【MCP】第二章 MCP 实战
文章目录
- [【MCP】第二章 MCP 实战](#【MCP】第二章 MCP 实战)
- 一、环境准备
-
- [1.stdio 的本地环境安装](#1.stdio 的本地环境安装)
- [2.Curosr 配置 MCP](#2.Curosr 配置 MCP)
- [二、MCP 使用案例:北京旅游](#二、MCP 使用案例:北京旅游)
- [三、MCP 手动开发项目:本地智能舆情分析系统](#三、MCP 手动开发项目:本地智能舆情分析系统)
-
- 1.需求
- [2.创建 MCP 项目](#2.创建 MCP 项目)
- 3.client.py
- 4.server.py
- 5.测试
一、环境准备
1.stdio 的本地环境安装
stdio 的本地环境有两种:
- Python 编写的服务,对应uvx 命令
- TypeScript 编写的服务,对应 npx 命令
从经验来看,TypeSrcipt 编写的服务居多
以 filesystem 为例,它提供的就是 npx 的方式
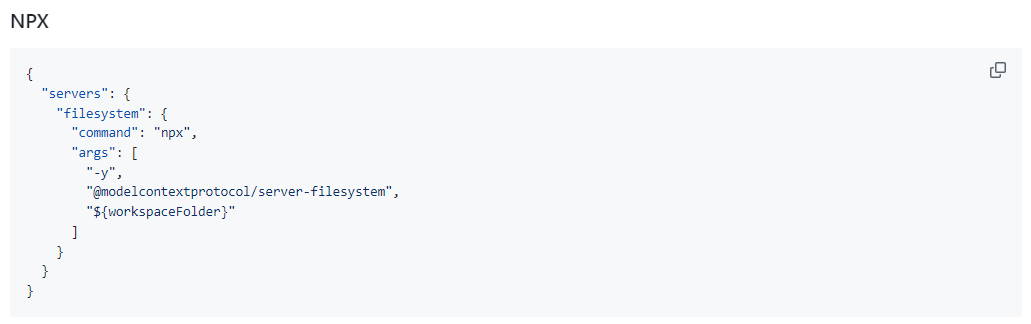
以 git 为例,它提供的就是 uvx 的方式
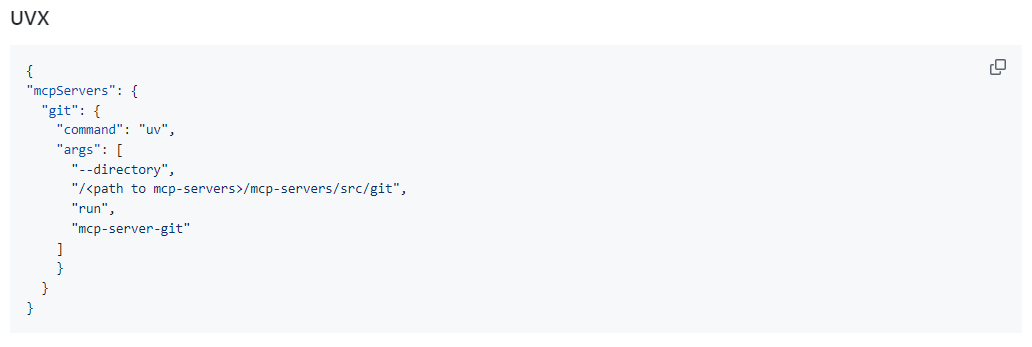
安装 uvx
需要有 python 环境:https://www.python.org/downloads
pip install uv
C:\Users\#{yourUserName}\AppData\Local\Python\pythoncore-3.14-64\Scripts\uv --version
C:\Users\#{yourUserName}\AppData\Local\Python\pythoncore-3.14-64\Scripts\uvx --version
建议配置 uv 环境变量
安装 npx
Node.js 官网:https://nodejs.org/zh-cn
npx --version
2.Curosr 配置 MCP
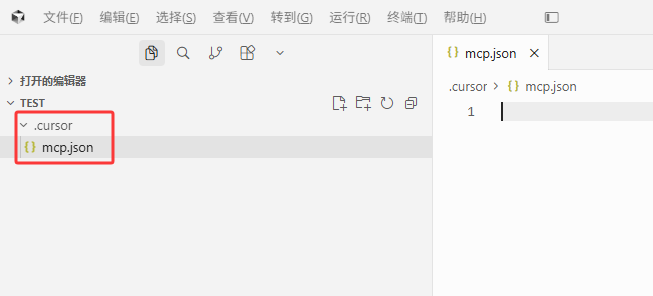
在项目目录下新建 .cursor 目录,并在 .cursor 目录下新建 mcp.json
二、MCP 使用案例:北京旅游
1.需求
现在交给你一个任务,编写一个北京一日游的出行攻略:
1.从高德地图的 MCP 服务中获取北京站到天安门、天安门到颐和园、颐和园到南锣鼓巷的地铁线路,并保存在数据库 beijing_trip 的表 subway_trips 中
2.从高德地图的 MCP 服务中获取颐和园、南锣鼓巷附近的美食信息,每处获取三家美食店铺信息,并将相应的信息存入表 location_foods 中
3.在工作目录 E:\MCPWorkSpace 下创建一个新的文件夹,命名为 "北京旅游" 在其中创建两个 txt,分别从数据库中将两个表的内容提取出来,并存放进去
4.最后根据 txt 中的内容,生成一个精美的 html 前端展示页面,存放在该目录下
涉及到的 MCP 服务:
- 高德地图服务
- mysql 服务
- filesystem 服务
2.安装 MCP
我们去 MCP 资源网站搜索相关服务,在上一章中列举了一些热门的资源网站,同种功能可能会有多种不同版本的实现,按照对应的说明文档去使用即可,我这里使用的 MCP 不一定是最好用的
mysql MCP:https://github.com/designcomputer/mysql_mcp_server
高德地图 MCP:https://lbs.amap.com/api/mcp-server/summary
filesystem MCP:https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem
