比如 100 万个粒子,每个都做:
- 更新位置
- 更新速度
- 算 lifetime
- 算颜色/尺寸
- 写回 buffer
这就是标准的数据并行。
形式上很像:
for each particle in parallel:
age += dt
velocity += force * dt
position += velocity * dt
color = ...
这正是 GPU compute 最喜欢的活。
为什么"实例"不那么适合?
因为"实例"不是一个简单的数据点,它更像一个"特效对象"。
一个 Niagara 实例通常要处理这些东西:
- 生命周期管理:创建、激活、停用、销毁
- 参数绑定:User/System 参数从哪里来
- 组件与 Actor 关系
- Transform、Attach、Visibility
- LOD / Scalability / Cull
- 事件、回调、同步
- 跟场景系统交互
- 跟渲染代理、资源管理、世界状态协作
这些事情本质上更像"对象管理",不是纯粹的数值并行。
UE 里的 Bookmark 基本就是"编辑器视角/相机位置的书签",主要用途就是让你在关卡编辑时,快速跳回某个观察位置。
但它不是 "玩家进入场景时的默认出生点",也不是运行时游戏逻辑里的起始位置。
更准确地说,它是给 Level Editor 视口 用的。
你可以把它理解成:
-
记录当前编辑器摄像机的位置和朝向
-
之后一键跳回这个观察点
-
方便在大场景里来回切换几个关键区域
典型用途有这些:
-
关卡很大,快速跳到大厅、走廊、Boss 房
区分这几个概念:
1. Bookmark
-
记录编辑器摄像机视角
-
仅用于编辑和浏览场景
-
不直接参与游戏运行
2. Player Start
-
决定游戏里玩家出生位置
-
是运行时逻辑的一部分
3. Camera Actor / CineCamera
-
是场景中的真实相机对象
-
可用于运行时或 Sequencer
4. Editor Startup Map / 上次打开位置
- 这是编辑器启动行为,不等于 Bookmark 本身
所以 Bookmark 更像:
"编辑器里的视口导航快捷点"。
"我上次下线在地图 A 的某个位置,这次进来还在那个位置"
那这不是 Bookmark,也不是默认编辑器行为,而是你要自己做:
-
保存角色 Transform
-
下次启动或加载关卡时读档
-
把角色放回那个位置
每次开始 Play 时,系统会按当前 GameMode 生成默认角色,并通常把它放到这个唯一的 PlayerStart 上。
只有在下面这些情况里,角色才不会每次都回到 PlayerStart:
-
你手动做了存档/读档
比如:
-
SaveGame -
Load Game From Slot -
保存角色
Transform -
下次开始时恢复位置和旋转
建一个 SaveGame 蓝图
比如叫 BP_PlayerSaveGame。
里面先放这些变量:
-
SavedLocation,类型Vector -
SavedRotation,类型Rotator -
更稳一点可以直接用
SavedTransform,类型Transform -
可选:
LevelName,类型String或Name
如果你以后还要存血量、背包、任务状态,也都放这里。
在合适的时候保存角色位置
通常你会在这些时机保存:
-
手动点击"保存"
-
到达 checkpoint
-
切关前
-
退出游戏前
-
某些关键事件后自动保存
蓝图逻辑大致是:
-
Create Save Game Object -
转成你的
BP_PlayerSaveGame -
取玩家角色:
Get Player Character
-
读取:
-
GetActorTransform或者
-
GetActorLocation -
GetActorRotation
-
-
写入到 SaveGame 变量
-
Save Game to Slot
如果只存位置旋转,核心就是:
-
角色当前
Transform -
写到
SaveGame -
Save Game to Slot("PlayerSlot", 0)
三,游戏开始时读取存档
通常放在:
-
GameMode -
GameInstance -
角色
BeginPlay
都能做,但初学时我更建议:
-
简单项目:先放在角色
BeginPlay -
稍正规一点:放在
GameMode或专门的存档管理器
-
Does Save Game Exist -
如果存在:
-
Load Game From Slot -
转成
BP_PlayerSaveGame
-
-
取出
SavedTransform -
对角色调用:
-
SetActorTransform或者
