文章导读
本文将从零开始,带你彻底掌握TF-IDF算法的原理与应用。内容分为三个部分:
- 基础篇:通过简单代码讲解TF-IDF的核心概念
- 实战篇:完整实现《红楼梦》120回的关键词提取
- 可视化篇:利用大模型快速生成交互式HTML页面
第一部分:TF-IDF基础篇
一、什么是TF-IDF?
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。它的核心思想是:
一个词在一篇文档中出现的频率越高,且在其他文档中出现的频率越低,则该词越能代表这篇文档的特征。
1. 通俗理解
想象你在读一本《红楼梦》:
- "宝玉"这个词在第27回(黛玉葬花)中出现了很多次,但在其他回目中相对较少 → 重要关键词
- "的"这个词在每一回都出现无数次 → 不重要(停用词)
- "红楼梦"这个书名在书中反而出现很少 → 也不能代表具体某回
TF-IDF正是用数学方式量化这种直觉。
2. 数学公式
TF-IDF(t,d) = TF(t,d) × IDF(t)
词频 TF(Term Frequency) :
TF(t,d) = 词t在文档d中出现的次数 / 文档d的总词数
逆文档频率 IDF(Inverse Document Frequency) :
IDF(t) = log( 总文档数N / (包含词t的文档数 + 1) )
为什么要+1?防止分母为0(当某个词在所有文档中都没出现时)。
3. 计算示例
假设有100回《红楼梦》:
- "宝玉"在80回中出现过,IDF = log(100/80) = 0.223
- "黛玉"在30回中出现过,IDF = log(100/30) = 0.523
某回中:
- "宝玉"出现10次,该回总词数200 → TF=0.05 → TF-IDF=0.05×0.223=0.01115
- "黛玉"出现5次,TF=0.025 → TF-IDF=0.025×0.523=0.01308(更高!)
二、简单代码演示
1. 入门示例
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 1. 准备语料(三篇简单文档)
corpus = [
'I love coding in Python', # 文档1
'Python is a great language', # 文档2
'I love machine learning' # 文档3
]
# 2. 创建TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 3. 计算TF-IDF矩阵
tfidf = vectorizer.fit_transform(corpus)
# 4. 获取词表
wordlist = vectorizer.get_feature_names_out()
print(f"词表:{wordlist}")
print(f"矩阵形状:{tfidf.shape}(3篇文档 × {len(wordlist)}个词)")
# 5. 转换为DataFrame查看
df = pd.DataFrame(tfidf.toarray(), columns=wordlist, index=['文档1', '文档2', '文档3'])
print("\nTF-IDF矩阵:")
print(df.round(4))运行结果:
词表:['coding' 'great' 'in' 'is' 'language' 'learning' 'love' 'machine' 'python']
矩阵形状:(3, 9)(3篇文档 × 9个词)
TF-IDF矩阵:
coding great in is language learning love machine python
文档1 0.5175 0.0000 0.4352 0.0000 0.0000 0.0000 0.4352 0.0000 0.5175
文档2 0.0000 0.5175 0.0000 0.4352 0.5175 0.0000 0.0000 0.0000 0.5175
文档3 0.0000 0.0000 0.0000 0.0000 0.0000 0.5175 0.4352 0.5175 0.00002. 代码解读
| 代码 | 作用 |
|---|---|
TfidfVectorizer() |
创建TF-IDF计算器 |
fit_transform(corpus) |
拟合语料并转换为TF-IDF矩阵 |
get_feature_names_out() |
获取所有特征词(词表) |
toarray() |
将稀疏矩阵转为密集矩阵便于查看 |
3. 红楼梦简化示例
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 前三回简化内容
corpus = [
"甄士隐梦幻识通灵 贾雨村风尘怀闺秀", # 第一回
"贾夫人仙逝扬州城 冷子兴演说荣国府", # 第二回
"托内兄如海荐西宾 接外孙贾母惜孤女" # 第三回
]
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
wordlist = vectorizer.get_feature_names_out()
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 提取每篇文档的Top5关键词
for j in range(len(corpus)):
featurelist = df.iloc[:, j].to_list()
word_weight = dict(zip(wordlist, featurelist))
sorted_words = sorted(word_weight.items(), key=lambda x: x[1], reverse=True)
print(f"\n第{j+1}回的Top5关键词:")
for word, score in sorted_words[:5]:
print(f" {word}: {score:.4f}")运行结果:
第1回的Top5关键词:
甄士隐: 0.4472
梦幻: 0.4472
闺秀: 0.4472
风尘: 0.4472
通灵: 0.4472
第2回的Top5关键词:
冷子兴: 0.4472
演说: 0.4472
仙逝: 0.4472
扬州: 0.4472
荣国府: 0.4472
第3回的Top5关键词:
托内兄: 0.4082
如海: 0.4082
惜孤女: 0.4082
接外孙: 0.4082
贾母: 0.4082三、TfidfVectorizer核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
