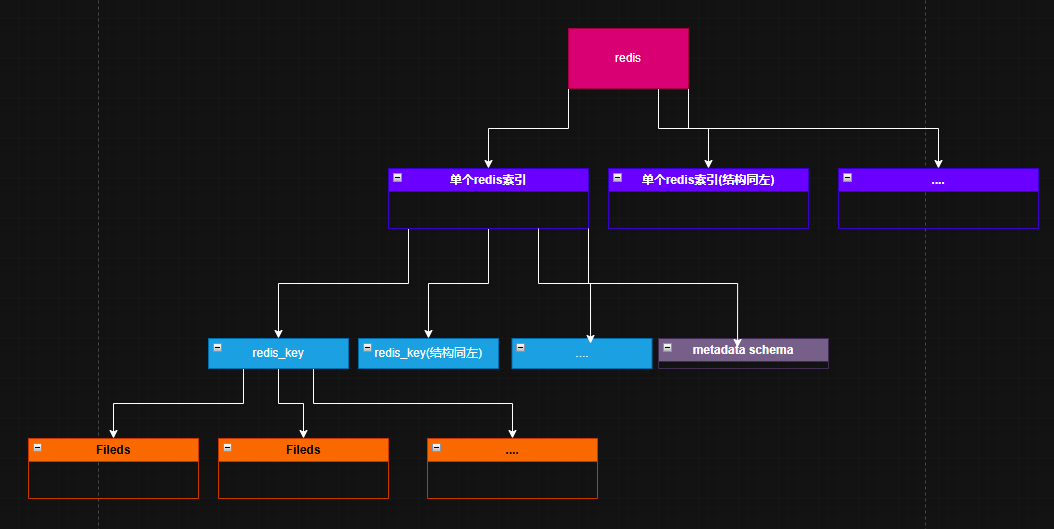
- redissearch干什么的?
- 定义:基于 Redis 构建的高性能全文搜索引擎模块。
- 优势 :
- 分词能力 :弥补传统
LIKE无法分词检索的缺陷。 - 轻量高性能:无需额外外挂大型搜索引擎(如 ES),降低运维成本,提升响应速度。
- 分词能力 :弥补传统
- redissearch里面有什么?
- A. Index (索引)
- 角色:独立的查询目录。
- 特性:存储指向 Redis Keys (Hash) 的指针和索引信息,本身不存储原始业务数据。
- B. Metadata Schema (元数据声明)
- 角色:索引的"蓝图"或"结构定义"。
- 作用:声明元数据的结构,指定哪些字段需要参与搜索以及它们的属性。
- C. Index Fields (字段类型)
| 类型 | 检索行为 | 适用场景 |
| :--- | :--- | :--- |
| TEXT | 全文搜索 | 文本描述、标题(支持分词和模糊匹配) |
| TAG | 精确过滤 | 分类、标签、状态码(多值精确匹配) |
| NUMERIC | 范围统计 | 价格、库存、时间戳(支持排序与区间过滤) |
| GEO | 地理检索 | 附近的人、门店位置(经纬度坐标计算) |
理解 metadata schema
schema 我们讲过,就是描述数据结构的声明格式。metadata schema 则用来描述元数据的结构声明。
这里的元数据是指我们将来要嵌入文档的元数据。因为对于文档元数据来说,它在存入 Redis 后,就被定义成了索引字段。
对于文档元数据来说,里面存放的就是一些文档属性值,如 source 表示文档来源。我们还可以手动加入其他元数据,这需要设置每个字段的声明:name 表示字段名,type 表示字段类型。
python
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
]一个简单的图示如下:
1.1.1环境设置
首先我们需要有一台云服务器部署redis,当然你自己本地部署也行,具体的部署方法推荐容器化部署,部署方式可以见我之前写的文章(标题4.2部分):
https://blog.csdn.net/xiuwoaiailixiya/article/details/156150728?spm=1001.2014.3001.5501
当然如果你想要为你的redis设置一个初始密码,可以在原示例docker run ...的末尾加一个这样的选项:
python
--requirepass "你的密码"是否运行起来可以用navicat测试或你直接进容器试下等等很多方法,这里就不再展示了。
接下来就是在我们自己的python开发环境安装相应的包:
安装 Redis 客户端包,以便将来定义客户端,以及运行搜索和查询命令。
python
pip install redis在 LangChain 中想要使用 Redis 向量库,需要安装 langchain-redis 包。
python
pip install -qU langchain-redis定义 Redis 连接 URL,客户端连接 Redis 时需要用到。
Redis连接的基本URL结构为:
python
[protocol]://[auth]@[host]:[port]/[database]根据 Index Name 查询其下的所有的 Index Fields,需要安装 redisvl,使用 rvl 命令行工具来检查索引。
python
pip install -U redisvlredisvl一个简单的查询方式如下:
python
rvl index info -i 索引名称 --host redis服务部署的ip地址 --port 服务监听的端口号 -a 密码1.1.2基本操作
