前言
树与二叉树是数据结构中重中之重的核心模块 ,既是数组、链表之后最常用的非线性结构,也是学习 AVL树、红黑树、堆、哈夫曼编码、B+树 等高级结构的前置基础。同时它也是考研、计算机复试、后端面试、算法笔试的高频考点,几乎逢考必出。因此本文从零梳理树与二叉树全套基础原理,统一全文定义规范 、分层拆解知识点、加粗标记核心考点、对比所有易混淆概念、配套公式推导与代码实现,适配「零基础入门」和「考研面试冲刺复盘」两类人群。全文由浅入深、体系闭环,你可以把它当作二叉树零基础教程 + 考前速查手册,通读一遍即可搞定绝大部分基础考点。
学习导航
本文约定
为规避不同教材定义冲突,全文统一以下标准,所有原理、公式、考点均基于该约定,无特例矛盾:
-
根节点深度 = 0(如无特殊说明,全文统一执行)
-
空树高度 = 0
-
叶子节点高度为0
-
所有"节点数"均特指非空有效节点,空节点不纳入统计范围
阅读路径建议 ⭐
针对零基础、备考、快速复盘三类人群定制专属阅读方案,精准降低学习负荷,高效突破重点:
|------------|-------------------------------|--------------------|---------------------|
| 读者类型 | 必读章节 | 选读章节 | 可跳过章节 |
| 初学者(第一次接触) | 1,2,3,4(性质1-3),5(满/完全/退化),6,7 | 4(性质4-5),5(线索),8,9 | 4(推导关系),5(哈夫曼细节),10 |
| 考研/面试复习 | 全部 | --- | --- |
| 快速回顾 | 3,4(性质速览),5(对比表),7,9,11 | 8,10 | 1,2 |
前置知识确认
学习本文全部内容,无需深厚编程基础,只需掌握三个基础逻辑即可轻松看懂:
-
✅ 理解递归的含义(不要求会写代码,只需懂自嵌套子结构逻辑)
-
✅ 理解栈的后进先出核心逻辑
-
✅ 理解队列的先进先出核心逻辑
1. 什么是树
1.1 树的定义
树是数据结构中核心的非线性层次结构 ,彻底区别于数组、链表的一对一线性关系,核心特征是一对多的层级关联,是二叉树、图等复杂结构的基础。
标准递归定义:树是n(n≥0)个节点的有限集合,严格满足以下两个条件:
-
当 n = 0 时,为空树,是合法的树结构
-
当 n > 0 时,有且仅有一个根节点 ,其余所有节点可划分成m个互不相交的有限子树,每个子树均遵循树的递归定义
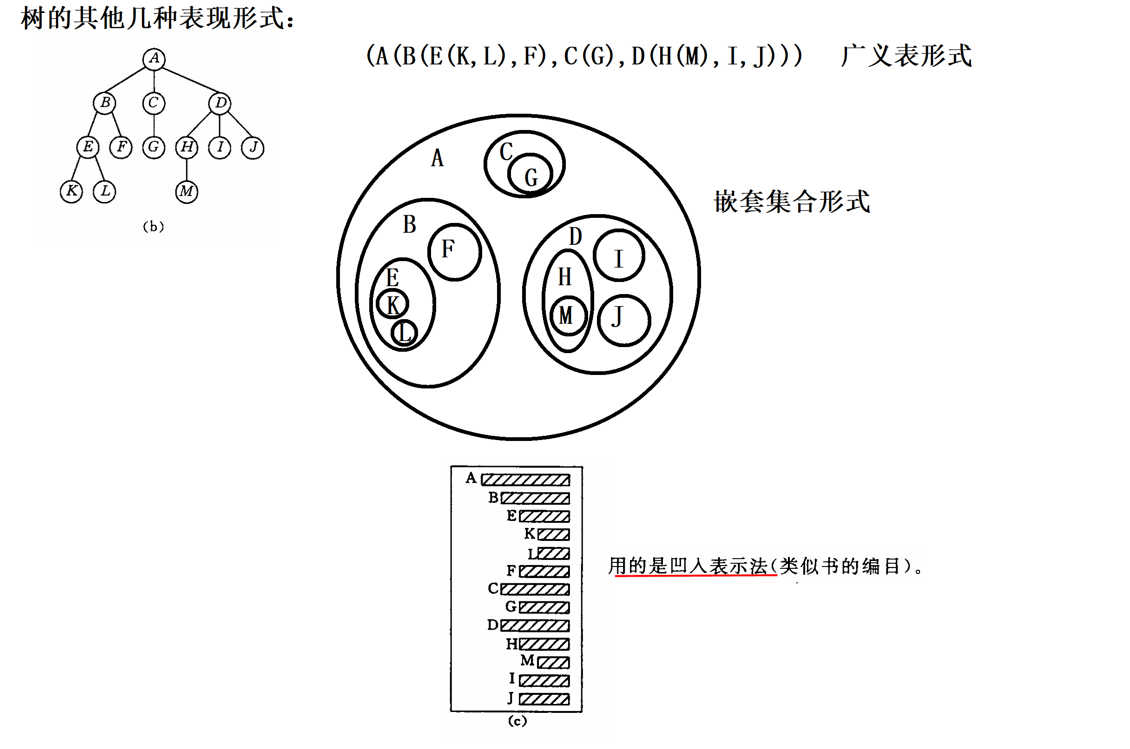
1.2 树的三种表示法
三种表示法仅用于笔试理论考察、结构可视化,无实际代码应用,核心作用是直观体现树的嵌套层级关系:
|------------|-------------------------|-----|
| 表示法 | 核心思想 | 示例 |
| 括号表示法(广义表) | 通过嵌套括号直接表达父子层级,简洁直观 | 如下图 |
| 嵌套集合表示法 | 利用集合包含关系体现层级,父集合包裹子节点集合 | 如下图 |
| 凹入表示法 | 通过缩进区分层级,缩进越多,节点层级越低 | 如下图 |
1.3 树的基本运算
树的基础运算是后续二叉树各类算法的铺垫,所有操作均围绕层级、父子、子树三大核心展开:
-
查找根:输入任意树/子树,返回其顶层唯一根节点,是遍历、查找算法的基础
-
求父节点:给定任意非根节点,返回其直接上层相邻节点(不含间接祖先)
-
求子树:给定任意节点,返回以该节点为新根的完整子树结构
-
判空:判断树的节点总数是否为0,区分空树与非空树
1.4 树的现实应用
树结构的核心价值是高效存储层级关系数据,现实中绝大多数分层场景均采用树结构实现:
-
操作系统目录结构:盘符→文件夹→子文件夹→文件,标准多层树状层级
-
企业组织架构图:高层→部门→员工,实现一对多层级管理
-
HTML文档对象模型(DOM):根标签→父标签→子标签,是网页结构的底层载体
2. 树的相关概念
本章所有名词是二叉树学习的核心基石,后续所有性质、判定、考点均依托这些概念,必须精准区分,杜绝混淆。
2.1 节点关系类
