目录
[1. 理解硬件](#1. 理解硬件)
[1.1 磁盘、服务器、机柜、机房](#1.1 磁盘、服务器、机柜、机房)
[1.2 磁盘物理结构](#1.2 磁盘物理结构)
[1.3 磁盘的存储结构](#1.3 磁盘的存储结构)
[1.4 磁盘的逻辑结构](#1.4 磁盘的逻辑结构)
[1.4.1 理解过程](#1.4.1 理解过程)
[1.4.2 真实过程](#1.4.2 真实过程)
[1.5 CHS && LBA地址](#1.5 CHS && LBA地址)
[2. 引入文件系统](#2. 引入文件系统)
[2.1 引入"块"概念](#2.1 引入"块"概念)
[2.2 引入"分区"概念](#2.2 引入"分区"概念)
[2.3 引入"inode"概念](#2.3 引入"inode"概念)
[3. ext2 文件系统](#3. ext2 文件系统)
[3.1 宏观认识](#3.1 宏观认识)
[3.2 Block Group](#3.2 Block Group)
[3.3 块组内部构成](#3.3 块组内部构成)
[3.3.1 超级块(Super Block)](#3.3.1 超级块(Super Block))
[3.3.2 GDT(组描述符表:Group Descriptor Table)](#3.3.2 GDT(组描述符表:Group Descriptor Table))
[3.3.3 块位图(Block Bitmap)](#3.3.3 块位图(Block Bitmap))
[3.3.4 inode位图(Inode Bitmap)](#3.3.4 inode位图(Inode Bitmap))
[3.3.5 i节点表(Inode Table)](#3.3.5 i节点表(Inode Table))
[3.3.6 Data Block](#3.3.6 Data Block)
[3.4 inode和datablock映射(弱化)](#3.4 inode和datablock映射(弱化))
[3.5 目录与文件名](#3.5 目录与文件名)
[3.6 路径解析](#3.6 路径解析)
[3.7 路径缓存](#3.7 路径缓存)
[3.8 挂载分区](#3.8 挂载分区)
[3.9 文件系统总结](#3.9 文件系统总结)
[4. 软硬连接](#4. 软硬连接)
[4.1 硬链接](#4.1 硬链接)
[4.2 软链接](#4.2 软链接)
[4.3 软硬连接对比](#4.3 软硬连接对比)
[4.4 软硬连接的用途](#4.4 软硬连接的用途)
本节重点:
- 理解磁盘物理结构
- 掌握CHS和LBA地址
- 掌握Ext系列⽂件系统原理
- 理解分区,格式化,路径解析,挂载等过程和操作
- 理解软硬连接使⽤和⽤途
1. 理解硬件
文件=内容+属性
文件分为:
- 被打开的文件(位于内存中,通过基础IO操作)
- 没有被打开的文件(存储在磁盘上)
- 对于存储在磁盘上的文件,它们是如何被找到的呢?这依赖于文件系统的目录结构组织方式。目录采用树状结构,路径分为绝对路径和相对路径两种形式。
- 文件存储在磁盘上的基本要求就是能被检索到,否则就如同被删除了一般。这正是文件系统的核心功能所在。
1.1 磁盘、服务器、机柜、机房
- 机械硬盘是计算机中唯一的机械设备
- 磁盘------外设
- 读取速度较慢
- 存储容量大且价格实惠

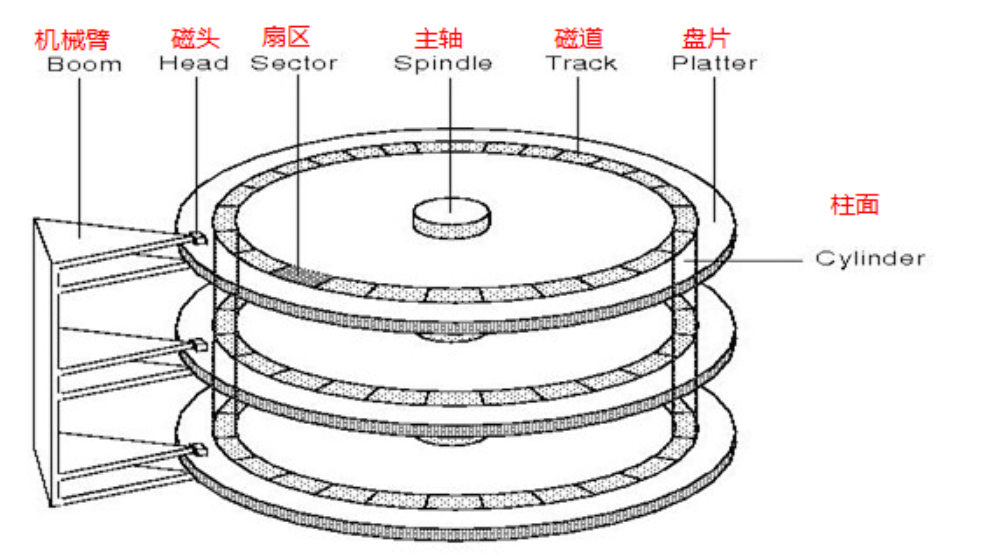
1.2 磁盘物理结构

1.3 磁盘的存储结构
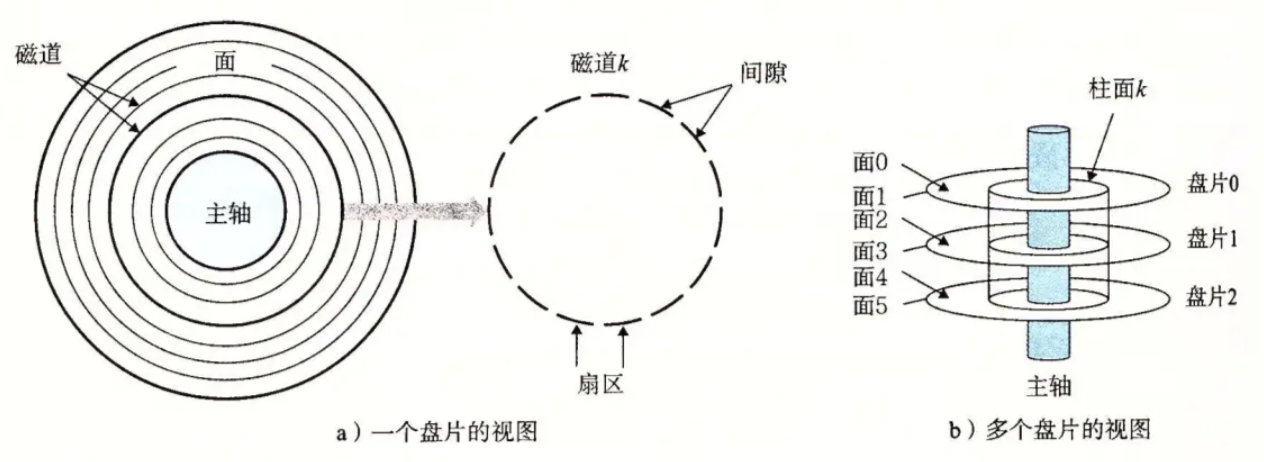
扇区:是磁盘存储数据的基本单位,512字节,块设备
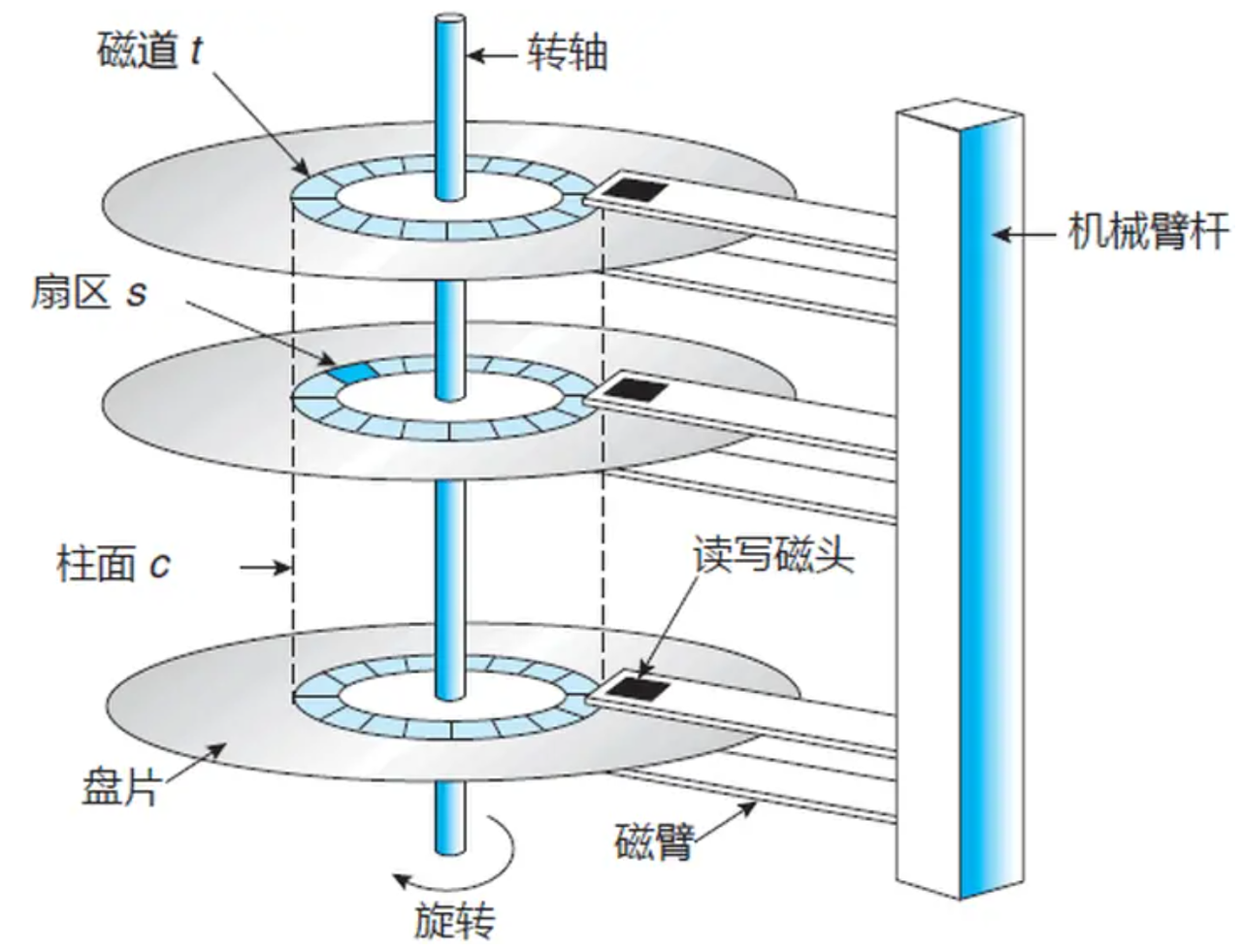
如何定位⼀个扇区呢?
