迁移学习:让 AI 站在巨人的肩膀上------从 CNN 到 ResNet 微调全攻略
📌 前言:一个让人头疼的现实问题
你有没有遇到过这种情况:
- 手头只有几百张图片,却想训练一个图像分类模型
- 从零开始训练动辄耗费几天 GPU 时间,成本高不可攀
- 数据量太少,模型要么欠拟合、要么严重过拟合
**迁移学习(Transfer Learning)**就是解决上述痛点的"银弹"。本文将从 CNN 基础出发,深入剖析迁移学习的核心原理,手把手带你理解并实践 ResNet 微调,彻底搞懂这一在工业界和学术界都被广泛使用的技术。
一、温故知新:CNN 是如何"看懂"图片的?
在理解迁移学习之前,我们先回顾 CNN 的工作原理,因为迁移学习正是建立在这个基础上的。
1.1 图像在计算机中的样子
图像在计算机中本质上是一堆数字矩阵,数值范围为 0~255。0 代表最暗,255 代表最亮。
-
灰度图 :单通道,形状为
(H, W) -
RGB 彩图 :三通道,形状为
(H, W, 3),分别对应红、绿、蓝三个通道例如一张 32×32 的 RGB 图像,其数据形状为 (32, 32, 3)
共有 32 × 32 × 3 = 3072 个像素值

图1:CNN 不同深度的层学习到的特征可视化,从浅层的边缘纹理到深层的语义特征
1.2 卷积层:特征提取的核心
卷积(Convolution) 是对图像局部区域和卷积核做逐元素相乘再求和的操作,其本质是一个可学习的滤波器(Filter)。
output i , j = ∑ m ∑ n input i + m , j + n × kernel m , n \text{output}i,j = \sum_{m}\sum_{n} \text{input}i+m, j+n \times \text{kernel}m,n outputi,j=m∑n∑inputi+m,j+n×kernelm,n
卷积层有三个关键超参数:
| 参数 | 含义 | 示例 |
|---|---|---|
| stride(步长) | 卷积核每次滑动的步长 | stride=1 |
| padding(填充) | 在边缘补充0,保持尺寸 | zero-padding=1 |
| depth(深度) | 卷积核个数,决定输出通道数 | depth=64 |
输出尺寸计算公式:
output_size = W − F + 2 P S + 1 \text{output\_size} = \frac{W - F + 2P}{S} + 1 output_size=SW−F+2P+1
其中 W 为输入尺寸,F 为卷积核大小,P 为 padding,S 为 stride。
📌 例子: 输入为 32×32×3 的图像,用 10 个 5×5×3 的卷积核,stride=1,padding=2:
32 − 5 + 2 × 2 1 + 1 = 32 \frac{32 - 5 + 2 \times 2}{1} + 1 = 32 132−5+2×2+1=32
输出为 32×32×10 的特征图(Feature Map)。
1.3 池化层:降维提速
池化层(Pooling)是一种降采样操作,作用是:
- 减小特征图尺寸,降低计算量
- 保留主要特征,一定程度上防止过拟合
- 引入一定的平移不变性
| 池化类型 | 操作 | 特点 |
|---|---|---|
| Max Pooling | 取局部区域最大值 | 最常用,保留显著特征 |
| Average Pooling | 取局部区域平均值 | 平滑特征,更柔和 |
| Global Average Pooling | 对整个特征图求均值 | 常用于网络末端替代全连接 |
1.4 全连接层:分类决策
当卷积层和池化层提取出足够的特征后,全连接层(Fully Connected Layer)将特征展平(Flatten)成一维向量,再通过线性变换映射到最终的分类结果。
卷积提特征 → 池化降维 → Flatten展平 → 全连接分类二、经典 CNN 架构一览
在迁移学习中,我们通常选用在大型数据集上预训练好的经典模型,了解它们的演化历程有助于选择合适的骨干网络。
| 模型 | 年份 | 创新点 | Top-5 错误率 |
|---|---|---|---|
| LeNet | 1998 | CNN 的鼻祖,首次成功应用于手写数字识别 | --- |
| AlexNet | 2012 | 深度学习复兴,引入 ReLU 和 Dropout | 15.3% |
| VGGNet | 2014 | 用多个 3×3 小卷积核堆叠替代大卷积核 | 7.3% |
| GoogLeNet | 2014 | Inception 模块,多尺度并行卷积 | 6.7% |
| ResNet | 2015 | 残差连接,突破深度瓶颈,层数达 152 层 | 3.57% |
三、迁移学习:从零到一的飞跃
3.1 什么是迁移学习?