初始化与添加文档
我们来看下需要使用到的两个接口:
class langchain_redis.vectorstores.RedisVectorStore 类,其初始化参数如下:
- embeddings:用于此存储的 Embeddings 实例。
- config:可选的 RedisConfig 对象。
class langchain_redis.config.RedisConfig 配置类,其关键配置参数如下:
- index_name:Redis 中索引的名称。默认为生成的 ULID 唯一标识符。
- key_prefix:Redis Key 的前缀。如果未设置,则默认为 index_name。
- redis_url :Redis 实例的 URL。默认为
"redis://localhost:6379"。 - metadata_schema:元数据字段的 schema。设置该字段对于将来的元数据过滤有帮助。
我们来看一个简单实例,向redis中新增我们的索引字段:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisVectorStore, RedisConfig
from langchain_text_splitters import CharacterTextSplitter
embedding_model = OpenAIEmbeddings(
model="text-embedding-3-large",
base_url="https://api.kourichat.com/v1"
)
redis_url = "redis://:123456@你的ip地址:8090"
#初始化redis向量数据库索引
redis_vector_config = RedisConfig(
index_name="QmlBasicGrammar",#定义索引名称
#key_prefix,不设置默认为index_name
redis_url=redis_url,
metadata_schema=[
{"name" : "category","type" : "tag"},#为每个文档设置分类
{"name" : "id","type" : "numeric"}#每个文档给予一个编号标识符
]
)
redis_vector = RedisVectorStore(
embeddings=embedding_model,
config=redis_vector_config
)
#添加文档
##分割源文档
docs_filepath = "C:\\Users\\15890\\Desktop\\QtQuick开发_QML基础语法.md"
###默认的single模式对markdown不进行任何分割
loder = UnstructuredMarkdownLoader(file_path=docs_filepath)
documents = loder.load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",#给定分词器的编码方式
chunk_size=200,
chunk_overlap=100
)
###分割文档,返回被分割的文档列表->list[Document]
texts = text_splitter.split_documents(documents)
###为每个文档设置上面我们规定的metadata_schema,因为原来只有source在每个document的metadata中
for i , doc in enumerate(texts,start=1):
doc.metadata["category"] = "QmlBasicGrammar"
