📊 阅读时长:25分钟 | 关键词:正则表达式进阶、Lookahead、Lookbehind、实战案例、日志解析
引言:当你需要"更聪明"的匹配
上一篇文章中,我们学完了正则表达式的核心语法------元字符、字符集、量词、分组、基础函数。这些已经能解决 80% 的正则需求。
但实际工作中,你会遇到这样的需求:
- 匹配"后面跟着
password的单词",但不包含password本身 - 匹配"前面是
$的数字",但不包含$本身 - 匹配"不在引号内的逗号"(用于 CSV 解析)
- 匹配重叠的字符串
这些需求用基础语法很难优雅地解决。今天这篇文章,我们来讲进阶特性,让你能写出更精准、更强大的正则表达式。
一、环视(Lookahead & Lookbehind):匹配"位置"而不是"字符"
1.1 什么是环视?
普通的正则匹配是"吃掉"字符的------匹配到了就把字符消耗掉,后续匹配从下一个字符继续。
环视(Lookaround)不同------它只检查某个位置的前面或后面是否符合条件 ,但不消耗字符,也不会把条件中的内容纳入匹配结果。
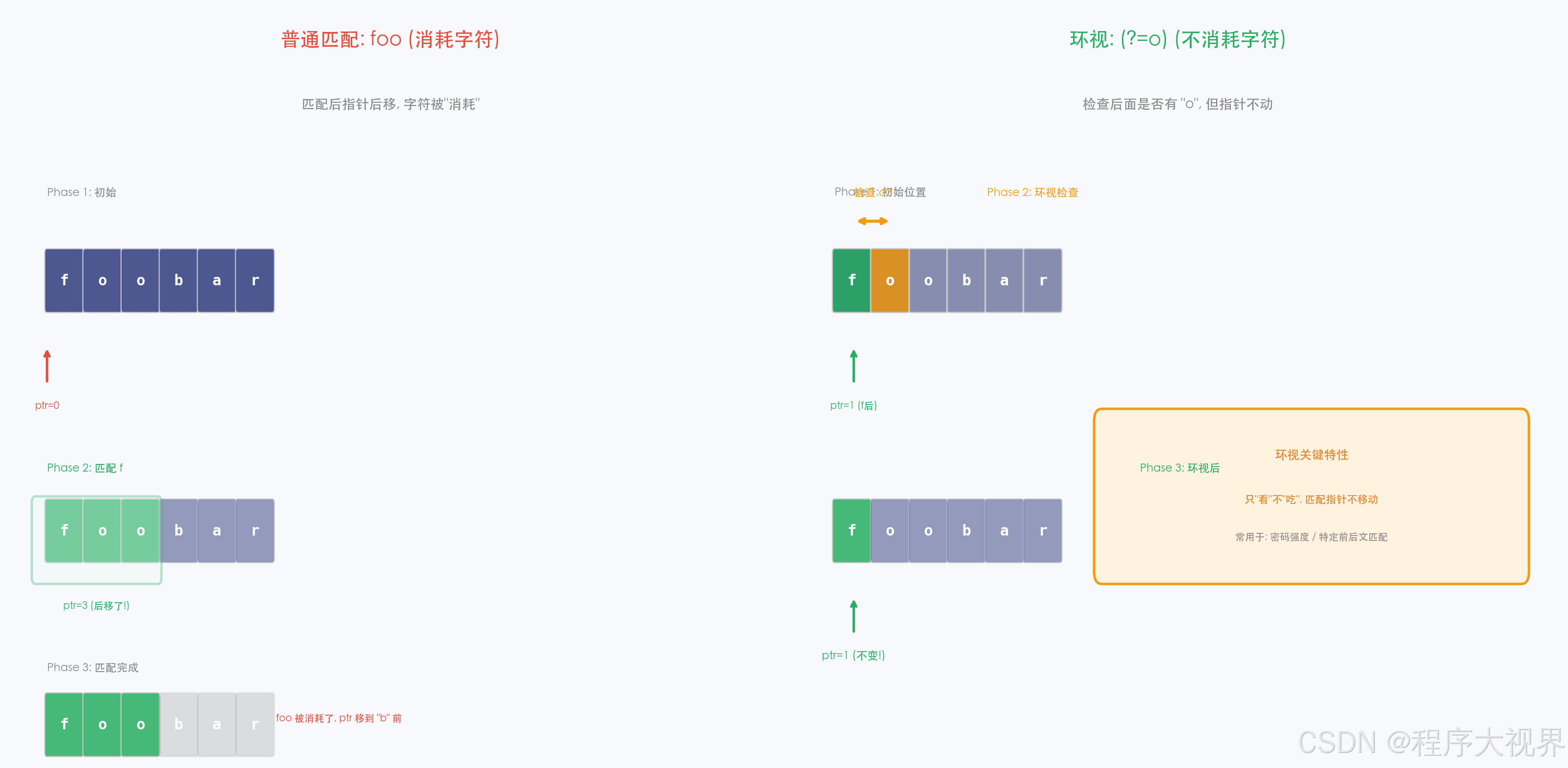
1.2 四种环视语法
| 类型 | 语法 | 含义 | 记忆口诀 |
|---|---|---|---|
| 正向先行环视 | (?=...) |
后面必须跟着 ... |
"前面看,有则行" |
| 负向先行环视 | (?!...) |
后面不能跟着 ... |
"前面看,无则行" |
| 正向后行环视 | (?<=...) |
前面必须是 ... |
"后面看,有则行" |
| 负向后行环视 | (?<!...) |
前面不能是 ... |
"后面看,无则行" |
1.3 正向先行环视 (?=...):后面必须跟着
python
import re
text = "foo bar fooish food"
# 匹配后面跟着 " bar" 的 "foo"
pattern = r"foo(?= bar)"
results = re.findall(pattern, text)
print(results)
# 输出:['foo']
# 解释:只有第一个 "foo" 后面跟着 " bar",第二个 "foo" 后面是 "ish",不匹配关键点 :(?= bar) 是条件,不参与匹配结果的输出。
1.4 负向先行环视 (?!...):后面不能跟着
python
import re