-
SetActorLocationAndRotation
-
这就能把角色放回上次保存的位置。
实际里常见做法是:
BeginPlay后延迟一小下再恢复
这里的 bookmark 不是你前面说的关卡视口 Bookmark ,而是 Unreal Insights/Trace 里的时间标记点。
你图里这几个命令的含义是:
-
Trace.Bookmark在当前 trace 时间线上插一个"文字标记点"
-
Trace.Screenshot在当前 trace 时间线上附一张当时画面的截图
-
Trace.RegionBegin <Name>/Trace.RegionEnd <Name>标记一段跨多帧的分析区间
所以如果你的问题是:
"性能分析时,能不能用自己定义的标记点,把某一段操作对应到 Insights 里方便看?"
答案是:可以,而且这正是推荐用法。
分清两类"bookmark":
- Editor Bookmark
-
视口位置书签
-
用来快速跳编辑器观察点
-
不直接进入性能 trace
- Trace Bookmark
-
性能采集时写进 trace 的事件标记
-
在 Unreal Insights 里能看到
-
用来对齐"这一刻我做了什么操作"
这两者不是同一个系统。
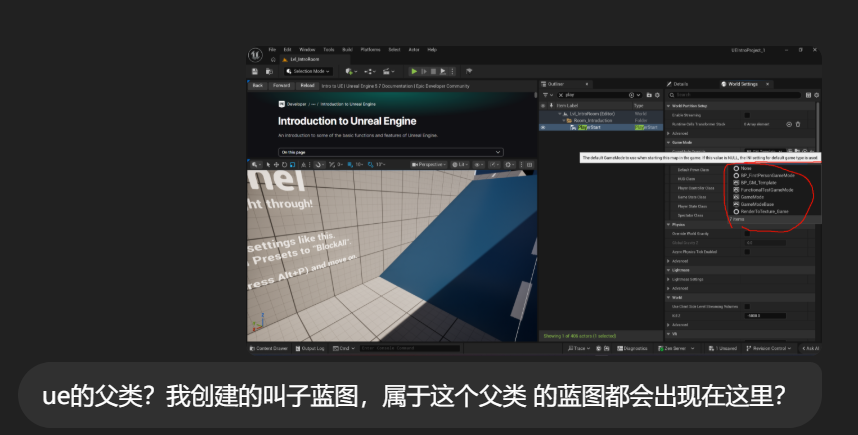
一类是引擎原生类:
-
GameMode -
GameModeBase
这两个更像"父类 / 基类"。
另一类是项目里的蓝图类:
-
BP_FirstPersonGameMode -
BP_GM_Template -
RenderToTexture_Game之类
这些通常是 Blueprint 子类,也就是你说的"子蓝图"。
UE 会列出:
- 原生
GameModeBase / GameMode
GameMode
-
当前关卡的规则与出生逻辑
-
适合决定"这一局开始时玩家该出生在哪"
GameInstance
-
游戏运行期间跨关卡常驻
-
适合管理存档加载、切关传值、全局状态
SaveGame
-
真正存到磁盘的数据容器
-
用来保存位置、旋转、血量、任务状态等
类型兼容的 Pawn 类。
某个类能当 Pawn 用,并且当前项目能看到它,
"所有可作为 Pawn 的类"。
Player Controller Class
那里列出的会是 PlayerController 这一支的类;不是 Pawn。
HUD Class
那里列出的会是 HUD 这一支的类。
UE HUD (Heads-Up Display) 是虚幻引擎中一种基础的2D平视显示系统,专用于在游戏画面最上层实时绘制信息,如血条、弹药数和分数
。它直接利用Canvas或C++绘制在屏幕上,轻量且适合快速显示实时数据,但在现代UE项目中,通常已被功能更强大的UMG Widget系统取代或互补使用。
不是正常控制角色,而是以旁观模式存在时,系统要生成哪一种 Spectator Pawn。
它通常用于这些情况:
-
玩家死亡后进入旁观
-
游戏开始前先作为旁观者等待
-
联机里只看不参与
-
编辑/调试时自由飞行观察
-
没有正式 Pawn 可控制时的替代观察体
默认一般会是:
SpectatorPawn
这是 UE 自带的一个"自由观察用 Pawn",通常特征是:
-
没有正常角色外形
-
不处理 Character 那套移动
-
更像一个自由飞行相机载体
-
常用于 free-fly 观察
它和 Default Pawn Class 的区别很重要。
Default Pawn Class
- 正常进入游戏时,玩家默认控制的角色/载体
Spectator Class
- 当玩家处于 spectator 状态时控制的载体
所以一般流程是:
-
正常游戏:控制
Default Pawn -
旁观模式:控制
SpectatorPawn
World Settings 是"这张关卡的配置",在开始 Play 时会被读取并生效。
不是说"只能在 Play 时存在",而是:
-
你在编辑器里改
-
开始运行这张图时,系统按这里的配置启动
关卡级运行配置。
一张关卡在一次运行里只会有一个生效的 GameMode 类。
至少对这张当前 World 来说,最终只会确定一个。
-
World Settings -> GameMode Override -
如果这里没设,就用
Project Settings -> Maps & Modes里的默认GameMode
所以"同时生效多个 GameMode"这种情况没有。
这就是它的设计:当前关卡选择一个游戏规则入口类。
如果你想做不同模式,一般做法不是"同一关同时挂多个 GameMode",而是:
-
不同关卡用不同
GameMode -
同一