doc.metadata["id"] = i
##执行最终步骤添加文档
ids = redis_vector.add_documents(texts)
print(f"前三个键值的唯一标识符为:{ids[:3]}")首先运行结果如下(:后面的才是对应key的真实唯一标识符):
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
Created a chunk of size 218, which is longer than the specified 200
Created a chunk of size 242, which is longer than the specified 200
Created a chunk of size 397, which is longer than the specified 200
前三个键值的唯一标识符为:['QmlBasicGrammar:01KMWAPDM1FTKMGFDDXMFT3E59', 'QmlBasicGrammar:01KMWAPDM2WQ8SCH67JH25QCHZ', 'QmlBasicGrammar:01KMWAPDM2WQ8SCH67JH25QCJ0']
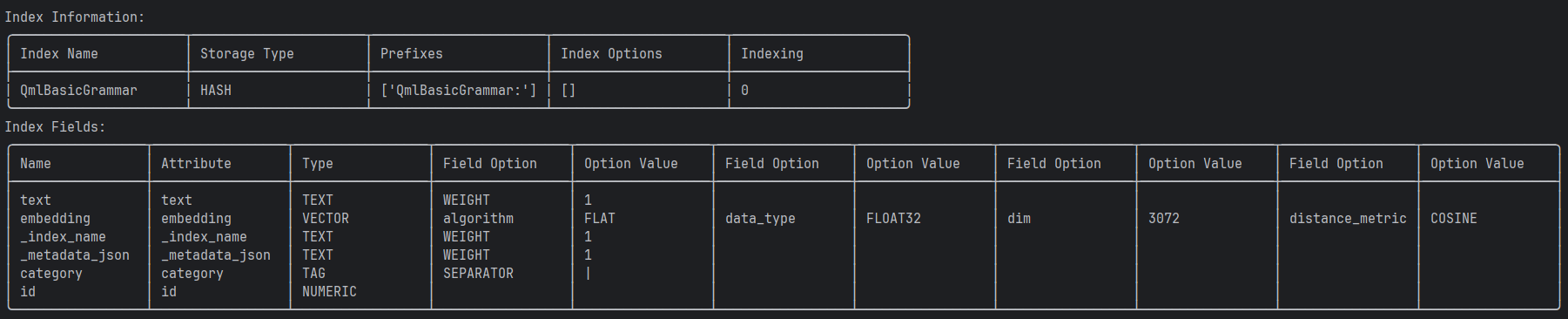
进程已结束,退出代码为 0我们用redisvl看看我们创建的这个索引具体张什么样(注意啊,要先添加文档索引才会被创建,不添加文档索引是不会被创建的 ):
再来看看navicat中查到的数据:
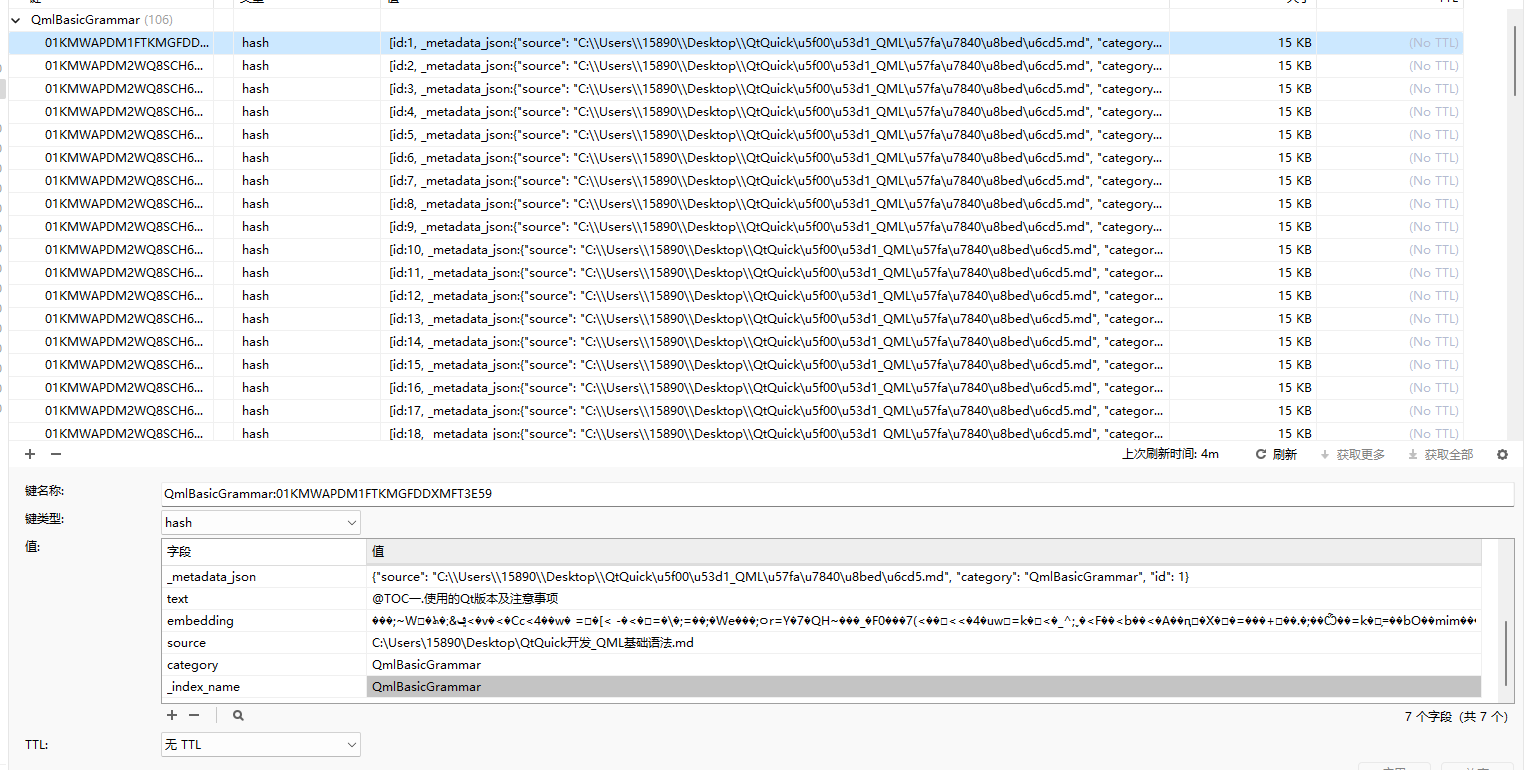
可以看到我们上面查到的ids就是每个键的键名称。
至于删除和通过id查询,和我们上篇文章的介绍的使用姿势基本相同,这里便不多赘述了。
向量搜索
对于redis向量存储,也有着前文内存向量数据库的两种搜索方式,不过它还可以根据最大边际相关性进行搜索,我们下面来一一介绍认识下他们:
相似性搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返回。这可以使用 similarity_search 方法来实现。代码如下(接着上面的代码续写,记得把添加文档的部分代码注释掉避免二次添加):
python
search_results = redis_vector.similarity_search(query="附加属性",k=2)
for doc in search_results:
print('*' * 30)
print(doc.page_content + "\n\n")结果如下:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
******************************
4.5只读属性
只读属性必须给初始值,之后不允许被修改,它的声明的语法如下:
readonly property <propertyType> <propertyName> : <value>
比如,下面的代码中的对只读属性的修改行为是不允许的,代码运行起来会直接爆错:
Item {
readonly property int someNumber: 10
Component.onCompleted: someNumber = 20
}
五.附加属性与附加信号处理器
5.1附加属性
这个东西不好理解,最好是多写一段时间qml才能逐步理解它,官方文档中给的解释经翻译是这样的:
******************************
>附加属性和附加信号处理器是一种机制,可为对象注释额外的属性或信号处理器,否则对象将无法使用这些属性或信号处理器。特别是,它们允许对象访问与个别对象特别相关的属性或信号。