max_features |
int | None | 最大特征数,保留最重要的N个词 |
min_df |
float或int | 1 | 忽略出现次数低于此值的词 |
max_df |
float或int | 1.0 | 忽略出现次数高于此值的词 |
ngram_range |
tuple | (1,1) | n-gram范围,如(1,2)包含单个词和两词组合 |
stop_words |
list或str | None | 停用词列表或内置停用词 |
python
# 示例:只保留重要特征
vectorizer = TfidfVectorizer(
max_features=5000, # 只保留5000个最重要的词
min_df=2, # 至少在2篇文档中出现
max_df=0.8, # 最多在80%文档中出现
ngram_range=(1,2) # 包含单个词和双词组合
)第二部分:红楼梦实战篇
四、项目完整代码
1. 项目文件结构
红楼梦TFIDF项目/
├── 分卷/ # 原始文本分卷文件夹
│ ├── 第01回.txt
│ ├── 第02回.txt
│ └── ...(共120回)
├── 红楼梦词库.txt # 自定义词典(人名、地名等)
├── StopwordsCN.txt # 中文停用词表
├── main.py # 主程序
└── chapter_keywords.json # 最终输出的JSON数据2. 第一阶段:批量读取文件
python
import pandas as pd
import os
import jieba
filePaths = []
fileContents = []
for root, dirs, files in os.walk(r".\分卷"):
for name in files:
filePath = os.path.join(root, name)
filePaths.append(filePath)
f = open(filePath, 'r', encoding='utf-8')
lines = f.readlines()
fileContent = ''.join(lines[1:]) if len(lines) > 1 else ''
f.close()
fileContents.append(fileContent)
corpos = pd.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
print(f"文件读取完成,共{len(corpos)}个文件")知识点:
os.walk():递归遍历文件夹os.path.join():跨平台路径拼接readlines():按行读取pd.DataFrame:结构化存储
3. 第二阶段:中文分词与预处理
python
jieba.load_userdict(r".\红楼梦词库.txt")
stopwords = pd.read_csv(r".\StopwordsCN.txt",
encoding='utf8',
engine='python',
index_col=False)
file_to_jieba = open(r'.\分词后汇总.txt', 'w', encoding='utf-8')
for index, row in corpos.iterrows():
juan_ci = ''
fileContent = row['fileContent']
segs = jieba.cut(fileContent)
for seg in segs:
if seg not in stopwords.stopword.values and len(seg.strip()) > 0:
juan_ci += seg + ' '
file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()
print("分词完成")知识点:
jieba.load_userdict():加载自定义词典jieba.cut():中文分词- 停用词过滤
iterrows():遍历DataFrame
4. 第三阶段:TF-IDF计算与关键词提取
python
from sklearn.feature_extraction.text import TfidfVectorizer
import json
inFile = open(r".\分词后汇总.txt", 'r', encoding='utf-8')
corpus = inFile.readlines()
inFile.close()
print(f"共读取{len(corpus)}回文本")
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
wordlist = vectorizer.get_feature_names_out()
print(f"词表生成完成,共{len(wordlist)}个词")
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
chapter_keywords = []
for j in range(len(corpus)):
featurelist = df.iloc[:, j].to_list()
resdict = {}
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
filtered = [(word, score) for word, score in resdict if score > 0][:50]
print(f"\n第{j + 1}回的关键词(前10):")
for idx, (word, score) in enumerate(filtered[:10], 1):
print(f" {idx}. {word}: {score:.4f}")
chapter_keywords.append({
"chapter": j + 1,
"top20_keywords": [word for word, score in filtered[:20]],
"scores": [round(score, 4) for word, score in filtered[:20]]
})
with open(r".\chapter_keywords.json", "w", encoding="utf-8") as f:
json.dump(chapter_keywords, f, ensure_ascii=False, indent=2)
