在 Elasticsearch(ES)中,DSL 是我们操作数据的核心工具,全称 Domain Specific Language(领域特定语言) ,是 ES 专门设计的JSON 风格查询语言 ,用于替代简单的 URI 查询,实现复杂检索、过滤、聚合、排序等所有数据操作。
简单对比:
- 简陋 URI 查询:
GET /goods/_search?q=goods_name:手机(仅支持简单条件) - 强大 DSL 查询:JSON 格式,支持多条件、分词检索、统计、高亮等所有高级功能
ES DSL 核心分类
DSL 分为两大核心类型,分工完全不同:
| 分类 | 核心作用 | 特点 | 适用场景 |
|---|---|---|---|
| 查询 DSL (Query DSL) | 检索匹配的文档 | 计算相关性打分 (_score),按匹配度排序 |
全文搜索、模糊匹配、文档筛选 |
| 聚合 DSL (Aggregation DSL) | 统计分析数据 | 不返回文档,返回统计结果 | 分组、求和、平均值、去重计数(类似 SQL GROUP BY) |
1. 查询 DSL(Query DSL)细分
这是最常用的部分,又分为 4 类:
- 全文查询(Full Text Queries) 针对文本字段(text) ,会先分词再匹配,用于模糊搜索 :
match、match_phrase(短语匹配)、multi_match(多字段搜索) - 词项查询(Term-Level Queries) 针对精确值字段 (keyword / 数字 / 日期),不分词、精确匹配 ,不打分:
term(精确单值)、terms(多值)、range(范围)、exists(非空判断) - 复合查询(Compound Queries) 组合多个查询条件,最核心:bool 查询(must/should/filter/must_not)
- 特殊查询 地理查询、嵌套文档查询、
match_all(查所有)
✨ 关键补充:Filter(过滤) 属于查询 DSL 的子句,不计算打分、结果会被缓存 ,性能远高于普通查询,优先用于精确过滤(如状态、时间范围)。
2. 聚合 DSL(Aggregation DSL)细分
用于数据统计,分为 3 类:
- 指标聚合(Metric) :计算数值(
avg/sum/max/min/ 去重计数) - 桶聚合(Bucket) :分组(
terms分组 /range范围分组 / 时间分组) - 管道聚合:基于聚合结果二次计算
DEL查询示例
DSL的基本语法如下:
bash
GET /索引名/_search
{
"query": {
"查询类型":{
"擦寻条件":"查询值"
}
}
}1.查询所有数据:
match_all 匹配所有数据,默认返回前 10 条:
bash
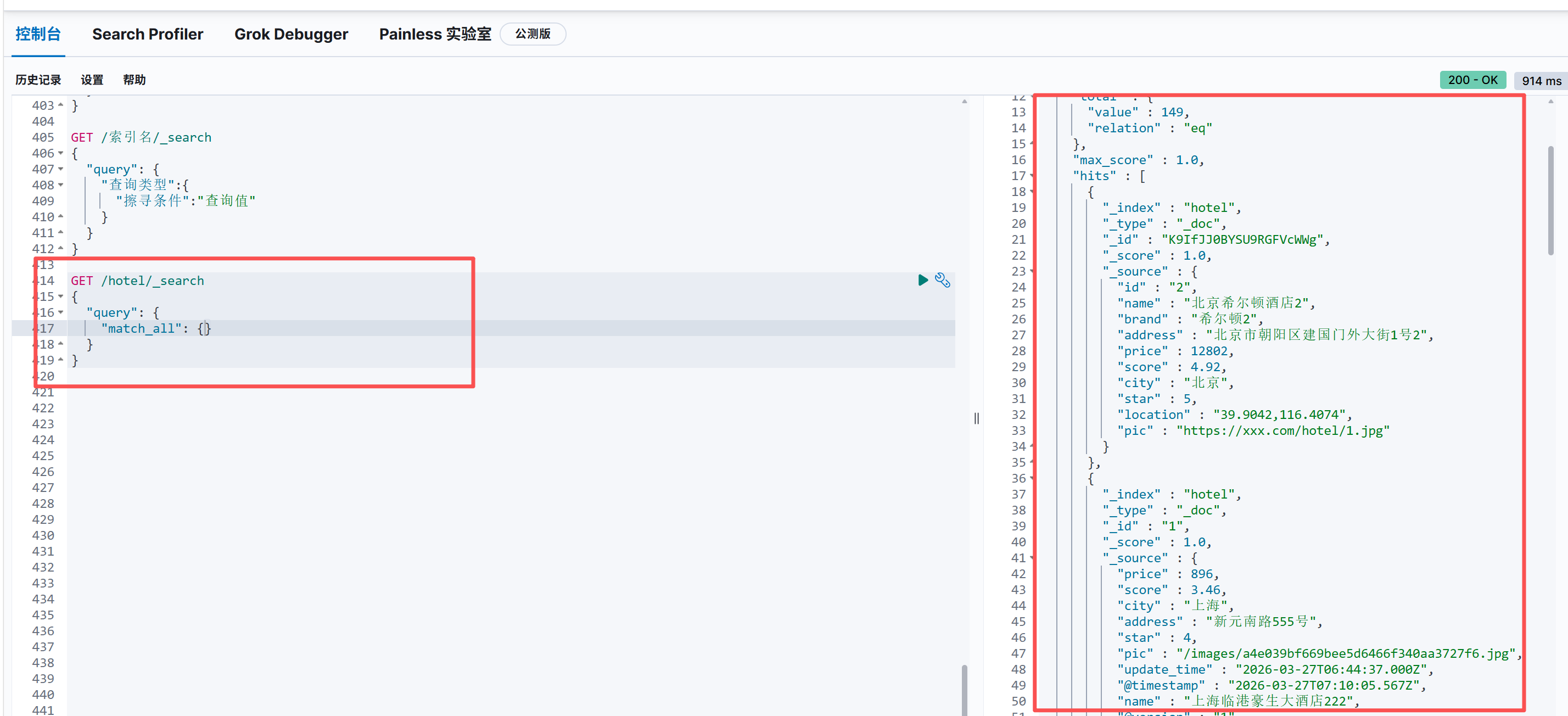
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
2. 全文查询:文本模糊搜索
针对 text 类型的商品名,分词匹配:
bash
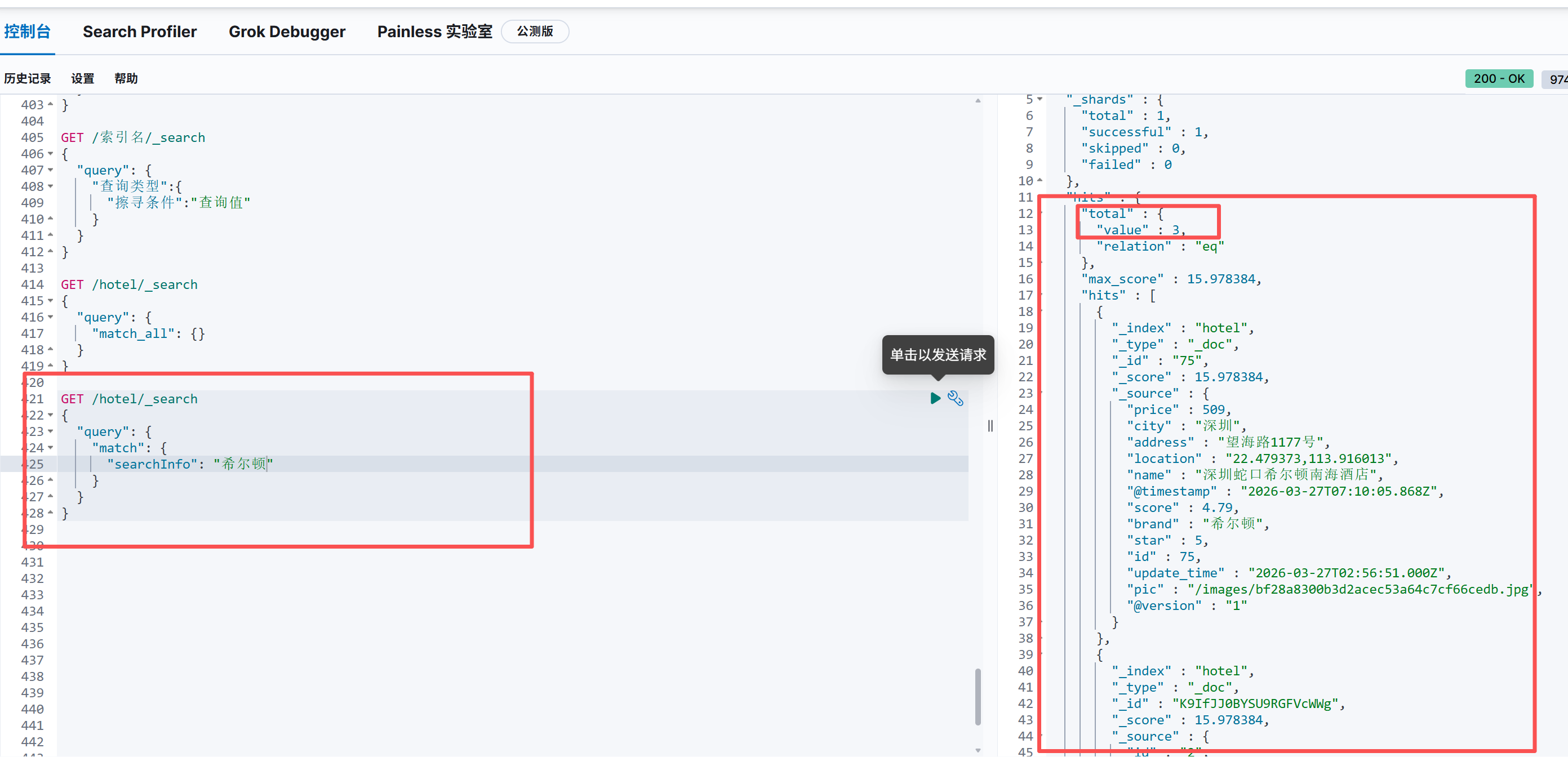
GET /hotel/_search
{
"query": {
