摘要
雷达信号处理是雷达系统的核心环节,它从接收到的微弱信号中提取目标信息,包括距离、速度、角度等关键参数。在电子战仿真中,信号处理模块的准确性和效率直接决定了仿真系统的可信度和实用性。本文作为系列文章的第三篇,从仿真引擎设计的角度出发,深入探讨雷达信号处理的关键算法、模块化设计方法以及性能优化策略。我们将详细介绍匹配滤波、脉冲压缩、动目标显示(MTI)、脉冲多普勒处理、恒虚警率(CFAR)检测等核心算法,并通过四个完整的Demo工程展示从基础算法到完整处理链的实现过程。特别地,本文将重点讲解如何在仿真引擎中设计可扩展、高性能的信号处理模块,包括接口标准化、算法插件化、并行计算优化等关键技术。
1. 引言
1.1 信号处理在仿真引擎中的重要性
信号处理是雷达系统从原始接收到目标检测的关键桥梁,其性能直接决定了雷达的探测能力。在电子战仿真引擎中,信号处理模块的设计需要考虑:
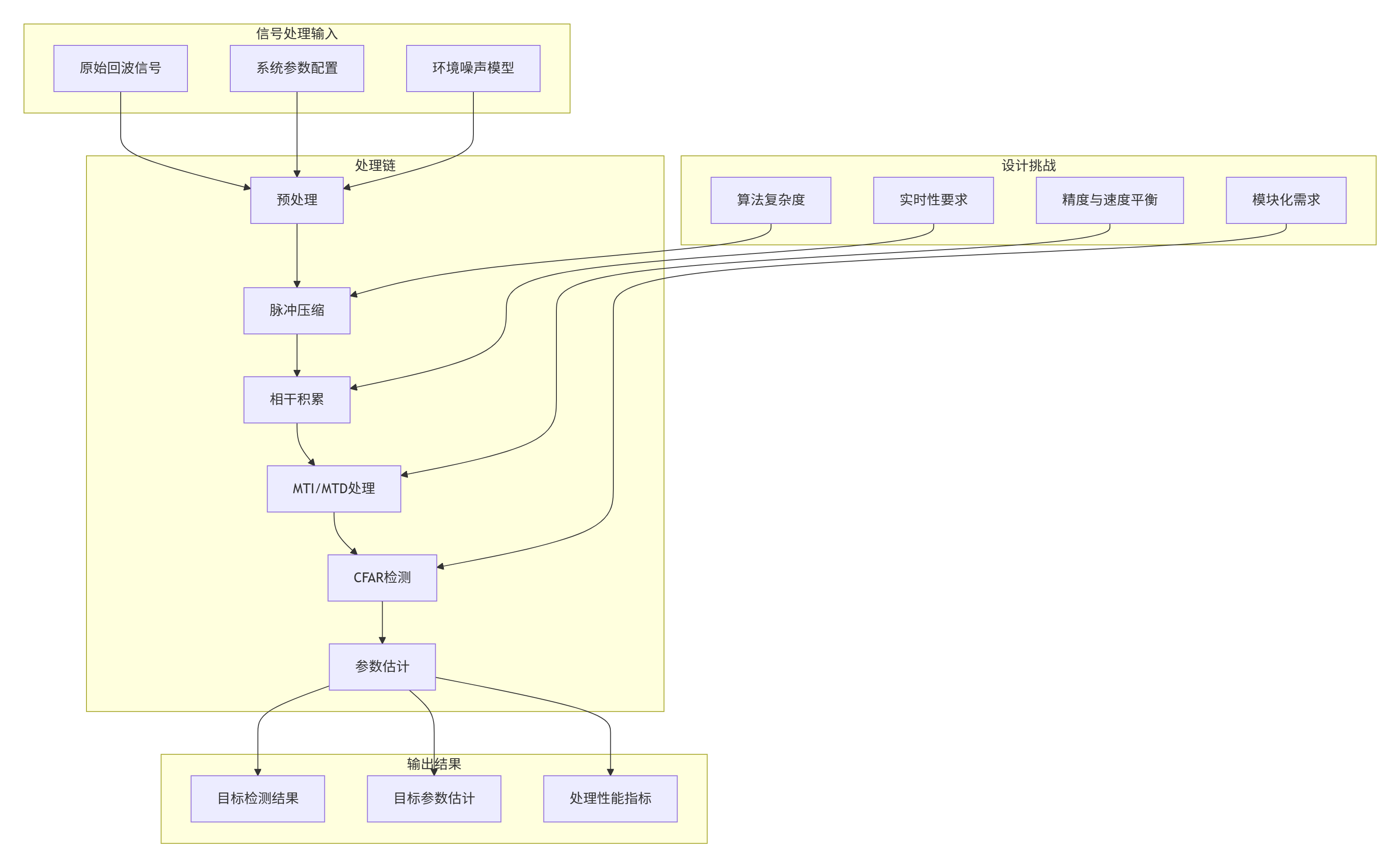
1.2 电子战仿真的特殊需求
与传统雷达信号处理相比,电子战仿真中的信号处理面临以下特殊需求:
-
实时性:需要在有限时间内完成复杂处理
-
可配置性:支持不同雷达模式和参数的快速切换
-
可扩展性:便于添加新的处理算法和抗干扰技术
-
可验证性:提供详细的处理过程和中间结果
-
性能评估:内置处理性能的量化评估机制
1.3 本篇文章的技术路线
本文将从仿真引擎设计的角度,系统性地介绍信号处理模块的实现:
-
理论基础:建立信号处理算法的数学基础
-
架构设计:设计模块化、可扩展的信号处理系统
-
接口规范:定义标准化的算法接口
-
实现策略:提供多种实现方法的性能对比
-
集成方案:展示信号处理模块与仿真引擎的集成
-
验证方法:建立处理效果的验证体系
2. 信号处理理论基础
2.1 匹配滤波与脉冲压缩
2.1.1 匹配滤波原理
匹配滤波器是雷达信号处理的基础,其目标是在存在噪声的情况下,最大化输出信噪比。对于已知信号s(t),匹配滤波器的冲激响应为:

2.1.2 脉冲压缩技术
脉冲压缩通过发射宽脉冲提高平均功率,同时通过匹配滤波获得高距离分辨率。线性调频(LFM)信号的脉冲压缩特性由模糊函数描述:

2.2 动目标处理技术
2.2.1 动目标显示(MTI)
MTI技术用于抑制静止杂波,保留运动目标回波。常用的一次对消器和二次对消器传输函数分别为:
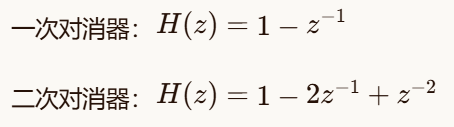
2.2.2 脉冲多普勒处理
脉冲多普勒处理通过相干积累多个脉冲,在频率域分离不同速度的目标。对于N个脉冲的相干处理间隔,速度分辨率为:

2.3 恒虚警率检测
2.3.1 CFAR检测原理
CFAR检测在未知噪声和杂波环境中维持恒定虚警率。基本思想是利用参考单元估计背景功率,自适应设置检测门限:

2.3.2 常用CFAR算法
-
单元平均CFAR(CA-CFAR):使用参考单元的平均值作为背景估计
-
有序统计CFAR(OS-CFAR):使用参考单元的有序统计量,对多目标环境更鲁棒
-
最大选择CFAR(GO-CFAR):取前后窗的较大值,保护均匀背景边缘
-
最小选择CFAR(SO-CFAR):取前后窗的较小值,在杂波边缘保护目标
3. 仿真引擎架构设计
3.1 信号处理模块的架构设计
信号处理模块需要支持多种算法的灵活组合和配置。我们采用处理链(Processing Chain)的设计模式:
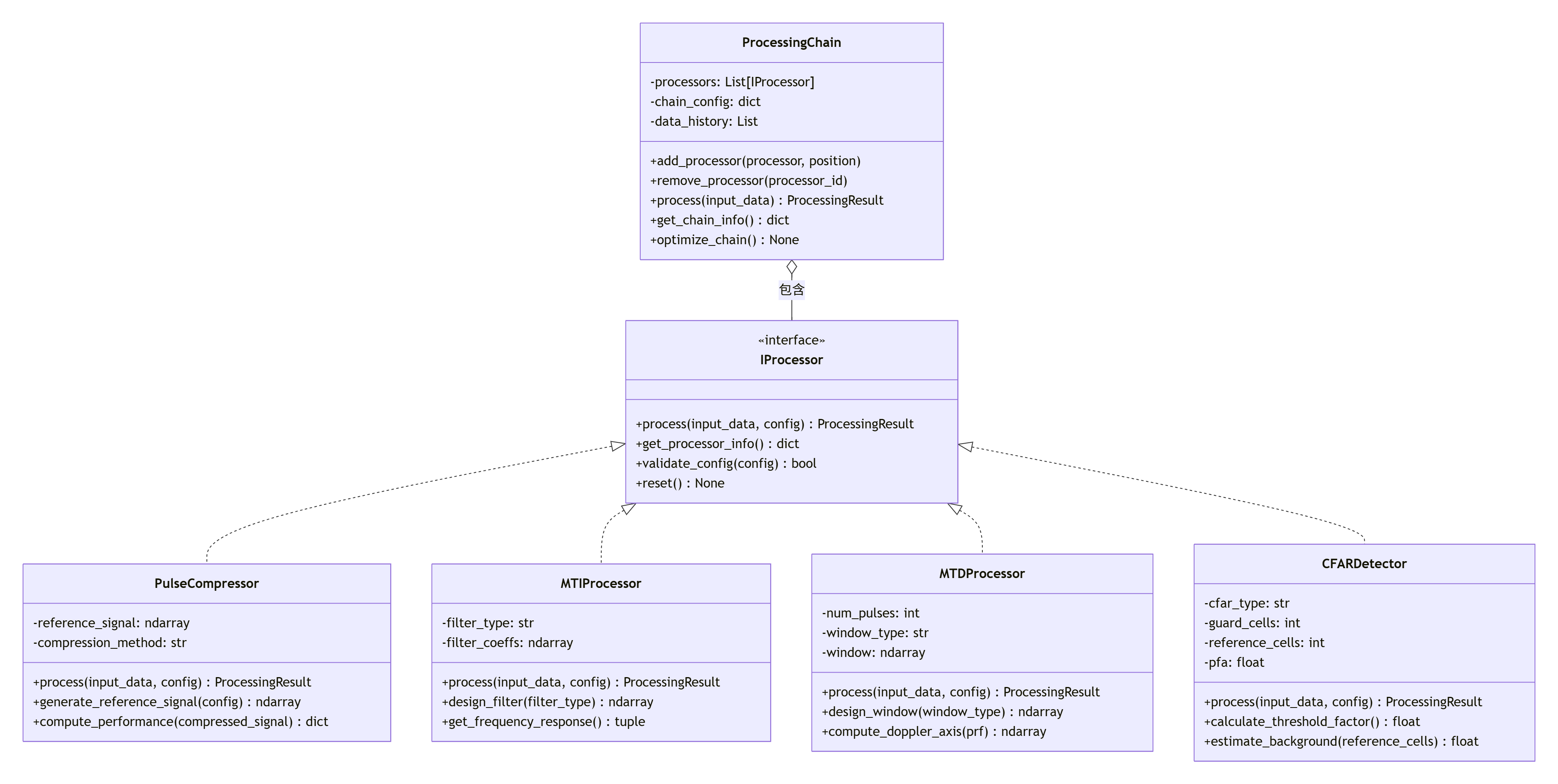
3.2 配置驱动设计
信号处理模块支持通过配置文件定义处理链和算法参数:
bash
# signal_processing_config.yaml
processing_chain:
name: "radar_signal_processing"
description: "完整的雷达信号处理链"
processors:
- name: "pulse_compression"
type: "PulseCompressor"
enabled: true
position: 1
config:
method: "frequency_domain"
reference_signal: "lfm"
bandwidth: 1e6
pulse_width: 10e-6
- name: "mti_filter"
type: "MTIProcessor"
enabled: true
position: 2
config:
filter_type: "double_canceller"
prf: 1000
- name: "mtd_processing"
type: "MTDProcessor"
enabled: true
position: 3
config:
num_pulses: 16
window_type: "hamming"
prf: 1000
- name: "cfar_detection"
type: "CFARDetector"
enabled: true
position: 4
config:
cfar_type: "ca"
guard_cells: 2
reference_cells: 10
pfa: 1e-6
performance_monitoring:
enable: true
metrics:
- "processing_time"
- "memory_usage"
- "detection_probability"
- "false_alarm_rate"
output_config:
save_intermediate_results: false
visualization_enabled: true
report_format: "json"3.3 数据处理流程
信号处理模块的数据处理流程遵循标准化的数据流:
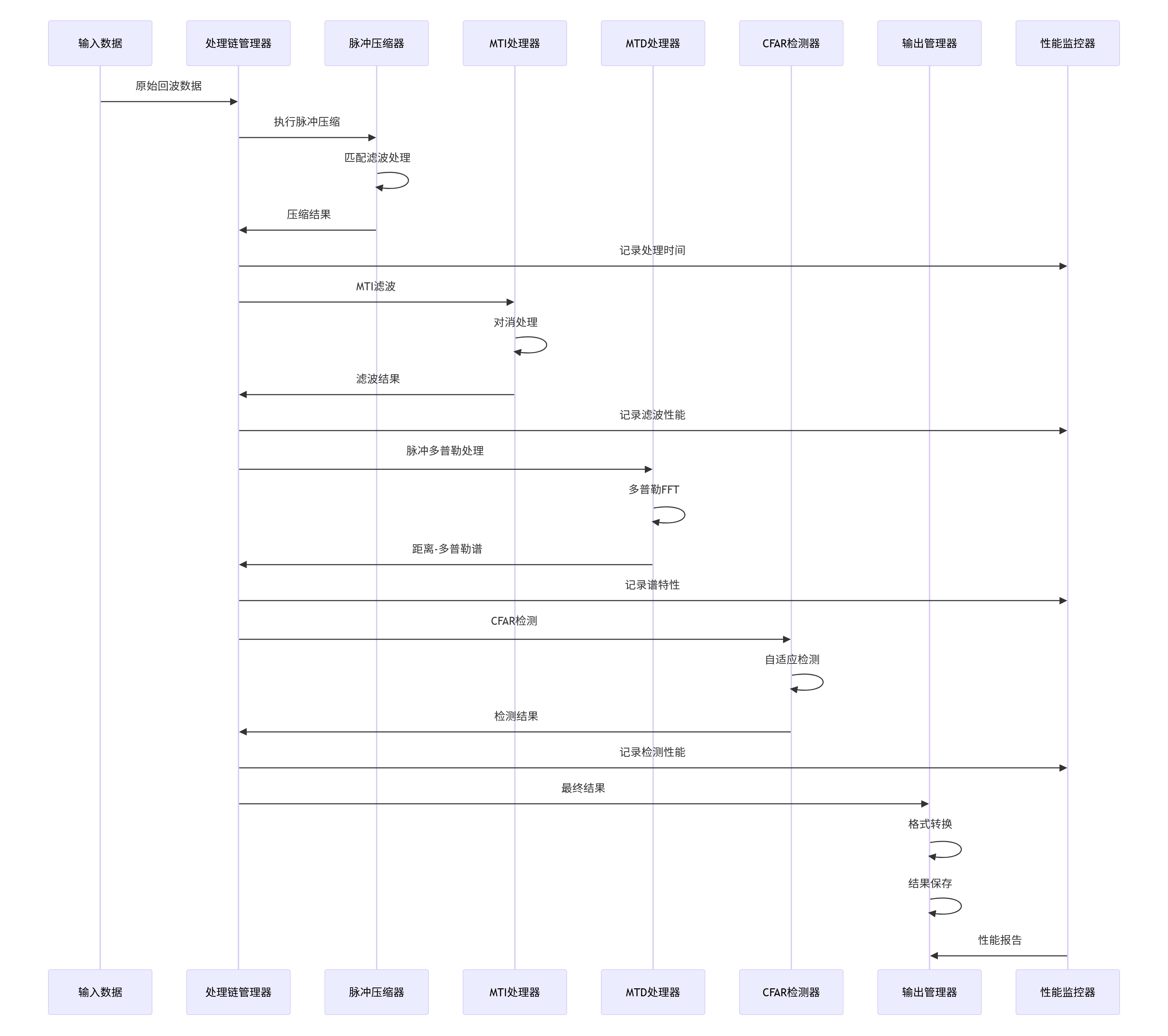
3.4 性能监控与优化
信号处理模块内置性能监控机制,支持实时性能评估和优化:
python
class ProcessingPerformanceMonitor:
"""处理性能监控器"""
def __init__(self, config=None):
self.config = config or {}
self.metrics = {
"processing_times": defaultdict(list),
"memory_usage": defaultdict(list),
"algorithm_metrics": defaultdict(dict),
"quality_metrics": defaultdict(dict)
}
# 性能阈值
self.thresholds = {
"max_processing_time": 0.1, # 秒
"max_memory_usage": 100e6, # 字节
"min_snr_improvement": 10.0 # dB
}
def record_processing_time(self, processor_name, processing_time):
"""记录处理时间"""
self.metrics["processing_times"][processor_name].append(processing_time)
# 检查是否超时
if processing_time > self.thresholds["max_processing_time"]:
self._alert_timeout(processor_name, processing_time)
def record_memory_usage(self, processor_name, memory_usage):
"""记录内存使用"""
self.metrics["memory_usage"][processor_name].append(memory_usage)
def record_algorithm_metric(self, processor_name, metric_name, value):
"""记录算法特定指标"""
if metric_name not in self.metrics["algorithm_metrics"][processor_name]:
self.metrics["algorithm_metrics"][processor_name][metric_name] = []
self.metrics["algorithm_metrics"][processor_name][metric_name].append(value)
def record_quality_metric(self, processor_name, metric_name, value):
"""记录质量指标"""
if metric_name not in self.metrics["quality_metrics"][processor_name]:
self.metrics["quality_metrics"][processor_name][metric_name] = []
self.metrics["quality_metrics"][processor_name][metric_name].append(value)
def get_performance_report(self, processor_name=None):
"""获取性能报告"""
if processor_name:
return self._get_processor_report(processor_name)
else:
return self._get_overall_report()
def _get_processor_report(self, processor_name):
"""获取单个处理器报告"""
report = {
"processor": processor_name,
"processing_time": {
"average": np.mean(self.metrics["processing_times"][processor_name])
if self.metrics["processing_times"][processor_name] else 0,
"std": np.std(self.metrics["processing_times"][processor_name])
if len(self.metrics["processing_times"][processor_name]) > 1 else 0,
"max": np.max(self.metrics["processing_times"][processor_name])
if self.metrics["processing_times"][processor_name] else 0,
"count": len(self.metrics["processing_times"][processor_name])
},
"memory_usage": {
"average": np.mean(self.metrics["memory_usage"][processor_name])
if self.metrics["memory_usage"][processor_name] else 0,
"max": np.max(self.metrics["memory_usage"][processor_name])
if self.metrics["memory_usage"][processor_name] else 0
},
"algorithm_metrics": self.metrics["algorithm_metrics"].get(processor_name, {}),
