游戏手感的调参一直很麻烦。
拿"跳跃"这一件事来说,要做出像马里奥那种"短按小跳、长按高跳、下落更快"的手感,开发者要在 jumpForce、重力倍数、下落额外加速度、上升中断阈值这一堆数值之间反复试。流程是:
改数值 → 等 Unity 编译 → 进 PlayMode → 按空格 → 用肌肉记忆判断"对不对" → 退出 PlayMode → 再改
每一轮都要切回编辑器、按按钮、观察、记忆。每个数值改 0.5,你都要把这套流程跑一遍。
我用 funplay-unity-mcp 把这个闭环交给 Claude Code 跑了一遍------AI 自己选参数、自己进 PlayMode、自己触发跳跃、自己采样 Y 轨迹、根据物理数据判断"飘不飘 / snap 不 snap"、再决定下一组参数。三轮迭代之后从"短/飘/snappy"分别拿到了可量化的数据和截图。这一篇就把这个过程完整记下来。
实验设置
最小可复现的跳跃 demo:
- 一块 20×20 的灰色平面当地面
- 一个红色 Cube 当 Player,挂 Rigidbody(冻转动、连续碰撞)
- 左边一排白色高度标记,在 y=1/2/3/4 米处,方便目测高度
- 侧视相机,看得清整个轨迹
挂在 Player 上的两个脚本:
csharp
// JumpController.cs - 跳跃逻辑本体
public class JumpController : MonoBehaviour
{
public float jumpForce = 5f;
public float fallGravityMultiplier = 1f;
public KeyCode jumpKey = KeyCode.Space;
Rigidbody _rb;
bool _grounded;
void Update()
{
_grounded = Physics.Raycast(transform.position, Vector3.down, 0.55f);
if (Input.GetKeyDown(jumpKey) && _grounded)
{
_rb.velocity = new Vector3(_rb.velocity.x, 0f, _rb.velocity.z);
_rb.AddForce(Vector3.up * jumpForce, ForceMode.Impulse);
}
}
void FixedUpdate()
{
// 下落时叠加额外重力,做出 snappy 手感
if (_rb.velocity.y < 0f && fallGravityMultiplier > 1f)
_rb.AddForce(Physics.gravity * (fallGravityMultiplier - 1f), ForceMode.Acceleration);
}
}
csharp
// JumpSampler.cs - 每 FixedUpdate 记录一次 (time, Y)
public class JumpSampler : MonoBehaviour
{
public List<float> times = new();
public List<float> ys = new();
bool _recording;
float _t0;
Rigidbody _rb;
public void TriggerJump(float force)
{
transform.position = new Vector3(0, 0.5f, 0);
_rb.velocity = Vector3.zero;
_rb.AddForce(Vector3.up * force, ForceMode.Impulse);
}
void FixedUpdate()
{
if (_recording) { times.Add(Time.time - _t0); ys.Add(transform.position.y); }
}
// 还有 Start/StopRecording、Summary() 略