- 确定磁头要访问哪⼀个柱⾯(磁道)(cylinder)
- 定位磁头(header)
- 定位⼀个扇区(sector)
- CHS地址定位
⽂件 = 内容+属性 都是数据,无非就是占据那几个扇区的问题!能定位⼀个扇区了,能不能定位多个扇区呢?
bash
[root@iZgw05f0yp422tzyebhkoaZ ~]# fdisk -l
Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: F51132A7-67B1-4650-806D-FD0DE6E1210C
Device Start End Sectors Size Type
/dev/vda1 2048 6143 4096 2M BIOS boot
/dev/vda2 6144 415743 409600 200M EFI System
/dev/vda3 415744 83886046 83470303 39.8G Linux filesystem- 扇区是从磁盘读出和写⼊信息的最⼩单位,通常⼤⼩为 512 字节。
- 磁头(head)数:每个盘⽚⼀般有上下两⾯,分别对应1个磁头,共2个磁头
- 磁道(track)数:磁道是从盘⽚外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁 头,不存储数据
- 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数
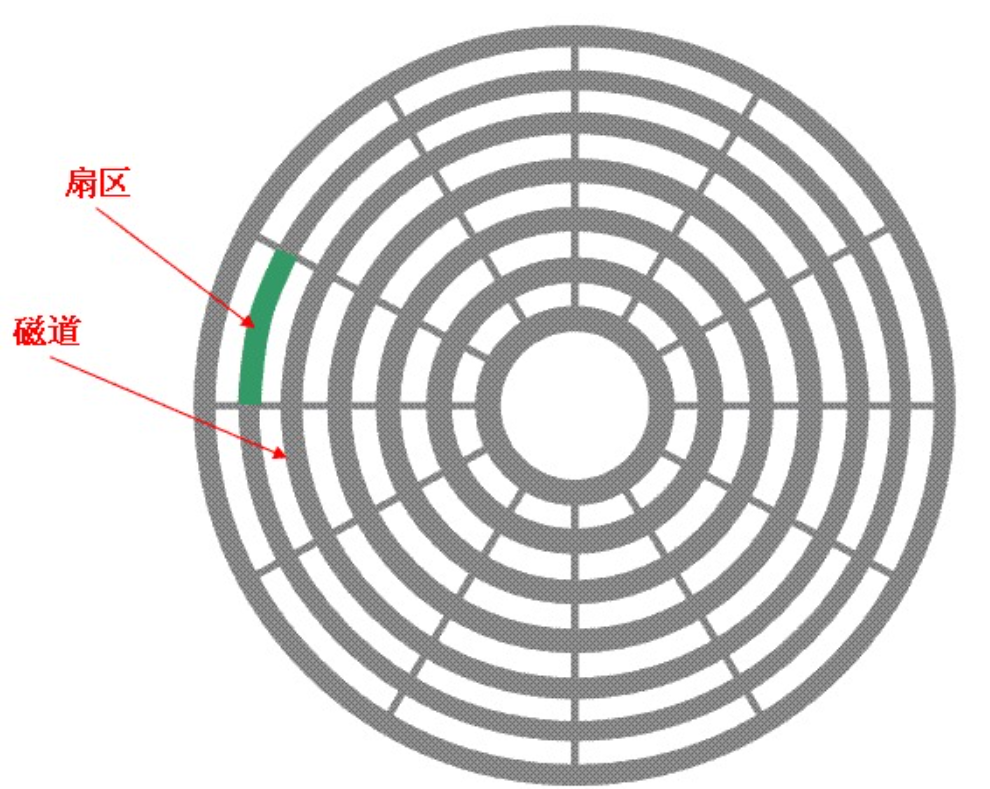
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘⽚的数量
- 磁盘容量=磁头数 × 磁道(柱⾯)数 × 每道扇区数 × 每扇区字节数
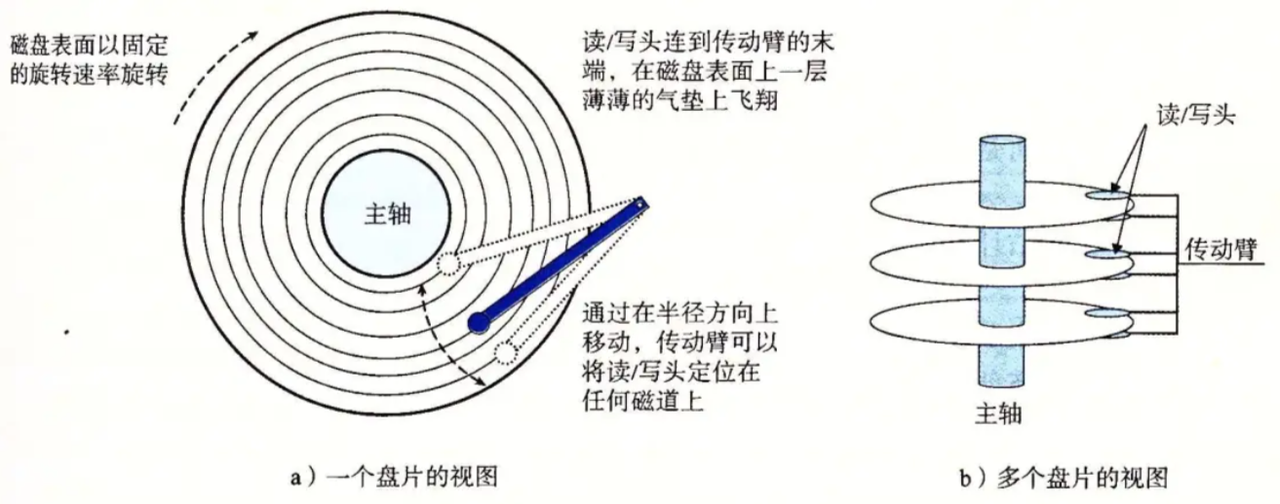
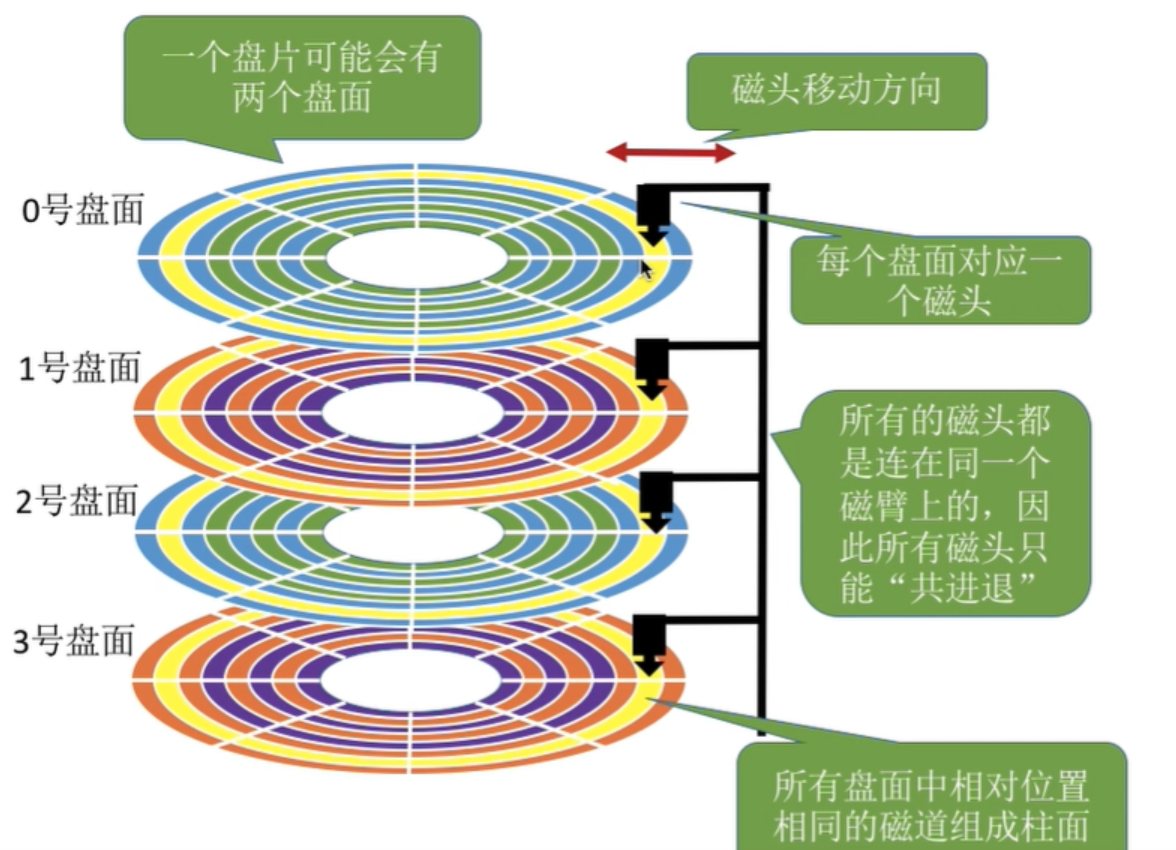
- 细节:传动臂上的磁头是共进退的(这点⽐较重要,后⾯会说明)