GameMode里根据条件切逻辑 -
或者做多个
BP_GM_xxx,不同地图选不同的那个
比如:
-
BP_GM_Menu -
BP_GM_SinglePlayer -
BP_GM_Combat -
BP_GM_Tutorial
每张图选一个。
最后再把"存档"和它区分一下:
-
GameMode:这一关怎么玩 -
SaveGame:长期保存什么数据 -
GameInstance:跨关卡全局管理
所以如果你要做"记住玩家上次位置":
-
数据存
SaveGame -
需要时由
GameMode或角色在开始时读取并应用
一句话总结:
World Settings 里的 GameMode 是这张关卡开始 Play 时采用的唯一主规则类;一张关卡同时只会有一个生效的 GameMode,这就是 UE 的设计。它负责绑定 Pawn/Controller/HUD 等运行类,但不负责当作存档仓库。
User Parameters
这是最接近"实例参数"的东西。
你可以把颜色、大小、速度、贴图、mesh、目标位置等暴露出去,然后每个 Niagara Component 单独赋值。
Niagara 可以更直接地在系统图上调场景效果,是因为它本来就是"行为资产 + 运行实例参数"的工作流;
Material 非常依赖 Instance,是因为材质图本质上更接近 shader 定义,改主图的代价和影响范围都更大。
Material 编辑的不是一个轻量逻辑图,而是更接近:
-
shader 功能组合
-
编译分支
-
uniform 表达式
-
纹理采样路径
-
渲染管线状态相关输入
你一旦直接改主 Material:
-
可能触发 shader 重新编译
-
所有引用这个 Material 的地方都会一起变
-
这个改动通常是"全局外观定义变化"
所以 UE 才强推:
-
Master Material -
Material Instance
因为大量场景需求其实只是:
-
换颜色
-
换 roughness
-
换 normal 强度
-
换贴图
-
换几个开关
这些都不该回去碰主 shader 图。
有些 Emitter 之间通过 Event 建立关联
不同 Emitter 的视觉结果在空间上重合了。
不是"一颗粒子自己同时长了两层系统"。
Ribbon_Trail_Leader
-
也生成一批自己的粒子
-
这些粒子会移动
-
同时发出
Location Event
RibbonTrailFollower
-
不直接像前两个那样普通 burst
-
它接收
Ribbon_Trail_Leader发出来的位置事件 -
然后生成 ribbon 的控制点/跟随粒子
-
最后用
Ribbon Renderer连成拖尾
Emitter A: 爆点粒子
Emitter B: 轨迹源粒子
Emitter C: 根据 B 的事件生成拖尾
第一类,只来自 OmnidirectionalBurst
-
只有 sprite 爆点
-
没有拖尾
-
看起来就是"一个效果"
来自 Ribbon_Trail_Leader 对应的那条链
-
你能看到 leader 本身的 sprite
-
同时 follower 生成了 ribbon 拖尾
-
两者叠在一起看,就像"一个粒子带两个效果"
UE 蓝图里标准写法
先拿到当前关卡正在运行的 GameMode 对象,再把它转成你预期的具体类型。
Get Game Mode
返回的是一个比较泛的引用,类型大概是:
GameModeBase/GameMode
这个泛类型只知道"它是个 GameMode",但不知道它是不是你自己写的:
-
BP_GM_Template -
GM_Singleplayer -
BP_FirstPersonGameMode
所以如果你想访问你自己加的东西,比如:
-
CurrentScore -
PlayerSpawnTransform -
SavePlayerData() -
StartWave()
就需要 Cast To GM_Singleplayer 这种操作。
-
Get Game Mode:拿到"某个游戏模式对象" -
Cast To GM_Singleplayer:确认"这个对象其实就是我这个具体类"
从别的蓝图访问自定义 GameMode 内容的标准方式。
第一,这不是"切换 GameMode"
很多初学者会误会。
Cast To 不会改变当前 GameMode,只是把已有对象按具体类型解释。
也就是:
-
当前关卡已经由
World Settings决定用了哪个 GameMode -
Get Game Mode拿到它 -
Cast只是为了访问它的自定义内容
只有当前关卡真的在用这个类时,Cast 才会成功
比如:
如果 World Settings -> GameMode Override 用的是:
GM_Singleplayer
那你 Cast To GM_Singleplayer 大概率成功。
如果当前关卡实际用的是:
BP_GM_Template
而你去 Cast To GM_Singleplayer
那就会失败。
GameMode 是规则层,不是角色层。
-
想拿规则/默认类/关卡流程 →
GameMode -
想拿当前玩家控制 →
PlayerController -
想拿当前角色 →
Get Player Character/Get Controlled Pawn -
想拿跨关卡全局 →
GameInstance -
想拿本局共享状态 →
GameState -
System Update管的是 System 级状态 -
每个
Emitter Update管的是 各自 Emitter 的状态 -
它们在同一个 Niagara System 里按调度顺序执行
-
不是"蓝色节点把右边每个 emitter 的 update 内容包办了"
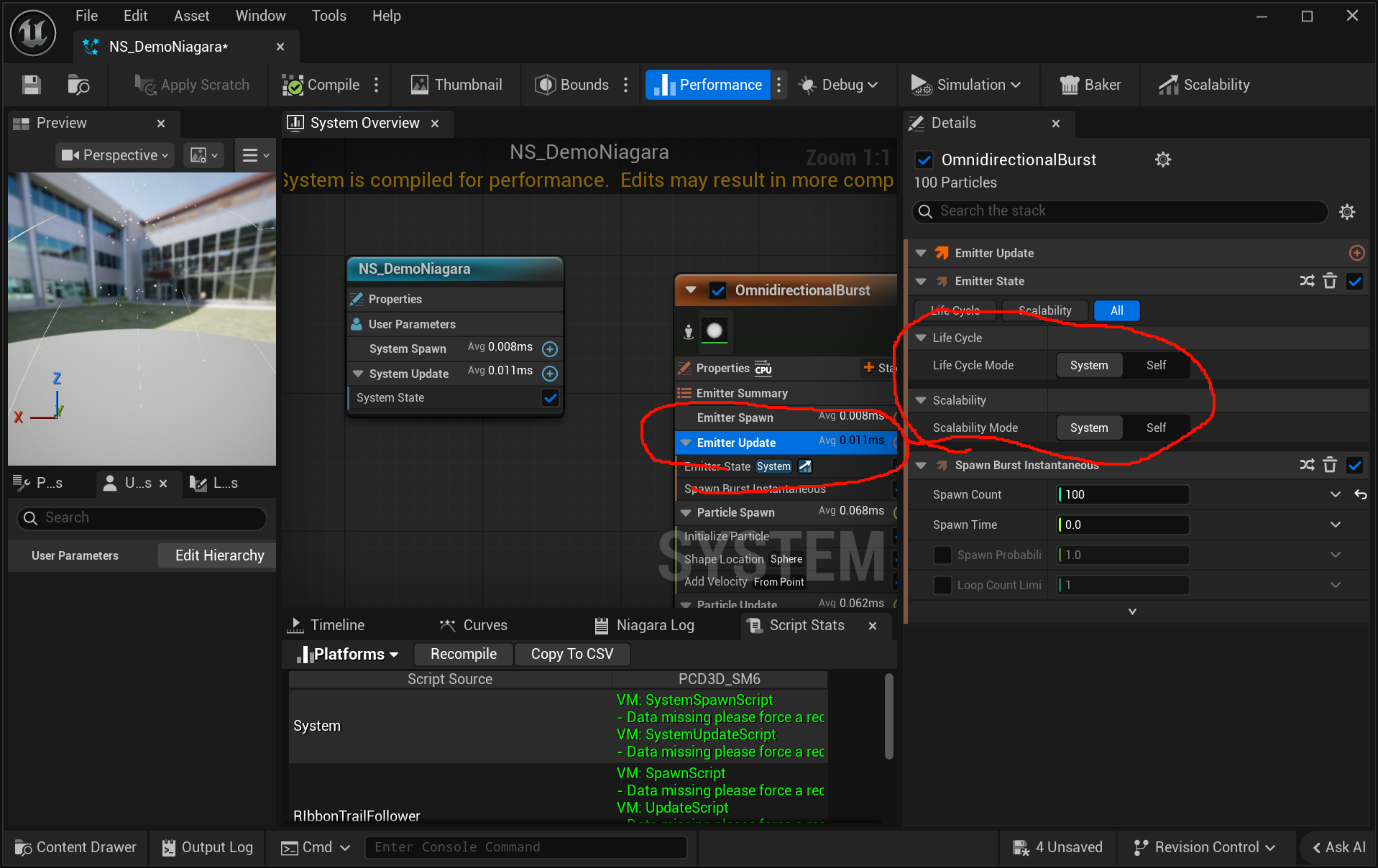
这里"管控"要拆成两层看。
第一层,生命周期/调度层面
System 会管。
比如你右侧这个:
Life Cycle Mode = System
这表示这个 emitter 的生命周期跟随 system。
也就是:
-
system 开始,它开始
-
system 循环,它跟着循环
-
system 停,它也停
这叫"调度/归属关系"。
模块带有明确的 Script Usage 限制 ,放错执行阶段就会直接 compile error。
某些模块只能在:
需要访问的是 每粒子数据 ,不是 system/emitter 级数据。模块内部会读写特定属性,Emitter Update 或 System Update,这些上下文里根本没有"当前粒子"这个概念
-
Particle Update:有"每个粒子"的上下文 -
Emitter Update:只有"这个 emitter 自己"的上下文
Niagara 的很多 Particle Update / Spawn 模块,最终都会被编译成 GPU 侧的 HLSL,尤其是在 GPU Sim 的 emitter 里。
如果这个 emitter 是 GPU 粒子,那么这些模块最后会落到 GPU compute/pass 里执行。
但 Niagara 和材质节点的核心差别在于执行语义不同:
-
材质节点
主要描述"一个像素/顶点怎么着色"。
-
Niagara 节点
主要描述"一个粒子在 Spawn / Update / Event / Simulation Stage 中怎么更新属性"。
也就是说,Niagara 更像"面向粒子状态更新的 DSL",而不是"面向表面着色的 DSL"。
- 某些模块会访问外部 GPU 资源,比如纹理、深度、GBuffer、distance field、grid
所以会出现很多"像 shader 一样"的节点,但它们的目标不是直接输出 Emissive Color 或 BaseColor,而是更新 Particles.* 属性。
播放一个 Sound Wave 资源,并把解码后的音频流输出到后面的混音或效果链。
前面选择一个音频资源,后面接 Mono Mixer,最后进 Output。也就是"一个声音源 -> 混音 -> 最终输出"。
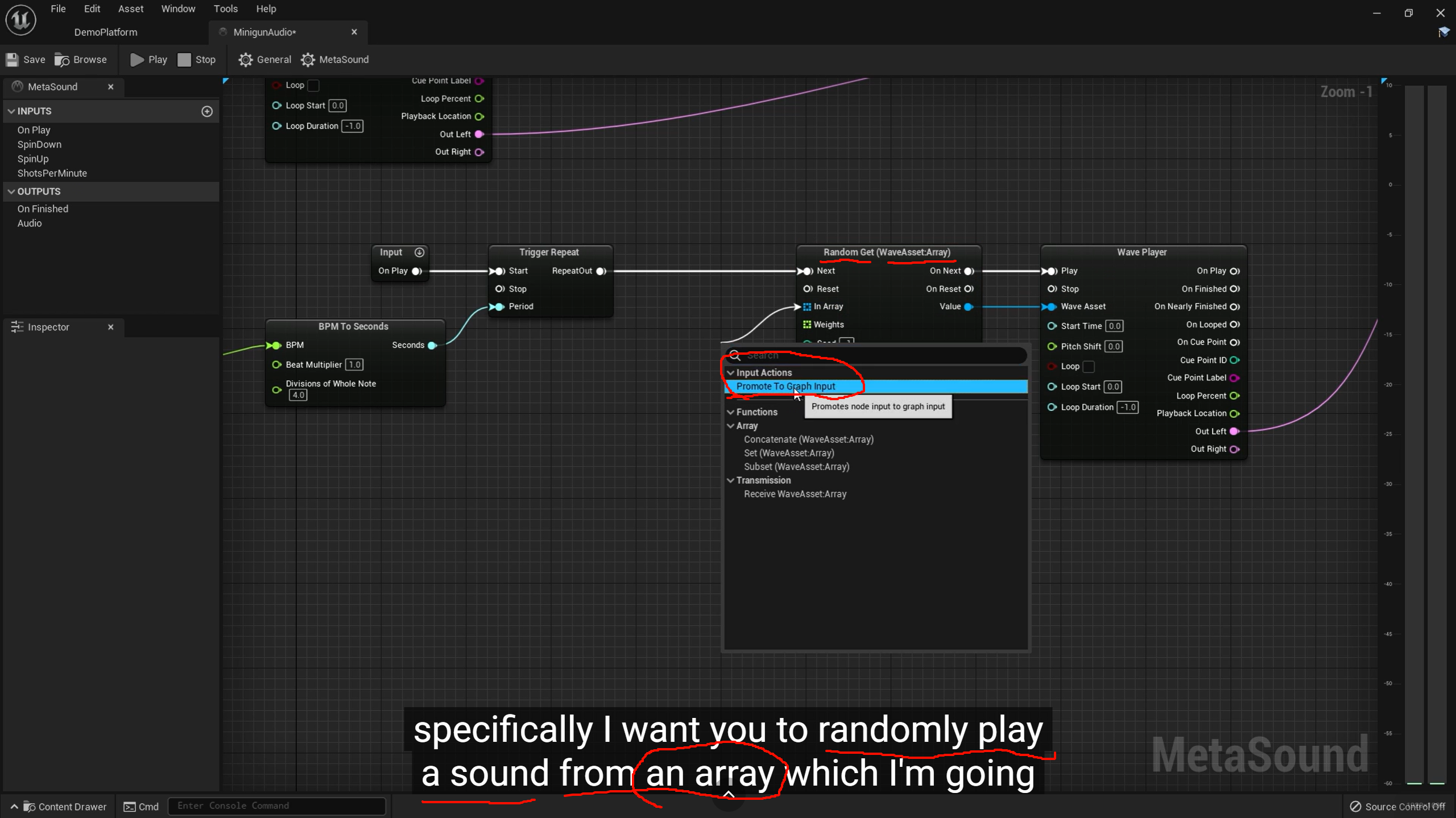
一层Random足以
这太神奇了,这个效果真的很好,总共只用了三个fire clip 就做的非常丰富了,Random的数值变化覆盖很广,这点很好用
这句话的意思是:
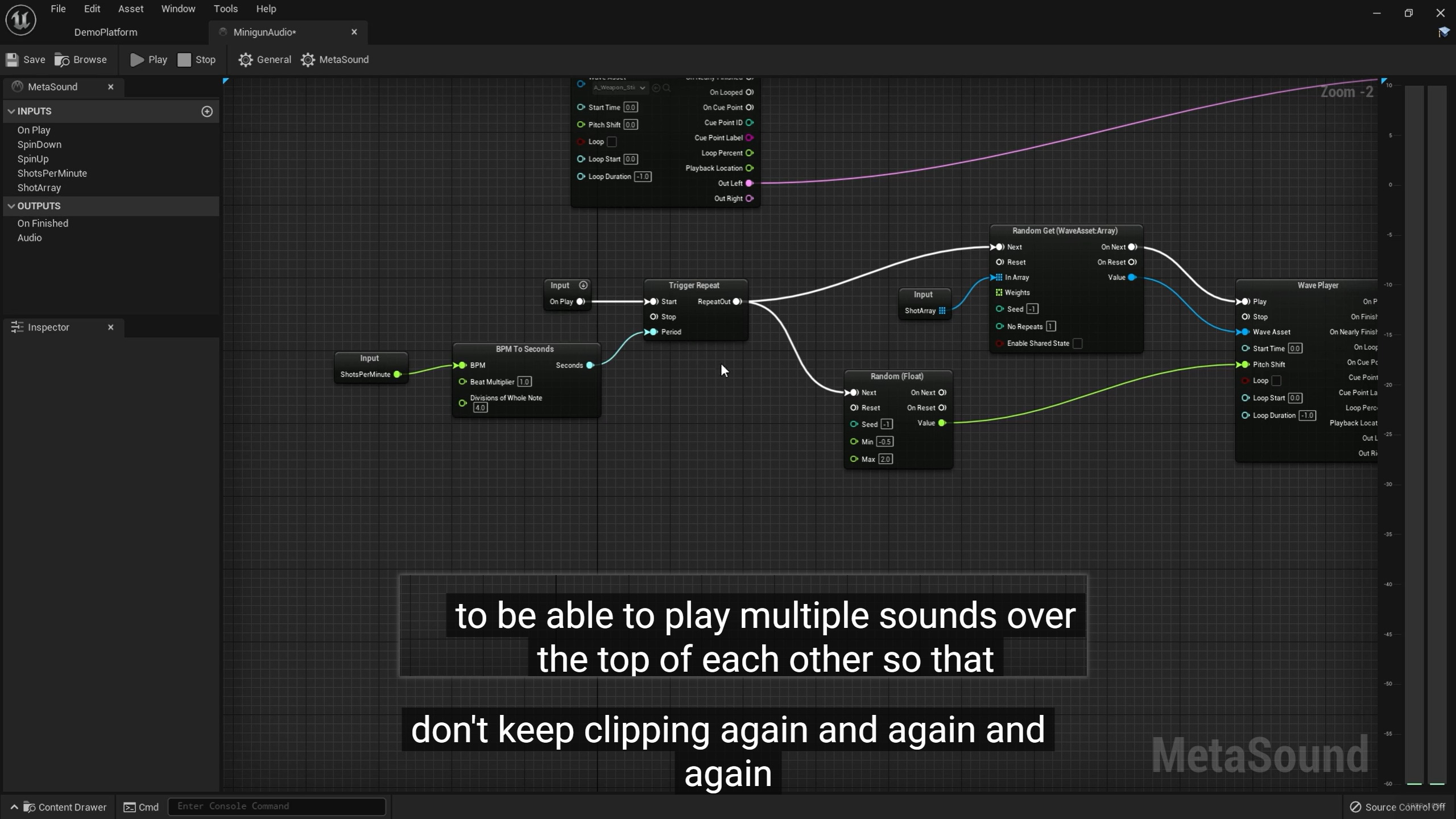
这里要让开火声音支持"重叠播放",而不是每次新开火都把上一次还没播完的声音硬切掉。
他说的 don't keep clipping again and again,这里的 clipping 不是严格指数字失真削波,而更像口语里的"被截断 / 被砍掉 / 被打断"。意思是:
如果武器射速很高,而你只用一个 Wave Player 播放 one-shot 枪声,那么下一发触发时,上一发声音可能还没放完,就被重新触发覆盖了。结果听感会变成:
-
声音尾巴一直被截断
-
每发都只听到前半截 transient
-
高频前端很密,但 body 和 tail 没了
-
连射会显得很假,很"机关式重复触发"
所以他要做的是:允许多发枪声在时间上叠加一点点。这样上一发还在衰减,下一发已经开始,听起来才会厚、连贯、真实。
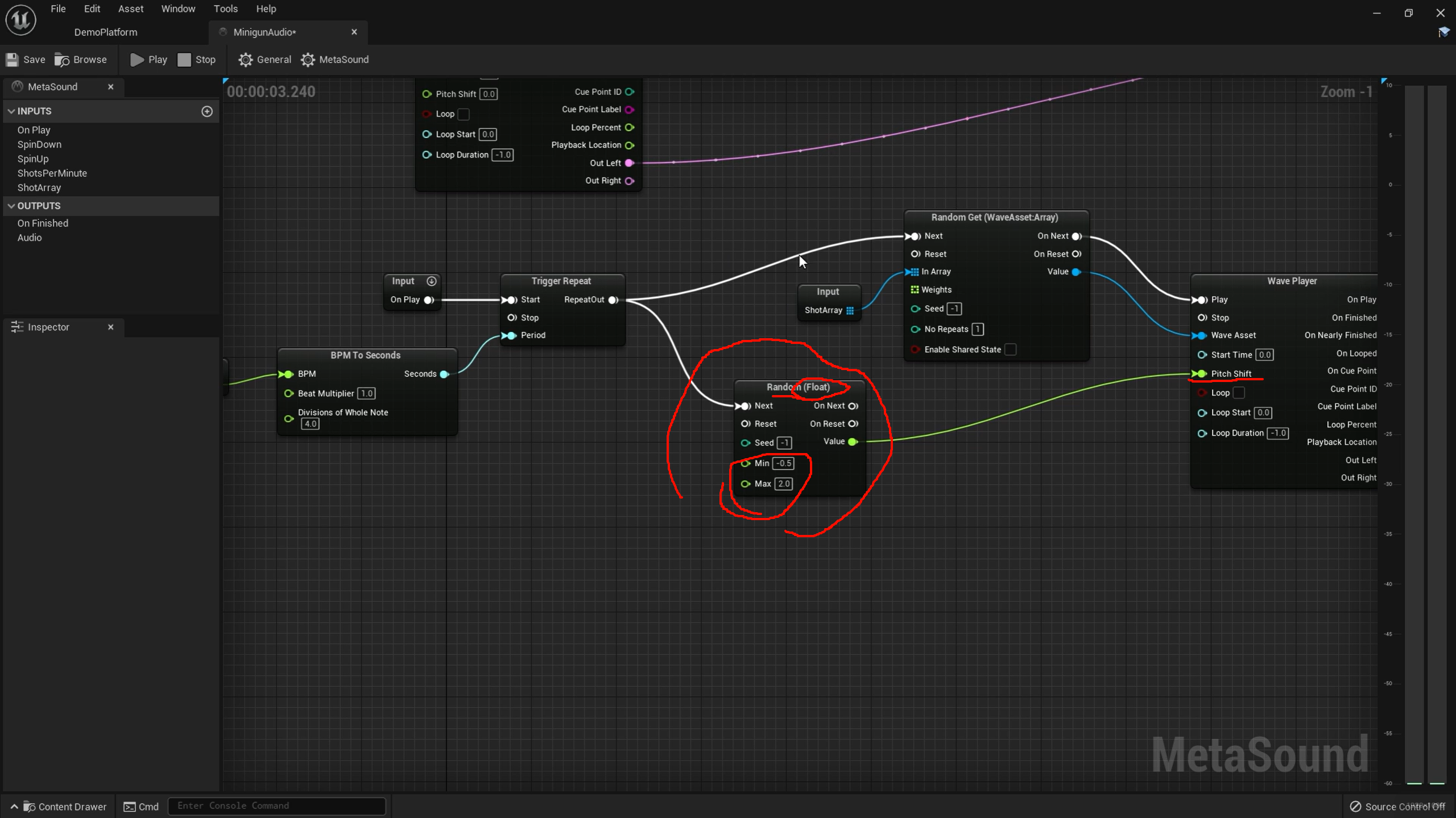
为什么Random float也有这么多插槽?