print("\n关键词提取完成!结果已保存到 chapter_keywords.json")知识点:
TfidfVectorizer:TF-IDF计算fit_transform():拟合+转换get_feature_names_out():获取词表.T.todense():转置并转为密集矩阵sorted()+lambda:按权重排序json.dump():导出JSON
5. 运行结果示例
文件读取完成,共120个文件
共读取120回文本
词表生成完成,共28473个词
第1回的关键词(前10):
1. 僧: 0.0523
2. 道人: 0.0487
3. 青埂峰: 0.0451
4. 顽石: 0.0412
5. 甄士隐: 0.0398
6. 石头: 0.0384
7. 梦幻: 0.0356
8. 通灵: 0.0339
9. 大荒山: 0.0321
10. 补天: 0.0305
第27回的关键词(前10):
1. 黛玉: 0.0612
2. 葬花: 0.0589
3. 宝玉: 0.0543
4. 红消香断: 0.0498
5. 花落: 0.0456
6. 荷锄: 0.0412
7. 泣残红: 0.0397
8. 燕子: 0.0365
9. 饯花: 0.0341
10. 宝钗: 0.0312
关键词提取完成!结果已保存到 chapter_keywords.json五、生成的JSON数据格式
这里先展示一下我们红楼梦TFIDF完整的代码:
python
import pandas as pd
import os
import jieba
filePaths = [] # 保存文件的路径
fileContents = [] # 保存文件路径对应的内容
for root, dirs, files in os.walk(fr".\分卷"): # 遍历文件夹
for name in files:
filePath = os.path.join(root, name) # 获取每个卷文件的路径
filePaths.append(filePath) # 把卷文件路径添加到列表filePaths中
f = open(filePath, 'r', encoding='utf-8')
lines = f.readlines() # 按行读取所有内容
# 跳过开头第一行
fileContent = ''.join(lines[1:]) if len(lines) > 1 else ''
f.close()
fileContents.append(fileContent) # 将每一卷的文件内容添加到列表fileContents中
corpos = pd.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
print(corpos)
jieba.load_userdict(r".\红楼梦词库.txt") # 导入分词库,把红楼梦专属的单词添加到jieba词库中。
# 导入停用词库,把无关的词提出
stopwords = pd.read_csv(r".\StopwordsCN.txt", encoding='utf8', engine='python', index_col=False)
# 进行分词,并与停用词进行对比删除
file_to_jieba = open(r'.\分词后汇总.txt', 'w', encoding='utf-8') # 创建一个新文本
for index, row in corpos.iterrows():
juan_ci = ''
fileContent = row['fileContent']
segs = jieba.cut(fileContent) # 对文本内容进行分词
for seg in segs:
if seg not in stopwords.stopword.values and len(seg.strip()) > 0:
juan_ci += seg + ' '
file_to_jieba.write(juan_ci+'\n')
file_to_jieba.close()
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import json
inFile = open(r".\分词后汇总.txt", 'r', encoding='utf-8')
corpus = inFile.readlines()
inFile.close() # 记得关闭文件
# 计算 TF-IDF
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus)
# 获取词表
wordlist = vectorizer.get_feature_names_out()
print(f"词表生成完成,共{len(wordlist)}个词")
# 转成DataFrame
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 循环输出每篇文本,输出关键词
chapter_keywords = []
for j in range(len(corpus)):
# 获取当前文本的所有词的权重
featurelist = df.iloc[:, j].to_list()
# 构建词-权重字典
resdict = {}
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
# 按权重降序排序
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
# 过滤掉权重为0的词,取前几个关键词
filtered = [(word, score) for word, score in resdict if score > 0][:50]
print(f"\n第{j + 1}回的关键词:{filtered}")
# 组装数据用于网页
chapter_keywords.append({
"chapter": j + 1,
"top20_keywords": [word for word, score in filtered],
"scores": [round(score, 4) for word, score in filtered]
})下面生成JSON数据
json
[
{
"chapter": 1,
"top20_keywords": ["僧", "道人", "青埂峰", "顽石", "甄士隐", ...],
"scores": [0.0523, 0.0487, 0.0451, 0.0412, 0.0398, ...]
