目录
-
- 一、火焰图原理:从"采集"到"解读"
-
- [1. 火焰图解决什么问题](#1. 火焰图解决什么问题)
- [2. 数据是怎么来的:调用栈采样](#2. 数据是怎么来的:调用栈采样)
- [3. 火焰图的图形语义](#3. 火焰图的图形语义)
-
- [3.1 X 轴:宽度代表热点程度](#3.1 X 轴:宽度代表热点程度)
- [3.2 Y 轴:表示调用栈深度](#3.2 Y 轴:表示调用栈深度)
- [3.3 颜色:通常只用于区分,不一定有固定含义](#3.3 颜色:通常只用于区分,不一定有固定含义)
- [3.4 X 轴通常不是时间线](#3.4 X 轴通常不是时间线)
- [4. 为什么叫"火焰图"](#4. 为什么叫“火焰图”)
- [5. 正确解读火焰图的方法](#5. 正确解读火焰图的方法)
- [6. 常见误区](#6. 常见误区)
-
- [误区一:把 X 轴当时间轴](#误区一:把 X 轴当时间轴)
- 误区二:看到红色就以为最热
- 误区三:只看最顶层函数
- 误区四:只看单个函数,不看整条调用路径
- 误区五:把采样结果当成绝对精确时间
- [二、使用Arthas Profiler生成火焰图](#二、使用Arthas Profiler生成火焰图)
- 三、火焰图优化实战
一、火焰图原理:从"采集"到"解读"
很多人会用火焰图,但并不一定真正理解火焰图的原理。理解原理以后,才能避免误读。
1. 火焰图解决什么问题
火焰图本质上是在回答一个问题:
程序运行过程中,CPU 时间主要花在哪些函数和调用路径上?
如果没有火焰图,我们看到的往往只是零散的方法耗时、线程栈或日志,很难从全局判断真正的热点。
火焰图的价值就在于:
- 把大量采样数据压缩成一张图
- 快速看到最热的函数
- 快速看到热点出现在哪条调用链上
2. 数据是怎么来的:调用栈采样
火焰图并不是"逐行记录每次函数调用",而是采样。
例如,Profiler 每隔 10ms 采集一次当前线程调用栈:
- 某次采样拿到:
A -> B -> C - 下一次采样拿到:
A -> B -> D - 再下一次采样拿到:
A -> E
随着采样次数越来越多,就可以统计出:
- 哪些栈路径出现频率最高
- 哪些函数在热点路径中反复出现
这些采样栈会被聚合,最后绘制成火焰图。
因此:
火焰图展示的不是"某一次调用",而是"统计意义上的热点分布"。
3. 火焰图的图形语义
这是理解火焰图最关键的部分。

3.1 X 轴:宽度代表热点程度
- 某个函数框越宽,表示该函数(或包含它的路径)出现的样本越多
- 样本越多,通常意味着消耗的 CPU 时间越多
所以:
宽,才是热。
3.2 Y 轴:表示调用栈深度
- 最底层通常是入口或调用链较上游的方法
- 越往上表示调用越深入
- 上层函数是下层函数调用出来的
所以:
下方是调用者,上方是被调用者。
3.3 颜色:通常只用于区分,不一定有固定含义
很多人会误以为"越红越热",这通常并不准确。
在大多数火焰图工具里:
- 颜色更多是为了视觉区分
- 不同颜色不一定代表不同耗时等级
- 除非某个工具明确赋予颜色特殊语义,否则不要过度解读颜色
所以:
颜色不是重点,宽度才是重点。
3.4 X 轴通常不是时间线
这是最容易误解的一点。
很多人看到图是横向展开的,就下意识认为:
- 左边是前面执行的
- 右边是后面执行的
这通常是错的。
火焰图中的左右位置,一般只是聚合后排布的位置,不表示真实的时间顺序。
所以:
火焰图通常不是时序图,而是聚合统计图。
4. 为什么叫"火焰图"
因为它看起来像一簇一簇向上燃烧的火焰:
- 每个矩形是一个函数
- 相同路径向上堆叠
- 热点路径形成宽而高的"火焰柱"
视觉上非常适合快速识别瓶颈路径。
5. 正确解读火焰图的方法
解读火焰图时,建议按下面顺序来:
第一步:找最宽的块
最宽的函数块,通常就是整体热点入口或热点路径的一部分。
第二步:顺着最宽块往上看
看它调用了谁,热点进一步落在哪个子函数。
第三步:区分"自身耗时"和"子调用耗时"
有时候某个函数很宽,并不代表它自己的代码慢,而是它调用的下游慢。
第四步:找"宽且可优化"的点
不是所有宽块都值得优化。比如:
- JDK 内部调度逻辑