Next
这是最关键的触发输入。每来一次 trigger,它就生成一次新的随机 float。
Reset
把这个随机节点的内部状态重置。
如果它用了固定 seed,reset 后通常会回到同一套随机序列起点;
既有"数值流",也有"触发流",
"收到一次 Next 事件 -> 用当前 Seed/Min/Max 生成一个值 -> 输出 Value -> 再发 On Next 告诉后面可以继续了"
有 trigger,而不是每帧自动变?
因为你想要的这一发播放期间保持这个值不变。没有 Next 这种显式触发,随机值会在不该变的时候变,
AD Envelope (Audio) 就是一个包络发生器,
quare 波形 × 包络
也就是用这个包络去"塑形"方波的音量。这样声音就不会是生硬地瞬间开始、瞬间结束,而会有一个很短的起音和衰减,更像 pluck / beep / synth stab。
-
收到
Trigger -
包络从 0 开始上升,这段叫
Attack -
到达峰值后开始下降,这段叫
Decay -
输出一条 0 到 1 再回到 0 的曲线
-
这条曲线和原始音频相乘,最终得到有头有尾的声音
所以它不是"播放音频"的节点,而是"给音频包一个振幅外形"的节点。
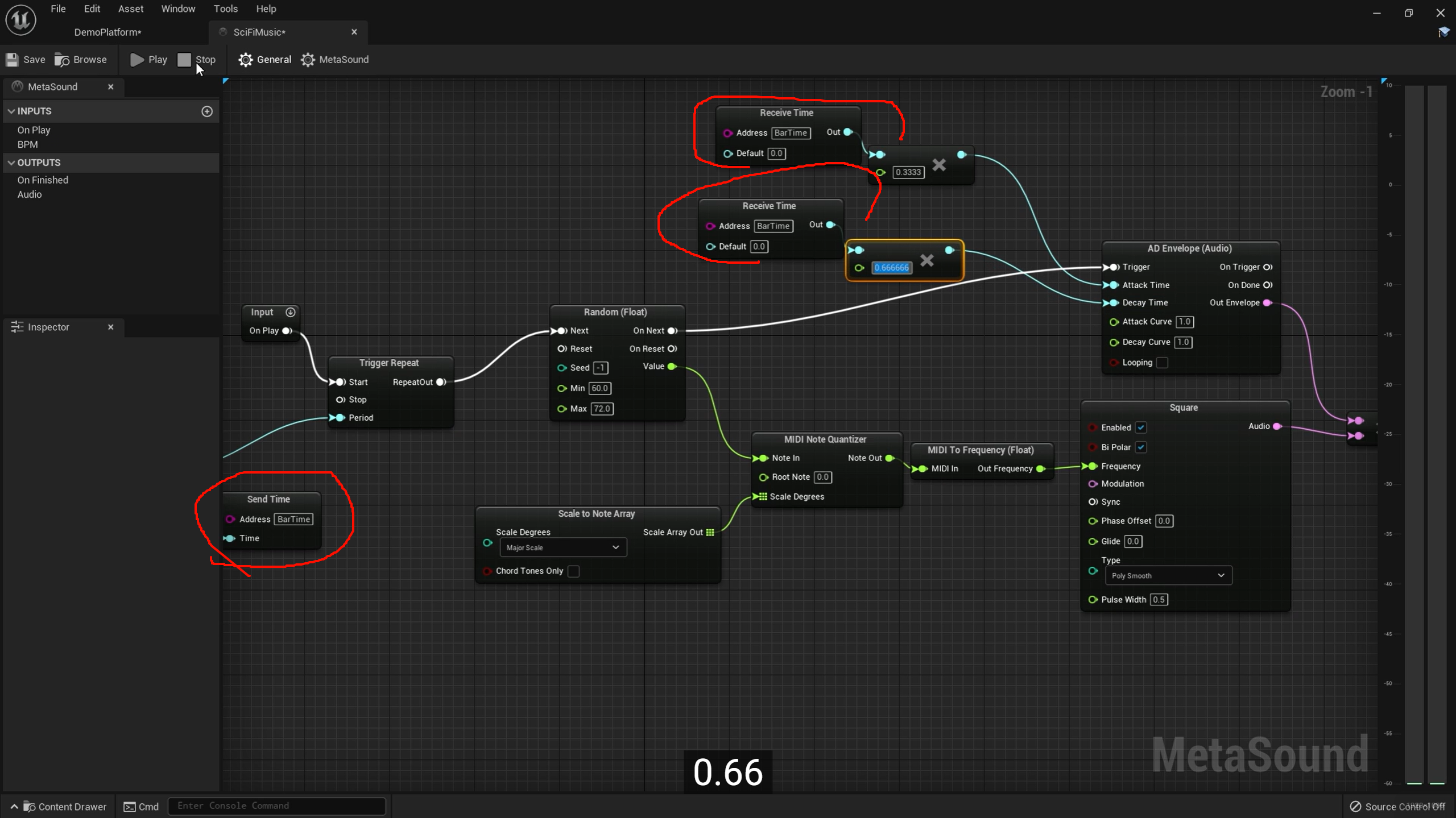
Time 类型的值在图里"隔空传递",不需要拉一根很长的线。
降低图布局耦合。
以后你把节点搬位置,或者中间再插别的逻辑,不用重新整理那种横跨半个画布的线。
表达"共享参数"的意图更强。
你一看到 Address = BarTime,就知道这几个地方在共享同一份时间基准。
再具体一点说你图里为什么用 Time 类型,而不是 Float。
因为 Attack Time、Decay Time 这些口本身就是时间语义。
MetaSound 里把时间单独做成类型,有两个好处:
-
语义明确:这是秒/时长,不是普通无单位 float
-
类型检查更清楚:接错类型时更容易发现
所以这里不是随便发一个数字,而是在发"一个时间长度"。
是在发"一个时间长度"。
在音乐领域中,
Envelope(包络、包络线) 是指声音在时间维度上音量、音色或音调的变化形态 。它描述了一个声音从发声、发展、持续到衰减的过程,通常被称为**ADSR(起音、衰减、延持、释放)**包络 。
A - Attack (起音)
D - Decay (衰减):
S - Sustain (延持):
R - Release (释放)

functional for experts, not well-shaped for usability.
