文章目录
-
- [1. 历史背景与开创性意义](#1. 历史背景与开创性意义)
-
- [1.1 传统方法的局限](#1.1 传统方法的局限)
- [1.2 FlowNet的突破(2015)](#1.2 FlowNet的突破(2015))
- [1.3 DispNet的贡献(2016)](#1.3 DispNet的贡献(2016))
- [2. 网络架构详解](#2. 网络架构详解)
-
- [2.1 总体架构:编码器-解码器 + 跳跃连接](#2.1 总体架构:编码器-解码器 + 跳跃连接)
- [2.2 编码器层规格](#2.2 编码器层规格)
- [2.3 解码器层规格](#2.3 解码器层规格)
- [2.4 跳跃连接机制](#2.4 跳跃连接机制)
- [3. 两种架构变体](#3. 两种架构变体)
-
- [3.1 DispNet (DispNetSimple)](#3.1 DispNet (DispNetSimple))
- [3.2 DispNetCorr (带相关层)](#3.2 DispNetCorr (带相关层))
- [4. 相比FlowNet的改进](#4. 相比FlowNet的改进)
-
- [4.1 解码器中增加卷积层](#4.1 解码器中增加卷积层)
- [4.2 1D相关替代2D相关](#4.2 1D相关替代2D相关)
- [4.3 多尺度损失权重调度](#4.3 多尺度损失权重调度)
- [5. 核心思想总结](#5. 核心思想总结)
立体匹配端到端神经网络的开创者,在flownet基础上把2D预测改成1D预测,基本上与flownet架构保持了一致,采用编码解码结构,这一点和初期语义分割网络差不多,编码是为了获取更加抽象的featuremap,解码上采样是为了恢复每个像素的属性。
《FlowNet: Learning Optical Flow with Convolutional Networks》
Dispnet:
《A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation》
1. 历史背景与开创性意义
1.1 传统方法的局限
在DispNet出现之前,视差估计主要依赖传统流水线:
左右图像 → 特征提取 → 代价计算 → 代价聚合 → 视差优化 → 后处理代表方法:
| 方法 | 特点 | 速度 |
|---|---|---|
| SGM (半全局匹配) | 手工设计的匹配代价 + 半全局优化 | ~1.1秒/帧 |
| MC-CNN (Žbontar & LeCun) | CNN做patch级匹配代价,仍需交叉代价聚合+SGM后处理 | ~67秒/帧 |
关键问题: 这些方法都不是端到端的------CNN仅负责局部特征匹配,视差的全局估计仍依赖手工设计的后处理流程。
1.2 FlowNet的突破(2015)
FlowNet 首次证明:密集像素级对应关系(光流)可以用单个CNN端到端学习。
核心思想:
- 用编码器-解码器架构替代整个传统流水线