"match": {
"searchInfo": "希尔顿"
}
}
}
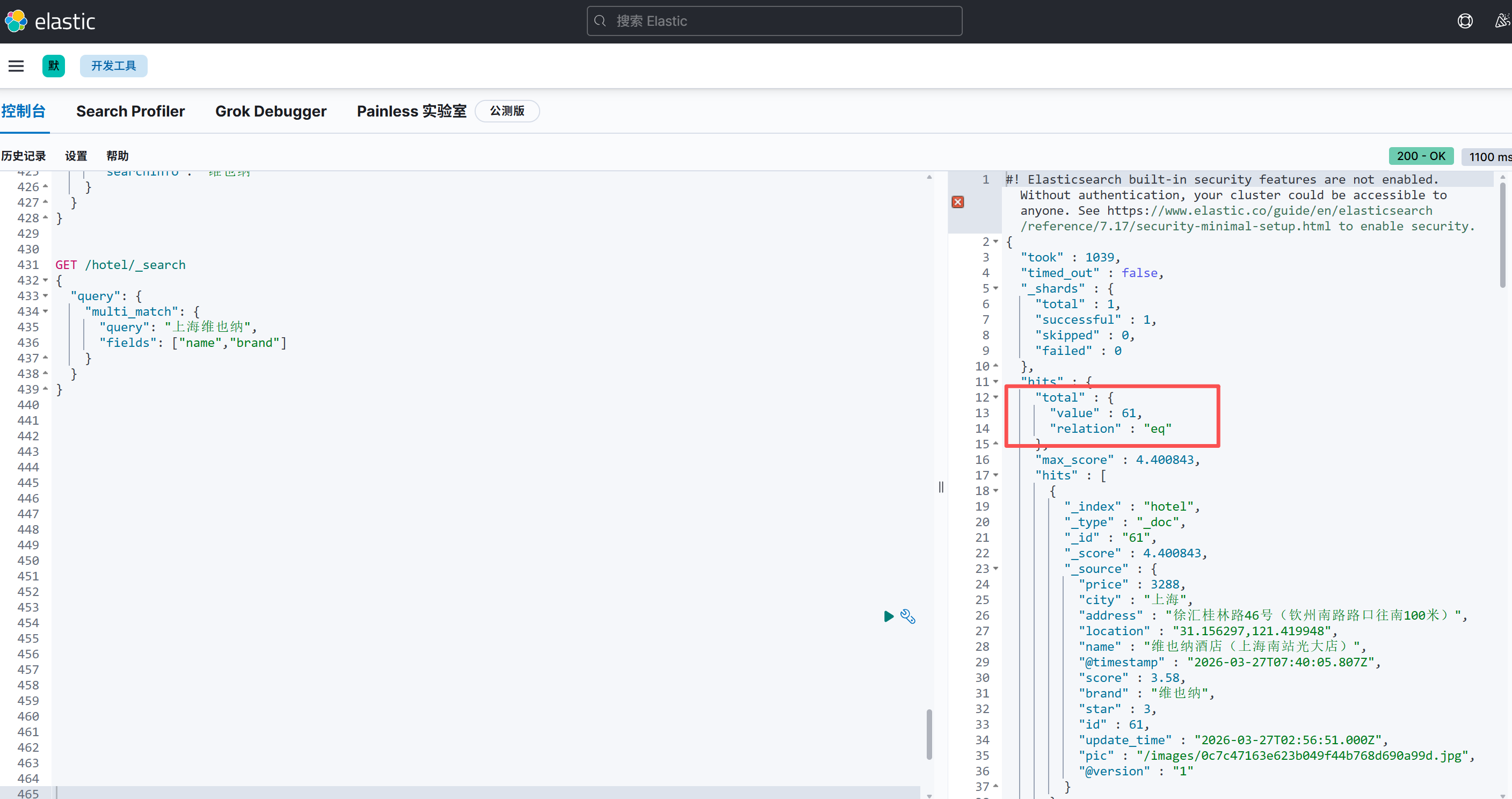
3.多字段检索
multi_match查询允许你在多个字段上执行全文搜索,与match类似,它也会进行分词,但是可以在多个字段上搜索给定的文本
bash
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "上海维也纳",
"fields": ["name","brand"]
}
}
}
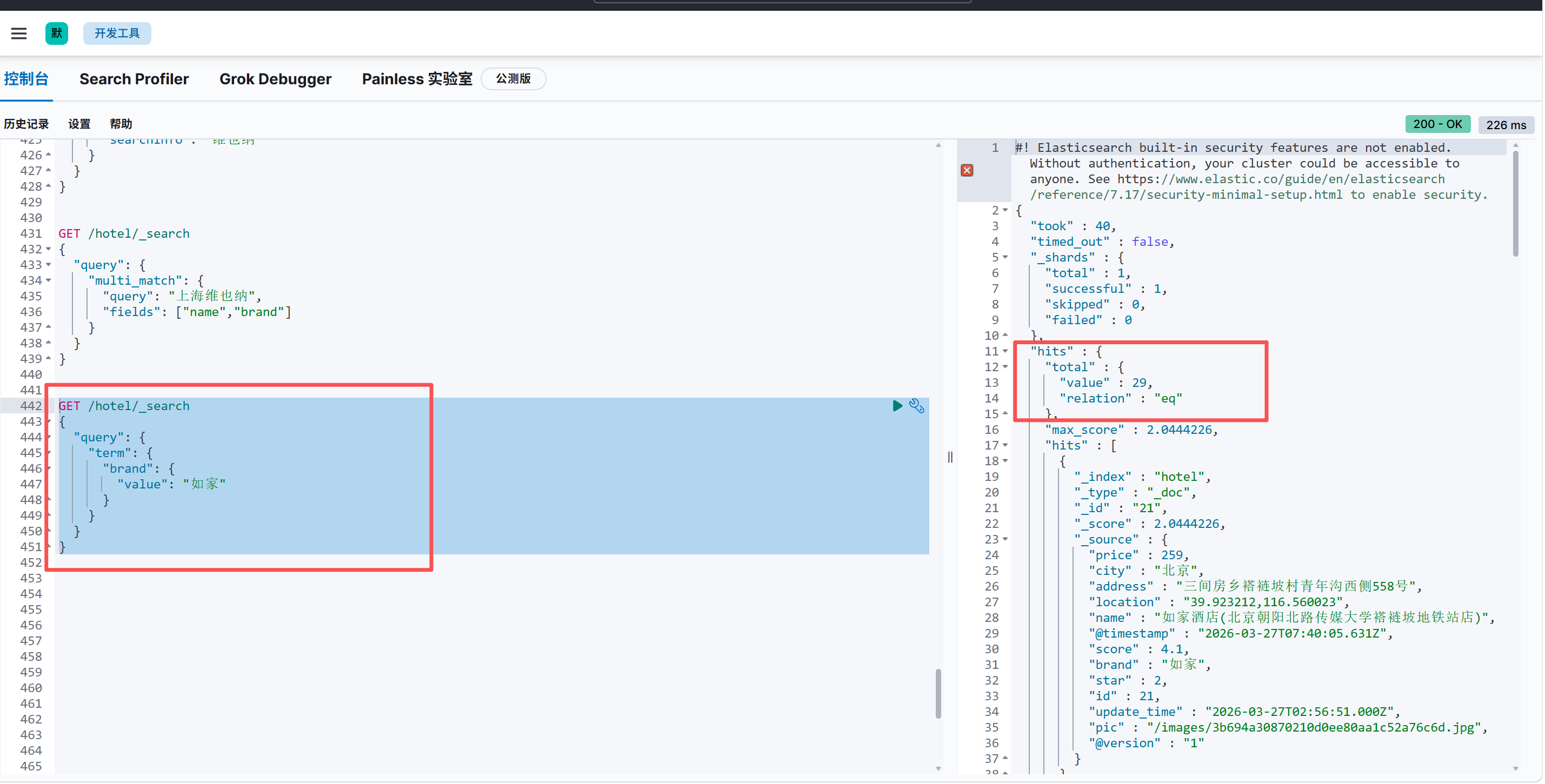
4.精确查询
单值精确匹配 term
bash
GET /hotel/_search
{
"query": {
"term": {
"brand": {
"value": "如家"
}
}
}
}
5.范围查询
range是范围查询,对于范围查询筛选的关键字有:
- gte:大于等于
- gt:大于
- lte:小于等于
- lt:小于
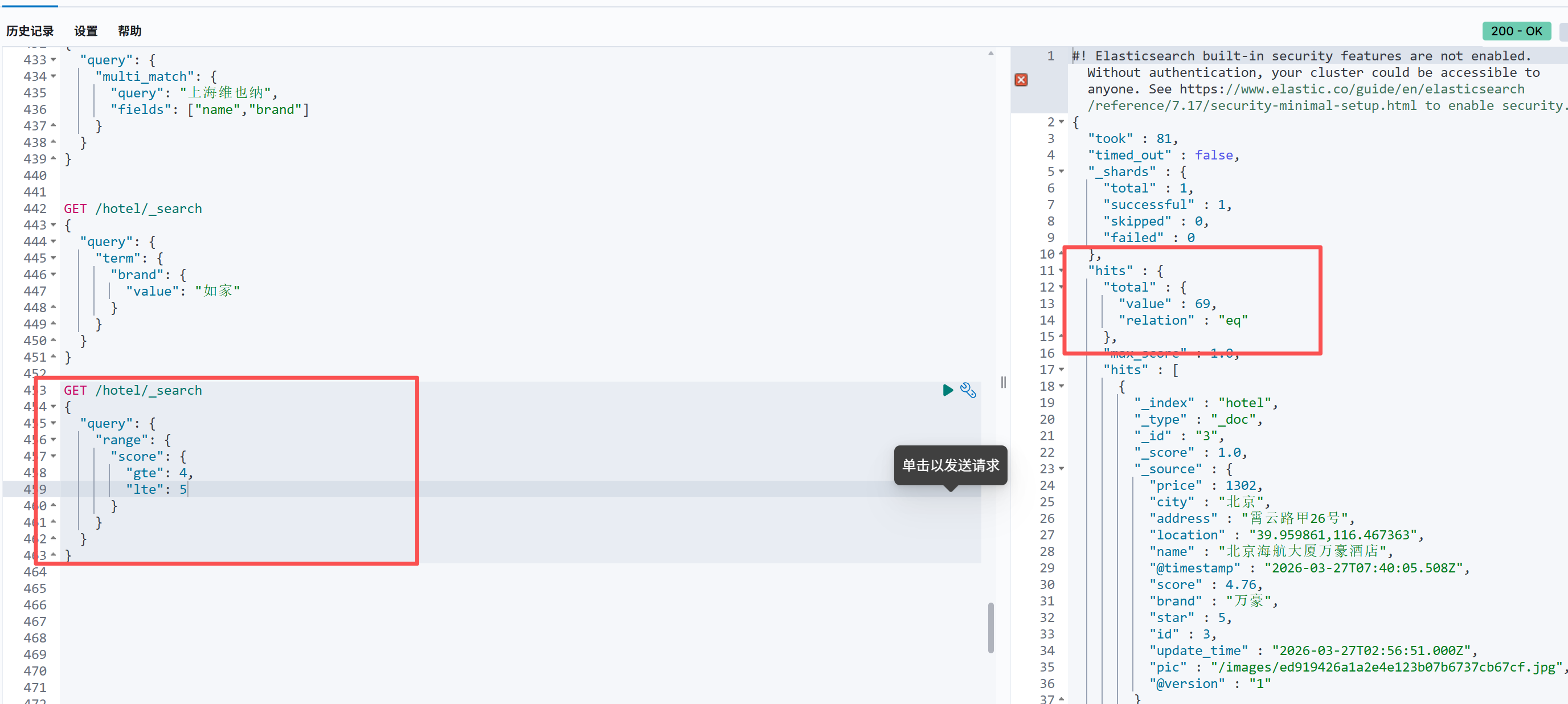
如果我们要查询评分在4到5之间的酒店数据:
bash
GET /hotel/_search
{
"query": {
"range": {
"score": {
"gte": 4,
"lte": 5
}
}
}
}
6.地理查询
地理查询 是 ES DSL 中特殊查询 的核心分支,专门用于地理位置数据检索,解决「附近搜索、地图圈选、地理边界过滤」等场景(比如外卖搜 3 公里内商家、地图找矩形 / 多边形内的景点、物流定位)。
它仅针对 ES 地理类型字段生效,是线下 LBS(基于位置服务)场景的必备查询语法。
使用地理查询前,必须先创建正确的地理字段类型,共 2 种:
表格
| 类型 | 用途 | 格式 | 适用场景 |
|---|---|---|---|
| geo_point | 地理坐标点(经纬度) | 经纬度组合 | 90% 场景(商家、用户、车辆定位) |
| geo_shape | 地理形状(点 / 线 / 面 / 多边形) | 复杂地理图形 | 进阶场景(区域边界、路线、商圈) |
✅ 工作中最常用:geo_point(下文重点讲解)
地理查询核心分类(3 种常用 + 1 种进阶)
基于 geo_point 有3 种高频查询,覆盖绝大多数 LBS 场景:
- geo_distance:圆形距离查询(搜某点周围 N 公里内 → 最常用)
- geo_bounding_box:矩形范围查询(地图矩形框选)
- geo_polygon:多边形范围查询(自定义不规则区域圈选)
- geo_shape:复杂形状查询(进阶,面与面的包含 / 相交)
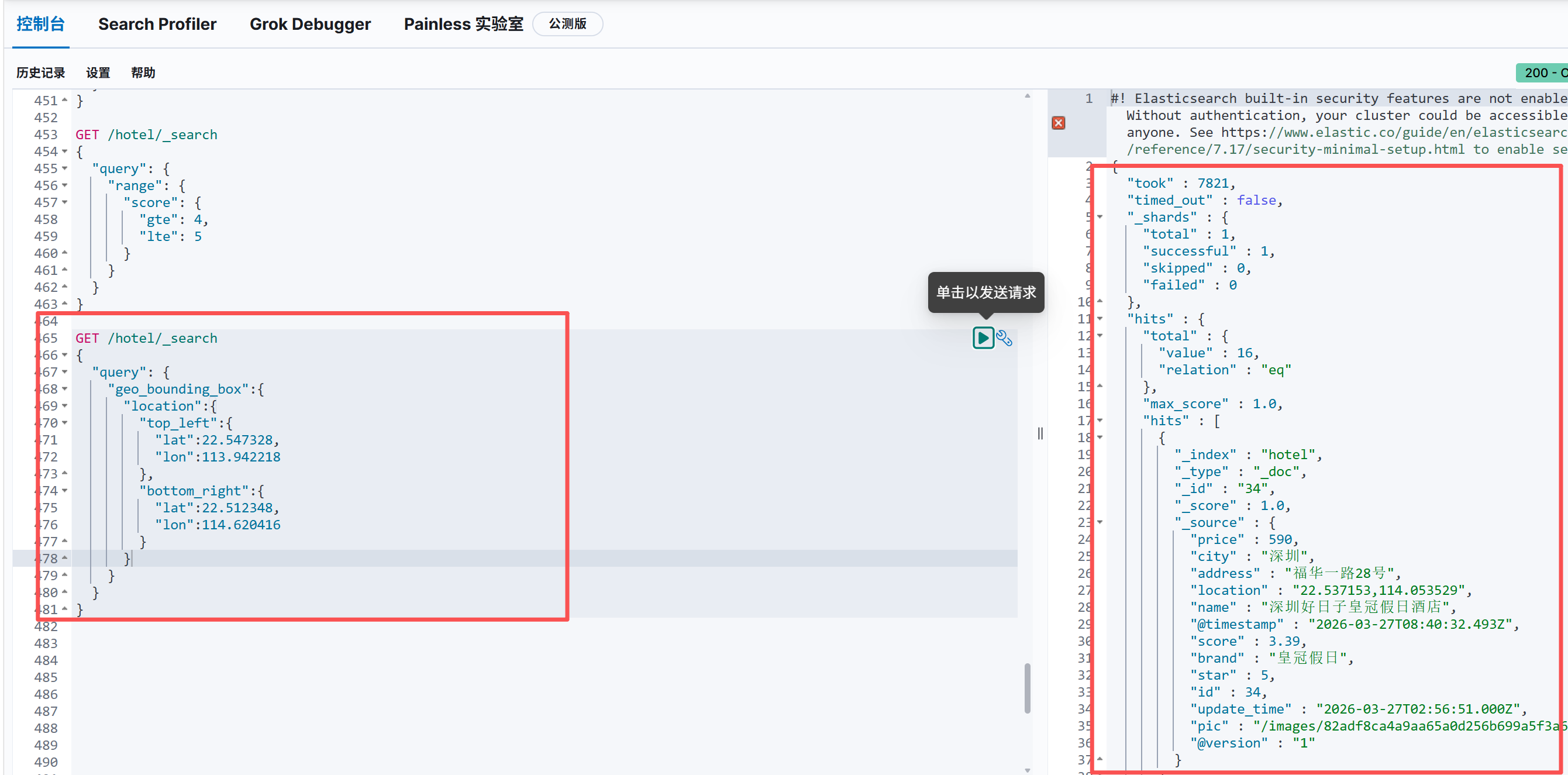
1.矩形范围搜索
场景 :地图上框选一个矩形区域,搜索区域内的商家
语法核心:
指定矩形左上角 + 右下角经纬度:
bash
GET /hotel/_search
{
"query": {
"geo_bounding_box":{
"location":{
"top_left":{
"lat":22.547328,
"lon":113.942218
},