QML 类型的实现可以选择在 C++ 中创建一个附加类型,它具有特定的属性和信号。这种类型的实例可在运行时创建并附加到特定对象上,允许这些对象访问附加类型的属性和信号。访问这些属性和信号时,需要在属性和各自的信号处理器前加上附加类型的名称。
进程已结束,退出代码为 0除了这最基本的功能外,langchain还提供了其他三种相似性搜索的方式对于redis向量存储:
- 根据向量搜索方法 :
similarity_search_by_vector - 根据查询搜索方法,并返回相似分值 :
similarity_search_with_score - 根据向量搜索方法,并返回相似分值 :
similarity_search_with_score_by_vector
有兴趣的读者可以自行问ai了解下这三个方法的使用姿势。
元数据过滤
这里的元数据过滤不能给一个返回bool值的函数了,需要给的是一个表达式,具体写的格式需要根据Index Fields提供的四种字段类型来写,我们看下面一个例子(注意前面相似性搜索时查出的两条数据的对应id值分别为49,50):
python
from redisvl.query.filter import Tag, Num
filter_condition = Tag("category") == "QmlBasicGrammar" and Num("id") < 50
search_results = redis_vector.similarity_search(
query="附加属性",
k=2,
filter=filter_condition
)
for doc in search_results:
print('*' * 30)
print(doc.page_content + "\n\n")此时查出来的结果和相似性搜索那里是一样的:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
******************************
4.5只读属性
只读属性必须给初始值,之后不允许被修改,它的声明的语法如下:
readonly property <propertyType> <propertyName> : <value>
比如,下面的代码中的对只读属性的修改行为是不允许的,代码运行起来会直接爆错:
Item {
readonly property int someNumber: 10
Component.onCompleted: someNumber = 20
}
五.附加属性与附加信号处理器
5.1附加属性
这个东西不好理解,最好是多写一段时间qml才能逐步理解它,官方文档中给的解释经翻译是这样的:
******************************
Item {
readonly property int someNumber: 10
Component.onCompleted: someNumber = 20
}
五.附加属性与附加信号处理器
5.1附加属性
这个东西不好理解,最好是多写一段时间qml才能逐步理解它,官方文档中给的解释经翻译是这样的:
>附加属性和附加信号处理器是一种机制,可为对象注释额外的属性或信号处理器,否则对象将无法使用这些属性或信号处理器。特别是,它们允许对象访问与个别对象特别相关的属性或信号。
进程已结束,退出代码为 0但是我们把id值缩小到48一下就完全不一样了(回答的牛马不相及):
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
******************************
4.3属性组(又叫分组属性)