},
{
"chapter": 2,
"top20_keywords": ["贾雨村", "冷子兴", "荣国府", ...],
"scores": [0.0712, 0.0654, 0.0598, ...]
}
]第三部分:可视化篇
六、HTML网页生成
1. 使用大模型生成HTML
完成关键词提取后,我们可以创建一个交互式网页来展示结果。这一步不需要手动编写代码,直接将以下提示词发送给大模型(如Claude、ChatGPT等):
请帮我生成一个HTML网页,用于展示红楼梦120回的关键词分析结果。
功能需求:
- 读取 chapter_keywords.json 文件(包含每回的top20关键词和权重)
- 支持滑动选择回目(第1回到第120回)
- 左侧展示词云(根据权重显示不同字体大小和随机颜色)
- 右侧展示关键词列表(带排名、TF-IDF值和进度条)
- 界面美观,响应式设计
数据格式:
{
"chapter": 1,
"top20_keywords": "僧", "道人", ...,
"scores": 0.0523, 0.0487, ...
}
结果展示:
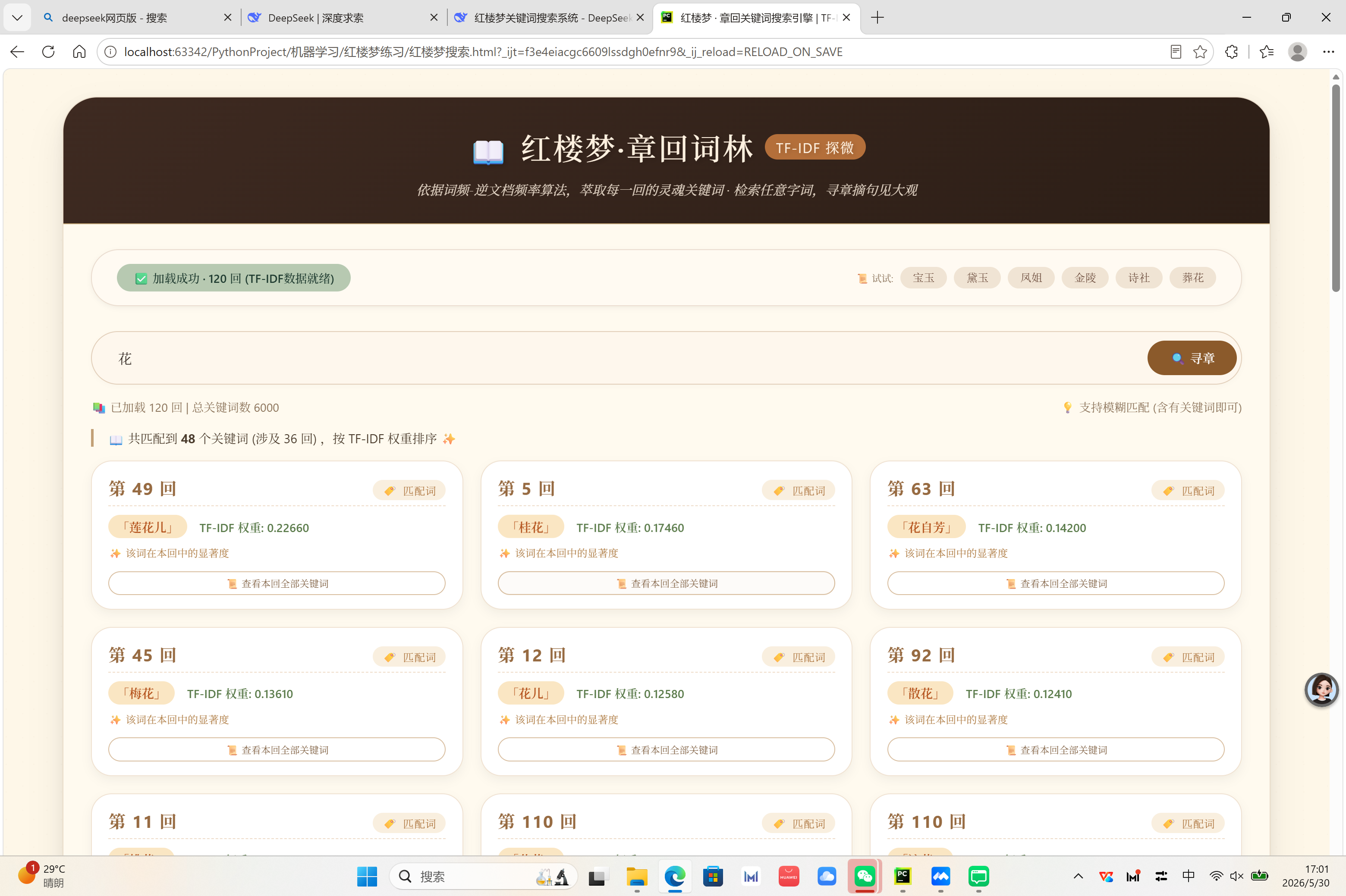
2. 部署说明
- 将生成的HTML文件与
chapter_keywords.json放在同一目录下 - 使用本地服务器打开(推荐VS Code的Live Server插件)
- 直接双击HTML文件可能因跨域限制无法读取本地JSON
3. 为什么交给大模型?
| 传统方式 | 使用大模型 |
|---|---|
| 手写HTML/CSS/JS约300行代码 | 一句话描述需求 |
| 调试样式和交互1-2小时 | 1分钟生成可用代码 |
| 需要熟悉前端技术栈 | 专注后端数据生成 |