"bottom_right":{
"lat":22.512348,
"lon":114.620416
}
}
}
}
}
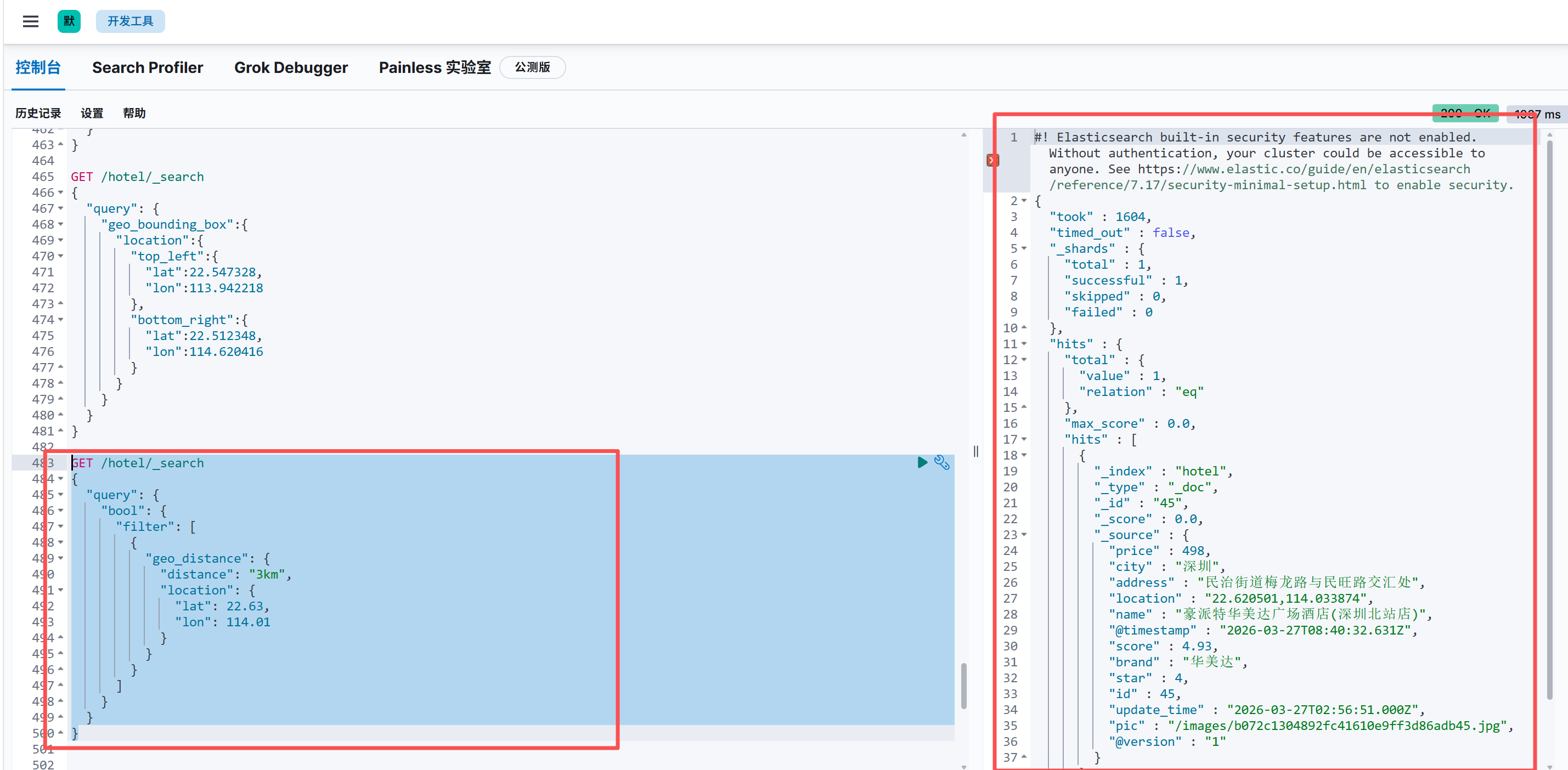
2.半径范围搜索:
场景:搜索「当前位置周围 3 公里内的所有商家」
语法核心:
distance:搜索半径(单位:km千米 /m米 /mi英里)location:中心点经纬度- 推荐用
filter(不打分、缓存、性能极高)
bash
GET /hotel/_search
{
"query": {
"bool": {
"filter": [
{
"geo_distance": {
"distance": "3km", // 指定距离,可以用m,km等等距离单位
"location": { // 值为中心点坐标
"lat": 22.63,
"lon": 114.01
}
}
}
]
}
}
}
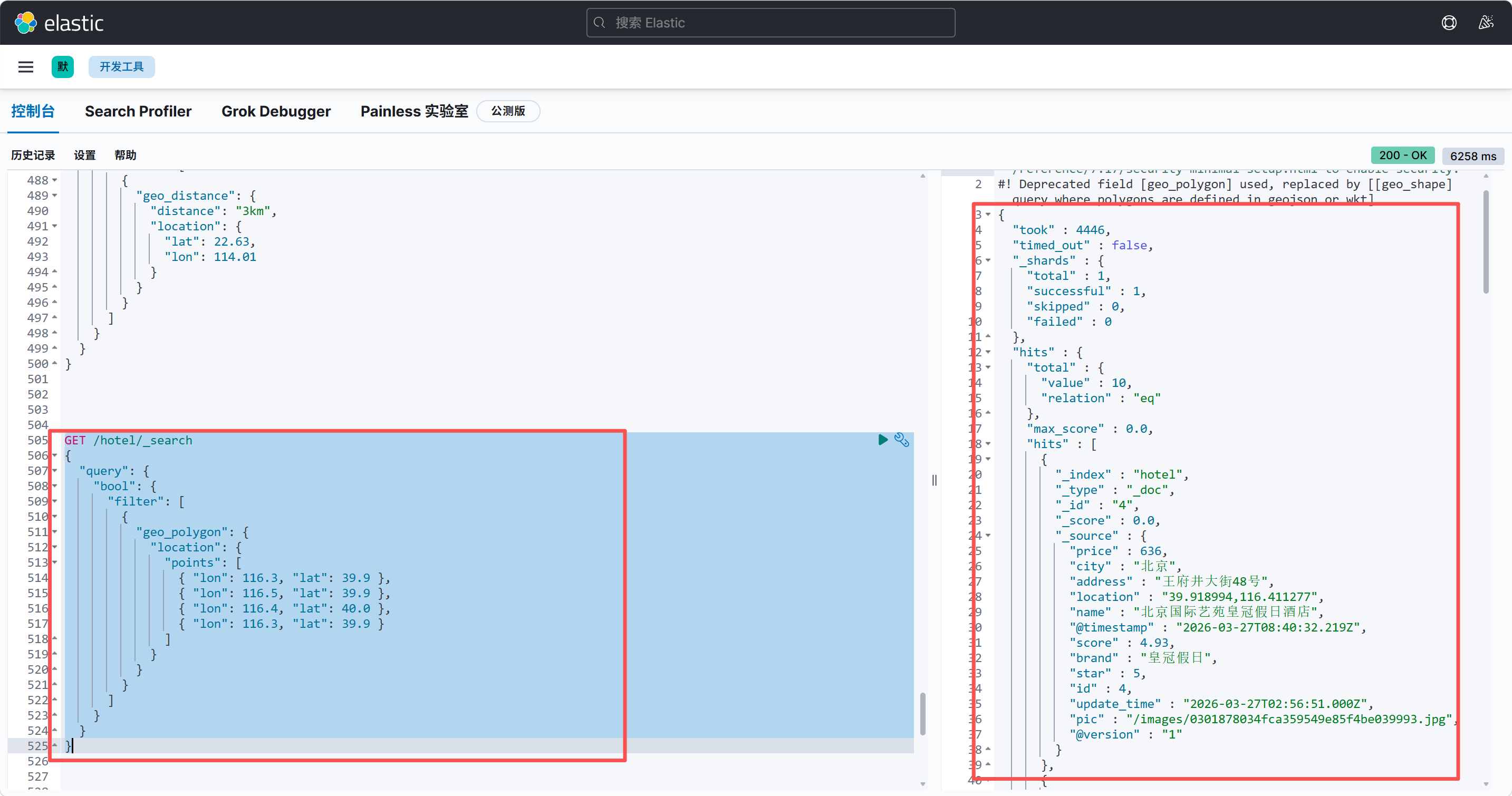
3. geo_polygon 多边形范围查询
场景 :自定义不规则多边形(如商圈、行政区),搜索区域内数据
语法核心:
传入 3 个及以上经纬度点,围成封闭多边形:
bash
GET /hotel/_search
{
"query": {
"bool": {
"filter": [
{
"geo_polygon": {
"location": {
"points": [
{ "lon": 116.3, "lat": 39.9 },
{ "lon": 116.5, "lat": 39.9 },
{ "lon": 116.4, "lat": 40.0 },
{ "lon": 116.3, "lat": 39.9 }
]
}
}
}
]
}
}
}
复合查询
DSL(Domain Specific Language)复合查询是 Elasticsearch 中用于构建复杂搜索逻辑的核心工具,它允许将多个叶子查询(如 match、term、range)或其他复合查询通过逻辑关系、评分调整等方式组合起来,实现精准的数据检索与排序控制Elastic。复合查询子句会包裹其他查询,并决定如何合并它们的结果和评分Elastic。
一、复合查询的核心概念
1.1 定义与作用
复合查询(Compound Query)是 Elasticsearch 查询 DSL 的重要组成部分,主要用于:
- 多条件组合:实现 "与 / 或 / 非" 等复杂逻辑运算
- 评分控制:自定义文档相关性分数,影响结果排序
- 查询与过滤分离:区分参与评分的查询条件和仅用于过滤的条件
- 嵌套组合:支持多层查询嵌套,构建高度复杂的搜索逻辑
1.2 与叶子查询的区别
表格
| 特性 | 叶子查询 | 复合查询 |
|---|---|---|
| 作用对象 | 特定字段的具体值 | 组合多个查询(叶子或复合) |
| 功能 | 基础数据匹配 | 逻辑组合、评分调整、过滤 |
| 示例 | match、term、range | bool、dis_max、function_score |
| 上下文 | 可在查询或过滤上下文 | 通常在查询上下文,可包含过滤子句 |
二、四种核心复合查询类型
Bool 查询(布尔查询)
最常用的复合查询,通过布尔逻辑组合多个查询条件,支持四种子句类型Elastic:
