
🔥大奇个人主页 :https://blog.csdn.net/m0_75192474?type=blog
⚡本文所属专栏:https://blog.csdn.net/m0_75192474/category_13131150.html
最近在做雷达与IMU的无线数据转发,但在数据解析过程中出现了数据混乱,让我很是头疼,因为之前是用Python做的,由于Python代码较为简单,所以对当时的大小端问题,有疏忽;这次换做了C++的Boost库来做UDP通信,发现了这个问题。
在网络通信当中,要传输的多字节数例如
16位,32位数据,通常需要涉及到数据的大小端转换问题,也与发送端和接收端的大小端存储模式相关,为了避免在数据接收端出现数据错乱的情况,我们通常要使用大小端转换来解决
发送端:ESP32S3 小端模式
接收端:电脑 x86 小端模式
uint16位数据发送和接收过程(无大小端转换)
例如:uint16_t temp = 0x1234 ,他有两个8位的字节组成,
- 高字节:
0x12 - 低字节:
0x34
发送端:由于ESP32S3的小端特性,低字节放低地址,先存低字节
内存排列(从左到右 → 地址由低到高):👉 内存:0x34 0x12 网络线路传输顺序:先发 0x34,再发 0x12
接收端:由于电脑 x86架构也是小端模式,收到顺序存入内存 收到第一个字节0x34放到低内存地址;收到第二个字节0x12放进高内存地址 拼接规则:低地址当低字节,高地址当高字节读到的值 = 0x1234
⭐ 此时好像没什么问题,但是他必须要求发送和接收端都是小端模式存储,如果你更换接收设备,同时这个设备他不是小端模式存储,那么数据就会错乱,直接乱码。
⚡ 因此历史规范:**互联网规定「网络字节序强制大端」**所有标准字段:IP、端口、协议长度字段,都统一按照大端模式存储
uint16位数据发送和接收过程(有大小端转换)
要发送的数据 :uint16_t temp = 0x1234 ,目标 :接收端同样收到 0x1234
-
发送前转成大端模式 :使用
htons()转换uint16_t send_net = htons(val);
转换后逻辑值还是0x1234,但**内存字节顺序翻转,**原来是0x3412,现在是0x1234;在网络中,先发0x12,再发0x34. -
接收后转成小端模式 :接收到的数据在内存中存储为
0x3412
转换小端模式,使用uint16_t recv_host = ntohs(recv) 此时 recv_host存储的值就是0x1234
大小端转换的4个函数原型(字节顺序翻转)
包含头文件 #include <arpa/inet.h>
- 主机 → 网络(发送前用)
c
uint16_t htons(uint16_t hostshort); // 16位:端口号
uint32_t htonl(uint32_t hostlong); // 32位:IP/数值- 网络 → 主机(接收后用)
c
uint16_t ntohs(uint16_t netshort); // 16位
uint32_t ntohl(uint32_t netlong); // 32位- 16 位转换:
htons /ntohs内部实现
因为翻转两次 = 还原,所以收发共用一套逻辑
c
// 内部真实实现(简化版)
uint16_t htons(uint16_t x)
{
// 把 2 个字节反过来!
return ((x & 0xFF) << 8) | ((x >> 8) & 0xFF);
}输入:0x1234
x & 0xFF→ 取低字节0x34<< 8→ 左移 8 位 →0x3400x >> 8→ 右移 8 位 →0x12- 两者相或 →
0x3400 | 0x0012 = 0x3412
结果:0x1234 → 变成 → 0x3412,字节完全翻转!
- 32 位转换:
htonl /ntohl内部实现
c
uint32_t htonl(uint32_t x)
{
return ((x & 0xFF) << 24) |
(((x >> 8) & 0xFF) << 16) |
(((x >> 16) & 0xFF) << 8) |
((x >> 24) & 0xFF);
}把 4 个字节 ABCD → DCBA
有符号int16_t数据处理
- 不管
int16_t(有符号)还是uint16_t(无符号):内存里只是两个二进制字节,符号位本身就藏在高位字节里; - 大小端转换只做一件事:翻转两个字节顺序,不碰里面的 bit、不修改正负;
- 发送:强转
uint16_t→htons翻转字节 → 发送 - 接收:收网络大端数据 →
ntohs翻回本机顺序 → 强转回int16_t自动恢复正负
问题表述:在UDP套接字传输过程中,我在解析ESP32S3发来的雷达数据时,发现雷达数据解析失败,进一步排查是雷达的距离数据和强度数据出现了错位,距离数据时16位,强度数据是8位,后续查找资料后发现是结构体字节对齐问题。
什么是结构体对齐
CPU 不是按 1 字节随便读内存 ,而是按「固定块」读取(4 字节、8 字节一块)编译器为了让 CPU 读得更快、硬件不报错,会自动在结构体成员之间填充空白字节 ,这就是结构体内存对齐
举例说明结构体字节对齐
uint16_t(2 字节,16 位)uint8_t(1 字节,8 位)
c
// 没有任何对齐指令:默认自然对齐
struct MsgDefault
{
uint8_t flag; // 1字节 8位
uint16_t value; // 2字节 16位
};规定:
- 8 位(1 字节):随便放哪里都可以(0、1、2、3...)
