一、 SELECT
SELECT 语句用于从数据库中选取数据。
结果被存储在一个结果表中,称为结果集。
SELECT column1, column2, ...
FROM table_name;与
SELECT * FROM table_name;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- *****: 通配符,表示选择表中的所有列。
二、SELECT DISTINCT 去重
SELECT DISTINCT 语句用于返回唯一不同的值。
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。
DISTINCT 关键词用于返回唯一不同的值。
SELECT DISTINCT column1, column2, ...
FROM table_name;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
三、WHERE
WHERE 子句用于提取那些满足指定条件的记录。
SELECT column1, column2, ...
FROM table_name
WHERE condition;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
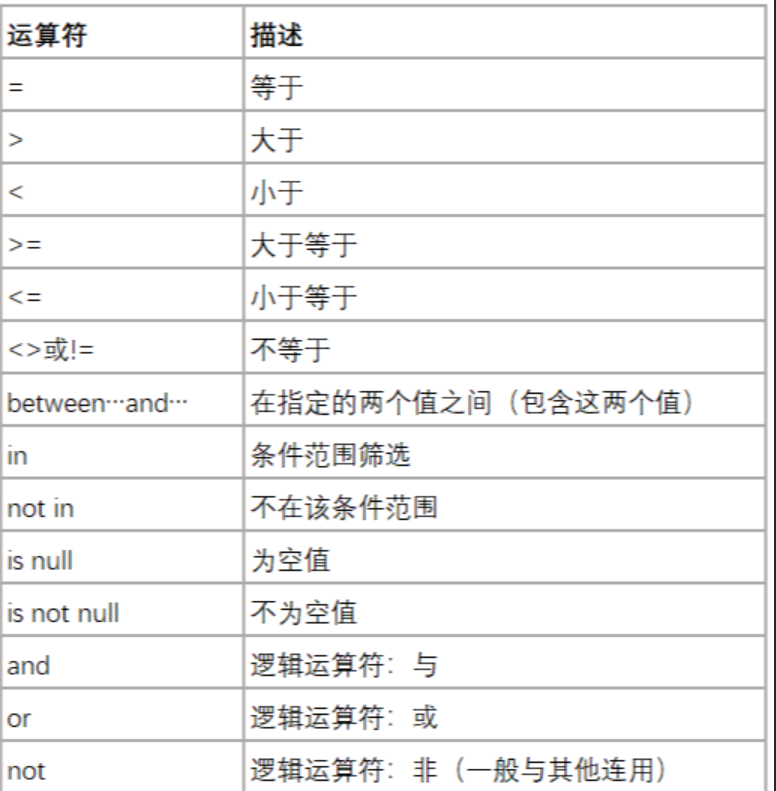
AND & OR 运算符
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
and 优先级高于 or
IN 操作符
IN 操作符允许您在 WHERE 子句中规定多个值。
SELECT column1, column2, ...
FROM table_name
WHERE column IN (value1, value2, ...);参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1, value2, ...:要查询的值,可以为多个值。
BETWEEN 在.....之间
BETWEEN 操作符选取介于两个值之间的数据范围内的值(包括两边),这些值可以是数值、文本或者日期。
SELECT column1, column2, ...
FROM table_name
WHERE column BETWEEN value1 AND value2;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1:范围的起始值。
- value2:范围的结束值。
between 还可以操作字符和日期
LIKE 模糊匹配
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
LIKE 操作符是 SQL 中用于在 WHERE 子句中进行模糊查询的关键字,它允许我们根据模式匹配来选择数据,通常与 % 和 _ 通配符一起使用。
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要搜索的字段名称。
- pattern:搜索模式。
通配符
%:匹配任意字符(包括零个字符)。_:匹配单个字符。
四、ORDER BY 排序
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;- column1, column2, ...:要排序的字段名称,可以为多个字段。
- ASC:表示按升序排序。
- DESC:表示按降序排序。
order by 与 in 的结合使用 把in里面的排在最后
select winner, subject
from nobel
where yr = 1984
order by subject in ('chemistry','physics'), subject, winner
这里表示把('chemistry','physics')放在最后再按subject, winner排序
subject in()表示把()里的视为1,其余的视为0;1排在0之后,即把()里的排在最后
五、LIMIT 从第几行开始取,取几行