| 子句类型 | 含义 | 是否参与评分 | 典型场景 |
|---|---|---|---|
| must | 必须匹配(逻辑与) | ✅ 是 | 核心搜索条件,如全文检索关键词 |
| filter | 必须匹配(逻辑与) | ❌ 否 | 结构化过滤,如价格区间、品牌筛选 |
| should | 应该匹配(逻辑或) | ✅ 是 | 可选条件,匹配越多评分越高 |
| must_not | 必须不匹配(逻辑非) | ❌ 否 | 排除特定条件,如不显示缺货商品 |
Function Score 查询(函数评分查询)
自定义文档评分逻辑 ,允许通过函数修改查询结果的原始评分,实现业务导向的排序策略,如按销量、价格、时效性加权等场景。
支持的评分函数包括:
weight:直接设置权重因子field_value_factor:基于字段值计算分数(如销量越高分数越高)random_score:随机评分(用于 AB 测试)script_score:通过脚本自定义复杂评分逻辑
bash
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"searchInfo": "如家酒店"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "万丽"
}
},
"weight": 100
}
],
"boost_mode": "sum"
}
}
}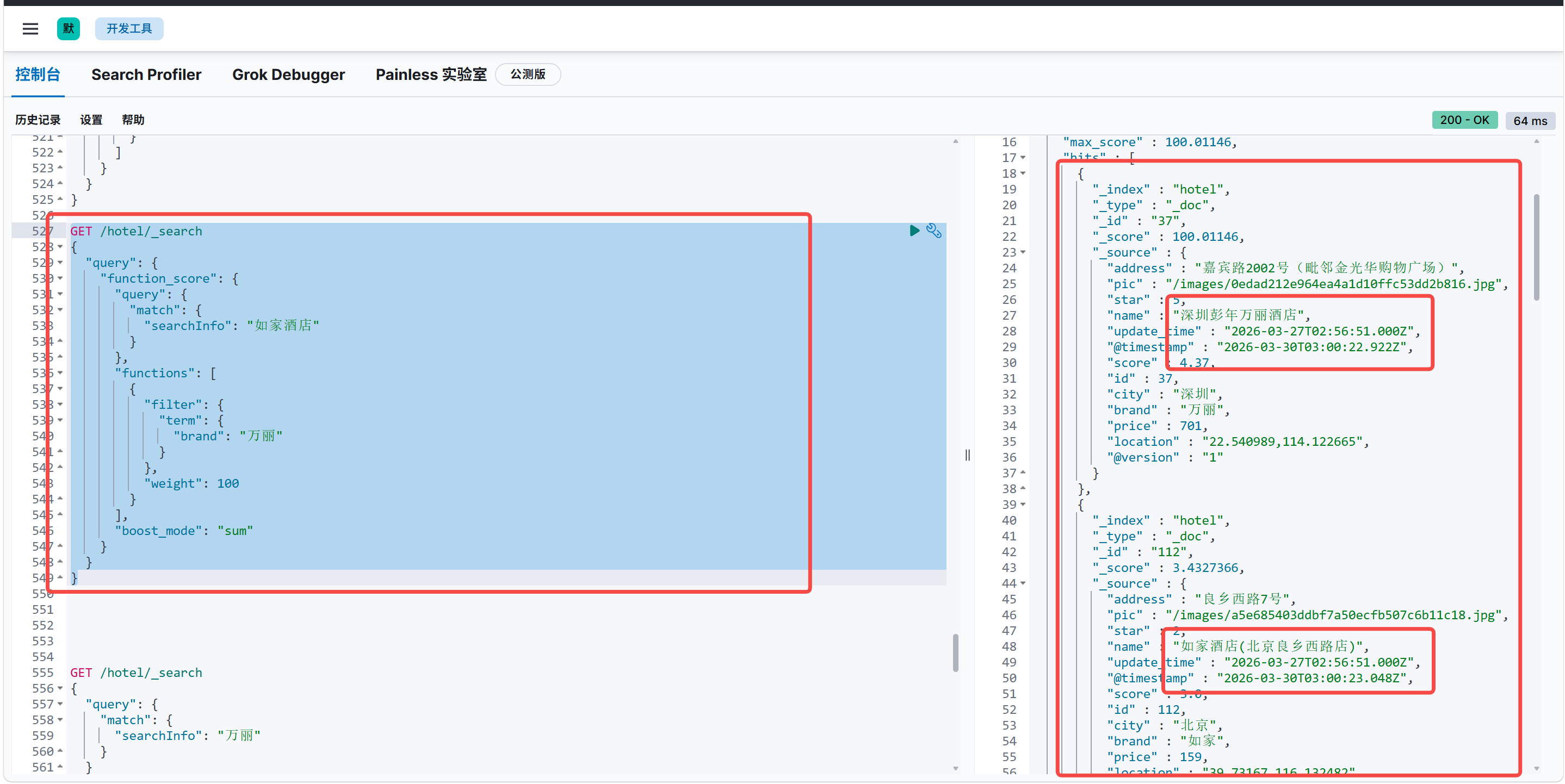
上述DSL中我们查询的是如家酒店但是单独给万丽加了权重所以万丽显示在第一行,这个就可以实现广告投放的一个效果,用户搜索酒店万丽酒店充值了所以广告排在第一
布尔查询:
2.1 Bool 查询(布尔查询)
最常用的复合查询,通过布尔逻辑组合多个查询条件,支持四种子句类型Elastic:
| 子句类型 | 含义 | 是否参与评分 | 典型场景 |
|---|---|---|---|
| must | 必须匹配(逻辑与) | ✅ 是 | 核心搜索条件,如全文检索关键词 |
| filter | 必须匹配(逻辑与) | ❌ 否 | 结构化过滤,如价格区间、品牌筛选 |
| should | 应该匹配(逻辑或) | ✅ 是 | 可选条件,匹配越多评分越高 |
| must_not | 必须不匹配(逻辑非) | ❌ 否 | 排除特定条件,如不显示缺货商品 |
bash
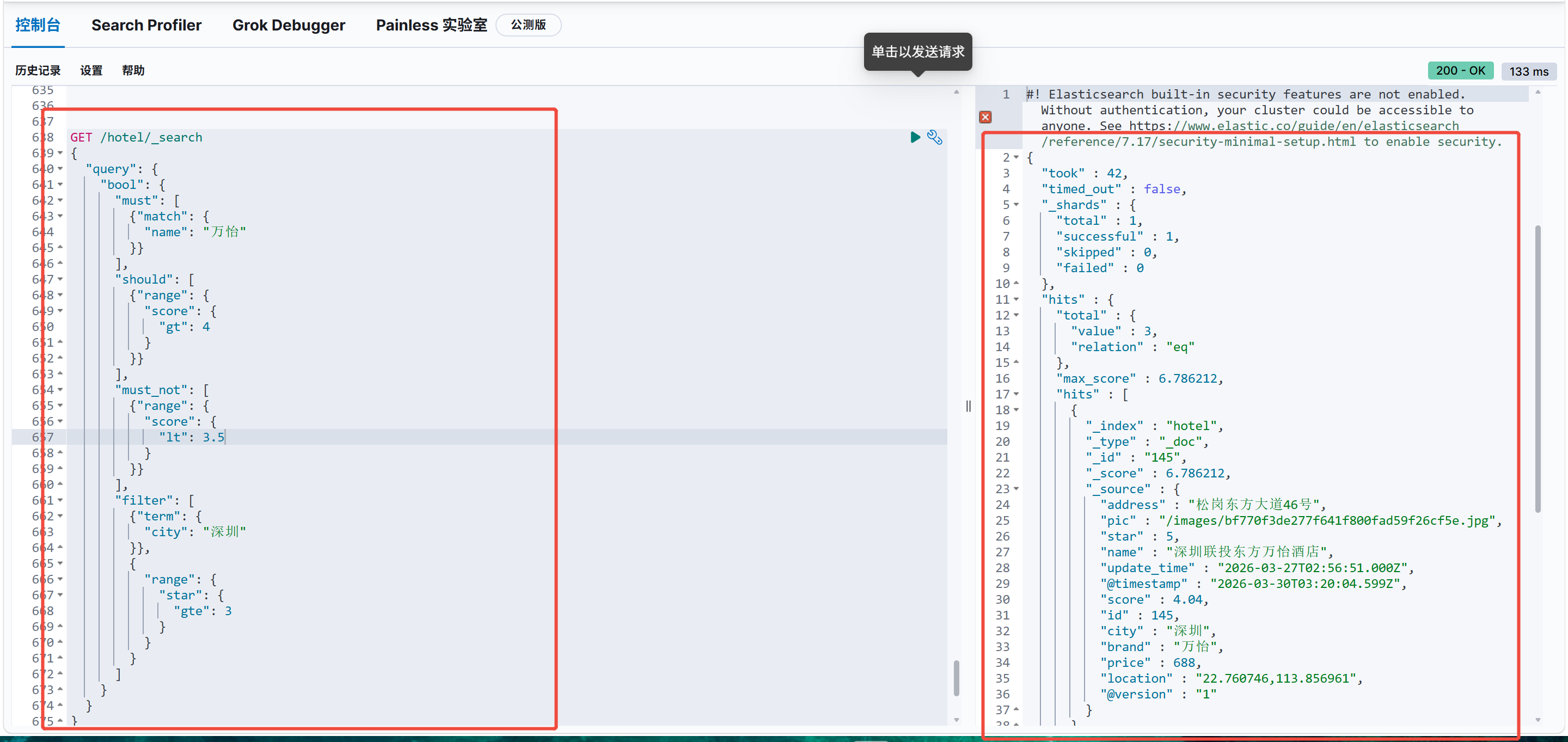
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "万怡" // 找出名称匹配万怡的
}}
],
"should": [
{"range": {
"score": {
"gt": 4 // 找出分数高于4的优先显示
}
}}
],
"must_not": [
{"range": {
"score": {
"lt": 3.5 // 低于3.5分的数据排除
}
}}
],
"filter": [
{"term": {
"city": "深圳" // 过滤出酒店在深圳的
}},
{
"range": {
"star": {
"gte": 3 // 过滤3星级酒
}
}
}