柱⾯(cylinder),磁头(head),扇区(sector),显然可以定位数据了,这就是数据定位(寻址)⽅式之⼀,CHS寻址⽅式。
CHS寻址
对早期的磁盘⾮常有效,知道⽤哪个磁头,读取哪个柱⾯上的第⼏扇区就可以读到数据了。 但是CHS模式⽀持的硬盘容量有限,因为系统⽤8bit来存储磁头地址,⽤10bit来存储柱⾯地 址,⽤6bit来存储扇区地址,⽽⼀个扇区共有512Byte,这样使⽤CHS寻址⼀块硬盘最⼤容量 为256 * 1024 * 63 * 512B = 8064 MB(1MB = 1048576B)(若按1MB=1000000B来算就是 8.4GB)
1.4 磁盘的逻辑结构
1.4.1 理解过程

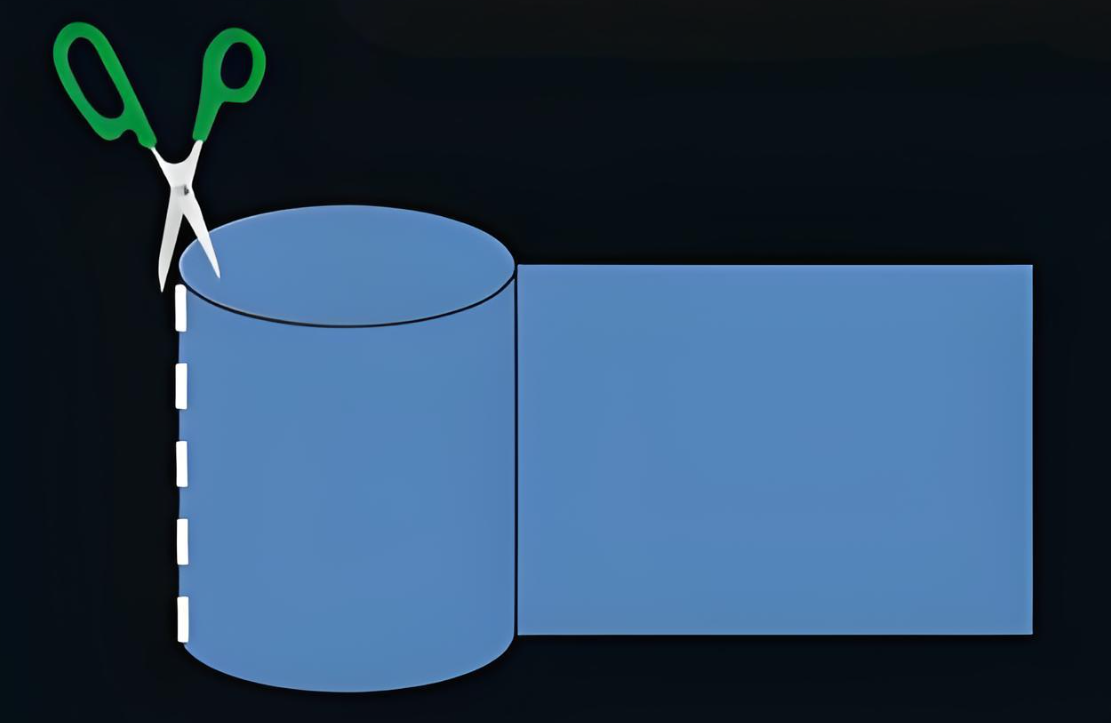
磁带上⾯可以存储数据,我们可以把磁带"拉直",形成线性结构

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻 辑存储结构我们也可以类似于: 
这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种地址叫做LBA( Logical Block Addressing:逻辑块寻址)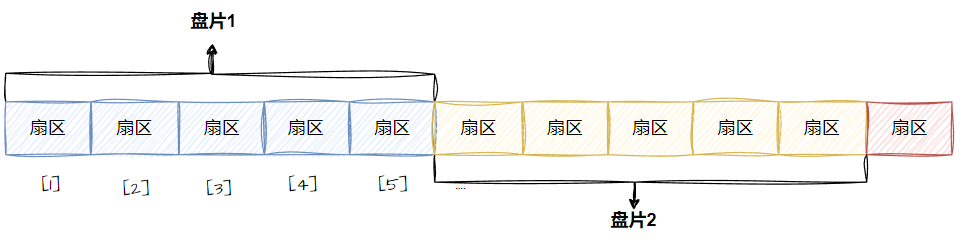
1.4.2 真实过程
⼀个细节:传动臂上的磁头是共进退的
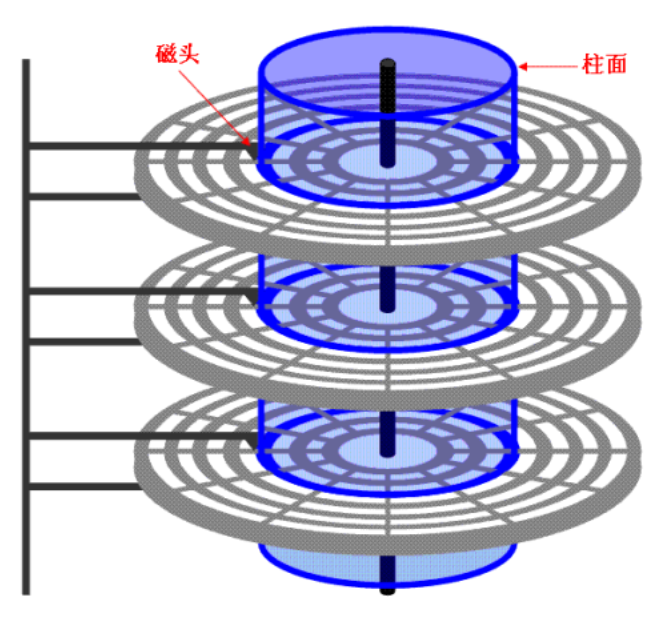
柱⾯ 是⼀个逻辑上的概念,其实就是每⼀⾯上,相同半径的磁道逻辑上构成柱⾯。
所以,磁盘物理上分了很多⾯,但是在我们看来,逻辑上,磁盘整体是由"柱⾯"卷起来的。
所以,磁盘的真实情况是:
磁道: 某⼀盘⾯的某⼀个磁道展开,即:⼀维数组 
柱⾯: 整个磁盘所有盘⾯的同⼀个磁道,即柱⾯展开:
柱⾯上的每个磁道,扇区个数是⼀样的,这不就是⼆维数组吗
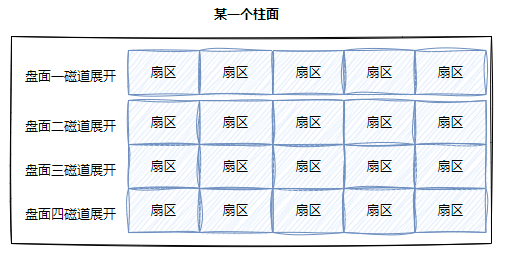
整盘:
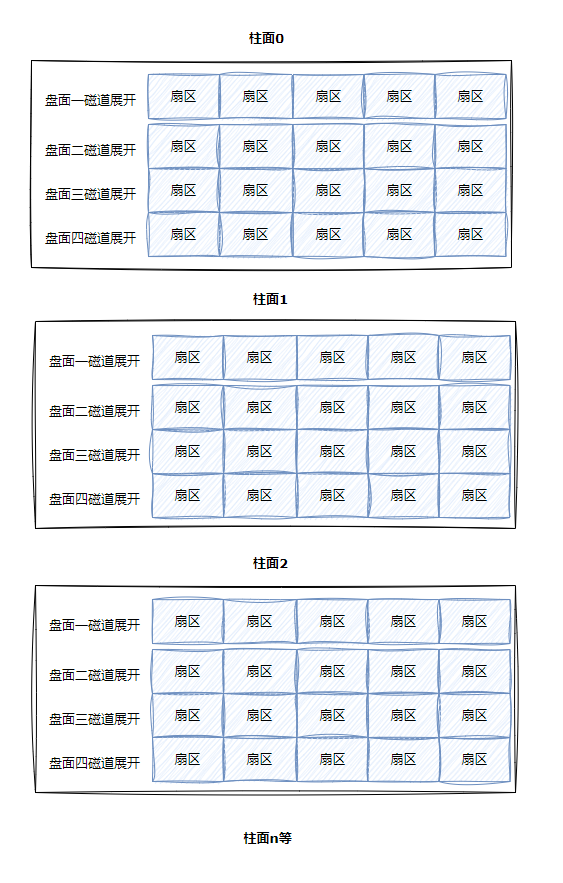
- 整个磁盘不就是多张⼆维的扇区数组表(三维数组?)
