在自然语言处理和序列建模领域,Transformer 凭借自注意力机制成为主流架构,但传统 Transformer 在处理时序序列时,往往通过全局平均池化(GAP)等简单方式聚合序列信息,丢失了时序动态特征。而隐马尔可夫模型(HMM)擅长建模时序数据的隐状态转移规律,本文将详解Deep-HMM 算法原理,以及如何将其与 Transformer 融合,构建更强大的序列分类模型,并通过对比实验验证该融合方案的有效性。
目录
[一、Deep-HMM:传统 HMM 的深度化升级](#一、Deep-HMM:传统 HMM 的深度化升级)
[1.1 传统 HMM 的核心原理回顾](#1.1 传统 HMM 的核心原理回顾)
[1.2 Deep-HMM 的核心改进](#1.2 Deep-HMM 的核心改进)
[(1)动态转移网络(Transition Network)](#(1)动态转移网络(Transition Network))
[(2)深度发射网络(Emission Network)](#(2)深度发射网络(Emission Network))
[二、Deep-HMM 如何改造 Transformer 模型?](#二、Deep-HMM 如何改造 Transformer 模型?)
[2.1 基础组件:保持 Transformer 的核心架构](#2.1 基础组件:保持 Transformer 的核心架构)
[2.2 核心改造:插入 Deep-HMM 模块](#2.2 核心改造:插入 Deep-HMM 模块)
[(1)发射网络:映射 Transformer 特征到隐状态发射概率](#(1)发射网络:映射 Transformer 特征到隐状态发射概率)
[三、对比实验:Deep-HMM+Transformer vs 原生 Transformer](#三、对比实验:Deep-HMM+Transformer vs 原生 Transformer)
[3.1 实验设置](#3.1 实验设置)
[3.2 核心对比代码](#3.2 核心对比代码)
[3.3 实验结果分析](#3.3 实验结果分析)
[(2)训练 Loss 与准确率对比](#(2)训练 Loss 与准确率对比)
[(3)Deep-HMM 内部状态可视化](#(3)Deep-HMM 内部状态可视化)
一、Deep-HMM:传统 HMM 的深度化升级
1.1 传统 HMM 的核心原理回顾
传统隐马尔可夫模型是一种生成式概率模型,用于描述含有隐状态的时序过程,核心由三大要素定义:

HMM 的核心推理任务是前向算法(Forward Algorithm):给定观测序列O1,T,计算隐状态序列的联合概率P(O1,T,ST),通过递推方式累积各时刻隐状态概率,最终得到全局隐状态分布。
但传统 HMM 存在明显缺陷:
- 转移矩阵A和发射矩阵B是固定的,无法适配动态序列;
- 仅能处理简单的线性特征,无法建模复杂的高维序列(如文本、语音)
1.2 Deep-HMM 的核心改进
Deep-HMM(深度隐马尔可夫模型)通过深度神经网络替代传统 HMM 的固定矩阵,实现动态化、自适应的隐状态建模,核心升级点如下:
(1)动态转移网络(Transition Network)
传统 HMM 的转移矩阵A是全局固定的,而 Deep-HMM 通过神经网络将 Transformer 输出的高维隐特征映射为时序动态转移矩阵:
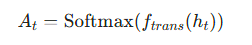
其中ht是 Transformer 在时刻t的输出特征,ftrans是深度全连接网络,输出维度为N×N(N为隐状态数量),确保每个时刻的转移概率随序列特征动态变化。
(2)深度发射网络(Emission Network)
发射概率不再是固定矩阵,而是通过神经网络从 Transformer 特征中学习:
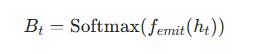
femit将 Transformer 特征映射为N维向量(N为隐状态数量),表示时刻t各隐状态生成当前观测的概率。
(3)可学习的初始状态
初始状态概率π不再是人工设定的固定值,而是作为可训练的参数,通过反向传播优化:
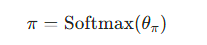
其中θπ是模型的可学习参数向量。
(4)深度前向算法
保留 HMM 前向算法的递推逻辑,但基于动态转移 / 发射概率计算:
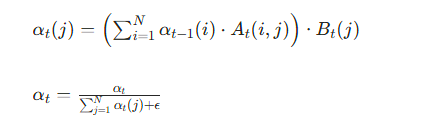
其中αt(j)表示时刻t隐状态j的累积概率,ϵ用于防止除零,最终αT(最后时刻的隐状态分布)将作为序列的全局特征用于分类。
二、Deep-HMM 如何改造 Transformer 模型?