迁移学习(Transfer Learning) 是指将一个已经在大规模数据集上训练好的模型的"知识",迁移到新的任务上。
用一个形象的比喻:
🎓 一位医学生在系统学习了人体解剖学、病理学之后,再去专修心脏外科,会比一个完全从零开始的人快很多------他不需要重新学"什么是细胞",而是把已有知识迁移过来,只需专注于新的细分领域。
CNN 的迁移学习也是如此:
- 预训练模型在 ImageNet(120万张图片,1000类)上学会了识别边缘、纹理、形状、高级语义等通用特征
- 我们把这些"通用特征提取器"直接拿来用,只需在顶部添加适合自己任务的分类头
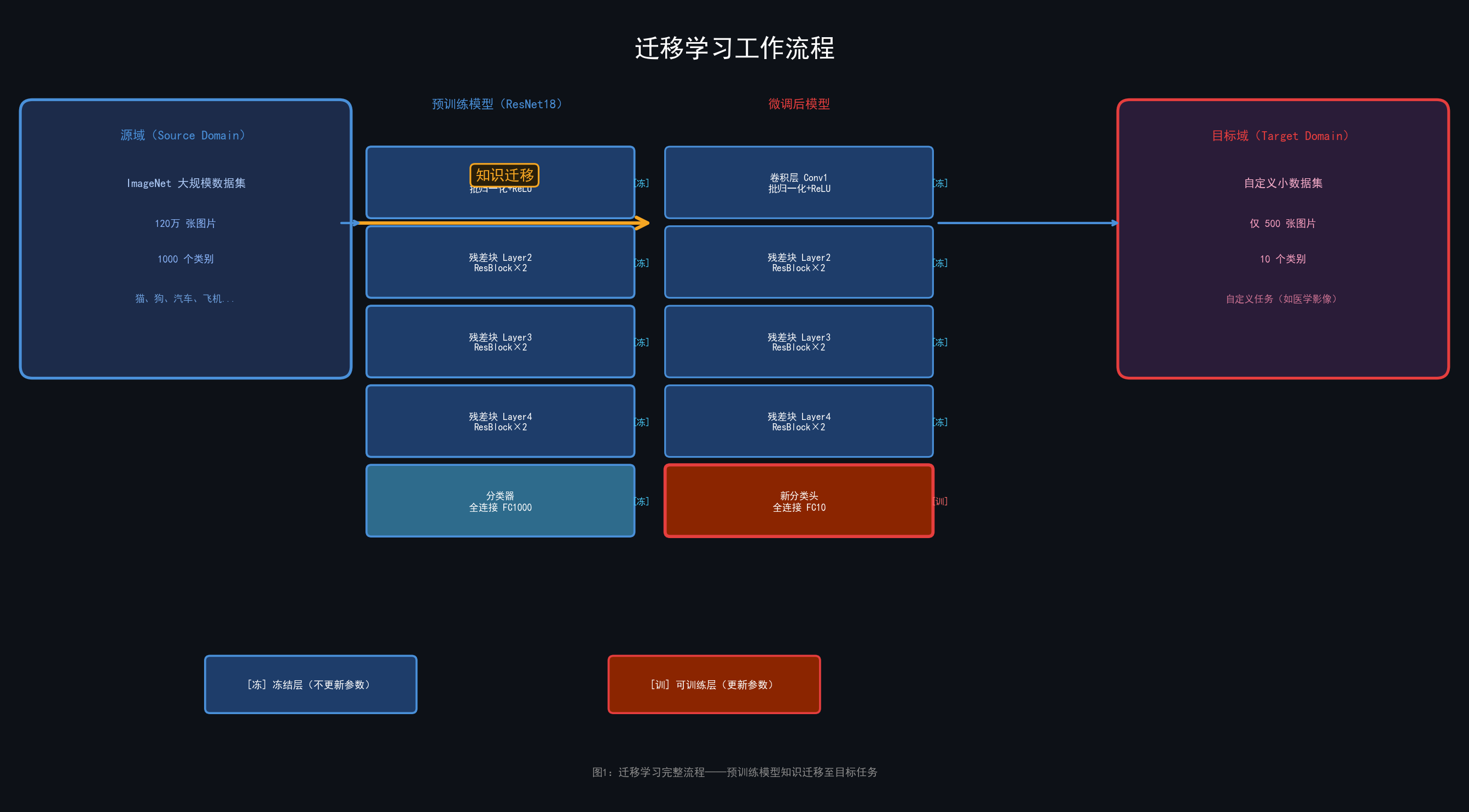
图2:迁移学习完整流程------从 ImageNet 预训练模型到自定义任务微调
3.2 为什么迁移学习有效?