# 匹配不是以 "bar" 结尾的单词(简化示例)
text = "foobar fooish barr"
# 匹配 "foo" 但后面不能跟着 "bar"
pattern = r"foo(?!bar)"
results = re.findall(pattern, text)
print(results)
# 输出:['foo']
# 解释:第一个 "foo" 后面跟着 "bar"(不匹配),第二个 "foo" 后面是 "ish"(匹配)1.5 正向后行环视 (?<=...):前面必须是
python
import re
text = "$100 €200 ¥300"
# 匹配前面有 "$" 的数字
pattern = r"(?<=\$)\d+"
results = re.findall(pattern, text)
print(results)
# 输出:['100']
# 解释:只有 "100" 前面是 "$",其他数字前面不是,不匹配注意 :后行环视中的内容必须是固定长度 的(Python 的 re 模块限制)。a) 可以,a+) 不行。
1.6 负向后行环视 (?<!...):前面不能是
python
import re
text = "user: admin, user: guest"
# 匹配 "user:" 但前面不能是 "admin, "
pattern = r"(?<!<admin, )user:"
results = re.findall(pattern, text)
print(results)
# 输出:['user:']
# 解释:第二个 "user:" 前面是 "admin, "(不匹配),第一个前面不是(匹配)1.7 综合案例:提取带特定前缀的单词
python
import re
text = "preheat prehistoric postpone preposition"
# 提取以 "pre" 开头的单词(用后行环视)
pattern = r"\b(?<=pre)\w+"
results = re.findall(pattern, text)
print(results)
# 输出:['preheat', 'prehistoric', 'preposition']二、命名的分组引用
2.1 给分组起名字
基础语法中,分组用 () 定义,用 \1 \2 引用(在正则内部),或用 group(1) group(2) 提取(在 Python 中)。
但数字引用很难维护------改一个分组,后面全要改。
命名分组语法 :(?P<name>...)