|-------|-----------------------------------------|
| 概念 | 定义 |
| 根节点 | 整棵树中唯一没有父节点的顶层节点,是树的起始节点 |
| 子节点 | 一个节点拥有的子树的根节点称之为该节点的孩子节点 |
| 父节点 | 相应的,该节点就是其孩子节点的父节点 |
| 兄弟节点 | 同一父节点下辖的所有子节点,互为兄弟节点 |
| 叶子节点 | 度为0的节点,无任何子节点,是树的末端节点 |
| 祖先/后代 | 祖先:从根节点到当前节点路径上的所有节点;后代:当前节点所有子树包含的全部节点 |
| 堂兄弟 | 父节点为兄弟关系的同级节点,层级相同、父节点不同 |
2.2 度量类
|-------|-------------------------------------|
| 概念 | 定义 |
| 节点的度 | 该节点拥有的直接子节点个数,与后代节点数量无关 |
| 树的度 | 树中所有节点的度的最大值,代表树的最大分支数 |
| 节点的层次 | 根节点为第1层,每向下一层,层次数+1 |
| 节点的深度 | 从根节点出发,到该节点经过的唯一路径中边的个数 (根节点的深度是0) |
| 节点的高度 | 从该节点出发,到其叶子结点的最长路径上边的个数 (叶子节点的高度是0) |
| 树的深度 | 树中所有节点的最大层次数,即树的纵向最大层数 |
| 树的高度 | 从叶子节点向上到根节点的最大边数 |
| 路径 | 从一个节点到另一个节点经过的边的序列,树中任意两点有唯一路径 |
| 路径长度 | 路径中包含的边的数量(非节点数量) |
2.3 结构类
-
森林 :m(m≥0)棵互不相交、相互独立的树的集合。空森林包含0棵树,单棵树可视为特殊森林,支持与二叉树相互转换。
-
有序树 :子节点之间存在固定顺序,交换任意子节点位置,会生成全新的树结构,结构不等价。
-
无序树:子节点之间无顺序区分,交换子节点位置后,树结构完全等价,无变化。
3. 什么是二叉树
3.1 二叉树的严格定义
二叉树是树结构中考察最多、应用最广的核心分支,拥有专属严格约束,并非普通树的简单特例,核心规则如下:
-
每个节点的度 ≤ 2,即任意节点最多拥有两个子节点
-
左右子树严格有序:即使节点仅有一棵子树,也必须明确区分左、右子树,位置不可互换
-
支持空树结构,空二叉树是合法的二叉树形态
3.2 ⭐ 关键区分:二叉树 vs 度为2的有序树
这是高频易错考点 ,绝大多数初学者易混淆,核心结论:二叉树不是树的特例,是完全独立的数据结构。
|---------|------------------------|-----------------------------|
| 对比维度 | 二叉树 | 度为2的有序树 |
| 是否允许空树 | ✅ 允许空树,定义包含空结构 | ❌ 不允许空树,默认存在有效节点 |
| 节点度范围 | 0、1、2 均合法,无强制约束 | 树中所有节点的度 ≤ 2,且至少有一个节点的度 = 2 |
| 左右子树的区分 | 严格区分,即使单侧子树为空,左右位置依然固定 | 仅区分子树顺序,不强调空位置的合法性 |
| 结论 | 二叉树不是树的特例,而是独立结构 | 普通有序树的特殊形态,归属普通树范畴 |
延申:度为 m 的有序树
- 所有节点 最多只能有 m 个分支(不能超)
- 必须至少有一个节点刚好拉满 m 个分支(否则不叫度为 m 的树)
总结:树中所有节点的度 ≤ m,且至少有一个节点的度 = m
3.3 二叉树的五种基本形态
所有复杂二叉树,均可拆解为以下五种基础形态的组合,是认知二叉树结构的基础:
-
空二叉树:无任何节点,高度为0
-
只有根节点:仅存在一个根节点,无左右子树,度为0
-
根节点 + 左子树:右子树为空,仅保留左侧分支
-
根节点 + 右子树:左子树为空,仅保留右侧分支
-
根节点 + 左右子树均非空:双侧分支完整,节点度为2
具体结构如下图:

4. 二叉树的性质
💡 本章分层学习:性质1-3为必考核心 ,选择、填空、计算题高频考察;性质4-5及推导关系为选读,考研、深度面试必须掌握,零基础可暂时跳过。