- 16 位(2 字节) :必须从偶数位置开始放(0、2、4...)
- 32 位(4 字节):必须从 4 的倍数开始放
下面一步步来排一下内存分布
-
首先放
flag变量,由于它是1个字节,那么他无所谓放在那里,我们把它放在偏移0的位置,那么下一个位置就是偏移1 -
接下来放
value变量,他是16位的,占两个字节,又由于16位数据必须放在偏移位置位偶数的地方,而此时偏移位置为1,是奇数 ;此时编译器自动帮你塞一个空字节(填充)占住偏移 1,0: flag;1: 填充字节(空的,没用) -
现在下一个位置变成了 偏移 2(偶数),可以放
value了最终的内存分布
0: flag
1: 填充
2: value 第1字节
3: value 第2字节
总大小 = 1 + 1 + 2 = 4 字节(原来是1+2=3字节)现在编译器自动添加了一个字节,那么在读取的时候就会出现呢内存错位。
解决结构体字节对齐问题(强制紧凑对齐)
🔥使用__attribute__((packed))关键字 直接告诉编译器:这个结构体,取消所有自动填充,全部紧凑排列。
c
typedef struct {
uint8_t a;
uint16_t b;
} __attribute__((packed)) test_t;它强制覆盖对齐规则:
- 不让 16 位变量必须从偶数开始
- 不让 32 位变量必须从 4 的倍数开始
- 所有成员紧贴着放,没有任何空隙
c
a(1字节) + b(2字节) = 总3字节
无填充、无空位🔥使用#pragma pack(push, 1) + #pragma pack(pop) 它告诉编译器:从现在开始,所有结构体按 1 字节对齐,不许填充
作用
push:保存当前对齐方式1:强制改成 1 字节对齐pop:恢复原来的对齐方式
c
#pragma pack(push, 1) // 临时改成1字节对齐
struct Test {
uint8_t a;
uint16_t b;
};
#pragma pack(pop) // 恢复默认🔥_Alignas(1) (C11 标准关键字)
_Alignas(N) = 强制按 N 字节对齐
c
struct Test {
uint8_t a;
uint16_t b;
} _Alignas(1);本项目实际情况
传输雷达距离 和强度数据到电脑
cpp
// 雷达单个点的结构体
typedef struct {
uint16_t distance; // 距离,单位mm
uint8_t intensity; // 信号强度
} ld14p_point_t;发送端ESP32S3
c
for (int i = 0; i < LD14P_POINT_PER_PACK; i++) //每包12个数据点
{
ros_lidar.lidar.points[i].distance = hton16(temp_lidar.points[i].distance);//距离数组16位
ros_lidar.lidar.points[i].intensity = temp_lidar.points[i].intensity;//强度数据8位
printf("距离:0x%x,强度:0x%x \\r\\n", temp_lidar.points[i].distance , temp_lidar.points[i].intensity);
}接收端电脑x86
cpp
for(int i=0;i< LD14P_POINT_PER_PACK;i++){ //此处注意接口提字节对齐问题,距离数据位16位,强度数据位8位,不用对齐会错位(已踩坑2026.3.27 21:07)
lidar_rawData.points[i].distance = (recv_buf_[3*i+7] << 8) | recv_buf_[3*i+8];
lidar_rawData.points[i].intensity = recv_buf_[3*i+9];
printf("距离:0x%x,强度:0x%x \\r\\n", lidar_rawData.points[i].distance , lidar_rawData.points[i].intensity);
}结果出现了字节错位,原因是距离为2个字节,强度为1个字节
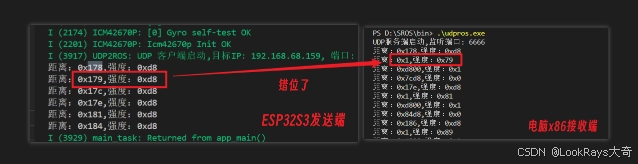
修改发送与接收的雷达单点结构体加上__attribute__((packed))
cpp
// 雷达单个点的结构体
typedef struct {
uint16_t distance; // 距离,单位mm
uint8_t intensity; // 信号强度
} __attribute__((packed)) ld14p_point_t;结果正确
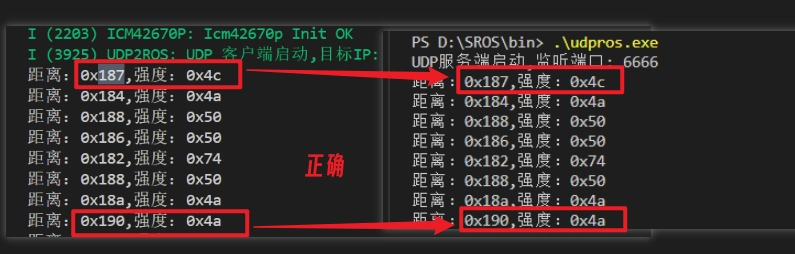
转换成实际距离M

| 方式 | 语法风格 | 适用平台 | 特点 |
|---|---|---|---|
__attribute__((packed)) |
GCC 风格 | Linux / 嵌入式 | 最常用、最简单 |
#pragma pack(1) |
预处理指令 | 全平台(Windows+Linux) | 最兼容 |
_Alignas(1) |
C11 标准 | 现代编译器 | 标准官方 |