mcp.json:
json
{
"mcpServers": {
"mysql": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"mysql-mcp-server",
"mysql_mcp_server"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "abc123",
"MYSQL_DATABASE": "beijing_trip"
}
},
"amap-maps-streamableHTTP": {
"url": "https://mcp.amap.com/mcp?key=您在高德官网上申请的key"
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"E:\\MCPWorkSpace"
]
}
}
}配置项说明:
- 先定位服务类型
- 有 command /args 的,是本地 stdio 服务
- 有 url 的,是远程 HTTP/SSE 服务
- 再定位服务本体
- mysql:
- 客户端现在系统 PATH 里找到 uvx
- uvx 再按 --from mysql-mcp-server 去 Python 包源里照这个包
- 找到后运行入口 mysql_mcp_server
- filesystem:
- 客户端先找到 npx
- npx 再去 npm registry 或你配置的镜像里找 @modelcontextprotocol/server-filesystem
- 下载后启动它
- amap-maps-streamableHTTP:
- 不需要找本地命令
- 直接用写死的 url
- 通过 DNS 定位到 mcp.amap.com,再发送 HTTP 请求连接
- mysql:
- 最后定位到它提供哪些工具
- 服务启动或连上后,客户端会按 MCP 协议做一次握手
- 然后向服务请求 "你有哪些 tools/resources/prompts"
- 这些能力是服务自己上报的,不是客户端预先知道的
3.执行

最终效果:
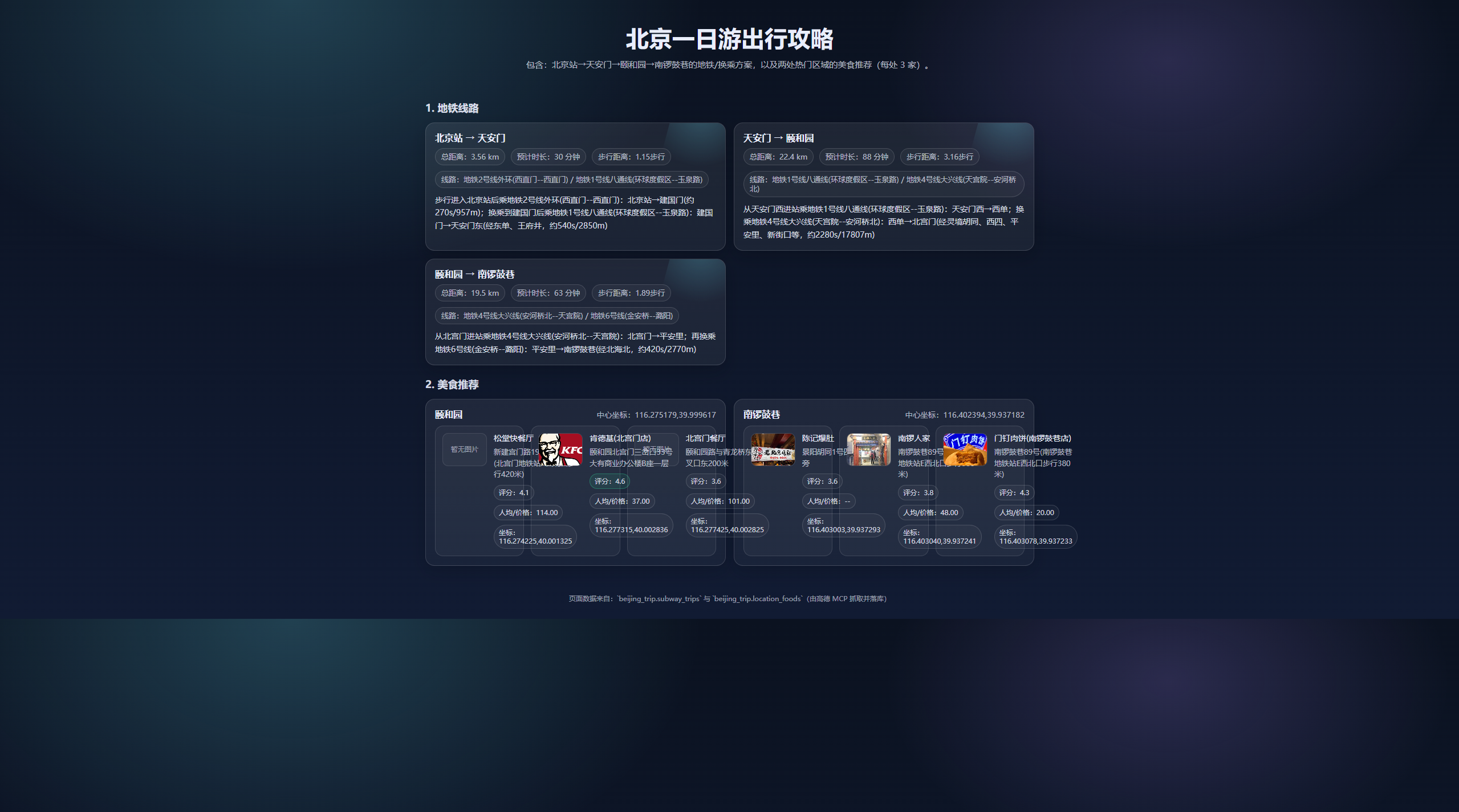
三、MCP 手动开发项目:本地智能舆情分析系统
1.需求
构建一个本地智能舆情分析系统,通过自然语言处理与多工具协作,实现用户查询意图的自动理解、新闻检索、情绪分析、结构化输出与邮件推送。
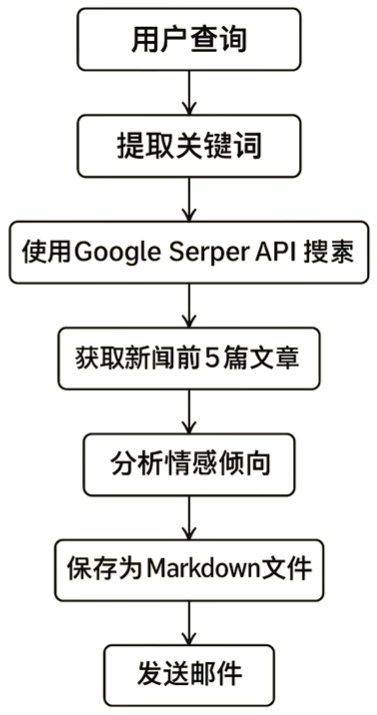
2.创建 MCP 项目
需要提前安装 uv 环境
进入你要创建项目的空间
uv init mcp-project
在项目目录下新建 .env、client.py 和 server.py 文件
- .env:用于配置 LLM 连接信息
- client.py:是我们的客户端,用户与客户端进行交互
- server.py:是服务端,其中包含了多种工具函数,客户端会对其中的工具函数进行调用
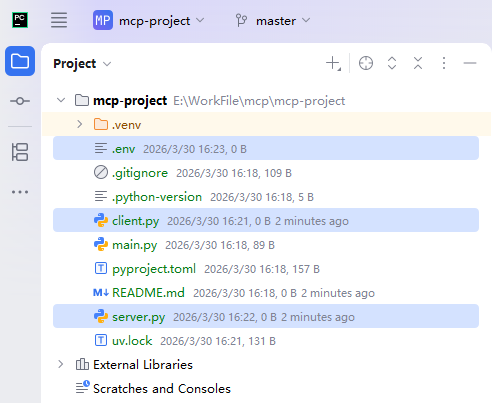
.env 配置样例
获取 SERPER_API_KEY
EMAIL_USER 为你的邮箱账号
EMAIL_PASS 不是邮箱密码,而是开通 SMTP 后的授权码
3.client.py
- 初始化客户端(API + MCP 会话)
- 连接 MCP 工具服务
- 用户输入问题
- 大模型规划工具调用链
- 执行工具 → 汇总 → 生成最终回答 → 保存
python
import asyncio
import os
import json
from typing import Optional, List
from contextlib import AsyncExitStack
from datetime import datetime