简单的说明一下,比如对于一个控件中的字体属性,它有加粗,颜色等等可以被设置的属性,一般我们只设置其中一个或两个属性时,只用.来设置就够用了:
import QtQuick
import QtQuick.Controls
Window {
id: mywindow
width: 640
height: 480
visible: true
title: qsTr("我喜欢你")
Button{
id:mybutton
width:200
height: 100
text: "text"
anchors.centerIn: parent
font.bold: true //是否加粗
font.pixelSize: 18 //字体大小
}
}
******************************
但是如果一个属性的子属性过多的时候,我们一般使用{}对多个子属性快捷的进行初始化:
font{
bold: true
pixelSize: 18
}
分组属性类型是具有子属性的类型。如果分组属性类型是对象类型(而不是值类型),则持有该类型的属性必须是只读的。这是为了防止替换子属性所属的对象。
4.4属性别名
属性别名很类似于C++的引用。它不需要像普通属性那样再分配额外的存储空间。如果想要对一个属性取别名,它的语法如下:
[default] property alias <name>: <alias reference>
看一个示例:
进程已结束,退出代码为 0最大边际相关性搜索
如果忘记MMR是什么了,可以移步我之前写的这篇文章的示例选择器部分-基于最大边际相关性的示例选择器(MMR)
https://blog.csdn.net/xiuwoaiailixiya/article/details/157815065?spm=1001.2014.3001.5502
这里就不多赘述了,直接展示使用方式:
使用 MMR 搜索,需要用到 max_marginal_relevance_search 方法。
python
search_results = redis_vector.max_marginal_relevance_search(
query="附加属性",
k=2,
fetch_k=10
)
for doc in search_results:
print('*' * 30)
print(doc.page_content + "\n\n")输出结果如下:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
******************************
4.5只读属性
只读属性必须给初始值,之后不允许被修改,它的声明的语法如下:
readonly property <propertyType> <propertyName> : <value>
比如,下面的代码中的对只读属性的修改行为是不允许的,代码运行起来会直接爆错:
Item {
readonly property int someNumber: 10
Component.onCompleted: someNumber = 20
}
五.附加属性与附加信号处理器
5.1附加属性
这个东西不好理解,最好是多写一段时间qml才能逐步理解它,官方文档中给的解释经翻译是这样的:
******************************
需要注意ListView.isCurrentItem是ListView的附加属性,而每一个委托model只是借用了一下ListView的这个附加属性,它并不是委托项的一个属性。
有点绕对吧,这里可以看一篇关于C++实现自定义附加属性的文章: https://www.jianshu.com/p/36ea29750398
进程已结束,退出代码为 0可以看到它又和上面相似性搜索的结果不一样了.