- 所有,寻址⼀个扇区:先找到哪⼀个柱⾯(Cylinder),在确定柱⾯内哪⼀个磁道(其实就是磁头位置, Head),在确定扇区(Sector),所以就有了CHS。
- 我们之前学过C/C++的数组,在我们看来,其实全部都是⼀维数组:

- 所以,每⼀个扇区都有⼀个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。所以 怎么计算得到这个LBA地址呢?
- LBA,1000,CHS 必须要! LBA地址转成CHS地址,CHS如何转换成为LBA地址。
- OS只需要使⽤LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址。谁做啊??磁盘 ⾃⼰来做!固件(硬件电路,伺服系统)
1.5 CHS && LBA地址
CHS转成LBA:
- 磁头数*每磁道扇区数 = 单个柱⾯的扇区总数
- LBA = 柱⾯号C*单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱⾯号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的
- 柱⾯和磁道都是从0开始编号的
- 总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参 数。
LBA转成CHS
- 柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
- 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
- 扇区号S = (LBA % 每磁道扇区数) + 1
- "//": 表⽰除取整
所以:从此往后,在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰转换。所以:
从现在开始,磁盘就是⼀个元素为扇区的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤ 磁盘,就可以⽤⼀个数字访问磁盘扇区了。
2. 引入文件系统
2.1 引入"块"概念
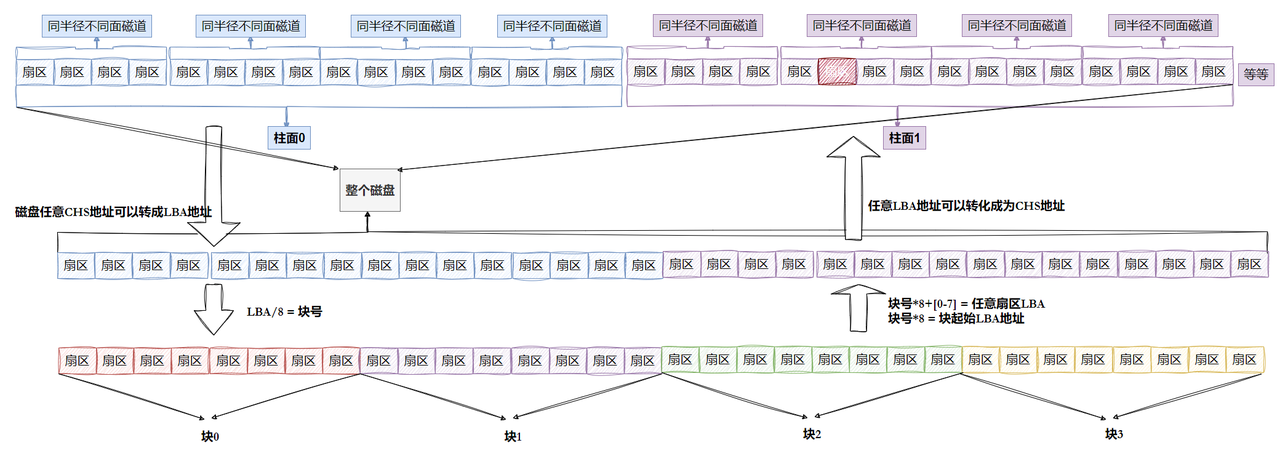
其实硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样 效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个"块"(block)。
硬盘的每个分区是被划分为⼀个个的"块"。⼀个"块"的⼤⼩是由格式化的时候确定的,并且不可 以更改,最常⻅的是4KB ,即连续**⼋个扇区组成⼀个"块"。"块"是⽂件存取的最⼩单位**。
OS文件系统访问磁盘,不以扇区为单位,而是以"块"为单位,一般是4KB(连续8个扇区)(可以调整)
注意:
- 磁盘就是⼀个三维数组,我们把它看待成为⼀个"⼀维数组",数组下标就是LBA,每个元素都是扇区
- 每个扇区都有LBA,那么8个扇区⼀个块,每⼀个块的地址我们也能算出来。
- 知道LBA:块号 = LBA/8
- 知道块号:LAB=块号*8 + n. (n是块内第⼏个扇区)
2.2 引入"分区"概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有⼀块磁盘并且将 它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的⼀种格式化。但是Linux的设备 都是以⽂件形式存在,那是怎么分区的呢?
柱⾯是分区的最⼩单位,我们可以利⽤参考柱⾯号码的⽅式来进⾏分区,其本质就是设置每个区的起 始柱⾯和结束柱⾯号码。此时我们可以将硬盘上的柱⾯(分区)进⾏平铺,将其想象成⼀个⼤的平⾯,如下图所⽰:

注意:
- 柱⾯⼤⼩⼀致,扇区个位⼀致,那么其实只要知道每个分区的起始和结束柱⾯号,知道每 ⼀个柱⾯多少个扇区,那么该分区多⼤,其实和解释LBA是多少也就清楚了.

2.3 引入"inode"概念
之前我们说过 ⽂件=数据+属性 ,我们使⽤ ls -l 的时候看到的除了看到⽂件名,还能看到⽂件元数据(属性)。
bash
[root@localhost linux]# ls -l
总⽤量 12
-rwxr-xr-x. 1 root root 7438 "9⽉ 13 14:56" a.out
-rw-r--r--. 1 root root 654 "9⽉ 13 14:56" test.c每⾏包含7列:
模式 、硬链接数 、⽂件所有者/组 、⼤⼩ 、最后修改时间 、⽂件名
ls -l读取存储在磁盘上的⽂件信息,然后显⽰出来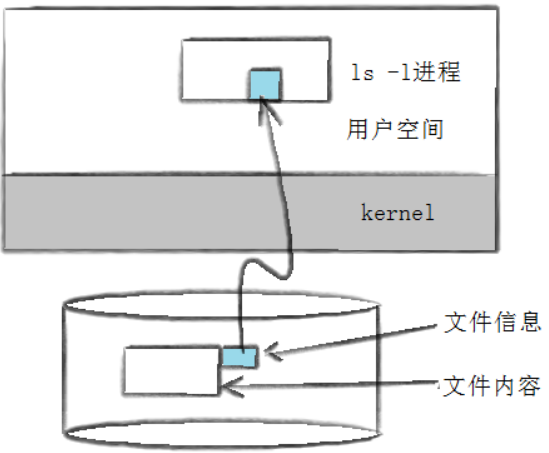
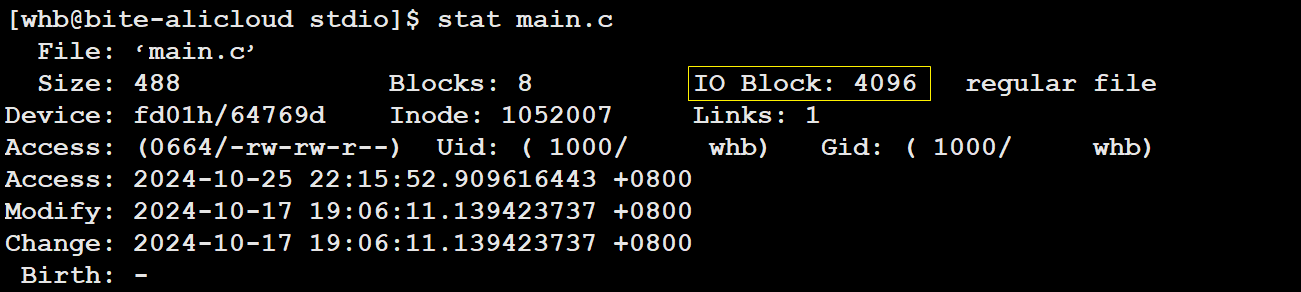
其实这个信息除了通过这种⽅式来读取,还有⼀个stat命令能够看到更多信息
bash
[root@localhost linux]# stat test.c
File: "test.c"
Size: 654 Blocks: 8 IO Block: 4096 普通⽂件
Device: 802h/2050d Inode: 263715 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-09-13 14:56:57.059012947 +0800
Modify: 2017-09-13 14:56:40.067012944 +0800
Change: 2017-09-13 14:56:40.069012948 +0800到这我们要思考⼀个问题,⽂件数据都储存在"块"中,那么很显然,我们还必须找到⼀个地⽅储存 ⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件 元信息的区域就叫做inode,中⽂译名为"索引节点"。
每⼀个⽂件都有对应的inode,⾥⾯包含了与该⽂件有关的⼀些信息。为了能解释清楚inode,我们需要是深⼊了解⼀下⽂件系统。
注意:
-
Linux下⽂件的存储是属性和内容分离存储的
-
Linux下,保存⽂件属性的集合叫做inode,⼀个⽂件,⼀个inode,inode内有⼀个唯⼀ 的标识符,叫做inode号
-
文件名不会作为属性存储在文件的inode中,因为文件属性具有固定大小,而文件名长度是可变的。文件名会存储在文件当前所处目录的数据块中
-
inode的⼤⼩⼀般是128字节或者256,我们后⾯统⼀128字节
-
任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的
- 我们已经知道硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,读取的基本单位是"块"。"块"⼜是硬盘的每个分区下的结构,难道"块"是随意的在分区上排布的吗?那要怎么找到"块"呢?