import re
from openai import OpenAI
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
load_dotenv()
class MCPClient:
def __init__(self):
self.exit_stack = AsyncExitStack()
self.openai_api_key = os.getenv("DASHSCOPE_API_KEY")
self.base_url = os.getenv("BASE_URL")
self.model = os.getenv("MODEL")
if not self.openai_api_key:
raise ValueError("❌ 未找到 OpenAI API Key,请在 .env 文件中设置 DASHSCOPE_API_KEY")
self.client = OpenAI(api_key=self.openai_api_key, base_url=self.base_url)
self.session: Optional[ClientSession] = None
async def connect_to_server(self, server_script_path: str):
# 对服务器脚本进行判断,只允许是 .py 或 .js
is_python = server_script_path.endswith('.py')
is_js = server_script_path.endswith('.js')
if not (is_python or is_js):
raise ValueError("服务器脚本必须是 .py 或 .js 文件")
# 确定启动命令,.py 用 python,.js 用 node
command = "python" if is_python else "node"
# 构造 MCP 所需的服务器参数,包含启动命令、脚本路径参数、环境变量(为 None 表示默认)
server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)
# 启动 MCP 工具服务进程(并建立 stdio 通信)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
# 拆包通信通道,读取服务端返回的数据,并向服务端发送请求
self.stdio, self.write = stdio_transport
# 创建 MCP 客户端会话对象
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
# 初始化会话
await self.session.initialize()
# 获取工具列表并打印
response = await self.session.list_tools()
tools = response.tools
print("\n已连接到服务器,支持以下工具:", [tool.name for tool in tools])
async def process_query(self, query: str) -> str:
# 准备初始消息和获取工具列表
messages = [{"role": "user", "content": query}]
response = await self.session.list_tools()
available_tools = [
{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
}
} for tool in response.tools
]