}为什么需要 JumpSampler?因为 AI 不能"凭感觉判断手感"------它需要可读的数值。直接采集 (t, y) 轨迹,然后从中算出峰值高度、到顶时间、上升/下降耗时比例,这些才是 AI 能拿来推理的客观信号。
整个 setup 让 AI 自己用 execute_code 工具就完成了------一段 C# 在 Unity 进程内即时编译执行,建场景、挂材质、保存 JumpDemo.unity。没有手动操作。
Iter 1:基线
AI 先跑一组保守值:jumpForce = 5,fallGravityMultiplier = 1.0(标准重力,没额外加速度)。
AI 调用链:
execute_code → TriggerJump(5),开始采样
get_editor_state × 2 → 故意让出编辑器线程几秒,让物理跑完
execute_code → 读 sampler,dump 出 741 个样本到 JSON读出的数据:
| 指标 | 值 |
|---|---|
| 峰值高度 | 1.725 m(起点 0.5m,跳起 1.23m) |
| 到顶时间 | 0.513 s |
| 落地时间 | 1.013 s |
| 上升:下降 | 0.51 : 0.50(对称) |
apex 截图------cube 大概到第 2 个高度标记之间:

AI 的判断:跳得太矮 。1.23m 的跳跃高度在 3D 平台跳跃游戏里很短,对应大概一格半的台阶高度,玩家会觉得这个角色"腿短"。可以接受的下限大概在 2m 以上。决定下一轮把 jumpForce 加到 8。
Iter 2:加力,但飘了
参数:jumpForce = 8,fallGravityMultiplier = 1.0。
| 指标 | 值 |
|---|---|
| 峰值高度 | 3.682 m(跳起 3.18m) |
| 到顶时间 | 0.816 s |
| 落地时间 | 1.636 s |
| 上升:下降 | 0.82 : 0.82(对称) |
apex 截图------cube 在第 4 个高度标记附近:

跳跃高度够了(3.18m,接近两层台阶)。但是问题更明显了:
- 整个空中时间 1.64 秒------这个数字在快节奏跳跃游戏里太长了。横向移动 4 个单位玩家还没落地。
- 上升和下降耗时一样 (0.82s vs 0.82s)。真实的"好手感"跳跃几乎都是下降快于上升------这就是为什么《蔚蓝》《空洞骑士》这些游戏要专门写一段"下落额外重力"的逻辑。
- 主观感受会是"角色像被绑了氢气球"。
AI 的判断:高度对了,但飘 。需要在下落阶段叠加额外重力。下一轮加 fallGravityMultiplier = 2.5。
Iter 3:snappy
参数:jumpForce = 8,fallGravityMultiplier = 2.5(下降时重力变成 2.5×g)。
| 指标 | 值 |
|---|---|
| 峰值高度 | 3.682 m(和 Iter 2 同高) |
| 到顶时间 | 0.804 s |
| 落地时间 | 1.324 s(比 Iter 2 少了 0.31s) |
| 上升:下降 | 0.80 : 0.52 |
关键指标变了------下降耗时只是上升的 0.65 倍。这就是 snappy 手感的物理标志。
三轮放在一张图里,对比一目了然:
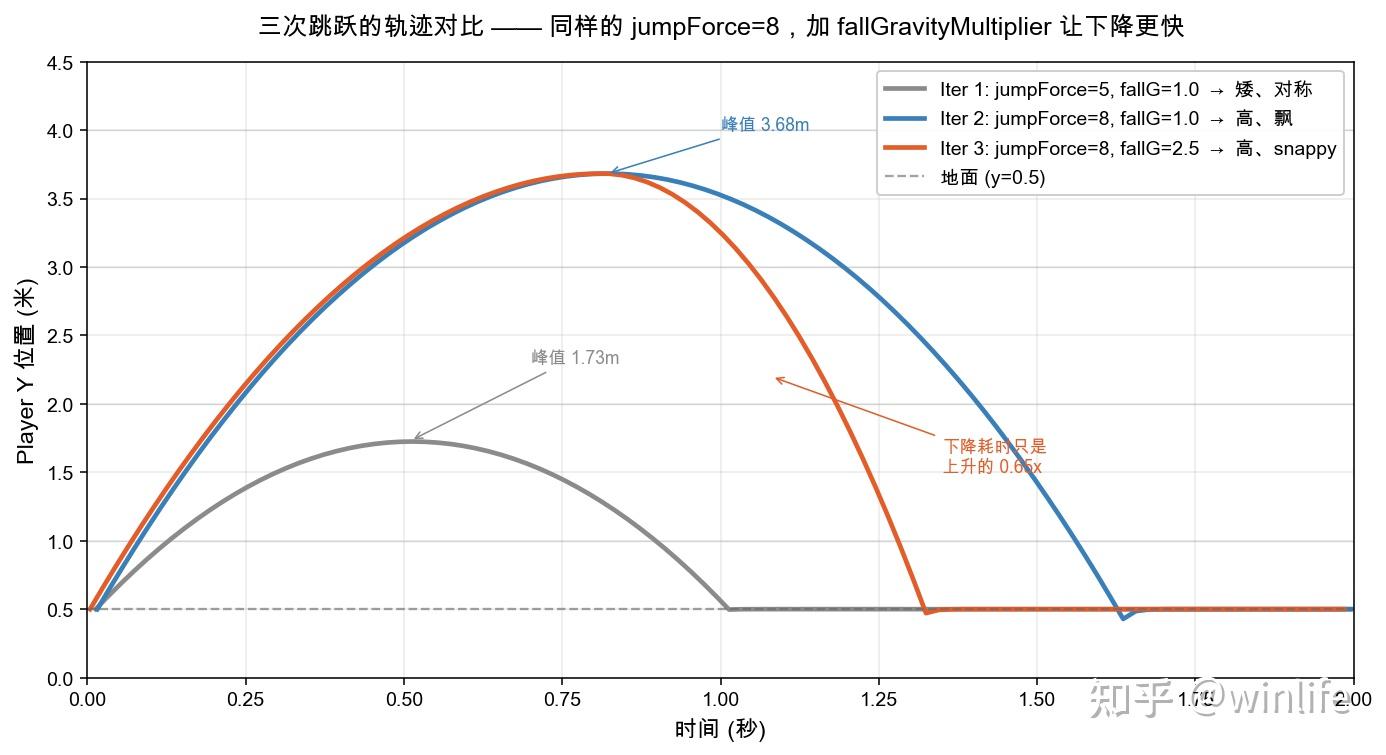
灰色(Iter 1):矮的对称弧。蓝色(Iter 2):高的对称弧,但下降段拖得很长。橙色(Iter 3):上升段和蓝色重合(因为 jumpForce 一样),但峰值之后突然加速下落,0.52 秒就落地。
这条橙色曲线就是"想要的手感"------给玩家"我能跳得高,但落地很快、节奏紧凑"的感觉。
这个闭环用到了什么
整套迭代下来,funplay-unity-mcp 提供的工具其实就这几个:
| 工具 | 用途 |
|---|---|
execute_code |
建场景、写 sampler 数据、触发 jump、读结果------绝大多数动作都靠它 |