4.1 ⭐ 性质1(每层最大节点数)
核心结论:二叉树的第 i 层,最多有 2^(i-1) 个节点(i ≥ 1)。
推导逻辑:二叉树单个节点最多衍生2个子节点,因此每一层的最大节点数,是上一层最大节点数的2倍,逐层形成2的幂次规律。
关联考点:是满二叉树、完全二叉树节点计算的底层核心依据。
4.2 ⭐ 性质2(深度为k的最大节点数)
核心结论:深度为 k 的二叉树,最多有2^k − 1 个节点(k ≥ 1)。
推导逻辑:基于性质1,每层最大节点数构成等比数列:1、2、4、8...2^(k-1),通过等比数列求和公式可得总节点最大值,该数值也是满二叉树的固定总节点数。
核心用途:快速判定满二叉树、计算二叉树最大容量。
4.3 ⭐ 性质3(叶子节点与度为2节点的关系)
核心结论:对任意二叉树,恒定满足 n0 = n2 + 1,无任何例外。
参数说明:n0=叶子节点数(度为0),n1=度为1的节点数,n2=度为2的节点数。
推导思路:
-
总节点数公式:n = n0 + n1 + n2
-
树的总边数公式:n − 1(n个节点的树,固定有n-1条连通边)
-
总边数也可通过度数计算:总边数 = n1 + 2·n2
-
联立化简得最终公式:n0 = n2 + 1
高频考点:已知叶子节点数,可直接推导度为2的节点数,无需其他条件。
4.4 性质4(节点数与高度的关系)
该性质用于通过节点数计算二叉树高度,区分两种极端场景:
-
最好情况(满二叉树) :节点分布最紧凑,高度最小,公式:h = ⌊log₂ n⌋ + 1
-
最坏情况(斜树) :节点单侧分布,高度最大,公式:h = n
⭐ 补充推论(完全二叉树核心) :高度为 h 的完全二叉树,节点数 n 严格满足:2^(h-1) ≤ n ≤ 2^h − 1。下限为该高度完全二叉树最少节点数,上限为满二叉树最大节点数。
4.5 ⭐ 性质5(完全二叉树的编号规律)
对完全二叉树进行层序编号(从1开始),任意编号为i的节点,满足固定寻址公式,是数组存储、堆结构的底层原理:
-
节点 i 的左子节点编号 = 2i(2i ≤ n 时存在)
-
节点 i 的右子节点编号 = 2i + 1(2i+1 ≤ n 时存在)
-
节点 i 的父节点编号 = ⌊i / 2⌋(i ≥ 2,根节点无父节点)
核心价值:无需遍历,通过算术运算即可O(1)时间定位父子节点,支撑堆排序、优先队列实现。
5. 几种特殊的二叉树
本章汇总6种高频特殊二叉树,是考试、面试核心考点,重点区分易混淆定义与判定规则。
5.1 六大特殊二叉树速览表 ⭐
|----------------|-----------------------------------|-----------------------|----------------------|
| 类型 | 核心定义 | 判定方法(原理) | 与前后知识关联 |
| 满二叉树 | 所有节点度 = 0 或 2,所有叶子节点在同一层 | 总节点数严格等于 2^h − 1 | 性质4的最好情况,完全二叉树的特例 |
| 完全二叉树 | 除最后一层外全部填满,最后一层节点靠左连续对齐 | 层序遍历中,遇空节点后不再出现非空节点 | 适配性质5编号规律、堆的底层结构 |
| 退化二叉树(斜树) | 所有节点仅保留左子树 或 仅保留右子树 | 树的高度等于总节点数,每层仅有1个节点 | 性质4的最坏情况,算法时间复杂度最差场景 |
| 二叉搜索树(BST) | 递归定义:左子树所有节点值 < 根节点值 < 右子树所有节点值 | 中序遍历结果为严格递增序列 | 中序遍历核心应用,平衡二叉树的基础 |
| 平衡二叉树(AVL) | 任意节点的左右子树高度差绝对值 ≤ 1 | 递归校验每个节点的子树高度差 | 优化BST单侧退化问题,保证查询效率稳定 |
| 哈夫曼树 | 带权路径长度(WPL)最小的二叉树,也称最优二叉树 | 贪心算法:每次选取两个权值最小的节点合并 | 应用于前缀编码、文件数据压缩 |
5.2 满二叉树 vs 完全二叉树(重点区分)⭐
二者是最高频混淆考点,核心区分逻辑极简:
-