- 还有就是上⾯提到的存储⽂件属性的inode,⼜是如何放置的呢?
- ⽂件系统就是为了组织管理这些的!!
3. ext2 文件系统
3.1 宏观认识
所有的准备⼯作都已经做完,是时候认识下⽂件系统了。我们想要在硬盘上储⽂件,必须先把硬盘格式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。在 Linux系统中,最常⻅的是ext2系列的⽂件系统。其早期版本为ext2,后来⼜发展出ext3和ext4。 ext3和ext4虽然对ext2进⾏了增强,但是其核⼼设计并没有发⽣变化,我们仍是以较⽼的ext2作为演⽰对象。
ext2⽂件系统将整个分区划分成若⼲个同样⼤⼩的块组(Block Group),如下图所⽰。只要能管理⼀个分区就能管理所有分区,也就能管理所有磁盘⽂件。
分盘、分区、分组
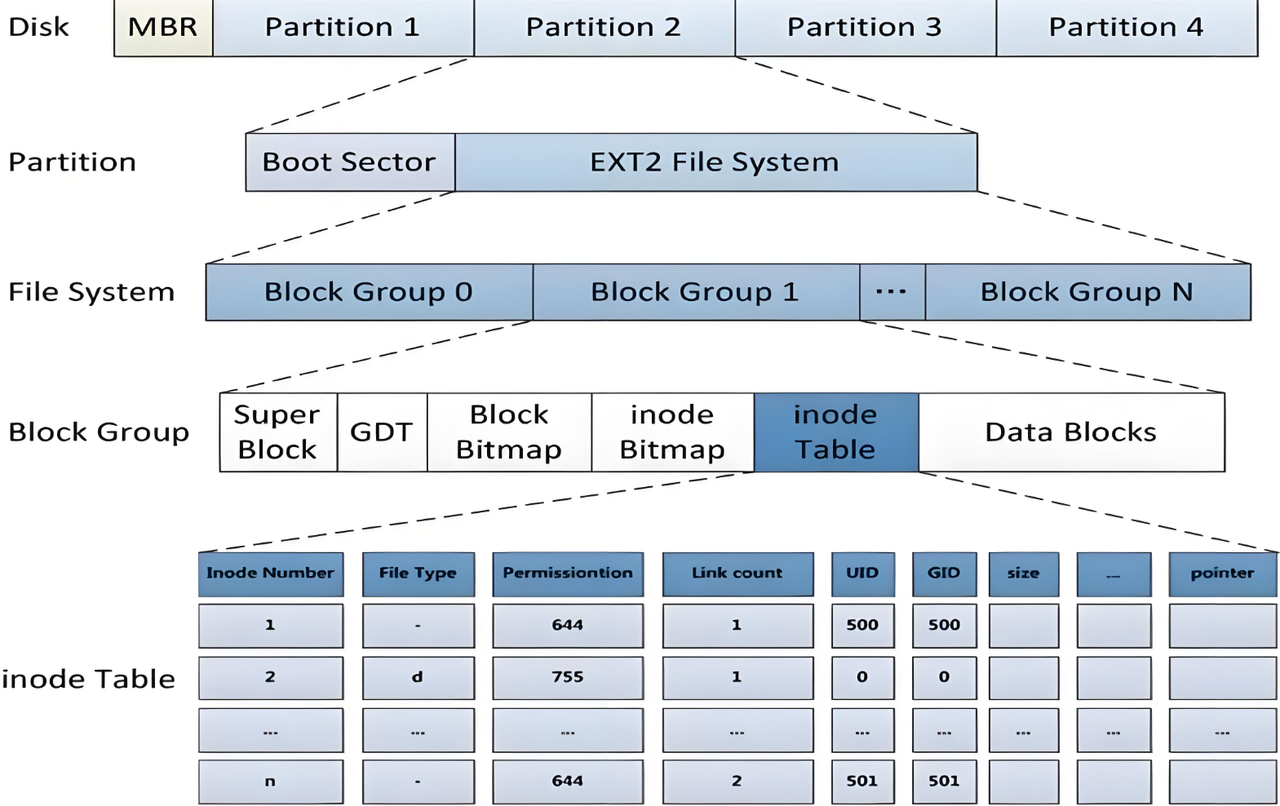
上图中启动块(Boot Block/Sector)的⼤⼩是确定的,为1KB,由PC标准规定,⽤来存储磁盘分区信 息和启动信息,任何⽂件系统都不能修改启动块。启动块之后才是ext2⽂件系统的开始。
3.2 Block Group
ext2⽂件系统会根据分区的⼤⼩划分为数个Block Group。⽽每个Block Group都有着相同的结构组 成。
3.3 块组内部构成
3.3.1 超级块(Super Block)
存放⽂件系统本⾝的结构信息,描述整个分区的⽂件系统信息。记录的信息主要有:bolck和inode的总量,未使⽤的block和inode的数量,⼀个block和inode的⼤⼩,最近⼀次挂载的时间,最近⼀次写⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息。Super Block的信息被破坏,可以说整个⽂件系统结构就被破坏了
超级块在每个块组的开头都有⼀份拷⻉(第⼀个块组必须有,后⾯的块组可以没有)。为了保证⽂件系统在磁盘部分扇区出现物理问题的情况下还能正常⼯作,就必须保证⽂件系统的super block信 息在这种情况下也能正常访问。所以⼀个⽂件系统的super block会在多个block group中进⾏备份, 这些super block区域的数据保持⼀致。
总结:
- 超级块是文件系统的核心信息区,存储分区总大小、inode与block数量、大小、挂载/写入/校验时间等关键结构信息,一旦损坏,文件系统基本失效
- 所以超级块会在多个快组开头备份(首个块组必备,后续可选),多份超级块内的数据保持一致,目的是在磁盘出现局部物理损坏时,仍能通过备份的超级块恢复使用
3.3.2 GDT(组描述符表:Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组的描述信息,如在这个块组中从哪⾥开始是inode Table,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉。
3.3.3 块位图(Block Bitmap)
Block Bitmap中记录着Data Block中哪个数据块已经被占⽤,哪个数据块没有被占⽤
3.3.4 inode位图(Inode Bitmap)
每个bit表⽰⼀个inode是否空闲可⽤。
3.3.5 i节点表(Inode Table)
- 存放⽂件属性如⽂件⼤⼩,所有者,最近修改时间等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区
3.3.6 Data Block
数据区:存放⽂件内容,也就是⼀个⼀个的Block。根据不同的⽂件类型有以下⼏种情况:
- 对于普通⽂件,⽂件的数据存储在数据块中。
- 对于⽬录,该⽬录下的所有⽂件名和⽬录名存储在所在⽬录的数据块中,除了⽂件名外,ls -l命令看到的其它信息保存在该⽂件的inode中。
- Block号按照分区划分,不可跨分区
inode和数据块,跨组编号的
inode和数据块,不能跨分区!!
所以,在同一个分区内部,inode编号,和块号都是唯一的!!
3.4 inode和datablock映射(弱化)
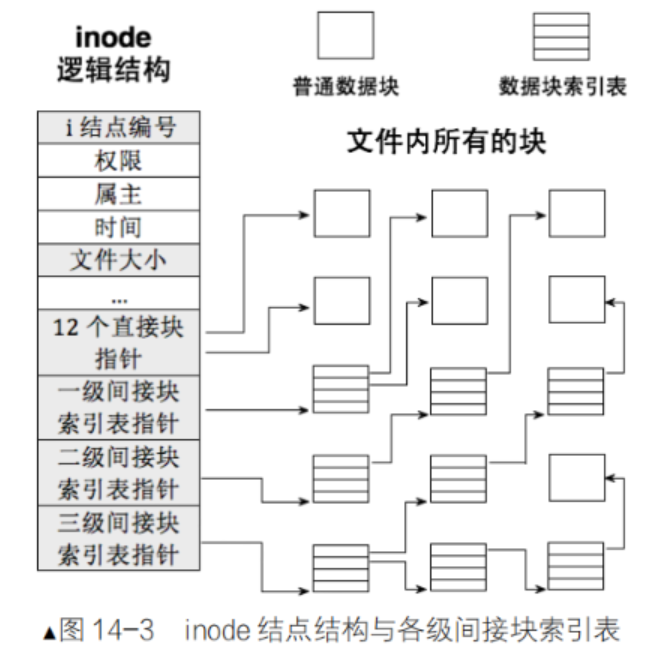
- inode内部存在__le32 i_blockEXT2_N_BLOCKS;/* Pointers to blocks */ , EXT2_N_BLOCKS =15,就是⽤来进⾏inode和block映射的
- 这样⽂件=内容+属性,就都能找到了。
结论:
分区之后的格式化操作,就是对分区进⾏分组,在每个分组中写⼊SB、GDT、Block Bitmap、Inode Bitmap等管理信息,这些管理信息统称:⽂件系统
只要知道⽂件的inode号,就能在指定分区中确定是哪⼀个分组,进⽽在哪⼀个分组确定 是哪⼀个inode
拿到inode⽂件属性和内容就全部都有了
知道inode号的情况下,在指定分区,请解释:对⽂件进⾏增、删、查、改是在 做什么?查:根据inode找到文件数据块位置,读取内容
改:修改已有数据块内容,或重新分配块并更新inode指针
增:分配新数据块,把数据写入,并在inode中记录块位置与大小
删:释放inode对应的所有数据块,标记inode为空闲,并不立即清空数据
下⾯,通过touch⼀个新⽂件来看看如何⼯作。
bash
[root@localhost linux]# touch abc
[root@localhost linux]# ls -i abc
263466 abc为了说明问题,我们将上图简化:
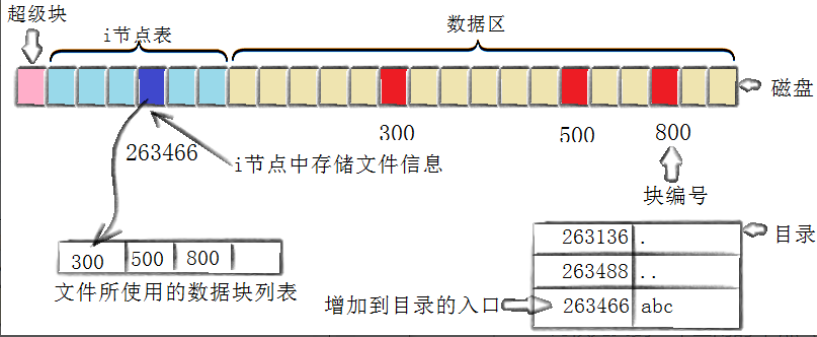
创建⼀个新⽂件主要有以下4个操作:
- 存储属性:内核先找到⼀个空闲的i节点(这⾥是263466)。内核把⽂件信息记录到其中。
- 存储数据:该⽂件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第⼀块数据复制到300,下⼀块复制到500,以此类推。
- 记录分配情况:⽂件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
- 添加⽂件名到⽬录:新的⽂件名abc。linux如何在当前的⽬录中记录这个⽂件?内核将⼊⼝(263466,abc)添加到⽬录⽂件。⽂件名和inode之间的对应关系将⽂件名和⽂件的内容及属性连接起来。
3.5 目录与文件名
我们访问文件,都是用的文件名,没用过inode号啊?
