开源技术|数据同步
本期我们将深度解构数新智能「开源技术」系列之------开源离线数据同步工具 DataX,其他相关文章可移步专栏合集查看。
作为大数据体系建设的基础工具,DataX 以 Framework+Plugin 核心设计破解异构数据源同步的 N*N 链路难题,是企业数据治理的重要抓手。本文将从架构设计、执行流程、插件开发等维度拆解其技术内核,提炼实操要点,为技术从业者提供可落地的参考思路。
大数据时代,企业数据分散在 MySQL、HDFS、HBase 等异构数据源中,N 种数据源两两同步需开发 N*(N-1)/2 条链路,复杂度呈指数级增长。离线数据同步工具 DataX,凭借抽象化设计将复杂度降至 N+N,成为异构数据同步的经典解决方案,本文将深度解构其技术内核。
1核心设计思想
DataX 架构的灵魂在于"中间抽象"与"解耦"。将复杂的 N * N 个对应关系简化为 N*I(Reader 插件)和 N*1(Writer 插件)的模型。
● 星型模型:在没有中间件的情况下,N 种数据源两两同步需要 N * (N-1) / 2条链路。DataX 引入了中间抽象层:
● Reader Plugin(读取插件):负责将源端数据读取并转换为 DataX 内部标准格式(Record)。
● Writer Plugin(写入插件):负责将内部 Record 转换为目标端数据格式并写入。
● Framework(中转站):处理缓冲、流控、并发与转换。
2系统架构组成
DataX 的系统架构由以下核心组件构成,各组件分工明确、协同工作,共同支撑起从任务触发到执行完成的全生命周期管理,各组件的角色与核心职责如下表所示:

这套组件形成了一套完整的任务执行体系,从配置解析到插件加载,从任务调度到数据传输,从状态监控到资源清理,每个环节都有专属组件负责,确保了整个同步流程的规范化和高效性。
3数据处理流水线
DataX 采用类似 Unix 管道的流水线(Pipeline) 架构,将数据处理过程拆解为三个串行且解耦的步骤,实现了异构系统间数据的高效、无损流转,整个流程环环相扣,形成了一条标准化的数据处理链路:
DataX 采用类似 Unix 管道的架构,实现数据在异构系统间的无损流转。
1.提取转换 :Reader Plugin 提取源数据,封装为统一的 Record 格式。
2.缓冲流控 :RecordChannel 充当漏斗,协调 Reader 和 Writer 的速度差异,防止下游因速度过快而崩溃。
3.最终落地:Writer Plugin 从通道消费 Record,执行目标系统的写入逻辑。

datax数据处理流水线
4作业执行生命周期
一个 DataX 任务(Job)从启动到结束遵循严密的逻辑链条:
Step 1. 初始化 (Init) :Engine 创建 JobContainer,加载读写插件。
Step 2. 准备 (Prepare):插件检查权限、表结构是否存在。