我们需要注意一个参数 fetch_k,fetch_k 是 MMR 算法第一步中,从向量库中初步获取的候选文档数量。
为了理解它,我们首先要明白 MMR 搜索是一个两阶段过程:
-
初步获取 :系统首先根据查询的纯向量相似度,从庞大的向量库中找出最相似的
fetch_k个文档。这一步的目标是"广撒网",先找到一个足够大的相关文档池。 -
重新排序与筛选 :然后,MMR 算法会在这个较小的候选池(大小为
fetch_k)中运行。它不再只考虑与查询的相似度,还会考虑候选文档之间的多样性。它会从这fetch_k个文档中,挑选出既与查询相关,彼此之间又不太相似的k个文档作为最终结果。
因此,其目的就是在保证相关性的前提下,提升结果的多样性。
1.2Pinecone向量存储
对于pinecone向量存储,它的相似性搜索部分,添加文档和删除这些操作和前面说的内存向量存储是一样的使用姿势,主要是初始化上的不同,下面我们介绍一种初始化方式,更详细的方式读者可以参考Pinecone官方文档进行使用.
Pinecone创建索引
Pinecone 是一款专门为 AI 应用设计的托管型向量数据库(Vector Database)。
它主要用于存储和搜索由 Embedding 模型生成的"向量数据",通过高效的近似最近邻(ANN)算法,实现毫秒级的语义搜索和相似度匹配。与 Redis 等多功能数据库不同,Pinecone 是 Serverless(无服务器) 架构的纯向量化存储方案,用户无需管理底层基础设施,只需通过 API 即可处理大规模的向量索引,是构建 RAG(检索增强生成)和智能推荐系统的工业级首选。
注册方式很简单,就是注册一个个人免费版然后获取一个api_key即可,你可以在初始化Pinecone向量存储对象时手动传入你的api_key,也可以自己在电脑里添加环境变量PINECONE_API_KEY。
LangChain 中使用 PineconeVectorStore 类初始化 Pinecone 向量库。我们需要:
- 创建索引。
- 使用索引来初始化
PineconeVectorStore。
下面是一个初始化示例:
python
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
# 建立索引
pc = Pinecone()
index_name = "qa"
if not pc.has_index(index_name):
pc.create_index(
name=index_name, # 索引名称
dimension=3072, # 尺寸,表示向量维度,需要和嵌入模型维度一致
metric="cosine", # 度量方式,cosine 表示余弦相似度
spec=ServerlessSpec(
cloud="aws", # 亚马逊云
region="us-east-1" # 区域
),
)
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 获取索引
index = pc.Index(index_name)
# 定义 Pinecone 向量存储
vector_store = PineconeVectorStore(embedding=embeddings, index=index)class langchain_pinecone.PineconeVectorStore 类,其初始化参数如下:
- embeddings:用于此存储的 Embeddings 实例。
- index:Pinecone 索引
如果我们是第一次创建索引,在 Pinecone 控制台则可以看见被创建的索引。
二.检索器
2.1相关概念
2.1.1检索系统
检索系统(Information Retrieval System, IR System)是一个为了满足用户信息需求,从大规模、非结构化的数据集合中,自动、高效地查找、排序并返回相关信息的计算机系统。
它的核心任务是:在正确的时间,以正确的方式,将正确的信息传递给正确的人。最常见的例子就是:搜索引擎(如 Google、百度)。
随着大型语言模型的流行,检索系统已成为人工智能应用(例如 RAG)的重要组成部分。且存在多种不同类型的检索系统,包括:
- 关系数据库
关系数据库是许多应用程序中使用的结构化数据存储的基本类型。数据存储在行(记录)和列(属性)中,可以通过 SQL(结构化查询语言)进行高效的查询和操作。关系数据库擅长维护数据完整性、支持复杂查询以及处理不同数据实体之间的关系。
- 词法搜索索引
许多搜索引擎基于将查询中的单词与每个文档中的单词进行匹配,这种方法称为词法检索。即一个单词经常出现在用户的查询和特定文档中,那么这个文档可能是一个很好的匹配。这通常使用倒排索引实现。
- 向量数据库
向量存储不使用字频,而是使用嵌入模型将文档转换为高维向量表示。这允许使用余弦相似度等数学运算对嵌入向量进行有效的相似性搜索。
2.1.2检索器