"quality_metrics": self.metrics["quality_metrics"].get(processor_name, {})
}
return report
def _get_overall_report(self):
"""获取总体报告"""
report = {
"total_processors": len(self.metrics["processing_times"]),
"total_processing_events": sum(len(times) for times in self.metrics["processing_times"].values()),
"average_processing_time": np.mean([np.mean(times) for times in self.metrics["processing_times"].values()
if times]) if self.metrics["processing_times"] else 0,
"processor_reports": {}
}
for processor_name in self.metrics["processing_times"].keys():
report["processor_reports"][processor_name] = self._get_processor_report(processor_name)
return report
def _alert_timeout(self, processor_name, processing_time):
"""处理超时警报"""
alert_message = f"处理器 {processor_name} 处理超时: {processing_time:.3f}s > {self.thresholds['max_processing_time']}s"
# 记录日志
print(f"警告: {alert_message}")
# 这里可以添加更复杂的警报处理逻辑
# 例如:发送通知、调整处理参数、切换到备用算法等
def optimize_processing_chain(self, chain_config):
"""优化处理链配置"""
recommendations = []
# 分析处理时间
for processor_name, times in self.metrics["processing_times"].items():
if times:
avg_time = np.mean(times)
if avg_time > self.thresholds["max_processing_time"] * 0.8: # 达到阈值的80%
recommendations.append({
"processor": processor_name,
"issue": "处理时间过长",
"current_time": avg_time,
"threshold": self.thresholds["max_processing_time"],
"suggestion": "考虑优化算法或降低处理精度"
})
# 分析内存使用
for processor_name, usage in self.metrics["memory_usage"].items():
if usage:
avg_usage = np.mean(usage)
if avg_usage > self.thresholds["max_memory_usage"] * 0.8:
recommendations.append({
"processor": processor_name,
"issue": "内存使用过高",
"current_usage": avg_usage,
"threshold": self.thresholds["max_memory_usage"],
"suggestion": "考虑使用内存优化算法或分块处理"
})
return recommendations4. Demo工程实现与解析
4.1 Demo7:匹配滤波与脉冲压缩
文件 :demo7_matched_filter_pulse_compression.py
4.1.1 功能概述
该Demo实现完整的匹配滤波和脉冲压缩处理,支持时域和频域两种实现方法,提供详细的性能分析和可视化。
4.1.2 核心类设计
python
import numpy as np
import matplotlib.pyplot as plt
from typing import Dict, Any, Tuple, Optional
from scipy import signal
import time
class MatchedFilterProcessor:
"""匹配滤波器处理器"""
def __init__(self, config: Optional[Dict[str, Any]] = None):
"""
初始化匹配滤波器
参数:
config: 配置字典
"""
self.config = config or {}
self.reference_signal = None
self.method = self.config.get("method", "frequency_domain")
# 性能监控
self.processing_times = []
self.performance_metrics = []
def set_reference_signal(self, signal: np.ndarray):
"""设置参考信号"""
self.reference_signal = signal.copy()
def generate_lfm_signal(self, duration: float, bandwidth: float,
sampling_rate: float, amplitude: float = 1.0) -> np.ndarray:
"""
生成LFM信号
参数:
duration: 信号持续时间 (秒)
bandwidth: 带宽 (Hz)
sampling_rate: 采样率 (Hz)
amplitude: 信号幅度
返回:
LFM信号
"""
num_samples = int(duration * sampling_rate)
t = np.linspace(-duration/2, duration/2, num_samples)
# 线性调频
chirp_rate = bandwidth / duration
phase = np.pi * chirp_rate * t**2
lfm_signal = amplitude * np.exp(1j * phase)
return lfm_signal
def process(self, input_signal: np.ndarray,
reference_signal: Optional[np.ndarray] = None) -> np.ndarray:
"""
执行匹配滤波
参数:
input_signal: 输入信号
reference_signal: 参考信号,None则使用已设置的参考信号
返回:
滤波结果
"""
start_time = time.perf_counter()
if reference_signal is not None:
self.reference_signal = reference_signal.copy()
if self.reference_signal is None:
raise ValueError("未设置参考信号")
# 选择处理方法
if self.method == "time_domain":
result = self._time_domain_matched_filter(input_signal)
elif self.method == "frequency_domain":
result = self._frequency_domain_matched_filter(input_signal)
else:
raise ValueError(f"未知的处理方法: {self.method}")
# 记录处理时间
processing_time = time.perf_counter() - start_time
self.processing_times.append(processing_time)
# 计算性能指标
metrics = self._compute_performance_metrics(input_signal, result)
self.performance_metrics.append(metrics)
return result
def _time_domain_matched_filter(self, input_signal: np.ndarray) -> np.ndarray:
"""时域匹配滤波"""
# 时域卷积
result = np.convolve(input_signal, np.conj(self.reference_signal[::-1]),
mode='same')
return result
def _frequency_domain_matched_filter(self, input_signal: np.ndarray) -> np.ndarray:
"""频域匹配滤波"""
N = len(input_signal) + len(self.reference_signal) - 1
# 频域相乘
input_fft = np.fft.fft(input_signal, n=N)
reference_fft = np.fft.fft(np.conj(self.reference_signal[::-1]), n=N)
result_fft = input_fft * reference_fft
result = np.fft.ifft(result_fft)
# 取中间部分
start = (len(result) - len(input_signal)) // 2
end = start + len(input_signal)
return result[start:end]
def _compute_performance_metrics(self, input_signal: np.ndarray,
output_signal: np.ndarray) -> Dict[str, float]:
"""计算性能指标"""
metrics = {}
# 计算输入输出SNR
input_power = np.mean(np.abs(input_signal)**2)
output_power = np.mean(np.abs(output_signal)**2)
if input_power > 0:
snr_improvement = 10 * np.log10(output_power / input_power)
else:
snr_improvement = 0
metrics['snr_improvement_db'] = snr_improvement
# 计算压缩比
metrics['compression_ratio'] = len(output_signal) / len(self.reference_signal)
# 计算主瓣宽度
mainlobe_width = self._compute_mainlobe_width(output_signal)