- 编码器逐步缩小特征图、增大感受野,学习多尺度抽象特征
- 解码器通过上卷积逐步恢复分辨率,输出密集光流场
- 跳跃连接将编码器的细节信息传递给解码器
1.3 DispNet的贡献(2016)
DispNet 将FlowNet的思想从光流迁移到视差估计,是首个端到端CNN视差估计网络:
- ✅ 速度快约1000倍(0.06s vs MC-CNN的67s)
- ✅ 精度接近当时SOTA(KITTI 2015排名第二)
- ✅ 证明了合成数据(FlyingThings3D)可以有效训练视差网络
2. 网络架构详解
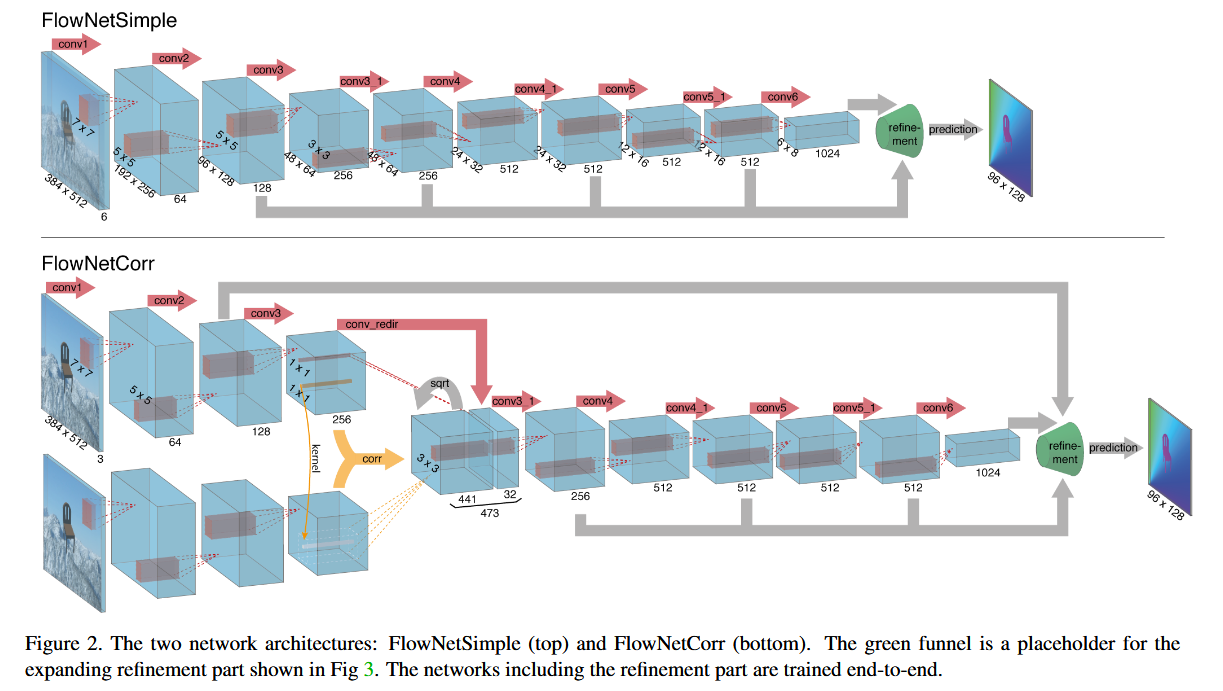
flownet编码器
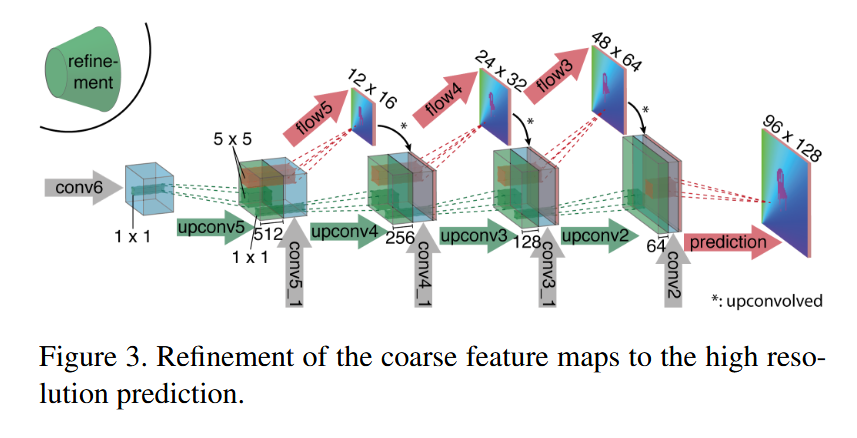
flownet 解码器
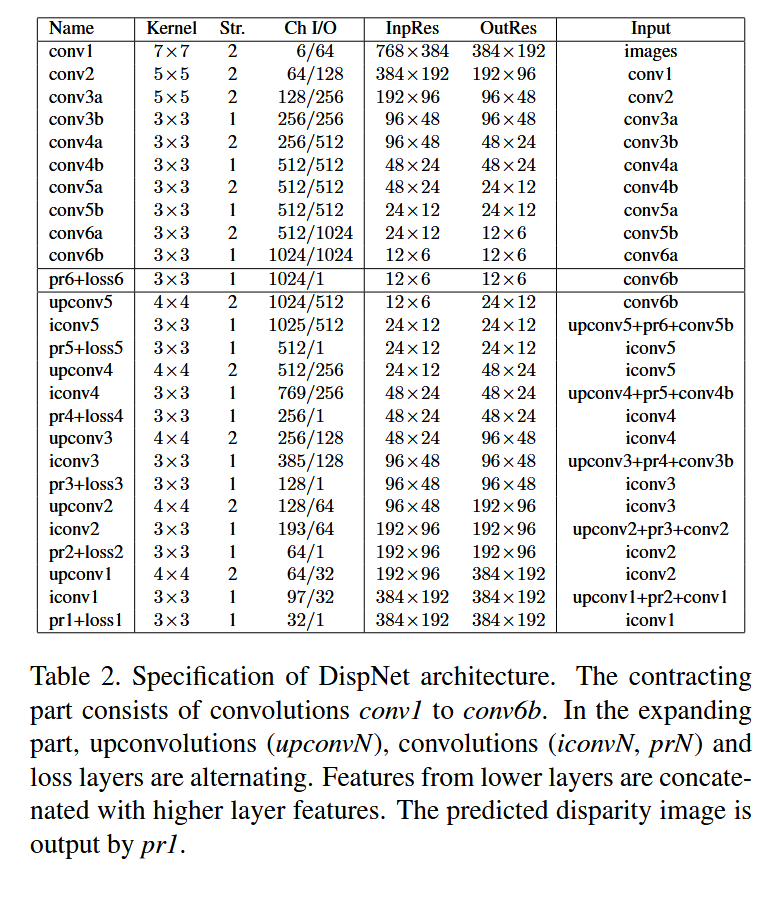
dispnet网络结构
2.1 总体架构:编码器-解码器 + 跳跃连接
输入图像对 (左, 右)
│
▼
┌─────────────────────────────────────────┐
│ 编码器(收缩部分) │
│ conv1 → conv2 → conv3a/b → conv4a/b │
│ → conv5a/b → conv6a/b │
│ 总下采样因子: 64x │
│ 感受野逐层增大,提取多尺度抽象特征 │
└──────────────┬──────────────────────────┘
│
▼
┌─────────────────────────────────────────┐
│ 解码器(扩展部分) │
│ upconv6 + iconv6 → upconv5 + iconv5 │
│ → upconv4 + iconv4 → upconv3 + iconv3 │
│ → upconv2 + iconv2 → upconv1 + iconv1 │
│ 逐步上采样恢复分辨率 │
│ 每级与编码器对应层做跳跃连接(拼接) │
└──────────────┬──────────────────────────┘
│
▼
pr1: 最终视差预测
(分辨率为输入的 1/2)关键设计原则: 没有信息瓶颈------即使中间特征图很小,信息也可以通过跳跃连接从编码器直接传到解码器对应层级。
2.2 编码器层规格
| 层名 | 核大小 | Stride | 通道数 (输入/输出) | 输入分辨率 | 输出分辨率 | 说明 |
|---|---|---|---|---|---|---|
| conv1 | 7×7 | 2 | 6/64 | 768×384 | 384×192 | 输入为左右图拼接(6通道) |
| conv2 | 5×5 | 2 | 64/128 | 384×192 | 192×96 | |
| conv3a | 5×5 | 2 | 128/256 | 192×96 | 96×48 | |
| conv3b | 3×3 | 1 | 256/256 | 96×48 | 96×48 | 不降采样 |