# 提取问题的关键词,对文件名进行生成。
# 在接收到用户提问后就应该生成出最后输出的 md 文档的文件名,
# 因为导出时若再生成文件名会导致部分组件无法识别该名称。
keyword_match = re.search(r'(关于|分析|查询|搜索|查看)([^的\s,。、?\n]+)', query)
keyword = keyword_match.group(2) if keyword_match else "分析对象"
safe_keyword = re.sub(r'[\\/:*?"<>|]', '', keyword)[:20]
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
md_filename = f"sentiment_{safe_keyword}_{timestamp}.md"
md_path = os.path.join("./sentiment_reports", md_filename)
# 更新查询,将文件名添加到原始查询中,使大模型在调用工具链时可以识别到该信息
# 然后调用 plan_tool_usage 获取工具调用计划
query = query.strip() + f" [md_filename={md_filename}] [md_path={md_path}]"
messages = [{"role": "user", "content": query}]
tool_plan = await self.plan_tool_usage(query, available_tools)
tool_outputs = {}
messages = [{"role": "user", "content": query}]
# 依次执行工具调用,并收集结果
for step in tool_plan:
tool_name = step["name"]
tool_args = step["arguments"]
for key, val in tool_args.items():
if isinstance(val, str) and val.startswith("{{") and val.endswith("}}"):
ref_key = val.strip("{} ")
resolved_val = tool_outputs.get(ref_key, val)
tool_args[key] = resolved_val
# 注入统一的文件名或路径(用于分析和邮件)
if tool_name == "analyze_sentiment" and "filename" not in tool_args:
tool_args["filename"] = md_filename
if tool_name == "send_email_with_attachment" and "attachment_path" not in tool_args:
tool_args["attachment_path"] = md_path
result = await self.session.call_tool(tool_name, tool_args)
tool_outputs[tool_name] = result.content[0].text
messages.append({
"role": "tool",
"tool_call_id": tool_name,
"content": result.content[0].text
})
# 调用大模型生成回复信息,并输出保存结果
final_response = self.client.chat.completions.create(
model=self.model,
messages=messages
)