目录是文件吗?如何理解?
- 目录也是文件,但是磁盘上没有目录的概念,只有文件属性+文件内容的概念
- 目录属性不用多说,而文件内容保存的是:文件名与Inode号之间的映射关系
cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
if (argc != 2)
{
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]);
if (!dir)
{
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL)
{
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0)
{
continue;
}
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}
bash
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ ./a.out ./
Filename: readdir.c, Inode: 1177829
Filename: a.out, Inode: 1179609- 所以,访问⽂件,必须打开当前⽬录,根据⽂件名,获得对应的inode号,然后进⾏⽂件访问
- 所以,访问⽂件必须要知道当前⼯作⽬录,本质是必须能打内容!
⽐如:要访问test.c, 就必须打开test(当前⼯作⽬录),然后才能获取test.c对应的inode进⽽对⽂件进⾏访问。
bash
whb@bite:~/code/test/test$ pwd
/home/whb/code/test/test
whb@bite:~/code/test/test$ ls -li
total 24
1596260 -rw-rw-r-- 1 whb whb 814 Oct 28 20:32 test.c3.6 路径解析
打开当前⼯作⽬录⽂件,查看当前⼯作⽬录⽂件的内容?当前⼯作⽬录不也是⽂件吗?我们访问 当前⼯作⽬录不也是只知道当前⼯作⽬录的⽂件名吗?要访问它,不也得知道当前⼯作⽬录的inode 吗?
- 所以也要打开:当前⼯作⽬录的上级⽬录,额....,上级⽬录不也是⽬录吗??不还是上⾯的问题吗?
- 所以类似"递归",需要把路径中所有的⽬录全部解析,出⼝是"/"根⽬录
- ⽽实际上,任何⽂件,都有路径,访问⽬标⽂件,⽐如: /home/whb/code/test/test/test.c 都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问 到test.c。这个过程叫做Linux路径解析。
- 所以,我们知道了:访问⽂件必须要有⽬录+⽂件名=路径的原因
- 根⽬录固定⽂件名,inode号,⽆需查找,系统开机之后就必须知道
可是路径谁提供?
- 你访问⽂件,都是指令/⼯具访问,本质是进程访问,进程有CWD!进程提供路径。
- 你open⽂件,提供了路径
可是最开始的路径从哪⾥来?
- 所以Linux为什么要有根⽬录,根⽬录下为什么要有那么多缺省⽬录?
- 你为什么要有家⽬录,你⾃⼰可以新建⽬录?
- 上⾯所有⾏为:本质就是在磁盘⽂件系统中,新建⽬录⽂件。⽽你新建的任何⽂件,都在你或者系统指定的⽬录下新建,这不就是天然就有路径了嘛!
- 系统+⽤⼾共同构建Linux路径结构.
3.7 路径缓存
1.Linux磁盘中,存在真正的⽬录吗?
- 不存在,只有⽂件。只保存⽂件属性+⽂件内容
2.访问任何⽂件,都要从/⽬录开始进⾏路径解析?
- 原则上是,但是这样太慢,所以Linux会缓存历史路径结构
系统会先在缓存中查找路径,若未命中再从文件系统检索,找到后会将新路径加入缓存。
3.Linux⽬录的概念,怎么产⽣的?
- 打开的⽂件是⽬录的话,由OS⾃⼰在内存中进⾏路径维护
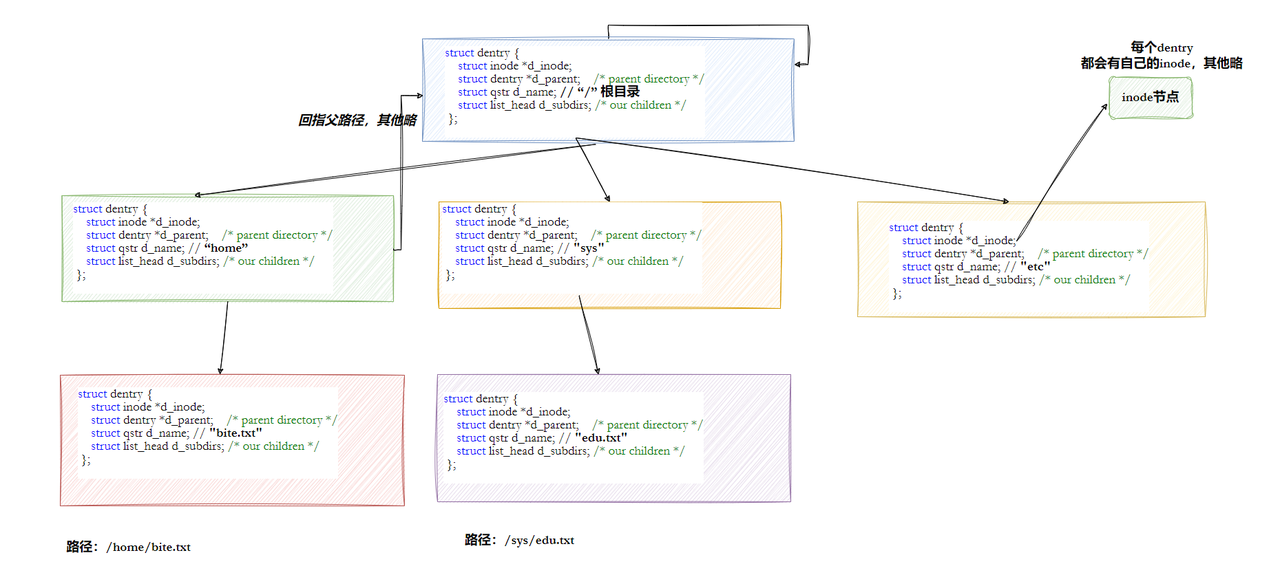
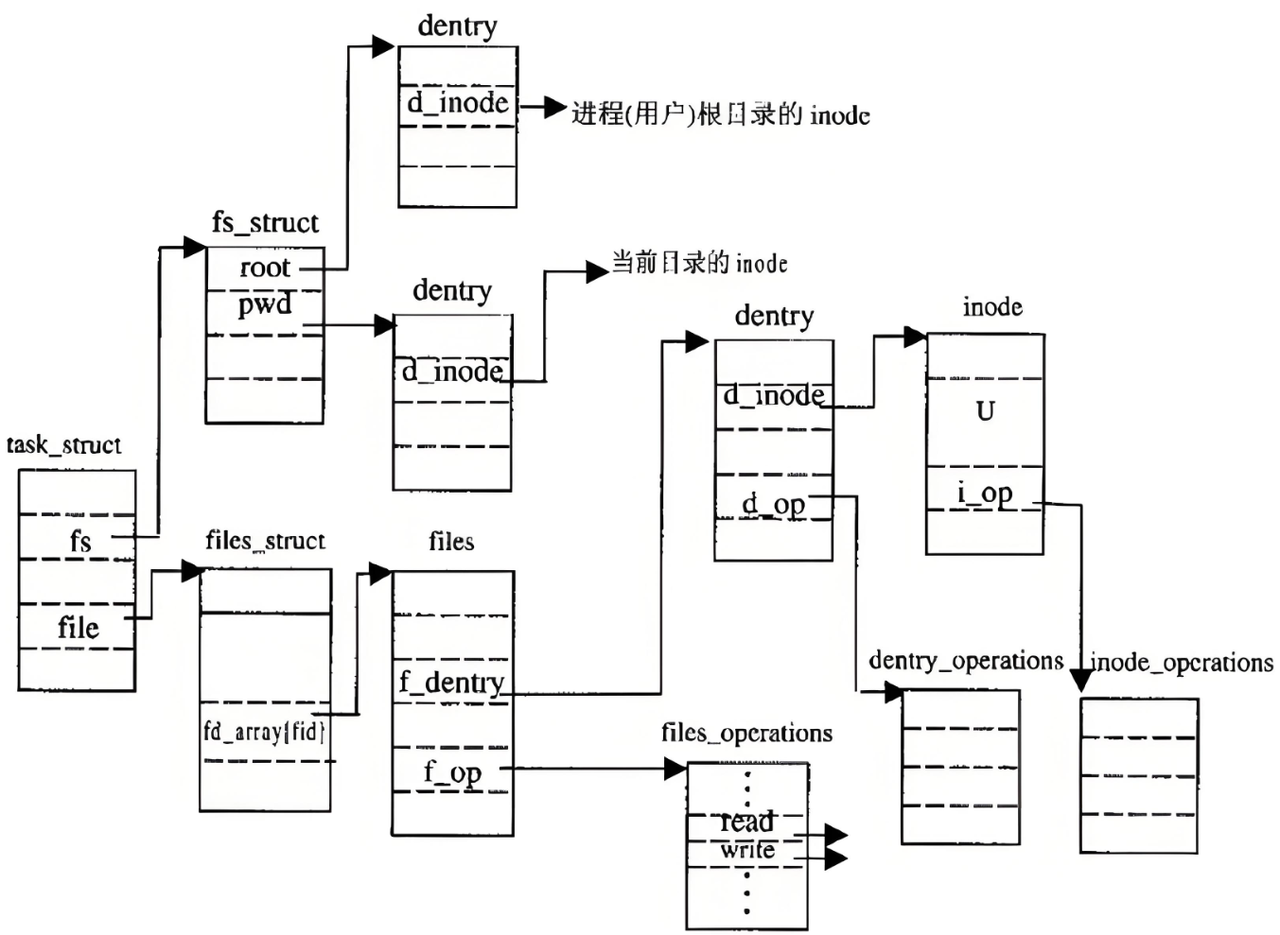
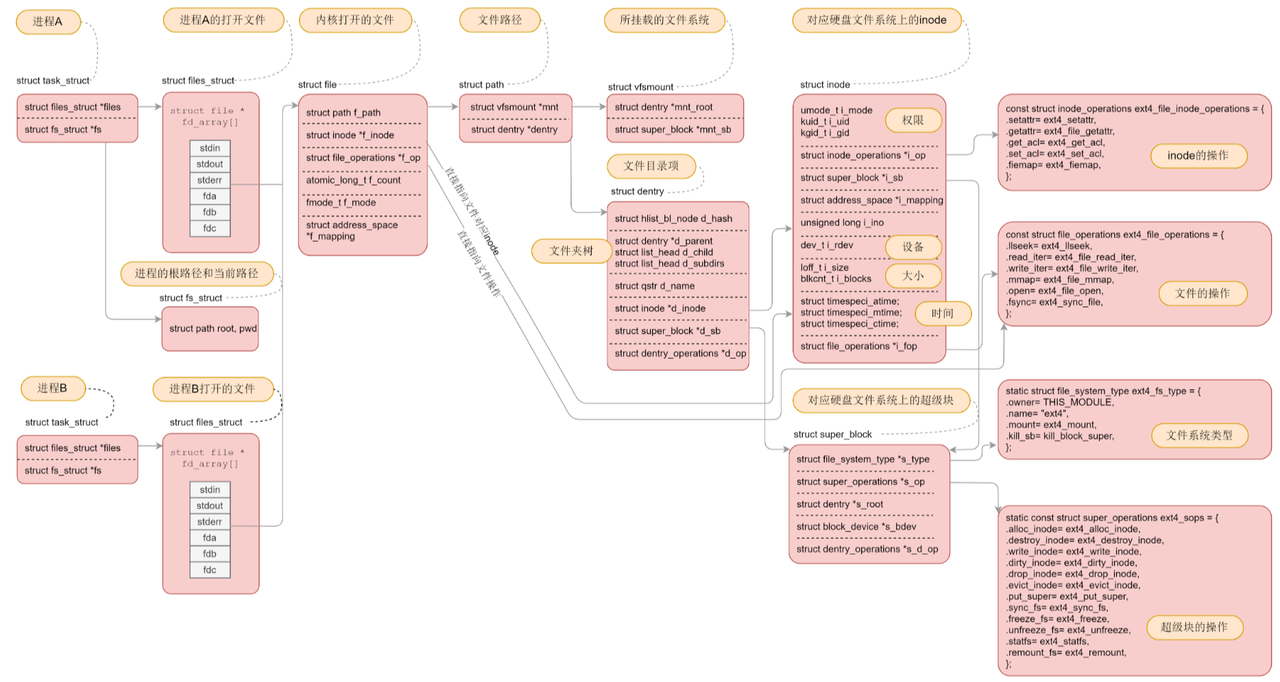
Linux中,在内核中维护树状路径结构的内核结构体叫做:struct dentry
- 每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开的⽂件,就可以在内存中形成整个树形结构
