目录


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》《笔试算法》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
其实严格来说链表篇的前两篇文章的题目我在数据结构专栏已经写过,但是当时是用C语言来写的,而且当时见过的代码不多,思路并不开阔,本专栏不仅会全部用C++进行重写,对于一些题目还会用一些更优地解法来改写
一、移除链表元素
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 1. 创建虚拟头节点,指向原链表头节点
ListNode* dummy = new ListNode(0, head);
// 2. 使用一个指针进行遍历,初始指向虚拟头节点
ListNode* curr = dummy;
// 3. 遍历链表,由于要执行删除操作,我们需要检查的是 curr->next
while (curr->next != nullptr) {
if (curr->next->val == val) {
// 手动释放被删除节点的内存,防止内存泄漏
ListNode* tmp = curr->next;
curr->next = curr->next->next; // 跨过需要删除的节点
delete tmp; // 释放内存
} else {
curr = curr->next; // 不需要删除,指针后移
}
}
// 4. 记录新的头节点并释放虚拟头节点
ListNode* newHead = dummy->next;
delete dummy;
return newHead;
}
};一、核心问题
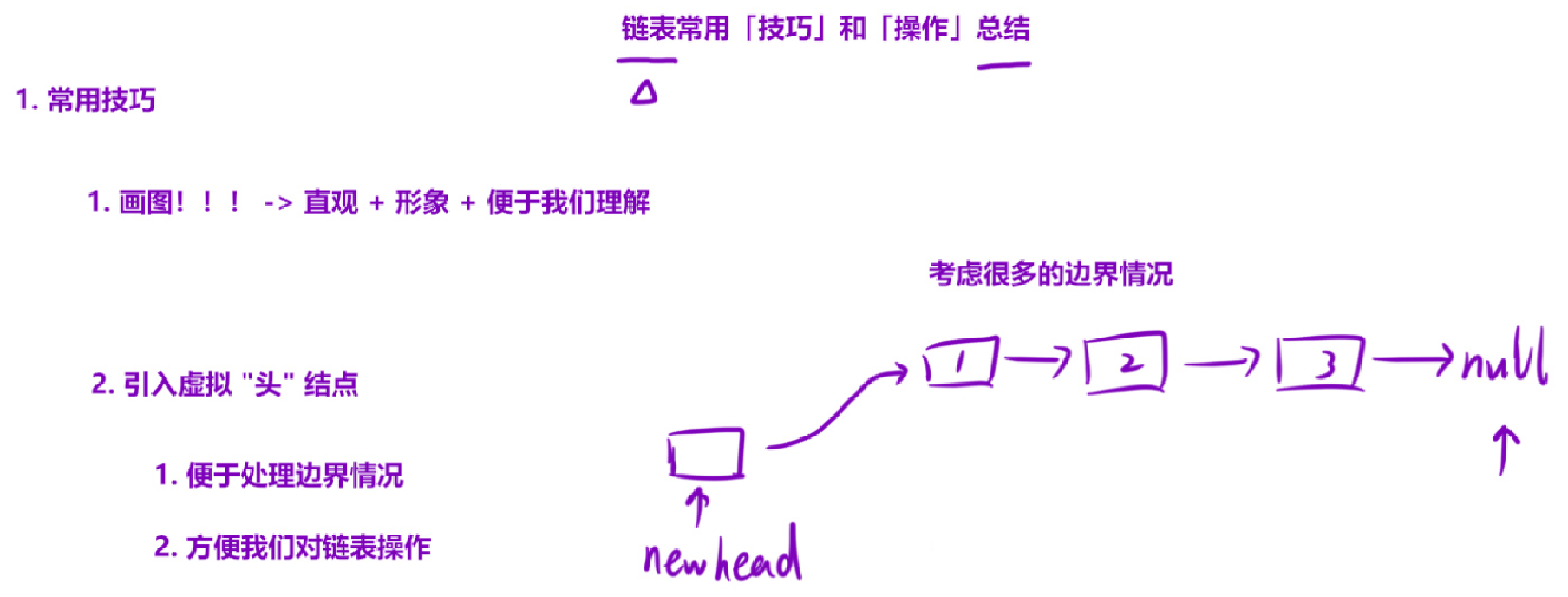
链表删除节点时,最大的麻烦是:如果要删除的节点是头节点,我们需要单独修改head指针;如果是中间节点,需要找到它的前驱节点才能完成删除 。
比如:
- 原链表:7 -> 7 -> 7,要删除所有7,直接操作head会很麻烦;
- 原链表:1 -> 6 -> 2,要删除6,需要先找到它的前驱1,再修改1的next。
下面代码用 虚拟头节点(Dummy Node) 解决了所有痛点,让删除逻辑对 "头节点 / 中间节点 / 尾节点" 完全统一。
二、代码解析
1. 第一步:创建虚拟头节点
cpp
ListNode* dummy = new ListNode(0, head);创建一个值为0的虚拟节点,让它的next指向原链表的头节点head。原链表变成了 dummy -> head -> ... -> nullptr
2. 第二步:初始化遍历指针
cpp
ListNode* curr = dummy;为什么curr要指向dummy,而不是head?