CNN 的不同层学习到的是不同层次的特征:
浅层(Low-level):边缘、颜色、纹理 --------------------- 通用,可迁移
↓
中层(Mid-level):轮廓、形状、局部模式 ------------ 较通用
↓
深层(High-level):语义特征、物体整体 --------------- 与任务相关因此,浅层特征几乎对所有视觉任务都有用,而深层特征则更依赖于具体任务。这就是为什么我们通常"冻结浅层、微调深层"。
3.3 迁移学习的完整步骤
步骤一:选择预训练模型
根据任务需求选择合适的骨干网络。通常推荐:
- 数据量极少(<1000张):使用 ResNet18、MobileNet 等轻量模型
- 数据量中等(1000~10000张):ResNet50、VGG16
- 数据量较大(>10000张):ResNet101、EfficientNet
步骤二:冻结预训练层参数
保持预训练模型的权重不变,防止在小数据集上过拟合:
python
import torchvision.models as models
import torch.nn as nn
# 加载 ResNet18 预训练模型
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 冻结所有参数
for param in model.parameters():
param.requires_grad = False
print("✅ 预训练层参数已冻结")步骤三:替换分类头
将原有的分类层(针对 ImageNet 1000类)替换为适合当前任务的层:
python
# 获取全连接层的输入特征数
num_features = model.fc.in_features # ResNet18 的 fc 层输入为 512
# 替换为新的分类头(假设是10分类任务)
model.fc = nn.Linear(num_features, 10)
print(f"✅ 分类头已替换:{num_features} → 10")步骤四:训练新增层
只更新新增分类头的参数:
python
import torch.optim as optim
# 只优化 fc 层的参数
optimizer = optim.Adam(model.fc.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
# 训练循环
def train_epoch(model, dataloader, optimizer, criterion, device):
model.train()
total_loss = 0
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)步骤五:微调(Fine-tuning)
在新层训练稳定后,可以解冻部分深层,使用极小的学习率进行微调:
python
# 解冻最后两个残差块
for name, param in model.named_parameters():
if 'layer4' in name or 'layer3' in name:
param.requires_grad = True
# 为不同层设置不同学习率(分层学习率)
optimizer = optim.Adam([
{'params': model.layer3.parameters(), 'lr': 1e-5}, # 低学习率
{'params': model.layer4.parameters(), 'lr': 1e-4}, # 中学习率
{'params': model.fc.parameters(), 'lr': 1e-3}, # 高学习率
])
print("✅ 开始微调阶段")⚠️ 注意:微调时学习率要设得非常小(通常比正常训练低 10~100 倍),否则会破坏预训练权重中的宝贵知识。
步骤六:完整代码示例
python
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
# ========== 1. 数据预处理 ==========
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # ImageNet 均值/方差
])
# ========== 2. 加载预训练模型 ==========
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 冻结所有层
for param in model.parameters():
param.requires_grad = False
# 替换分类头(10分类)
model.fc = nn.Linear(model.fc.in_features, 10)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# ========== 3. 定义优化器和损失函数 ==========
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.1, patience=5, verbose=True
)
criterion = nn.CrossEntropyLoss()
print(f"✅ 模型加载完成,训练设备:{device}")
print(f"📊 可训练参数数量:{sum(p.numel() for p in model.parameters() if p.requires_grad):,}")四、深入理解:ResNet 为何是迁移学习的首选?