ask ai,不用钱,f1对着当前的鼠标位置直接询问
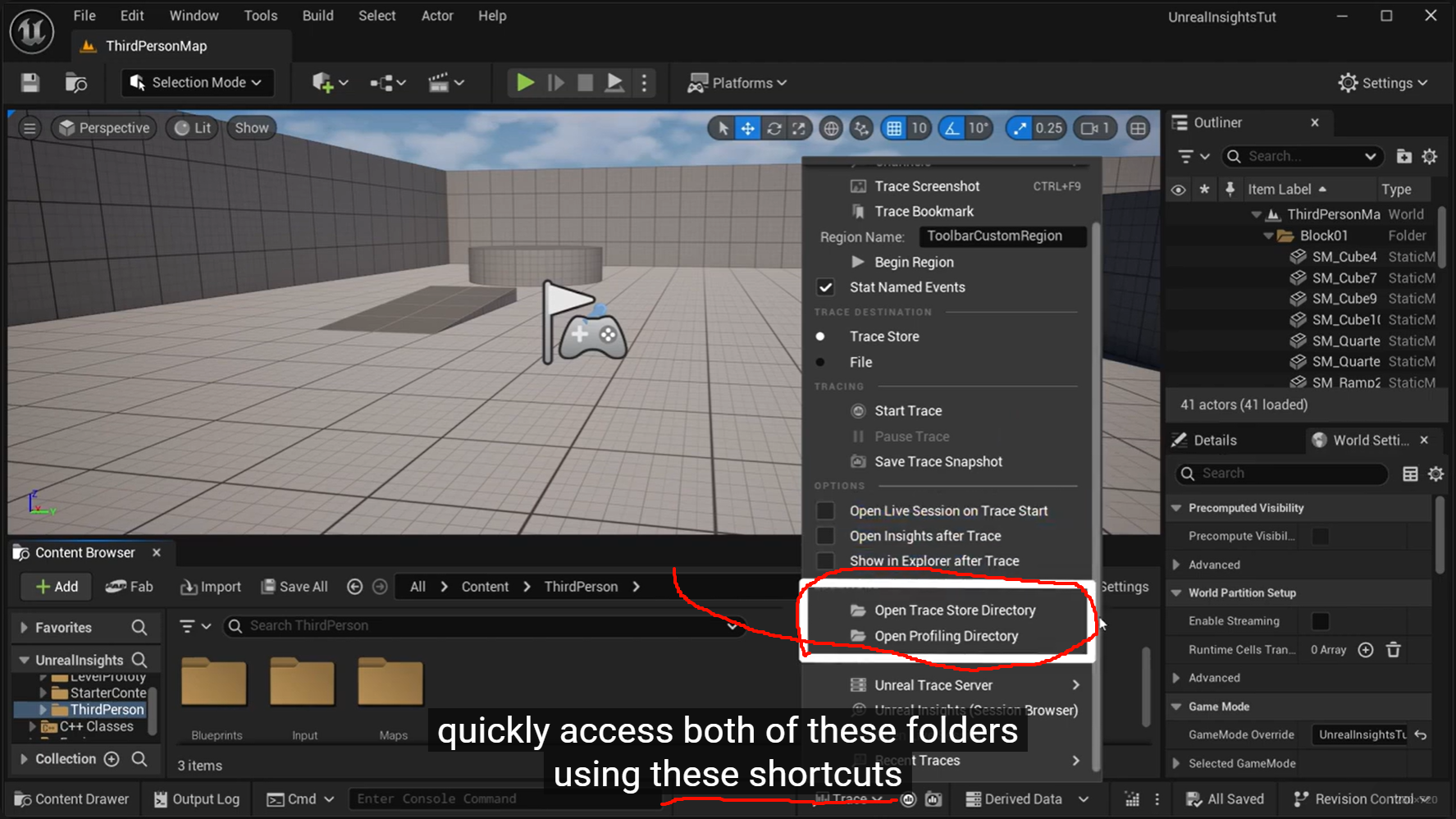
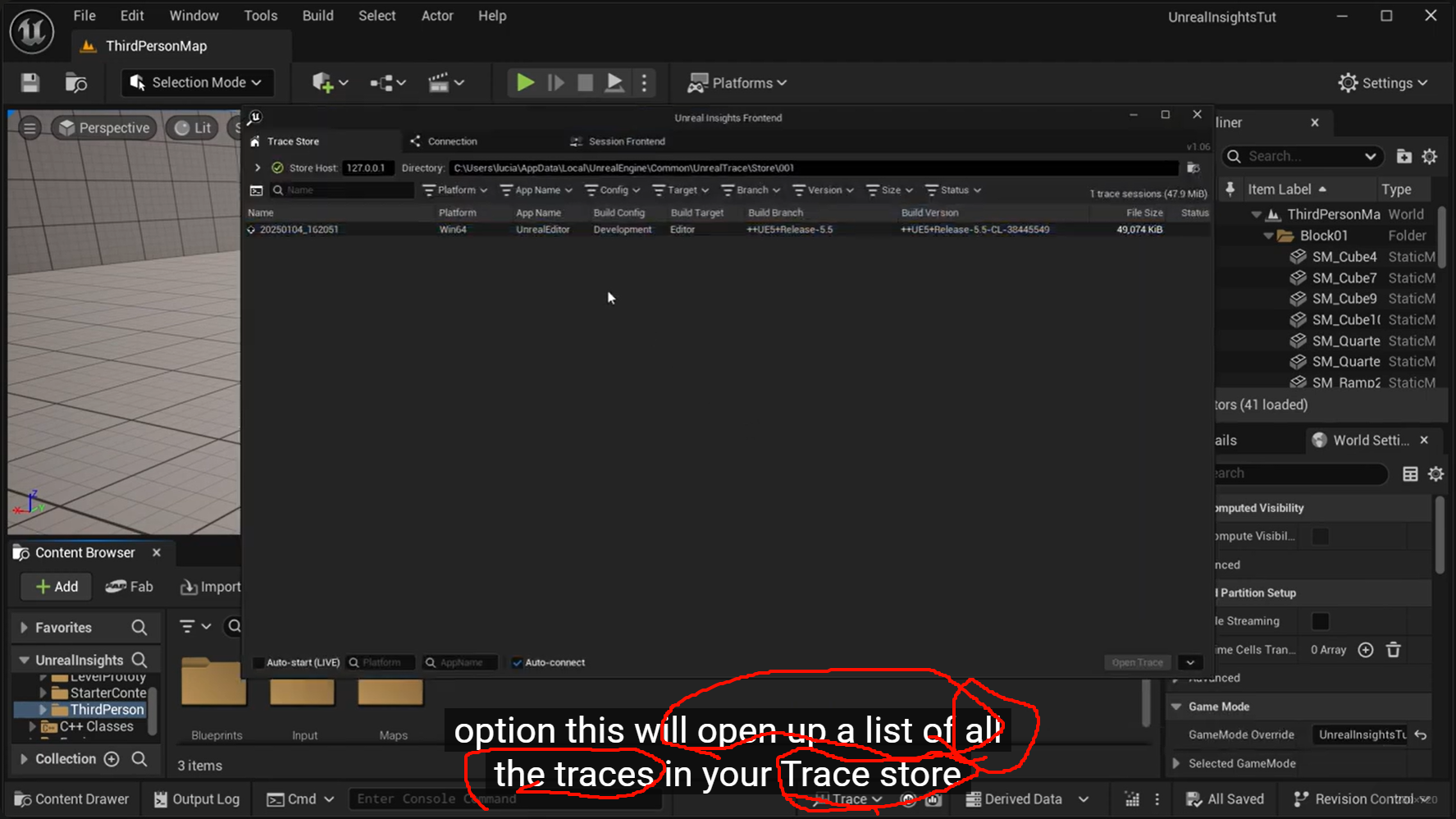
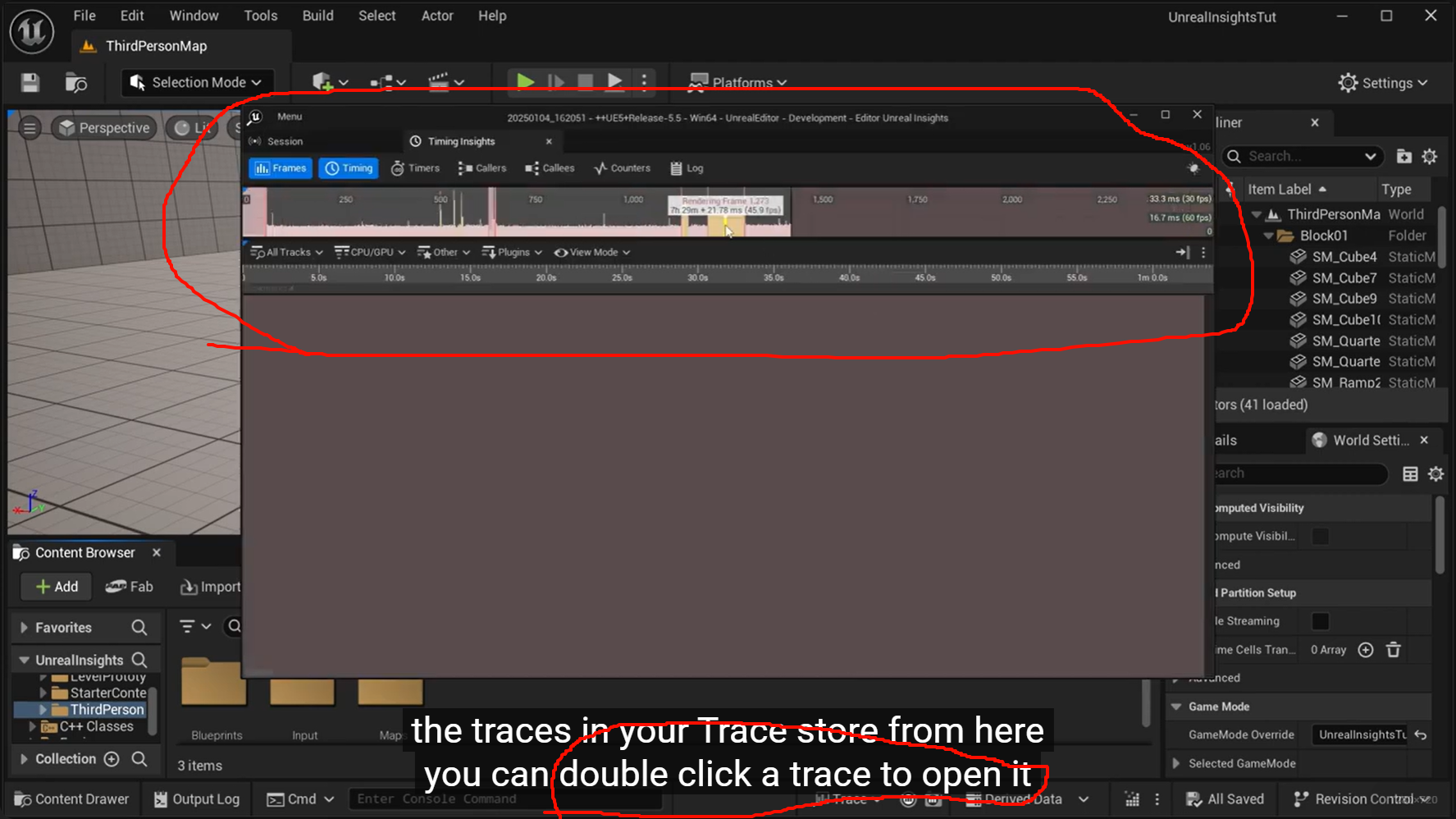
Trace Store = 面向 Insights 会话管理
File = 面向独立文件保存
快速开始/结束,
先用 Trace Store。
共享给同事、或者想明确控制输出位置,用 File 更合适。
profile
更偏统计视角,比如函数耗时占比、热点分布,强调 aggregate information
trace
更偏时间线视角,强调 event ordering、duration、cross-thread correlation、causality

Region
"一个命名的时间区间"
也就是你点了 Begin Region 以后,trace 里会插入一个"region start"事件,名字就是上面的 Region Name。后面结束时会有对应的 end event,于是 Insights 里就能把这段时间显示成一个带名字的区间。
在 5.7 文档里把 Timing Regions 描述为由 TRACE_BEGIN_REGION / TRACE_END_REGION 发出的长时事件;Blueprint API 里 Trace Mark Region Start 也明确是"为指定名称的 region 发出 begin event"。
Bookmark
更像"一个时刻的标记点"
Region
更像"从 A 到 B 的一段区间"
如果你当前没进 Play,通常测到的就是编辑器侧活动,也就是 editor session 的 trace。这里面会包含编辑器 UI、工具、viewport、asset/editor tick 等编辑器进程里的事件,而不是你期望的纯 gameplay runtime。
如果你在已经运行的游戏上下文里开始 trace,例如 PIE、Standalone、或者远端设备上的 game 进程,那采到的才会更接近你要的 gameplay 数据。官方的 quick start 和 on-device profiling 都把"运行项目后再采集"或"对 device 上运行的 game 进程采集"作为常见工作流。
没开 Play 就点 Start Trace
= 主要在录 editor
先进入 PIE / Standalone 再录
= 更接近录 game
想看最干净的游戏性能
= 优先 Standalone / 打包版 / 目标设备,少依赖编辑器内采集。社区里也经常用 standalone 加 trace 参数来避免 editor 噪音。
还有一个细节:即使你是"在游戏开始后才手动开启 trace",社区也有人观察到 trace 里可能仍会出现 Trace.Start 之前的一些数据,所以它不一定是一个绝对纯净、只从你点击那一刻开始的世界。
除了 MoE 这种按专家激活的稀疏计算外,再加一条"按记忆查表"的稀疏轴。
让模型在需要事实、短语模式、局部知识时,能更像"查到"而不是"现算"。这也是视频里会说成"fixed one of the biggest problems with AI"的原因。