因为我们的删除逻辑是:通过 "前驱节点" 删除 "后继节点"。
- 如果curr指向head,那么删除head节点时,没有前驱节点,无法修改next指针;
- 而curr指向dummy时,dummy是原head的前驱,所有节点(包括原head)都可以用 "前驱节点删除后继节点" 的统一逻辑处理。
3. 第三步:遍历链表,删除目标节点
cpp
while (curr->next != nullptr) {
if (curr->next->val == val) {
// 情况1:下一个节点需要删除
ListNode* tmp = curr->next; // 保存要删除的节点地址(为了释放内存)
curr->next = curr->next->next; // 前驱节点直接跳过目标节点,指向目标的下一个节点
delete tmp; // 释放被删除节点的内存,防止内存泄漏
} else {
// 情况2:下一个节点不需要删除,前驱节点后移
curr = curr->next;
}
}情况 1:curr->next->val == val(节点需要删除)
- 为什么要先保存curr->next到tmp?
因为执行curr->next = curr->next->next后,我们就失去了对原curr->next节点的引用,如果不提前保存,就无法释放它的内存,会造成内存泄漏。 - 为什么删除节点后,curr不需要后移?
比如链表是dummy -> 7 -> 7 -> nullptr,val=7: -
- curr指向dummy,curr->next是第一个7,删除后curr->next变成第二个7;
-
- 如果此时curr后移,会错过对第二个7的检查;
-
- 不后移的话,下一次循环会直接检查新的curr->next(第二个7),继续删除,直到所有7都被清理。
情况 2:curr->next->val != val(节点不需要删除)
此时curr需要后移,继续检查下一个节点。比如链表dummy -> 1 -> 2 -> nullptr,val=6:
- curr指向dummy,
curr->next=1不需要删除,curr后移到1; - curr=1,
curr->next=2不需要删除,curr后移到2; - curr=2,
curr->next=nullptr,循环结束。
二、反转链表
解法1:双指针 + 临时变量
1. 定义两个指针 prev 和 curr:
- prev:记录当前节点的前一个节点(初始为 nullptr,因为原链表的头节点反转后会成为尾节点,尾节点的 next 应为 nullptr)
- curr:记录当前正在处理的节点(初始为链表头节点 head)
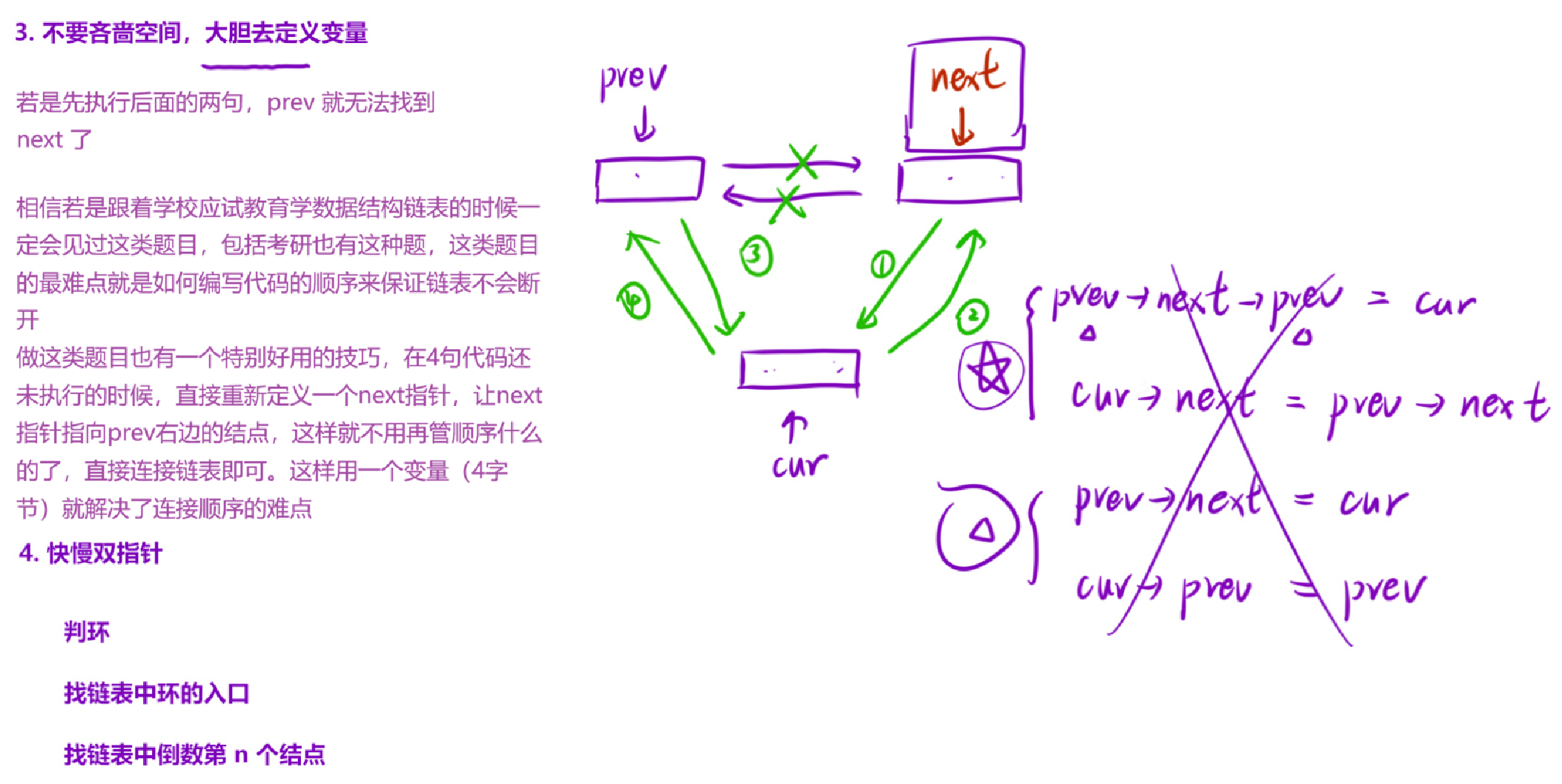
2. 遍历链表,对每个节点执行 4 步操作:
- 临时保存当前节点的下一个节点(防止断链)
- 将当前节点的 next 指向 prev(完成反转)
- prev 向后移动到当前节点
- curr 向后移动到原下一个节点
3. 遍历结束后,curr 指向 nullptr,prev 指向原链表的尾节点(即反转后的新头节点),返回 prev 即可。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr; // 记录前一个节点,初始为 nullptr
ListNode* curr = head; // 记录当前节点,初始为头节点
while (curr != nullptr) {