| conv4a | 3×3 | 2 | 256/512 | 96×48 | 48×24 | |
| conv4b | 3×3 | 1 | 512/512 | 48×24 | 48×24 | |
| conv5a | 3×3 | 2 | 512/512 | 48×24 | 24×12 | |
| conv5b | 3×3 | 1 | 512/512 | 24×12 | 24×12 | |
| conv6a | 3×3 | 2 | 512/1024 | 24×12 | 12×6 | |
| conv6b | 3×3 | 1 | 1024/1024 | 12×6 | 12×6 | 最深层 |
注:
- 分辨率以输入768×384为例
- 每个卷积层后跟ReLU激活
- 卷积核从7×7 → 5×5 → 3×3逐渐缩小
- 通道数逐层翻倍至1024
2.3 解码器层规格
解码器每一级的结构为:上卷积(upconv) → 拼接(跳跃连接+上一级预测) → 卷积(iconv)
| 层名 | 核大小 | Stride | 通道数 (输入/输出) | 输入分辨率 | 输出分辨率 | 说明 |
|---|---|---|---|---|---|---|
| pr6+loss6 | 3×3 | 1 | 1024/1 | 12×6 | 12×6 | 最粗预测 |
| upconv5 | 4×4 | 2 | 1024/512 | 12×6 | 24×12 | |
| iconv5 | 3×3 | 1 | 1025/512 | 24×12 | 24×12 | 拼接: upconv5 + conv5b + pr6上采样 |
| pr5+loss5 | 3×3 | 1 | 512/1 | 24×12 | 24×12 | |
| upconv4 | 4×4 | 2 | 512/256 | 24×12 | 48×24 | |
| iconv4 | 3×3 | 1 | 769/256 | 48×24 | 48×24 | |
| pr4+loss4 | 3×3 | 1 | 256/1 | 48×24 | 48×24 | |
| upconv3 | 4×4 | 2 | 256/128 | 48×24 | 96×48 | |
| iconv3 | 3×3 | 1 | 385/128 | 96×48 | 96×48 | |
| pr3+loss3 | 3×3 | 1 | 128/1 | 96×48 | 96×48 | |
| upconv2 | 4×4 | 2 | 128/64 | 96×48 | 192×96 | |
| iconv2 | 3×3 | 1 | 193/64 | 192×96 | 192×96 | |
| pr2+loss2 | 3×3 | 1 | 64/1 | 192×96 | 192×96 | |
| upconv1 | 4×4 | 2 | 64/32 | 192×96 | 384×192 | |