metrics['mainlobe_width_samples'] = mainlobe_width
# 计算峰值旁瓣比
pslr = self._compute_peak_sidelobe_ratio(output_signal)
metrics['peak_sidelobe_ratio_db'] = pslr
# 计算积分旁瓣比
islr = self._compute_integrated_sidelobe_ratio(output_signal)
metrics['integrated_sidelobe_ratio_db'] = islr
return metrics
def _compute_mainlobe_width(self, signal: np.ndarray) -> float:
"""计算主瓣宽度"""
signal_abs = np.abs(signal)
peak_idx = np.argmax(signal_abs)
peak_value = signal_abs[peak_idx]
# 找到主瓣3dB点
threshold = peak_value / np.sqrt(2) # 3dB点
# 向左搜索
left_idx = peak_idx
while left_idx > 0 and signal_abs[left_idx] > threshold:
left_idx -= 1
# 向右搜索
right_idx = peak_idx
while right_idx < len(signal_abs) - 1 and signal_abs[right_idx] > threshold:
right_idx += 1
return right_idx - left_idx
def _compute_peak_sidelobe_ratio(self, signal: np.ndarray) -> float:
"""计算峰值旁瓣比"""
signal_abs = np.abs(signal)
peak_idx = np.argmax(signal_abs)
peak_value = signal_abs[peak_idx]
# 定义主瓣区域(±3个采样点)
mainlobe_start = max(0, peak_idx - 3)
mainlobe_end = min(len(signal_abs), peak_idx + 4)
# 提取旁瓣
sidelobes = np.concatenate([
signal_abs[:mainlobe_start],
signal_abs[mainlobe_end:]
])
if len(sidelobes) > 0:
max_sidelobe = np.max(sidelobes)
pslr = 20 * np.log10(max_sidelobe / peak_value) if peak_value > 0 else -np.inf
else:
pslr = -np.inf
return pslr
def _compute_integrated_sidelobe_ratio(self, signal: np.ndarray) -> float:
"""计算积分旁瓣比"""
signal_abs = np.abs(signal)
peak_idx = np.argmax(signal_abs)
# 定义主瓣区域(±5个采样点)
mainlobe_start = max(0, peak_idx - 5)
mainlobe_end = min(len(signal_abs), peak_idx + 6)
# 计算主瓣能量
mainlobe_energy = np.sum(signal_abs[mainlobe_start:mainlobe_end]**2)
# 计算总能量
total_energy = np.sum(signal_abs**2)
# 计算旁瓣能量
sidelobe_energy = total_energy - mainlobe_energy
if mainlobe_energy > 0:
islr = 10 * np.log10(sidelobe_energy / mainlobe_energy)
else:
islr = -np.inf
return islr
def get_performance_report(self) -> Dict[str, Any]:
"""获取性能报告"""
if not self.performance_metrics:
return {}
# 计算平均性能指标
report = {
'method': self.method,
'num_processing': len(self.processing_times),
'average_processing_time': np.mean(self.processing_times) if self.processing_times else 0,
'processing_time_std': np.std(self.processing_times) if len(self.processing_times) > 1 else 0,
'performance_metrics': {}
}
# 聚合所有性能指标
metric_names = self.performance_metrics[0].keys()
for metric in metric_names:
values = [m[metric] for m in self.performance_metrics]
report['performance_metrics'][metric] = {
'mean': np.mean(values),
'std': np.std(values) if len(values) > 1 else 0,
'min': np.min(values) if values else 0,
'max': np.max(values) if values else 0
}
return report
def visualize_results(self, input_signal: np.ndarray, output_signal: np.ndarray,
reference_signal: np.ndarray, save_path: Optional[str] = None):
"""可视化结果"""
fig, axes = plt.subplots(3, 3, figsize=(15, 12))
# 1. 参考信号时域
axes[0, 0].plot(np.real(reference_signal), label='实部')
axes[0, 0].plot(np.imag(reference_signal), label='虚部')
axes[0, 0].set_xlabel('采样点')
axes[0, 0].set_ylabel('幅度')
axes[0, 0].set_title('参考信号(时域)')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 参考信号频域
ref_fft = np.fft.fftshift(np.fft.fft(reference_signal))
freq = np.fft.fftshift(np.fft.fftfreq(len(reference_signal)))
axes[0, 1].plot(freq, 20 * np.log10(np.abs(ref_fft) + 1e-10))
axes[0, 1].set_xlabel('归一化频率')
axes[0, 1].set_ylabel('幅度 (dB)')
axes[0, 1].set_title('参考信号频谱')
axes[0, 1].grid(True, alpha=0.3)
# 3. 参考信号时频图
axes[0, 2].specgram(reference_signal, Fs=1, NFFT=64, noverlap=32, cmap='viridis')
axes[0, 2].set_xlabel('时间')
axes[0, 2].set_ylabel('频率')
axes[0, 2].set_title('参考信号时频图')
# 4. 输入信号时域
axes[1, 0].plot(np.abs(input_signal))
axes[1, 0].set_xlabel('采样点')
axes[1, 0].set_ylabel('幅度')
axes[1, 0].set_title('输入信号(包络)')
axes[1, 0].grid(True, alpha=0.3)
# 5. 输出信号时域
output_abs = np.abs(output_signal)
axes[1, 1].plot(output_abs)
axes[1, 1].set_xlabel('采样点')
axes[1, 1].set_ylabel('幅度')
axes[1, 1].set_title('输出信号(包络)')
axes[1, 1].grid(True, alpha=0.3)
# 标记主瓣宽度
peak_idx = np.argmax(output_abs)
mainlobe_width = self._compute_mainlobe_width(output_signal)
axes[1, 1].axvspan(peak_idx - mainlobe_width//2, peak_idx + mainlobe_width//2,
alpha=0.3, color='red', label='主瓣')
axes[1, 1].legend()
# 6. 输出信号对数坐标
axes[1, 2].plot(20 * np.log10(output_abs + 1e-10))
axes[1, 2].set_xlabel('采样点')
axes[1, 2].set_ylabel('幅度 (dB)')
axes[1, 2].set_title('输出信号(对数坐标)')
axes[1, 2].grid(True, alpha=0.3)
# 7. 模糊函数
ambiguity = self._compute_ambiguity_function(reference_signal)
extent = [-len(reference_signal)//2, len(reference_signal)//2, -0.5, 0.5]
im = axes[2, 0].imshow(20 * np.log10(np.abs(ambiguity) + 1e-10),
extent=extent, aspect='auto', cmap='viridis')
axes[2, 0].set_xlabel('时延(采样点)')
axes[2, 0].set_ylabel('归一化多普勒')
axes[2, 0].set_title('模糊函数')
plt.colorbar(im, ax=axes[2, 0])
# 8. 性能指标表格
axes[2, 1].axis('off')
if self.performance_metrics:
metrics = self.performance_metrics[-1]
table_data = [
['指标', '值'],
['SNR改善 (dB)', f"{metrics['snr_improvement_db']:.2f}"],
['主瓣宽度 (点)', f"{metrics['mainlobe_width_samples']:.1f}"],