检索器是检索系统中的一个核心组件,它接收来自用户接口的查询(Query),检索出包含查询关键词的候选文档集合。
我们可以使用上面提到的任何检索系统实现方式创建检索器。如关系数据库、向量数据库等。由于其重要性和多样性,LangChain 提供了一个统一的接口来与不同类型的检索系统进行交互。LangChain 的检索器接口非常简单:
- 输入:查询字符串
- 输出:文档列表(标准化的 LangChain 文档对象 Document)
例如,使用关系数据库的检索系统,检索器可以将问题转换为 SQL 语句,并执行查询,最后将查询结果响应用户。(该示例将来会在 LangGraph 中讲解,在这里帮助理解概念即可)
2.2使用向量数据库作为检索器
2.2.1使用向量数据库提供的as_retriever方法
向量存储是索引和检索非结构化数据的一种强大而有效的方法。可以通过调用向量数据库的 as_retriever 方法,将向量存储用作检索器。在这里我们使用 Redis 向量存储。(as_retriever返回的也是一个Runnable方法,我们invoke后返回的是查询到的文档列表,即ListDocument)
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisVectorStore, RedisConfig
from langchain_text_splitters import CharacterTextSplitter
embedding_model = OpenAIEmbeddings(
model="text-embedding-3-large",
base_url="https://api.kourichat.com/v1"
)
redis_url = "redis://:123456@你自己的ip:8090"
#初始化redis向量数据库索引
redis_vector_config = RedisConfig(
index_name="QmlBasicGrammar",#定义索引名称
#key_prefix,不设置默认为index_name
redis_url=redis_url,
metadata_schema=[
{"name" : "category","type" : "tag"},#为每个文档设置分类
{"name" : "id","type" : "numeric"}#每个文档给予一个编号标识符
]
)
redis_vector = RedisVectorStore(
embeddings=embedding_model,
config=redis_vector_config
)
#创建检索器
redis_retriever = redis_vector.as_retriever()
docs = redis_retriever.invoke("附加属性")
print(f"查询出来的各文档id为:{[doc.metadata.get("id") for doc in docs]}")运行结果为:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
查询出来的各文档id为:[48, 50, 49, 54]
进程已结束,退出代码为 0as_retriever 方法也支持我们传递相关参数修改搜索结果,如:
- search_type :设置相似算法,包括:
"similarity"(默认)、"mmr"或"similarity_score_threshold"(相似性分数阈值) - search_kwargs :
- k :限制检索器返回的文档
k数量。 - fetch_k :要传递给 MMR 算法的文档量。
- k :限制检索器返回的文档
我们这里以mmr作为一个例子看下:
python
...
#创建检索器
redis_retriever = redis_vector.as_retriever(
search_type="mmr",
search_kwargs={
"k" : 2,
"fetch_k" : 10
}
)
docs = redis_retriever.invoke("附加属性")
print(f"查询出来的各文档id为:{[doc.metadata.get("id") for doc in docs]}")运行结果如下:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
查询出来的各文档id为:[48, 53]
进程已结束,退出代码为 02.2.2使用@chain
除了使用 as_retriever 方法,我们还可以自行创建一个"检索器"。回想一下检索器的特点:
- LangChain 检索器是一个 Runnable 的对象
- LangChain 检索器输入为查询字符串,输出为文档列表(标准化的 LangChain 文档对象 Document)
python
...