]
}
}
}
搜索结果处理
我们学会了搜索API的基本使用,按照相关性算法我们只是针对特定数据,如果需要进行排序,分页等就需要进行另外的操作了
排序搜索结果
再关系型数据库中要排序非常简单,通过order by关键字即可,那么在ES中排序也非常简单,通过sort选项允许用户控制搜索结果的返回顺序 ,升序(ASC)降序(DESC)
我们来写一段查询,查询深圳的酒店评分从高到低排序如果评分相同,则按照价格从高到低排序,如何实现:
bash
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "深圳"
}
}
},
"sort": [
{ "score": {"order": "desc"}},
{ "price": {"order": "asc"}}
]
}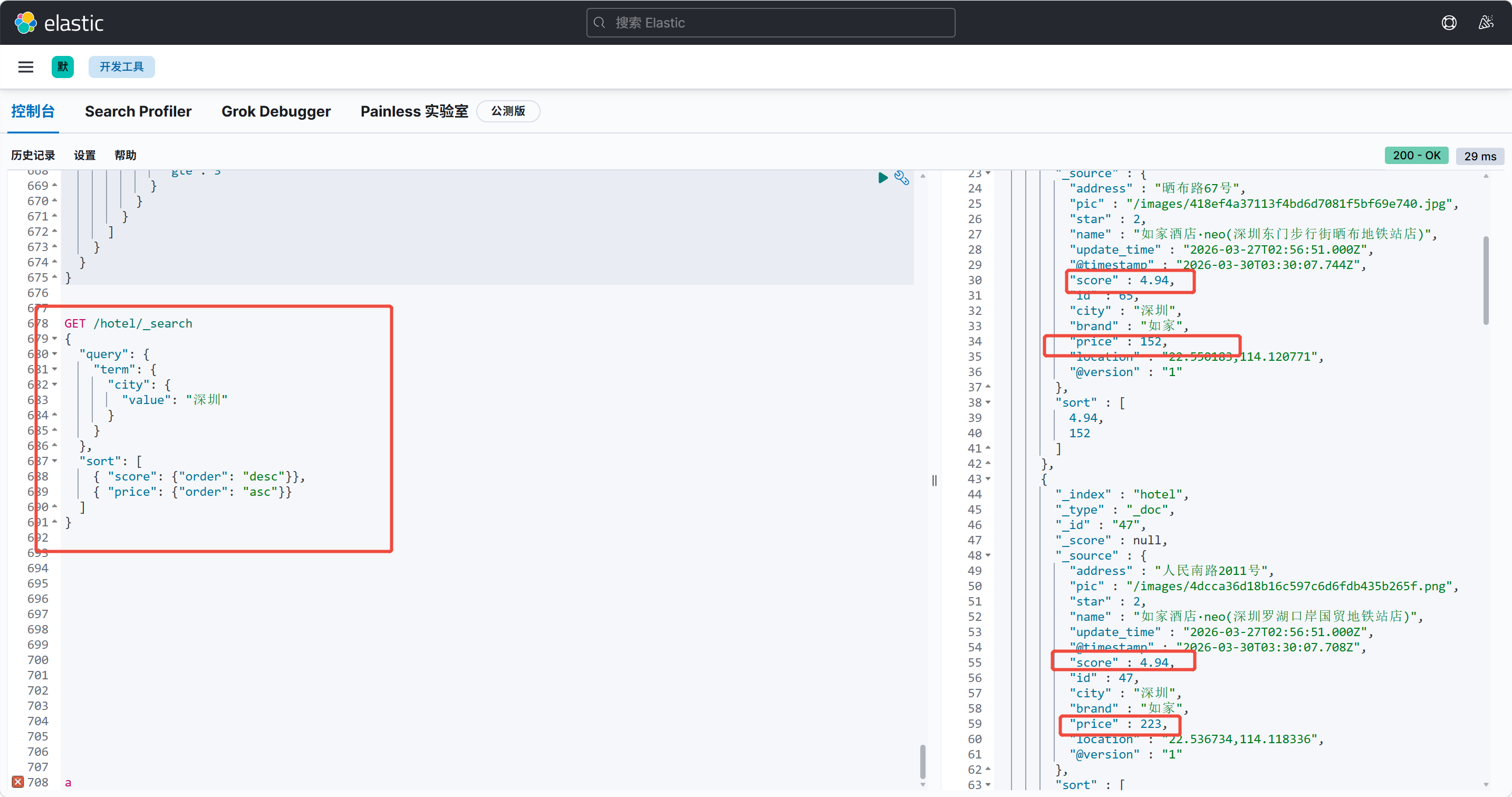
从查询结果来看第1条数据分数和第2条相同,所以按照价格从低到高
分页搜索结果
在ES中默认分页显示前10条数据,因为ES分页参数默认size默认是10,我们可以通过调整form,size实现分页
例如我们查询所有酒店信息,以价格的升序排序,返回前5条
bash
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from": 0, // 起始的位置
"size": 5 // 每页多少条数据
}Spring Boot整合ElasticSearch
项目搭建
1.核心依赖
添加ElasticSeach依赖
XML
<!-- 统一版本需要与你安装的版本一致 -->
<elasticsearch.version>7.17.10</elasticsearch.version>
<!-- 核心依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- ES低级别客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- ES高级客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>添加FastJSON2依赖
XML
<fastjson2.version>2.0.49</fastjson2.version>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>添加工具包
为了方便开发,我们可以添加commons-lang3
XML
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.17.0</version>
</dependency>配置RestHighLevelClient对象
RestHighLevelClient 是 Elasticsearch 7.x 官方推荐的 Java 高级客户端,基于 RESTful API 封装,用来在 Java 中操作 ES。
- 底层走 HTTP(9200 端口),替代了旧的 TransportClient
- 语法贴近原生 DSL,支持查询、增删改、批量、聚合、高亮等
- 结构清晰、稳定易用,是 Spring Boot 整合 ES 最常用的客户端