六、GROUP BY 与 聚合函数
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
聚合函数会忽略空值
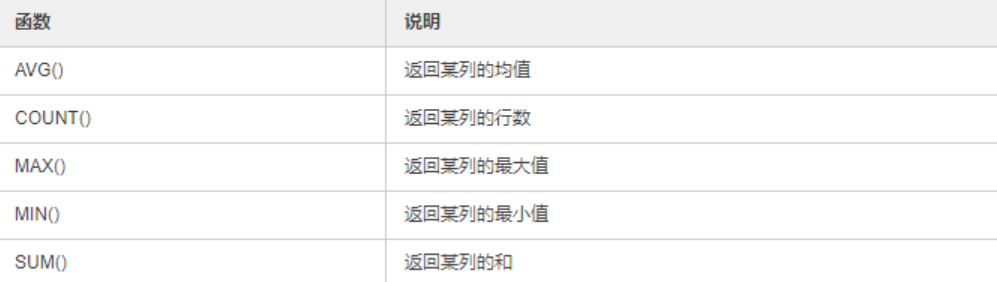
AVG() 函数
AVG() 函数返回数值列的平均值。
SELECT AVG(column_name) FROM table_name
SUM() 函数
SUM() 函数返回数值列的总数。
SELECT SUM(column_name) FROM table_name;
SQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SQL COUNT(column_name)
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name;
SQL COUNT(*) 语法 查询不为空的行数
COUNT(*) 函数返回表中的记录数(查询有多少行):
SELECT COUNT(*) FROM table_name;
SQL COUNT(DISTINCT column_name) 查询不重复的行数
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;
-- 查询所有记录的条数
select count(*) from access_log;
-- 查询websites 表中 alexa列中不为空的记录的条数
select count(alexa) from websites;
-- 查询websites表中 country列中不重复的记录条数
select count(distinct country) from websites;MAX() 函数
MAX() 函数返回指定列的最大值。
SELECT MAX(column_name) FROM table_name;
MIN() 函数
MIN() 函数返回指定列的最小值。
SELECT MIN(column_name) FROM table_name;
七、HAVING 筛选(对于聚合后的数据)
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。

SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING condition;
参数说明:
column1:要检索的列。aggregate_function(column2):一个聚合函数,例如SUM、COUNT、AVG等,应用于column2的值。table_name:要从中检索数据的表。GROUP BY column1:根据column1列的值对数据进行分组。HAVING condition:一个条件,用于筛选分组的结果。只有满足条件的分组会包含在结果集中。
八、常见函数
ROUND() 函数 四舍五入
ROUND() 函数用于把数值字段舍入为指定的小数位数。
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;
| 参数 | 描述 |
|---|---|
| column_name | 必需。要舍入的字段。 |
| decimals | 可选。规定要返回的小数位数。 |

九、基础用法总结

十、窗口函数
窗口函数是SQL中的一项高级特性,用于在不改变查询结果集行数的情况下,对每一行执行聚合计算或者其他复杂的计算,也就是说窗口函数可以跨行计算,可以扫描所有的行,并把结果填到每一行中。这些函数通常与OVER()子句一起使用,可以定义窗口或分区,并在上面执行计算,使用窗口函数,可以使许多难以处理的棘手问题变得较为容易。
窗口函数的特点包括:
输入多行(一个窗口),返回一个值:窗口函数为每行数据进行一次计算,但不会改变原始查询结果集的行数
计算方式灵活:可以使用partition by字句将数据分区,并使用order by子句来进行排序等一些复杂运算
与聚合函数结合使用:可以与聚合函数结合使用,在不分组的情况下计算如总和、平均值、最小值、最大值等聚合值。
语法结构解析
**<窗口函数> OVER (
PARTITION BY \<分组列\>
ORDER BY \<排序列\>
ROWS 或 RANGE \<窗口框架定义\>
)**
其中:
PARTITION BY 子句用于将数据分成不同的分区,窗口函数将在每个分区内执行。可以理解为group by
ORDER BY 子句定义了数据的排序方式,决定窗口函数的计算顺序。
ROWS BETWEEN 子句指定了窗口的范围,可以是行数、区间等。
常用的窗口函数SQL示例

聚合函数:
SUM()、AVG()、COUNT()、MAX()、MIN()等
排序函数:
ROW_NUMBER():为窗口内的每一行分配一个唯一的序号,序号连续且不重复;
RANK():排名函数,允许有并列的名次,名次后面会出现空位。
ENSE_RANK():排名函数,允许有并列的名次,名次后面不会空出位置,即序号连续。

分组窗口函数:
NTILE():将窗口内的行分为指定数量的组,每组的行数尽可能相等。
分布窗口函数:
PERCENT_RANK():计算每一行的相对排名,返回一个介于0到1之间的值,表示当前行在分区中的排名百分比。
CUME_DIST():计算小于或等于当前行的行数占窗口总行数的比例。
偏移分析函数: 同比,环比