- 框架底层调度
- 不可控的中间件等待
真正值得优先优化的是:
- 宽度大
- 业务上可改
- 改动收益明显
6. 常见误区
误区一:把 X 轴当时间轴
通常错误。火焰图不是按时间先后展开的。
误区二:看到红色就以为最热
不一定。颜色很多时候只是装饰性区分。
误区三:只看最顶层函数
顶层函数可能只是"最后被采样到的点",真正的耗时根因可能在更下层。
误区四:只看单个函数,不看整条调用路径
火焰图强调的是路径,不是孤立函数。
误区五:把采样结果当成绝对精确时间
火焰图是统计近似,不是逐条精确计时。但在定位热点上通常足够有效。
二、使用Arthas Profiler生成火焰图
当你不再满足于单方法观测,而是想从全局视角看"CPU 时间到底烧在哪",就该使用 profiler 了。
示例:
bash
[arthas@3792116]$ profiler start
Profiling started
[arthas@3792116]$ profiler stop
OK
profiler output file: /root/myapp/arthas-output/20260327-144254.html 这个过程可以理解为:
- 开始采样程序运行时的调用栈
- 运行一段时间,让业务流量进来
- 停止采样并输出分析结果
- 生成 HTML 火焰图文件
- 分析火焰图,查看性能热点
Profiler 适合什么场景
- CPU 高,但线程栈看不出明确原因
- 接口整体慢,但 trace 看的是局部,不够全局
- 想找真正的热点方法和热点路径
- 做性能优化前的基线分析
三、火焰图优化实战
我这边收到的问题是线上测试数据权限场景时,CPU的负载近乎100%,具体的数据权限处理场景是sql条件拼接了in {集合},集合包含2000个部门ID,按照常理理解这个场景的瓶颈应该在数据库的sql查询上,但实际现象就是服务器的CPU负载跑满了,问题出在了数据权限组件的sql解析上。我先是review了一遍组件代码,对组件内的字符串拼接处理进行了优化(字符串替换优化、添加本地缓存等),但实测下来优化效果非常不明显。
生成火焰图
针对这种CPU负载过高,但却无法定位热点的问题,火焰图就很适用。
我本地采用Jmeter对线上环境进行了压测(100并发、5分钟),然后通过Arthas Profiler命令抓取并生成了压测时间段内的应用程序的CPU火焰图:
注:由于是在docker容器中执行的应用程序,
所以需要先将arthas相关文件通过docker cp拷贝到容器内::
docker cp ./arthas xxx:./arthas然后再进入到docker容器内执行相应的抓取操作:
docker exec -it xxx /bin/sh
bash
# 开始抓取
[arthas@3792116]$ profiler start
Profiling started
# 结束抓取,并生成火焰图
[arthas@3792116]$ profiler stop
OK
# 结束后,会提示相应的结果文件位置
profiler output file: /root/myapp/arthas-output/20260327-144254.html 可将上述的输出结果文件拷贝到本地,然后通过浏览器即可查看相应的火焰图:
分析火焰图
可通过浏览器查看相应的火焰图(即前文提到的/root/myapp/arthas-output/20260327-144254.html ),具体的火焰图效果如下:

上面的火焰图看着很高,但其实最下面的都是框架级的调用代码,比如undertow、spring framework、mybaits等,并且最下层的这些行的宽度都一样,可以顺着这些行 往上看 直到看到我们需要调试的组件代码,可以发现真正涉及到数据权限相关的要从这行开始看起:
com/neusoft/oscoe/osmium/data/permission/mybatis/interceptor/DataPermissionInterceptor.intercept