- ES 8.x 已废弃 ,被新的
ElasticsearchClient取代
配置配置RestHighLevelClient对象
在SpringBoot中我们可以通过配置类创建Bean注入到Spring容器中,作为ES的操作能力,创建一个config包并创建ElasticSearchConfig文件
java
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
// 配置ES节点的地址和端口
HttpHost host = new HttpHost("192.168.126.140",9200,"http");
// 返回RestHighLevelClient对象
return new RestHighLevelClient(RestClient.builder(host));
}
}注意:这些配置应该通过application配置文件去配置,这里为了快速入门,简化了流程
通过RestHighLevelClient操作文档
参考索引创建文档实体类
java
@Data
public class HotelDoc {
// 字段名要和Elasticsearch中的一致,类型要兼容
/** 酒店的地址 */
private String address;
/** 酒店的品牌 */
private String brand;
/** 酒店所在的城市 */
private String city;
/** 酒店的唯一标识符 */
private String id;
/** 酒店的经纬度信息 */
private String location;
/** 酒店的名称 */
private String name;
/** 酒店的图片URL或路径 */
private String pic;
/** 酒店的价格 */
private int price;
/** 酒店的评分 */
private float score;
/** 酒店的星级 */
private byte star;
}定义数据访问层
定义CRUD方法
java
public interface HotelDao {
/** 添加酒店文档 */
public boolean insert(HotelDoc hotelDoc);
/** 根据酒店ID获取酒店文档 */
public HotelDoc getById(String id);
/** 更新酒店文档 */
public boolean update(HotelDoc hotelDoc);
/** 删除酒店文档 */
public boolean delete(String id);
}实现添加文档
java
@Repository
public class HotelDaoImpl implements HotelDao {
// 默认请求选项
private final RequestOptions requestOptions = RequestOptions.DEFAULT;
// 定义索引常量名
private static final String INDEX_NAME = "hotel";
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public boolean insert(HotelDoc hotelDoc) {