python
import re
text = "2024-05-31"
# 数字分组
pattern1 = r"(\d{4})-(\d{2})-(\d{2})"
m1 = re.search(pattern1, text)
print(m1.groups()) # ('2024', '05', '31')
print(m1.group(1)) # '2024'
# 命名分组(推荐!)
pattern2 = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})"
m2 = re.search(pattern2, text)
print(m2.group("year")) # '2024'
print(m2.group("month")) # '05'
print(m2.group("day")) # '31'
# 也可以在正则内部用 \P=name 引用
pattern3 = r"(?P<word>\w+)\s+\P=word"
text2 = "hello hello world world"
print(re.findall(pattern3, text2)) # ['hello']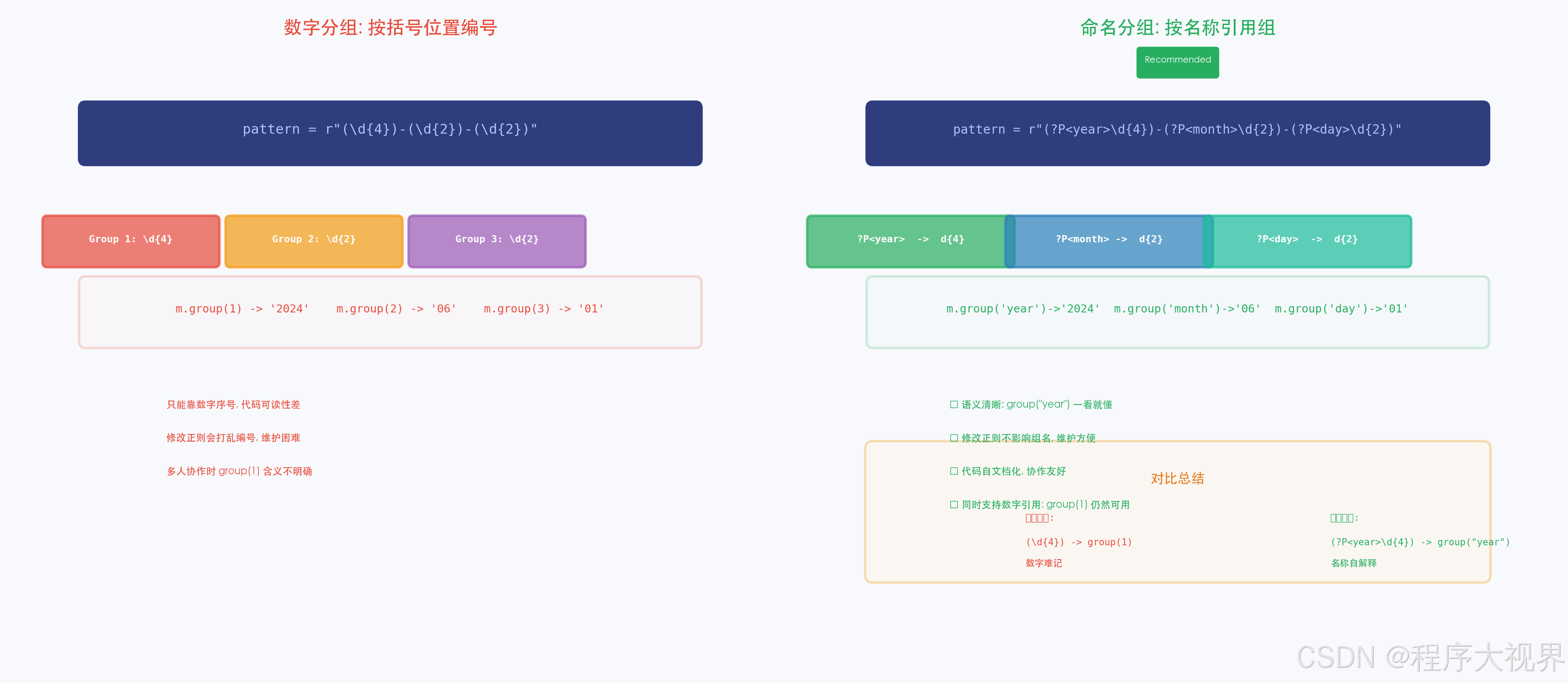
2.2 在替换中使用命名分组
python
import re
text = "2024-05-31"
# 把 YYYY-MM-DD → DD/MM/YYYY
pattern = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})"
replacement = r"\P<day>/\P<month>/\P<year>"
result = re.sub(pattern, replacement, text)
print(result)
# 输出:31/05/2024三、标志位(Flags):改变匹配的"性格"
3.1 常用标志位速查表
| 标志位 | 简写 | 作用 |
|---|---|---|
re.IGNORECASE |
re.I |
忽略大小写 |
re.MULTILINE |
re.M |
^ 和 $ 匹配每一行的开头/结尾 |
re.DOTALL |
re.S |
. 也能匹配换行符 \n |
re.VERBOSE |
re.X |
允许正则写成多行 + 添加注释 |
re.ASCII |
re.A |
\w \d \s 只匹配 ASCII,不匹配中文 |
re.LOCALE |
re.L |
根据本地设置匹配(少用) |
3.2 re.I:忽略大小写
python
import re
text = "Hello HELLO hello"
pattern = r"hello"
print(re.findall(pattern, text)) # ['hello']
print(re.findall(pattern, text, re.I)) # ['Hello', 'HELLO', 'hello']3.3 re.M:多行模式
python
import re
text = """first line
second line
third line"""
# 没有 M 标志:^ 和 $ 只匹配整个字符串的开头/结尾
pattern1 = r"^\w+"