request_recompile |
写完 JumpController.cs / JumpSampler.cs 后让 Unity 重新编译 |
wait_for_compilation |
等编译完,避免后续动作跑在旧代码上 |
enter_play_mode / exit_play_mode |
进出运行态 |
get_editor_state |
既是状态查询,也是"让一让线程,让物理跑几百毫秒"的工具 |
capture_game_view |
截 Game 视图作可视证据 |
注意一件事:这一轮没有用 simulate_key_press 。我们绕过了 Input 系统,直接在 execute_code 里 Rigidbody.AddForce 触发跳跃。这是有意的------simulate_key_press 要发到 Input.GetKeyDown 那条路径,受帧率、按键时序影响;而调参实验需要的是"在完全可控的初始条件下重复触发同一个动作",直接给 impulse 更纯粹。
但如果你要验证的不是物理参数,而是玩家操作链 ("按住空格 0.2 秒 vs 0.5 秒,跳跃曲线有什么差别"),那 simulate_key_press 就是对的工具------它支持 duration 参数,能模拟"按住---释放"。
这种闭环对游戏开发意味着什么
调一个参数 → 编译 → 进 PlayMode → 主观感受 → 退出 → 再调,这个流程的痛点不在任何一步本身------单看任何一步都不慢。痛点在于这一切都在你这一个开发者的注意力上。你要保持上下文:上一轮跳了多高?这次比上次高了还是矮了?上升 / 下降的节奏感是变好了还是变差了?
AI 能把这个上下文外化成数字。peakY 从 1.725 涨到 3.682,下降耗时从 0.82 降到 0.52------这些数字不会因为你被电话打断、被同事问问题而忘记。AI 可以一轮一轮跑下去,把每一组参数和结果记在结构化的 JSON 里。你回来看的时候,看到的是一张轨迹对比图,而不是"我记得我之前调到 6 的时候好像不错"。
这不是替代调参------主观手感判断还是人来做("snappy 到什么程度玩家觉得舒服","是不是太硬了"这一类)。这是把"测量 + 记录 + 复现"这一段交出去,让人只做"判断"那一部分。
局限
这个闭环现在还做不好的事:
主观手感的最终评判。AI 能告诉你"下降快了 36%",但不能告诉你"这个 36% 对 Metroidvania 游戏是不是合适、对休闲跳跳乐是不是过头"。这需要游戏设计师拍板。
复杂操作链的模拟 。"二段跳 + 滑墙 + 蹬墙跳"这种组合,纯靠 simulate_key_press 模拟很容易出现时序错位。这种场景建议人来录一段然后回放,AI 负责分析。
视觉手感。轨迹是数值上的,但玩家感受里还有挤压形变、粒子特效、屏幕震动、镜头跟随阻尼------这些只能靠看截图/视频判断。funplay 能截图,但"美不美"还得人来说。
完整数据
Iter 1: f=5, g=1.0 → peakY=1.725 peakT=0.513 landT=1.013 ratio=1.00
Iter 2: f=8, g=1.0 → peakY=3.682 peakT=0.816 landT=1.636 ratio=1.00
Iter 3: f=8, g=2.5 → peakY=3.682 peakT=0.804 landT=1.324 ratio=0.65代码(JumpController + JumpSampler)和样本数据 JSON 都在我本地的实验目录里,看 funplay-unity-mcp 仓库的话能复现:
- 仓库:https://github.com/FunplayAI/funplay-unity-mcp
- 上一篇入门教程:在 Unity 里用 AI 做游戏:funplay-unity-mcp 从安装到第一次让 AI 改场景
下一篇会写"让 AI 帮你跑 PlayMode 回归测试"------同样是闭环思路,但场景换成已有项目的 BUG 复现 + 修复验证。