try{
IndexRequest request = new IndexRequest(INDEX_NAME,"_doc")
.id(hotelDoc.getId()).source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 通过客户端发送新增文档请求
this.restHighLevelClient.index(request,requestOptions);
return true;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
@Override
public HotelDoc getById(String id) {
return null;
}
@Override
public boolean update(HotelDoc hotelDoc) {
return false;
}
@Override
public boolean delete(String id) {
return false;
}
}测试文档添加
java
@Test
void addHotelDoc() {
HotelDoc hotelDoc = new HotelDoc();
// 定义一个测试id
hotelDoc.setId("999");
// 测试数据
hotelDoc.setCity("深圳");
hotelDoc.setAddress("福田区福华三路");
hotelDoc.setBrand("万豪酒店");
hotelDoc.setName("深圳福田万豪酒店");
hotelDoc.setLocation("22.543063,114.057868"); // 经纬度
hotelDoc.setPic("http://example.com/hotel-pic.jpg");
hotelDoc.setPrice(800);
hotelDoc.setScore(4.8f);
hotelDoc.setStar((byte) 3);
boolean inserted = hotelDao.insert(hotelDoc);
if(inserted){
System.out.println("新增成功!");
}else{
System.out.println("新增失败!");
}
}我们来运行一下测试

提示新增成功,再Kibanan去查一遍ID为999的文档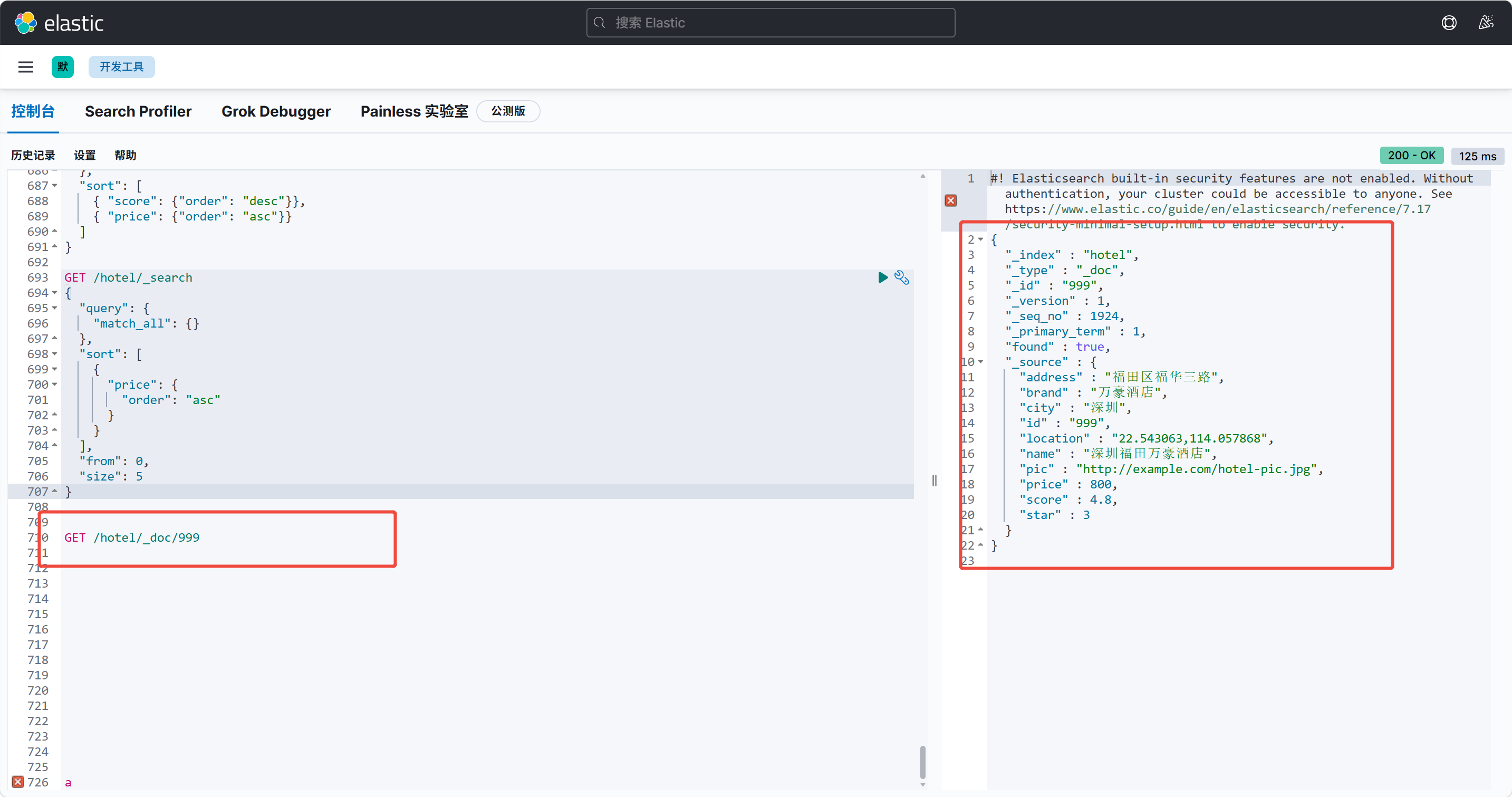
实现文档其他操作
通过新增文档我们了解了RestHighLevelClient的基本操作,其他文档操作我们只需要遵循相同规则,查看官方文档即可
java
@Repository
public class HotelDaoImpl implements HotelDao {
// 默认请求选项
private final RequestOptions requestOptions = RequestOptions.DEFAULT;
// 定义索引常量名
private static final String INDEX_NAME = "hotel";