print(re.findall(pattern1, text)) # ['first']
# 有 M 标志:^ 和 $ 匹配每一行的开头/结尾
pattern2 = r"^\w+"
print(re.findall(pattern2, text, re.M)) # ['first', 'second', 'third']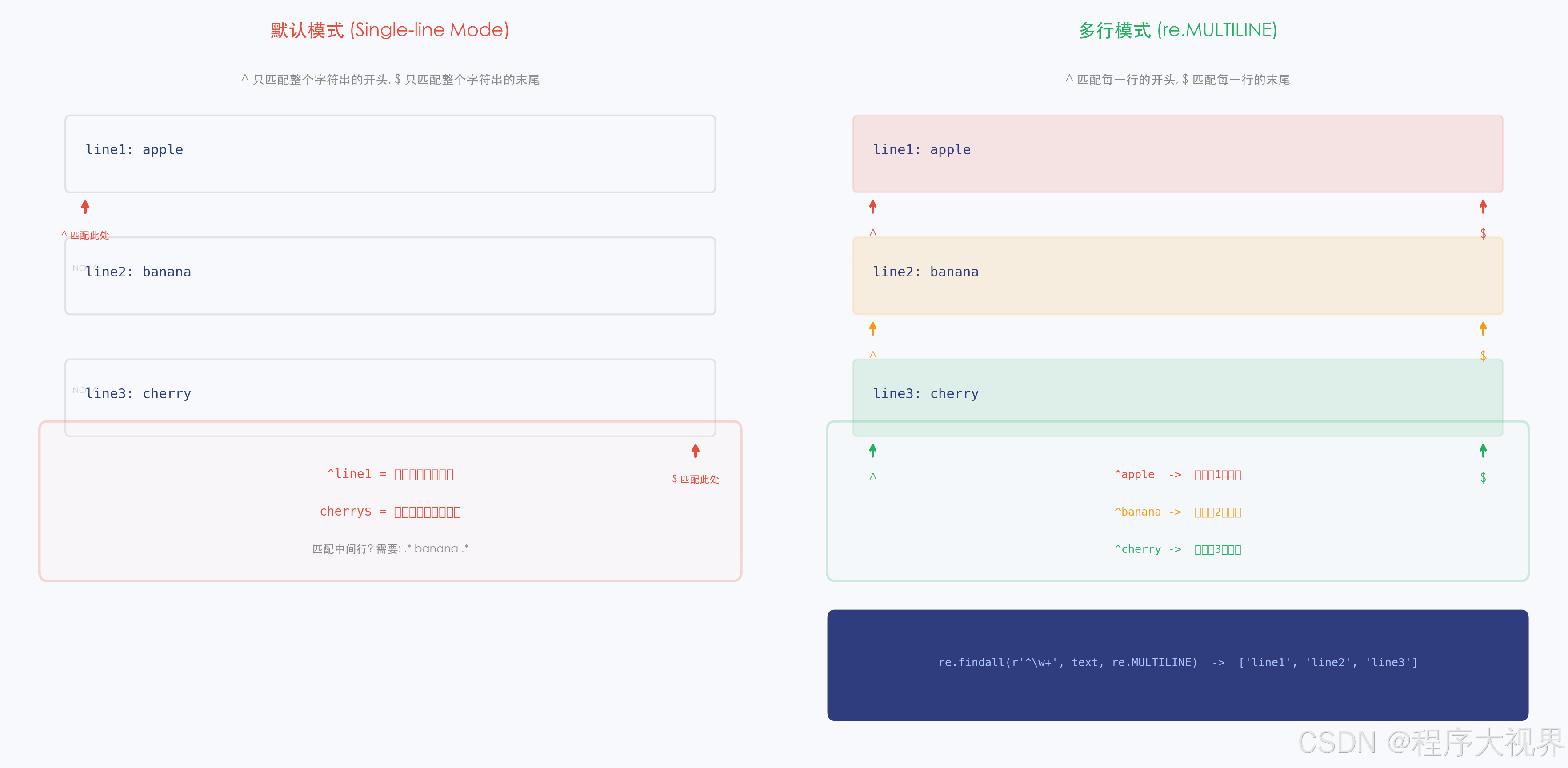
3.4 re.S(DOTALL):让 . 也能匹配换行符
python
import re
text = "<div>\nhello\n</div>"
# 默认:. 不匹配 \n
pattern1 = r"<div>.*</div>"
print(re.findall(pattern1, text)) # [] (匹配不到)
# DOTALL:. 也匹配 \n
pattern2 = r"<div>.*</div>"
print(re.findall(pattern2, text, re.S)) # ['<div>\nhello\n</div>']3.5 re.X(VERBOSE):把正则写成"诗"
当正则表达式很长时,一行写下来完全没法维护。re.X 允许你:
- 换行和空格会被忽略(用
\或[ ]来匹配真正的空格) #后面是注释
python
import re
text = "姓名:张三,电话:13800138000"
# 不用 VERBOSE:一行,难读
pattern1 = r"姓名:(\w+),电话:(\d{11})"
# 用 VERBOSE:多行 + 注释,可读性强!
pattern2 = r"""
^姓名:(?P<name>\w+) # 捕获姓名
,电话:(?P<phone>\d{11}) # 捕获电话
"""
m = re.search(pattern2, text, re.VERBOSE | re.I)
if m:
print(m.group("name")) # 张三
print(m.group("phone")) # 13800138000四、实战:日志文件解析
这是正则表达式在真实工作中最常见的用途之一。
4.1 日志格式分析
假设我们有如下格式的日志文件:
[2024-05-31 10:23:45] [INFO] user_login: user_id=1001, ip=192.168.1.1
[2024-05-31 10:24:01] [ERROR] db_connect_failed: timeout=5000ms
[2024-05-31 10:25:13] [WARNING] slow_query: query_time=3.2s
[2024-05-31 10:26:00] [INFO] user_logout: user_id=10014.2 用正则解析每条日志
python
import re
log_line = "[2024-05-31 10:23:45] [INFO] user_login: user_id=1001, ip=192.168.1.1"
pattern = r"""
^\[
(?P<date>\d{4}-\d{2}-\d{2}) # 日期
\s+
(?P<time>\d{2}:\d{2}:\d{2}) # 时间