包含关系 :满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树
-
结构差异:满二叉树是「完美填满、无任何空缺」;完全二叉树是「允许最后一层缺节点,但必须靠左补齐,无中间空缺、无右侧零散节点」
-
数值差异:满二叉树节点数固定为 2^h-1;完全二叉树节点数在 2^(h-1) ~ 2^h-1 之间浮动
5.3 线索二叉树
普通二叉树存在严重空间浪费:n个节点的二叉树,会产生n+1 个空指针域,空指针无任何实际作用,线索二叉树专为解决该问题而生。
核心思想:复用节点的空指针域,存放节点在对应遍历序列中的「前驱节点」和「后继节点」地址,无需递归即可直接遍历整棵树,提升遍历效率。
存储改造规则:每个节点新增两个标志位,区分指针用途:
-
ltag = 0:左指针指向左孩子;ltag = 1:左指针指向遍历前驱节点
-
rtag = 0:右指针指向右孩子;rtag = 1:右指针指向遍历后继节点
分类 :按遍历方式分为前序线索二叉树、中序线索二叉树、后序线索二叉树,其中中序线索二叉树应用最广。
5.4 哈夫曼树核心细节
哈夫曼树是贪心算法在树结构中的经典应用,也是唯一一类节点度只能为0或2的特殊二叉树,无度为1的节点,该特性为固定考点。
5.4.1 核心相关概念
-
节点权值:人为为每个叶子节点设定的数值,代表节点权重、概率、频次等属性
-
路径长度:节点到根节点的路径边数
-
带权路径长度(WPL):所有叶子节点的「权值 × 路径长度」之和,是衡量哈夫曼树优劣的唯一标准
5.4.2 构建步骤(标准贪心流程)
-
初始化:将所有带权叶子节点加入节点集合,作为初始独立节点
-
选取节点:从集合中选出两个权值最小的节点作为左右子节点
-
合并节点:新建一个父节点,权值为两个子节点权值之和,构建新的子树
-
更新集合:删除原两个子节点,将新父节点加入集合
-
循环迭代:重复上述步骤,直至集合中仅剩一个节点,即为哈夫曼树根节点
5.4.3 核心特性
-
哈夫曼树无度为1的节点 ,所有非叶子节点度均为2
-
权值越小的叶子节点,路径长度越长;权值越大的节点,路径长度越短,保证整体WPL最小
-
同一组权值可构建多棵不同结构的哈夫曼树,但所有合法树的WPL数值完全相同
-
n个叶子节点构建的哈夫曼树,总节点数为 2n-1
5.4.4 哈夫曼编码
哈夫曼编码是哈夫曼树的核心落地应用,属于无损压缩编码,广泛用于文件压缩、数据传输场景。
-
编码规则:左分支记为0,右分支记为1,从根节点到对应叶子节点的路径序列即为该节点的编码
-
核心特性:前缀编码,任意一个字符的编码都不是其他字符编码的前缀,解码无歧义
-
压缩原理:高频字符权值大、路径短、编码位数少;低频字符权值小、路径长、编码位数多,整体压缩数据体积
6. 二叉树的存储结构
二叉树主流存储方式分为顺序存储、链式存储、静态链表存储,核心掌握前两种的优劣对比与适配场景。
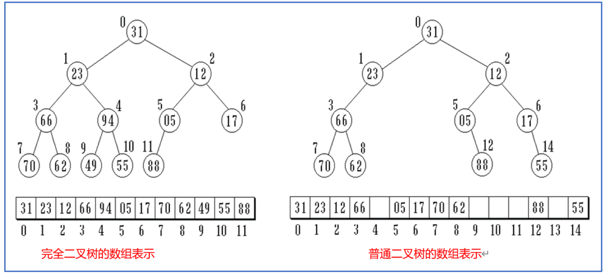
6.1 顺序存储(数组)
-
适用对象 :仅适配完全二叉树、满二叉树,空间利用率最高;普通二叉树会产生大量空间浪费
-
存储方式:基于层序编号规则,将节点按从上到下、从左到右的顺序存入数组对应下标位置
-
空节点处理:用特殊标记值(`#`、`null`、0等)占位,保证数组下标与理论节点编号一一对应
-
⭐ 核心优势 :通过性质5公式 2i / 2i+1 / ⌊i/2⌋ 实现O(1)极速定位父子节点,无需遍历
-
核心缺点:对稀疏、不规则的普通二叉树,需大量空间填充空节点,空间复杂度极高
6.2 链式存储
链式存储是普通二叉树的通用存储方案,分为二叉链表、三叉链表两种结构:
|------|-------------------------|--------------|----------------|
| 类型 | 节点结构 | 空间开销 | 适用场景 |
| 二叉链表 | 数据域 + 左孩子指针 + 右孩子指针 | 较小,无冗余空间 | 绝大多数通用二叉树场景 |
| 三叉链表 | 数据域 + 左指针 + 右指针 + 父节点指针 | 较大,额外占用父指针空间 | 需要频繁反向查找父节点的场景 |