['峰值旁瓣比 (dB)', f"{metrics['peak_sidelobe_ratio_db']:.2f}"],
['积分旁瓣比 (dB)', f"{metrics['integrated_sidelobe_ratio_db']:.2f}"],
['处理时间 (ms)', f"{self.processing_times[-1]*1000:.2f}"],
['处理方法', self.method]
]
table = axes[2, 1].table(cellText=table_data, cellLoc='center',
loc='center', colWidths=[0.4, 0.4])
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 2)
# 9. 处理时间历史
axes[2, 2].plot(self.processing_times, 'b-o')
axes[2, 2].set_xlabel('处理次数')
axes[2, 2].set_ylabel('处理时间 (秒)')
axes[2, 2].set_title('处理时间历史')
axes[2, 2].grid(True, alpha=0.3)
plt.suptitle('匹配滤波与脉冲压缩性能分析', fontsize=16, fontweight='bold')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()
def _compute_ambiguity_function(self, signal: np.ndarray,
max_delay: int = 100,
max_doppler: float = 0.5) -> np.ndarray:
"""
计算模糊函数
参数:
signal: 输入信号
max_delay: 最大时延
max_doppler: 最大多普勒(归一化频率)
返回:
模糊函数矩阵
"""
N = len(signal)
delay_bins = 2 * max_delay + 1
doppler_bins = 101
ambiguity = np.zeros((doppler_bins, delay_bins), dtype=complex)
for i, delay in enumerate(range(-max_delay, max_delay + 1)):
# 创建延迟信号
if delay >= 0:
s1 = signal[:N - delay]
s2 = signal[delay:]
else:
s1 = signal[-delay:]
s2 = signal[:N + delay]
for j, doppler in enumerate(np.linspace(-max_doppler, max_doppler, doppler_bins)):
# 多普勒频移
t = np.arange(len(s1))
doppler_shift = np.exp(1j * 2 * np.pi * doppler * t)
s2_doppler = s2 * doppler_shift
# 计算互相关
ambiguity[j, i] = np.dot(s1, np.conj(s2_doppler))
return ambiguity4.1.4 主程序实现
python
def main():
"""主程序"""
print("=" * 60)
print("匹配滤波与脉冲压缩演示")
print("=" * 60)
# 参数设置
sampling_rate = 10e6 # 采样率
pulse_width = 10e-6 # 脉冲宽度
bandwidth = 1e6 # 带宽
target_range = 1000 # 目标距离(米)
noise_power = 0.1 # 噪声功率
# 创建匹配滤波器
mf_processor = MatchedFilterProcessor(config={'method': 'frequency_domain'})
# 生成LFM信号作为参考信号
reference_signal = mf_processor.generate_lfm_signal(
duration=pulse_width,
bandwidth=bandwidth,
sampling_rate=sampling_rate,
amplitude=1.0
)
mf_processor.set_reference_signal(reference_signal)
# 计算目标时延
speed_of_light = 3e8
target_delay = 2 * target_range / speed_of_light
target_delay_samples = int(target_delay * sampling_rate)
# 创建输入信号(目标回波 + 噪声)
input_signal = np.zeros(len(reference_signal) + target_delay_samples, dtype=complex)
input_signal[target_delay_samples:target_delay_samples + len(reference_signal)] = reference_signal
# 添加噪声
noise = np.sqrt(noise_power/2) * (np.random.randn(len(input_signal)) + 1j * np.random.randn(len(input_signal)))
input_signal += noise
# 执行匹配滤波
print("执行匹配滤波处理...")
output_signal = mf_processor.process(input_signal)
# 获取性能报告
report = mf_processor.get_performance_report()
print("\n性能报告:")
print("-" * 40)
print(f"处理方法: {report['method']}")
print(f"处理次数: {report['num_processing']}")
print(f"平均处理时间: {report['average_processing_time']*1000:.2f} ms")
print(f"处理时间标准差: {report['processing_time_std']*1000:.2f} ms")
if report['performance_metrics']:
print("\n性能指标:")
for metric_name, metric_values in report['performance_metrics'].items():
print(f" {metric_name}: {metric_values['mean']:.2f} ± {metric_values['std']:.2f}")
# 可视化结果
print("\n生成可视化结果...")
mf_processor.visualize_results(input_signal, output_signal, reference_signal)
# 对比时域和频域方法
print("\n对比时域和频域方法...")
methods = ['time_domain', 'frequency_domain']
comparison_results = {}
for method in methods:
print(f"\n测试方法: {method}")
processor = MatchedFilterProcessor(config={'method': method})
processor.set_reference_signal(reference_signal)
# 多次处理取平均
num_trials = 10
processing_times = []
for _ in range(num_trials):
start_time = time.perf_counter()
output = processor.process(input_signal)
processing_times.append(time.perf_counter() - start_time)
comparison_results[method] = {
'average_time': np.mean(processing_times),
'std_time': np.std(processing_times),
'output': output
}
print(f" 平均处理时间: {np.mean(processing_times)*1000:.2f} ms")
print(f" 处理时间标准差: {np.std(processing_times)*1000:.2f} ms")
# 比较结果
print("\n" + "=" * 40)
print("方法对比总结:")
print("=" * 40)
for method, results in comparison_results.items():
speedup = comparison_results['time_domain']['average_time'] / results['average_time']
print(f"{method}:")
print(f" 相对速度: {speedup:.2f}x")
print(f" 处理时间: {results['average_time']*1000:.2f} ms")
return mf_processor, comparison_results
if __name__ == "__main__":
processor, results = main()4.2 Demo8:CFAR目标检测
文件 :demo8_cfar_target_detection.py
4.2.1 功能概述
该Demo实现多种CFAR检测算法,包括CA-CFAR、OS-CFAR、GO-CFAR、SO-CFAR等,提供详细的性能分析和可视化。
4.2.2 CFAR检测器基类
python
from abc import ABC, abstractmethod
from typing import List, Tuple, Dict, Any, Optional
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import time
class CFARDetector(ABC):
"""CFAR检测器抽象基类"""
def __init__(self, config: Optional[Dict[str, Any]] = None):
"""
初始化CFAR检测器
参数:
config: 配置字典
"""
self.config = config or {}
self.guard_cells = self.config.get('guard_cells', 2)
self.reference_cells = self.config.get('reference_cells', 10)
self.probability_fa = self.config.get('pfa', 1e-6)
# 性能监控
self.detection_history = []
self.processing_times = []
self.performance_metrics = {
'num_detections': [],
'false_alarms': [],