\]\[
(?P<level>\w+) # 日志级别
\]\]
\s+
(?P<message>.+?) # 日志消息(非贪婪)
$
"""
m = re.search(pattern, log_line, re.VERBOSE)
if m:
print(f"日期:{m.group('date')}")
print(f"时间:{m.group('time')}")
print(f"级别:{m.group('level')}")
print(f"消息:{m.group('message')}")
# 输出:
# 日期:2024-05-31
# 时间:10:23:45
# 级别:INFO
# 消息:user_login: user_id=1001, ip=192.168.1.14.3 批量解析日志文件
python
import re
pattern = re.compile(r"""
^\[(?P<date>\d{4}-\d{2}-\d{2})\s+(?P<time>\d{2}:\d{2}:\d{2})\]
\s+\[(?P<level>\w+)\]
\s+(?P<message>.+?)$
""", re.VERBOSE)
# 模拟日志内容
log_data = """
[2024-05-31 10:23:45] [INFO] user_login: user_id=1001
[2024-05-31 10:24:01] [ERROR] db_connect_failed: timeout
[2024-05-31 10:25:13] [WARNING] slow_query: query_time=3.2s
"""
# 统计各级别日志数量
level_count = {}
for line in log_data.strip().split("\n"):
m = pattern.search(line)
if m:
level = m.group("level")
level_count[level] = level_count.get(level, 0) + 1
print("日志级别统计:", level_count)
# 输出:日志级别统计: {'INFO': 1, 'ERROR': 1, 'WARNING': 1}五、实战:从 HTML 中提取结构化数据
5.1 提取所有链接
python
import re
html = """
<a href="https://example.com">Example</a>
<a href='/about'>About</a>
<img src="logo.png">
"""
pattern = r"""(?<=href="|href=')(?P<url>[^"']+)(?="|')"""
urls = re.findall(pattern, html)
print(urls)
# 输出:['https://example.com', '/about']5.2 更健壮的链接提取(处理双引号/单引号)
python
import re
html = """
<a href="https://example.com" class="link">Example</a>
<a href='/about' class='link'>About</a>
"""