4.1 深度网络的两大顽疾
随着网络层数增加,传统 CNN 面临两个严重问题:
① 梯度消失(Gradient Vanishing)
反向传播时,梯度从输出层向输入层传递。若每层梯度 < 1,经过多层相乘后趋近于 0,浅层参数几乎无法更新:
∂ L ∂ W 1 = ∂ L ∂ z n ⋅ ∂ z n ∂ z n − 1 ⋯ ∂ z 2 ∂ z 1 ≈ 0 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial z_n} \cdot \frac{\partial z_n}{\partial z_{n-1}} \cdots \frac{\partial z_2}{\partial z_1} \approx 0 ∂W1∂L=∂zn∂L⋅∂zn−1∂zn⋯∂z1∂z2≈0
② 网络退化(Degradation)
更诡异的是,即使解决了梯度问题,56层网络在训练集上的错误率竟然高于20层网络------这说明"更深并不总是更好"。
4.2 ResNet 的革命性创新:残差连接
何凯明在 2015 年提出了一个极其优雅的解决方案------残差块(Residual Block):
┌──────────────────┐
│ shortcut │
X ────┤ ├──→ F(X) + X
│ Conv → BN → ReLU│
│ Conv → BN │
└──────────────────┘数学表达:
output = F ( X ) + X \text{output} = F(X) + X output=F(X)+X
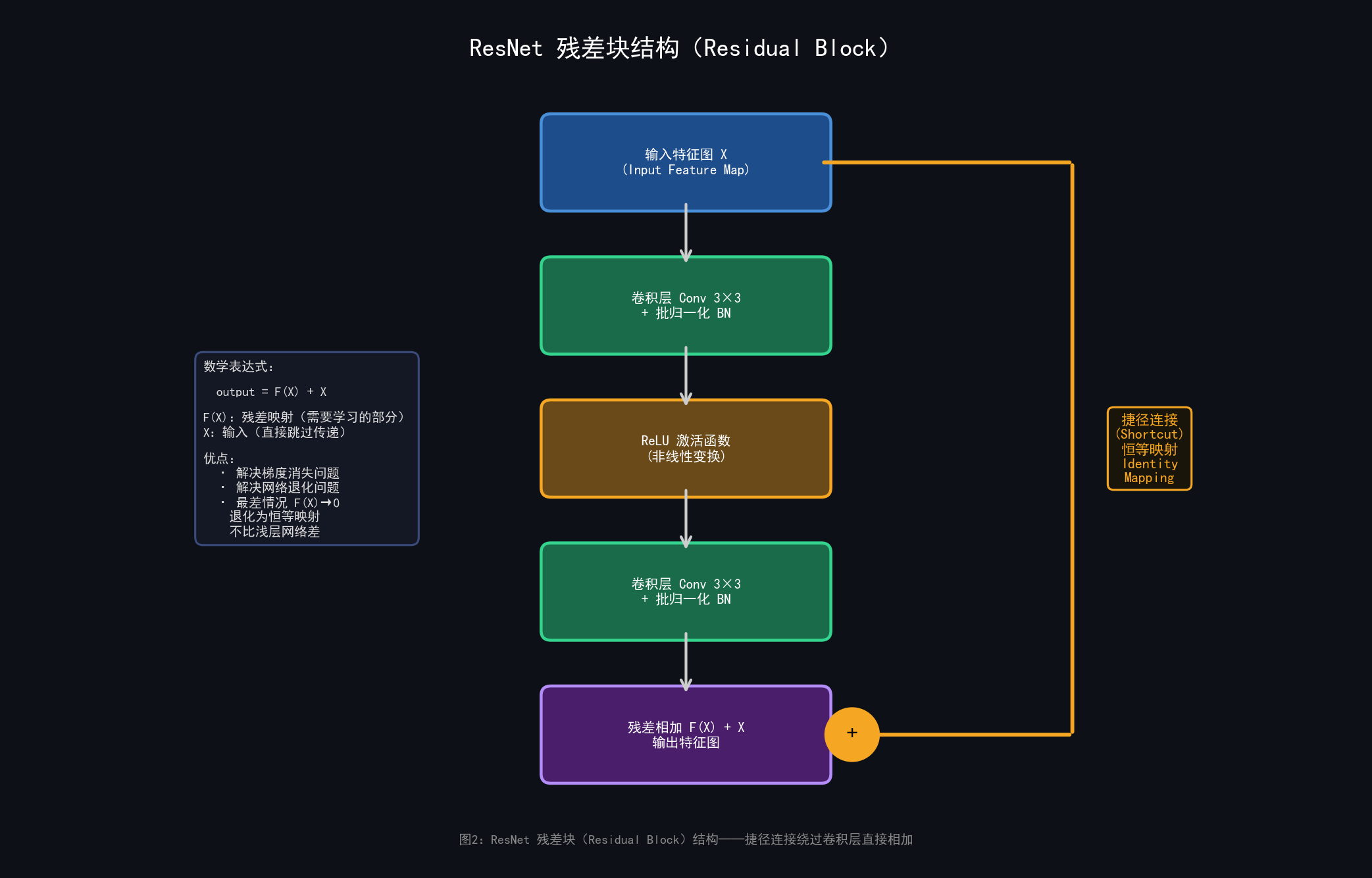
图3:ResNet 残差块(Residual Block)结构------捷径连接(Skip Connection)绕过主路径直接相加
网络只需要学习残差 F(X) = output - X,而不是完整的映射。
极端情况下,F(X)→0,输出=输入,网络可以轻松退化为恒等映射,不会因为加深而变差。
4.3 Batch Normalization:训练稳定的关键
ResNet 中大量使用了 Batch Normalization(BN):
目的:使每层的输出满足均值为 0、方差为 1 的分布,从而:
- 加速收敛(允许使用更大的学习率)
- 减少对权重初始化的依赖
- 具有轻微的正则化效果
python
# 残差块的 PyTorch 实现
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 当 stride≠1 或通道数变化时,shortcut 需要调整维度
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # 残差相加 ✨
out = self.relu(out)
return out4.4 在 ResNet 上添加自定义层
在迁移学习中,有时需要在预训练模型上"嫁接"自定义层。推荐使用继承方式,代码更清晰:
python
class CustomResNet(nn.Module):
def __init__(self, num_classes=20):