注意事项 :如果你定义的结构体中含有子结构体,那么在使用__attribute__((packed)) 和_Alignas时,要对每一个结构体加上,否则无法实现紧凑对齐
c
// 子结构体:加 packed
struct Sub {
uint8_t a;
uint16_t b;
} **attribute**((packed));
// 父结构体:也加 packed
struct Main {
uint8_t x;
struct Sub sub;
uint32_t y;
} **attribute**((packed));在使用__attribute__((packed)) 和_Alignas时,要对每一个结构体加上,否则无法实现紧凑对齐
c
// 子结构体:加 packed
struct Sub {
uint8_t a;
uint16_t b;
} **attribute**((packed));
// 父结构体:也加 packed
struct Main {
uint8_t x;
struct Sub sub;
uint32_t y;
} **attribute**((packed));在 C++(以及 C 语言)中,memset 和 memcpy 是有关底层内存操作。它们直接操作内存字节,效率极高,如果发送和接收端定义的结构体完全一致,且紧凑对齐,可以使用 memcpy 来拷贝数据。
结构体在内存里就是一段连续的二进制数据, memcpy 就是拷贝连续二进制,两边结构一致 → 拷贝后完美还原
memcpy (内存拷贝)
- 功能:从源地址拷贝指定数量的字节到目标地址。
- 函数原型 :
void *memcpy(void *destination, const void *source, size_t num);
参数解释:
destination: 目标内存地址。source: 源内存地址。num: 拷贝的字节数。
典型场景:打包 UDP 数据包
如果你想把结构体转为字节流发给 UDP:
c
uint8_t buffer[128];
memcpy(buffer, &speedtoros, sizeof(speedtoros));
// 现在 buffer 里存的就是 speedtoros 的原始二进制数据⚠️ 致命误区:
- 内存重叠 :如果源地址和目标地址有重叠(比如把数组的后半部分拷到前半部分),
memcpy的行为是未定义的。此时必须使用memmove。 - 长度溢出 :如果
num超过了目标缓冲区的实际大小,会发生缓冲区溢出,这是嵌入式开发中最隐蔽的 Bug。
memset (内存设置)
- 功能 :将一段内存区域的每个字节都设置为同一个值。
- 函数原型 :
void *memset(void *ptr, int value, size_t num); - 参数解释:
ptr: 指向要填充的内存块的指针。value: 要设置的值(虽然是int,但内部会转为unsigned char,即只取低 8 位)。num: 要设置的字节数 (常用sizeof获取)。
**典型场景:**结构体清零
c
SensorData_t myData;
memset(&myData, 0, sizeof(myData)); // 将所有成员初始化为 0⚠️ 致命误区:
- 不能用于非 0/ -1 的整数数组填充: 如果你写
memset(arr, 1, sizeof(arr)),由于它是按字节 填充,每个int变成0x01010101,结果是16843009而不是1。 - 不能用于带虚函数或 STL 容器的类: 对
std::string或带有虚函数的类使用memset会破坏内部指针(如虚函数表指针 vptr),导致程序直接崩溃。
memset 的误区:为什么填充 1 会失败?
memset 是按 字节 (Byte) 填充的,而不是按 数字 (Number) 填充。
假设有一个 int 数组(在 ESP32 中,一个 int 占 4 个字节)如果执行 memset(arr, 1, sizeof(arr));
- 理想情况:把每个
int变成1。 - **实际发生:**它把
int内部的 4个字节 全部变成了01。 - **结果:**这个
int在内存里变成了二进制的00000001 00000001 00000001 00000001。
转换成十进制,这个数是 16,843,009 ,而不是 1。
结论 :
memset只适合初始化为 0 (00000000) 或 -1 (补码是11111111)。
memcpy 的误区:什么是内存重叠
memcpy 的底层实现通常是极其追求速度的,它假设源地址和目标地址是完全分开的。
假设有一个数组 char a[] = "abcdefg";,你想把从 a[2] 开始的内容往后挪一位,挪到 a[3]源地址是 &a[2] 目标地址是 &a[3]。
- 问题 :目标地址
a[3]本身就是源数据的一部分。 - 后果 :当
memcpy正在拷贝第一个字节时,它可能会覆盖掉后面还没来得及拷贝的原始数据。最后导致数据乱码或全变成重复的字符。
解决方法:
memcpy:仅用于两块完全独立的缓冲区(比如从传感器结构体拷贝到发送缓冲区)。memmove:如果需要在同一个数组 内移动数据,使用memmove。它会多做一个判断,如果是重叠的,它会从后往前拷贝,确保数据安全。