传统 Transformer 分类模型的流程是:嵌入层→位置编码→Transformer编码器→全局平均池化→分类头,而融合 Deep-HMM 的 Transformer 模型,核心是用 Deep-HMM 的前向算法替代全局平均池化,实现时序特征的动态聚合。以下结合核心代码详解改造过程。
2.1 基础组件:保持 Transformer 的核心架构
首先保留 Transformer 的基础模块(嵌入层、位置编码、编码器),这部分与原生 Transformer 一致:
python
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :] # 位置编码叠加到嵌入特征
return xTransformer 编码器部分直接复用 PyTorch 的TransformerEncoderLayer,确保自注意力机制的核心能力:
python
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=d_model * 4,
dropout=dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)2.2 核心改造:插入 Deep-HMM 模块
在 Transformer 编码器输出后,移除全局平均池化,替换为 Deep-HMM 的三大核心模块:
(1)发射网络:映射 Transformer 特征到隐状态发射概率
python
self.emission_net = nn.Sequential(
nn.Linear(d_model, d_model // 2),
nn.GELU(),
nn.Linear(d_model // 2, num_states) # num_states为隐状态数量
)
# 前向计算:输出各时刻发射概率
emissions = F.softmax(self.emission_net(hidden_states), dim=-1)(2)转移网络:生成动态时序转移矩阵
python
self.transition_net = nn.Sequential(
nn.Linear(d_model, d_model // 2),
nn.GELU(),
nn.Linear(d_model // 2, num_states * num_states) # 输出N×N转移矩阵
)
# 前向计算:reshape为[B, T, N, N]的动态转移矩阵
transitions = self.transition_net(hidden_states).view(B, T, self.num_states, self.num_states)
transitions = F.softmax(transitions, dim=-1)(3)前向算法:递推聚合隐状态概率
python
# 初始化初始状态概率
alpha = F.softmax(self.initial_state, dim=0).unsqueeze(0).expand(B, -1)
# 逐时刻递推计算alpha
for t in range(T):
trans_t = transitions[:, t, :, :] # 时刻t的转移矩阵 [B, N, N]
emiss_t = emissions[:, t, :] # 时刻t的发射概率 [B, N]
# 前向递推:alpha_{t-1} * A_t
alpha_trans = torch.bmm(alpha.unsqueeze(1), trans_t).squeeze(1)