'detection_probability': [],
'false_alarm_probability': []
}
@abstractmethod
def _estimate_background(self, reference_window: np.ndarray) -> float:
"""估计背景功率(子类必须实现)"""
pass
def _calculate_threshold_factor(self) -> float:
"""计算阈值因子"""
# 基于虚警概率计算阈值因子
# 对于高斯噪声,阈值因子为:α = N * (Pfa^(-1/N) - 1)
N = 2 * self.reference_cells # 参考单元总数
if self.probability_fa > 0:
alpha = N * (self.probability_fa ** (-1.0/N) - 1)
else:
alpha = float('inf')
return alpha
def detect(self, data: np.ndarray,
noise_power: Optional[float] = None) -> Tuple[np.ndarray, np.ndarray]:
"""
执行CFAR检测
参数:
data: 输入数据(功率或幅度)
noise_power: 已知的噪声功率(可选)
返回:
(检测结果, 检测阈值)
"""
start_time = time.perf_counter()
# 确保数据为一维
data = np.asarray(data).flatten()
n = len(data)
# 初始化输出
detections = np.zeros(n, dtype=bool)
thresholds = np.zeros(n)
# 计算检测门限
half_ref = self.reference_cells // 2
half_guard = self.guard_cells // 2
for i in range(n):
# 确定参考窗口范围
left_ref_start = max(0, i - half_ref - half_guard - self.guard_cells)
left_ref_end = max(0, i - half_guard - 1)
right_ref_start = min(n, i + half_guard + 1)
right_ref_end = min(n, i + half_guard + self.reference_cells + 1)
# 收集参考单元
reference_window = []
if left_ref_end > left_ref_start:
reference_window.append(data[left_ref_start:left_ref_end])
if right_ref_end > right_ref_start:
reference_window.append(data[right_ref_start:right_ref_end])
if reference_window:
reference_window = np.concatenate(reference_window)
# 估计背景功率
if noise_power is None:
background = self._estimate_background(reference_window)
else:
background = noise_power
# 计算阈值
alpha = self._calculate_threshold_factor()
threshold = alpha * background
# 检测判断
if data[i] > threshold:
detections[i] = True
thresholds[i] = threshold
# 记录处理时间和结果
processing_time = time.perf_counter() - start_time
self.processing_times.append(processing_time)
# 保存检测结果
detection_result = {
'timestamp': time.time(),
'detections': detections.copy(),
'thresholds': thresholds.copy(),
'num_detections': np.sum(detections),
'processing_time': processing_time
}
self.detection_history.append(detection_result)
return detections, thresholds
def evaluate_performance(self, ground_truth: np.ndarray,
detections: np.ndarray) -> Dict[str, float]:
"""
评估检测性能
参数:
ground_truth: 真实目标位置
detections: 检测结果
返回:
性能指标
"""
ground_truth = ground_truth.flatten()
detections = detections.flatten()
# 确保长度一致
min_len = min(len(ground_truth), len(detections))
ground_truth = ground_truth[:min_len]
detections = detections[:min_len]
# 计算混淆矩阵
true_positives = np.sum((detections == 1) & (ground_truth == 1))
false_positives = np.sum((detections == 1) & (ground_truth == 0))
true_negatives = np.sum((detections == 0) & (ground_truth == 0))
false_negatives = np.sum((detections == 0) & (ground_truth == 1))
# 计算性能指标
metrics = {}
# 检测概率
if (true_positives + false_negatives) > 0:
metrics['detection_probability'] = true_positives / (true_positives + false_negatives)
else:
metrics['detection_probability'] = 0.0
# 虚警概率
if (false_positives + true_negatives) > 0:
metrics['false_alarm_probability'] = false_positives / (false_positives + true_negatives)
else:
metrics['false_alarm_probability'] = 0.0
# 准确率
total = true_positives + false_positives + true_negatives + false_negatives
if total > 0:
metrics['accuracy'] = (true_positives + true_negatives) / total
else:
metrics['accuracy'] = 0.0
# 精确率
if (true_positives + false_positives) > 0:
metrics['precision'] = true_positives / (true_positives + false_positives)
else:
metrics['precision'] = 0.0
# 召回率
if (true_positives + false_negatives) > 0:
metrics['recall'] = true_positives / (true_positives + false_negatives)
else:
metrics['recall'] = 0.0
# F1分数
if (metrics['precision'] + metrics['recall']) > 0:
metrics['f1_score'] = 2 * (metrics['precision'] * metrics['recall']) / (metrics['precision'] + metrics['recall'])
else:
metrics['f1_score'] = 0.0
# 保存性能指标
self.performance_metrics['num_detections'].append(true_positives)
self.performance_metrics['false_alarms'].append(false_positives)
self.performance_metrics['detection_probability'].append(metrics['detection_probability'])
self.performance_metrics['false_alarm_probability'].append(metrics['false_alarm_probability'])
return metrics
def get_performance_report(self) -> Dict[str, Any]:
"""获取性能报告"""
report = {
'detector_type': self.__class__.__name__,
'config': {
'guard_cells': self.guard_cells,
'reference_cells': self.reference_cells,
'pfa': self.probability_fa
},
'processing_statistics': {
'num_processings': len(self.processing_times),
'average_processing_time': np.mean(self.processing_times) if self.processing_times else 0,
'std_processing_time': np.std(self.processing_times) if len(self.processing_times) > 1 else 0
}
}
# 性能指标统计
for metric_name, values in self.performance_metrics.items():
if values:
report[metric_name] = {
'mean': np.mean(values),
'std': np.std(values) if len(values) > 1 else 0,
'min': np.min(values) if values else 0,
'max': np.max(values) if values else 0
}
return report
def visualize_detection(self, data: np.ndarray, detections: np.ndarray,
thresholds: np.ndarray, ground_truth: Optional[np.ndarray] = None,