- 整个树形节点也同时会⾪属于LRU(Least Recently Used,最近最少使⽤)结构中,进⾏节点淘汰
- 整个树形节点也同时会⾪属于Hash,⽅便快速查找
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry 结构,缓存新路径
3.8 挂载分区
我们已经能够根据inode号在指定分区找⽂件了,也已经能根据⽬录⽂件内容,找指定的inode了,在 指定的分区内,我们可以为所欲为了。可是: 问题:inode不是不能跨分区吗?Linux不是可以有多个分区吗?我怎么知道我在哪⼀个分区???
bash
$ dd if=/dev/zero of=./disk.img bs=1M count=5 #制作⼀个⼤的磁盘块,就当做⼀个分区
$ mkfs.ext4 disk.img # 格式化写⼊⽂件系统
$ mkdir /mnt/mydisk # 建⽴空⽬录
$ df -h # 查看可以使⽤的分区
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/1002
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的⽬录
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/1002
/dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk
$ sudo umount /mnt/mydisk # 卸载分区
whb@bite:/mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% /
tmpfs 986M 0 986M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 986M 0 986M 0% /sys/fs/cgroup
tmpfs 198M 0 198M 0% /run/user/0
tmpfs 198M 0 198M 0% /run/user/1002/dev/loop0 在Linux系统中代表第⼀个循环设备(loopdevice)。循环设备,也被称为 回环设备或者loopback设备,是⼀种伪设备(pseudo-device),它允许将⽂件作为块设备 (block device)来使⽤。这种机制使得可以将⽂件(⽐如ISO镜像⽂件)挂载(mount)为 ⽂件系统,就像它们是物理硬盘分区或者外部存储设备⼀样
bash
whb@bite:/mnt$ ls /dev/loop* -l
brw-rw---- 1 root disk 7, 0 Oct 17 18:24 /dev/loop0
brw-rw---- 1 root disk 7, 1 Jul 17 10:26 /dev/loop1
brw-rw---- 1 root disk 7, 2 Jul 17 10:26 /dev/loop2
brw-rw---- 1 root disk 7, 3 Jul 17 10:26 /dev/loop3
brw-rw---- 1 root disk 7, 4 Jul 17 10:26 /dev/loop4
brw-rw---- 1 root disk 7, 5 Jul 17 10:26 /dev/loop5
brw-rw---- 1 root disk 7, 6 Jul 17 10:26 /dev/loop6
brw-rw---- 1 root disk 7, 7 Jul 17 10:26 /dev/loop7
crw-rw---- 1 root disk 10, 237 Jul 17 10:26 /dev/loop-control- 分区写⼊⽂件系统,⽆法直接使⽤,需要和指定的⽬录关联,进⾏挂载才能使⽤。
- 所以,可以根据访问⽬标⽂件的"路径前缀"准确判断我在哪⼀个分区。
总结:
Linux会自动帮你定位文件所在的分区,你不需要手动判断,内核通过挂载点(目录)就能知道当前路径属于哪个分区
1.inode不跨分区
inode不跨分区,每个分区有自己独立的inode编号池。
分区A的 inode=123 和分区B的 inode=123 完全不是同一个文件
2.Linux如何知道你在哪个分区?