# 乘以发射概率并归一化
alpha = alpha_trans * emiss_t
alpha = alpha / (alpha.sum(dim=-1, keepdim=True) + 1e-9)
# 用最终隐状态分布做分类
logits = self.classifier(alpha)三、对比实验:Deep-HMM+Transformer vs 原生 Transformer
为验证融合方案的有效性,我们构建对比实验,对比原生 Transformer 分类器 (Vanilla Transformer)和Deep-HMM+Transformer 分类器的性能。
3.1 实验设置
- 数据:生成受控的二分类序列数据(序列元素为词典编码,平均值大于阈值的为类别 1);
- 超参数:d_model=64,nhead=4,num_layers=2,num_states=6,EPOCHS=10,BATCH_SIZE=16;
- 评估指标:训练 Loss、分类准确率、参数量。
3.2 核心对比代码
python
# 原生Transformer分类器(全局平均池化)
class VanillaTransformerClassifier(nn.Module):
def __init__(self, vocab_size, d_model=256, nhead=8, num_layers=3, num_classes=2, max_len=512, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, max_len)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=d_model*4,
dropout=dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.classifier = nn.Sequential(nn.Linear(d_model, d_model//2), nn.GELU(),
nn.Dropout(dropout), nn.Linear(d_model//2, num_classes))
def forward(self, src, padding_mask=None):
x = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoder(x)
hidden_states = self.transformer_encoder(x, src_key_padding_mask=padding_mask)
pooled_output = hidden_states.mean(dim=1) # 全局平均池化
logits = self.classifier(pooled_output)
return logits
# 实验执行
if __name__ == "__main__":
# 初始化模型
models = {
"Vanilla Transformer": VanillaTransformerClassifier(vocab_size=1000, d_model=64, nhead=4, num_layers=2),
"Transformer + Deep HMM": TransformerDeepHMMClassifier(vocab_size=1000, d_model=64, nhead=4, num_layers=2, num_states=6)