super(CustomResNet, self).__init__()
# 加载预训练 ResNet18
self.resnet = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 冻结 ResNet 参数
for param in self.resnet.parameters():
param.requires_grad = False
# 新增自定义全连接层(1000 → 20)
self.fc = nn.Linear(1000, num_classes)
def forward(self, x):
x = self.resnet(x) # 经过预训练骨干网络
x = self.fc(x) # 经过自定义分类头
return x
model = CustomResNet(num_classes=10)
print(model)五、迁移学习在实战中的三种策略
根据目标数据集的大小和与源域的相似度,有三种不同的迁移策略:
策略一:特征提取(Feature Extraction)
适用场景:目标数据集小,且与源域(ImageNet)相似
- ✅ 冻结所有预训练层
- ✅ 只训练新增分类头
- ✅ 训练速度快,不易过拟合
策略二:部分微调(Partial Fine-tuning)
适用场景:目标数据集中等,与源域有一定差异
- ✅ 冻结浅层(通用特征层)
- ✅ 微调深层(任务相关层)
- ✅ 使用分层学习率
策略三:全量微调(Full Fine-tuning)
适用场景:目标数据集较大,与源域差异较大
- ✅ 解冻所有层
- ✅ 使用极小学习率(如 1e-5)
- ⚠️ 需要防止过拟合,配合 Dropout、数据增强等
| 策略 | 数据量 | 相似度 | 速度 | 风险 |
|---|---|---|---|---|
| 特征提取 | 小 | 高 | 最快 | 低 |
| 部分微调 | 中 | 中 | 中 | 中 |
| 全量微调 | 大 | 低 | 慢 | 高(需防过拟合) |

图4:三种迁移学习微调策略对比------蓝色表示冻结层,橙红色表示可训练层
六、学习率调度:迁移学习的加速器
迁移学习中,学习率的调整策略至关重要。PyTorch 提供了三种主流方案:
6.1 周期性衰减(StepLR / CosineAnnealingLR)
python
# 余弦退火:学习率以余弦函数平滑衰减
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=50, eta_min=1e-6
)6.2 自适应调整(ReduceLROnPlateau)
当指标(loss/accuracy)停止改善时,自动降低学习率:
python
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 监控 loss 最小值
factor=0.1, # 学习率缩小为原来的 0.1
patience=10, # 连续 10 个 epoch 无改善才触发
verbose=True # 打印调整信息
)
# 在训练循环中调用
for epoch in range(num_epochs):
train_loss = train_epoch(...)