七、常见问题与解决方案
Q1:jieba分词结果不准确怎么办?
python
# 添加自定义词典
jieba.add_word('薛宝钗', freq=1000)
# 或调整词频
jieba.suggest_freq('林妹妹', True)Q2:内存不足如何处理?
python
vectorizer = TfidfVectorizer(max_features=5000, min_df=2)Q3:JSON文件无法被HTML读取?
使用Live Server打开HTML文件(直接双击可能因跨域问题无法读取本地JSON)。
八、知识点总结
| 阶段 | 核心库 | 主要功能 |
|---|---|---|
| 文件读取 | os, pandas | 批量遍历、存储文件 |
| 文本预处理 | jieba | 中文分词、自定义词典 |
| 特征提取 | sklearn | TF-IDF计算 |
| 数据导出 | json | 保存为JSON格式 |
| 可视化 | 大模型生成 | 交互式网页展示 |
九、总结
通过本文,你学到了:
- TF-IDF算法原理:TF×IDF的数学含义和直观理解
- sklearn实现:TfidfVectorizer的使用方法和参数调优
- 中文NLP流程:分词→停用词过滤→TF-IDF→关键词排序
- 完整项目实战:红楼梦120回关键词提取
- 高效可视化:利用大模型快速生成HTML页面
下一步学习方向:
- 词云可视化(pyecharts/wordcloud)
- LDA主题模型
- TextRank算法
- Word2Vec词向量
本文为CSDN原创技术教程
如果对你有帮助,欢迎点赞、收藏、转发
有任何问题,欢迎评论区交流讨论
#NLP入门 #文本挖掘 #红楼梦分析 #TFIDF #Python实战 #大模型辅助开发