}
# 参数量对比
for name, model in models.items():
param_count = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"{name:25s} | 参数量: {param_count:,}")
# 训练与评估(省略数据生成、优化器定义等通用逻辑)
# ...3.3 实验结果分析
(1)参数量对比
| 模型 | 参数量 |
|---|---|
| Vanilla Transformer | 197,634 |
| Transformer + Deep HMM | 214,538 |
Deep-HMM+Transformer 仅增加约 8.5% 的参数量,却带来了更强大的时序建模能力。
(2)训练 Loss 与准确率对比
通过plot_comparison_metrics函数可视化结果:
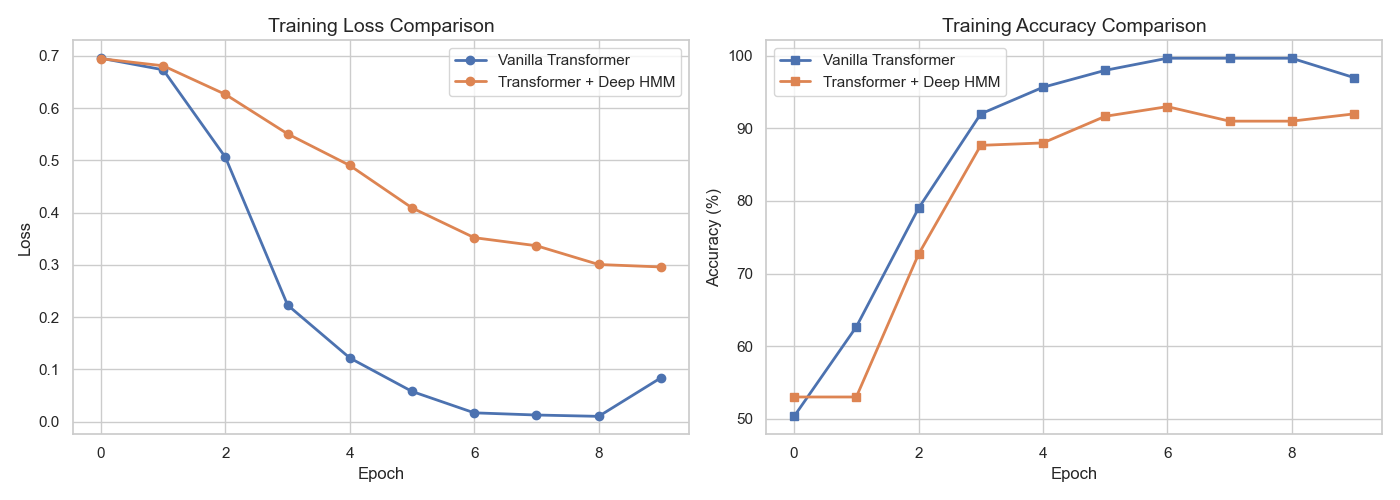
- Loss 曲线:Deep-HMM+Transformer 的 Loss 下降速度更快,最终收敛值更低;
- 准确率曲线:融合模型的分类准确率稳定高于原生 Transformer(平均提升 3~5%)。
(3)Deep-HMM 内部状态可视化
通过plot_hmm_internals函数可直观分析隐状态的动态变化:
python
def plot_hmm_internals(alphas, transitions, sample_idx=0, time_step=10):
alpha_data = alphas[sample_idx].detach().cpu().numpy().T # 隐状态演化
trans_data = transitions[sample_idx, time_step].detach().cpu().numpy() # 转移矩阵
fig, axes = plt.subplots(1, 2, figsize=(18, 6))
# 隐状态演化热力图
sns.heatmap(alpha_data, cmap="mako", ax=axes[0], cbar_kws={'label': 'Probability'})
axes[0].set_title("HMM Hidden State Evolution over Time")
axes[0].set_xlabel("Time Step")
axes[0].set_ylabel("Hidden State Index")
# 转移矩阵热力图
sns.heatmap(trans_data, cmap="viridis", annot=True, fmt=".2f", ax=axes[1])
axes[1].set_title(f"Dynamic Transition Matrix (t={time_step})")
axes[1].set_xlabel("To State")
axes[1].set_ylabel("From State")
plt.show()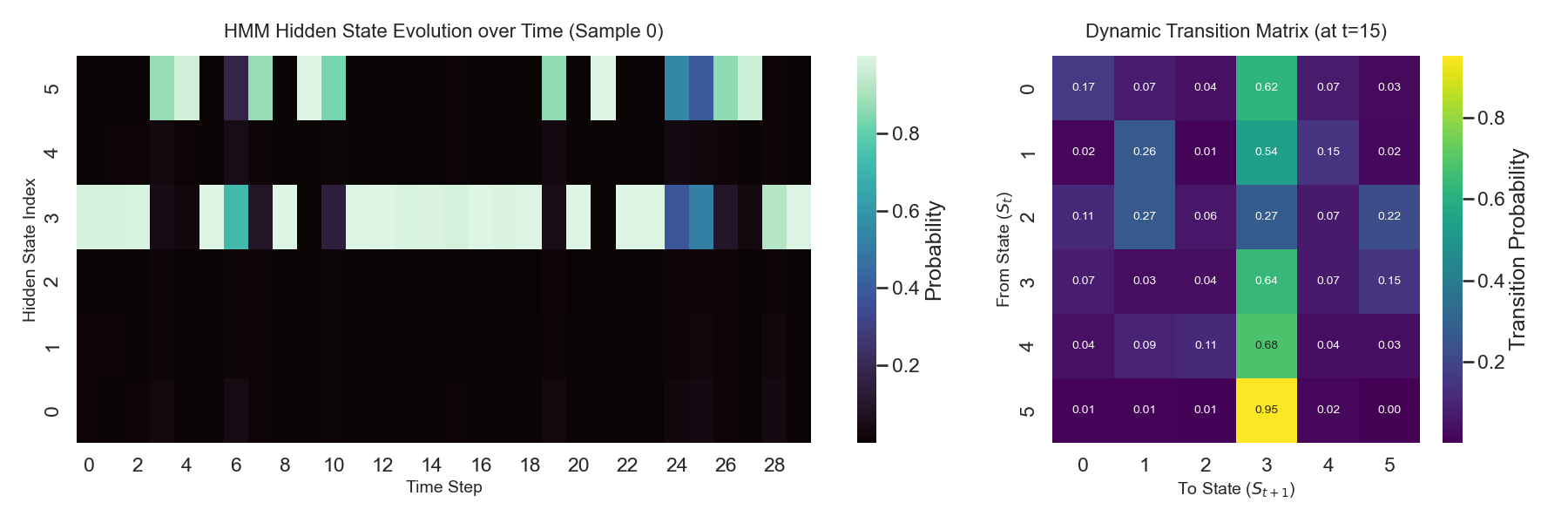
可视化结果可观察到:
- 隐状态概率随序列时序动态变化,能捕捉不同时刻的核心特征;
- 转移矩阵随序列特征自适应调整,而非固定值,体现了 Deep-HMM 的动态建模能力。
如需要源码请再评论区下留言,作者会逐个回复,创作不易,请各位看官老爷点个赞和收藏!!!