cpp
typedef int ElemType;
//二叉链表
typedef struct BTNode
{
ElemType data;
struct BTNode* leftchild;
struct BTNode* rightchild;
};
//三叉链表
typedef struct BTNode
{
ElemType data;
struct BTNode* leftchild;
struct BTNode* rightchild;
struct BTNode* parent;
};6.3 静态链表存储
-
定义 :不使用动态内存指针,通过数组模拟链表,用数组下标替代内存地址实现节点关联
-
适用场景:C语言等低级编程语言、嵌入式开发、内存严格受限的设备环境,日常开发极少使用
6.4 两种主流存储方式对比 ⭐
|---------|-----------------|--------------------|
| 对比维度 | 顺序存储(数组) | 链式存储(二叉链表) |
| 空间利用率 | 完全二叉树极高,一般二叉树极低 | 稳定O(n),无冗余浪费 |
| 定位左右孩子 | O(1) 算术运算,极速定位 | 通过指针遍历访问 |
| 定位父节点 | O(1) 算术运算 | 需三叉链表或遍历查找,效率低 |
| 插入/删除节点 | 效率差,需移动大量数组元素 | 效率优,仅修改指针指向,O(1)操作 |
| 适用场景 | 完全二叉树、堆、优先队列 | 所有普通二叉树、动态变化的树结构 |
7. 二叉树的遍历
遍历是二叉树最核心、最高频的考点,所有二叉树算法、改造、应用均基于遍历实现,重点掌握非递归遍历、序列还原、多层级遍历三大核心内容。
7.1 前中后序遍历(非递归方式考的多)
7.1.1 三种遍历的访问顺序 ⭐
前、中、后序遍历均属于深度优先遍历(DFS) ,唯一区别是根节点的访问时机不同:
|-----------------|-----------|-------|
| 遍历方式 | 访问顺序 | 记忆口诀 |
| 前序遍历(Preorder) | 根 → 左 → 右 | "根左右" |
| 中序遍历(Inorder) | 左 → 根 → 右 | "左根右" |
| 后序遍历(Postorder) | 左 → 右 → 根 | "左右根" |
7.1.2 递归遍历实现(最简理解版)
递归遍历逻辑极简,完全贴合遍历定义,代码可读性高,适合理解原理、笔试简答,日常算法刷题基础必掌握。核心逻辑:递归遍历左子树 → 访问节点 → 递归遍历右子树(根据遍历顺序调整访问时机)。
cpp
// 前序遍历:根左右
void preOrder(TreeNode* root) {
if(root == NULL) return;
visit(root); // 访问根节点
preOrder(root->left); // 遍历左子树
preOrder(root->right); // 遍历右子树
}
// 中序遍历:左根右
void inOrder(TreeNode* root) {
if(root == NULL) return;
inOrder(root->left); // 遍历左子树
visit(root); // 访问根节点
inOrder(root->right); // 遍历右子树
}
// 后序遍历:左右根
void postOrder(TreeNode* root) {
if(root == NULL) return;
postOrder(root->left); // 遍历左子树
postOrder(root->right); // 遍历右子树
visit(root); // 访问根节点
}递归遍历优缺点:逻辑零门槛、代码简洁;缺点是树深度过大时会出现栈溢出,实际工程与面试中更考察非递归实现。
7.1.3 ⭐ 非递归遍历实现(面试/笔试高频)
非递归遍历基于栈结构模拟递归过程,规避栈溢出问题,是考试重点、工程常用写法,必须熟练掌握流程与代码逻辑。
1. 前序非递归遍历