你访问的目录路径,已经告诉你所在分区
例如:
- / -> 根分区(sad1)
- /home -> 独立分区(sad2)
- /data -> 独立分区(sad3)
内核维护一张挂载表,记录哪个目录对应哪个分区
你进入某个目录,内核就只知道:我现在在哪个分区里
3.文件路径 -> 分区 -> inode
你打开文件时,系统流程是:
路径名 -> 找到属于哪个分区 -> 在该分区内找inode
3.9 文件系统总结
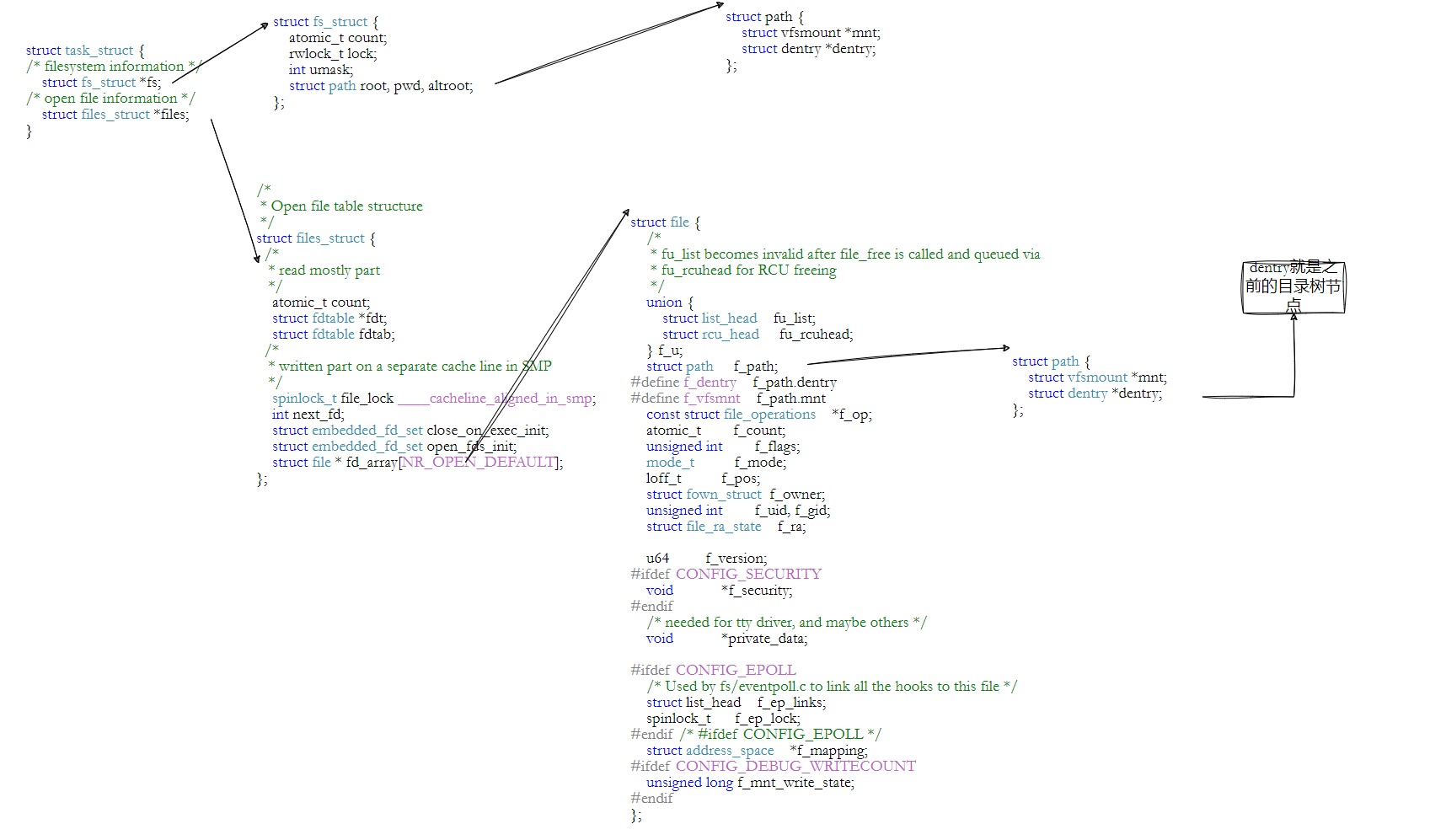
下⾯⽤⼏张图总结
4. 软硬连接
4.1 硬链接
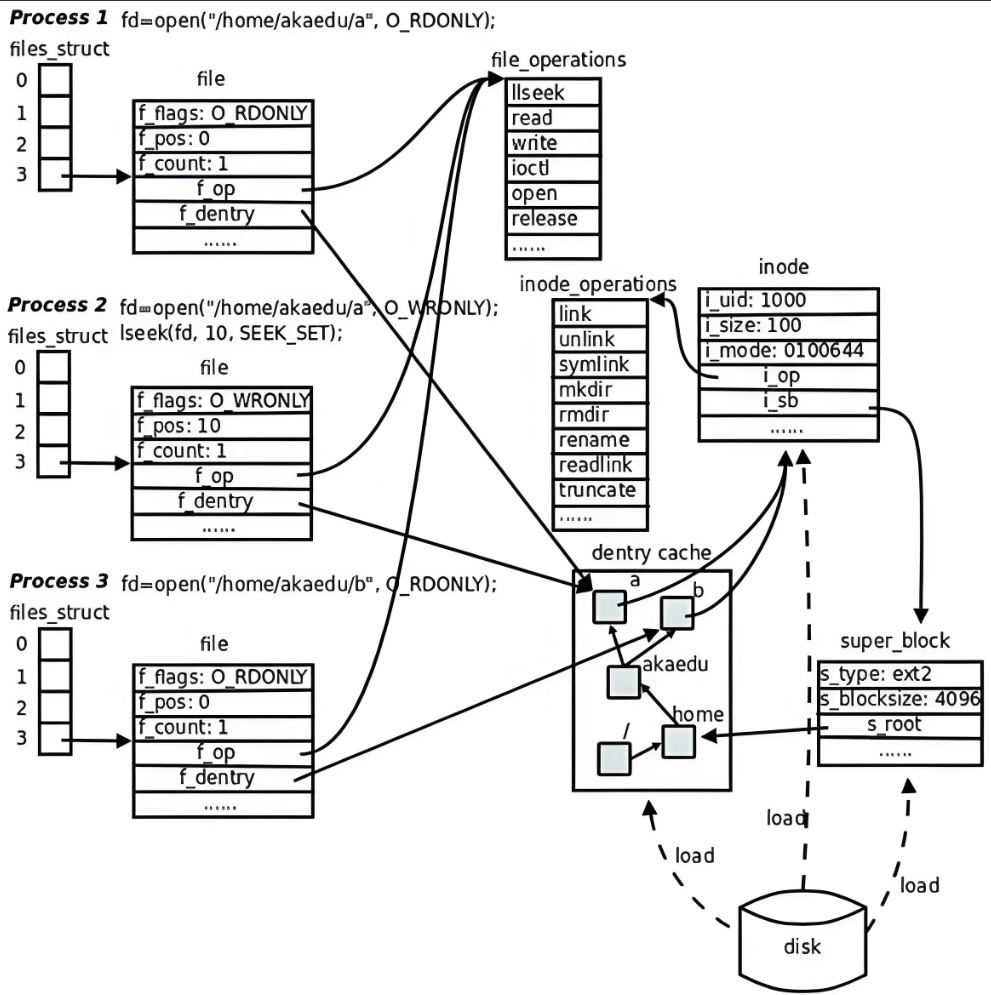
我们看到,真正找到磁盘上⽂件的并不是⽂件名,⽽是inode。其实在linux中可以让多个⽂件名对应 于同⼀个inode。
bash
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ touch file1
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ ln file1 file2
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ ls -li file*
1179626 -rw-rw-r-- 2 wsj wsj 0 Mar 30 23:33 file1
1179626 -rw-rw-r-- 2 wsj wsj 0 Mar 30 23:33 file2- file1和file2的链接状态完全相同,他们被称为指向⽂件的硬链接。内核记录了这个连接数,inode 1179626 的硬连接数为2。
- 我们在删除⽂件时⼲了两件事情:1.在⽬录中将对应的记录删除,2.将硬连接数-1,如果为0,则 将对应的磁盘释放。
4.2 软链接
硬链接是通过inode引⽤另外⼀个⽂件,软链接是通过名字引⽤另外⼀个⽂件,但实际上,新的⽂件和被引⽤的⽂件的inode不同,应⽤常⻅上可以想象成⼀个快捷⽅式。在shell中的做法
bash
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ touch f1
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ ln -sf f1 f2
[wsj@iZgw05f0yp422tzyebhkoaZ lesson22]$ ls -li
total 32
1179626 -rw-rw-r-- 1 wsj wsj 0 Mar 30 23:42 f1
1179689 lrwxrwxrwx 1 wsj wsj 2 Mar 30 23:43 f2 -> f1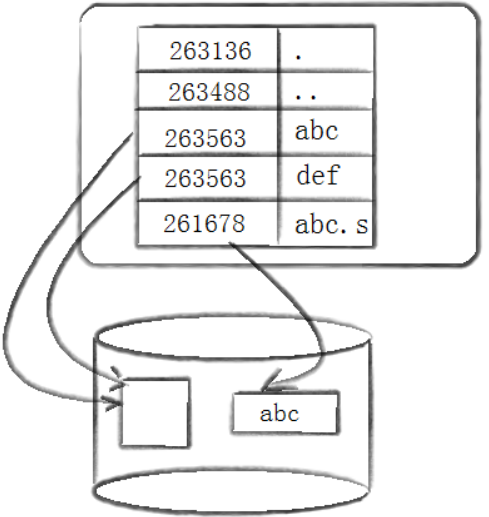
ACM 是文件三个时间属性的缩写,具体含义如下:
- Access:文件最后被访问的时间
- Modify:文件内容最后被修改的时间
- Change:文件属性最后被修改的时间
4.3 软硬连接对比
硬链接:ln 源文件 链接名
软链接:ln -s 源文件 链接名
- 软连接是独⽴⽂件
- 硬链接只是⽂件名和⽬标⽂件inode的映射关系
4.4 软硬连接的用途
硬链接:
- . (当前目录)和**..**(上级目录) 就是硬链接
- ⽂件备份
软连接:类似快捷⽅式