| iconv1 | 3×3 | 1 | 97/32 | 384×192 | 384×192 | |
| pr1+loss1 | 3×3 | 1 | 32/1 | 384×192 | 384×192 | 最终预测 |
说明: 解码器的每一层拼接三部分:上卷积结果 + 编码器对应层特征 + 上一级视差预测的上采样。最终输出pr1的分辨率为输入的1/2。
2.4 跳跃连接机制
编码器 解码器
conv6b ──────────────→ (直接输入解码器起始)
conv5b ──── 拼接 ────→ iconv5 (与 upconv5 输出拼接)
conv4b ──── 拼接 ────→ iconv4
conv3b ──── 拼接 ────→ iconv3
conv2 ──── 拼接 ────→ iconv2
conv1 ──── 拼接 ────→ iconv1作用: 编码器低层保留了空间细节(边缘、纹理),解码器高层提供语义理解。拼接后让网络在每个尺度都能同时利用细节和语义信息。
3. 两种架构变体
3.1 DispNet (DispNetSimple)
文中着重体现了DispNetSimple。
左图 ──┐
├── 拼接为 6 通道 → 编码器 → 解码器 → 视差图
右图 ──┘特点:
- 两张图像直接在通道维度拼接,送入统一的编码器
- 网络自行学习如何从拼接输入中提取匹配信息
- 架构简单,但需要网络自己"发现"左右图的对应关系
3.2 DispNetCorr (带相关层)
文中提了一句DispNetCorr ,这是根据flownet推测的。
左图 → conv1 → conv2 ──→ 特征图 f_L ──┐
├── 1D 相关层 → 拼接 → 后续编码器
右图 → conv1 → conv2 ──→ 特征图 f_R ──┘ → 解码器
(共享权重) → 视差图特点:
- 两张图像分别通过共享权重的conv1、conv2提取特征
- 在特征图上执行1D水平相关(因为极线校正后视差只在水平方向)
- 相关层无可学习参数,是纯粹的模板匹配操作
1D相关层的数学定义:
给定特征图 f 1 f_1 f1和 f 2 f_2 f2,位置 x 1 x_1 x1和 x 2 x_2 x2之间的相关值为:
c ( x 1 , x 2 ) = ∑ o ∈ − k , k ⟨ f 1 ( x 1 + o ) , f 2 ( x 2 + o ) ⟩ c(x_1, x_2) = \sum_{o \in -k, k} \langle f_1(x_1 + o), f_2(x_2 + o) \rangle c(x1,x2)=o∈−k,k∑⟨f1(x1+o),f2(x2+o)⟩
其中 K = 2 k + 1 K = 2k+1 K=2k+1是块大小。本质上是两个特征块的内积(余弦相似度的非归一化版本)。
DispNet 1D相关 vs FlowNet 2D相关:
| 特性 | FlowNet (2D相关) | DispNet (1D相关) |
|---|---|---|
| 搜索方向 | 水平 + 垂直 | 仅水平 |