LAG():访问当前行之前的第n行数据。向上取n行
LEAD():访问当前行之后的第n行数据。
FIRST_VALUE():获取窗口内第一行的值。
LAST_VALUE():获取窗口内最后一行的值。
NTH_VALUE():获取窗口内第n行的值,如果存在多行则返回第一个。
十一、表连接
SQL join 用于把来自两个或多个表的行结合起来。
| 类型 | 描述 |
|---|---|
| INNER JOIN | 返回两个表中满足连接条件的记录(交集)。 |
| LEFT JOIN | 返回左表中的所有记录,即使右表中没有匹配的记录(保留左表)。 |
| RIGHT JOIN | 返回右表中的所有记录,即使左表中没有匹配的记录(保留右表)。 |
| FULL OUTER JOIN | 返回两个表的并集,包含匹配和不匹配的记录。 |
| CROSS JOIN | 返回两个表的笛卡尔积,每条左表记录与每条右表记录进行组合。 |
| SELF JOIN | 将一个表与自身连接。 |
| NATURAL JOIN | 基于同名字段自动匹配连接的表。 |
示例
表1:Customers
| CustomerID | Name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
表2:Orders
| OrderID | CustomerID | Product |
|---|---|---|
| 101 | 1 | Laptop |
| 102 | 2 | Phone |
| 103 | 4 | Tablet |
| JOIN 类型 | 结果 |
|---|---|
| INNER JOIN | 返回两个表中匹配的记录。在给定的例子中,只有 CustomerID 为 1 和 2 的记录在两个表中都有匹配,所以只会返回这些记录。 |
| LEFT JOIN | 返回左表(Customers)中的所有记录,即使右表(Orders)中没有匹配的记录。对于左表中没有匹配的右表记录,结果中的右表字段将为 NULL。在例子中,CustomerID 为 3 的记录在右表中没有匹配,所以其对应的 Product 将为 NULL。 |
| RIGHT JOIN | 返回右表(Orders)中的所有记录,即使左表(Customers)中没有匹配的记录。对于右表中没有匹配的左表记录,结果中的左表字段将为 NULL。在例子中,OrderID 为 103 的记录在左表中没有匹配,所以其对应的 Name 将为 NULL。 |
| FULL OUTER JOIN | 返回两个表中的所有记录,无论它们是否匹配。如果某个表中没有匹配的记录,那么该表的字段将为 NULL。在例子中,CustomerID 为 3 和 OrderID 为 103 的记录将分别在对方的表中显示为 NULL。 |
| CROSS JOIN | 返回两个表的笛卡尔积,即左表中的每一行与右表中的每一行组合。在例子中,每个顾客都将与每个订单组合,产生多个结果。 |
| SELF JOIN | 表与其自身进行连接。这通常用于查询表中相互关联的记录,比如员工与其经理之间的关系。 |
JOIN
两个表中满足条件的就连接,不满足的直接剔除
JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;参数说明:
- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table1:要连接的第一个表。
- table2:要连接的第二个表。
- condition:连接条件,用于指定连接方式。
LEFT JOIN
LEFT JOIN 是 SQL 中的一个连接关键字,用于从多个表中提取数据。
LEFT JOIN 与 INNER JOIN 不同之处在于,LEFT JOIN 会返回左表中的所有记录,即使在右表中没有匹配的记录。
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;或:
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;**注释:**在某些数据库中,LEFT JOIN 称为 LEFT OUTER JOIN。
- table1 :左表(主表),
LEFT JOIN会保留该表的所有记录。 - table2 :右表(从表),如果没有匹配的数据,用
NULL填充对应的列。 - ON table1.column_name=table2.column_name:指定连接条件,通常是两个表的共同字段。
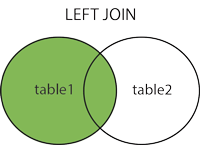
- 返回左表中的所有记录,即使右表没有匹配的数据。
- 如果右表没有匹配的记录,结果中该行右表字段为
NULL。
RIGHT JOIN
RIGHT JOIN 是 SQL 中的一个连接关键字,用于从多个表中提取数据。
与 LEFT JOIN 类似,但其行为相反:RIGHT JOIN 会返回右表中的所有记录,即使左表中没有匹配的记录。
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;或:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;**注释:**在某些数据库中,RIGHT JOIN 称为 RIGHT OUTER JOIN。
- table1:左表。
- table2 :右表,
RIGHT JOIN会保留该表的所有记录。 - ON table1.column_name=table2.column_name:指定连接条件,通常是两个表的共同字段。
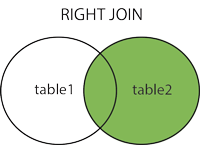
- 保留右表的所有记录:即使左表中没有匹配的记录,也会在结果中包含右表的所有记录。
- 左表未匹配时填充
NULL:如果左表中没有对应的记录,用NULL填充左表的列。
十二、子查询
- 子查询本身就是一段完整的查询语句,然后用括号英文括号
()包裹嵌套在主查询语句中,子查询可以多层嵌套 - 最常用的子查询运用在
from和where子句中
子查询或称为内部查询、嵌套查询,指的是在 PostgreSQL 查询中的 WHERE 子句中嵌入查询语句。
一个 SELECT 语句的查询结果能够作为另一个语句的输入值。
子查询可以与 SELECT、INSERT、UPDATE 和 DELETE 语句一起使用,并可使用运算符如 =、<、>、>=、<=、IN、BETWEEN 等。
以下是子查询必须遵循的几个规则:
-
子查询必须用括号括起来。
-
子查询在 SELECT 子句中只能有一个列,除非在主查询中有多列,与子查询的所选列进行比较。
-
ORDER BY 不能用在子查询中,虽然主查询可以使用 ORDER BY。可以在子查询中使用 GROUP BY,功能与 ORDER BY 相同。
-
子查询返回多于一行,只能与多值运算符一起使用,如 IN 运算符。
-
BETWEEN 运算符不能与子查询一起使用,但是,BETWEEN 可在子查询内使用。
子查询通常与 SELECT 语句一起使用。基本语法如下:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
十三、云端数据库连接到Navicat
实在写不动,步骤较多自己摸索