final_output = final_response.choices[0].message.content
# 对辅助函数进行定义,目的是把文本清理成合法的文件名
def clean_filename(text: str) -> str:
text = text.strip()
text = re.sub(r'[\\/:*?\"<>|]', '', text)
return text[:50]
# 使用清理函数处理用户查询,生成用于文件命名的前缀,并添加时间戳、设置输出目录
# 最后构建出完整的文件路径用于保存记录
safe_filename = clean_filename(query)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"{safe_filename}_{timestamp}.txt"
output_dir = "./llm_outputs"
os.makedirs(output_dir, exist_ok=True)
file_path = os.path.join(output_dir, filename)
# 将对话内容写入 md 文档,其中包含用户的原始提问以及模型的最终回复结果
with open(file_path, "w", encoding="utf-8") as f:
f.write(f"🗣 用户提问:{query}\n\n")
f.write(f"🤖 模型回复:\n{final_output}\n")
print(f"📄 对话记录已保存为:{file_path}")
return final_output
async def chat_loop(self):
# 初始化提示信息
print("\n🤖 MCP 客户端已启动!输入 'quit' 退出")
# 进入主循环中等待用户输入
while True:
try:
query = input("\n你: ").strip()
if query.lower() == 'quit':
break
# 处理用户的提问,并返回结果
response = await self.process_query(query)
print(f"\n🤖 AI: {response}")
except Exception as e:
print(f"\n⚠️ 发生错误: {str(e)}")
async def plan_tool_usage(self, query: str, tools: List[dict]) -> List[dict]:
# 构造系统提示词 system_prompt。
# 将所有可用工具组织为文本列表插入提示中,并明确指出工具名,
# 限定返回格式是 JSON,防止其输出错误格式的数据。
print("\n📤 提交给大模型的工具定义:")
print(json.dumps(tools, ensure_ascii=False, indent=2))
tool_list_text = "\n".join([
f"- {tool['function']['name']}: {tool['function']['description']}"
for tool in tools
])
system_prompt = {
"role": "system",
"content": (
"你是一个智能任务规划助手,用户会给出一句自然语言请求。\n"
"你只能从以下工具中选择(严格使用工具名称):\n"
f"{tool_list_text}\n"
"如果多个工具需要串联,后续步骤中可以使用 {{上一步工具名}} 占位。\n"
"返回格式:JSON 数组,每个对象包含 name 和 arguments 字段。\n"
"不要返回自然语言,不要使用未列出的工具名。"
)
}
# 构造对话上下文并调用模型。
# 将系统提示和用户的自然语言一起作为消息输入,并选用当前的模型。
planning_messages = [