| 搜索范围 | 最大位移 d=20, stride=2 | 最大位移 d=40, stride=1 |
| 对应输入像素 | ±40 像素 (因stride=2) | ±160 像素 (conv2后4x下采样) |
| 计算量 | O ( w × h × D 2 ) O(w \times h \times D^2) O(w×h×D2) | O ( w × h × D ) O(w \times h \times D) O(w×h×D) |
| 输出大小 | w × h × ( 2 D + 1 ) 2 w \times h \times (2D+1)^2 w×h×(2D+1)2 | w × h × ( 2 D + 1 ) w \times h \times (2D+1) w×h×(2D+1) |
结论: DispNet利用了视差估计的1D特性,以更低的计算代价覆盖了更大的位移范围和更精细的采样。
4. 相比FlowNet的改进
4.1 解码器中增加卷积层
| 方法 | 解码器结构 | 效果 |
|---|---|---|
| FlowNet | upconv → 拼接 → (直接到下一级) | 基准 |
| DispNet | upconv → 拼接 → iconv(额外卷积) → (到下一级) | KITTI 2015 上EPE相对下降约15% |
分析: 额外的卷积层让网络能更好地正则化视差预测,减少噪声和伪影,生成更平滑的视差图。
4.2 1D相关替代2D相关
- 视差只存在于水平方向(极线约束),因此1D相关即可
- 计算量从 O ( D 2 ) O(D^2) O(D2)降到 O ( D ) O(D) O(D)
- 同时覆盖更大位移范围
4.3 多尺度损失权重调度
FlowNet的训练方式: 所有层的损失同时激活
DispNet的训练方式: 采用渐进式损失调度
阶段 1: 只激活 loss6(最粗分辨率 12×6)
其他loss权重为0
↓
阶段 2: 逐步激活 loss5, loss4, ...
↓
阶段 3: 激活 loss1(最细分辨率)
停用低分辨率损失原理:
- 由于跳跃连接的存在,如果所有损失同时激活,底层会收到来自多个尺度的混合梯度
- 渐进式调度让网络先学习粗略结构,再逐步精细化
- 类似于课程学习(curriculum learning)的思想
5. 核心思想总结
| 方面 | 要点 |
|---|---|
| 核心创新 | 首次将端到端CNN应用于视差估计,替代传统多阶段流水线 |
| 架构基础 | 编码器-解码器 + 跳跃连接(继承自FlowNet) |
| 关键改进 | 1D相关层、解码器额外卷积、渐进式损失调度 |
| 速度优势 | 比当时SOTA快约1000倍(0.06s/帧) |
| 训练数据 | 合成数据(FlyingThings3D)足以训练出泛化性好的网络 |
| 局限性 | 最终输出仍为1/4分辨率;微调后泛化能力下降;边缘处不够锐利 |
| 历史地位 | 端到端视差估计的开创者,后续所有深度学习视差方法的基础 |