第一,提出 Engram 作为条件记忆模块,现代化了 classic n-gram embedding 的思路;第二,提出 Sparsity Allocation ,分析神经计算和静态记忆之间的分配,并报告了一个 U-shaped scaling law ;第三,在论文摘要里声称把 Engram 扩到 27B parameters 后,在严格 iso-parameter、iso-FLOPs 的对比下,性能超过对应的 MoE baseline。
它把大模型的 memory / lookup 机制做成了一条独立的架构方向,试图突破'记忆和推理全混在一起、检索代价高'这个老问题。 不过要注意,相关论文和 GitHub 仓库公开时间是 2026 年 1 月,
3 月 24 日前后 DeepSeek-V3-0324 那波,那么那次更偏向 V3 的推理/编码能力增强与本地运行效率表现 ,和这里这个"memory breakthrough"不是同一件事。Venturebeat+2Simon Willison's Weblog+2
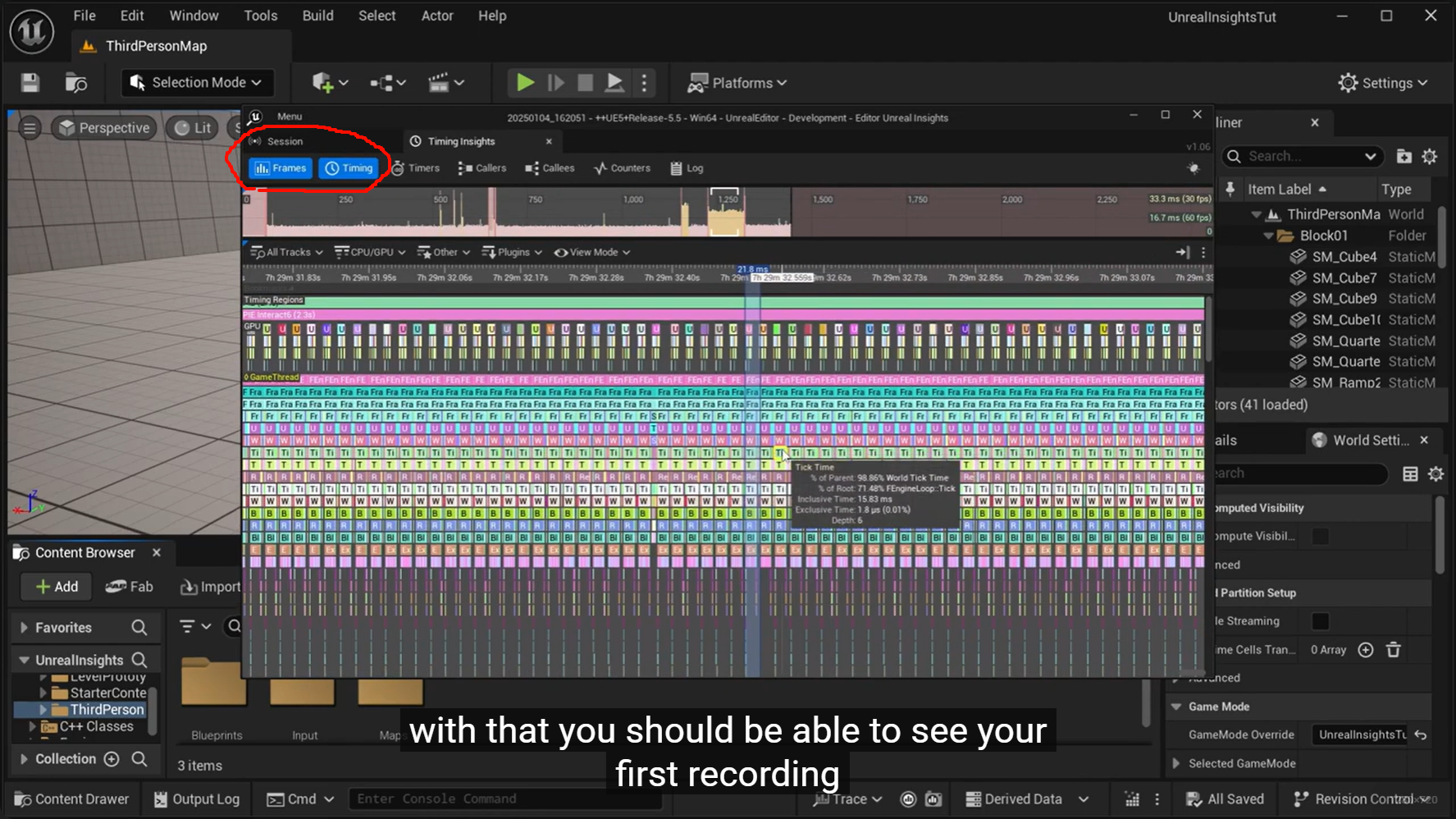
彩色块时间轴,本质上就是 Timing 视图。
Timers
这是对 Timing 里采集到的 timer/scope 做聚合统计。
Callers
看"谁调用了这个 timer"。
Callees
看"这个 timer 又调用了谁"。
日常粗定位时,通常只需要优先看这两个:
-
Timing -
Timers
常见工作流基本是:
-
先在
Timing找到卡顿帧/异常区间 -
再用
Timers看该区间热点排序
"这帧为什么慢",先盯 Timing。
已经知道"这段慢",但想回答"最贵的是谁",看 Timers。
已经知道"最贵的是它",但想回答"它为什么会被跑起来"或"它里面到底慢在哪",再进 Callers/Callees。
DeepSeek-V3-0324,那它在 3 月下旬被认为"突破"的东西,主要是这几类:
第一,是 V3 本体的推理能力明显上升 。DeepSeek 官方把它概括成 "major boost in reasoning performance",而 Hugging Face 模型页给了更具体的基准提升:例如 MMLU-Pro 从 75.9 到 81.2,GPQA 从 59.1 到 68.4,AIME 从 39.6 到 59.4,LiveCodeBench 从 39.2 到 49.2。也就是说,这次最核心不是换了一个全新架构名,而是 V3 这个 checkpoint 在 reasoning / math / code 上跳了一档 。DeepSeek API Docs+1
第二,是 前端代码生成和可执行性更强 。官方写的是 "Stronger front-end development skills",模型页进一步说得更具体:生成出来的代码可执行性更好,网页和 game front-end 也更美观。这个点在社区传播里很突出,因为它不是抽象 benchmark,而是很多人一试就能感到差别的那种提升。DeepSeek API Docs+1
第三,是 tool use / function calling 更稳 。官方直接写了 "Smarter tool-use capabilities",Hugging Face 页则写成 function calling accuracy 提升、修复了旧版 V3 的一些问题。换句话说,0324 的突破不只是"答题更强",也包括 更像一个能调工具、能按结构办事的 production model 。DeepSeek API Docs+1