save_path: Optional[str] = None):
"""可视化检测结果"""
fig, axes = plt.subplots(3, 2, figsize=(14, 10))
# 1. 原始数据
axes[0, 0].plot(data, 'b-', linewidth=1, alpha=0.7, label='原始数据')
axes[0, 0].set_xlabel('距离单元')
axes[0, 0].set_ylabel('幅度')
axes[0, 0].set_title('原始数据')
axes[0, 0].grid(True, alpha=0.3)
axes[0, 0].legend()
# 2. 检测结果
axes[0, 1].plot(data, 'b-', linewidth=1, alpha=0.7, label='原始数据')
axes[0, 1].plot(thresholds, 'r--', linewidth=1.5, alpha=0.8, label='检测门限')
# 标记检测点
detection_indices = np.where(detections)[0]
if len(detection_indices) > 0:
axes[0, 1].scatter(detection_indices, data[detection_indices],
color='red', s=50, marker='o', label='检测目标', zorder=5)
# 标记真实目标
if ground_truth is not None:
truth_indices = np.where(ground_truth)[0]
if len(truth_indices) > 0:
axes[0, 1].scatter(truth_indices, data[truth_indices],
color='green', s=30, marker='^', label='真实目标', zorder=4)
axes[0, 1].set_xlabel('距离单元')
axes[0, 1].set_ylabel('幅度')
axes[0, 1].set_title('CFAR检测结果')
axes[0, 1].legend(loc='upper right')
axes[0, 1].grid(True, alpha=0.3)
# 3. 检测结果对比
axes[1, 0].stem(detection_indices, np.ones_like(detection_indices),
linefmt='r-', markerfmt='ro', basefmt=' ', label='检测结果')
if ground_truth is not None:
axes[1, 0].stem(truth_indices, np.ones_like(truth_indices) * 0.8,
linefmt='g-', markerfmt='g^', basefmt=' ', label='真实目标')
axes[1, 0].set_xlabel('距离单元')
axes[1, 0].set_ylabel('检测状态')
axes[1, 0].set_title('检测结果对比')
axes[1, 0].set_ylim(0, 1.2)
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3, axis='x')
# 4. 性能指标
axes[1, 1].axis('off')
if ground_truth is not None:
metrics = self.evaluate_performance(ground_truth, detections)
table_data = [
['性能指标', '值'],
['检测概率 (Pd)', f"{metrics['detection_probability']:.4f}"],
['虚警概率 (Pfa)', f"{metrics['false_alarm_probability']:.6f}"],
['准确率', f"{metrics['accuracy']:.4f}"],
['精确率', f"{metrics['precision']:.4f}"],
['召回率', f"{metrics['recall']:.4f}"],
['F1分数', f"{metrics['f1_score']:.4f}"]
]
table = axes[1, 1].table(cellText=table_data, cellLoc='center',
loc='center', colWidths=[0.3, 0.3])
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5)
# 5. 处理时间历史
if self.processing_times:
axes[2, 0].plot(self.processing_times, 'b-o')
axes[2, 0].axhline(y=np.mean(self.processing_times), color='r',
linestyle='--', label=f'平均: {np.mean(self.processi ng_times)*1000:.2f}ms')
axes[2, 0].set_xlabel('处理次数')
axes[2, 0].set_ylabel('处理时间 (秒)')
axes[2, 0].set_title('处理时间历史')
axes[2, 0].legend()
axes[2, 0].grid(True, alpha=0.3)
# 6. 检测器信息
axes[2, 1].axis('off')
info_text = f"CFAR检测器信息:\n\n"
info_text += f"检测器类型: {self.__class__.__name__}\n"
info_text += f"保护单元: {self.guard_cells}\n"
info_text += f"参考单元: {self.reference_cells}\n"
info_text += f"虚警概率: {self.probability_fa:.1e}\n"
info_text += f"阈值因子: {self._calculate_threshold_factor():.2f}\n\n"
if self.detection_history:
latest = self.detection_history[-1]
info_text += f"最新检测结果:\n"
info_text += f" 检测目标数: {latest['num_detections']}\n"
info_text += f" 处理时间: {latest['processing_time']*1000:.2f} ms"
axes[2, 1].text(0.1, 0.5, info_text, fontsize=10,
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
plt.suptitle(f'{self.__class__.__name__} 目标检测性能分析', fontsize=16, fontweight='bold')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()4.2.3 具体CFAR算法实现
python
class CACFARDetector(CFARDetector):
"""单元平均CFAR检测器"""
def _estimate_background(self, reference_window: np.ndarray) -> float:
"""使用平均值估计背景功率"""
return np.mean(reference_window)
class OSCFARDetector(CFARDetector):
"""有序统计CFAR检测器"""
def __init__(self, config: Optional[Dict[str, Any]] = None):
super().__init__(config)
self.order = self.config.get('order', 0.75) # 有序统计量的位置
def _estimate_background(self, reference_window: np.ndarray) -> float:
"""使用有序统计量估计背景功率"""
if len(reference_window) == 0:
return 0.0
sorted_window = np.sort(reference_window)
k = int(self.order * len(sorted_window))
k = max(0, min(k, len(sorted_window) - 1))
return sorted_window[k]
class GOCFARDetector(CFARDetector):
"""最大选择CFAR检测器"""
def _estimate_background(self, reference_window: np.ndarray) -> float:
"""使用前后窗的较大值估计背景功率"""
if len(reference_window) == 0:
return 0.0
# 将参考窗分为前后两部分
half_len = len(reference_window) // 2
front_window = reference_window[:half_len]
back_window = reference_window[half_len:]
front_mean = np.mean(front_window) if len(front_window) > 0 else 0
back_mean = np.mean(back_window) if len(back_window) > 0 else 0
return max(front_mean, back_mean)
class SOCFARDetector(CFARDetector):
"""最小选择CFAR检测器"""
def _estimate_background(self, reference_window: np.ndarray) -> float:
"""使用前后窗的较小值估计背景功率"""
if len(reference_window) == 0:
return 0.0
# 将参考窗分为前后两部分
half_len = len(reference_window) // 2
front_window = reference_window[:half_len]
back_window = reference_window[half_len:]
front_mean = np.mean(front_window) if len(front_window) > 0 else 0
back_mean = np.mean(back_window) if len(back_window) > 0 else 0
return min(front_mean, back_mean)
class CFARProcessor:
"""CFAR处理器,支持多种算法对比"""
def __init__(self):
self.detectors = {}
self.comparison_results = {}