scheduler.step(train_loss) # 传入监控指标6.3 自定义调整(LambdaLR)
为不同参数组设置不同的学习率变化规律:
python
# 不同层使用不同学习率倍数
lambda_backbone = lambda epoch: 0.1 ** (epoch // 30) # backbone 衰减快
lambda_head = lambda epoch: 1.0 # head 保持不变
scheduler = torch.optim.lr_scheduler.LambdaLR(
optimizer,
lr_lambda=[lambda_backbone, lambda_head]
)七、实战案例:人脸关键点检测(回归任务)
迁移学习不只用于分类,回归任务同样适用。以人脸关键点预测为例:
python
class FaceKeypointNet(nn.Module):
"""人脸关键点检测网络(5个关键点 = 10个坐标值)"""
def __init__(self):
super(FaceKeypointNet, self).__init__()
self.resnet = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 冻结 backbone
for param in self.resnet.parameters():
param.requires_grad = False
# 回归头:输出 10 个坐标(5个关键点 × 2)
self.fc = nn.Sequential(
nn.Linear(1000, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 10),
nn.Sigmoid() # 输出归一化到 [0,1],对应坐标比例
)
def forward(self, x):
x = self.resnet(x)
x = self.fc(x)
return x
# 回归任务使用 MSE 损失
criterion = nn.MSELoss()💡 注意:回归任务中,标签(坐标点)也需要同步进行归一化处理,将像素坐标归一化到 0, 1 区间,与模型输出一致。
八、常见踩坑指南
❌ 坑1:忘记归一化输入数据
预训练模型是在 ImageNet 的特定均值/方差下训练的,输入数据必须用相同的参数归一化:
python
# ✅ 正确:使用 ImageNet 统计量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])❌ 坑2:微调时学习率过大
过大的学习率会在几个 epoch 内破坏预训练权重,导致性能急剧下降:
python
# ❌ 错误:微调时学习率过大
optimizer = optim.SGD(model.parameters(), lr=0.01)
# ✅ 正确:微调使用极小学习率
optimizer = optim.Adam(model.parameters(), lr=1e-5)❌ 坑3:忘记 model.train() 和 model.eval()
Batch Normalization 和 Dropout 在训练和推理时行为不同:
python
# 训练时
model.train()
# 推理/评估时
model.eval()
with torch.no_grad(): # 不计算梯度,节省内存
outputs = model(images)❌ 坑4:输入尺寸不匹配
大多数预训练模型期望输入为 224×224,请务必在数据预处理中 Resize:
python
transforms.Resize(256),
transforms.CenterCrop(224), # 裁剪到 224×224九、总结:迁移学习的核心价值
迁移学习的魅力在于它完美契合了工程实践的现实需求:
- 数据稀缺时,预训练模型提供了强大的特征基础
- 计算资源有限时,冻结层策略大幅降低训练成本
- 任务特殊时,微调让通用特征适配特定领域
一句话总结:
🚀 "不要重新发明轮子,站在巨人的肩膀上,用迁移学习加速你的 AI 之旅。"
迁移学习选型建议流程图(文字版)
你的任务是什么?
├── 图像分类 → ResNet50 / EfficientNet-B4
├── 目标检测 → ResNet + FPN (Faster RCNN / YOLO)
├── 图像分割 → ResNet + UNet / DeepLab
└── 关键点回归 → ResNet18 / MobileNet (轻量快速)
数据量多少?
├── <1000张 → 特征提取(冻结全部)
├── 1000~1w张 → 部分微调(冻结浅层)
└── >1w张 → 全量微调(极小学习率)📚 参考资料
- He, K., et al. (2016). Deep Residual Learning for Image Recognition. CVPR 2016.
- Yosinski, J., et al. (2014). How transferable are features in deep neural networks?. NIPS 2014.
- PyTorch 官方文档:torchvision.models
- ImageNet 竞赛历年结果:Papers With Code - ImageNet Benchmark
如果觉得本文有帮助,欢迎 一键三连 ⭐ 点赞 + 收藏 + 关注,后续将持续更新深度学习系列文章!
有问题欢迎评论区讨论,我会尽快回复 💬