第四,是 中文写作、改写、翻译这类非纯 benchmark 任务也有提升 。模型页提到中文中长文本写作、multi-turn interactive rewriting、translation、letter writing 这些都做了优化。这个不一定是英文社区最先强调的点,但从产品能力上看,0324 不是只补数学题分数。Hugging Face
还有一个当时很受关注但不属于"能力突破"本身的点:许可证变成了 MIT 。官方 API News 明确写了 models are now released under the MIT License;这让 0324 在开源生态里的可用性和传播性都更强。很多讨论热度其实是"能力提升 + 更宽松许可"叠加出来的。DeepSeek API Docs+1
所以更准确地总结:
DeepSeek-V3-0324 的"突破"不是提出了一个像 Engram 那样的新理论方向,
而是把 V3 这条 dense/MoE 实用模型线,往 reasoning、coding、front-end generation、tool use 这几个最敏感的实际能力上,明显推高了一截 。DeepSeek API Docs+1
如果你要一句更短、更贴近工程圈的说法,可以概括成:
0324 突破的是 V3 的实战可用性,不是范式。
尤其是推理、代码、前端生成、函数调用这几个落地面。DeepSeek API Docs+1
Timer (计时器 / 触发算子)
定义:一种物理实体或逻辑原语,用于对 Time 进行离散化采样并产生中断信号。
-
工程理性 (Frederick Brooks/工程实现) :Timer 是一个功能块,其核心逻辑是:当 Δt≥threshold 时,执行状态跃迁 σ。
-
控制论视角 (Ashby/Wiener):一种用于维持系统稳态或驱动周期性行为的反馈调节机制。它将连续的时间维度转化为离散的、可干预的事件触发源。
-
本质属性 :它是具象的工具,执行的是"量化时间并输出信号"的操作。
Timing (时序 / 同步约束)
定义:事件在时间轴上的相对位置关系及其协同性 (Synchronization)。
-
数字逻辑与工程 :指信号传播的约束条件,如建立时间 (Setup time) 与保持时间 (Hold time)。它关注的是信号到达的准时性而非持续性。
-
系统理论 :指子系统间交互的共时性约束。在分布式系统或复杂性科学中,Timing 决定了涌现 (Emergence) 是否发生。如果 Timing 失调,即便 Time 充足且 Timer 准确,系统仍会进入死锁或竞争状态 (Race Condition)。
-
语言哲学 (Wittgenstein):指向行为在特定语境下的"适切性",即逻辑命题在时间序列中生效的特定切片。
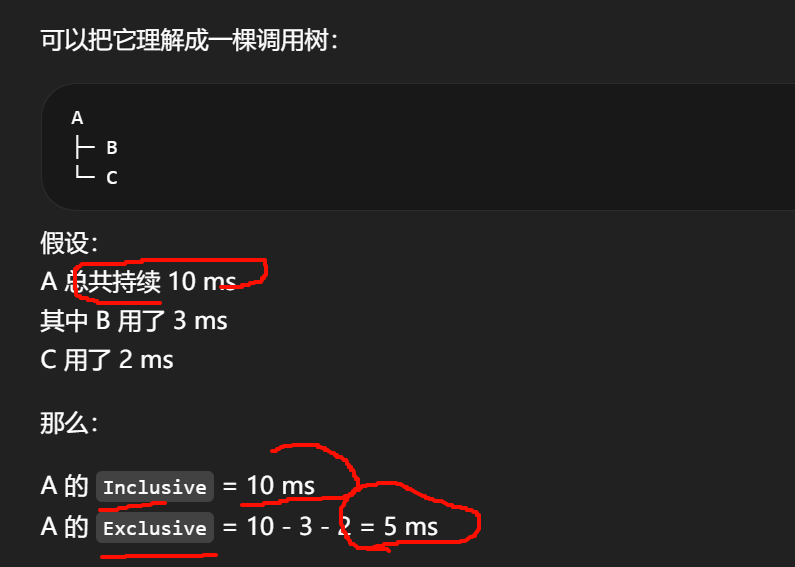
同名 timer 事件做累计、平均、最大值、调用次数、inclusive/exclusive 等汇总。
会明显受采样窗口长度影响。
Inclusive 和 Exclusive 是看一个 scope 的耗时时最核心的两个概念。