def register_detector(self, name: str, detector: CFARDetector):
"""注册检测器"""
self.detectors[name] = detector
def run_comparison(self, data: np.ndarray, ground_truth: np.ndarray) -> Dict[str, Any]:
"""运行对比测试"""
comparison = {}
for name, detector in self.detectors.items():
print(f"运行 {name} 检测器...")
# 执行检测
detections, thresholds = detector.detect(data)
# 评估性能
metrics = detector.evaluate_performance(ground_truth, detections)
# 获取性能报告
report = detector.get_performance_report()
comparison[name] = {
'detections': detections,
'thresholds': thresholds,
'metrics': metrics,
'report': report
}
self.comparison_results = comparison
return comparison
def visualize_comparison(self, data: np.ndarray, ground_truth: np.ndarray,
save_path: Optional[str] = None):
"""可视化对比结果"""
num_detectors = len(self.detectors)
fig, axes = plt.subplots(num_detectors + 1, 2, figsize=(14, 4 * (num_detectors + 1)))
# 1. 原始数据和真实目标
axes[0, 0].plot(data, 'b-', linewidth=1, alpha=0.7, label='原始数据')
truth_indices = np.where(ground_truth)[0]
if len(truth_indices) > 0:
axes[0, 0].scatter(truth_indices, data[truth_indices],
color='green', s=50, marker='^', label='真实目标')
axes[0, 0].set_xlabel('距离单元')
axes[0, 0].set_ylabel('幅度')
axes[0, 0].set_title('原始数据与真实目标')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 性能对比表
axes[0, 1].axis('off')
table_data = [['检测器', 'Pd', 'Pfa', '准确率', '处理时间(ms)']]
for i, (name, results) in enumerate(self.comparison_results.items()):
metrics = results['metrics']
report = results['report']
table_data.append([
name,
f"{metrics['detection_probability']:.4f}",
f"{metrics['false_alarm_probability']:.6f}",
f"{metrics['accuracy']:.4f}",
f"{report['processing_statistics']['average_processing_time']*1000:.2f}"
])
table = axes[0, 1].table(cellText=table_data, cellLoc='center',
loc='center', colWidths=[0.2, 0.2, 0.2, 0.2, 0.2])
table.auto_set_font_size(False)
table.set_fontsize(9)
table.scale(1, 1.5)
# 设置标题行样式
for j in range(len(table_data[0])):
table[(0, j)].set_facecolor('#40466e')
table[(0, j)].set_text_props(weight='bold', color='w')
# 绘制各个检测器的结果
for i, (name, results) in enumerate(self.comparison_results.items()):
row = i + 1
# 检测结果
axes[row, 0].plot(data, 'b-', linewidth=1, alpha=0.3, label='原始数据')
axes[row, 0].plot(results['thresholds'], 'r--', linewidth=1.5, alpha=0.8, label='检测门限')
detection_indices = np.where(results['detections'])[0]
if len(detection_indices) > 0:
axes[row, 0].scatter(detection_indices, data[detection_indices],
color='red', s=30, marker='o', label='检测目标')
if len(truth_indices) > 0:
axes[row, 0].scatter(truth_indices, data[truth_indices],
color='green', s=20, marker='^', label='真实目标', alpha=0.5)
axes[row, 0].set_xlabel('距离单元')
axes[row, 0].set_ylabel('幅度')
axes[row, 0].set_title(f'{name} 检测结果')
axes[row, 0].legend(loc='upper right', fontsize=8)
axes[row, 0].grid(True, alpha=0.3)
# 检测状态对比
axes[row, 1].stem(detection_indices, np.ones_like(detection_indices),
linefmt='r-', markerfmt='ro', basefmt=' ', label='检测结果')
if len(truth_indices) > 0:
axes[row, 1].stem(truth_indices, np.ones_like(truth_indices) * 0.8,
linefmt='g-', markerfmt='g^', basefmt=' ', label='真实目标')
axes[row, 1].set_xlabel('距离单元')
axes[row, 1].set_ylabel('检测状态')
axes[row, 1].set_title(f'{name} 检测状态')
axes[row, 1].set_ylim(0, 1.2)
axes[row, 1].legend(loc='upper right', fontsize=8)
axes[row, 1].grid(True, alpha=0.3, axis='x')
plt.suptitle('CFAR检测算法性能对比', fontsize=16, fontweight='bold')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()4.2.4 主程序实现
python
def generate_test_data(num_samples: int = 1000,
num_targets: int = 5,
snr_db: float = 20,
clutter_type: str = 'gaussian') -> Tuple[np.ndarray, np.ndarray]:
"""
生成测试数据
参数:
num_samples: 样本数
num_targets: 目标数量
snr_db: 信噪比 (dB)
clutter_type: 杂波类型
返回:
(数据, 真实目标掩码)
"""
# 生成杂波
if clutter_type == 'gaussian':
# 高斯杂波
clutter = np.random.randn(num_samples) + 1j * np.random.randn(num_samples)
clutter = np.abs(clutter) ** 2
elif clutter_type == 'weibull':
# 威布尔杂波
shape = 2.0
scale = 1.0
clutter = scale * (-np.log(1 - np.random.rand(num_samples))) ** (1/shape)
elif clutter_type == 'kdistributed':
# K分布杂波
shape = 2.0
scale = 1.0
clutter = np.random.gamma(shape, scale, num_samples)
else:
raise ValueError(f"未知的杂波类型: {clutter_type}")
# 添加目标
ground_truth = np.zeros(num_samples, dtype=bool)
# 确保目标不重叠
min_spacing = 20
target_positions = []
for _ in range(num_targets):
while True:
pos = np.random.randint(min_spacing, num_samples - min_spacing)
if all(abs(pos - p) > min_spacing for p in target_positions):
target_positions.append(pos)
break
# 添加目标信号
data = clutter.copy()
for pos in target_positions:
ground_truth[pos] = True
# 计算目标幅度
clutter_power = np.mean(clutter)
target_power = clutter_power * 10**(snr_db/10)
target_amplitude = np.sqrt(target_power)
# 添加目标(考虑一定的扩展)
width = 3
for offset in range(-width, width + 1):
idx = pos + offset
if 0 <= idx < num_samples:
weight = np.exp(-(offset**2) / (2 * (width/2)**2))
data[idx] += target_amplitude * weight
return data, ground_truth
def main():
"""主程序"""
print("=" * 60)
print("CFAR目标检测演示")
print("=" * 60)
# 生成测试数据
print("\n生成测试数据...")