ListNode* nextTemp = curr->next; // 1. 临时保存下一个节点
curr->next = prev; // 2. 将当前节点指向前一个节点,完成反转
prev = curr; // 3. prev 指针向后移动
curr = nextTemp; // 4. curr 指针向后移动
}
// 当循环结束时,curr 指向 nullptr,prev 指向原链表的最后一个节点,即新链表的头节点
return prev;
}
};解法2:递归法(加分项)
递归解法的本质是将大问题拆解为小问题 ,利用递归调用栈记录回溯路径,在回溯阶段完成指针反转。核心逻辑基于以下两个信念:
- 假设
reverseList(head->next)能成功反转head之后的所有节点,返回反转后的新头节点newHead - 我们只需处理当前节点head与已反转子链表的连接关系,就能完成整个链表的反转
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
// 递归终止条件:如果是空链表,或者当前节点是最后一个节点,直接返回
if (head == nullptr || head->next == nullptr) {
return head;
}
// 递归调用,翻转第二个节点到最后的部分
// newHead 是反转后新链表的头节点
ListNode* newHead = reverseList(head->next);
// 此时 head->next 指向的是反转后的尾节点
// 将尾节点的 next 指向当前的 head
head->next->next = head;
// 切断当前 head 原本向后的指向,防止形成环
head->next = nullptr;
// 返回新的头节点
return newHead;
}
};注意当调用reverseList(5)时,触发终止条件,返回节点5(newHead首次赋值),这个newHead会被reverseList(4)接收,然后继续向上传递,全程不变
三、链表的中间节点
解法:快慢指针(龟兔赛跑算法)
利用两个速度不同的指针同时遍历链表:
- 慢指针(slow):每次走 1 步。
- 快指针(fast):每次走 2 步。
当快指针到达链表末尾时,慢指针恰好位于链表的中间位置。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* middleNode(ListNode* head) {
// 初始化快慢指针,均指向头结点
ListNode* slow = head;
ListNode* fast = head;
// 当 fast 不为空且 fast 的下一个结点也不为空时,继续遍历
while (fast != nullptr && fast->next != nullptr) {
slow = slow->next; // 慢指针每次走一步
fast = fast->next->next; // 快指针每次走两步
}
// 当快指针走到尽头时,慢指针刚好走到中间位置
return slow;
}
};快慢指针原理解析
快慢指针的核心逻辑是速度差带来的位置关系 ,我们可以从两个角度理解:
1. 速度关系:快指针是慢指针的 2 倍
设慢指针速度为 v(每次 1 步),快指针速度为 2v(每次 2 步)。两者同时从起点出发,当快指针到达终点时,它走过的路程是慢指针的 2 倍。因此,慢指针走过的路程恰好是总路程的一半,也就是链表的中间位置。