system_prompt,
{"role": "user", "content": query}
]
response = self.client.chat.completions.create(
model=self.model,
messages=planning_messages,
tools=tools,
tool_choice="none"
)
# 提取出模型返回的 JSON 内容
content = response.choices[0].message.content.strip()
match = re.search(r"```(?:json)?\\s*([\s\S]+?)\\s*```", content)
if match:
json_text = match.group(1)
else:
json_text = content
# 在解析 JSON 之后返回调用计划
try:
plan = json.loads(json_text)
return plan if isinstance(plan, list) else []
except Exception as e:
print(f"❌ 工具调用链规划失败: {e}\n原始返回: {content}")
return []
async def cleanup(self):
await self.exit_stack.aclose()
async def main():
server_script_path = "D:\\mcp-project\\server.py"
client = MCPClient()
try:
await client.connect_to_server(server_script_path)
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())4.server.py
- 用户输入:"分析小米汽车舆情并发邮件"
- 客户端(LLM)分析,并生成工具调用链
- search_google_news
- analyze_sentiment
- send_email_with_attachment
- 服务端逐个执行工具,返回结果
python
import os
import json
import smtplib
from datetime import datetime
from email.message import EmailMessage
import httpx
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化 MCP 服务器
mcp = FastMCP("NewsServer")
# @mcp.tool() 是 MCP 框架的装饰器,表明这是一个 MCP 工具。之后是对这个工具功能的描述
@mcp.tool()
async def search_google_news(keyword: str) -> str:
"""
使用 Serper API(Google Search 封装)根据关键词搜索新闻内容,返回前5条标题、描述和链接。
参数:
keyword (str): 关键词,如 "小米汽车"
返回:
str: JSON 字符串,包含新闻标题、描述、链接
"""
# 从环境中获取 API 密钥并进行检查
api_key = os.getenv("SERPER_API_KEY")
if not api_key:
return "❌ 未配置 SERPER_API_KEY,请在 .env 文件中设置"
# 设置请求参数并发送请求
url = "https://google.serper.dev/news"
headers = {
"X-API-KEY": api_key,