这个DataPermissionInterceptor是数据权限组件的核心处理拦截器,从这行往上看才真正涉及到数据权限组件的相关处理,同时这行也是火焰图中最宽的众行之一(具体定位时可优先定位到业务相关 (而不是框架或jdk相关)、最宽的 核心实现代码)。

从DataPermissionInterceptor往上看,可以发现从com/github/pagehelper/PageInterceptor.intercept开始,调用链拆分成:
com/github/pagehelper/PageInterceptor.countcom/github/pagehelper/util/ExecutorUtil.pageQuery
即DataPermissionInterceptor组件之后调用了PageHelper组件的PageInterceptor,其中PageInterceptor又拆分为PageInterceptor.count和ExecutorUtil.pageQuery 2部分,即分别处理分页计数和具体的分页查询,如此便可基本确认PageHelper组件的PageInterceptor的执行基本占用了全部的CPU资源。
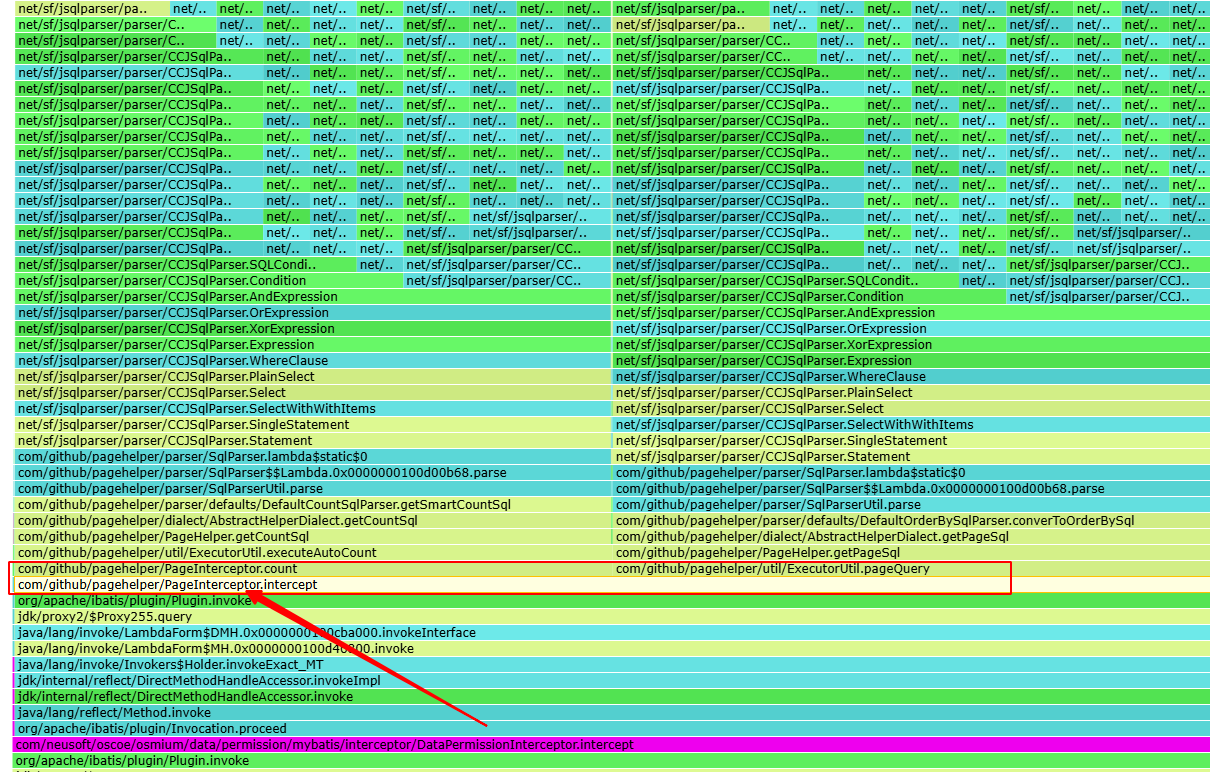
再顺着PageInterceptor.count和ExecutorUtil.pageQuery 往上看,可以看出满屏充斥着大量的net/sf/jsqlparser/parser/...包名前缀,即下面中的粉色部分(可通过页面的CTRL+F搜索指定关键字即可高亮显示为粉色),结论就是PageHelper的PageInterceptor拦截器底层调用了jsqlparser解析sql时耗费了大量的CPU资源,此处的jsqlparser解析sql便是此次CPU高负载的根源。

分析问题代码
前文我们已经定位到PageHelper的PageInterceptor拦截器底层的jsqlparser解析sql便是此次CPU高负载的根源。
PageHepler组件负责为DAO方法添加分页查询逻辑,它会通过jsqlparser解析sql并附加分页查询条件(比如limit..,order by ...),如果被解析的sql过长则会出现性能问题,而出现问题的场景正是由于数据权限组件DataPermissionInterceptor给sql拼接了条件 in { 2000个部门ID}(数据权限组件底层采用了字符串拼接,所以没有jsqlparser解析慢的问题),而PageHelper的PageInterceptor拦截器在其之后执行,此时的PageInterceptor拦截器便需要解析拼接了 in { 2000个部门ID}的sql语句,即解析sql字符串并转换为java对象,此处转换耗费了大量的CPU资源,导致了CPU负载飙升到100%。
解决方案
定位到了问题根源,接下来说说解决办法。既然PageHelper解析长sql有性能问题,那么我就将PageHelper的PageInterceptor拦截器的执行顺序提前,即在数据权限组件DataPermissionInterceptor之前执行。如此PageHelper解析的通常都是短sql,即没有拼接数据权限条件的sql,而DataPermissionInterceptor在PageHelper拼接完分页sql后再拼接数据权限相关查询条件,综上便可避免PageHelper解析长sql的性能问题。但需要额外处理的就是DataPermissionInterceptor需要自行识别limit..,order by ...(需兼容众多数据库分页语法)等分页条件,并将数据权限相关的sql条件 拼接到正确的位置上(原方案DataPermissionInterceptor无需关注分页,由PageHepler统一兜底处理,有利有弊吧):
注: 关于mybatis 拦截器顺序相关的介绍可参见我的另一篇博客:
MyBatis Interceptor执行顺序详解(plugin机制、责任链模式)
sql
select
*
from my_table
col = 'val'
and '数据权限相关的sql条件'
limit 10, 20
order by my_name desc经过上述调整后,再次压测CPU负载如愿降下来了,打卡下班...