核心思路:先访问根节点,持续遍历左子树入栈,左子树遍历完毕后弹出栈顶,遍历右子树,循环直至栈空。
cpp
void preOrderNoRec(TreeNode* root) {
if(root == NULL) return;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur != NULL || !st.empty()) {
// 遍历左子树,沿途访问节点、入栈
while(cur != NULL) {
visit(cur);
st.push(cur);
cur = cur->left;
}
// 左子树遍历完毕,回溯处理右子树
cur = st.top();
st.pop();
cur = cur->right;
}
}2. 中序非递归遍历(最高频)
核心思路:先入栈所有左子树节点,无左子树时弹出并访问节点,再遍历右子树,严格遵循左根右顺序。
cpp
void inOrderNoRec(TreeNode* root) {
if(root == NULL) return;
stack<TreeNode*> st;
TreeNode* cur = root;
while(cur != NULL || !st.empty()) {
// 所有左节点全部入栈
while(cur != NULL) {
st.push(cur);
cur = cur->left;
}
// 弹出栈顶,访问根节点
cur = st.top();
st.pop();
visit(cur);
// 遍历右子树
cur = cur->right;
}
}3. 后序非递归遍历(易错难点)
核心思路:后序遍历左右根顺序最特殊,需借助辅助标记记录右子树是否遍历完成,避免重复访问,常规双栈法、标记法两种主流写法,这里给出面试最常用的标记法。
cpp
// 定义带标记的节点结构体
struct Node {
TreeNode* p;
bool visited; // 标记是否已访问右子树
Node(TreeNode* p_, bool v_) : p(p_), visited(v_) {}
};
void postOrderNoRec(TreeNode* root) {
if(root == NULL) return;
stack<Node> st;
TreeNode* cur = root;
while(cur != NULL || !st.empty()) {
// 遍历左子树,全部入栈,标记未访问
while(cur != NULL) {
st.push(Node(cur, false));
cur = cur->left;
}
Node top = st.top();
st.pop();
// 右子树未遍历,重新入栈并遍历右子树
if(!top.visited) {
st.push(Node(top.p, true));
cur = top.p->right;
} else {
// 左右子树均遍历完成,访问当前节点
visit(top.p);
}
}
}7.1.4 三种遍历核心特性总结
-
前序遍历:优先输出根节点,可快速获取树的层级结构,用于树的复制、创建、打印目录结构
-
中序遍历 :二叉排序树遍历结果为严格递增序列,是BST查询、排序的核心依托,考点最多
-
后序遍历 :优先遍历子树再访问根,适合自底向上的操作,如树的删除、销毁、统计节点高度
7.2 层序遍历(广度优先遍历 BFS)⭐
层序遍历是二叉树独有的高频遍历方式,基于队列先进先出特性,按从上到下、从左到右的层级顺序访问节点,是完全二叉树判定、树的深度计算、逐层打印的核心算法。
7.2.1 基础层序遍历(一维输出)
核心逻辑:根节点入队 → 队首节点出队访问 → 左右子节点依次入队 → 循环至队列为空。
cpp
void levelOrder(TreeNode* root) {
if(root == NULL) return;
queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
TreeNode* cur = q.front();
