前言:
在去年的时候,有打通webrtc的音频降噪使用流程,但是对于非稳态噪声,webrtc效果也不是特别好,就想折腾AI音频训练来处理降噪,晚上本想用rnnoise开源项目来训练音频降噪处理模型,但是人不在状态,就没有弄了,只搭建了基本环境,下个礼拜再开始弄;然后就整理了一下同声传译里面的语音识别的开源项目,这个之前在看到过这个,想着里面的技术原理是怎么样的,毕竟自己也是专门干嵌入式音视频的,很好奇里面的技术;现在这块的技术用在很多生活场景里面的智能硬件里面,比如说AI眼镜、机器人、翻译软件等产品:
首先来介绍一下它里面的技术框架流程:
音频采集与预处理模块负责从麦克风或视频流中获取音频信号并进行降噪、增强等预处理操作;自动语音识别(ASR)模块将音频内容转换为文本;机器翻译(MT)模块实现源语言到目标语言的文本转换;语音合成(TTS)模块则将翻译后的文本转换为语音输出。在端到端方法中,还可以直接将源语言语音翻译为目标语言语音,无需经过文本中间表示,这种方式被称为语音到语音翻译(S2ST),总结如下:
音频前处理(AEC/NS/VAD) → ASR → 机器翻译 → TTS → 字幕/播报/回传
然后查了一下,比较适合嵌入式的语音识别模块开源项目如下:
whisper.cpp:
项目地址:
go
https://github.com/ggml-org/whisper.cpp/tree/v1.8.4
这是一个对 OpenAI Whisper 自动语音识别(ASR)模型 的高性能推理实现。
它的特点是:
-
纯 C/C++ 实现,无外部依赖
-
对 Apple Silicon 做了重点优化,支持:
-
-
ARM NEON
-
Accelerate framework
-
Metal
-
Core ML
-
-
支持 x86 架构的 AVX 指令
-
支持 POWER 架构的 VSX 指令
-
支持 F16 / F32 混合精度
-
支持整数量化
-
运行时 零内存分配
-
支持 Vulkan
-
支持纯 CPU 推理
-
支持 NVIDIA GPU 高效推理
-
支持 OpenVINO
-
支持 Ascend NPU
-
支持 Moore Threads GPU
-
提供 C 风格 API
-
支持 VAD(语音活动检测)
支持的平台
-
Mac OS(Intel 和 Arm)
-
iOS
-
Android
-
Linux / FreeBSD
-
WebAssembly
-
Windows(MSVC 和 MinGW)
-
Raspberry Pi
-
Docker
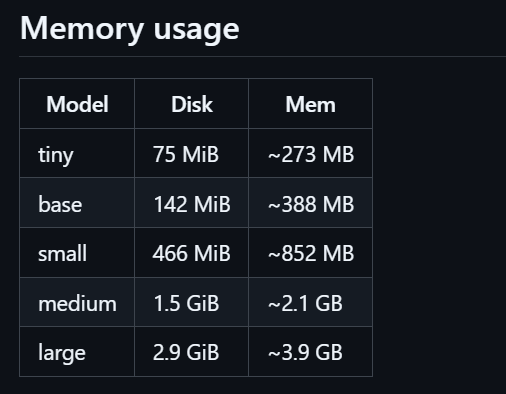
内存占用:
演示效果:
sherpa-onnx:
项目地址:
go
https://github.com/k2-fsa/sherpa-onnx
这个仓库支持在 本地 运行以下功能:
• 语音转文本(ASR),同时支持 流式 和 非流式
• 文本转语音(TTS)
• 说话人分离
• 说话人识别
• 说话人验证 • 口语语言识别
• 音频标签
• VAD(例如 silero-vad) • 语音增强(例如 gtcrn、DPDFNet)
• 关键词检测
• 声源分离(例如 spleeter、UVR)
支持的硬件平台和操作系统包括:
• x86、x86_64、32 位 ARM、64 位 ARM(arm64 / aarch64)、RISC-V(riscv64)、RK NPU、Ascend NPU
• Linux、macOS、Windows、openKylin
• Android、WearOS
• iOS
• HarmonyOS
• NodeJS
• WebAssembly
• NVIDIA Jetson Orin NX(支持 CPU 和 GPU)
• NVIDIA Jetson Nano B01(支持 CPU 和 GPU)
• Raspberry Pi
• RV1126
• LicheePi4A
• VisionFive 2 • 旭日 X3 派 • 爱芯派
• RK3588
提供以下类别的预训练模型下载:
• 语音识别(ASR)
• 文本转语音(TTS)
• VAD
• 关键词检测 • 音频标签
• 说话人识别
• 语言识别
• 标点恢复
• 说话人分段
• 语音增强
• 声源分离
总结:
后面打算在3568和1126B上折腾一下 sherpa-onnx