Step 3. 拆分 (Split) :Job 拆分为多个 Task;例如 1 亿条数据拆分为 10个 Task 并行处理。
Step 4. 调度 (Schedule) :TaskGroup 被分配到物理资源运行。
Step 5. 执行 (Post/Cleanup):执行后置脚本,释放链接及内存资源。
5源码模块地图
DataX 的源码架构采用模块化设计,各模块分工明确,形成了一套层次清晰的技术底座,四大核心模块的作用及关键包 / 类如下表所示,模块之间通过标准化的接口交互,实现了核心逻辑与业务逻辑的解耦:
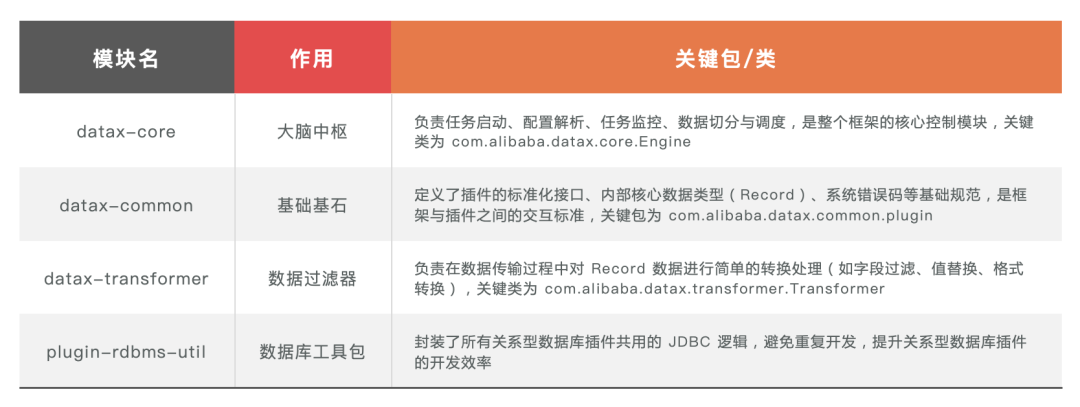
模块化的源码设计,使得 DataX 的核心框架与业务插件完全解耦,开发者在开发新插件时,仅需遵循 datax-common 定义的标准接口,无需关注框架内部的实现细节,极大降低了开发门槛。
6插件开发
DataX 的强大之处,不仅在于其成熟的核心框架,更在于其极高的可扩展性 ------ 通过开发自定义插件,可快速适配新的异构数据源。开发 DataX 新插件(Reader/Writer)仅需四大核心步骤,遵循标准化的开发流程,即可实现插件的快速开发与部署:
● 接口实现:实现 Reader.Job / Reader.Task 或 Writer.Job / Writer.Task。
● 内部转换:在插件中完成原生数据类型与 com.alibaba.datax.common.element 下各种 Column 类型的互转。
● 配置定义:编写插件对应的 plugin.json 描述文件。
● 打包部署:放入 DataX 的 plugin 目录下即可通过命令行调用。
插件开发说明:
DataX/dataxPluginDev.md at master · alibaba/DataX · GitHubgithub.com/alibaba/DataX/blob/master/dataxPluginDev.md
示例代码参考:
PGCopyWriter 代码实现示例github.com/liuyuanyuan/DataX-Pro/commit/c099640f4dd3a583e0a517fe8a6c1ac1ff089156
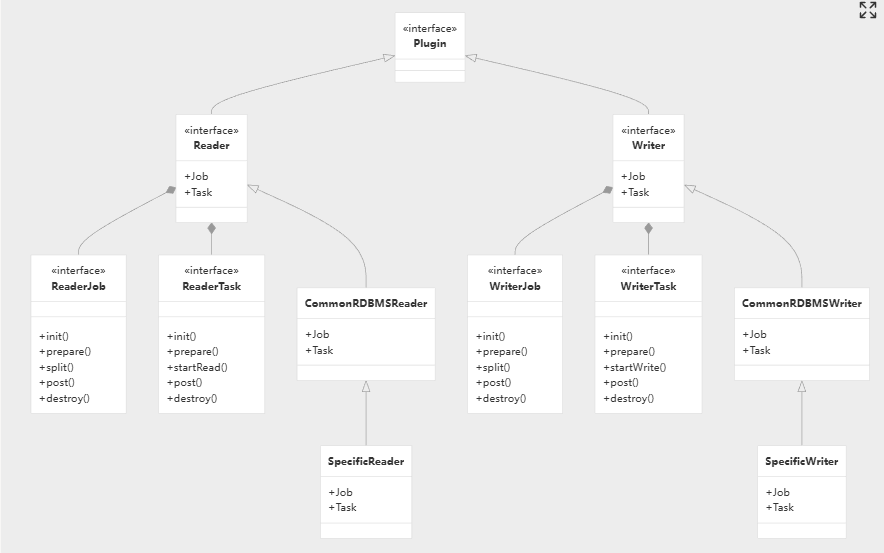
datax 的 plugin 架构
7常用运行参数
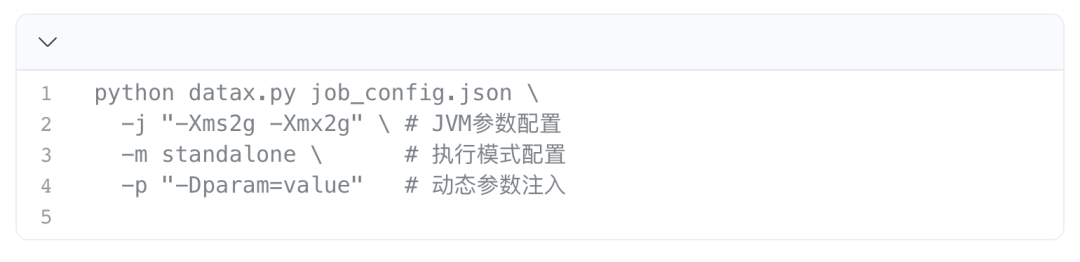
在实际使用 DataX 时,可通过命令行参数对任务执行进行精细化配置,平衡任务的吞吐率、内存占用和执行稳定性,核心常用运行参数如下,基于 python 脚本的调用格式为:
在实际应用中,无论是常规的关系型数据库、大数据存储的同步,还是个性化的数据源适配,DataX 都能通过灵活的配置和自定义插件,满足企业的多样化数据同步需求,成为大数据架构中数据流转的核心基础设施。