q.pop();
visit(cur);
// 左子节点先入队,保证从左到右顺序
if(cur->left != NULL) q.push(cur->left);
if(cur->right != NULL) q.push(cur->right);
}
}7.2.2 分层层序遍历(二维输出,高频面试)
在基础遍历基础上,通过记录每层节点数量,实现逐层分组输出,可直接求解树的最大深度、每层节点平均值等经典题型。
cpp
// 分层遍历,结果按层级存储为二维数组
vector<vector<int>> levelOrderLayer(TreeNode* root) {
vector<vector<int>> res;
if(root == NULL) return res;
queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
int size = q.size(); // 记录当前层级节点总数
vector<int> layer;
for(int i = 0; i < size; i++) {
TreeNode* cur = q.front();
q.pop();
layer.push_back(cur->val);
if(cur->left) q.push(cur->left);
if(cur->right) q.push(cur->right);
}
res.push_back(layer);
}
return res;
}7.3 ⭐ 遍历序列还原二叉树(计算题)
已知两种遍历序列,唯一还原二叉树结构,是笔试选择、填空、画图题核心考点,存在固定还原规则,无需盲目推导。
7.3.1 可还原组合 & 不可还原组合
-
有效组合(唯一还原):前序+中序、后序+中序
-
无效组合(不唯一):前序+后序(无法区分左右子树边界,多解)
7.3.2 通用还原步骤(口诀:定根、分左右、递归)
-
定根:前序首元素/后序尾元素为当前子树根节点
-
分左右:在中序序列中找到根节点位置,左侧为左子树所有节点,右侧为右子树所有节点
-
截序列:根据中序左右子树节点数量,截取前序/后序对应的左右子树序列
-
递归迭代:对左右子树序列重复上述步骤,直至序列为空
7.3.3 经典示例
示例:前序序列【A B D E C F】、中序序列【D B E A F C】
-
前序首元素A为整树根节点;
-
中序中A左侧【D B E】为左子树,右侧【F C】为右子树;
-
递归拆分左右子树序列,最终还原完整二叉树结构。
8. 树、森林与二叉树的转换
普通树、森林结构复杂、分支不固定,运算繁琐,工程与考试中通常将其统一转换为二叉树处理,是树形运算的重要基础。
8.1 普通树 → 二叉树(左孩子右兄弟法)⭐
8.1.1 转换核心规则
-
左孩子:节点的第一个子节点,作为二叉树左孩子
-
右兄弟:节点相邻的右侧兄弟节点,作为二叉树右孩子
8.1.2 三步快速转换法
-
连线:所有亲兄弟节点之间横向连线
-
剪枝:每个节点仅保留与第一个子节点的连线,删除其余子节点连线
-
旋转:整体顺时针旋转45°,规整为二叉树标准层级结构
8.1.3 核心特性
-
转换后的二叉树无右子树(根节点无兄弟)
-
转换唯一可逆,可通过二叉树还原原普通树
8.2 森林 → 二叉树转换
8.2.1 转换规则
-
将森林中每一棵树单独转换为二叉树
-
所有二叉树根节点视为兄弟节点,依次横向连线
-
整体旋转规整,形成完整二叉树
8.2.2 核心特性
森林转换后的二叉树,根节点存在右子树(对应森林中其他树),可通过该特性区分单树转换与森林转换结果。
8.3 二叉树 → 树/森林(逆转换)
8.3.1 二叉树还原普通树
-
若节点有右孩子,全部视为兄弟节点,横向连线
-
保留所有父子连线,删除节点与右孩子的纵向连线
-
规整结构,还原为多分支普通树
8.3.2 二叉树还原森林
-
从根节点出发,沿右孩子链拆分,每一段独立子树为森林中的一棵树
-
将所有拆分后的二叉树分别还原为普通树,最终得到完整森林
8.4 转换通用结论
-
树转二叉树:左孩子、右兄弟,根无右子树
-