2. 位置分析:结合奇偶长度验证
我们以结点索引(从 0 开始)来分析两种情况:
情况 1:链表长度为奇数(如 n=5,索引 0~4)
目标:找到索引为 floor(n/2) = 2 的结点(中间结点)。
遍历过程:
- 初始:slow=0,fast=0
- 第 1 次循环:slow=1,fast=2(0+2)
- 第 2 次循环:slow=2,fast=4(2+2)
- 检查循环条件:
fast=4,fast->next=nullptr,循环停止。
结果:slow=2,正好是中间结点。
情况 2:链表长度为偶数(如 n=6,索引 0~5)
目标:找到索引为 floor(n/2) = 3 的结点(第二个中间结点)。
遍历过程:
- 初始:slow=0,fast=0
- 第 1 次循环:slow=1,fast=2(0+2)
- 第 2 次循环:slow=2,fast=4(2+2)
- 第 3 次循环:slow=3,fast=nullptr(
4->next->next = 5->next = nullptr) - 检查循环条件:fast=nullptr,循环停止。
结果:slow=3,正好是第二个中间结点。
四、合并两个有序链表
解法1:带哨兵节点的迭代法
利用双指针遍历 两个链表,每次选取当前值较小的节点接入新链表,同时通过 哨兵节点(Dummy Node) 统一处理链表头节点的边界情况,避免单独编写逻辑处理头节点为空的场景。
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
// 1. 创建虚拟头节点(哨兵节点),方便处理边界情况
// 注意:在栈上分配,避免使用 new 带来忘记 delete 的内存泄漏风险
ListNode dummy(0);
// 2. cur 指针用于构建新链表,初始指向虚拟头节点
ListNode* cur = &dummy;
// 3. 当两个链表都不为空时,比较当前节点的值,较小的接入新链表
while (list1 != nullptr && list2 != nullptr) {
if (list1->val <= list2->val) {
cur->next = list1; // 将 list1 的节点接到 cur 后面
list1 = list1->next; // list1 指针后移
} else {
cur->next = list2; // 将 list2 的节点接到 cur 后面
list2 = list2->next; // list2 指针后移
}
cur = cur->next; // cur 指针也向前移动一步
}
// 4. 循环结束后,最多只有一个链表还未遍历完
// 直接将未遍历完的链表剩余部分(它本身已经是有序的)拼接到 cur 的尾部即可
cur->next = (list1 != nullptr) ? list1 : list2;
// 5. 返回虚拟头节点的下一个节点,即合并后真实链表的头节点
return dummy.next;
}
};要点补充:
1. 哨兵节点 dummy 的创建
cpp
ListNode dummy(0);
ListNode* cur = &dummy;作用 :哨兵节点是一个虚拟的头节点,不存储有效数据,仅作为新链表的 "占位符"。