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public boolean insert(HotelDoc hotelDoc) {
try{
IndexRequest request = new IndexRequest(INDEX_NAME,"_doc")
.id(hotelDoc.getId()).source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 通过客户端发送新增文档请求
this.restHighLevelClient.index(request,requestOptions);
return true;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
@Override
public HotelDoc getById(String id) {
GetRequest request = new GetRequest(INDEX_NAME,"_doc",id);
try {
String json = restHighLevelClient.get(request, requestOptions).getSourceAsString();
return JSON.parseObject(json, HotelDoc.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public boolean update(HotelDoc hotelDoc) {
UpdateRequest request = new UpdateRequest(INDEX_NAME,"_doc",hotelDoc.getId())
.doc(JSON.toJSONString(hotelDoc),XContentType.JSON);
try {
return restHighLevelClient.update(request,requestOptions).getResult() ==
UpdateResponse.Result.UPDATED;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public boolean delete(String id) {
DeleteRequest request = new DeleteRequest(INDEX_NAME,"_doc",id);
try {
return restHighLevelClient.delete(request,requestOptions).getResult() ==
UpdateResponse.Result.DELETED;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}上述代码中可以了解到各个方法创建的Request对象有所区别
- 新增使用IndexRequest,使用source方法定义请求体
- 修改使用UpdateRequest,使用doc方法定义请求体
- 查看使用GetRequest,不需要请求体
- 删除使用DeleteRequest,不需要请求体