from langchain_core.runnables import chain
from typing import List
#创建检索器
@chain
def retriever(query: str) -> List[Document]:
return redis_vector.similarity_search(query, k=2)
docs = retriever.invoke("附加属性")
print(f"查询出来的各文档id为:{[doc.metadata.get("id") for doc in docs]}")运行结果如下:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
查询出来的各文档id为:[48, 50]
进程已结束,退出代码为 0上面定义了一个函数,使用 @chain 修饰,该修饰可以使其成为 Runnable 函数,且满足检索器输入输出的要求。在函数中,我们依旧使用向量数据库的相似性搜索方法,这样灵活性也更高,想要进行元数据筛选也更方便。
注意,这并不是真正的检索器,检索器是一个 Runnable 对象,而我们定义的只是一个函数,具备其特点罢了。
三.一个简单的RAG综合案例
这里应该加上添加文档部分的,但是我是懒狗,因为之前已经在redis中添加了数据,所以我不想再添加,所以完整的应该是将上面的分割文档部分和add_documents部分添加上,这里我就不添加了:
python
from typing import List
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_redis import RedisVectorStore, RedisConfig
#定义嵌入模型
embedding_model = OpenAIEmbeddings(
model="text-embedding-3-large",
base_url="https://api.kourichat.com/v1"
)
#构建向量数据库连接客户端
redis_url = "redis://:123456@111.231.81.4:8090"
#初始化redis向量数据库索引
redis_vector_config = RedisConfig(
index_name="QmlBasicGrammar",#定义索引名称
#key_prefix,不设置默认为index_name
redis_url=redis_url,
metadata_schema=[
{"name" : "category","type" : "tag"},#为每个文档设置分类
{"name" : "id","type" : "numeric"}#每个文档给予一个编号标识符
]
)
redis_vector = RedisVectorStore(
embeddings=embedding_model,
config=redis_vector_config
)
#定义检索器
retriever = redis_vector.as_retriever()
#定义提示词模板
prompt = ChatPromptTemplate(
[
("system" , "请从检索到的文档中回答用户的问题,如果检索到的文档为空回答:{error},检索到的文档如下:\n{content}\n用户问题为:{question}"),
]
)
#定义LLM模型
model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
#定义输出解析器
parser = StrOutputParser()
##额外:因为LLM接受的是一个文本,所以我们需要将接收到的所有document转为一整段文本喂给LLM
def Convert(docs : List[Document]) -> str:
return "\n\n".join(doc.page_content for doc in docs)
#定义一个完整的RAG链
##因为error,content和question需要一并传入prompt,所以需要使用RunnableParallel,它接收一个字典
##RunnableParallel 的一个强制要求:它要求字典里的每一个 value 都必须是一个 Runnable 对象、函数(Callable) 或另一个 字典。
##RunnablePassthrough()标识此处为一个伪Runnable对象,也就是用户的输入直接穿透到此位置
##实际上question这里的值为我们下面输入的"附加属性"
###注意,这个"附加属性"文本会被传给parallel_tasks_section的所有任务分支,所以error那里lambda必须有一个参数,即便说我们返回的值是固定的
parallel_tasks_section = RunnableParallel({
"content" : retriever | Convert,
"error" : lambda x : "我不知道答案",
"question" : RunnablePassthrough() #也可以这么写 lambda ques : ques
})
chain = parallel_tasks_section | prompt | model | parser
for chunk in chain.stream("附加属性"):
print(chunk,end="",flush=True)
if "。" in chunk :
print("\n")运行后的结果如下:
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
附加属性是一种机制,用于为对象注释额外的属性或信号处理器,这样对象就可以使用这些属性或信号处理器。
它们允许对象访问与特定对象相关的特定属性或信号。
QML类型的实现可以选择在C++中创建附加类型,具有特定的属性和信号,这些类型的实例能够在运行时创建并附加到特定对象上,以使这些对象能够访问附加类型的属性和信号。当
访问这些属性和信号时,需要在属性和信号处理器前加上附加类型的名称。
进程已结束,退出代码为 0如果我们问一个源文档中没有的内容,输出结果如下:
python
for chunk in chain.stream("介绍一下docker"):
print(chunk,end="",flush=True)
if "。" in chunk :
print("\n")
python
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\test15.py
我不知道答案。
进程已结束,退出代码为 0需要注意,我们这里仍然不支持多轮对话,虽然LangChain有一种内存存储对话内容的方式或者我们用循环去保存上下文,但是这些方法要么过时要么占内存。我们将在LangGraph部分再来让我们能写出支持多轮对话的代码。