# 匹配 href="..." 或 href='...'
pattern = r"href\s*=\s*[\"'](?P<url>[^\"']*)[\"']"
urls = re.findall(pattern, html)
print(urls)
# 输出:['https://example.com', '/about']六、常见坑与最佳实践
6.1 贪婪 vs 非贪婪:一个字符之差
python
import re
text = "<div>content1</div><div>content2</div>"
# 贪婪(默认):尽量多匹配
print(re.findall(r"<div>.*</div>", text))
# 输出:['<div>content1</div><div>content2</div>']
# 解释:.* 从第一个 <div> 匹配到最后一个 </div>
# 非贪婪(加 ?):尽量少匹配
print(re.findall(r"<div>.*?</div>", text))
# 输出:['<div>content1</div>', '<div>content2</div>']
# 解释:.*? 每个 <div> 匹配到最近的 </div>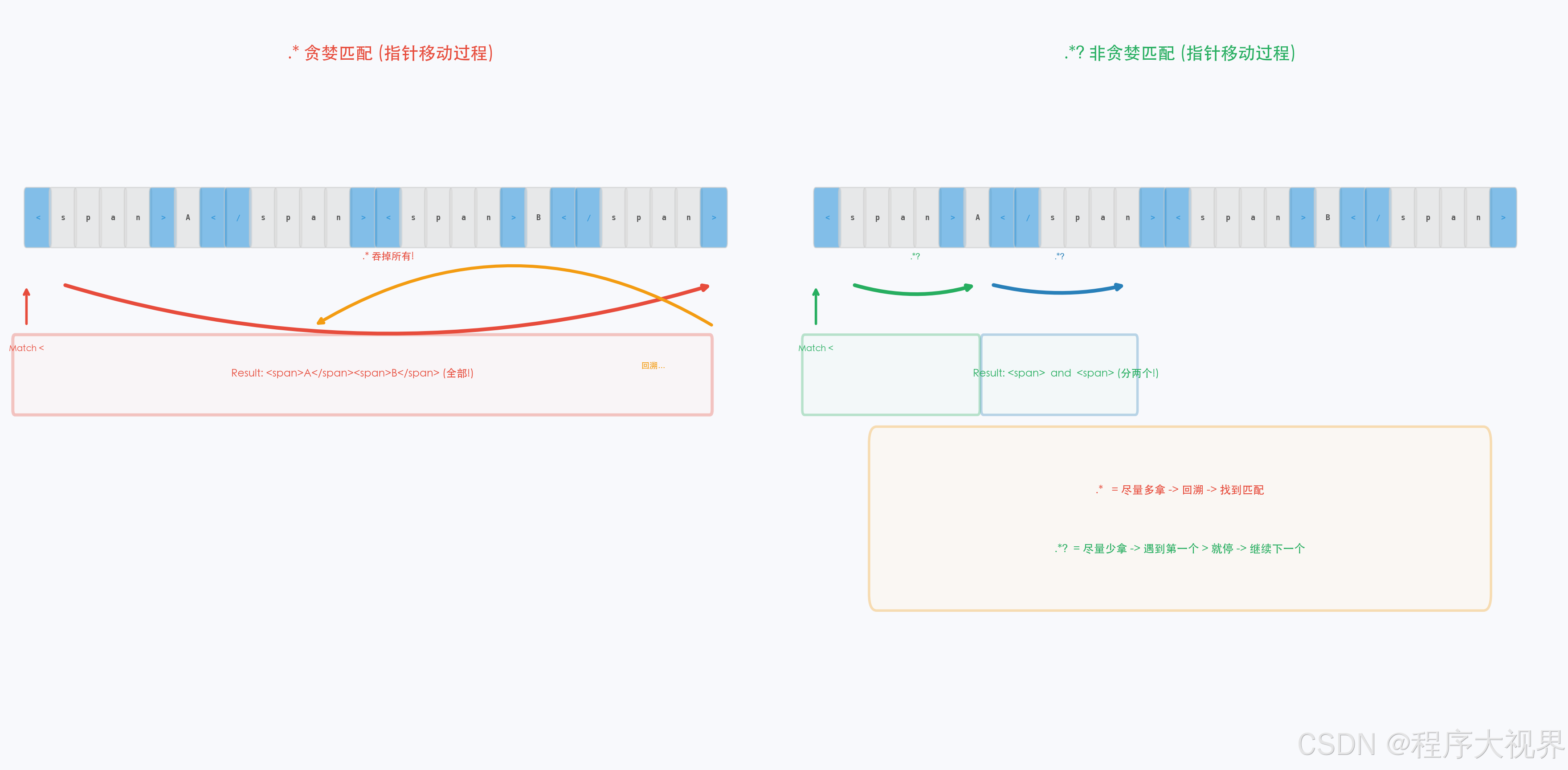
6.2 . 不匹配 \n:别忘了 re.S
这是新手最容易踩的坑:
python
import re
text = "<tag>\ncontent\n</tag>"
print(re.findall(r"<tag>.*</tag>", text)) # [](匹配不到!)