森林转二叉树:多树为兄弟,根存在右子树
-
转换前后,树的叶子节点数量不变(高频判断考点)
9. 二叉树经典题型与解题模板
汇总考研、面试、笔试高频题型,固化解题模板,直接套用即可快速解题,规避重复思考。
9.1 基础计算类题型
9.1.1 节点数、叶子数快速计算
核心公式:n0 = n2 + 1(万能恒成立)
常用推论:
-
满二叉树:n1=0,总节点数 n=2n0-1
-
完全二叉树:度为1的节点数 n1=0或1(最后一层最少节点场景为1)
-
哈夫曼树:n1=0,总节点数=2n0-1
9.1.2 高度/深度计算模板
递归模板(通用所有二叉树):
cpp
int getHeight(TreeNode* root) {
if(root == NULL) return 0;
int leftH = getHeight(root->left);
int rightH = getHeight(root->right);
return max(leftH, rightH) + 1;
}9.2 结构判定类题型
9.2.1 完全二叉树判定
层序遍历判定规则:遍历过程中遇到空节点后,后续所有节点必须全为空,否则不是完全二叉树。
9.2.2 平衡二叉树判定
核心规则:任意节点左右子树高度差绝对值≤1,且左右子树均为平衡二叉树。可基于上述高度递归代码改造实现。
9.3 遍历衍生题型
-
二叉树镜像:递归交换每个节点的左右子树
-
判断两棵树相同:节点值相等 + 左右子树完全相同
-
找最大/最小节点:BST中序遍历首尾节点,普通树遍历对比
10. 易错点&踩坑总结(避坑手册)
汇总90%初学者会混淆的概念、公式、判定规则,精准规避考试扣分点。
10.1 概念混淆避坑
-
坑1:混淆二叉树与度为2的有序树:二叉树允许单侧空子树、严格区分左右,度为2的有序树无空结构定义
-
坑2:满二叉树≠完全二叉树:满二叉树是完全二叉树特例,完全二叉树不满足逐层填满
-
坑3:深度与高度混淆:本文统一约定根深度为0、叶子高度为0,数值等价,其他教材定义可能不同,以本文考点为准
-
坑4:哈夫曼树存在度为1节点:错误!哈夫曼树无度为1节点,仅0、2度节点
10.2 公式计算避坑
-
坑5:完全二叉树节点公式误用:高度h的完全二叉树节点数范围 2^(h-1) ≤ n ≤ 2^h-1,不可颠倒上下限
-
坑6:编号公式下标混乱 :性质5编号规则从1开始,数组从0开始存储需重新推导公式
-
坑7:n0=n2+1适用范围:任意二叉树恒成立,包括满、完全、斜树、哈夫曼树,无特例
10.3 遍历&转换避坑
-
坑8:前序+后序可还原二叉树:错误!无中序无法区分左右子树,多解无唯一结构
-
坑9:树转二叉树丢失叶子节点:转换前后叶子节点数量不变,是高频判断题考点
-
坑10:层序遍历无序入队:必须先左后右入队,否则破坏从左到右的层级顺序
11. 全文核心考点速查表(复盘专用)
极简汇总所有必考公式、规则、结论,适合考前快速复盘、面试突击记忆。
11.1 核心公式汇总
-
二叉树通用公式:n0 = n2 + 1
-
第i层最大节点数:2^(i-1)
-
深度k最大总节点数:2^k - 1
-
完全二叉树高度:h = ⌊log₂n⌋ + 1
-
完全二叉树父子编号:左2i、右2i+1、父⌊i/2⌋
-
n个叶子哈夫曼树总节点数:2n-1
11.2 必考结论速记
-
二叉树是独立结构,不是普通树的特例
-
满二叉树一定是完全二叉树,反之不成立
-
BST中序遍历为递增序列
-
哈夫曼编码是无前缀编码,用于无损压缩
-
树转二叉树:左孩子右兄弟,根无右子树
-
递归遍历简洁,非递归遍历无栈溢出,面试优先考非递归
尾语
读到这里,你已经完整啃完了数据结构树与二叉树的全部核心基础内容 。从最基础的树定义、名词概念,到二叉树性质、特殊二叉树、存储方式、遍历算法,再到树与森林的转换、高频题型模板、易错点避坑、考点速查,本文完成了从理论定义到实战解题的完整闭环。
二叉树是后续高级数据结构与算法的基石,学好它,再学习平衡树、堆排序、树形DP、数据库索引结构都会事半功倍。建议大家收藏本文,日常学习用来梳理体系,考前复习用来快速复盘,做题卡住时随时查阅。