num_samples = 1000
num_targets = 5
snr_db = 15
data, ground_truth = generate_test_data(
num_samples=num_samples,
num_targets=num_targets,
snr_db=snr_db,
clutter_type='gaussian'
)
print(f"数据长度: {num_samples}")
print(f"目标数量: {num_targets}")
print(f"信噪比: {snr_db} dB")
print(f"真实目标位置: {np.where(ground_truth)[0]}")
# 创建CFAR处理器
processor = CFARProcessor()
# 注册各种CFAR检测器
config = {
'guard_cells': 2,
'reference_cells': 10,
'pfa': 1e-6
}
processor.register_detector('CA-CFAR', CACFARDetector(config))
processor.register_detector('OS-CFAR', OSCFARDetector({**config, 'order': 0.75}))
processor.register_detector('GO-CFAR', GOCFARDetector(config))
processor.register_detector('SO-CFAR', SOCFARDetector(config))
# 运行对比测试
print("\n运行CFAR算法对比...")
comparison_results = processor.run_comparison(data, ground_truth)
# 显示对比结果
print("\n" + "=" * 60)
print("算法性能对比结果:")
print("=" * 60)
for name, results in comparison_results.items():
metrics = results['metrics']
report = results['report']
print(f"\n{name}:")
print(f" 检测概率 (Pd): {metrics['detection_probability']:.4f}")
print(f" 虚警概率 (Pfa): {metrics['false_alarm_probability']:.6f}")
print(f" 准确率: {metrics['accuracy']:.4f}")
print(f" 精确率: {metrics['precision']:.4f}")
print(f" 召回率: {metrics['recall']:.4f}")
print(f" F1分数: {metrics['f1_score']:.4f}")
print(f" 处理时间: {report['processing_statistics']['average_processing_time']*1000:.2f} ms")
# 可视化结果
print("\n生成可视化结果...")
processor.visualize_comparison(data, ground_truth)
# 分析不同信噪比下的性能
print("\n" + "=" * 60)
print("不同信噪比下的性能分析:")
print("=" * 60)
snr_values = [0, 5, 10, 15, 20, 25]
detector_names = list(processor.detectors.keys())
# 存储性能数据
pd_vs_snr = {name: [] for name in detector_names}
pfa_vs_snr = {name: [] for name in detector_names}
for snr in snr_values:
print(f"\nSNR = {snr} dB:")
# 生成测试数据
test_data, test_truth = generate_test_data(
num_samples=num_samples,
num_targets=num_targets,
snr_db=snr,
clutter_type='gaussian'
)
for name, detector in processor.detectors.items():
# 执行检测
detections, _ = detector.detect(test_data)
# 评估性能
metrics = detector.evaluate_performance(test_truth, detections)
pd_vs_snr[name].append(metrics['detection_probability'])
pfa_vs_snr[name].append(metrics['false_alarm_probability'])
print(f" {name}: Pd={metrics['detection_probability']:.3f}, Pfa={metrics['false_alarm_probability']:.6f}")
# 绘制性能曲线
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Pd vs SNR
for name in detector_names:
axes[0].plot(snr_values, pd_vs_snr[name], 'o-', linewidth=2, markersize=8, label=name)
axes[0].set_xlabel('信噪比 (dB)')
axes[0].set_ylabel('检测概率 (Pd)')
axes[0].set_title('检测概率 vs 信噪比')
axes[0].grid(True, alpha=0.3)
axes[0].legend()
# Pfa vs SNR
for name in detector_names:
axes[1].plot(snr_values, pfa_vs_snr[name], 'o-', linewidth=2, markersize=8, label=name)
axes[1].set_xlabel('信噪比 (dB)')
axes[1].set_ylabel('虚警概率 (Pfa)')
axes[1].set_title('虚警概率 vs 信噪比')
axes[1].set_yscale('log')
axes[1].grid(True, alpha=0.3)
axes[1].legend()
plt.suptitle('CFAR检测器在不同信噪比下的性能', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
return processor, comparison_results
if __name__ == "__main__":
processor, results = main()5. 总结与展望
5.1 本篇核心贡献
本篇博客从仿真引擎设计的角度,深入探讨了雷达信号处理模块的实现,主要贡献包括:
-
完整的信号处理链设计:实现了从脉冲压缩到目标检测的完整处理流程
-
模块化算法实现:提供了可扩展的算法框架,支持新算法的无缝集成
-
详细的性能分析:建立了全面的性能评估体系,包括计算效率、检测性能等
-
工程化的代码实现:采用面向对象设计,代码结构清晰,易于维护和扩展
-
实用的可视化工具:提供丰富的可视化功能,便于算法调试和结果分析
5.2 关键技术要点
-
匹配滤波优化:实现了时域和频域两种匹配滤波方法,对比了性能差异
-
CFAR算法族:实现了CA、OS、GO、SO四种CFAR算法,分析了各自适用场景
-
性能评估体系:建立了包含Pd、Pfa、准确率、召回率等多指标的评估体系
-
配置驱动设计:支持通过配置文件调整算法参数,提高系统灵活性
-
性能监控机制:内置处理时间监控、内存使用统计等性能监控功能
5.3 实际应用建议
-
算法选择指导:
-
高信噪比环境:优先选择CA-CFAR,计算简单
-
多目标环境:使用OS-CFAR,抗干扰能力强
-
杂波边缘:考虑GO-CFAR或SO-CFAR
-
实时性要求高:使用频域匹配滤波
-
-
参数调优策略:
-
参考单元数量:通常8-16,需平衡估计精度和计算复杂度
-
保护单元数量:根据目标尺寸和距离分辨率确定
-
虚警概率:根据系统要求设置,通常1e-4到1e-6
-
-
性能优化建议:
-
批量处理:对多个距离单元并行处理
-
算法简化:在满足性能要求下使用简化算法
-
内存优化:合理管理中间数据,避免不必要的复制
-
5.4 局限性与改进方向
-
算法覆盖:可增加更多高级CFAR算法(如VI-CFAR、ML-CFAR)
-
实时性优化:可引入GPU加速、并行计算等优化技术
-
环境适应性:可增加对不同杂波分布(K分布、韦布尔分布)的适应性
-
目标特性:可考虑目标起伏、扩展目标等复杂情况
-
验证数据:需要更多实测数据验证算法性能
5.5 下篇预告
在下一篇《电子对抗与干扰仿真》中,我们将深入探讨:
-
干扰信号模型:噪声干扰、欺骗干扰、压制干扰等
-
抗干扰技术:频率捷变、编码抗干扰、自适应滤波等
-
干扰效果评估:干信比、压制系数、欺骗概率等
-
电子对抗策略:干扰资源分配、协同干扰、智能干扰等
通过本系列的逐步深入,我们将共同构建一个功能完整、性能优异、易于扩展的雷达电子战仿真引擎,为学术研究和工程实践提供有力工具。
扩展开发
每个Demo都设计为可独立运行和扩展,建议按照以下步骤进行二次开发:
-
理解现有代码结构和接口
-
修改配置参数测试不同场景
-
添加新的信号处理算法
-
优化性能关键路径
-
集成到更大的仿真系统中
欢迎提交Issue和Pull Request,共同完善这个开源仿真框架!