"Content-Type": "application/json"
}
payload = {"q": keyword}
async with httpx.AsyncClient() as client:
response = await client.post(url, headers=headers, json=payload)
data = response.json()
# 检查数据,并按照格式提取新闻,返回前五条新闻
if "news" not in data:
return "❌ 未获取到搜索结果"
articles = [
{
"title": item.get("title"),
"desc": item.get("snippet"),
"url": item.get("link")
} for item in data["news"][:5]
]
# 将新闻结果以带有时间戳命名后的 JSON 格式文件的形式保存在本地指定的路径
output_dir = "./google_news"
os.makedirs(output_dir, exist_ok=True)
filename = f"google_news_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
file_path = os.path.join(output_dir, filename)
with open(file_path, "w", encoding="utf-8") as f:
json.dump(articles, f, ensure_ascii=False, indent=2)
return (
f"✅ 已获取与 [{keyword}] 相关的前5条 Google 新闻:\n"
f"{json.dumps(articles, ensure_ascii=False, indent=2)}\n"
f"📄 已保存到:{file_path}"
)
# @mcp.tool() 是 MCP 框架的装饰器,标记该函数为一个可调用的工具
@mcp.tool()
async def analyze_sentiment(text: str, filename: str) -> str:
"""
对传入的一段文本内容进行情感分析,并保存为指定名称的 Markdown 文件。
参数:
text (str): 新闻描述或文本内容
filename (str): 保存的 Markdown 文件名(不含路径)
返回:
str: 完整文件路径(用于邮件发送)
"""
# 这里的情感分析功能需要去调用 LLM,所以从环境中获取 LLM 的一些相应配置
openai_key = os.getenv("DASHSCOPE_API_KEY")
model = os.getenv("MODEL")
client = OpenAI(api_key=openai_key, base_url=os.getenv("BASE_URL"))
# 构造情感分析的提示词
prompt = f"请对以下新闻内容进行情绪倾向分析,并说明原因:\n\n{text}"
# 向模型发送请求,并处理返回的结果
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content.strip()
# 生成 Markdown 格式的舆情分析报告,并存放进设置好的输出目录
markdown = f"""# 舆情分析报告
**分析时间:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
---
## 📥 原始文本
{text}
---
## 📊 分析结果
{result}
"""
output_dir = "./sentiment_reports"