print(re.findall(r"<tag>.*</tag>", text, re.S)) # ['<tag>\ncontent\n</tag>']6.3 括号的转义:\( 而不是 (
python
import re
# 想匹配字符串中的 (123) 这种格式
text = "函数返回了 (123) 这个结果"
pattern = r"\(\d+\)" # 正确:转义括号
print(re.findall(pattern, text)) # [' (123)']
# pattern = r"(\d+)" # 错误:这变成了捕获分组!6.4 最佳实践速查表
| 实践 | 推荐做法 | 原因 |
|---|---|---|
| 复杂正则 | 用 re.VERBOSE 多行书写 + 注释 |
可维护性 |
| 分组引用 | 用命名分组 (?P<name>...) |
可读性与可维护性 |
| 重复使用 | 用 re.compile() 预编译 |
性能 |
| 匹配中文 | 用 [\u4e00-\u9fff] 或 \w(需确认) |
准确性 |
| HTML 解析 | 不要用正则,用 BeautifulSoup |
正则无法处理嵌套标签 |
七、动手练习
练习 1:密码强度校验
用正则表达式校验密码是否同时满足:
- 至少 8 位
- 包含大小写字母
- 包含数字
- 包含特殊字符(
[email #$%^&*])
python
import re
def is_strong_password(pwd):
"""
返回 True 如果密码满足所有条件
提示:用多个正则分别校验,或用一个复杂正则
"""
# 在这里写你的代码
pass
# 测试
tests = ["Abc123!", "password", "ABC123!!", "Short1!"]
for t in tests:
print(f"{t}: {is_strong_password(t)}")练习 2:提取 Markdown 中的图片链接
从 Markdown 文本中提取所有图片的 URL:
python
import re
md_text = """
这是一篇文章。

一些内容。

结束。
"""
# 写正则提取所有图片 URL
pattern = r"your_pattern_here"
urls = re.findall(pattern, md_text)
print(urls)
# 期望输出:['images/pic1.png', 'https://example.com/img2.jpg']练习 3:解析 Nginx/Apache 访问日志
Common Log Format 格式:127.0.0.1 - - [31/May/2024:10:23:45 +0800] "GET /api/users HTTP/1.1" 200 1234
用正则解析出:IP、时间、请求方法、路径、协议、状态码、响应大小。
小结
今天这篇文章,我们深入了正则表达式的进阶特性:
| 知识点 | 关键内容 |
|---|---|
| 环视 | (?=) 先行、(?<=) 后行;不消耗字符 |
| 命名分组 | (?P<name>...) + \P=name;可维护性强 |
| 标志位 | re.I 忽略大小写;re.M 多行;re.S DOTALL;re.X VERBOSE |
| 贪婪/非贪婪 | 默认贪婪 * +;加 ? 变非贪婪 *? +? |
| 实战 | 日志解析、HTML 提取、密码校验 |
一句话总结 :正则表达式是处理文本的强大武器,但记住------如果你用正则解析 HTML,说明你已经有 2 个问题了。
下一篇文章,我们将进入数据分析双雄的第一位:NumPy------Python 科学计算的基石,一切数组运算的起点。
本文是「Python从入门到数据分析」系列的第 15 篇,共 24 篇。关注我,不错过后续更新。