核心优势 :避免单独处理新链表的第一个节点(比如 list1 和 list2 都不为空时,无需额外判断谁是头节点)。所有节点的接入逻辑统一为 cur->next = 目标节点,代码更简洁,边界情况处理更安全。
栈上分配的原因:这里直接在栈上创建 dummy,而不是用 new,避免了手动 delete 带来的内存泄漏风险(函数结束时栈上变量自动销毁)。
2. 如果不使用哨兵节点,需要额外处理新链表的头节点,代码会更冗余:
cpp
// 无哨兵的简化逻辑(仅示意)
ListNode* head = nullptr;
if (list1->val <= list2->val) {
head = list1;
list1 = list1->next;
} else {
head = list2;
list2 = list2->next;
}
ListNode* cur = head;
// 后续循环...五、链表的回文结构
核心算法思路
该解法的核心逻辑是:将链表的后半部分反转,再与前半部分逐节点比较,具体分为 3 个步骤:
- 快慢指针找中点:用slow(每次走 1 步)和fast(每次走 2 步)指针,当fast到达链表末尾时,slow恰好指向链表的中间位置(或后半部分的起始位置)。
- 反转后半部分链表:从slow节点开始,反转后半部分链表,使后半部分的顺序倒转。
- 双指针比较两部分:用left(从原链表头开始)和right(从反转后的后半部分头开始)同时遍历,逐节点比较值是否相等,判断是否为回文。
cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
bool chkPalindrome(ListNode* A) {
// 1. 边界情况处理:空链表或单节点链表,直接返回true
if (A == nullptr || A->next == nullptr) {
return true;
}
// 2. 快慢指针找链表中点
ListNode* slow = A;
ListNode* fast = A;
while (fast != nullptr && fast->next != nullptr) {
slow = slow->next; // slow每次走1步
fast = fast->next->next; // fast每次走2步
}
// 3. 反转后半部分链表(从slow节点开始)
ListNode* prev = nullptr;
ListNode* curr = slow;
while (curr != nullptr) {
ListNode* nextTemp = curr->next; // 保存下一个节点,防止断链
curr->next = prev; // 反转当前节点的next指针
prev = curr; // prev向前移动到当前节点
curr = nextTemp; // curr向前移动到原下一个节点
}
// 4. 双指针比较前半部分和反转后的后半部分
ListNode* left = A; // 前半部分指针:从原链表头开始
ListNode* right = prev; // 后半部分指针:从反转后的后半部分头开始
while (right != nullptr) { // 以后半部分遍历完为终止条件
if (left->val != right->val)
return false;
left = left->next; // 前半部分指针后移
right = right->next;// 后半部分指针后移
}
return true;
}
};结语