os.makedirs(output_dir, exist_ok=True)
if not filename:
filename = f"sentiment_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"
file_path = os.path.join(output_dir, filename)
with open(file_path, "w", encoding="utf-8") as f:
f.write(markdown)
return file_path
@mcp.tool()
async def send_email_with_attachment(to: str, subject: str, body: str, filename: str) -> str:
"""
发送带附件的邮件。
参数:
to: 收件人邮箱地址
subject: 邮件标题
body: 邮件正文
filename (str): 保存的 Markdown 文件名(不含路径)
返回:
邮件发送状态说明
"""
# 获取并配置 SMTP 相关信息
smtp_server = os.getenv("SMTP_SERVER") # 例如 smtp.qq.com
smtp_port = int(os.getenv("SMTP_PORT", 465))
sender_email = os.getenv("EMAIL_USER")
sender_pass = os.getenv("EMAIL_PASS")
# 获取附件文件的路径,并进行检查是否存在
full_path = os.path.abspath(os.path.join("./sentiment_reports", filename))
if not os.path.exists(full_path):
return f"❌ 附件路径无效,未找到文件: {full_path}"
# 创建邮件并设置内容
msg = EmailMessage()
msg["Subject"] = subject
msg["From"] = sender_email
msg["To"] = to
msg.set_content(body)
# 添加附件并发送邮件
try:
with open(full_path, "rb") as f:
file_data = f.read()
file_name = os.path.basename(full_path)
msg.add_attachment(file_data, maintype="application", subtype="octet-stream", filename=file_name)
except Exception as e:
return f"❌ 附件读取失败: {str(e)}"
try:
with smtplib.SMTP_SSL(smtp_server, smtp_port) as server:
server.login(sender_email, sender_pass)
server.send_message(msg)
return f"✅ 邮件已成功发送给 {to},附件路径: {full_path}"
except Exception as e:
return f"❌ 邮件发送失败: {str(e)}"
if __name__ == "__main__":
mcp.run(transport='stdio')5.测试
- 调整客户端代码中 server.py 的文件路径
- 启动客户端
- 输入需求
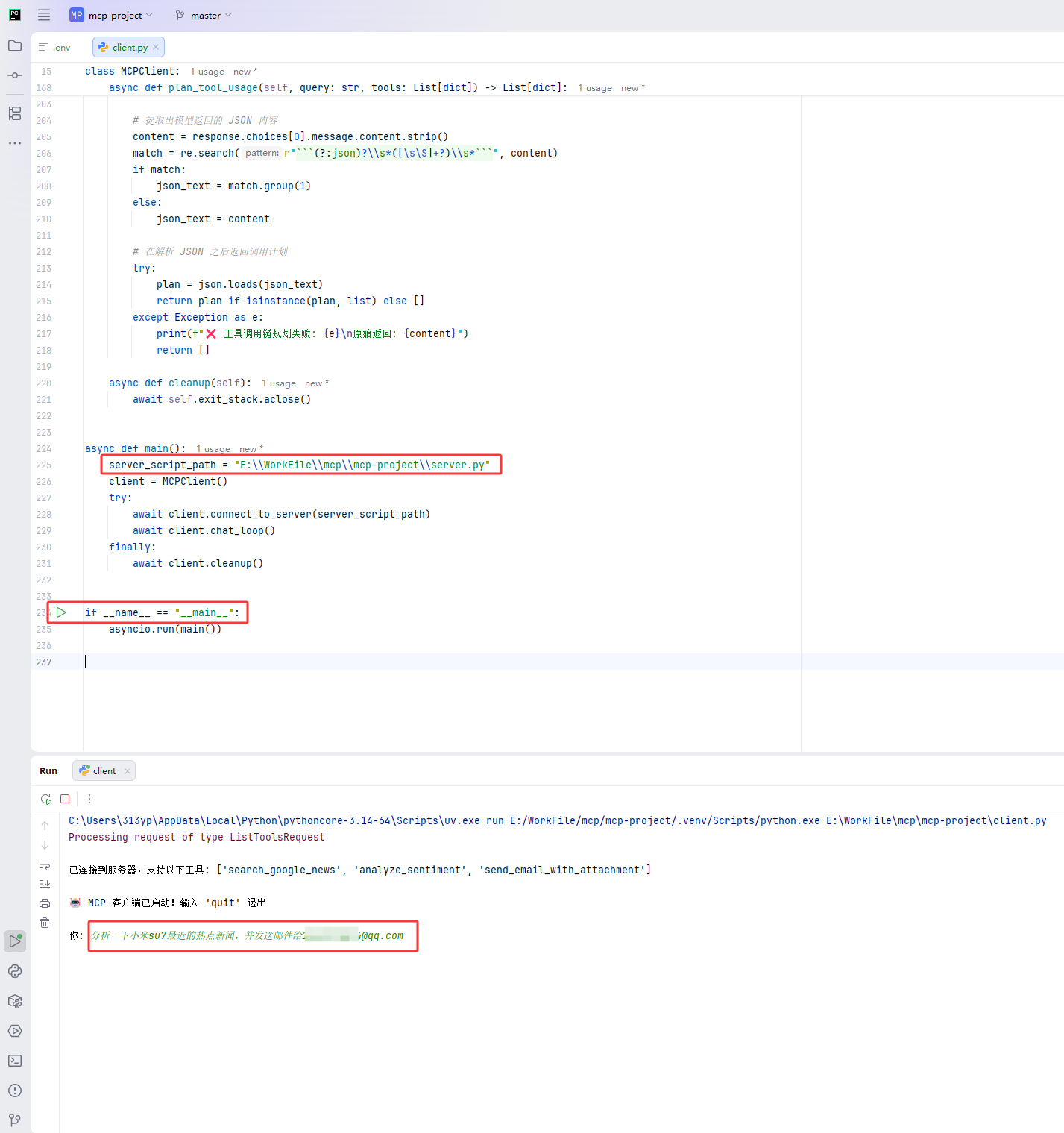
控制台打印信息
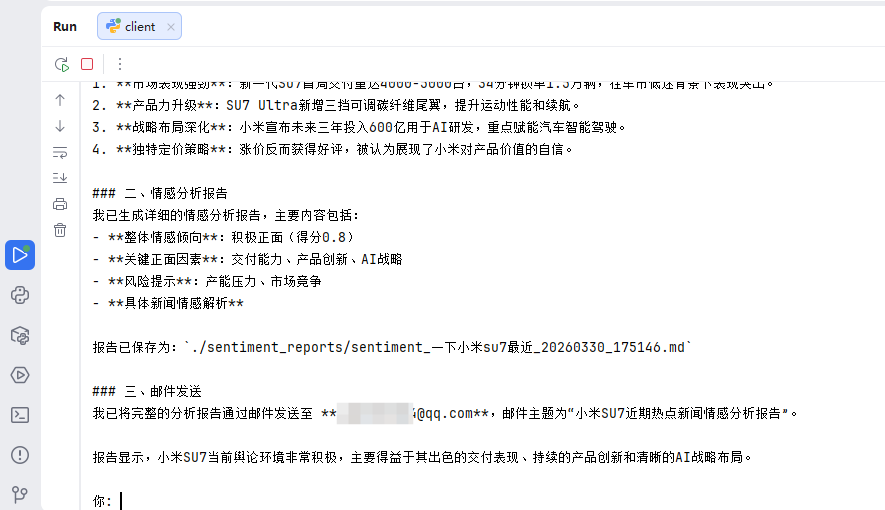
邮件内容
附件内容
